
Mengapa oilmen membutuhkan NLP? Bagaimana Anda membuat komputer memahami jargon profesional? Apakah mungkin untuk menjelaskan kepada mesin apa itu "tekanan", "respons throttle", "annular"? Bagaimana karyawan baru dan asisten suara terhubung? Kami akan mencoba menjawab pertanyaan-pertanyaan ini dalam artikel tentang penerapan asisten digital dalam perangkat lunak untuk dukungan produksi minyak, yang memfasilitasi pekerjaan rutin seorang pengembang geologi.
Kami di institut tersebut mengembangkan perangkat lunak kami sendiri ( https://rn.digital/ ) untuk industri minyak, dan agar pengguna menyukainya, Anda tidak hanya perlu mengimplementasikan fungsi yang berguna di dalamnya, tetapi juga memikirkan tentang kenyamanan antarmuka setiap saat. Salah satu tren di UI / UX saat ini adalah transisi ke antarmuka suara. Bagaimanapun, apa pun yang dikatakan seseorang, bentuk interaksi yang paling alami dan nyaman bagi seseorang adalah ucapan. Jadi keputusan dibuat untuk mengembangkan dan menerapkan asisten suara di produk perangkat lunak kami.
Selain meningkatkan komponen UI / UX, pengenalan asisten juga memungkinkan Anda mengurangi "ambang" bagi karyawan baru untuk bekerja dengan perangkat lunak. Fungsionalitas program kami sangat luas, dan mungkin perlu waktu lebih dari satu hari untuk mengetahuinya. Kemampuan untuk "meminta" asisten untuk menjalankan perintah yang diperlukan akan mengurangi waktu yang dihabiskan untuk menyelesaikan tugas, sekaligus mengurangi stres pada pekerjaan baru.
Karena layanan keamanan perusahaan sangat sensitif terhadap transfer data ke layanan eksternal, kami berpikir untuk mengembangkan asisten berdasarkan solusi sumber terbuka yang memungkinkan Anda memproses informasi secara lokal.
Secara struktural, asisten kami terdiri dari modul-modul berikut:
- Pengenalan Ucapan (ASR)
- Pemilihan objek semantik (Natural Language Understanding, NLU)
- Eksekusi perintah
- Sintesis ucapan (Text-to-Speech, TTS)
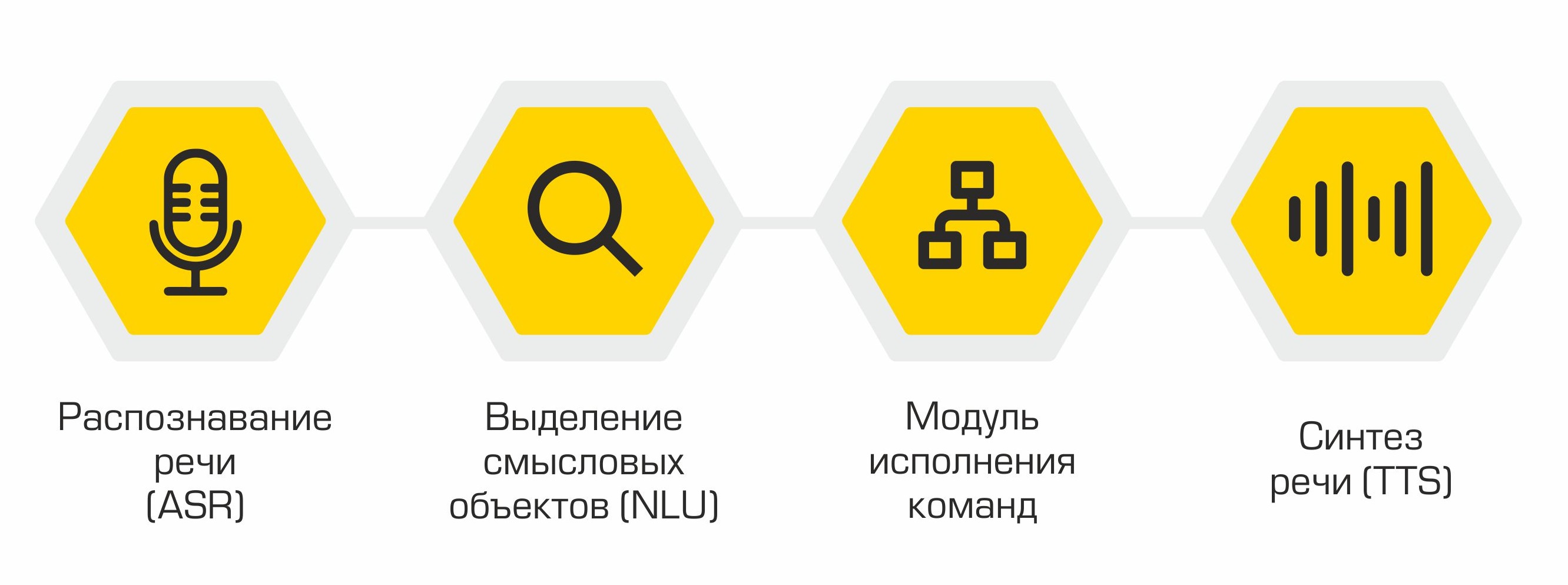
Prinsip asisten: dari kata-kata (pengguna) ke tindakan (dalam perangkat lunak)!
Output dari setiap modul berfungsi sebagai pintu masuk untuk komponen selanjutnya dalam sistem. Jadi, ucapan pengguna diubah menjadi teks dan dikirim untuk diproses ke algoritme pembelajaran mesin untuk menentukan maksud pengguna. Bergantung pada maksud ini, kelas yang diperlukan diaktifkan dalam modul eksekusi perintah, yang memenuhi permintaan pengguna. Setelah menyelesaikan operasi, modul eksekusi perintah mengirimkan informasi tentang status eksekusi perintah ke modul sintesis ucapan, yang kemudian akan memberi tahu pengguna.
Setiap modul pembantu adalah layanan mikro. Jadi, jika diinginkan, pengguna dapat melakukannya tanpa teknologi ucapan sama sekali dan langsung beralih ke "otak" asisten - ke modul untuk menyorot objek semantik - melalui bentuk bot obrolan.
Pengenalan suara
Tahap pertama pengenalan suara adalah pemrosesan sinyal ucapan dan ekstraksi fitur. Representasi paling sederhana dari sinyal audio adalah osilogram. Ini mencerminkan jumlah energi pada waktu tertentu. Namun, informasi ini tidak cukup untuk menentukan suara yang diucapkan. Penting bagi kita untuk mengetahui berapa banyak energi yang terkandung dalam rentang frekuensi yang berbeda. Untuk melakukan ini, dengan menggunakan transformasi Fourier, transisi dibuat dari osilogram ke spektrum.
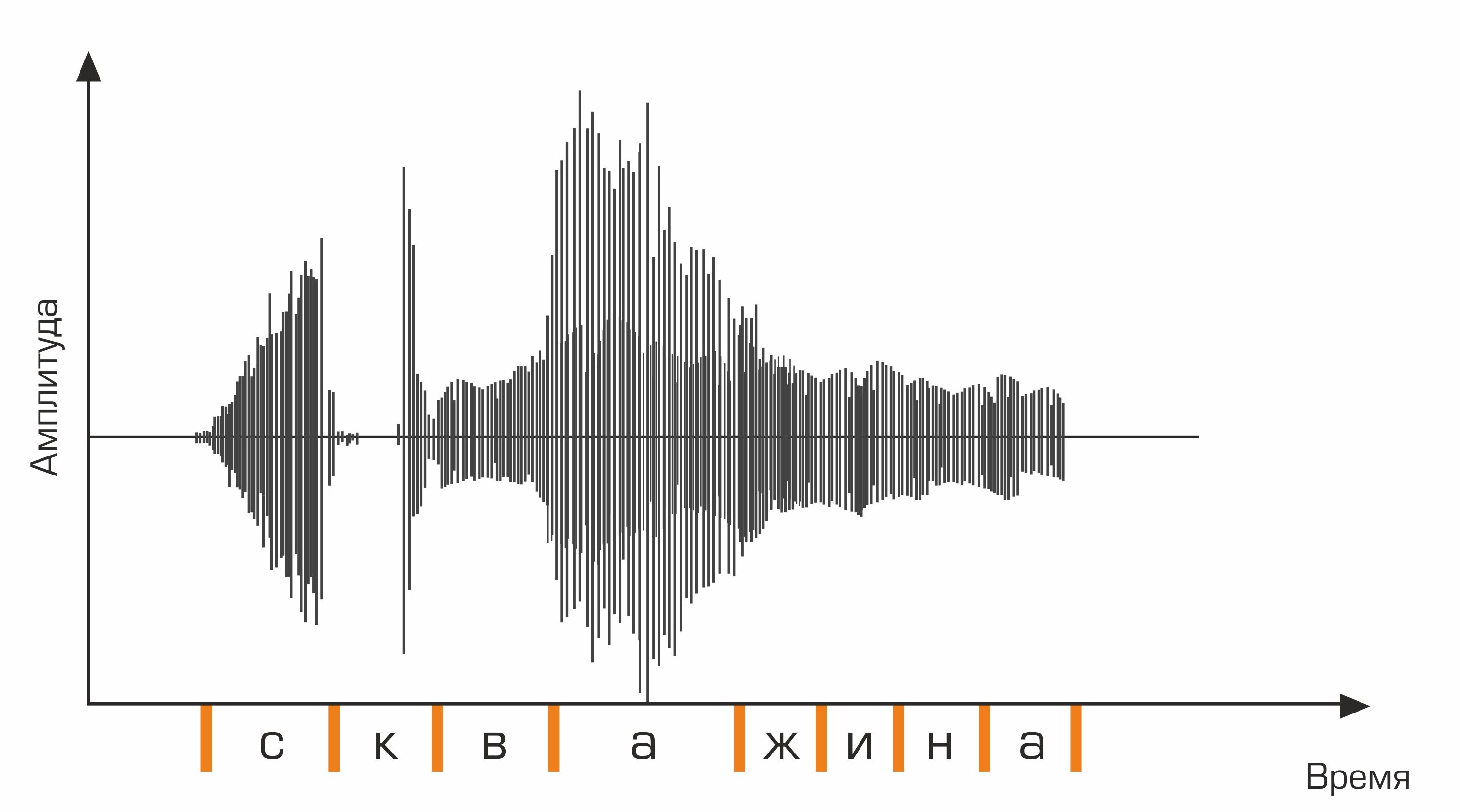
Ini adalah osilogram.
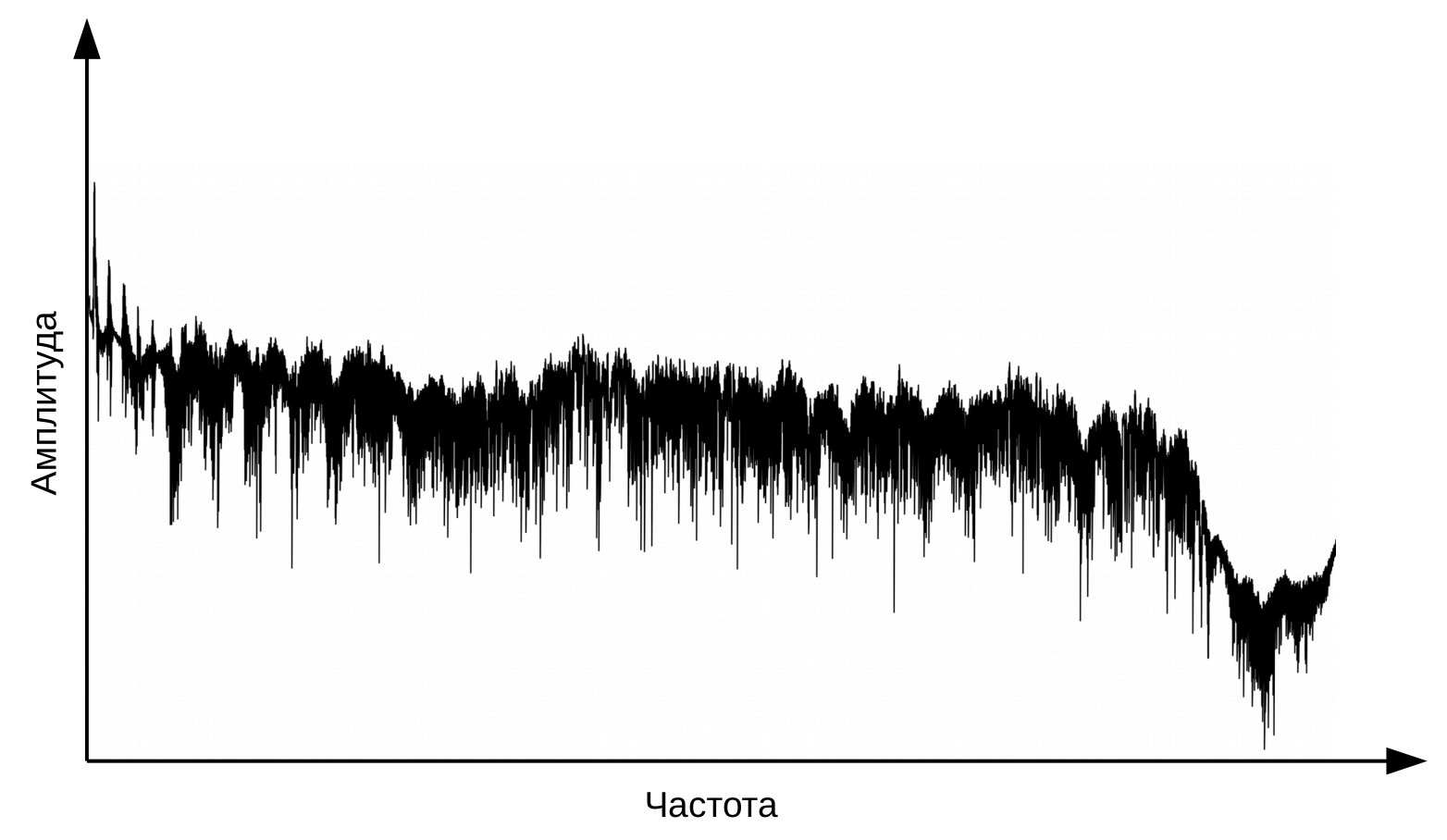
Dan inilah spektrum untuk setiap momen dalam waktu.
Di sini perlu diklarifikasi bahwa ucapan terbentuk ketika aliran udara bergetar melewati laring (sumber) dan saluran vokal (filter). Untuk mengklasifikasikan fonem, kita hanya memerlukan informasi tentang konfigurasi filter, yaitu tentang posisi bibir dan lidah. Informasi ini dapat dibedakan dengan transisi dari spektrum ke cepstrum (cepstrum - anagram dari kata spektrum), dilakukan dengan menggunakan transformasi Fourier terbalik dari logaritma spektrum. Sekali lagi, sumbu x bukanlah frekuensi, tetapi waktu. Istilah "frekuensi" digunakan untuk membedakan antara domain waktu cepstrum dan sinyal audio asli (Oppenheim, Schafer. Digital Signal Processing, 2018).
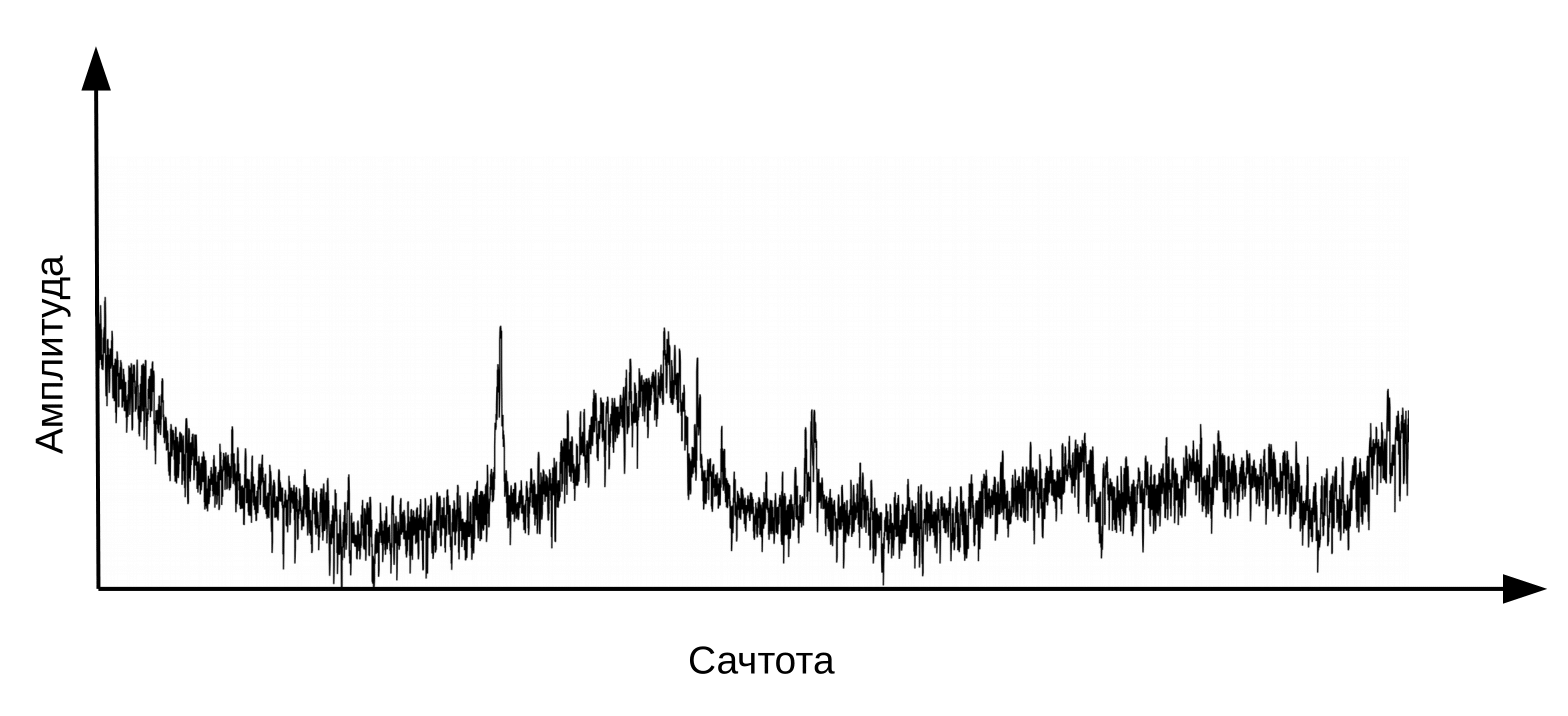
Cepstrum, atau sederhananya "spektrum logaritma spektrum". Ya, ya, istilah yang umum , bukan salah ketik
Informasi tentang posisi saluran suara ditemukan di 12 koefisien cepstrum pertama. 12 koefisien cepstral ini dilengkapi dengan fitur dinamis (delta dan delta-delta) yang menjelaskan perubahan dalam sinyal audio. (Jurafsky, Martin. Pidato dan Pemrosesan Bahasa, 2008). Vektor nilai yang dihasilkan disebut vektor MFCC (koefisien cepstral frekuensi-mel) dan merupakan fitur akustik paling umum yang digunakan dalam pengenalan suara.
Apa yang terjadi selanjutnya dengan tanda-tandanya? Mereka digunakan sebagai masukan untuk model akustik. Ini menunjukkan unit linguistik mana yang paling mungkin untuk "menelurkan" vektor MFCC semacam itu. Dalam sistem yang berbeda, unit linguistik seperti itu dapat menjadi bagian dari fonem, fonem, atau bahkan kata. Dengan demikian, model akustik mengubah urutan vektor MFCC menjadi urutan fonem yang paling mungkin.
Selanjutnya, untuk urutan fonem, perlu dilakukan pemilihan urutan kata yang sesuai. Di sinilah kamus bahasa berperan, berisi transkripsi semua kata yang dikenali oleh sistem. Menyusun kamus semacam itu adalah proses yang melelahkan yang membutuhkan pengetahuan ahli tentang fonetik dan fonologi bahasa tertentu. Contoh baris dari kamus transkripsi:
baiklah skv aa zh yn ay
Pada langkah selanjutnya, model bahasa menentukan probabilitas sebelumnya dari kalimat dalam bahasa tersebut. Dengan kata lain, model tersebut memberikan perkiraan seberapa besar kemungkinan kalimat tersebut muncul dalam suatu bahasa. Model bahasa yang baik akan menentukan bahwa frasa "Bagan tarif minyak" lebih mungkin daripada kalimat "Bagan sembilan minyak".
Kombinasi model akustik, model bahasa, dan kamus pelafalan menciptakan “kisi” hipotesis - semua kemungkinan urutan kata yang kemungkinan besar dapat ditemukan menggunakan algoritme pemrograman dinamis. Sistemnya akan menawarkannya sebagai teks yang dikenali.
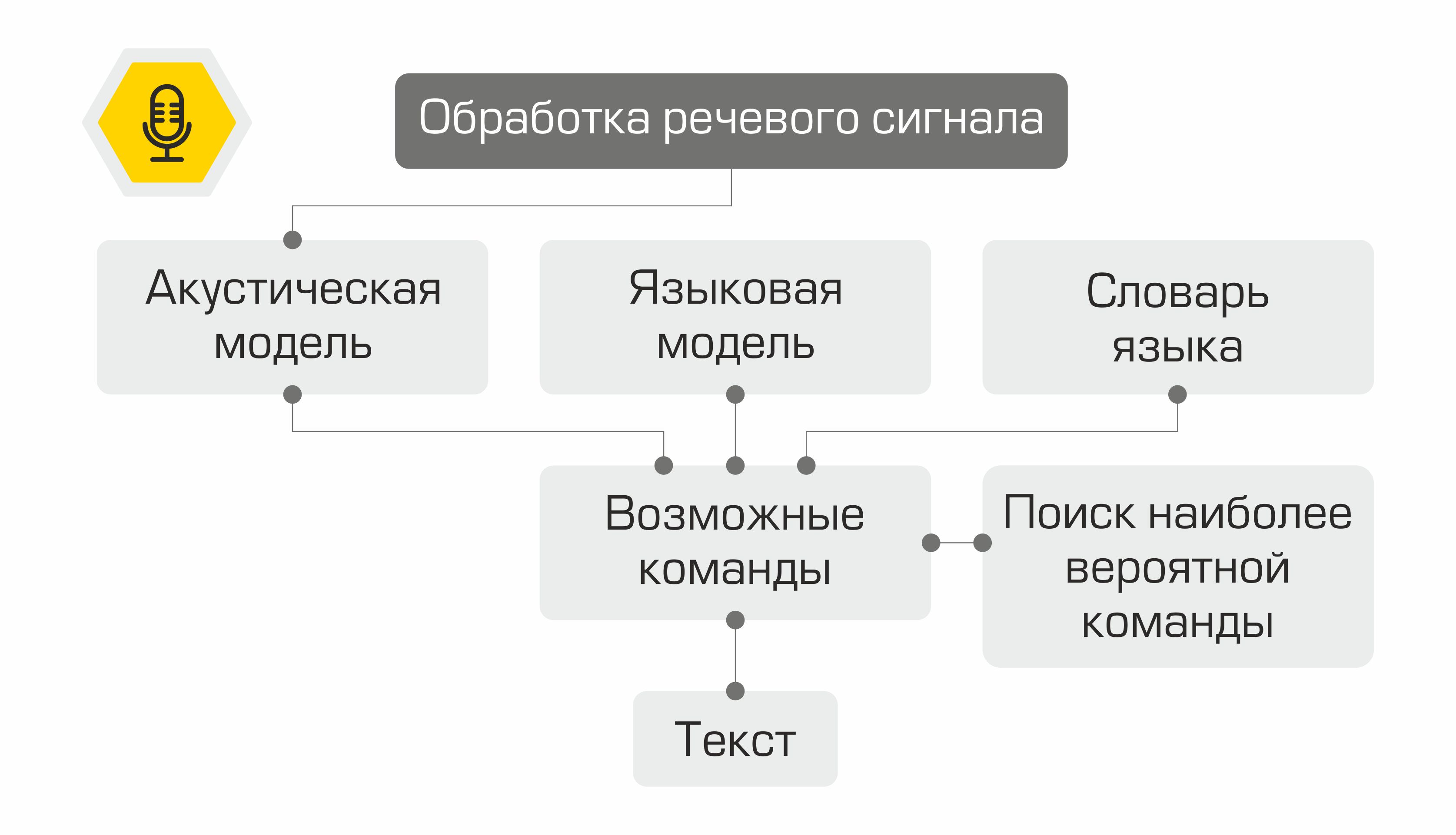
Representasi skematis dari pengoperasian sistem pengenalan suara
Tidaklah praktis untuk menemukan kembali roda dan menulis pustaka pengenalan suara dari awal, jadi pilihan kami jatuh pada kerangka kaldi . Keuntungan yang tidak diragukan lagi dari pustaka adalah fleksibilitasnya, memungkinkan, jika perlu, untuk membuat dan memodifikasi semua komponen sistem. Selain itu, Lisensi Apache 2.0 memungkinkan Anda untuk menggunakan perpustakaan secara bebas dalam pengembangan komersial.
Sebagai data untuk pelatihan model akustik digunakan dataset audio freeware VoxForge . Untuk mengubah urutan fonem menjadi kata-kata, kami menggunakan kamus bahasa Rusia yang disediakan oleh perpustakaan CMU Sphinx . Karena kamus tidak memuat pengucapan istilah-istilah khusus untuk industri minyak, berdasarkan itu, menggunakan utilitasg2p-seq2seq melatih model grafem ke fonem untuk membuat transkripsi kata baru dengan cepat. Model bahasa dilatih baik pada transkrip audio dari VoxForge dan pada kumpulan data yang kami buat, yang berisi istilah industri minyak dan gas, nama ladang, dan perusahaan pertambangan.
Pemilihan objek semantik
Jadi, kami mengenali ucapan pengguna, tetapi ini hanya sebaris teks. Bagaimana Anda memberi tahu komputer apa yang harus dilakukan? Sistem kontrol suara paling awal menggunakan set perintah yang sangat terbatas. Setelah mengenali salah satu frasa ini, dimungkinkan untuk memanggil operasi yang sesuai. Sejak itu, teknologi dalam pemrosesan dan pemahaman bahasa alami (NLP dan NLU, masing-masing) telah melompat maju. Saat ini, model yang dilatih pada sejumlah besar data dapat memahami dengan baik arti sebuah pernyataan.
Untuk mengekstrak makna dari teks frase yang dikenali, perlu untuk menyelesaikan dua masalah pembelajaran mesin:
- Klasifikasi tim pengguna (Klasifikasi Intent).
- Alokasi entitas bernama (Pengakuan Entitas Bernama).
Saat mengembangkan model, kami menggunakan pustaka Rasa open source , yang didistribusikan di bawah Lisensi Apache 2.0.
Untuk mengatasi masalah pertama, teks harus disajikan sebagai vektor numerik yang dapat diproses oleh mesin. Untuk transformasi seperti itu, model saraf StarSpace digunakan , yang memungkinkan " menumpuk " teks permintaan dan kelas permintaan ke dalam ruang bersama.

Model Saraf StarSpace
Selama pelatihan, jaringan saraf belajar untuk membandingkan entitas, sehingga meminimalkan jarak antara vektor permintaan dan vektor kelas yang tepat dan memaksimalkan jarak ke vektor kelas yang berbeda. Selama pengujian, kelas y dipilih untuk kueri x sehingga:
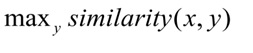
Jarak cosinus digunakan sebagai ukuran kemiripan vektor :, di
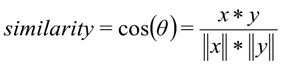
mana
x adalah permintaan pengguna, y adalah kategori permintaan.
3000 kueri ditandai untuk melatih pengklasifikasi maksud pengguna. Total kami lulus dari 8 kelas. Kami membagi sampel menjadi sampel pelatihan dan sampel uji dalam rasio 70/30 menggunakan metode stratifikasi variabel target. Stratifikasi memungkinkan kami untuk mempertahankan distribusi asli kelas di kereta dan ujian. Kualitas model yang dilatih dinilai dengan beberapa kriteria sekaligus:
- Ingat - proporsi permintaan yang diklasifikasikan dengan benar untuk semua permintaan kelas ini.
- Pangsa permintaan yang diklasifikasikan dengan benar (Akurasi).
- Presisi - proporsi permintaan yang diklasifikasikan dengan benar relatif terhadap semua permintaan yang dikaitkan sistem ke kelas ini.
- F1 – .
Juga, matriks kesalahan sistem digunakan untuk menilai kualitas model klasifikasi. Sumbu y adalah kelas pernyataan yang sebenarnya, sumbu x adalah kelas yang diprediksi oleh algoritme.
Pada sampel kontrol, model menunjukkan hasil sebagai berikut:
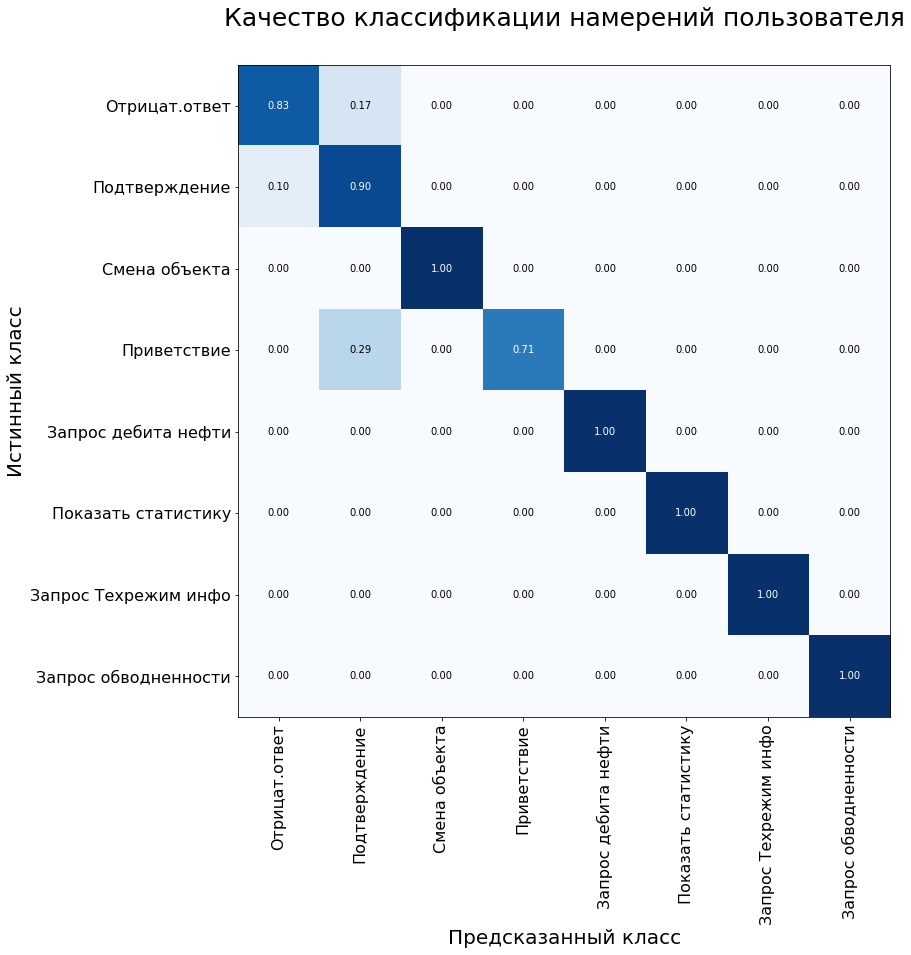
Metrik model pada set data pengujian: Akurasi - 92%, F1 - 90%.
Tugas kedua - pemilihan entitas bernama - adalah mengidentifikasi kata dan frasa yang menunjukkan objek atau fenomena tertentu. Entitas tersebut dapat berupa, misalnya, nama deposito atau perusahaan pertambangan.
Untuk mengatasi masalah tersebut, kami menggunakan algoritme Bidang Acak Bersyarat, yang merupakan sejenis bidang Markov. CRF adalah model diskriminatif, yaitu model probabilitas bersyarat P(Y | X) keadaan laten Y (kelas kata) dari observasi X (kata).
Untuk memenuhi permintaan pengguna, asisten kami perlu menyorot tiga jenis entitas bernama: nama bidang, nama sumur, dan nama objek pengembangan. Untuk melatih model, kami menyiapkan kumpulan data dan membuat anotasi: setiap kata dalam sampel diberi kelas yang sesuai.

Contoh dari set pelatihan untuk masalah Pengakuan Entitas Bernama.
Namun, ternyata semuanya tidak sesederhana itu. Jargon profesional cukup umum di kalangan pengembang lapangan dan ahli geologi. Tidak sulit bagi orang untuk memahami bahwa "injektor" adalah sumur injeksi, dan "Samotlor", kemungkinan besar, berarti ladang Samotlor. Untuk model yang dilatih dengan jumlah data terbatas, masih sulit untuk menggambar paralel seperti itu. Untuk mengatasi keterbatasan ini, fitur luar biasa dari perpustakaan Rasa membantu membuat kamus sinonim.
## sinonim: Samotlor
- Samotlor
- Samotlor
- ladang minyak terbesar di Rusia
Penambahan sinonim juga memungkinkan kami untuk sedikit memperluas sampel. Volume seluruh kumpulan data adalah 2000 permintaan, yang kami bagi menjadi train dan test dalam rasio 70/30. Kualitas model dinilai menggunakan metrik F1 dan adalah 98% saat diuji pada sampel kontrol.
Eksekusi perintah
Bergantung pada kelas permintaan pengguna yang ditentukan di langkah sebelumnya, sistem mengaktifkan kelas yang sesuai di kernel perangkat lunak. Setiap kelas memiliki setidaknya dua metode: metode yang secara langsung menjalankan permintaan dan metode untuk menghasilkan respons bagi pengguna.
Misalnya, ketika sebuah perintah ditetapkan ke kelas "request_production_schedule", sebuah objek dari kelas RequestOilChart dibuat yang mengeluarkan informasi tentang produksi minyak dari database. Entitas bernama khusus (misalnya, nama sumur dan bidang) digunakan untuk mengisi slot dalam kueri untuk mengakses database atau kernel perangkat lunak. Asisten menjawab dengan bantuan templat yang disiapkan, ruang-ruang yang diisi dengan nilai-nilai data yang diunggah.

Contoh prototipe asisten yang berfungsi.
Sintesis ucapan

Cara kerja sintesis ucapan serentak.
Teks pemberitahuan pengguna yang dihasilkan pada tahap sebelumnya ditampilkan di layar dan juga digunakan sebagai masukan untuk modul sintesis ucapan lisan. Pembuatan ucapan dilakukan menggunakan perpustakaan RHVoice... Lisensi GNU LGPL v2.1 memungkinkan framework digunakan sebagai komponen perangkat lunak komersial. Komponen utama dari sistem sintesis wicara adalah prosesor linguistik, yang memproses teks masukan. Teks dinormalisasi: angka direduksi menjadi representasi tertulis, singkatan diuraikan, dll. Kemudian, menggunakan kamus pengucapan, transkripsi untuk teks dibuat, yang kemudian dikirim ke input prosesor akustik. Komponen ini bertanggung jawab untuk memilih elemen suara dari database ucapan, menggabungkan elemen yang dipilih dan memproses sinyal suara.
Menyatukan semuanya
Jadi, semua komponen asisten suara sudah siap. Tinggal "mengumpulkan" mereka dalam urutan dan tes yang benar. Seperti yang kami sebutkan sebelumnya, setiap modul adalah layanan mikro. Kerangka RabbitMQ digunakan sebagai bus untuk menghubungkan semua modul. Ilustrasi dengan jelas menunjukkan pekerjaan internal asisten menggunakan contoh permintaan pengguna yang khas:
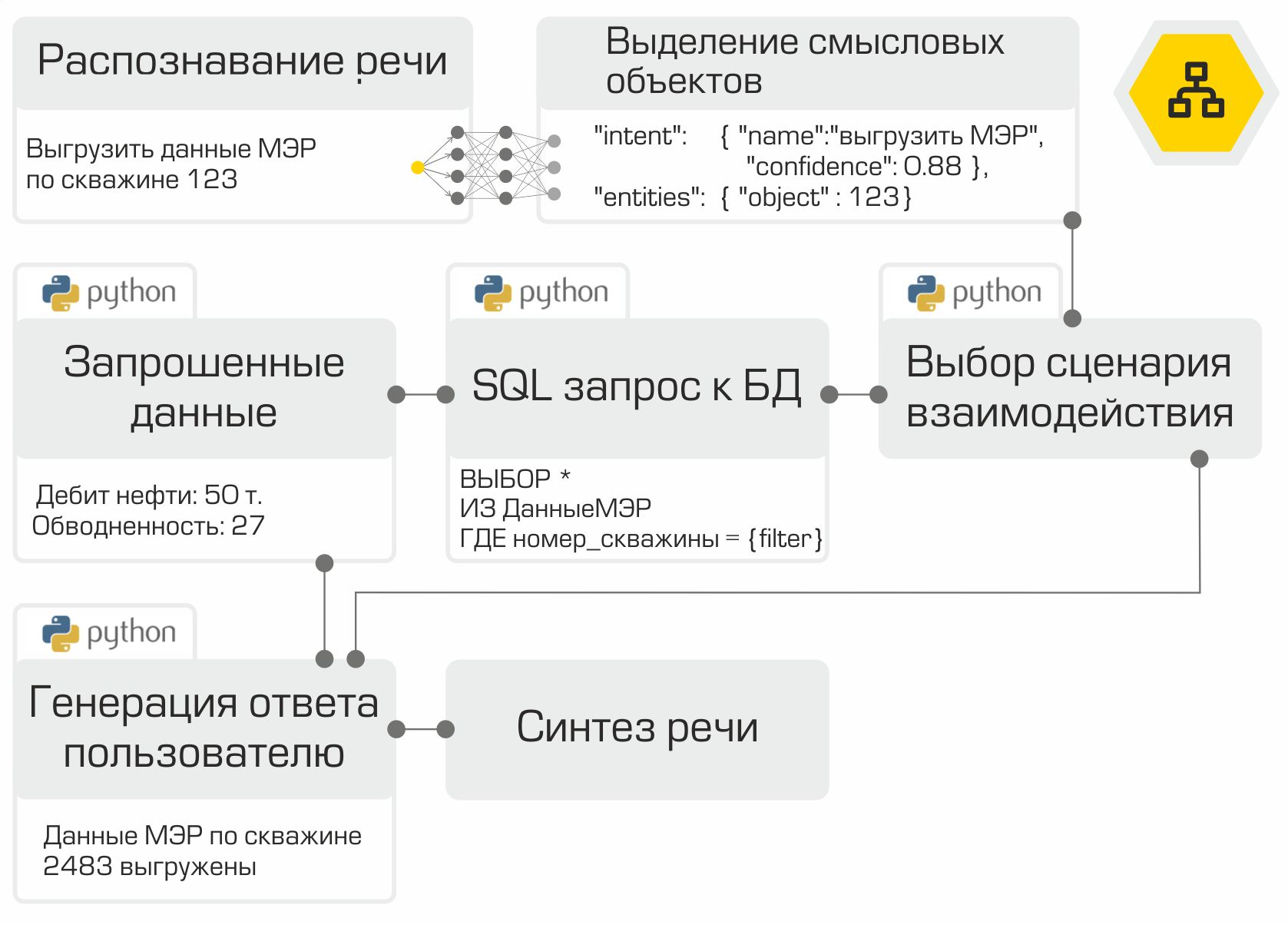
Solusi yang dibuat memungkinkan penempatan seluruh infrastruktur di jaringan Perusahaan. Pemrosesan informasi lokal adalah keuntungan utama dari sistem. Namun, Anda harus membayar otonomi karena Anda harus mengumpulkan data, melatih, dan menguji model sendiri, daripada menggunakan kekuatan vendor top di pasar asisten digital.
Saat ini kami sedang mengintegrasikan asisten ke dalam salah satu produk kami.
Betapa mudahnya mencari sumur atau semak favorit Anda hanya dengan satu frasa!
Pada tahap selanjutnya, direncanakan untuk mengumpulkan dan menganalisis umpan balik dari pengguna. Ada juga rencana untuk memperluas perintah yang dikenali dan dijalankan oleh asisten.
Proyek yang dijelaskan dalam artikel ini bukanlah satu-satunya contoh penggunaan metode pembelajaran mesin di Perusahaan kita. Jadi, misalnya, analisis data digunakan untuk secara otomatis memilih calon sumur untuk pengukuran geologi dan teknis, yang tujuannya adalah untuk merangsang produksi minyak. Di salah satu artikel yang akan datang, kami akan memberi tahu Anda bagaimana kami memecahkan masalah keren ini. Berlangganan ke blog kami jangan sampai ketinggalan!