
Memecahkan masalah data science dengan Python tidaklah mudah
Mengapa? Alat yang ada kurang cocok untuk memecahkan masalah yang berkaitan dengan deret waktu dan alat ini sulit untuk diintegrasikan satu sama lain. Metode Scikit-learn mengasumsikan bahwa data terstruktur dalam format tabel dan bahwa setiap kolom terdiri dari variabel acak yang independen dan terdistribusi secara merata - asumsi yang tidak ada hubungannya dengan data deret waktu. Paket yang memiliki modul untuk pembelajaran mesin dan bekerja dengan deret waktu, seperti statsmodels , tidak berteman baik satu sama lain. Selain itu, banyak operasi penting dengan deret waktu, seperti membagi data menjadi set pelatihan dan pengujian sepanjang interval waktu, tidak tersedia dalam paket yang ada.
Untuk mengatasi masalah serupa, sktime telah dibuat .

Logo pustaka Sktime di GitHub
Sktime adalah perangkat pembelajaran mesin sumber terbuka dengan Python yang dirancang khusus untuk bekerja dengan deret waktu. Proyek ini dikembangkan oleh komunitas dan didanai oleh British Council for Economic and Social Research , Consumer Data Research dan Alan Turing Institute .
Sktime memperluas scikit-learn API untuk memecahkan masalah deret waktu. Ini berisi semua algoritme dan alat transformasi yang diperlukan untuk menyelesaikan masalah regresi deret waktu, peramalan, dan klasifikasi secara efisien. Library tersebut menyertakan algoritme pembelajaran mesin khusus dan metode transformasi untuk deret waktu yang tidak ditemukan di library populer lainnya.
Sktime dirancang untuk bekerja dengan scikit-learn, dengan mudah mengadaptasi algoritme untuk masalah deret waktu yang saling terkait, dan membangun model yang kompleks. Bagaimana itu bekerja? Banyak masalah deret waktu terkait satu sama lain dalam satu atau lain cara. Algoritme yang dapat digunakan untuk menyelesaikan satu masalah sering kali dapat diterapkan untuk menyelesaikan masalah lain yang terkait dengannya. Ide ini disebut reduksi. Misalnya, model regresi deret waktu (yang menggunakan deret untuk memprediksi nilai keluaran) dapat digunakan kembali untuk masalah prakiraan deret waktu (yang memprediksi nilai keluaran - nilai yang akan diterima di masa mendatang).
Ide utama proyek:“Sktime menawarkan pembelajaran mesin yang mudah dipahami dan terintegrasi menggunakan deret waktu. Ia memiliki algoritme yang kompatibel dengan scikit-learn dan alat berbagi model, didukung oleh taksonomi tugas pembelajaran yang jelas, dokumentasi yang jelas, dan komunitas yang ramah. "
Dalam artikel ini, saya akan menyoroti beberapa fitur unik sktime .
Model data yang benar untuk deret waktu
Sktime menggunakan struktur data bersarang untuk deret waktu dalam bentuk kerangka data pandas .
Setiap baris dalam kerangka data tipikal berisi variabel acak yang independen dan terdistribusi merata - kasus, dan kolom - variabel berbeda. Untuk metode sktime, setiap sel dalam bingkai data Pandas sekarang dapat berisi seluruh deret waktu. Format ini fleksibel untuk data multidimensi, panel, dan heterogen, dan memungkinkan metode digunakan kembali di Pandas dan scikit-learn .
Pada tabel di bawah ini, setiap baris adalah observasi yang berisi larik deret waktu di kolom X dan nilai kelas di kolom Y. Sktime evaluator dan transformator mahir bekerja dengan deret waktu semacam itu.
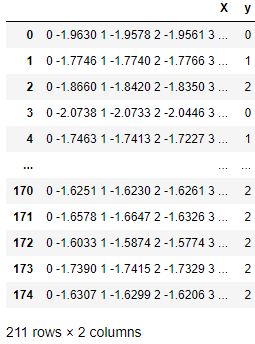
Struktur data deret waktu asli yang kompatibel dengan sktime.
Di tabel berikut, setiap elemen seri X telah dipindahkan ke kolom terpisah seperti yang diperlukan oleh metode scikit-learn. Dimensinya cukup tinggi - 251 kolom! Selain itu, pengurutan waktu kolom diabaikan oleh algoritma pembelajaran yang bekerja dengan nilai tabel (tetapi digunakan oleh klasifikasi deret waktu dan algoritma regresi).
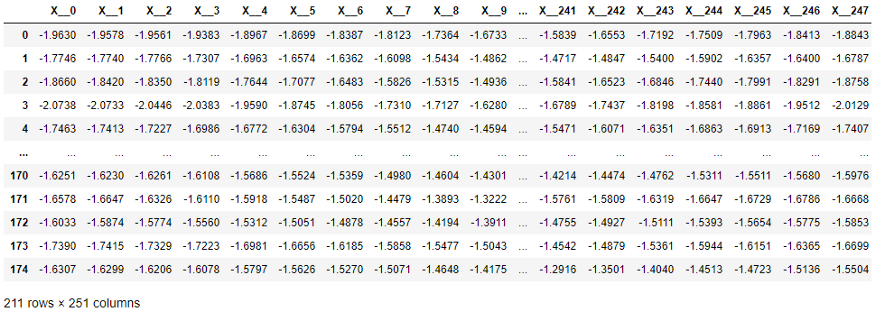
Struktur data deret waktu dibutuhkan oleh scikit-learn.
Untuk tugas pemodelan dari beberapa deret gabungan, struktur data deret waktu asli yang kompatibel dengan sktime sangat ideal. Model yang dilatih pada data tabel yang diharapkan oleh scikit-learn akan macet di banyak fitur.
Apa yang bisa dilakukan sktime ?
Menurut halaman GitHub , sktime saat ini menyediakan kemampuan berikut:
- Algoritme modern untuk klasifikasi deret waktu, analisis regresi, dan peramalan (porting dari toolkit
tsmlke Java); - Transformator deret waktu: transformasi deret tunggal (misalnya, detrending atau deseasonization), transformasi deret sebagai fitur (misalnya, ekstraksi fitur), dan alat untuk berbagi banyak transformer.
- Saluran pipa untuk transformer dan model;
- Menyiapkan model;
- Kumpulan model, misalnya, hutan acak yang sepenuhnya dapat disesuaikan untuk klasifikasi dan regresi deret waktu, ansambel untuk masalah multidimensi.
Sktime API
Seperti yang disebutkan sebelumnya, sktime mendukung metode scikit-learn API dasar untuk kelas
fit, predictdan transform.
Untuk kelas evaluator (atau model), sktime menyediakan metode
fituntuk melatih model dan metode predictuntuk menghasilkan prediksi baru.
The evaluator sktime memperpanjang scikit-belajar regressors dan pengklasifikasi dengan menyediakan waktu analog seri untuk metode ini.
Untuk kelas sktime transformer menyediakan metode
fitdan transformuntuk mengubah data seri. Ada beberapa jenis transformasi yang tersedia:
- , , ;
- , (, );
- (, );
- , , , (, ).
Contoh selanjutnya adalah adaptasi dari panduan perkiraan dari GitHub . Seri dalam contoh ini (kumpulan data maskapai Box-Jenkins) menunjukkan jumlah penumpang pesawat internasional per bulan dari tahun 1949 hingga 1960.
Pertama, muat data dan bagi menjadi rangkaian pelatihan dan pengujian, dan buat grafik. Dalam sktime memiliki dua fitur yang mudah digunakan untuk memudahkan pelaksanaan tugas-tugas ini -
temporal_train_test_splitforyang dipisahkan oleh sekumpulan data dan waktu plot_ys, diplot berdasarkan pengujian dan sampel pelatihan.
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])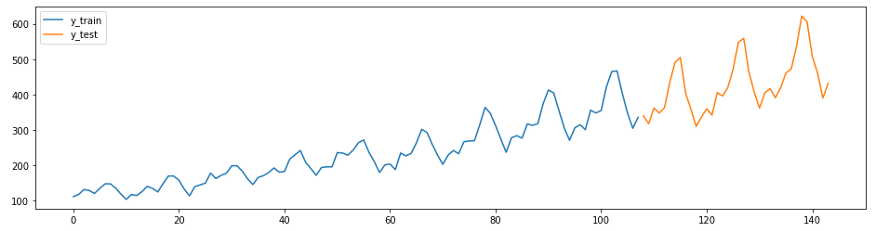
Sebelum membuat perkiraan yang kompleks, ada baiknya untuk membandingkan perkiraan Anda dengan nilai yang diperoleh menggunakan algoritme Bayesian naif. Model yang baik harus melebihi nilai-nilai ini. Dalam sktime ada metode
NaiveForecasterdengan strategi berbeda untuk membuat proyeksi baseline.
Kode dan diagram di bawah ini menunjukkan dua prediksi yang naif. Peramal c
strategy = “last”akan selalu memprediksi nilai terakhir dari rangkaian tersebut.
Peramal
strategy = “seasonal_last”memprediksi nilai terakhir seri untuk musim tertentu. Musim dalam contoh ditetapkan sebagai “sp=12”, yaitu 12 bulan.
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957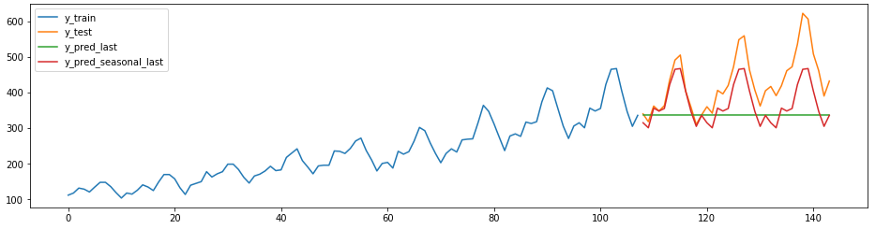
Cuplikan prediksi berikut menunjukkan bagaimana regressor sklearn yang ada dapat dengan mudah, benar dan dengan sedikit usaha diadaptasi untuk tugas perkiraan. Di bawah ini adalah metode
ReducedRegressionForecasterdari sktime yang memprediksi sebuah seri menggunakan model sklearnRandomForestRegressor. Di bawah kap, sktime membagi data pelatihan menjadi jendela 12 sehingga regressor dapat melanjutkan pelatihan.
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)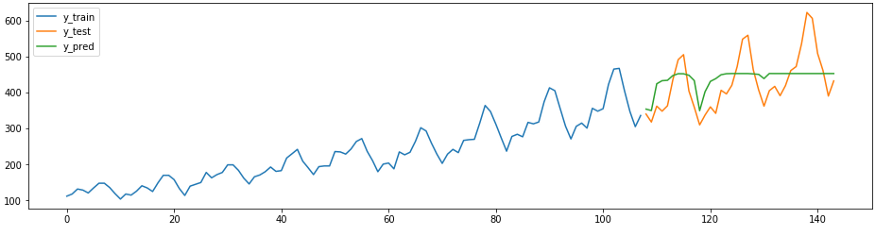
Di sktime juga punya metode peramalan sendiri, misalnya
AutoArima.
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469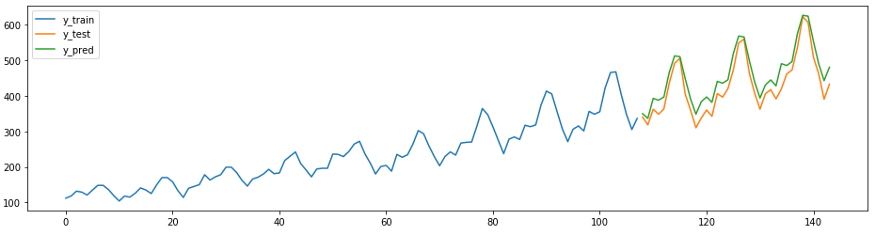
Untuk mempelajari lebih dalam tentang fungsionalitas perkiraan sktime , lihat tutorialnya di sini .
Klasifikasi deret waktu
Ini juga
sktimedapat digunakan untuk mengklasifikasikan deret waktu ke dalam kelompok yang berbeda.
Dalam contoh kode di bawah ini, klasifikasi deret waktu tunggal semudah klasifikasi di scikit-learn. Satu-satunya perbedaan adalah struktur data deret waktu bersarang yang kita bicarakan di atas.
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868Contoh diambil dari pypi.org/project/sktime
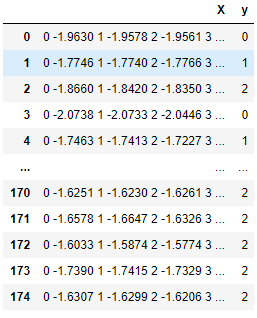
Data diteruskan ke TimeSeriesForestClassifier
Untuk mempelajari lebih lanjut tentang klasifikasi seri, lihat panduan klasifikasi univariat dan multivariat sktime .
Sumber daya sktime tambahan
Untuk mempelajari lebih lanjut tentang Sktime, lihat tautan berikut untuk dokumentasi dan contoh.
- Deskripsi API mendetail: sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .