Anda dapat melakukannya secara manual, tetapi ada juga kerangka kerja dan pustaka untuk ini yang membuat proses ini lebih cepat dan lebih mudah. Hari ini kita akan berbicara
tentang salah satu dari mereka, featuretools , serta pengalaman praktis menggunakannya.

Pipa paling modis
Halo! Saya Alexander Loskutov, saya bekerja di Leroy Merlin sebagai analis data, atau, istilahnya sekarang, seorang ilmuwan data. Tanggung jawab saya termasuk bekerja dengan data, dimulai dengan kueri analitik dan pembongkaran, diakhiri dengan pelatihan model, membungkusnya, misalnya, dalam layanan, menyiapkan pengiriman dan penyebaran kode, dan memantau pekerjaannya.
Prediksi urungkan adalah salah satu produk yang sedang saya kerjakan.
Tujuan Produk: Memprediksi kemungkinan pelanggan membatalkan pesanan online. Dengan bantuan prediksi seperti itu, kami dapat menentukan pelanggan mana yang melakukan pemesanan yang harus dipanggil terlebih dahulu untuk meminta konfirmasi pesanan, dan siapa yang tidak boleh ditelepon sama sekali. Pertama, fakta panggilan dan konfirmasi pesanan dari klien melalui telepon mengurangi kemungkinan pembatalan, dan kedua, jika kami menelepon dan orang tersebut menolak, maka kami dapat menghemat sumber daya. Karyawan akan meluangkan lebih banyak waktu yang mereka habiskan untuk mengumpulkan pesanan. Selain itu, dengan cara ini produk akan tetap ada di rak, dan jika pada saat itu pelanggan di toko membutuhkannya, dia akan dapat membelinya. Dan ini akan mengurangi jumlah barang yang dikumpulkan di pesanan yang dibatalkan nanti dan tidak ada di rak.
Pelopor
Untuk uji coba produk, kami hanya menerima pesanan pascabayar untuk diambil di beberapa toko.
Solusi siap pakai bekerja seperti ini: pesanan datang kepada kami, dengan bantuan Apache NiFi kami memperkaya informasi tentangnya - misalnya, menarik data barang. Kemudian semua ini ditransfer melalui broker pesan Apache Kafka ke layanan yang ditulis dengan Python. Layanan menghitung fitur untuk pesanan, dan kemudian model pembelajaran mesin diambil untuk mereka, yang memberikan kemungkinan pembatalan. Setelah itu, sesuai dengan logika bisnis, kami siapkan jawaban apakah kami perlu menelepon klien sekarang atau tidak (misalnya, jika pesanan dilakukan dengan bantuan karyawan di dalam toko atau pesanan dilakukan pada malam hari, maka Anda tidak boleh menelepon).
Tampaknya, apa yang mencegah dari memanggil semua orang berturut-turut? Faktanya adalah bahwa kami memiliki jumlah sumber daya yang terbatas untuk panggilan, jadi penting untuk memahami siapa yang harus menelepon, dan siapa yang pasti akan mengambil pesanan mereka tanpa menelepon.
Pengembangan model
Saya terlibat dalam layanan, model, dan, karenanya, perhitungan fitur untuk model, yang akan dibahas lebih lanjut.
Saat menghitung fitur selama pelatihan, kami menggunakan tiga sumber data.
- Piring dengan informasi meta pesanan: nomor pesanan, stempel waktu, perangkat pelanggan, metode pengiriman, metode pembayaran.
- Piring dengan posisi di kuitansi: nomor pesanan, artikel, harga, jumlah, jumlah barang dalam persediaan. Setiap posisi berjalan pada baris terpisah.
- Tabel - buku referensi barang: artikel, beberapa bidang dengan kategori barang, satuan ukuran, deskripsi.
Dengan menggunakan metode Python standar dan pustaka pandas, Anda dapat dengan mudah menggabungkan semua tabel menjadi satu tabel besar, setelah itu, dengan menggunakan groupby, Anda dapat menghitung semua jenis fitur seperti agregat berdasarkan pesanan, riwayat berdasarkan produk, berdasarkan kategori produk, dll. Tetapi ada beberapa masalah di sini.
- Paralelisme perhitungan. Groupby standar bekerja dalam satu utas, dan pada data besar (hingga 10 juta baris) seratus fitur dianggap sangat panjang, sementara kapasitas inti yang tersisa tidak aktif.
- Jumlah kode: setiap permintaan tersebut perlu ditulis secara terpisah, diperiksa kebenarannya, dan kemudian semua hasil masih perlu dikumpulkan. Ini membutuhkan waktu, terutama mengingat kerumitan beberapa penghitungan - misalnya, menghitung riwayat terbaru untuk item dalam tanda terima dan menggabungkan karakteristik ini untuk pesanan.
- Anda dapat membuat kesalahan jika Anda membuat kode semuanya dengan tangan.
Keuntungan dari pendekatan “kami menulis semuanya dengan tangan” adalah, tentu saja, kebebasan bertindak sepenuhnya, Anda dapat memberikan imajinasi Anda untuk terungkap.
Timbul pertanyaan: bagaimana bagian dari pekerjaan ini dapat dioptimalkan. Salah satu solusi adalah dengan menggunakan featuretools perpustakaan .
Di sini kita sudah beralih ke inti dari artikel ini, yaitu ke perpustakaan itu sendiri dan praktik penggunaannya.
Mengapa fiturTools?
Mari pertimbangkan berbagai kerangka kerja untuk pembelajaran mesin dalam bentuk pelat (gambar itu sendiri dicuri jujur dari sini , dan mungkin tidak semua ditunjukkan di sana, tapi tetap saja):
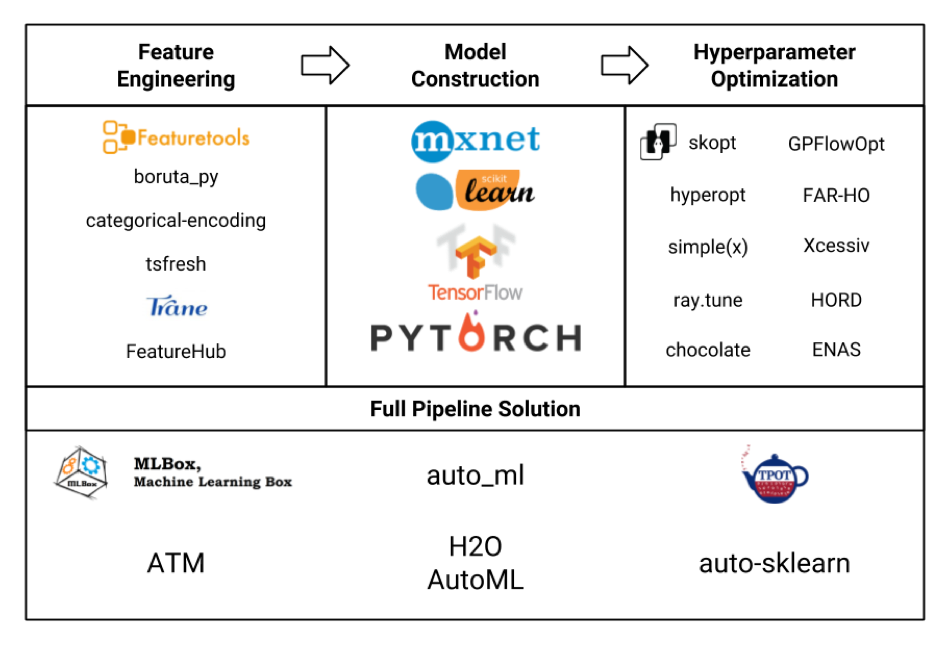
Kami terutama tertarik pada blok Rekayasa Fitur. Jika kita melihat semua framework dan paket ini, ternyata featuresetools adalah yang paling canggih, dan bahkan menyertakan fungsionalitas beberapa library lain seperti tsfresh .
Juga, kelebihan dari fitur-fitur (tidak beriklan sama sekali!) Termasuk:
- komputasi paralel di luar kotak
- ketersediaan banyak fitur di luar kotak
- fleksibilitas dalam penyesuaian - hal-hal yang cukup kompleks dapat dipertimbangkan
- akuntansi untuk hubungan antara tabel yang berbeda (relasional)
- lebih sedikit kode
- kecil kemungkinannya untuk membuat kesalahan
- dengan sendirinya, semuanya gratis, tanpa registrasi dan SMS (tapi dengan pypi)
Tapi tidak sesederhana itu.
- Kerangka kerja ini membutuhkan pembelajaran, dan penguasaan penuh akan memakan waktu yang cukup lama.
- Itu tidak memiliki komunitas yang besar, meskipun pertanyaan paling populer masih di Google dengan baik.
- Penggunaannya sendiri juga memerlukan kehati-hatian agar tidak memperbesar ruang fitur secara tidak perlu dan tidak menambah waktu kalkulasi.
Latihan
Saya akan memberikan contoh konfigurasi alat fitur.
Selanjutnya akan ada kode dengan penjelasan singkat, lebih detail tentang fitur-fitur, kelas-kelasnya, metode, kapabilitasnya, bisa Anda baca, termasuk dalam dokumentasi di website framework. Jika Anda tertarik dengan contoh aplikasi praktis dengan peragaan beberapa kemungkinan menarik dalam tugas nyata, maka tulis di komentar, mungkin saya akan menulis artikel terpisah.
Begitu.
Pertama, Anda perlu membuat objek kelas EntitySet, yang berisi tabel dengan data dan mengetahui hubungannya satu sama lain.
Izinkan saya mengingatkan Anda bahwa kami memiliki tiga tabel dengan data:
- orders_meta (informasi meta pesanan)
- orders_items_lists (informasi tentang item dalam pesanan)
- item (referensi artikel dan propertinya)
Kami menulis (selanjutnya, data hanya 3 toko yang digunakan):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

Hore! Sekarang kita memiliki objek yang memungkinkan kita menghitung semua jenis tanda.
Saya akan memberikan kode untuk menghitung fitur yang cukup sederhana: untuk setiap pesanan, kami akan menghitung berbagai statistik harga dan kuantitas barang, serta beberapa fitur berdasarkan waktu dan produk dan kategori barang yang paling sering dalam pesanan (fungsi yang melakukan berbagai transformasi dengan data disebut primitif di alat fitur) ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)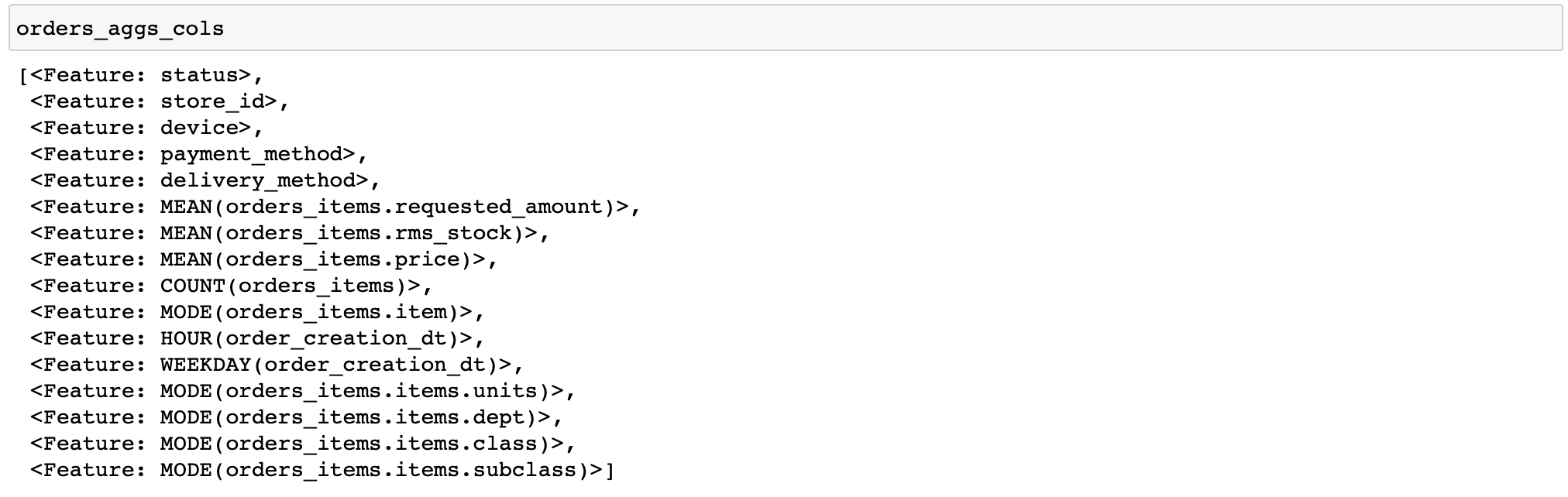

Tidak ada kolom boolean dalam tabel di sini, jadi primitif apa pun tidak diterapkan. Secara umum, sebaiknya alat fitur itu sendiri menganalisis tipe data dan hanya menerapkan fungsi yang sesuai.
Juga, saya secara manual menentukan hanya beberapa pesanan untuk kalkulasi. Ini memungkinkan Anda untuk men-debug penghitungan Anda dengan cepat (bagaimana jika Anda mengonfigurasi sesuatu yang salah).
Sekarang mari tambahkan lebih banyak agregat ke fitur kita, yaitu persentil. Tetapi alat fitur tidak memiliki primitif bawaan untuk menghitungnya. Jadi, Anda perlu menulisnya sendiri.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
Dan tambahkan ke kalkulasi:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)Maka semuanya sama. Sejauh ini, semuanya cukup sederhana dan mudah (relatif, tentu saja).
Tetapi bagaimana jika kita ingin menyimpan kalkulator fitur kita dan menggunakannya pada tahap eksekusi model, yaitu dalam layanan?
Fitur-fitur dalam pertempuran
Di sinilah kesulitan utama dimulai.
Untuk menghitung karakteristik pesanan masuk, Anda harus melakukan semua operasi dengan pembuatan EntitySet lagi. Dan jika untuk tabel besar tampaknya cukup normal untuk membuang objek pandas.DataFrame ke EntitySet, kemudian melakukan operasi serupa untuk DataFrames dari satu baris (ada lebih banyak dari mereka di tabel dengan pemeriksaan, tetapi rata-rata 3,3 posisi per cek, itu tidak cukup) - Tidak banyak. Lagi pula, pembuatan objek dan penghitungan seperti itu dengan bantuannya pasti mengandung overhead, yaitu, sejumlah operasi yang tidak dapat dihapuskan yang diperlukan, misalnya, untuk alokasi memori dan inisialisasi saat membuat objek dengan ukuran berapa pun atau proses paralelisasi itu sendiri saat menghitung beberapa fitur secara bersamaan.
Oleh karena itu, dalam mode operasi "satu pesanan pada satu waktu" di fitur fitur produk kami tidak menunjukkan efisiensi terbaik, mengambil rata-rata 75% dari waktu respons layanan (rata-rata 150-200 ms tergantung pada perangkat keras). Sebagai perbandingan: menghitung prediksi menggunakan catboost pada fitur yang sudah jadi membutuhkan waktu 3% dari waktu respons layanan, yaitu tidak lebih dari 10 md.
Selain itu, ada jebakan lain yang terkait dengan penggunaan primitif adat. Faktanya adalah bahwa kita tidak bisa begitu saja menyimpan dalam acar sebuah objek kelas yang berisi primitif yang telah kita buat, karena yang terakhir tidak diawetkan.
Lalu mengapa tidak menggunakan fungsi save_features () built-in, yang dapat menyimpan daftar objek FeatureBase, termasuk primitif yang kita buat?
Ini akan menyimpannya, tetapi tidak mungkin untuk membacanya nanti menggunakan fungsi load_features () jika kita tidak membuatnya lagi sebelumnya. Artinya, primitif yang, secara teori, harus kita baca dari disk, pertama-tama kita buat lagi sehingga kita tidak akan pernah menggunakannya lagi.
Ini terlihat seperti ini:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorDalam fungsi load (), Anda harus membuat primitif (mendeklarasikan variabel custom_primitives) yang tidak akan digunakan. Tetapi tanpa ini, pemuatan fitur lebih lanjut di tempat fungsi load_features () dipanggil akan gagal dengan RuntimeError: Primitive "persentile05" dalam modul "featureetools.primitives.base.aggregation_primitive_base" tidak ditemukan .
Ternyata tidak terlalu logis, tetapi berfungsi, dan Anda dapat menyimpan kedua kalkulator yang sudah terikat ke format data tertentu (karena fitur terkait dengan EntitySet yang dihitung, meskipun tanpa nilai itu sendiri), dan kalkulator hanya dengan daftar primitif yang diberikan.
Mungkin di masa mendatang hal ini akan diperbaiki dan akan memungkinkan untuk dengan mudah menyimpan kumpulan objek FeatureBase yang sewenang-wenang.
Lalu mengapa kita menggunakannya?
Karena dari segi waktu pengembangan murah, sedangkan waktu respon di bawah beban yang ada cocok dengan SLA kami (5 detik) dengan margin.
Namun, Anda harus menyadari bahwa untuk layanan yang harus dengan cepat menanggapi permintaan yang sering diterima, menggunakan fitur fitur tanpa "squat" tambahan seperti panggilan asinkron akan menjadi masalah.
Ini adalah pengalaman kami menggunakan alat fitur pada tahap pembelajaran dan inferensi.
Kerangka kerja ini sangat baik sebagai alat untuk menghitung dengan cepat sejumlah besar fitur untuk pelatihan, ini sangat mengurangi waktu pengembangan dan kemungkinan kesalahan.
Apakah akan menggunakannya pada tahap penarikan tergantung pada tugas Anda.