
!
, Head of AI Celsus. .
, , ML- . «» — , , .
ML- DS-, , CV .
Jadi, misalkan Anda memutuskan untuk mendirikan AI start-up untuk mendeteksi kanker payudara (omong-omong, jenis onkologi paling umum di kalangan wanita) dan akan membuat sistem yang secara akurat akan mendeteksi tanda-tanda patologi pada pemeriksaan mamografi, dokter melawan kesalahan, dan mengurangi waktu untuk membuat diagnosis ... Misi yang cemerlang, bukan?

Anda telah mengumpulkan tim pemrogram berbakat, insinyur dan analis ML, membeli peralatan mahal, menyewa kantor, dan memikirkan strategi pemasaran. Semuanya tampaknya siap untuk mulai mengubah dunia menjadi lebih baik! Sayangnya, semuanya tidak sesederhana itu, karena Anda lupa tentang hal terpenting - tentang data. Tanpanya, Anda tidak dapat melatih jaringan neural atau model pembelajaran mesin lainnya.
Di sinilah salah satu kendala utama terletak - kuantitas dan kualitas set data yang tersedia. Sayangnya, di bidang kedokteran diagnostik, masih sangat sedikit kumpulan data yang berkualitas tinggi, terverifikasi, lengkap, dan bahkan lebih sedikit lagi yang tersedia untuk umum bagi para peneliti dan perusahaan AI.
Pertimbangkan situasi menggunakan contoh yang sama dari deteksi kanker payudara. Lebih atau kurang set data publik berkualitas tinggi dapat dihitung dengan satu jari: DDSM (sekitar 2600 kasus), InBreast (115), MIAS (161). Ada juga OPTIMAM dan BCDR dengan prosedur yang agak rumit dan membingungkan untuk mendapatkan akses.
Dan bahkan jika Anda dapat mengumpulkan data publik dalam jumlah yang memadai, kendala berikutnya menanti Anda: hampir semua kumpulan data ini diizinkan untuk digunakan hanya untuk tujuan non-komersial. Selain itu, markup di dalamnya bisa sangat berbeda - dan itu bukan fakta bahwa itu cocok untuk tugas Anda. Secara umum, tanpa mengumpulkan kumpulan data Anda sendiri dan markupnya, dimungkinkan untuk membuat hanya sebuah MVP, tetapi bukan produk berkualitas tinggi, yang siap untuk beroperasi dalam kondisi pertempuran.
Jadi, Anda mengirimkan permintaan ke institusi medis, mengangkat semua koneksi dan kontak Anda, dan menerima koleksi beragam gambar di tangan Anda. Jangan bersukacita sebelumnya, Anda berada di awal jalan! Memang, meskipun ada standar terpadu untuk menyimpan gambar medis, DICOM(Digital Imaging and Communications in Medicine), dalam kehidupan nyata semuanya tidak begitu cerah. Misalnya, informasi tentang sisi (Kiri / Kanan) dan proyeksi ( CC / MLO ) gambar dada dapat disimpan di sumber data yang berbeda di bidang yang sama sekali berbeda. Satu-satunya solusi di sini adalah mengumpulkan data dari sebanyak mungkin sumber dan mencoba mempertimbangkan semua opsi yang memungkinkan dalam logika layanan.
Apa yang Anda markup adalah apa yang Anda tuai
Kami akhirnya sampai pada bagian yang menyenangkan - proses markup data. Apa yang membuatnya begitu istimewa dan tak terlupakan di bidang medis? Pertama, proses penandaan itu sendiri jauh lebih rumit dan lebih lama daripada di sebagian besar industri. Sinar-X tidak dapat diunggah ke Yandex.Toloka dan Anda bisa mendapatkan set data yang diberi tag dengan harga satu sen. Ini membutuhkan kerja keras dari spesialis medis, dan disarankan untuk memberikan setiap gambar untuk menandai ke beberapa dokter - dan ini mahal dan memakan waktu.
Lebih buruk lagi: para ahli sering tidak setuju dan memberikan tanda yang sama sekali berbeda dari gambar yang sama pada keluaran. Dokter memiliki kualifikasi, pendidikan, tingkat "kecurigaan" yang berbeda. Seseorang menandai semua objek dalam gambar dengan rapi di sepanjang kontur, dan seseorang - dengan bingkai lebar. Akhirnya, salah satu dari mereka penuh dengan energi dan antusiasme, sementara yang lain menandai gambar di layar laptop kecil setelah shift dua puluh jam. Semua perbedaan ini secara alami "membuat gila" jaringan neural, dan Anda tidak akan mendapatkan model berkualitas tinggi dalam kondisi seperti itu.
Situasi ini juga tidak diperbaiki oleh fakta bahwa sebagian besar kesalahan dan ketidaksesuaian terjadi justru pada kasus yang paling kompleks, yang paling berharga untuk melatih neuron. Misalnya penelitianmenunjukkan bahwa sebagian besar kesalahan yang dilakukan dokter saat membuat diagnosis pada mammogram dengan peningkatan kepadatan jaringan payudara, sehingga tidak mengherankan bahwa ini juga yang paling sulit untuk sistem AI.
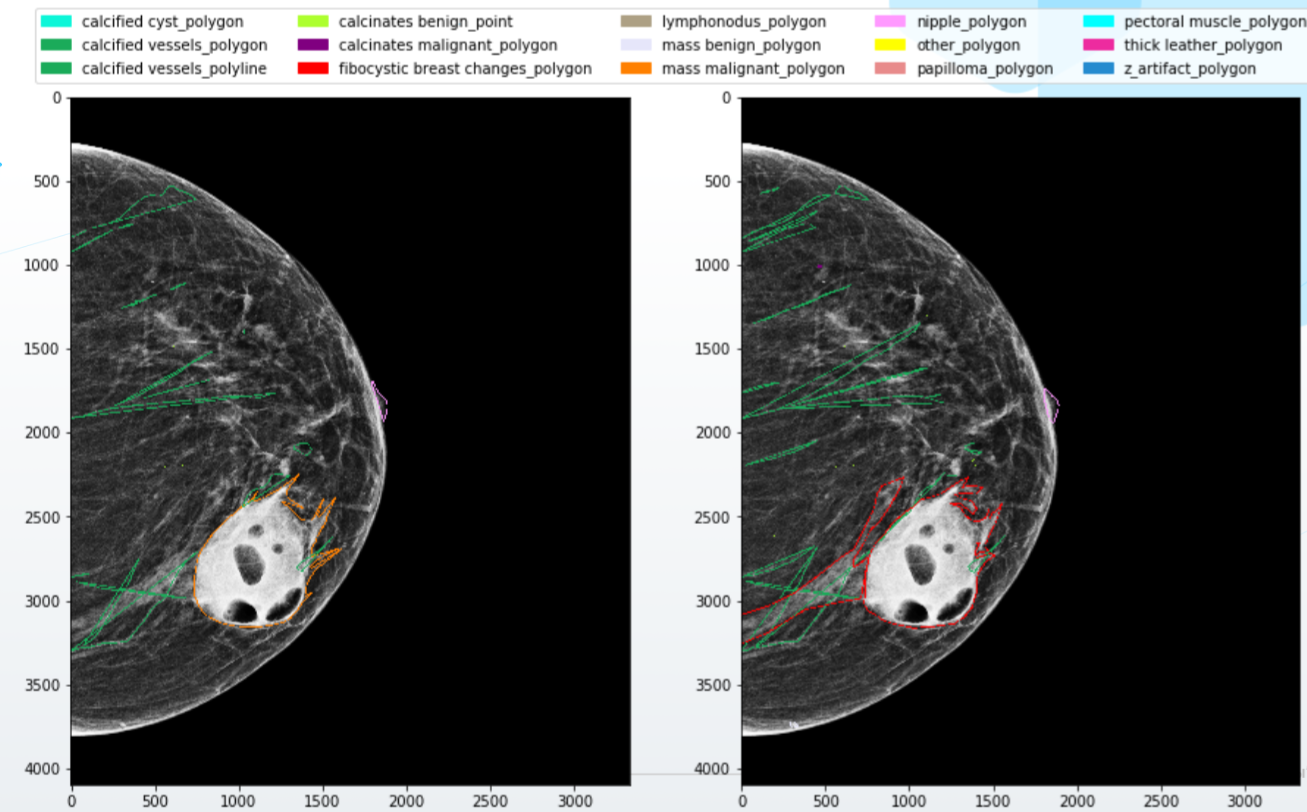
Apa yang harus dilakukan? Tentu saja, pertama-tama, Anda perlu membangun sistem interaksi yang berkualitas tinggi dengan dokter. Tulis aturan rinci untuk markup, dengan contoh dan visualisasi, berikan spesialis dengan perangkat lunak dan peralatan berkualitas tinggi, tulis logika untuk menggabungkan konflik kecil dalam markup dan minta pendapat tambahan jika terjadi konflik yang lebih serius.
Seperti yang dapat Anda bayangkan, semua ini meningkatkan biaya markup. Tetapi jika Anda tidak siap untuk mengambilnya sendiri, lebih baik tidak pergi ke bidang kedokteran.
Tentu saja, jika Anda mendekati proses dengan bijak, maka biaya dapat dan harus dikurangi - misalnya, melalui pembelajaran aktif. Dalam hal ini, sistem ML itu sendiri meminta dokter gambar mana yang perlu diberi tanda tambahan untuk memaksimalkan kualitas pengenalan patologi. Ada berbagai cara untuk menilai keyakinan model dalam prediksinya - Kerugian Pembelajaran, Pembelajaran Aktif Diskriminatif, Putus Sekolah MC, entropi probabilitas yang diprediksi, cabang keyakinan, dan banyak lainnya. Mana yang lebih baik digunakan, hanya eksperimen pada model dan kumpulan data Anda yang akan ditampilkan.
Akhirnya, Anda dapat sepenuhnya mengabaikan markup dokter dan hanya mengandalkan hasil akhir yang dikonfirmasi - misalnya, kematian atau pemulihan pasien. Mungkin ini adalah pendekatan terbaik (walaupun ada banyak nuansa di sini), tetapi hanya dapat mulai bekerja dalam sepuluh hingga lima belas tahun, paling banter, ketika PACS (pengarsipan gambar dan sistem komunikasi) dan sistem informasi medis (MIS ) dan ketika cukup data telah terkumpul. Tetapi bahkan dalam kasus ini, tidak ada yang menjamin kemurnian dan kualitas data ini.
Model yang bagus - preprocessing yang baik

Hore! Model telah dilatih, menunjukkan hasil yang sangat baik, dan siap untuk diujicobakan. Perjanjian kerja sama disepakati dengan beberapa organisasi medis, sistem dipasang dan dikonfigurasi, demonstrasi dilakukan kepada dokter dan kemampuan sistem ditunjukkan.
Dan sekarang hari pertama operasi sistem selesai, Anda membuka dasbor dengan metrik dengan hati yang tenggelam ... Dan Anda melihat gambar berikut: sekumpulan permintaan ke sistem, dengan nol objek yang terdeteksi oleh sistem dan, dari Tentu saja, reaksi negatif dari dokter. Bagaimana? Bagaimanapun, sistem tersebut terbukti sangat baik dalam pengujian internal!
Setelah dianalisis lebih lanjut, ternyata di institusi medis ini ada semacam mesin sinar-X yang tidak Anda kenal dengan pengaturannya sendiri, dan akibatnya, gambar terlihat sangat berbeda. Jaringan saraf tidak dilatih pada gambar seperti itu, jadi tidak mengherankan bahwa itu "gagal" pada gambar tersebut dan tidak mendeteksi apa pun. Dalam dunia pembelajaran mesin, kasus seperti itu biasanya disebut sebagai Data Di Luar Distribusi. Model biasanya berperforma jauh lebih buruk pada data semacam itu, dan ini adalah salah satu masalah utama machine learning.
Contoh ilustratif: tim kami menguji model publikdari para peneliti di Universitas New York, dilatih tentang sejuta gambar. Penulis artikel berpendapat bahwa model tersebut menunjukkan deteksi onkologi berkualitas tinggi pada mammogram, dan secara khusus mereka berbicara tentang tingkat akurasi ROC-AUC di wilayah 0,88-0,89. Pada data kami, model yang sama menunjukkan hasil yang jauh lebih buruk - dari 0,65 hingga 0,70, bergantung pada kumpulan data.
Solusi paling sederhana untuk masalah di permukaan ini adalah mengumpulkan semua kemungkinan jenis gambar, dari semua perangkat, dengan semua pengaturan, menandainya, dan melatih sistem di atasnya. Minus? Sekali lagi, panjang dan mahal. Dalam beberapa kasus, Anda dapat melakukannya tanpa markup - pembelajaran tanpa pengawasan akan membantu Anda. Gambar tanpa label diberikan ke neuron dengan cara tertentu, dan model "terbiasa" dengan fiturnya, yang memungkinkannya berhasil mendeteksi objek dalam gambar serupa di masa mendatang. Ini dapat dilakukan, misalnya, menggunakan pseudo-markup dari gambar yang tidak diberi tag atau berbagai tugas tambahan.
Namun, ini juga bukan obat mujarab. Selain itu, metode ini mengharuskan Anda mengumpulkan semua jenis gambar yang ada di dunia, yang pada prinsipnya tampaknya merupakan tugas yang mustahil. Dan solusi terbaik di sini adalah menggunakan pemrosesan awal universal.
Preprocessing adalah algoritma untuk memproses data masukan sebelum dimasukkan ke dalam jaringan saraf. Prosedur ini dapat mencakup perubahan otomatis pada kontras dan kecerahan, berbagai normalisasi statistik, dan penghapusan bagian gambar yang tidak perlu (artefak).
Misalnya, setelah banyak percobaan, tim kami berhasil membuat pemrosesan awal universal untuk gambar sinar-X kelenjar susu, yang membawa hampir semua gambar masukan ke dalam bentuk seragam, yang memungkinkan jaringan saraf memprosesnya dengan benar.

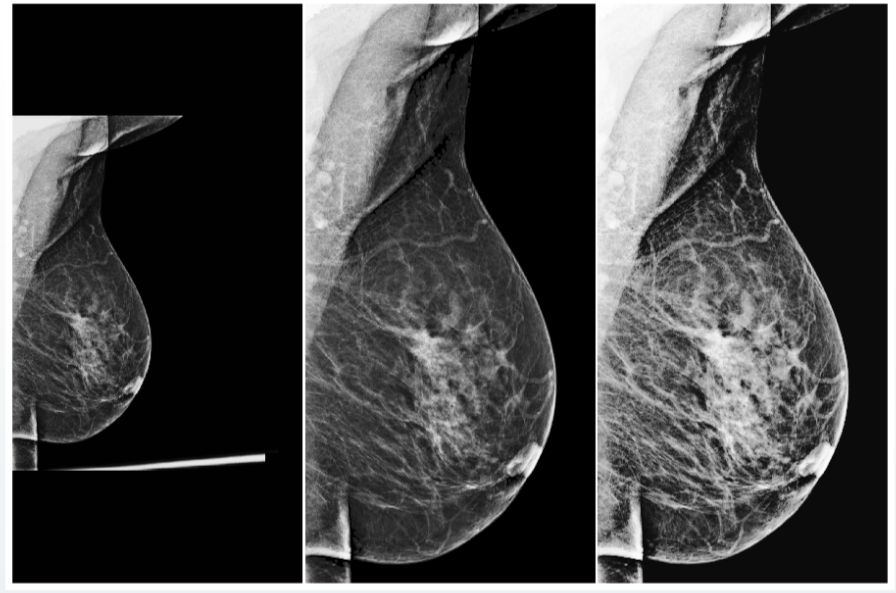
Tetapi bahkan dengan pra-pemrosesan universal, Anda tidak boleh melupakan pemeriksaan kualitas data masukan. Misalnya, dalam kumpulan data fluorografi, kami sering menemukan gambar uji, termasuk tas, botol, dan benda lainnya. Jika sistem menetapkan kemungkinan adanya patologi pada gambar seperti itu, ini jelas tidak meningkatkan kepercayaan komunitas medis pada model Anda. Untuk menghindari masalah seperti itu, sistem AI juga harus menunjukkan kepercayaan mereka pada prediksi yang benar dan validitas data masukan.

Perangkat keras yang berbeda bukan satu-satunya masalah dengan kemampuan sistem AI untuk menggeneralisasi, menggeneralisasi, dan bekerja dengan data baru. Parameter yang sangat penting adalah karakteristik demografis dari kumpulan data. Misalnya, jika sampel pelatihan Anda didominasi oleh orang Rusia berusia di atas 60 tahun, tidak ada yang dapat menjamin bahwa model tersebut akan berfungsi dengan benar pada anak muda Asia. Sangat penting untuk memantau kesamaan indikator statistik dari sampel pelatihan dan populasi sebenarnya yang akan digunakan sistem tersebut.
Jika ada ketidaksesuaian yang ditemukan, sangat penting untuk melakukan pengujian, dan kemungkinan besar, pelatihan tambahan atau penyesuaian model. Sangat penting untuk melakukan pemantauan terus-menerus dan revisi sistem secara teratur. Di dunia nyata, sejuta hal bisa terjadi: mesin sinar-X telah diganti, asisten laboratorium baru telah datang yang melakukan penelitian dengan cara berbeda, kerumunan migran dari negara lain tiba-tiba membanjiri kota. Semua ini dapat menyebabkan penurunan kualitas sistem AI Anda.
Namun, seperti yang sudah Anda duga, belajar bukanlah segalanya. Sistem perlu dinilai minimal, dan metrik standar mungkin tidak dapat diterapkan di bidang medis. Ini juga menyulitkan untuk mengevaluasi layanan AI yang bersaing. Tetapi ini adalah topik untuk bagian kedua dari materi - seperti biasa, berdasarkan pengalaman pribadi kita.