Baru-baru ini Sberbank dalam artikel Yang kita butuhkan adalah generasi yang menyarankan pendekatan yang tidak biasa untuk menyaring teks berkualitas rendah (sampah teknis dan spam template).
Kami melengkapi pendekatan ini dengan satu lagi heuristik: kami membuat kompresi teks menggunakan zlib dan membuang kompresi yang paling kuat dan lemah, lalu kami menerapkan klasifikasi. Rentang kompresi yang dipilih secara empiris untuk teks normal × 1.2— × 8 (kurang dari 1.2 - karakter acak dan sampah teknis, lebih dari 8 - spam template).
Pendekatan tersebut tentunya menarik dan layak diadopsi. Tetapi bukankah rasio kompresi zlib pada teks berkualitas memiliki ketergantungan non-linier pada panjang teks yang dikompresi? Mari kita periksa.
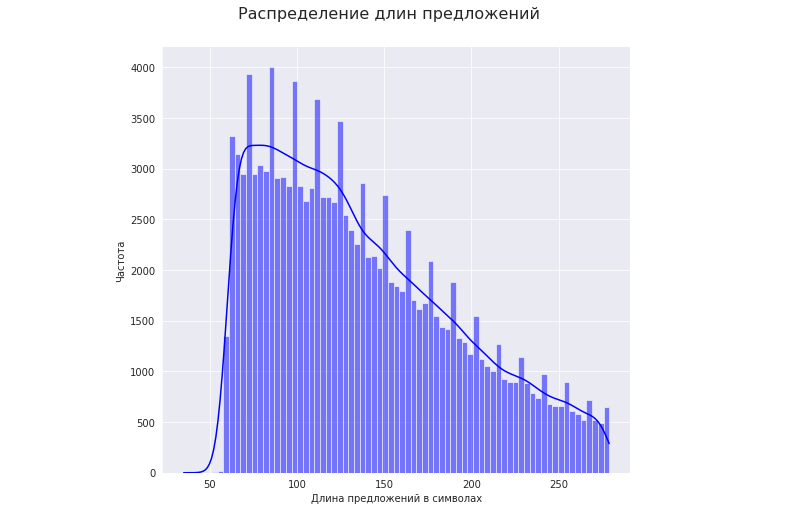
Mari kita ambil kumpulan teks kalimat yang panjangnya berkisar dari 50 hingga 280 karakter:
import zlib
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.optimize import curve_fit
with open('/content/test.txt', 'r', encoding='utf-8') as f:
text = f.read()
sntc = text.split('\n')
l_sntc = [] #
k_zlib = [] #
for s in sntc:
l_sntc.append(len(s))
k_zlib.append(len(s) / len(zlib.compress(s.encode(), -1)))
Mari kita lihat bagaimana panjang kalimat berkualitas tinggi memengaruhi rasio kompresi.
Untuk ini:
1. Mari kita ambil rentang panjang kalimat dengan frekuensi tertinggi (persentil 25 - 75). Dalam kasus kami, ini memiliki panjang 92 hingga 175 karakter:
mp_1 = np.percentile(np.array(l_sntc), [25, 75])
print(': ' + str(mp_1))
2. . 25 (25 + w) 75 (75 - w) ( ), w - ( 2.5 ).
:
w = 2.5 #
mp_2 = np.percentile(np.array(l_sntc), [25 + w, 75 - w])
dl = int(min(mp_2[0] - mp_1[0], mp_1[1] - mp_2[1]))
print(' : ' + str(dl))
3 .
+- 3 :
#
id_sntc = range(len(sntc)) #
x = zip(l_sntc, id_sntc)
xs = sorted(x, key = lambda tup: tup[0])
l_sntc_s = [x[0] for x in xs]
id_snt_s = [x[1] for x in xs]
gr = 0 #
k_gr = [[]] #
l_gr = [[]] #
sl0 = l_sntc_s[l_sntc_s.index(mp_1[0])] #
nt = l_sntc_s.index(mp_1[1])
for i in range(nt, len(l_sntc_s)):
if l_sntc_s[i] > l_sntc_s[nt]:
nt = i
break
for i in range(l_sntc_s.index(mp_1[0]), nt):
if l_sntc_s[i] > sl0 + dl:
sl0 = l_sntc_s[i]
k_gr.append([])
l_gr.append([])
gr += 1
else:
k_gr[gr].append(k_zlib[id_snt_s[i]])
l_gr[gr].append(l_sntc_s[i])
print(' : ' + str(gr))
20 .
3. , :
x = [0]
y = [0]
for i in range(gr + 1):
x.append(np.percentile(np.array(l_gr[i]), 50))
y.append(np.percentile(np.array(k_gr[i]), 50))

:

x - , y - .
x = np.array(x)
y = np.array(y)
#
def func(x, a, b):
return a * x ** b
popt, pcov = curve_fit(func, x, y, (0.27, 0.24), maxfev=10 ** 6)
a, b = popt
print('a = {0}\nb = {1}'.format(*tuple(popt)))
print(' : ' + str(np.corrcoef(y, a * x ** b)[0][1]))
a = 0.17601951773514363, b = 0.3256903074228561, : 0.9999489378452683
:

( 50 - 280 ) , . "c" "y = " ( ), , :
c = np.percentile(np.array(k_zlib), 50)
graph = plt.figure()
axes = graph.add_axes([0, 0, 1, 1])
axes.set_xlabel(' ')
axes.set_ylabel(' ')
axes.set_title(' ')
axes.plot([60, 280], [c, c], color='r')
axes.plot(range(60, 281), a * np.array(range(60, 281)) ** b, color='b')

. ~130 , ~130 - . . , .
, . , .
k_zlib_f = np.array(k_zlib) * c / (a * np.array(l_sntc) ** b)
, :
dalam kasus kami, kalimat telah dibersihkan dari sampah teknis, jadi sebagai contoh kami hanya memfilter kalimat yang berisi spam:
p_zlib_1 = np.percentile(np.array(k_zlib), 99.95)
p_zlib_2 = np.percentile(np.array(k_zlib_f), 99.95)
for i in range(len(sntc)):
if k_zlib_f[i] > p_zlib_2 and k_zlib[i] <= p_zlib_1:
print(sntc[i])

Seperti yang Anda lihat, ini adalah kalimat pendek yang rasio kompresinya diremehkan . Dalam praktiknya, kalimat dengan panjang yang sama sangat jarang ditemukan di korpus. Biasanya, rentang panjangnya cukup signifikan.
Kode laptop lengkap diposting di GitHub .
Mungkin itu akan berguna bagi seseorang. Saya telah mengadopsi pendekatan ini untuk diri saya sendiri sebagai cara yang relatif sederhana dan efektif untuk menyingkirkan sampah teknis dan spam template.