
Pembelajaran mesin semakin bergeser dari model yang dirancang tangan ke jaringan pipa yang dioptimalkan secara otomatis menggunakan alat-alat seperti H20 , TPOT, dan sklearn otomatis . Perpustakaan-perpustakaan ini, bersama dengan teknik-teknik seperti pencarian acak , bertujuan untuk menyederhanakan pemilihan model dan menyetel bagian-bagian pembelajaran mesin dengan menemukan model terbaik untuk suatu dataset tanpa intervensi manual. Namun, pengembangan objek, bisa dibilang aspek yang lebih berharga dari pipa pembelajaran mesin, tetap hampir sepenuhnya manusia.
Fitur desain ( Rekayasa fitur), juga dikenal sebagai pembuatan fitur, adalah proses menciptakan fitur baru dari data yang ada untuk melatih model pembelajaran mesin. Langkah ini mungkin lebih penting daripada model aktual yang digunakan karena algoritma pembelajaran mesin hanya belajar dari data yang kami berikan, dan membuat fitur yang relevan dengan tugas sangat diperlukan (lihat artikel yang sangat bagus “Beberapa Hal yang Berguna. Hal yang Perlu Diketahui Tentang Pembelajaran Mesin " ).
Biasanya, pengembangan fitur adalah proses manual yang panjang berdasarkan pengetahuan domain, intuisi, dan manipulasi data. Proses ini bisa sangat membosankan, dan karakteristik akhirnya akan dibatasi oleh subjektivitas manusia dan waktu. Desain fitur otomatis bertujuan untuk membantu ilmuwan data secara otomatis membuat banyak objek kandidat dari suatu set data yang darinya yang terbaik dapat dipilih dan digunakan untuk pelatihan.
Pada artikel ini, kita akan melihat contoh penggunaan pengembangan fitur otomatis dengan pustaka Python featuresetools.... Kami akan menggunakan kumpulan data sampel untuk menunjukkan dasar-dasarnya (perhatikan pos selanjutnya menggunakan data nyata). Kode lengkap dari artikel ini tersedia di GitHub .
Dasar-dasar Pengembangan Fitur
Pengembangan karakteristik berarti menciptakan karakteristik tambahan dari data yang ada, yang sering tersebar di beberapa tabel terkait. Pengembangan fitur membutuhkan penggalian informasi yang relevan dari data dan memasukkannya ke dalam satu tabel yang kemudian dapat digunakan untuk melatih model pembelajaran mesin.
Proses menciptakan karakteristik sangat memakan waktu, karena biasanya diperlukan beberapa langkah untuk membuat setiap karakteristik baru, terutama ketika menggunakan informasi dari beberapa tabel. Kami dapat mengelompokkan operasi pembuatan fitur ke dalam dua kategori: transformasi dan agregasi . Mari kita lihat beberapa contoh untuk melihat konsep ini dalam tindakan.
Transformasibertindak pada satu tabel (dalam istilah Python, tabel hanya Pandas
DataFrame), membuat fitur baru dari satu atau lebih kolom yang ada. Misalnya, jika kita memiliki tabel pelanggan di bawah ini,
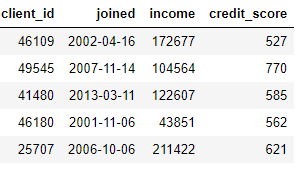
kita dapat membuat fitur dengan menemukan bulan dari sebuah kolom
joinedatau mengambil logaritma natural dari sebuah kolom income. Ini adalah kedua transformasi karena mereka hanya menggunakan informasi dari satu tabel.
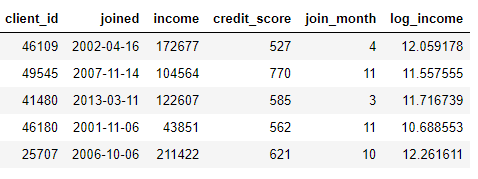
Di sisi lain, agregasi dilakukan lintas tabel dan menggunakan hubungan satu ke banyak untuk mengelompokkan kasus dan kemudian menghitung statistik. Misalnya, jika kami memiliki tabel lain dengan informasi tentang pinjaman pelanggan, di mana setiap pelanggan dapat memiliki beberapa pinjaman, kami dapat menghitung statistik seperti nilai rata-rata pinjaman, maksimum dan minimum untuk setiap pelanggan.
Proses ini mencakup pengelompokan tabel pinjaman menurut pelanggan, menghitung agregasi, dan kemudian menggabungkan data yang diterima dengan data pelanggan. Ini adalah bagaimana kita bisa melakukannya dengan Python menggunakan bahasa Pandas .
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)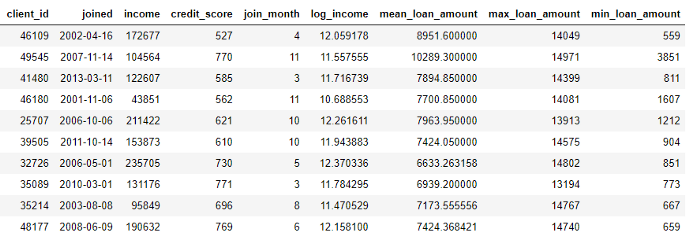
Operasi ini tidak rumit sendiri, tetapi jika kita memiliki ratusan variabel yang tersebar di puluhan tabel, proses ini tidak dapat dilakukan secara manual. Idealnya, kita membutuhkan solusi yang dapat secara otomatis melakukan transformasi dan agregasi di beberapa tabel dan menggabungkan data yang dihasilkan menjadi satu tabel. Meskipun Pandas adalah sumber yang bagus, masih ada banyak manipulasi data yang ingin kami lakukan secara manual! (Untuk informasi lebih lanjut tentang mendesain fitur secara manual, lihat Buku Pegangan Ilmu Data Python yang luar biasa .)
Peralatan khusus
Untungnya, featureetools adalah solusi tepat yang kami cari. Pustaka Python open source ini secara otomatis menghasilkan banyak ciri dari seperangkat tabel terkait. Guarantetools didasarkan pada teknik yang dikenal sebagai " Sintesis Fitur Mendalam " yang terdengar jauh lebih mengesankan daripada yang sebenarnya (namanya berasal dari menggabungkan beberapa fitur, bukan karena menggunakan pembelajaran yang mendalam!).
Deep Feature Synthesis menggabungkan beberapa operasi transformasi dan agregasi (disebut primitif fiturdalam kamus FeatureTools) untuk membuat fitur dari data yang tersebar di banyak tabel. Seperti kebanyakan ide dalam pembelajaran mesin, ini adalah metode yang kompleks berdasarkan pada konsep-konsep sederhana. Dengan mempelajari satu blok bangunan pada satu waktu, kita dapat membentuk pemahaman yang baik tentang teknik yang kuat ini.
Pertama, mari kita lihat data dari contoh kita. Kami telah melihat sesuatu dari dataset di atas, dan set lengkap tabel terlihat seperti ini:
clients: informasi dasar tentang klien dalam asosiasi kredit. Setiap klien hanya memiliki satu baris dalam kerangka data ini
loans: pinjaman kepada pelanggan. Setiap kredit hanya memiliki barisnya sendiri dalam kerangka data ini, tetapi pelanggan dapat memiliki beberapa kredit.
payments: pembayaran pinjaman. Setiap pembayaran hanya memiliki satu baris, tetapi setiap pinjaman akan memiliki beberapa pembayaran.
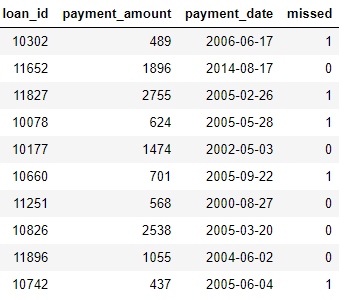
Jika kami memiliki tugas pembelajaran mesin seperti memprediksi apakah pelanggan akan membayar pinjaman di masa depan, kami ingin menggabungkan semua informasi pelanggan menjadi satu tabel. Tabel tersebut ditautkan (melalui variabel
client_iddan loan_id), dan kita bisa menggunakan serangkaian transformasi dan agregasi untuk menyelesaikan proses secara manual. Namun, kita akan segera melihat bahwa alih-alih kita dapat menggunakan featureetools untuk mengotomatiskan proses.
Entities and EntitySets (entitas dan set entitas)
Dua konsep pertama dari featureetools adalah entitas dan entitas . Entity hanyalah sebuah tabel (atau jika Anda berpikir dalam Panda). EntitySet adalah kumpulan tabel dan hubungan di antara mereka. Bayangkan entitasset hanyalah struktur data Python lain dengan metode dan atributnya sendiri. Kita bisa membuat seperangkat entitas kosong diooltetools menggunakan yang berikut ini:
DataFrame
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')Sekarang kita perlu menambahkan entitas. Setiap entitas harus memiliki indeks, yang merupakan kolom dengan semua elemen unik. Artinya, setiap nilai dalam indeks harus muncul hanya sekali dalam tabel. Indeks dalam bingkai data
clientsadalah client_idkarena setiap klien hanya memiliki satu baris dalam bingkai data itu. Kami menambahkan entitas dengan indeks yang ada ke entitas yang ditetapkan menggunakan sintaks berikut:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients,
index = 'client_id', time_index = 'joined')Kerangka data
loansjuga memiliki indeks unik loan_id, dan sintaksis untuk menambahkannya ke set entitas sama dengan untuk clients. Namun, tidak ada indeks unik untuk kerangka data pembayaran. Ketika kita menambahkan entitas ini ke set entitas, kita perlu memberikan parameter make_index = Truedan menentukan nama indeks. Selain itu, sementara featuresetools akan secara otomatis menyimpulkan tipe data dari setiap kolom dalam suatu entitas, kita dapat menimpanya dengan meneruskan kamus jenis kolom ke parameter variable_types.
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')Untuk kerangka data ini, meskipun
missedmerupakan bilangan bulat, ini bukan variabel numerik karena hanya dapat mengambil 2 nilai diskrit, jadi kami memberi tahuoolsetools untuk memperlakukannya sebagai variabel kategorikal. Setelah menambahkan bingkai data ke set entitas, kami memeriksa salah satu dari mereka:
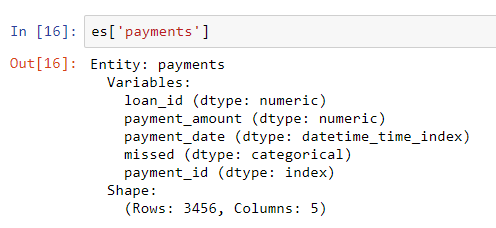
Jenis kolom disimpulkan dengan benar dengan revisi yang ditentukan. Selanjutnya, kita perlu menunjukkan bagaimana tabel dalam himpunan entitas terkait.
Hubungan antar tabel
Cara terbaik untuk mewakili hubungan antara dua tabel adalah dengan analogi orangtua-anak . Hubungan satu-ke-banyak: setiap orang tua dapat memiliki banyak anak. Di area tabel, tabel induk memiliki satu baris untuk setiap orangtua, tetapi tabel anak dapat memiliki beberapa baris yang sesuai dengan beberapa anak dari orangtua yang sama.
Misalnya, dalam dataset kami,
clientsframe adalah induk dari loansframe. Setiap klien hanya memiliki satu baris clients, tetapi dapat memiliki beberapa baris loans. Demikian loansjuga orang tuapaymentskarena setiap pinjaman akan memiliki beberapa pembayaran. Orang tua terhubung dengan anak-anak mereka dengan variabel yang sama. Ketika kami melakukan agregasi, kami mengelompokkan tabel anak dengan variabel induk dan menghitung statistik pada anak-anak dari setiap orangtua.
Untuk meresmikan hubungan dalam Featureetools , kita hanya perlu menentukan variabel yang menghubungkan dua tabel bersama.
clientsdan tabel loansdikaitkan dengan variabel client_id, dan loans, dan payments- dengan bantuan loan_id. Sintaks untuk membuat hubungan dan menambahkannya ke set entitas ditunjukkan di bawah ini:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es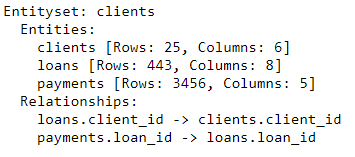
Set entitas sekarang berisi tiga entitas (tabel) dan hubungan yang mengikat entitas ini bersama-sama. Setelah menambahkan entitas dan memformalkan hubungan, set entitas kami selesai dan kami siap untuk membuat fitur.
Fitur primitif
Sebelum kita dapat bergerak sepenuhnya ke sintesis sifat-sifat yang mendalam, kita perlu memahami sifat-sifat primitif . Kita sudah tahu apa itu, tetapi kita memanggil mereka dengan nama yang berbeda! Ini hanya operasi dasar yang kami gunakan untuk membentuk fitur baru:
- Agregasi: Operasi dilakukan pada hubungan orangtua-anak (satu-ke-banyak) yang dikelompokkan berdasarkan orang tua dan menghitung statistik untuk anak-anak. Contohnya adalah mengelompokkan tabel
loansdenganclient_iddan menentukan jumlah pinjaman maksimum untuk setiap klien. - Konversi: operasi dilakukan dari satu tabel ke satu atau beberapa kolom. Contohnya termasuk perbedaan antara dua kolom dalam tabel yang sama, atau nilai absolut kolom.
Fitur-fitur baru dibuat di dalam featureetools menggunakan primitif ini, baik sendiri atau sebagai beberapa primitif. Di bawah ini adalah daftar beberapa primitif diooltetools (kami juga dapat mendefinisikan primitif khusus ):
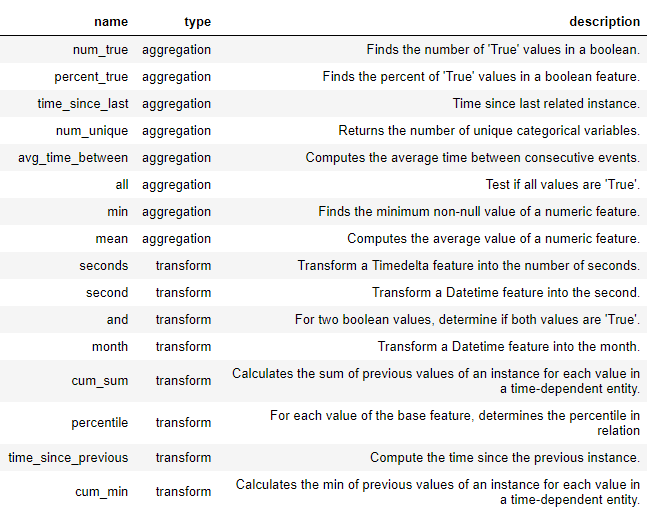
Primitif ini dapat digunakan sendiri atau dikombinasikan untuk membuat fitur. Untuk membuat fitur dengan primitif yang ditentukan, kami menggunakan fungsi
ft.dfs(singkatan dari sintesis fitur mendalam). Kami melewati serangkaian entitas target_entity, yang merupakan tabel yang ingin kami tambahkan fitur yang dipilih trans_primitives(transformasi) dan agg_primitives(agregat):
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])Hasilnya adalah kerangka data fitur baru untuk setiap klien (karena kami membuat klien
target_entity). Misalnya, kami memiliki satu bulan di mana setiap klien bergabung, yang merupakan transformasi primitif:
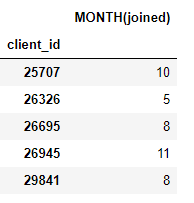
Kami juga memiliki sejumlah primitif agregasi seperti jumlah pembayaran rata-rata untuk setiap klien:
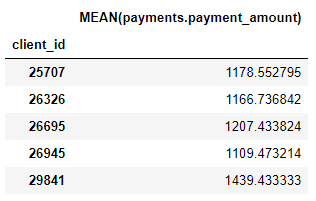
Meskipun kami hanya menetapkan beberapa primitif, tooletools telah menciptakan banyak fitur baru dengan menggabungkan dan menumpuk primitif ini.
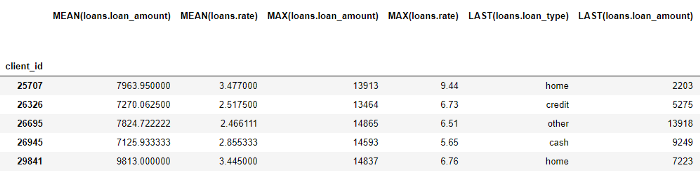
Kerangka data lengkap berisi 793 kolom fitur baru!
Sintesis Tanda yang Dalam
Kami sekarang memiliki segalanya untuk memahami sintesis fitur mendalam (dfs). Bahkan, kita sudah melakukan dfs di pemanggilan fungsi sebelumnya! Ciri yang dalam hanyalah sifat yang terdiri dari kombinasi beberapa primitif, dan dfs adalah nama proses yang menciptakan sifat-sifat tersebut. Kedalaman fitur yang mendalam adalah jumlah primitif yang diperlukan untuk membuat fitur.
Misalnya, kolom
MEAN (payment.payment_amount)adalah fitur yang dalam dengan kedalaman 1 karena dibuat menggunakan agregasi tunggal. Elemen dengan kedalaman dua adalah ini LAST(loans(MEAN(payment.payment_amount)). Ini dilakukan dengan menggabungkan dua agregasi: LAST (terbaru) di atas MEAN. Ini merupakan pembayaran rata-rata untuk pinjaman terbaru untuk setiap klien.
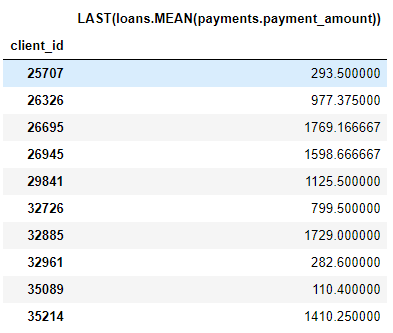
Kita dapat menyusun fitur ke kedalaman apa pun yang kita inginkan, tetapi dalam praktiknya saya tidak pernah melampaui kedalaman 2. Setelah titik ini, fitur sulit ditafsirkan, tetapi saya mendesak siapa pun yang tertarik untuk mencoba "masuk lebih dalam" .
Kita tidak perlu secara manual menentukan primitif, tetapi sebaliknya kita dapat membiarkan set fitur secara otomatis memilih fitur untuk kita. Untuk ini kami menggunakan pemanggilan fungsi yang sama
ft.dfs, tetapi kami tidak memberikan primitif apa pun:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()
Featureetools telah menciptakan banyak fitur baru bagi kami. Meskipun proses ini secara otomatis membuat sifat-sifat baru, itu tidak akan menggantikan Data Scientist karena kita masih harus mencari tahu apa yang harus dilakukan dengan semua sifat itu. Misalnya, jika tujuan kami adalah untuk memprediksi apakah pelanggan akan membayar kembali pinjaman, kami mungkin mencari tanda-tanda yang paling relevan dengan hasil tertentu. Selain itu, jika kita memiliki pengetahuan tentang bidang subjek, kita dapat menggunakannya untuk memilih fitur primitif spesifik atau untuk sintesis mendalam fitur kandidat .
Langkah selanjutnya
Desain fitur otomatis memecahkan satu masalah tetapi menciptakan masalah lain: Terlalu banyak fitur. Meskipun sulit untuk mengatakan mana dari fitur-fitur ini yang penting sebelum memasang model, kemungkinan besar tidak semuanya relevan dengan tugas yang ingin kita latih model kita. Selain itu, terlalu banyak fitur yang dapat menurunkan kinerja model karena fitur yang kurang berguna menyingkirkan yang lebih penting.
Masalah atribut yang terlalu banyak dikenal sebagai kutukan dimensi . Ketika jumlah fitur (dimensi data) meningkat dalam model, menjadi lebih sulit untuk mempelajari korespondensi antara fitur dan tujuan. Faktanya, jumlah data yang diperlukan agar model dapat bekerja dengan baik adalahskala secara eksponensial dengan jumlah fitur .
Kutukan dimensi dikombinasikan dengan pengurangan fitur (juga dikenal sebagai pemilihan fitur) : proses menghilangkan fitur yang tidak perlu. Ini dapat mengambil banyak bentuk: Analisis Komponen Utama (PCA), SelectKBest, menggunakan nilai-nilai fitur dari model, atau pengkodean otomatis menggunakan jaringan saraf dalam. Namun, pengurangan fitur adalah topik terpisah untuk artikel lain. Pada titik ini, kita tahu bahwa kita dapat menggunakan featureetools untuk membuat banyak fitur dari banyak tabel dengan sedikit usaha!
Keluaran
Seperti banyak topik dalam pembelajaran mesin, desain fitur otomatis dengan featureetools adalah konsep kompleks berdasarkan ide-ide sederhana. Menggunakan konsep himpunan entitas, entitas, dan hubungan ,ooletetools dapat melakukan sintesis fitur yang mendalam untuk membuat fitur baru. Sintesis fitur yang mendalam, pada gilirannya, menggabungkan primitif - agregat yang beroperasi melalui hubungan satu-ke-banyak antara tabel, dan transformasi , fungsi yang diterapkan pada satu atau beberapa kolom dalam satu tabel - untuk membuat fitur baru dari beberapa tabel.

Cari tahu detail cara mendapatkan profesi profil tinggi dari awal atau Tingkatkan keterampilan dan gaji dengan mengikuti kursus online berbayar SkillFactory:
- Kursus Pembelajaran Mesin (12 minggu)
- Data Science (12 )
- (9 )
- «Python -» (9 )
- DevOps (12 )
- - (8 )