
Nama saya Sasha, di SberDevices saya mengerjakan pengenalan ucapan dan bagaimana data dapat membuatnya lebih baik. Pada artikel ini, saya akan berbicara tentang kumpulan data ucapan Golos baru, yang terdiri dari file audio dan transkripsi yang sesuai. Total durasi rekaman kira-kira 1240 jam, frekuensi pengambilan sampelnya adalah 16 kHz. Saat ini, ini adalah kumpulan rekaman audio terbesar dalam bahasa Rusia, yang ditandai dengan tangan. Kami merilis korpus di bawah lisensi yang dekat dengan CC Attribution ShareAlike , yang memungkinkannya digunakan untuk penelitian ilmiah dan tujuan komersial. Saya akan berbicara tentang apa saja kumpulan data tersebut, bagaimana kumpulan data itu disusun, dan hasil apa yang dapat dicapai.
Struktur dataset Golos
Saat membuat dataset, kami dipandu oleh keinginan untuk menyelesaikan masalah cold start, ketika data dari pengguna sebenarnya belum tersedia. Inilah yang pada akhirnya memungkinkan untuk membuatnya tersedia untuk umum, karena ucapan pengguna sebenarnya tidak ada.
Rekaman audio dalam kumpulan data dikumpulkan dari dua sumber. Sumber pertama adalah platform crowdsourcing, itulah sebabnya kami menyebutnya Crowd Domain. Sumber kedua adalah rekaman yang dibuat di studio menggunakan perangkat target SberPortal. Ini memiliki sistem mikrofon khusus, dan ini adalah salah satu perangkat tempat pengenalan ucapan kami harus berfungsi.
Kami menyebutnya sumber Farfield-domain, karena jarak dari pengguna ke perangkat biasanya cukup jauh. Untuk merekam melalui SberPortal di studio, kami menggunakan tiga jarak: 1, 3, dan 5 meter dari pengguna ke perangkat. Setiap domain memiliki bagian pelatihan dan pengujian, struktur yang dihasilkan ditunjukkan pada tabel:
| Domain | Bagian pelatihan | Bagian uji |
|---|---|---|
| Orang banyak | 979 796 file | 1095 jam | 9994 file | 11,2 jam |
| Farfield | 124 003 berkas | 132,4 jam | 1916 berkas | 1,4 jam |
| Total | 1 103 799 file | 1227,4 jam | 11910 berkas | 12,6 jam |
Tidak ada informasi pribadi dalam kumpulan data, seperti usia, jenis kelamin, atau ID pengguna - semuanya impersonal. Bagian pelatihan dan pengujian mungkin berisi ucapan dari pengguna yang sama.
| Statistik \ Domain | Orang banyak | Farfield |
|---|---|---|
| jumlah | 979796 file | 124003 file |
| Rata-rata | 4,0 dtk. | 3,8 dtk. |
| Simpangan baku | 1,9 dtk. | 1,6 dtk. |
| Persentil ke-1 | 1,4 dtk. | 2.0 dtk. |
| Persentil ke-50 | 3,7 dtk. | 3,5 dtk. |
| Persentil ke-95 | 7,3 detik | 6,8 dtk |
| Persentil ke-99 | 10,5 dtk. | 9,6 dtk. |
Tabel di atas memberikan beberapa informasi statistik tentang entri: mean, deviasi standar, dan persentil. Untuk kejelasan, gambar tersebut menunjukkan dua histogram dari distribusi panjang record:
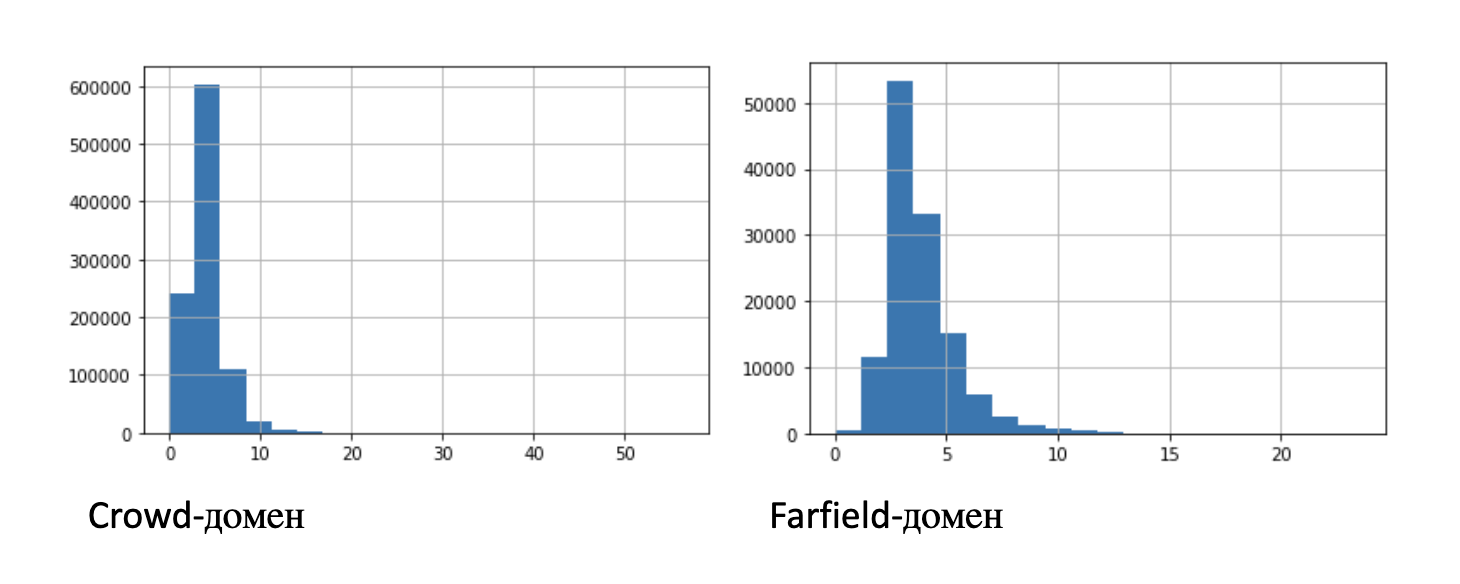
Untuk eksperimen dengan jumlah record yang terbatas, kami mengidentifikasi subset dengan panjang yang lebih pendek: 100 jam, 10 jam, 1 jam, 10 menit.
Pengumpulan data
Di SberDevices, kami mengembangkan keluarga asisten virtual Salute, jadi kami menghasilkan ucapan yang mirip dengan permintaan pengguna untuk asisten. Kami telah membuat sistem templat untuk mendeskripsikan permintaan dalam berbagai domain - musik, film, pemesanan produk, dan lain-lain. Mereka adalah ekspresi yang mendeskripsikan struktur permintaan dan menguraikannya menjadi komponen. Dengan menggunakan template, kita dapat menghasilkan kueri yang masuk akal, melatih kembali model akustik, membuat model bahasa berdasarkan kueri ini, dan banyak lagi.
Contoh template:
| Template | Contoh |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | Mainkan buku film hijau |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | Anda memiliki buku hijau film |
| [command_demands_ip] + [film_title_ip] | Apa kamu punya buku hijau |
| [film_title_ip] + [command_demands_vp] | letakkan buku hijau |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | memfilmkan tempat buku hijau |
| [film_title_ip] | buku hijau |
| [command_demands_vp] + [film_title_ip] | nyalakan buku hijau |
| [film_syn_ip] + [film_title_ip] | filmkan buku hijau |
| [command_demands_vp] + [film_title_ip] | Nyalakan buku hijau |
| ... | ... |
Dalam tanda kurung siku - penunjukan entitas yang sesuai. Lebih jauh dalam tabel untuk dua entitas "film_title_ip" dan "film_title_vp" ada opsi yang memungkinkan untuk mengisinya:
| film_title_ip | film_title_vp |
|---|---|
| obsesi | obsesi |
| pelarian | pelarian |
| Si cantik dan si buruk rupa | Si cantik dan si buruk rupa |
| Pulau | Pulau |
| Jane Eyre | Jane Eyre |
| Wuthering Heights | Wuthering Heights |
| ... | ... |
Proses pembuatan dataset audio yang diberi tag terdiri dari beberapa tahapan:
- Langkah 1. Pertama, kami membuat template untuk domain tertentu.
- 2. - . , :
- 3. «» :
- 4. – , , . – . 80% Golos. , “”, , . , , .
- 4*. - , , , , , , . , . , , , , , . , .

- 5*. , . , . , , , . , , , . , , , . , . :

:
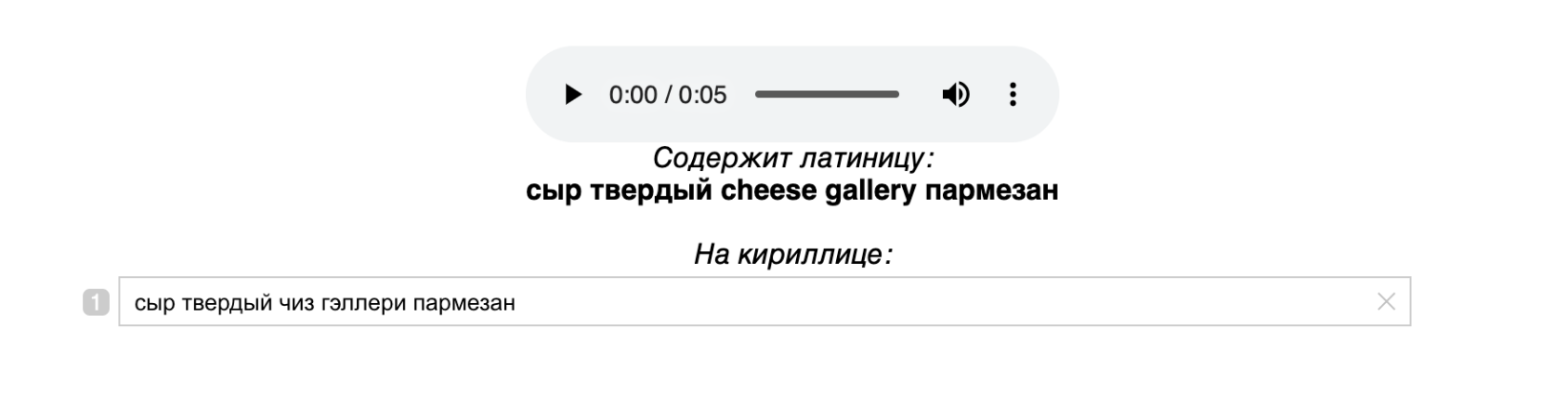
, . .
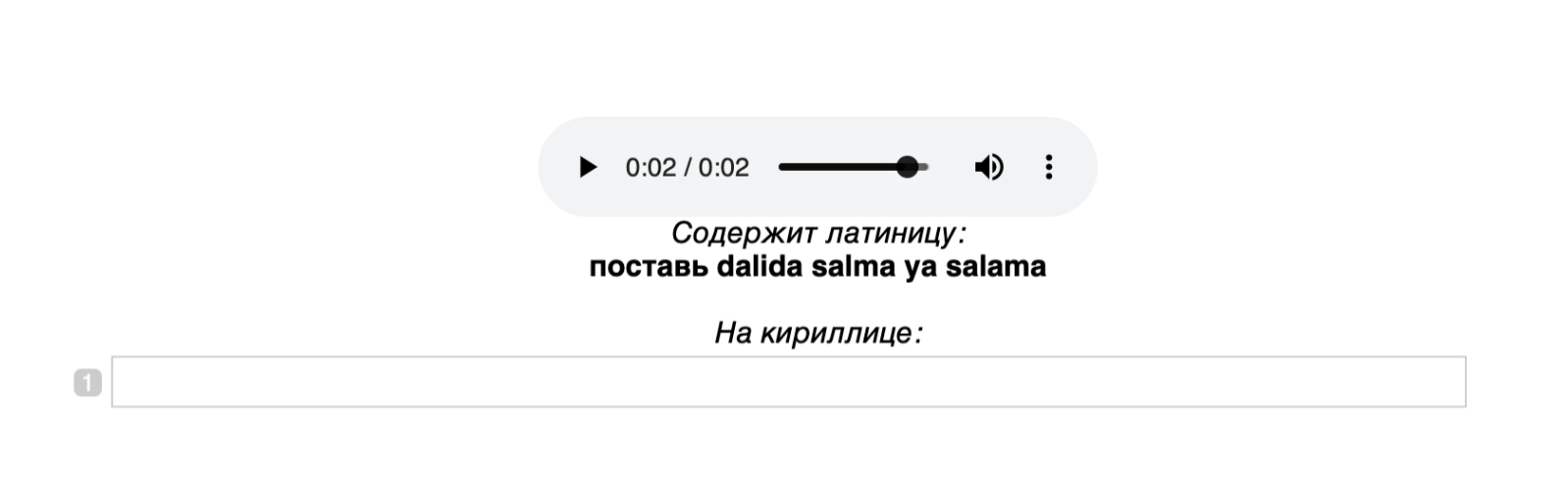
, , , .
- 5 . 3 , .
. -, , . -, . , .
, , “” – , “” - . , , , ( ) . bias , , . , . , .
Proses pembuatan set data yang dijelaskan memungkinkan Anda membuat markup dengan kualitas setinggi mungkin, yang membedakannya dari yang lain yang dibuat secara otomatis atau semi-otomatis. Kami menggunakan data ini untuk membuat sistem pengenalan suara di perangkat kami. Karena kualitas penandaan yang tinggi, keakuratan sistem yang dihasilkan sebanding dengan yang dimiliki manusia. Semua data, bersama dengan model akustik dan bahasa terlatih untuk pengenalan suara, tersedia di halaman GitHub proyek , serta di ML Space dari Sbercloud , layanan untuk melatih model pembelajaran mesin, tempat kumpulan data kami dapat diunduh dengan mulus langsung di antarmuka . Kami akan memberi tahu Anda lebih banyak tentang penggunaan ML Space dan cara kami menggunakannya untuk mengajarkan model pengenalan suara di artikel berikutnya.
Saat ini, ada banyak data terbuka dalam bahasa Inggris, tetapi tidak ada kumpulan data berkualitas tinggi dalam bahasa Rusia. Sekarang korpus juga tersedia dalam bahasa Rusia, yang dapat digunakan untuk pengenalan dan sintesis ucapan, dan model yang dilatih menggunakan korpus tersebut menunjukkan kualitas yang sangat tinggi. Kami percaya bahwa kumpulan data Golos akan memungkinkan komunitas ilmiah Rusia untuk bergerak lebih cepat dalam meningkatkan teknologi ucapan bahasa Rusia.