Selamat siang, para pembaca yang budiman! Materi ini bersifat teoritis dan ditujukan secara eksklusif untuk analis pemula yang pertama kali menemukan analisis BI.
Apa yang secara tradisional dipahami oleh konsep ini? Secara sederhana, ini adalah sistem yang kompleks (seperti, misalnya, penganggaran) untuk mengumpulkan, memproses dan menganalisis data, menyajikan hasil akhir dalam bentuk grafik, bagan, tabel.
Ini membutuhkan kerja yang terkoordinasi dengan baik dari beberapa spesialis sekaligus. Data engineer bertanggung jawab atas penyimpanan dan proses ETL / ELT, analis data membantu mengisi database, analis BI mengembangkan dashboard, analis bisnis menyederhanakan komunikasi dengan pelanggan laporan. Tetapi opsi ini hanya mungkin jika perusahaan siap membayar untuk kerja tim. Dalam kebanyakan kasus, perusahaan kecil bergantung pada satu orang untuk meminimalkan biaya, yang seringkali tidak memiliki pandangan yang luas di bidang BI sama sekali, tetapi hanya memiliki kenalan mengangguk dengan platform pelaporan.
Dalam hal ini, hal berikut terjadi: pengumpulan, pemrosesan, dan analisis data terjadi dengan kekuatan alat tunggal - platform BI itu sendiri. Dalam hal ini, data tidak dihapus sebelumnya dengan cara apa pun, tidak melalui komposit. Pengumpulan informasi berasal dari sumber primer tanpa partisipasi penyimpanan perantara. Hasil pendekatan ini dapat dengan mudah dilihat di forum tematik. Jika Anda mencoba meringkas semua pertanyaan tentang alat BI, maka yang berikut mungkin akan masuk dalam 3 teratas: cara memuat data yang tidak terstruktur dengan baik ke dalam sistem, cara menghitung metrik yang diperlukan darinya, apa yang harus dilakukan jika laporan berjalan sangat lambat. Anehnya, di forum ini Anda hampir tidak akan menemukan diskusi tentang alat ETL, pengalaman gudang data, praktik terbaik pemrograman, dan kueri SQL. Apalagi, saya berulang kali menemukan faktayang analis BI berpengalaman tidak berbicara terlalu menyanjung tentang penggunaan R / Python / Scala, mengutip fakta bahwa semua masalah dapat diselesaikan hanya dengan menggunakan platform BI. Pada saat yang sama, semua orang memahami bahwa rekayasa tanggal yang kompeten memungkinkan Anda menyelesaikan banyak masalah saat membuat pelaporan BI.
-. , . -, , , -, .
«Data – BI» . . (-) (csv, txt, xlsx . .).
. . , . , , . BI .
. (, 1). , . ( , , . .). BI-, . .
«Data – DB – BI» , , . , , .
. , . . SQL ( ), BI-. .
. , . . . SQL.
«Data – ETL – DB – BI» . ETL- , R/Python/Scala . . . .
. , . . BI-.
. ETL- SQL. . , .
. «» SQLite. , (). E-Commerce Data Kaggle.
#
import pandas as pd
#
pd.set_option('display.max_columns', 10)
pd.set_option('display.expand_frame_repr', False)
path_dataset = 'dataset/ecommerce_data.csv'
#
def func_main(path_dataset: str):
#
df = pd.read_csv(path_dataset, sep=',')
#
list_col = list(map(str.lower, df.columns))
df.columns = list_col
# -
df['invoicedate'] = df['invoicedate'].apply(lambda x: x.split(' ')[0])
df['invoicedate'] = pd.to_datetime(df['invoicedate'], format='%m/%d/%Y')
#
df['amount'] = df['quantity'] * df['unitprice']
#
df_result = df.drop(['invoiceno', 'quantity', 'unitprice', 'customerid'], axis=1)
#
df_result = df_result[['invoicedate', 'country', 'stockcode', 'description', 'amount']]
return df_result
#
def func_sale():
tbl = func_main(path_dataset)
df_sale = tbl.groupby(['invoicedate', 'country', 'stockcode'])['amount'].sum().reset_index()
return df_sale
#
def func_country():
tbl = func_main(path_dataset)
df_country = pd.DataFrame(sorted(pd.unique(tbl['country'])), columns=['country'])
return df_country
#
def func_product():
tbl = func_main(path_dataset)
df_product = tbl[['stockcode','description']].\
drop_duplicates(subset=['stockcode'], keep='first').reset_index(drop=True)
return df_product
Extract Transform. , . . , , .
#
import pandas as pd
import sqlite3 as sq
from etl1 import func_country,func_product,func_sale
con = sq.connect('sale.db')
cur = con.cursor()
##
# cur.executescript('''DROP TABLE IF EXISTS country;
# CREATE TABLE IF NOT EXISTS country (
# country_id INTEGER PRIMARY KEY AUTOINCREMENT,
# country TEXT NOT NULL UNIQUE);''')
# func_country().to_sql('country',con,index=False,if_exists='append')
##
# cur.executescript('''DROP TABLE IF EXISTS product;
# CREATE TABLE IF NOT EXISTS product (
# product_id INTEGER PRIMARY KEY AUTOINCREMENT,
# stockcode TEXT NOT NULL UNIQUE,
# description TEXT);''')
# func_product().to_sql('product',con,index=False,if_exists='append')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale;
# CREATE TABLE IF NOT EXISTS sale (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country_id INTEGER NOT NULL,
# product_id INTEGER NOT NULL,
# amount REAL NOT NULL,
# FOREIGN KEY(country_id) REFERENCES country(country_id),
# FOREIGN KEY(product_id) REFERENCES product(product_id));''')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale_data_lake;
# CREATE TABLE IF NOT EXISTS sale_data_lake (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country TEXT NOT NULL,
# stockcode TEXT NOT NULL,
# amount REAL NOT NULL);''')
# func_sale().to_sql('sale_data_lake',con,index=False,if_exists='append')
## (sale_data_lake) (sale)
# cur.executescript('''INSERT INTO sale (invoicedate, country_id, product_id, amount)
# SELECT sdl.invoicedate, c.country_id, pr.product_id, sdl.amount
# FROM sale_data_lake as sdl LEFT JOIN country as c ON sdl.country = c.country
# LEFT JOIN product as pr ON sdl.stockcode = pr.stockcode
# ''')
##
# cur.executescript('''DELETE FROM sale_data_lake''')
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
round(s.amount,1) as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
print(select(sql))
cur.close()
con.close()
(Load) . . . , . .
SQL, . , BI-.
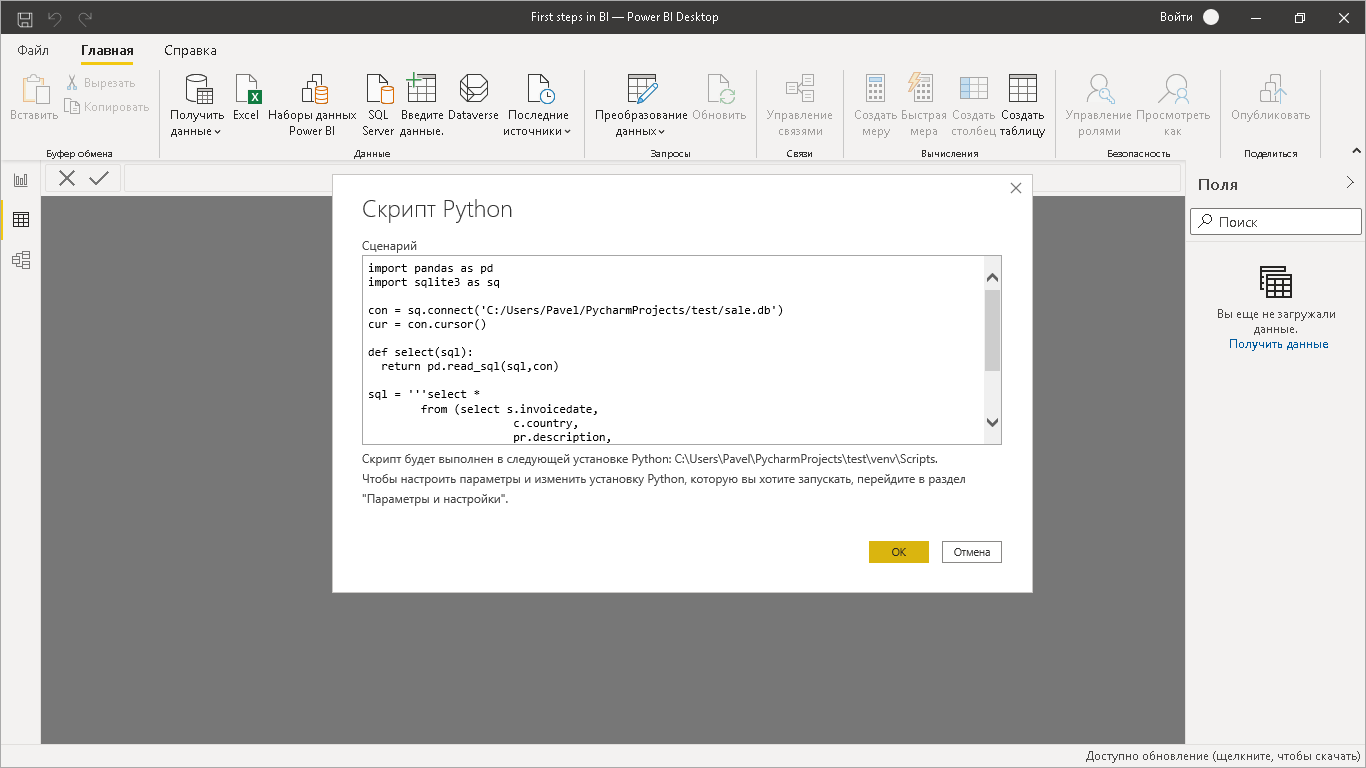
BI- SQLite Python.
import pandas as pd
import sqlite3 as sq
con = sq.connect('C:/Users/Pavel/PycharmProjects/test/sale.db')
cur = con.cursor()
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
replace(round(s.amount,1),'.',',') as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
tbl = select(sql)
print(tbl)
.
«Data – Workflow management platform + ETL – DB – BI» . .
. . .
. . BI. .
«Data – Workflow management platform + ELT – Data Lake – Workflow management platform + ETL – DB – BI» , : (Data Lake), (DB), .
. . , Data Lake.
. . Data Lake – , .
.
BI- .
BI , .
, SQL, - , , , .
Itu saja. Semua kesehatan, semoga sukses dan kesuksesan profesional!