Di artikel ini, Anda akan belajar
- Apa itu CNN dan bagaimana cara kerjanya
- Apa itu peta fitur
- Apa itu max pooling
- Fungsi kerugian untuk berbagai tugas pembelajaran mendalam
Pengenalan kecil
Rangkaian artikel ini bertujuan untuk memberikan pemahaman intuitif tentang cara kerja deep learning, apa tugasnya, arsitektur jaringan, mengapa salah satunya lebih baik dari yang lain. Hanya ada sedikit hal spesifik dalam semangat "bagaimana menerapkannya". Mendalami setiap detail membuat materi menjadi terlalu rumit bagi kebanyakan audiens. Tentang cara kerja grafik komputasi atau cara kerja propagasi mundur melalui lapisan konvolusional telah ditulis. Dan, yang terpenting, ini ditulis jauh lebih baik daripada yang akan saya jelaskan.
Pada artikel sebelumnya, kita membahas FCNN - apa itu FCNN dan apa masalahnya. Solusi untuk masalah tersebut terletak pada arsitektur jaringan saraf konvolusional.
Convolutional Neural Networks (CNN)
Jaringan saraf konvolusional. Ini terlihat seperti ini (arsitektur vgg-16):
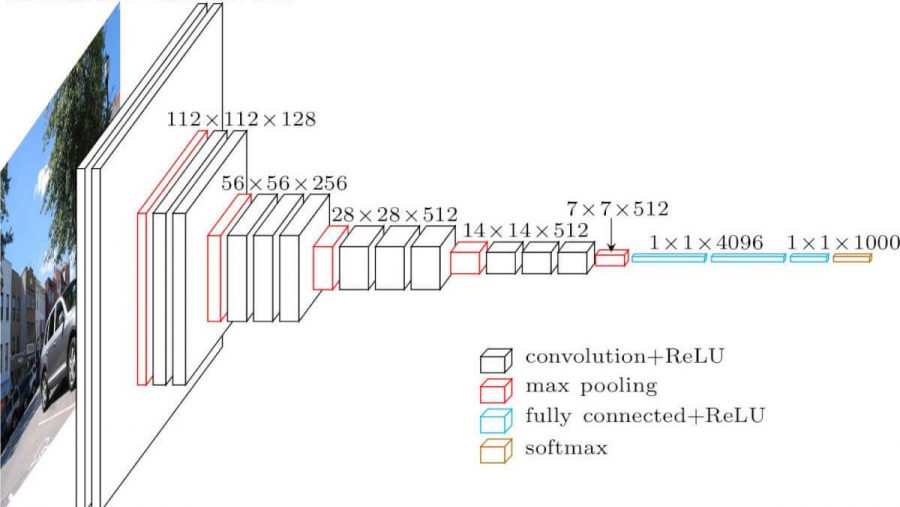
Apa perbedaan dari jaringan yang sepenuhnya terhubung? Lapisan tersembunyi sekarang memiliki operasi konvolusi.
Seperti inilah bentuk konvolusinya:

Kami hanya mengambil gambar (untuk saat ini - saluran tunggal), mengambil kernel konvolusi (matriks), yang terdiri dari parameter pelatihan kami, "melapiskan" kernel (biasanya 3x3) pada gambar, melakukan perkalian elemen-bijaksana dari semua nilai piksel dari gambar yang mengenai kernel. Kemudian semua ini dijumlahkan (Anda juga perlu menambahkan parameter bias - offset), dan kami mendapatkan beberapa nomor. Nomor ini adalah elemen dari lapisan keluaran. Kami memindahkan inti ini di atas gambar kami dengan beberapa langkah (langkah) dan mendapatkan elemen berikutnya. Matriks baru dibangun dari elemen tersebut, dan kernel konvolusi berikutnya diterapkan padanya (setelah fungsi aktivasi diterapkan padanya). Dalam kasus ketika gambar input adalah tiga saluran, kernel konvolusi juga tiga saluran - filter.
Tapi semuanya tidak sesederhana itu di sini. Matriks yang kita dapatkan setelah konvolusi disebut peta fitur, karena mereka menyimpan beberapa fitur dari matriks sebelumnya, tetapi dalam bentuk yang berbeda. Dalam praktiknya, beberapa filter konvolusi digunakan sekaligus. Ini dilakukan untuk "membawa" sebanyak mungkin fitur ke lapisan konvolusi berikutnya. Dengan setiap lapisan konvolusi, fitur kami, yang berada di gambar masukan, disajikan lebih banyak dan lebih banyak lagi dalam bentuk abstrak.
Beberapa catatan lagi:
- Setelah dilipat, peta fitur kita menjadi lebih kecil (lebar dan tinggi). Kadang-kadang, untuk mengurangi lebar dan tinggi lebih lemah, atau tidak menguranginya sama sekali (konvolusi yang sama), metode bantalan nol digunakan - mengisi dengan nol "sepanjang kontur" dari peta fitur masukan.
- Setelah lapisan konvolusional terbaru, tugas klasifikasi dan regresi menggunakan beberapa lapisan yang terhubung sepenuhnya.
Mengapa ini lebih baik dari FCNN
- Sekarang kita dapat memiliki lebih sedikit parameter yang bisa dilatih antar lapisan
- Sekarang, saat kami mengekstrak fitur dari gambar, kami tidak hanya memperhitungkan satu piksel, tetapi juga piksel di dekatnya (mengidentifikasi pola tertentu dalam gambar)
Penyatuan maks
Ini terlihat seperti ini:
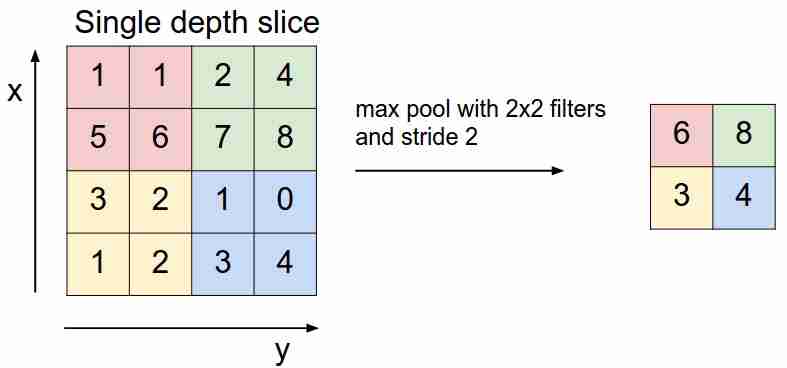
Kami "menggeser" di atas peta fitur kami dengan filter dan hanya memilih fitur yang paling penting (dalam hal sinyal masuk, sebagai nilai tertentu), mengurangi dimensi peta fitur. Ada juga penyatuan rata-rata (berbobot), ketika kita menghitung rata-rata nilai yang termasuk dalam filter, tetapi dalam praktiknya, penyatuan maksimumlah yang lebih dapat diterapkan.
- Lapisan ini tidak memiliki parameter yang bisa dilatih
Fungsi kerugian
Kami memberi makan jaringan X ke input, mencapai output, menghitung nilai fungsi kerugian, melakukan algoritme propagasi mundur - inilah cara jaringan saraf modern belajar (sejauh ini, kami hanya berbicara tentang pembelajaran yang diawasi).
Bergantung pada tugas yang diselesaikan jaringan neural, fungsi kerugian yang berbeda digunakan:
- Masalah regresi . Kebanyakan mereka menggunakan fungsi mean squared error (MSE).
- Masalah klasifikasi . Mereka terutama menggunakan kerugian cross-entropy.
Kami belum mempertimbangkan tugas lain - ini akan dibahas di artikel berikut. Mengapa sebenarnya fungsi seperti itu untuk tugas-tugas seperti itu? Di sini Anda perlu memasukkan estimasi kemungkinan maksimum dan matematika. Siapa peduli - Saya menulis tentang itu di sini .
Kesimpulan
Saya juga ingin menarik perhatian Anda ke dua hal yang digunakan dalam arsitektur jaringan saraf, termasuk yang konvolusional - putus sekolah (Anda dapat membacanya di sini ) dan normalisasi batch . Saya sangat merekomendasikan membaca.
Pada artikel selanjutnya kita akan menganalisis arsitektur CNN, kita akan mengerti mengapa yang satu lebih baik dari yang lain.