Melodi obsesif (cacing telinga bahasa Inggris.) - fenomena yang terkenal dan terkadang menjengkelkan. Begitu salah satunya tersangkut di kepala, mungkin sulit untuk menyingkirkannya. Penelitian telah menunjukkan bahwa apa yang disebut interaksi dengan komposisi aslinya , baik mendengarkan atau menyanyikannya, membantu mengusir melodi yang mengganggu. Tetapi bagaimana jika Anda tidak dapat mengingat nama lagunya, tetapi hanya dapat menyenandungkan nadanya?
Saat menggunakan metode yang ada untuk membandingkan melodi yang dinyanyikan dengan rekaman studio polifonik aslinya, sejumlah kesulitan muncul. Suara rekaman live atau studio dengan lirik, vokal latar, dan instrumen bisa sangat berbeda dari senandung seseorang. Selain itu, karena kesalahan atau desain, versi kami mungkin tidak memiliki nada, kunci, tempo, atau ritme yang sama persis. Inilah sebabnya mengapa begitu banyak pendekatan saat ini terhadap kueri dengan sistem senandung memetakan melodi yang dinyanyikan ke database melodi yang sudah ada sebelumnya atau versi yang dinyanyikan lainnya dari lagu itu, daripada mengidentifikasinya secara langsung. Namun, jenis pendekatan ini sering kali didasarkan pada database terbatas yang memerlukan pembaruan manual. Hum to Search
diluncurkan pada bulan Oktoberadalah sistem Penelusuran Google yang baru dan sepenuhnya pembelajaran mesin yang memungkinkan seseorang menemukan lagu dengan menyanyikan atau terburu-buru. Tidak seperti metode yang ada, pendekatan ini menciptakan embedding dari spektogram lagu, melewati representasi perantara. Ini memungkinkan model untuk membandingkan melodi kami secara langsung dengan rekaman asli (polifonik) tanpa harus memiliki versi melodi atau MIDI yang berbeda untuk setiap trek. Itu juga tidak perlu menggunakan logika buatan tangan yang rumit untuk mengekstrak melodi. Pendekatan ini sangat menyederhanakan database untuk Hum ke Penelusuran, memungkinkan Anda untuk terus menambahkan embeddings trek asli dari seluruh dunia, bahkan rilis terbaru, ke dalamnya.
Bagaimana itu bekerja
Banyak sistem pengenalan musik yang ada mengubah sampel audio menjadi spektogram untuk menemukan kecocokan yang lebih tepat sebelum memproses sampel audio. Namun, ada satu masalah dalam mengenali melodi yang dinyanyikan - sering kali informasi tersebut relatif sedikit, seperti dalam contoh lagu "Bella Ciao" ini . Perbedaan antara versi yang dinyanyikan dan segmen yang sama dari rekaman studio yang sesuai dapat divisualisasikan menggunakan spektogram yang ditunjukkan di bawah ini:

Visualisasi potongan yang dinyanyikan dan rekaman studionya
Mengingat gambar di sebelah kiri, model harus menemukan audio yang sesuai dengan gambar kanan dalam koleksi lebih dari 50 juta gambar yang serupa (sesuai dengan segmen rekaman studio dari lagu lain). Untuk melakukan ini, model harus belajar untuk fokus pada melodi dominan dan mengabaikan vokal latar, instrumen, dan timbre suara, serta perbedaan karena kebisingan latar atau gema. Untuk menentukan sendiri melodi dominan yang dapat digunakan untuk membandingkan kedua spektogram ini, Anda dapat mencari persamaan pada garis-garis di bawah gambar di atas.
Upaya sebelumnya untuk menerapkan pengenalan musik, terutama musik di kafe atau klub, telah menunjukkan bagaimana pembelajaran mesin dapat diterapkan pada masalah ini. Now Playing , dirilis pada tahun 2017 untuk ponsel Pixel, menggunakan jaringan neural dalam bawaan untuk mengenali lagu tanpa perlu sambungan server, dan Penelusuran Suara , yang kemudian mengembangkan teknologinya, menggunakan pengenalan berbasis server untuk mencari lebih dari 100 juta lagu dengan cepat dan akurat. Kami juga perlu menerapkan apa yang kami pelajari dalam rilis ini untuk mengenali musik dari perpustakaan besar yang serupa, tetapi sudah dari bagian yang dinyanyikan.
Menyiapkan pembelajaran mesin
Langkah pertama dalam evolusi Hum to Search adalah mengubah model pengenalan musik yang digunakan di Now Playing dan Sound Search untuk bekerja dengan rekaman melodi. Pada dasarnya, banyak mesin pencari serupa (seperti pengenalan gambar) bekerja dengan cara yang sama. Dalam proses pelatihan, jaringan saraf menerima pasangan (melodi dan rekaman asli) sebagai masukan dan membuat embeddings, yang nantinya akan digunakan untuk mencocokkan melodi yang dinyanyikan.

Menyiapkan pelatihan jaringan saraf
Untuk memastikan pengenalan apa yang kita nyanyikan, embeddings pasangan audio dengan melodi yang sama harus ditempatkan di samping satu sama lain, meskipun keduanya memiliki iringan instrumen dan suara nyanyian yang berbeda. Pasangan audio yang berisi melodi berbeda harus berjauhan. Selama pelatihan, jaringan menerima pasangan audio tersebut hingga ia belajar membuat embeddings dengan properti ini.
Pada akhirnya, model terlatih akan dapat menghasilkan embeddings untuk lagu kami, mirip dengan embeddings pada rekaman master lagu. Dalam kasus ini, menemukan lagu yang tepat hanya dengan mencari database untuk embeddings serupa yang dihitung berdasarkan rekaman audio musik populer.
Data pelatihan
Karena melatih model membutuhkan pasangan lagu (direkam dan dinyanyikan), tantangan pertama adalah mendapatkan data yang cukup. Dataset asli kami sebagian besar terdiri dari cuplikan yang dinyanyikan (sangat sedikit yang berisi hanya senandung motif tanpa kata-kata). Untuk membuat model lebih andal, selama pelatihan, kami menerapkan augmentasi pada fragmen berikut: kami mengubah nada dan tempo dalam urutan acak. Model yang dihasilkan bekerja cukup baik sebagai contoh di mana lagu itu dinyanyikan daripada disenandungkan atau disiulkan.
Untuk meningkatkan performa model pada melodi tanpa kata, kami membuat data pelatihan tambahan dengan "hum" buatan dari kumpulan data audio yang ada. Untuk ini kami menggunakan SPICE , model ekstraksi lapangan yang dikembangkan oleh tim tambahan kami sebagai bagian dari sebuah proyekFreddieMeter . SPICE mengekstrak nilai nada dari audio tertentu, yang kemudian kami gunakan untuk menghasilkan melodi yang terdiri dari nada audio diskrit. Versi pertama dari sistem ini telah mengubah bagian aslinya di sini .
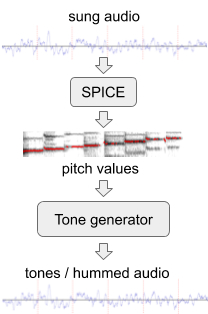
Menghasilkan "hum" dari fragmen audio yang dinyanyikan.
Kemudian kami meningkatkan pendekatan dengan mengganti penghasil nada sederhana dengan jaringan saraf yang menghasilkan suara yang menyerupai dengungan nyata dari suatu motif tanpa kata. Sebagai contoh, potongan di atas dapat diubah menjadi seperti senandung atau peluit .
Pada langkah terakhir, kami membandingkan data pelatihan dengan mencampur dan mencocokkan cuplikan audio. Ketika, misalnya, kami menemukan cuplikan serupa dari dua artis berbeda, kami menyelaraskannya dengan model awal kami dan oleh karena itu memberikan model dengan pasangan tambahan cuplikan audio dari melodi yang sama.
Memperbaiki model
Dalam melatih model Hum to Search, kami memulai dengan fungsi kerugian triplet , yang telah bekerja dengan baik dalam berbagai tugas klasifikasi seperti mengklasifikasikan gambar dan musik yang direkam . Jika sepasang audio diberikan yang cocok dengan melodi yang sama (titik R dan P dalam ruang embedding yang ditunjukkan di bawah), fungsi kerugian triplet mengabaikan bagian tertentu dari data pelatihan yang diturunkan dari melodi lain. Ini membantu meningkatkan perilaku belajar ketika model menemukan melodi lain yang terlalu sederhana dan sudah jauh dari R dan P (lihat poin E). Dan juga ketika itu terlalu kompleks untuk tahap pelatihan model saat ini dan ternyata terlalu dekat dengan R (lihat poin H).

Contoh segmen audio yang dirender sebagai titik dalam ruang
Kami telah menemukan bahwa kami dapat meningkatkan keakuratan model dengan memperhatikan data pelatihan tambahan (titik H dan E), yaitu dengan merumuskan pengertian umum keyakinan model dalam serangkaian contoh: seberapa yakin model itu semua data, dengan mana dia bekerja dapat diklasifikasikan dengan benar? Atau apakah dia menemukan contoh yang tidak sesuai dengan pemahamannya saat ini? Berdasarkan hal ini, kami telah menambahkan fungsi kerugian yang membawa tingkat kepercayaan model mendekati 100% di semua area ruang embedding, menghasilkan kualitas dan akurasi memori yang lebih baik untuk model kami .
Perubahan yang disebutkan di atas, khususnya augmentasi dan kombinasi data pelatihan, memungkinkan model jaringan saraf yang digunakan dalam penelusuran Google untuk mengenali lagu yang dinyanyikan. Sistem saat ini mencapai tingkat akurasi yang tinggi berdasarkan basis data lebih dari setengah juta lagu yang terus kami perbarui. Koleksi lagu ini memiliki ruang untuk berkembang, dengan lebih banyak musik dari seluruh dunia yang akan datang.
Untuk menguji fitur ini, buka versi terbaru Google app, klik ikon mikrofon dan ucapkan "Lagu apa ini" atau klik "Temukan lagu". Sekarang Anda bisa bersenandung atau bersiul melodi! Kami berharap Hum to Search akan membantu Anda menyingkirkan melodi yang obsesif atau sekadar mencari dan mendengarkan trek tanpa memasukkan namanya.