
Seringkali, penggunaan alat yang sudah jadi dalam pembangunan menjadi solusi yang kurang optimal. Jadi itu terjadi dengan kami. Untuk mengelola pipeline data, kami memutuskan untuk mengembangkan sistem kami sendiri - Wombat. Kami akan memberi tahu Anda apa yang terjadi, dan penolakan untuk menggunakan solusi siap pakai yang diberikan kepada kami.
Mengapa kami mengembangkan sistem kami sendiri
Membuat sistem pengelolaan pipeline data Anda sendiri bukanlah pilihan yang jelas. Saat ini ada banyak solusi siap pakai yang dapat menyelesaikan masalah: Aliran udara, MLflow, Kubeflow, Luigi, dan banyak lagi lainnya. Kami telah bereksperimen dengan banyak sistem ini dan sampai pada kesimpulan bahwa tidak ada yang cocok untuk kami.
Misalnya, pertimbangkan solusi paling umum - Aliran udara. Ini menggabungkan enam blok utama: API untuk mendeskripsikan saluran pipa, pengumpul aliran wok, panel kontrol dan antarmuka, penjadwal tugas dan pengatur tugas, dan, terakhir, memantau komponen Aliran Udara. Namun untuk mengelola pipeline, fungsi ini tidak cukup dalam kasus kami.
Bagi kami, fitur seperti integrasi sistem pengelolaan pipeline dengan sistem build dan CI, integrasi dengan Kubernetes, kemampuan untuk mengelola artefak, dan validasi data sangat penting.

Kami memikirkan berapa biaya yang harus kami keluarkan untuk membangun fungsionalitas sistem yang sudah jadi ke tingkat yang diperlukan dan menyadari bahwa akan jauh lebih mudah dan lebih cepat untuk mengembangkan sistem kami sendiri. Kami menyebutnya Wombat - karena hewannya sangat lucu, dan kedua, karena dianggap sebagai penyelamat alam Australia. Dan bagi kami, sistem yang memungkinkan kami menggabungkan pengembangan dan semua tahapan bekerja dengan data juga akan menjadi keselamatan yang nyata.
Masalah apa yang kami pecahkan
Secara historis, dalam tim pengembangan kami, teknisi DevOps mendukung layanan dalam produksi. Dan mereka terbiasa bekerja dengan pipeline, yang dijelaskan bukan dengan kode, tetapi oleh konfigurasi dalam format seperti yaml. Karena perbedaan ini, Anda harus berbagi dukungan atau melatih teknisi untuk bekerja dengan sistem integrasi berkelanjutan non-klasik.
Semua ini akan menjadi pekerjaan yang mubazir dan tidak perlu, karena pipeline dalam bentuk grafik asiklik terarah dijelaskan dengan sempurna dalam format yang digunakan dalam alat CI dan DevOps standar.

Masalah kedua yang kami hadapi adalah penyimpanan dan pembuatan versi artefak. Bekerja dengan artefak dalam sistem pengelolaan pipeline data memungkinkan Anda mendapatkan dua peluang yang sangat berguna: menggunakan kembali hasil bekerja dengan pipeline dan mereproduksi eksperimen dengan data, menghemat waktu untuk mengatur eksperimen baru.
Jika organisasi penyimpanan artefak tidak otomatis, cepat atau lambat artefak baru akan mulai menimpa artefak lama, atau ruang kosong di mesin produksi akan mulai habis. Selain itu, produksi perlu menerapkan persyaratan khusus untuk memastikan keandalan dan toleransi kesalahan penyimpanan, yang merupakan proses mahal lainnya.
Oleh karena itu, kami ingin mendapatkan solusi yang akan melakukan semua tugas yang terkait dengan pengelolaan pipeline di latar belakang, sambil mengizinkan pakar data untuk bekerja dengan artefak dari proyek lain, dan pada saat yang sama tidak memikirkan biaya penyimpanan data.
Masalah ketiga adalah pengetikan aliran data. Ya, Python memungkinkan Anda mengembangkan prototipe dan menguji berbagai hipotesis dengan kecepatan tinggi. Tetapi ketika bekerja dengan data, Anda harus memperhatikan jenis yang Anda kerjakan jika Anda tidak ingin kejutan yang tidak terduga. Untuk mengurangi jumlah masalah seperti itu dalam produksi, kami memerlukan dukungan untuk mendeskripsikan skema data, hingga mendeskripsikan skema bingkai data, dan pengetikan data harus dilakukan secara terpisah untuk pengembangan dan produksi.
Apa yang terjadi pada akhirnya
Secara konvensional, arsitektur Wombat dapat direpresentasikan seperti ini:

Diagram ini menunjukkan peran sistem. Ini adalah lapisan perantara antara deskripsi saluran pipa dan sistem CI, yang dengannya Anda dapat bekerja dengannya dalam produksi.
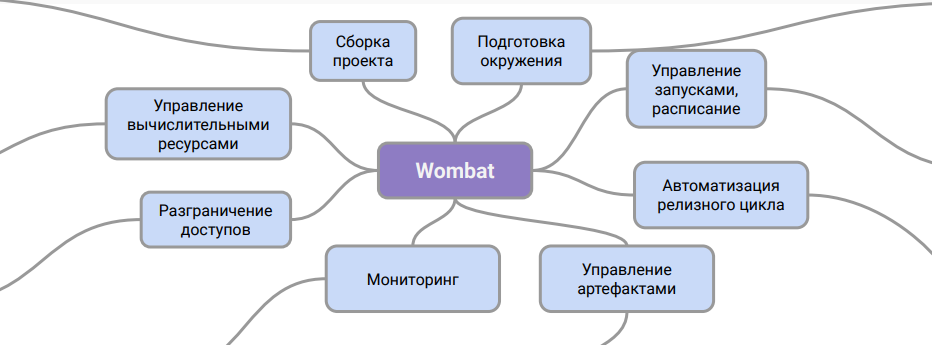
Berkat skema kerja ini, kami dapat mengatur dukungan untuk pipeline di departemen DevOps tanpa pelatihan tambahan untuk teknisi dan tanpa melibatkan pakar data dalam proses ini. Selain itu, masalah dengan penyimpanan artefak data dan versinya telah terpecahkan.
Sekarang kami sedang mengembangkan fungsionalitas yang akan memungkinkan pengenalan alat ke tahap awal pembuatan prototipe dan eksperimen dalam bentuk asli data Scientists, yang secara signifikan akan mempercepat peluncuran proyek ke dalam percontohan dan produksi.
Kami sedang mempersiapkan untuk merilis alat ini dalam sumber terbuka dalam waktu dekat. Kami akan senang jika Anda membagikan pendapat Anda tentang proyek kami dan pengalaman Anda bekerja dengan sistem pipeline data modern.
Selain itu, menyadari bahwa artikel ini lebih bersifat informatif daripada teknis, dalam waktu dekat kami berencana untuk menyiapkan teks hardcore yang lebih detail. Tulis di komentar apa yang ingin Anda lihat dan temukan dalam istilah teknis. Kami akan memperhitungkan, mendeskripsikan dan menulis. Terima kasih atas perhatiannya!
PS Kami masih tertarik dengan programmer berbakat. Ayo, itu akan menarik !