- Artikel Penelitian
- Pytorch : YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 ( gudang utama - digunakan untuk mereproduksi hasil)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet : YOLOv4-tiny, YOLOv4-CSP, YOLOv4x-MISH
- Struktur YOLOv4-CSP
YOLO v4 yang diskalakan adalah jaringan neural paling akurat ( 55,8% AP ) di kumpulan data Microsoft COCO dari semua jaringan neural yang dipublikasikan hingga saat ini. Dan juga yang terbaik dalam hal rasio kecepatan terhadap akurasi di seluruh rentang akurasi dan kecepatan dari 15 FPS hingga 1774 FPS . Saat ini, ini adalah jaringan saraf Top1 untuk deteksi objek.
YOLO v4 yang diskalakan mengungguli jaringan neural dalam hal akurasi:
- Google EfficientDet D7x / DetectoRS atau SpineNet-190 (dilatih sendiri tentang data tambahan)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
Kami menunjukkan bahwa pendekatan Jaringan YOLO dan Cross-Stage-Partial (CSP) adalah yang terbaik dalam hal akurasi absolut dan rasio akurasi terhadap kecepatan.
Grafik Akurasi (sumbu vertikal) dan Latency (sumbu horizontal) pada GPU Tesla V100 (Volta) dengan batch = 1 tanpa menggunakan TensorRT:
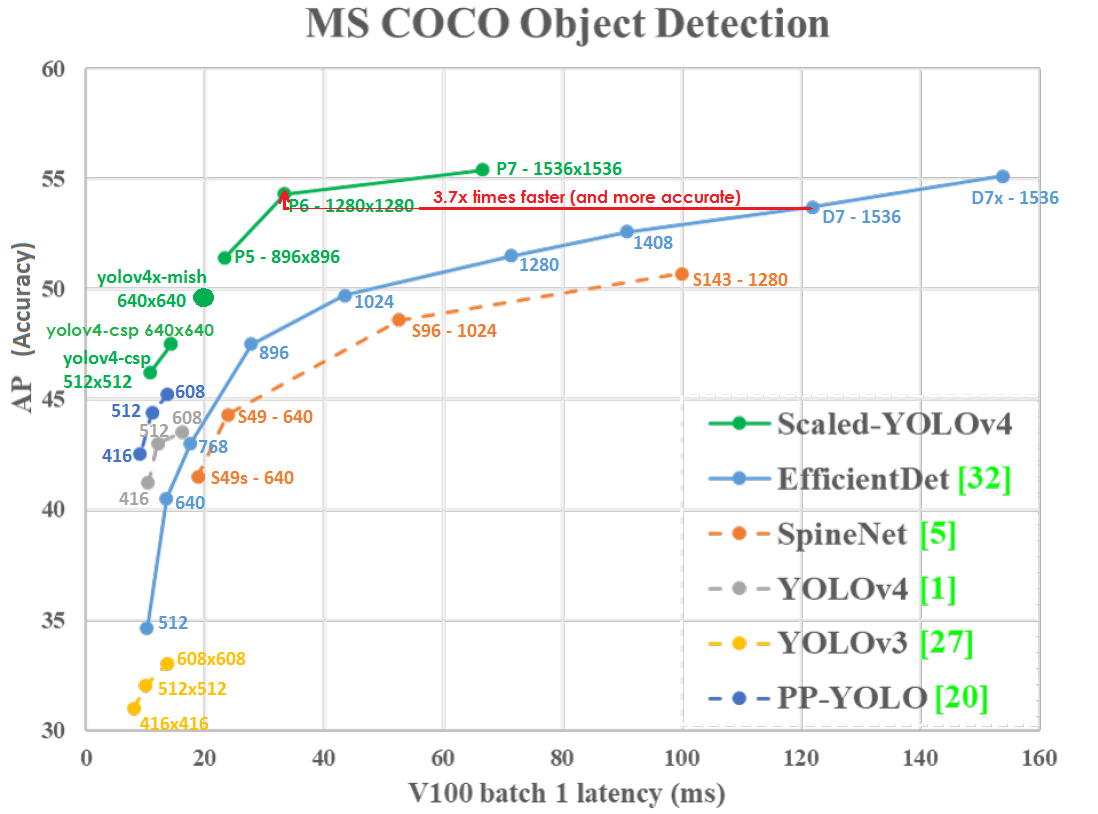
Bahkan pada resolusi jaringan yang lebih rendah, Scaled-YOLOv4-P6 (1280x1280) 30 FPS sedikit lebih akurat dan 3,7x lebih cepat daripada EfficientDetD7 (1536x1536) 8.2 FPS. Itu. YOLOv4 memanfaatkan resolusi jaringan dengan lebih baik.
Skala YOLO v4 terletak pada kurva optimalitas Pareto - apa pun jaringan saraf lain yang Anda gunakan, selalu ada jaringan YOLOv4 seperti itu, yang lebih akurat pada kecepatan yang sama, atau lebih cepat dengan akurasi yang sama, yaitu. YOLOv4 adalah yang terbaik dalam hal kecepatan dan akurasi.
YOLOv4 yang diskalakan lebih akurat dan lebih cepat daripada jaringan neural:
- Google EfficientDet D0-D7x
- Google SpineNet S49s - S143
- Baidu Paddle-Paddle PP YOLO
- Dan banyak lagi
Scaled YOLO v4 adalah rangkaian jaringan neural yang dibangun dari jaringan YOLOv4 yang ditingkatkan dan diskalakan. Jaringan saraf kami dilatih dari awal tanpa menggunakan beban terlatih (Imagenet atau lainnya).
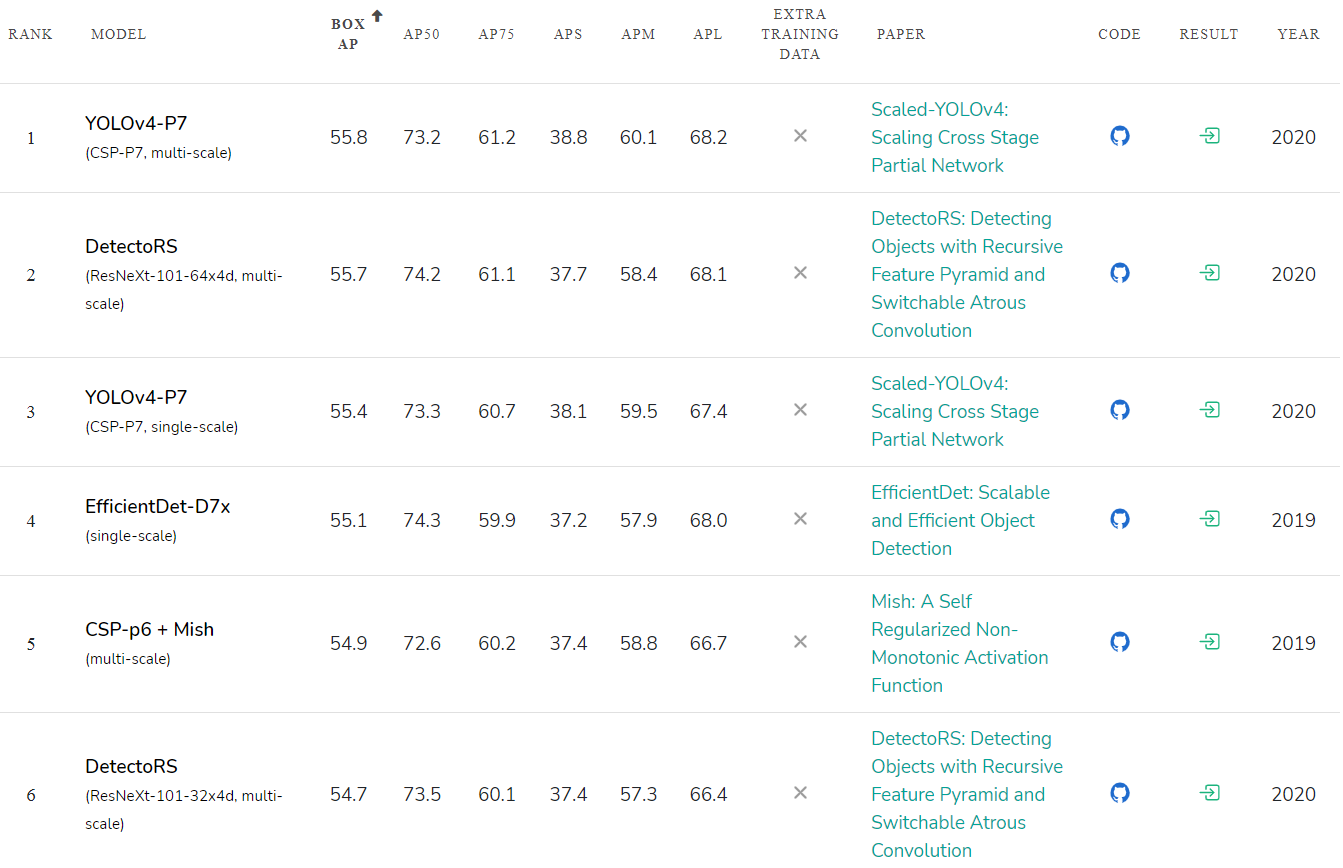
Peringkat akurasi jaringan saraf yang dipublikasikan: paperwithcode.com/sota/object-detection-on-coco :
Kecepatan jaringan saraf YOLOv4-tiny mencapai 1774 FPS pada GPU game RTX 2080Ti menggunakan TensorRT + tkDNN (batch = 4, FP16): github com / ceccocats / tkDNN
YOLOv4-tiny dapat berjalan secara real-time pada 39 FPS / 25ms Latency di JetsonNano (416x416, fp16, batch = 1) tkDNN / TensorRT:

YOLOv4 yang diskalakan menggunakan sumber daya komputer paralel seperti GPU dan NPU dengan jauh lebih efisien. Misalnya, GPU V100 (Volta) memiliki performa: 14 TFLops - 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
Jika kita uji kedua model pada GPU V100 dengan batch = 1 , dengan parameter --hparams = mixed_precision = true dan tanpa --tensorrt = FP32 , maka:
- YOLOv4-CSP (640x640) - 47.5% AP - 70 FPS - 120 BFlops (60 FMA)
Berdasarkan BFlops, seharusnya 933 FPS = (112.000 / 120), tetapi kenyataannya kami mendapatkan 70 FPS, yaitu menggunakan 7,5% GPU = (70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
Itu. efisiensi operasi komputasi pada perangkat dengan komputasi paralel masif seperti GPU yang digunakan di YOLOv4-CSP (7.5 / 1.6) = 4,7x lebih baik daripada efisiensi operasi yang digunakan di EfficientDetD3.
Biasanya, jaringan neural dijalankan pada CPU hanya dalam tugas penelitian untuk proses debug yang lebih mudah, dan karakteristik BFlops saat ini hanya untuk kepentingan akademis. Dalam tugas dunia nyata, kecepatan dan akurasi yang nyata itu penting, bukan kinerja di atas kertas. Kecepatan sebenarnya dari YOLOv4-P6 adalah 3,7x lebih cepat daripada EfficientDetD7 pada GPU V100. Oleh karena itu, perangkat dengan paralelisme besar GPU / NPU / TPU / DSP dengan kecepatan, harga, dan pembuangan panas yang jauh lebih optimal hampir selalu digunakan:
- GPU Tertanam (Jetson Nano / Nx)
- Mobile-GPU / NPU / DSP (Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge (Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-motors TPU 144 TOPS-8bit)
- Cloud GPU (nVidia A100 / V100 / TitanV)
- Cloud NPU (Google-TPU, Huawei Ascend, Intel Habana, Qualcomm AI 100, ...)
Juga saat menggunakan jaringan neural Di Web - biasanya GPU digunakan melalui WebGL, WebAssembly, pustaka WebGPU, untuk kasus ini - ukuran model dapat berpengaruh : github.com/tensorflow/tfjs#about-this-repo
Menggunakan perangkat dan algoritme dengan kelemahan paralelisme adalah jalan buntu pembangunan, karena tidak mungkin untuk mengurangi ukuran litograf yang lebih kecil dari ukuran atom silikon untuk meningkatkan frekuensi prosesor:
- Ukuran terbaik saat ini untuk fabrikasi perangkat Semikonduktor adalah 5 nanometer.
- Ukuran kisi kristal silikon adalah 0,5 nanometer.
- Jari-jari atom silikon adalah 0,1 nanometer.
Solusinya adalah komputer dengan paralelisme masif: pada satu kristal atau pada beberapa kristal yang dihubungkan oleh sebuah interposer. Oleh karena itu, sangat penting untuk membuat jaringan saraf yang secara efisien menggunakan mesin komputasi paralel besar-besaran seperti GPU dan NPU.
Peningkatan dalam Skala YOLOv4 dibandingkan YOLOv4:
- YOLOv4 yang diskalakan menggunakan teknik penskalaan jaringan yang optimal untuk mendapatkan jaringan YOLOv4-CSP -> P5 -> P6 -> P7
- Arsitektur jaringan yang ditingkatkan: Backbone dioptimalkan dan Neck (PAN) menggunakan koneksi Cross-stage-partial (CSP) dan aktivasi Mish
- Exponential Moving Average (EMA) digunakan selama pelatihan - ini adalah kasus khusus SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- Untuk setiap resolusi jaringan, jaringan saraf terpisah dilatih (di YOLOv4, hanya satu jaringan saraf yang dilatih untuk semua resolusi)
- Memperbaiki normalizer di lapisan [yolo]
- Aktivasi yang diubah untuk Lebar dan Tinggi, yang memungkinkan pelatihan jaringan lebih cepat
- Gunakan parameter [net] letter_box = 1 (pertahankan rasio aspek gambar masukan) untuk jaringan resolusi tinggi (untuk semua kecuali yolov4-tiny.cfg)
Arsitektur jaringan saraf Scaled-YOLOv4 (contoh dari tiga jaringan: P5, P6, P7):

Sambungan CSP sangat efisien, sederhana, dan dapat diterapkan ke jaringan neural apa pun. Intinya adalah itu
- setengah dari sinyal keluaran berjalan di sepanjang jalur utama (menghasilkan lebih banyak informasi semantik dengan bidang reseptif yang besar)
- dan separuh sinyal lainnya mengikuti jalan memutar (menyimpan lebih banyak informasi spasial dengan bidang reseptif kecil)
Contoh paling sederhana dari koneksi CSP (di sebelah kiri adalah jaringan biasa, di sebelah kanan adalah jaringan CSP):

Contoh koneksi CSP di YOLOv4-CSP / P5 / P6 / P7
(di sebelah kiri adalah jaringan biasa, di sebelah kanan adalah jaringan CSP):

Di YOLOv4-tiny ada 2 koneksi CSP :

YOLOv4 digunakan di berbagai bidang dan tugas:
- Pemerintah Taiwan: Kontrol lalu lintas www.taiwannews.com.tw/en/news/3957400 dan youtu.be/IiU6wFmfVnk
- Amazon: Instans Anti-Covid19 Distance-assistant github.com/amzn/distance-assistant dan Amazon Neurochip / Amazon EC2 Inf1: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- based-object-detection-with-an-aws-neuron-compiled-yolov4-model-on-aws-inferentia
- BMW Innovation Lab: github.com/BMW-InnovationLab
Dan dalam banyak tugas lainnya….
Ada implementasi dalam berbagai kerangka kerja:
- Pytorch : github.com/WongKinYiu/ScaledYOLOv4
- Darknet : github.com/AlexeyAB/darknet
- TensorFlow : github.com/hunglc007/tensorflow-yolov4-tflite
- o pip instal yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- Struktur jaringan dapat dilihat menggunakan utilitas Netron - Visualizer untuk jaringan saraf: github.com/lutzroeder/netron
Cara mengompilasi dan menjalankan Cloud Object Detection secara gratis :
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- video: www.youtube.com/watch?v=mKAEGSxwOAY
Cara menyusun dan menjalankan Pelatihan di Cloud secara gratis :
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- video: youtu.be/mmj3nxGT2YQ
Selain itu, pendekatan YOLOv4 dapat digunakan di tugas lain, misalnya, saat mendeteksi objek 3D:
- Kode - Complex-YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- Kode - YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch
