
Artikel ini menjelaskan detail teknis dari masalah yang menyebabkan Slack mogok pada 12 Mei 2020. Untuk lebih lanjut tentang proses menanggapi insiden itu, lihat kronologi Ryan Katkov, "Kedua Tangan di Remote . "
Pada 12 Mei 2020, Slack mengalami kecelakaan signifikan pertama dalam waktu yang lama. Segera kami menerbitkan ringkasan kejadian tersebut , tetapi ini adalah kisah yang cukup menarik, jadi kami ingin membahas detail teknis secara lebih rinci.
Pengguna memperhatikan downtime pada pukul 4:45 malam PT, tetapi cerita sebenarnya dimulai sekitar pukul 8:30 pagi. Tim Rekayasa Keandalan Basis Data menerima peringatan tentang peningkatan beban yang signifikan pada bagian infrastruktur. Pada saat yang sama, Tim Lalu Lintas menerima peringatan bahwa kami tidak membuat beberapa permintaan API.
Peningkatan beban basis data disebabkan oleh penyebaran konfigurasi baru, yang menyebabkan bug kinerja lama. Perubahan dengan cepat terlihat dan digulung kembali - itu adalah bendera untuk fungsi yang melakukan penyebaran bertahap, sehingga masalahnya diselesaikan dengan cepat. Insiden itu berdampak kecil pada pelanggan, tetapi hanya berlangsung tiga menit, dan sebagian besar pengguna masih dapat berhasil mengirim pesan selama kesalahan singkat pagi ini.
Salah satu konsekuensi dari insiden tersebut adalah perluasan yang signifikan dari lapisan aplikasi web inti kami. CEO kami Stuart Butterfield menulis tentang beberapa dampak karantina dan isolasi diri pada penggunaan Slack. Sebagai hasil dari pandemi, kami meluncurkan lebih banyak contoh di tingkat aplikasi web daripada di Februari tahun ini. Kami mengukur dengan cepat ketika pekerja dimuat, seperti yang terjadi di sini - tetapi pekerja menunggu lebih lama untuk beberapa permintaan basis data untuk diselesaikan, yang menyebabkan beban lebih tinggi. Selama kejadian, kami meningkatkan jumlah instance sebesar 75%, yang menghasilkan jumlah host aplikasi web tertinggi yang pernah kami jalankan hingga saat ini.
Segalanya tampak bekerja dengan baik selama delapan jam berikutnya - sampai muncul sejumlah besar kesalahan HTTP 503 . Kami meluncurkan saluran respons insiden baru, dan insinyur aplikasi web yang bertugas secara manual meningkatkan armada aplikasi web sebagai mitigasi awal. Anehnya, itu tidak membantu sama sekali. Kami sangat cepat memperhatikan bahwa beberapa contoh aplikasi web sedang dalam beban berat, sedangkan sisanya tidak. Sejumlah penelitian telah mulai menyelidiki kinerja aplikasi web dan load balancing. Setelah beberapa menit, kami mengidentifikasi masalahnya.
Di balik load balancer Layer 4 adalah seperangkat instance HAProxy untuk mendistribusikan permintaan ke tingkat aplikasi web. Kami menggunakan Konsul untuk penemuan layanan dan templat-konsul untuk merender daftar backend aplikasi web yang sehat di mana HAProxy harus merutekan permintaan.
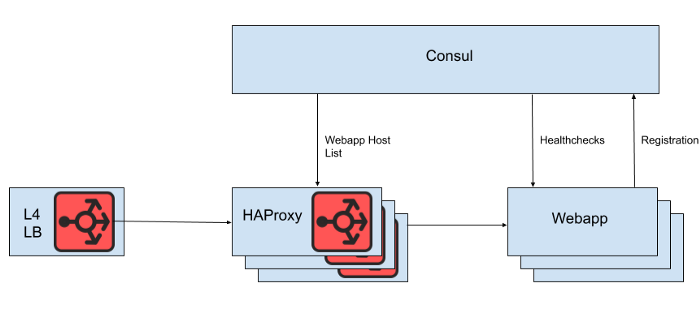
Ara. 1. Tampilan arsitektur Slack load balancing tingkat tinggi
Namun, kami tidak merender daftar host aplikasi web langsung dari file konfigurasi HAProxy, karena memperbarui daftar akan memerlukan reboot HAProxy. Proses reboot HAProxy melibatkan pembuatan proses yang sama sekali baru, sambil menjaga yang lama sampai selesai memproses permintaan saat ini. Reboot yang terlalu sering dapat menyebabkan terlalu banyak proses HAProxy berjalan dan kinerjanya buruk. Keterbatasan ini bertentangan dengan tujuan untuk meningkatkan skala aplikasi web secara otomatis, yaitu untuk membawa instance baru ke dalam produksi secepat mungkin. Karena itu, kami menggunakan HAProxy Runtime APIuntuk mengelola keadaan server HAProxy tanpa me-reboot setiap kali server tingkat web masuk atau keluar. Perlu dicatat bahwa HAProxy dapat berintegrasi dengan antarmuka DNS Konsul, tetapi ini menambah jeda karena DNS TTL, membatasi kemampuan untuk menggunakan tag Konsul, dan mengelola respons DNS yang sangat besar sering menyebabkan situasi dan kesalahan tepi yang menyakitkan.

Ara. 2. Bagaimana satu set aplikasi web backend dikelola pada satu server Slack HAProxy
Dalam status HAProxy kami, kami menetapkan template untuk server HAProxy. Bahkan, ini adalah "slot" yang dapat diduduki oleh aplikasi web backend. Ketika sebuah contoh aplikasi web baru diluncurkan atau yang lama mulai gagal, katalog layanan Konsul diperbarui. Template-konsul mencetak versi baru dari daftar host, dan program manajemen haproxy-server-state-terpisah yang dikembangkan di Slack membaca daftar host ini dan menggunakan HAProxy Runtime API untuk memperbarui status HAProxy.
Kami menjalankan M bersamaan Kolam Instansi HAProxy dan Kolam Aplikasi Web, masing-masing di Zona Ketersediaan AWS yang terpisah. HAProxy dikonfigurasikan dengan N "slot" untuk backend aplikasi web di setiap AZ, memberikan total backend N * M yang dapat diarahkan ke semua AZ. Beberapa bulan yang lalu, jumlah itu lebih dari cukup - kami belum pernah meluncurkan apa pun yang dekat dengan banyak contoh tingkat aplikasi web kami. Namun, setelah insiden basis data pagi, kami meluncurkan sedikit lebih banyak dari contoh aplikasi web N * M. Jika Anda menganggap slot HAProxy sebagai permainan kursi raksasa, maka beberapa contoh webapp ini dibiarkan tanpa ruang. Ini bukan masalah - kami memiliki kapasitas layanan lebih dari cukup.
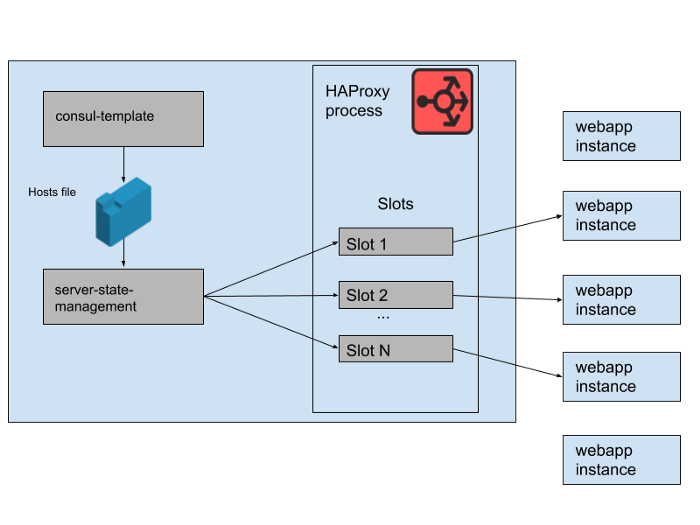
Ara. 3. "Slots" dalam proses HAProxy dengan beberapa contoh aplikasi web yang berlebihan tidak menerima lalu lintas
Namun, ada masalah di siang hari. Ada bug dalam program yang menyinkronkan daftar host yang dihasilkan oleh template-konsul dengan keadaan server HAProxy. Program ini selalu berusaha menemukan slot untuk instance webapp baru sebelum membebaskan slot yang ditempati oleh instance webapp lama yang tidak lagi berfungsi. Program ini mulai melempar kesalahan dan keluar lebih awal karena tidak dapat menemukan slot kosong, yang berarti bahwa instance HAProxy yang sedang berjalan tidak memperbarui keadaan mereka. Seiring berjalannya waktu, grup autoscaling webapp tumbuh dan menyusut, dan daftar backend di negara HAProxy menjadi semakin usang.
Pada pukul 4:45 sore, sebagian besar instance HAProxy hanya dapat mengirim permintaan ke set backend yang tersedia di pagi hari, dan set backend webapp lama ini sekarang menjadi minoritas. Kami secara teratur menyediakan instance HAProxy baru, jadi ada beberapa yang baru dengan konfigurasi yang benar, tetapi kebanyakan dari mereka berusia lebih dari delapan jam dan oleh karena itu terjebak dengan keadaan backend yang penuh dan ketinggalan zaman. Akhirnya, layanan macet. Itu terjadi pada akhir hari kerja di Amerika Serikat, karena saat itulah kami mulai meningkatkan lapisan aplikasi web saat lalu lintas berkurang. Autoscale akan mematikan contoh webapp lama di tempat, yang berarti bahwa tidak ada cukup banyak dari mereka yang tersisa dalam keadaan server HAProxy untuk melayani permintaan.
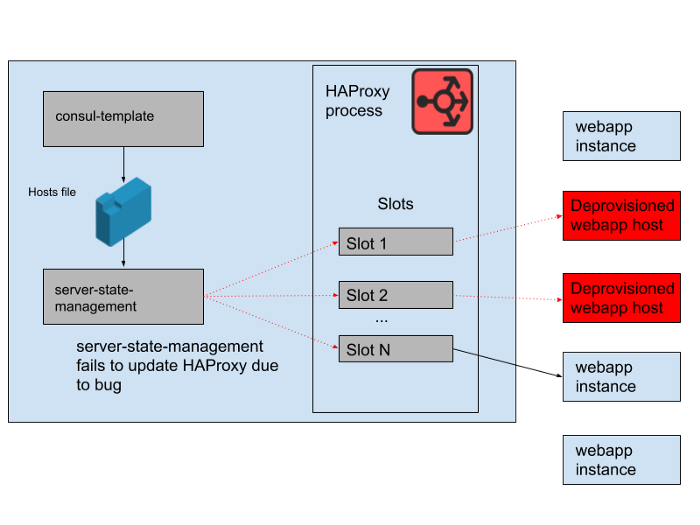
Ara. 4. Keadaan HAProxy berubah dari waktu ke waktu dan slot mulai merujuk terutama ke host jarak jauh
. Setelah itu, kami langsung mengajukan pertanyaan: mengapa pemantauan tidak menangkap masalah ini. Kami memiliki sistem peringatan untuk situasi khusus ini, tetapi sayangnya itu tidak berfungsi sebagaimana mestinya. Kegagalan pemantauan tidak diperhatikan, sebagian karena sistem "hanya bekerja" untuk waktu yang lama dan tidak memerlukan perubahan apa pun. Penyebaran HAProxy yang lebih luas di mana aplikasi ini menjadi bagiannya juga relatif statis. Pada tingkat perubahan yang lambat, lebih sedikit insinyur berinteraksi dengan infrastruktur pemantauan dan peringatan.
Kami tidak mengerjakan banyak tumpukan HAProxy ini, karena kami secara bertahap memindahkan semua penyeimbangan muatan ke Utusan (kami baru-baru ini memindahkan lalu lintas websocket ke sana). HAProxy telah melayani dengan baik dan andal selama bertahun-tahun, tetapi memiliki beberapa masalah operasional seperti dalam insiden ini. Kami akan mengganti pipa kompleks untuk mengelola keadaan server HAProxy dengan integrasi Utusan kami sendiri dengan bidang kontrol xDS untuk penemuan titik akhir. Versi terbaru HAProxy (sejak versi 2.0) juga menyelesaikan banyak masalah operasional ini. Namun demikian, kami telah mempercayai Utusan dengan jala layanan internal untuk beberapa waktu sekarang, jadi kami berusaha untuk mentransfer penyeimbangan beban juga. Pengujian awal kami terhadap Utusan + xDS pada skala tampak menjanjikan, dan migrasi ini akan meningkatkan kinerja dan ketersediaan di masa mendatang.Arsitektur load balancing dan penemuan layanan baru kebal terhadap masalah yang menyebabkan kegagalan ini.
Kami berupaya agar Slack dapat diakses dan andal, tetapi dalam kasus ini kami gagal. Slack adalah alat penting bagi pengguna kami, itulah sebabnya kami berusaha untuk belajar dari setiap kejadian, terlepas dari apakah pelanggan memperhatikannya atau tidak. Kami mohon maaf atas ketidaknyamanan yang disebabkan oleh kegagalan ini. Kami berjanji untuk menggunakan pengetahuan ini untuk meningkatkan sistem dan proses kami.