
Saya memutuskan untuk menulis artikel untuk siapa pun yang mencoba menemukan pertanyaan dan jawaban wawancara Amazon yang relevan. Saya telah mengambil beberapa pertanyaan wawancara yang telah diajukan dalam beberapa bulan terakhir dan mencoba memberikan jawaban yang ringkas dan jelas kepada mereka. Ada pertanyaan yang sulit, ada yang sederhana, tetapi bagaimanapun juga, keduanya bisa bermanfaat.
T: Pasangan itu memiliki dua anak dan pasangan itu tahu bahwa salah satu dari mereka adalah laki-laki. Seberapa besar kemungkinan anak lain akan menjadi laki-laki?
Tidak ada tangkapan di sini. Probabilitas satu anak menjadi laki-laki tidak tergantung pada yang lain, jadi 50%. Anda mungkin bingung dengan pertanyaan Leonard Mlodinov , di mana jawabannya adalah sepertiga, tetapi ini adalah pertanyaan yang sama sekali berbeda, tidak terkait dengan pertanyaan kami.
T: Jelaskan apa itu nilai-p.
Jika Anda mencari di Google tentang nilai p, Anda akan mendapatkan jawaban berikut: "Ini adalah probabilitas untuk mendapatkan model probabilistik tertentu dari distribusi nilai variabel acak nilai statistik yang sama atau lebih ekstrem (aritmatika mean, median, dll.), dibandingkan dengan yang diamati sebelumnya, asalkan hipotesis nolnya benar. "
Jawaban verbal, karena p sangat spesifik artinya dan sering disalahpahami.
Definisi yang lebih sederhana dari nilai-p adalah: "Ini adalah probabilitas bahwa statistik yang diamati akan terjadi secara kebetulan, dengan mempertimbangkan distribusi sampel."
Alpha menetapkan standar bagaimana nilai ekstrim harus sebelum hipotesis nol dapat ditolak. Nilai p menunjukkan ekstrimnya data.
Q: Ada 4 bola merah dan 2 bola biru, berapa probabilitasnya akan sama dalam dua pemilu?
Jawabannya adalah probabilitas keduanya berwarna merah, ditambah probabilitas keduanya berwarna biru. Mari kita asumsikan bahwa pertanyaan ini tanpa pengganti.
- Probabilitas 2 merah = (4/6) * (3/6) = 1/3 atau 33%
- Probabilitas 2 biru = (2/6) * (1/6) = 1/18 atau 5,6%
Oleh karena itu, probabilitas bola akan sama kira-kira 38,6%.
T: Jelaskan pohon, SVM dan hutan acak. Beri tahu kami tentang kelebihan dan kekurangan mereka.
Decision Trees: Sebuah model pohon yang digunakan untuk membuat model keputusan berdasarkan satu atau lebih kondisi.
Kelebihan: Mudah diimplementasikan, intuitif, menangani nilai yang hilang.
Kekurangan: varian tinggi, tidak tepat
Kelebihan: akurasi dimensi tinggi
Kekurangan: kecenderungan overfit, tidak secara langsung memperkirakan probabilitas
Kelebihan: Dapat mencapai presisi yang lebih tinggi, menangani nilai yang hilang, tidak memerlukan penskalaan fungsi, dapat menentukan kepentingan fungsi.
Kekurangan: kotak hitam, intensif secara komputasi.
Reduksi dimensi adalah proses pengurangan jumlah fitur dalam sebuah dataset. Ini terutama penting saat Anda ingin mengurangi varians model Anda (overfitting).
Wikipedia menyatakan empat manfaat pengurangan dimensi:
- Mengurangi waktu dan ruang penyimpanan yang dibutuhkan.
- Menghapus multikolinearitas meningkatkan interpretasi parameter model pembelajaran mesin.
- Ini menjadi lebih mudah untuk memvisualisasikan data saat diperkecil ke dimensi yang sangat kecil seperti 2D atau 3D.
- Menghindari kutukan dimensi.
Kita perlu membuat beberapa asumsi atas pertanyaan ini sebelum kita dapat menjawabnya. Misalkan ada dua kemungkinan lokasi untuk membeli item tertentu di Amazon, dan kemungkinan menemukannya di lokasi A adalah 0,6 dan B adalah 0,8. Kemungkinan menemukan produk di Amazon dapat dijelaskan sebagai berikut:
Kita dapat merumuskan ulang hal di atas sebagai P (A) = 0,6 dan P (B) = 0,8. Juga, mari kita asumsikan bahwa ini adalah peristiwa independen, yang berarti kemungkinan satu peristiwa tidak bergantung pada peristiwa lain. Kita kemudian dapat menggunakan rumus ...
P (A atau B) = P (A) + P (B) - P (A dan B)
P (A atau B) = 0.6 + 0.8 - (0.6 * 0, 8)
P (A atau B) = 0,92
Q: Jika ada 8 bola dengan berat yang sama dan 1 bola yang beratnya lebih sedikit (total 9 bola), berapa banyak timbangan yang dibutuhkan untuk menentukan bola mana yang paling berat?

Dibutuhkan dua timbangan (lihat Bagian A dan B di atas):
Anda harus membagi sembilan bola menjadi tiga kelompok yang terdiri dari tiga dan menimbang dua kelompok. Jika timbangannya seimbang (opsi 1), Anda tahu bahwa bola berat itu termasuk dalam kelompok bola ketiga. Jika tidak, Anda akan mengambil grup dengan beban besar (opsi 2).
Kemudian Anda mengikuti langkah yang sama, tetapi Anda akan memiliki tiga kelompok satu balon, bukan tiga kelompok tiga.
T: Apa itu "pelatihan ulang"?
Overfitting adalah error saat model "pas" dengan data, menghasilkan model dengan varians tinggi dan bias rendah. Akibatnya, model overfitting akan memprediksi titik data baru secara tidak akurat, meskipun model tersebut memiliki fidelitas yang tinggi dalam data pelatihan.
T: Kami memiliki dua model, satu dengan akurasi 85%, yang lainnya dengan akurasi 82%. Mana yang akan kamu pilih?
Jika kita hanya peduli pada keakuratan model, maka jawabannya adalah 85%. Tetapi jika pewawancara bertanya tentang hal ini, mungkin ada baiknya mencari tahu dalam konteks apa pertanyaan tersebut diajukan, yaitu. apa yang model coba prediksi. Ini akan memberi kita gagasan yang lebih baik tentang apakah metrik penilaian harus benar-benar akurat, atau metrik lain seperti perolehan atau skor f1.
T: Apa yang dimaksud dengan algoritma Bayesian naif?
Pengklasifikasi Naive Bayesian adalah pengklasifikasi populer yang digunakan dalam Ilmu Data. Ide di balik ini didasarkan pada teorema Bayes:

Secara sederhana, persamaan ini digunakan untuk menjawab pertanyaan berikutnya. “Berapa probabilitas y (variabel keluaran saya) dengan X (variabel masukan saya)? Dan karena asumsi naif bahwa variabel-variabel tidak bergantung untuk kelas tertentu, Anda dapat mengatakan bahwa:

Selain itu, dengan menghilangkan penyebut, kita dapat mengatakan bahwa P (y | X) sebanding dengan ruas kanan.
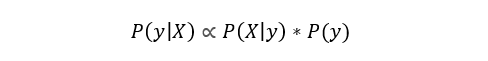
Oleh karena itu, tujuannya adalah menemukan kelas dengan probabilitas proporsional tertinggi.
T: Bagaimana perubahan biaya keanggotaan dasar mempengaruhi pasar?
Saya tidak 100% yakin tentang jawaban atas pertanyaan ini, tetapi saya akan mencoba yang terbaik!
Mari kita ambil contoh kenaikan biaya keanggotaan dasar - ada dua pihak yang terlibat: pembeli dan penjual.
Bagi pembeli, dampak kenaikan iuran keanggotaan dasar pada akhirnya bergantung pada elastisitas harga permintaan pembeli. Jika elastisitas harga tinggi, maka kenaikan harga tertentu akan menyebabkan penurunan permintaan yang signifikan dan sebaliknya. Pembeli yang terus membeli iuran keanggotaan mungkin adalah pelanggan Amazon yang paling setia dan aktif - kemungkinan besar mereka juga akan lebih memperhatikan produk premium.
Penjual akan menderita karena biaya membeli sekeranjang produk Amazon sekarang lebih tinggi. Ini akan membuat beberapa makanan lebih terpengaruh sementara yang lain mungkin tidak. Kemungkinan produk premium yang dibeli pelanggan paling setia Amazon tidak akan terpukul separah elektronik.
Terima kasih atas perhatian Anda!
Yang saya sukai dari wawancara ini dan masalah yang mereka hadapi adalah dua hal:
- Mereka membantu Anda mempelajari konsep-konsep baru yang tidak Anda kenal sebelumnya.
- Mereka membuka konsep yang Anda ketahui dari sudut pandang baru.
Saya harap semua ini akan membantu Anda mempersiapkan perjalanan Anda ke dunia Ilmu Data!
, Data Science AR- Banuba - Skillbox.
, -: , , . «» .
« ». . , , , .
:
1) , ?
2) ?
3) ?
4) , , -?
5) , ?
, .