Saya dulunya adalah pemimpin tim, dan saya bertanggung jawab atas beberapa layanan pengkritik. Dan jika ada yang salah pada mereka, itu menghentikan proses bisnis nyata. Misalnya, pesanan berhenti masuk ke perakitan di gudang.
Saya baru-baru ini menjadi Pemimpin Arah dan sekarang bertanggung jawab atas tiga tim, bukan satu. Masing-masing menjalankan sistem IT. Saya ingin memahami apa yang terjadi di setiap sistem dan apa yang dapat merusak.
Pada artikel ini saya akan berbicara tentang
- apa yang kami monitor
- bagaimana kita memantau
- dan yang paling penting, apa yang kita lakukan dengan hasil pengamatan ini.

Lamoda memiliki banyak sistem. Semua dari mereka dilepaskan, sesuatu berubah di dalamnya, sesuatu terjadi pada tekniknya. Dan saya ingin memiliki setidaknya ilusi bahwa kita dapat dengan mudah melokalisasi kerusakan. Saya terus-menerus dibombardir dengan peringatan yang saya coba cari tahu. Untuk menjauh dari abstraksi dan pergi ke spesifik, saya akan memberi tahu Anda contoh pertama.
Dari Waktu ke Waktu Sesuatu Meledak: Kronik Api
Suatu pagi musim panas yang hangat, tanpa deklarasi perang, seperti biasanya, pemantauan kami berhasil. Sebagai peringatan, kami menggunakan Icinga. Alert mengatakan bahwa kita memiliki 50 GB hard drive yang tersisa di server DBMS. Kemungkinan besar, 50 gigabytes adalah setetes air di lautan, dan itu akan berakhir dengan sangat cepat. Kami memutuskan untuk melihat seberapa banyak ruang kosong yang tersisa. Anda perlu memahami bahwa ini bukan mesin virtual, tetapi server besi, dan database sedang dalam beban berat. Ada SSD 1,5 terabyte. Memori ini akan segera berakhir: memori akan bertahan selama 20-30 hari. Ini sangat sedikit, Anda harus segera menyelesaikan masalah.
Kemudian kami memeriksa berapa banyak memori yang sebenarnya dikonsumsi dalam 1-2 hari. Ternyata 50 gigabyte akan bertahan sekitar 5-7 hari. Setelah itu, layanan yang berfungsi dengan basis data ini diperkirakan akan berakhir. Kita mulai memikirkan konsekuensinya: apa yang akan segera kita arsipkan, data apa yang akan kita hapus. Departemen analisis data memiliki semua cadangan, sehingga Anda dapat dengan aman melepaskan segala yang lebih tua dari 2015.
Kami mencoba menghapusnya dan ingat bahwa MySQL tidak akan berfungsi seperti itu dari setengah tendangan. Data yang dihapus memang bagus, tetapi ukuran file yang dialokasikan untuk tabel dan untuk DB tidak berubah. MySQL kemudian menggunakan ruang ini. Artinya, masalahnya tidak terpecahkan, tidak ada lagi ruang.
Mencoba pendekatan yang berbeda: memigrasikan label dari SSD yang sudah kadaluwarsa ke yang lebih lambat. Untuk melakukan ini, kami memilih pelat yang beratnya banyak, tetapi di bawah sedikit beban, dan menggunakan pemantauan Percona. Kami memindahkan tabel dan sudah berpikir tentang memindahkan server sendiri. Setelah langkah kedua, server mengambil bukan 1,5, tetapi 4 terabyte SSD.
Kami memadamkan api ini: kami mengorganisir langkah dan, tentu saja, memperbaiki pemantauan. Sekarang peringatan akan dipicu bukan pada 50 gigabyte, tetapi pada setengah terabyte, dan nilai pemantauan kritis akan dipicu pada 50 gigabyte. Namun pada kenyataannya itu hanya selimut bagian belakang. Ini akan bertahan untuk sementara waktu. Tetapi jika kita membiarkan pengulangan situasi tanpa memecah pangkalan menjadi beberapa bagian dan tidak berpikir tentang sharding, semuanya akan berakhir buruk.
Mari kita asumsikan lebih jauh kita mengubah server. Pada tahap tertentu, perlu untuk me-restart master. Mungkin, dalam hal ini akan ada kesalahan. Dalam kasus kami, waktu henti sekitar 30 detik. Tetapi permintaan datang, tidak ada tempat untuk menulis, kesalahan telah dituangkan, pemantauan telah berhasil. Kami menggunakan sistem pemantauan Prometheus - dan kami melihat di dalamnya bahwa metrik 500 kesalahan atau jumlah kesalahan saat membuat pesanan telah melonjak. Tapi kita tidak tahu detailnya: pesanan macam apa yang tidak diciptakan, dan sebagainya.
Selanjutnya saya akan memberi tahu Anda bagaimana kami bekerja dengan pemantauan agar tidak jatuh ke dalam situasi seperti itu.
Memantau ulasan dan deskripsi yang jelas untuk dukungan pelanggan
Kami memiliki beberapa arah dan indikator yang kami pantau. Ada televisi di mana-mana di kantor, di mana ada banyak label teknis dan bisnis yang berbeda, yang, selain pengembang, dipantau oleh layanan dukungan.
Dalam artikel ini, saya berbicara tentang bagaimana kita memilikinya dan menambahkan apa yang ingin kita capai. Ini juga berlaku untuk tinjauan pemantauan. Jika kami secara teratur mengambil inventaris "properti" kami, maka kami dapat memperbarui semua yang sudah usang dan memperbaikinya, mencegah pengulangan fakap. Untuk melakukan ini, Anda perlu daftar yang jelas.
Kami memiliki konfigurasi dengan peringatan di repositori, di mana sekarang ada 4678 baris. Dari daftar ini, sulit untuk memahami apa yang dibicarakan setiap pemantauan spesifik. Katakanlah metrik kita disebut db_disc_space_left. Layanan dukungan tidak akan segera mengerti tentang apa ini. Sesuatu tentang ruang kosong, bagus.
Kami ingin menggali lebih dalam. Kami melihat konfigurasi pemantauan ini dan memahami dari mana asalnya.
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
Metrik ini memiliki nama, batasannya sendiri, kapan menyertakan pemantauan peringatan, peringatan untuk melaporkan situasi kritis. Kami menggunakan konvensi penamaan metrik. Di awal setiap metrik ada nama sistem. Berkat ini, area tanggung jawab menjadi jelas. Jika orang yang bertanggung jawab atas sistem memulai metrik, segera jelas siapa yang harus dituju.
Peringatan mengalir di telegram atau kendur. Layanan dukungan bereaksi terhadap mereka terlebih dahulu 24/7. Orang-orang melihat apa yang sebenarnya meledak, jika ini adalah situasi normal. Mereka memiliki instruksi:
- yang diberikan untuk menggantikan,
- dan instruksi yang ditetapkan dalam pertemuan secara berkelanjutan. Dengan nama pemantauan yang meledak, seseorang dapat menemukan artinya. Untuk yang paling kritis, dijelaskan apa yang pecah, apa akibatnya, yang perlu diangkat.
Kami juga memiliki shift bergilir dalam tim yang bertanggung jawab atas sistem utama. Setiap tim memiliki seseorang yang selalu tersedia. Jika sesuatu terjadi, mereka mengambilnya.
Ketika peringatan dipicu, tim dukungan perlu dengan cepat menemukan semua informasi utama. Akan lebih baik memiliki tautan ke deskripsi pemantauan yang dilampirkan ke pesan kesalahan. Misalnya, agar ada informasi seperti itu:
- deskripsi pemantauan ini dalam pengertian, istilah yang relatif sederhana;
- alamat di mana ia berada;
- penjelasan tentang apa itu metrik;
- konsekuensi: bagaimana itu akan berakhir jika kita tidak memperbaiki kesalahan;
- , , . , , . -, .
Akan lebih mudah untuk segera melihat dinamika lalu lintas di antarmuka Prometheus.
Saya ingin membuat deskripsi seperti itu untuk setiap pemantauan. Mereka akan membantu Anda membangun ulasan Anda dan membuat penyesuaian. Kami menerapkan praktik ini: konfigurasi icing sudah berisi tautan untuk pertemuan dengan informasi ini. Saya sudah bekerja pada satu sistem selama hampir 4 tahun, pada dasarnya tidak ada deskripsi seperti itu. Jadi sekarang saya mengumpulkan pengetahuan bersama. Deskripsi juga mengatasi kurangnya kesadaran tim.
Kami memiliki instruksi untuk sebagian besar peringatan, di mana ada tertulis apa yang mengarah pada dampak bisnis tertentu. Inilah sebabnya kita harus segera memilah-milah situasinya. Tingkat keparahan kemungkinan insiden ditentukan oleh layanan dukungan bersama dengan bisnis.
Saya akan memberikan contoh: jika pemantauan konsumsi memori pada server RabbitMQ dari layanan pemrosesan pesanan dipicu, ini berarti bahwa layanan antrian mungkin macet dalam beberapa jam atau bahkan beberapa menit. Dan ini, pada gilirannya, akan menghentikan banyak proses bisnis. Akibatnya, pelanggan tidak akan berhasil menunggu pesanan, pemberitahuan SMS / push, perubahan status dan banyak lagi.
Diskusi pemantauan dengan bisnis sering terjadi setelah insiden serius. Jika terjadi kerusakan, kami mengumpulkan komisi dengan perwakilan dari arah yang terkait dengan pembebasan atau kejadian kami. Pada pertemuan itu, kami menganalisis alasan kejadian itu, bagaimana memastikan bahwa kejadiannya tidak pernah kambuh, kerusakan apa yang kami derita, berapa banyak uang yang kami hilangkan, dan untuk apa.
Itu terjadi bahwa Anda perlu menghubungkan bisnis untuk memecahkan masalah yang dibuat untuk pelanggan. Kami membahas tindakan proaktif di sana: pemantauan seperti apa yang harus dilakukan sehingga ini tidak terjadi lagi.
Layanan dukungan memantau nilai metrik menggunakan bot telegram. Ketika pemantauan baru muncul, staf pendukung membutuhkan alat sederhana yang akan memberi tahu Anda di mana kerusakan itu dan apa yang harus dilakukan tentang hal itu. Tautan ke deskripsi di lansiran menyelesaikan masalah ini.
Saya melihat fakap sebagai kenyataan: menggunakan Sentry untuk tanya jawab
Tidak cukup hanya dengan mencari tahu tentang kesalahan, Anda ingin melihat detailnya. Kasing penggunaan standar kami adalah sebagai berikut: meluncurkan rilis dan menerima peringatan dari tumpukan K8S. Berkat pemantauan, kami melihat status pod: versi aplikasi mana yang diluncurkan, bagaimana penyebarannya berakhir, semuanya bagus.
Kemudian kita melihat RMM, yang kita miliki dengan pangkalan dan dengan beban di atasnya. Untuk Grafana dan papan, kami melihat jumlah koneksi ke Kelinci. Dia keren, tapi dia tahu bagaimana mengalir ketika memori habis. Kami memantau hal-hal ini, dan kemudian kami memeriksa Sentry. Hal ini memungkinkan Anda untuk menonton secara online bagaimana kegagalan berikutnya terungkap dengan semua detail. Dalam hal ini, pemantauan pasca-rilis melaporkan apa yang rusak dan bagaimana.
Dalam proyek PHP, kami menggunakan klien gagak dan juga memperkaya dengan data. Sentry semuanya teragregasi dengan indah. Dan kita melihat dinamika untuk setiap fakap, seberapa sering itu terjadi. Dan kami juga melihat contoh, permintaan mana yang tidak berhasil, ekstensi mana yang keluar.
Itu terlihat seperti ini. Saya melihat bahwa pada rilis berikutnya ada lebih banyak kesalahan dari biasanya. Kami akan memeriksa apa yang secara khusus rusak. Dan kemudian, jika perlu, kami akan mendapatkan pesanan yang gagal sesuai dengan konteksnya dan memperbaikinya.
Kami punya hal keren - mengikat Jira. Ini adalah pelacak tiket: mengklik tombol, dan kesalahan tugas dibuat di Jira dengan tautan ke Sentry dan jejak tumpukan kesalahan ini. Tugas ditandai dengan label tertentu.
Salah satu pengembang membawa inisiatif yang masuk akal - "Proyek bersih, Sentry bersih". Selama perencanaan, setiap kali kita melakukan sprint setidaknya 1-2 tugas yang dibuat dari Sentry. Jika ada sesuatu yang rusak dalam sistem sepanjang waktu, maka Sentry dipenuhi dengan jutaan kesalahan kecil yang bodoh. Kami secara teratur membersihkannya agar kami tidak kehilangan yang benar-benar serius.
Nyala api untuk alasan apa pun: kita menyingkirkan pemantauan, yang dipalu semua orang
- Terbiasa dengan kesalahan
Jika sesuatu terus-menerus berkedip dan terlihat rusak, itu memberi perasaan norma yang salah. Meja layanan dapat diperdayai dengan berpikir bahwa situasinya memadai. Dan ketika sesuatu yang serius rusak, itu akan diabaikan. Seperti dalam sebuah dongeng tentang seorang anak laki-laki yang berteriak: "Serigala, serigala!".
Kasing klasik adalah proyek kami, yang bertanggung jawab atas pemrosesan pesanan. Ia bekerja dengan sistem otomatisasi gudang dan mentransfer data di sana. Sistem ini biasanya dirilis pada jam 7 pagi, setelah itu kami mulai memantau. Semua orang terbiasa dengan itu dan skor, yang tidak terlalu baik. Akan lebih bijaksana untuk menyetel kontrol ini. Misalnya, untuk menautkan rilis sistem tertentu dan beberapa peringatan melalui Prometheus, tidak perlu memotong alarm tambahan.
- Pemantauan tidak memperhitungkan indikator bisnis
Sistem pemrosesan pesanan mentransfer data ke gudang. Kami telah menambahkan monitor ke sistem ini. Tak satu pun dari mereka yang menembak, dan tampaknya semuanya baik-baik saja. Penghitung menunjukkan bahwa data pergi. Kasing ini menggunakan sabun. Pada kenyataannya, penghitung mungkin terlihat seperti ini: bagian hijau adalah pertukaran masuk, bagian kuning keluar.
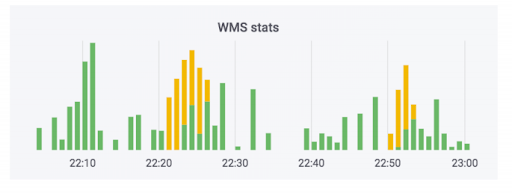
Kami punya kasus ketika data benar-benar senang, tetapi kurva. Pesanan tidak dibayarkan, tetapi ditandai sebagai telah dibayar. Artinya, pembeli akan dapat mengambilnya secara gratis. Tampaknya menakutkan. Tetapi yang sebaliknya lebih menyenangkan: seseorang datang untuk mengambil pesanan yang dibayar, dan ia diminta untuk membayar lagi karena kesalahan dalam sistem.
Untuk menghindari situasi ini, kami mengamati tidak hanya teknologi, tetapi juga metrik bisnis. Kami memiliki pemantauan khusus, yang memantau jumlah pesanan yang membutuhkan pembayaran setelah diterima. Setiap lompatan besar dalam metrik ini akan menunjukkan jika ada kesalahan.
Pemantauan kinerja bisnis adalah hal yang jelas, tetapi seringkali diabaikan ketika layanan baru dirilis, termasuk kami. Semua orang mencakup layanan baru dengan metrik teknis murni yang terkait dengan disk, proses, apa pun. Sebagai toko online, kami memiliki hal yang kritis - jumlah pesanan yang dibuat. Kita tahu berapa banyak orang biasanya membeli, disesuaikan dengan promosi pemasaran. Karena itu, kami memantau indikator ini selama rilis.
Hal penting lainnya: ketika seorang klien berulang kali memesan pengiriman ke alamat yang sama, kami tidak menyiksanya dengan berkomunikasi dengan pusat panggilan, tetapi secara otomatis mengkonfirmasi pesanan. Sistem crash memiliki dampak besar pada pengalaman pelanggan. Kami juga memantau metrik ini, karena rilis sistem yang berbeda dapat sangat mempengaruhinya.
Kami menyaksikan dunia nyata: kami peduli dengan sprint yang sehat dan kinerja kami
Agar bisnis dapat melacak berbagai indikator, kami memfilmkan sistem Dasbor Waktu Nyata yang kecil. Awalnya dibuat untuk tujuan yang berbeda. Bisnis memiliki rencana untuk berapa banyak pesanan yang ingin kami jual pada hari tertentu di bulan mendatang. Sistem ini menunjukkan kesesuaian rencana dan dibuat pada kenyataannya. Untuk jadwal, dia mengambil data dari basis produksi, membaca dari sana dengan cepat.
Setelah replika kami berantakan. Tidak ada pemantauan, jadi kami tidak punya waktu untuk mengetahuinya. Tetapi bisnis melihat bahwa kami tidak memenuhi rencana untuk 10 unit pesanan konvensional, dan mulai berlari dengan komentar. Kami mulai mencari tahu alasannya. Ternyata data yang tidak relevan dibaca dari replika yang rusak. Ini adalah kasus di mana bisnis mengamati indikator yang menarik, dan kami saling membantu ketika masalah muncul.
Saya akan memberi tahu Anda tentang pemantauan lain dari dunia nyata, yang telah lama dikembangkan dan terus disetel oleh setiap tim. Kami memiliki Jira Viewer - memungkinkan Anda untuk menonton proses pengembangan. Sistem ini sangat sederhana: kerangka PHP Symfony, yang pergi ke Jira Api dan mengambil data dari sana tentang tugas, sprint, dan sebagainya, tergantung pada apa yang diberikan sebagai input. Jira Viewer secara teratur menulis metrik terkait dengan tim dan proyek mereka ke Prometeus. Di sana mereka dipantau, waspada, dan dari sana ditampilkan di Grafana. Berkat sistem ini, kami mengikuti Work yang sedang berlangsung.
- Kami memantau berapa lama tugas telah dilakukan sejak saat ini hingga menjadi produksi. Jika angkanya terlalu besar, secara teoritis ini menunjukkan masalah dengan proses, tim, deskripsi tugas, dan sebagainya. Umur tugas adalah metrik penting, tetapi tidak cukup dengan sendirinya.
- . , , . , .
- – ready for release, . - - , « ».
- : , . .
- . 400 150. , , .
- Saya memantau di tim saya jumlah permintaan tarik dari pengembang di luar jam kerja. Khususnya, setelah jam 8 malam. Dan ketika metrik menembak, ini adalah tanda yang mengkhawatirkan: seseorang entah tidak punya waktu untuk sesuatu, atau terlalu banyak berusaha dan cepat atau lambat hanya terbakar.
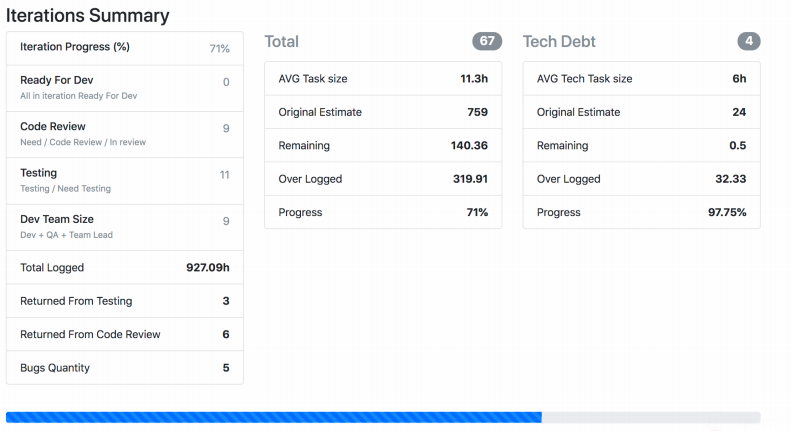
Tangkapan layar menunjukkan bagaimana Jira Viewer mengeluarkan data. Ini adalah halaman di mana ada ringkasan status tugas dari sprint, berapa berat masing-masing, dan sejenisnya. Hal-hal semacam itu juga berkumpul dan terbang ke Prometheus.
Bukan hanya metrik teknis: apa yang sudah kita pantau, apa yang bisa kita pantau dan mengapa semua ini diperlukan
Untuk menyatukan semua ini, saya mengusulkan untuk memantau bersama teknologi dan metrik yang terkait dengan proses, pengembangan, dan bisnis. Metrik teknis saja tidak cukup.
- , -, Grafana-. . , , .
- : , . , , crontab supervisor. . , , .
- – , , .
- : , - , . , .
- , . – Sentry . - , . - , . Sentry , , .
- . , , .
- , . , - , - . .