
Chatbots sekarang banyak digunakan di berbagai area bisnis. Misalnya, bank dapat menggunakannya untuk mengoptimalkan pekerjaan pusat kontak mereka, langsung menjawab pertanyaan pelanggan populer dan memberi mereka informasi referensi. Bagi pelanggan, chatbot juga merupakan alat yang nyaman: menulis pertanyaan dalam obrolan jauh lebih mudah daripada menunggu jawaban dengan menelepon pusat kontak.
Di area lain, chatbots juga berfungsi dengan baik: dalam bidang kedokteran, mereka dapat mewawancarai pasien, menyampaikan gejala ke spesialis, dan membuat janji dengan dokter untuk menegakkan diagnosis. Di perusahaan logistik, bot obrolan akan membantu Anda menyetujui tanggal pengiriman, mengubah alamat, dan memilih titik penjemputan yang nyaman. Di toko online besar, bot obrolan telah mengambil alih sebagian pemeliharaan pesanan, dan di bidang layanan berbagi mobil, bot obrolan melakukan hingga 90% tugas operator. Namun, bot obrolan belum dapat menyelesaikan keluhan. Umpan balik negatif dan situasi kontroversial masih berada di pundak operator dan spesialis.
Jadi, sebagian besar bisnis yang sedang berkembang sudah secara aktif menggunakan chatbot untuk bekerja dengan pelanggan. Namun, manfaat menerapkan chatbot sering kali bervariasi: di beberapa perusahaan tingkat otomatisasi mencapai 90%, di perusahaan lain hanya 30-40%. Tergantung pada apa? Seberapa baik metrik ini untuk bisnis? Apakah ada cara untuk meningkatkan otomatisasi chatbot? Artikel ini akan membahas pertanyaan yang akan membantu Anda memahami hal ini.
Pembandingan
Saat ini, hampir setiap area bisnis memiliki lingkungan kompetitifnya sendiri. Banyak perusahaan mengambil pendekatan bisnis serupa. Oleh karena itu, jika perusahaan pesaing menggunakan bot obrolan dalam aktivitasnya, maka sangat disarankan untuk membandingkannya. Benchmarking adalah alat perbandingan yang baik.
Dalam kasus kami, pembandingan chatbot akan melibatkan penelitian rahasia untuk membandingkan fungsionalitas chatbot pesaing dengan fungsionalitas chatbot Anda sendiri. Mari kita pertimbangkan kasus menggunakan bot obrolan bank sebagai contoh.
Misalkan bank telah mengembangkan chatbot untuk mengoptimalkan pengoperasian pusat kontak dan mengurangi biaya pemeliharaannya. Untuk melakukan benchmarking, perlu dilakukan analisis terhadap bank lain dan mengidentifikasi chatbot yang paling fungsional dari kompetitornya.
Diperlukan untuk membentuk daftar pertanyaan untuk verifikasi (setidaknya 50 pertanyaan dibagi menjadi beberapa topik):
- Pertanyaan tentang layanan perbankan , misalnya: "Berapa tarif deposit Anda?", "Bagaimana cara menerbitkan ulang kartu?" dll.
- Informasi referensi , misalnya: "Berapa nilai tukar saat ini?", "Bagaimana cara mendapatkan liburan kredit?" dll.
- Tingkat pemahaman klien. (Ketahanan bot terhadap kesalahan ketik, kesalahan, persepsi ucapan sehari-hari), misalnya: "Saya membuka kartu, apa yang saya lakukan?", "Isi ulang ponsel", dll.
- Percakapan tentang topik abstrak , misalnya: "Ceritakan lelucon", "Apa yang harus dilakukan selama isolasi diri?" dll.
Catatan: topik pertanyaan ini diberikan sebagai contoh dan dapat diperluas atau diubah.
Ini adalah pertanyaan yang harus Anda tanyakan pada chatbot Anda serta chatbot pesaing Anda. Setelah menulis pertanyaan, 3 opsi untuk hasil dimungkinkan (tergantung pada hasil, skor yang sesuai diberikan):
- bot tidak mengenali pertanyaan pelanggan (0 poin);
- bot mengenali pertanyaan klien, tetapi hanya setelah mengklarifikasi pertanyaan (0,5 poin);
- bot mengenali pertanyaan itu pada percobaan pertama (1 poin).
Jika chatbot mentransfer klien ke operator, maka pertanyaannya juga dianggap tidak dikenal (0 poin).
Selanjutnya, jumlah poin yang dicetak oleh setiap chatbot dijumlahkan, setelah itu bagian dari pertanyaan yang dikenali dengan benar pada setiap topik dihitung (rendah - kurang dari 40%, sedang - dari 40 hingga 80%, tinggi - lebih dari 80%), dan peringkat akhir disusun. Hasilnya dapat disajikan dalam bentuk tabel:
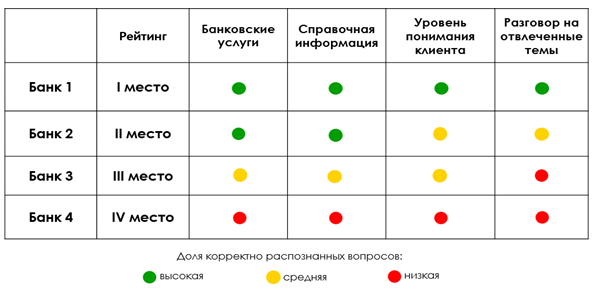
Misalkan, berdasarkan hasil benchmarking, chatbot bank menempati urutan kedua. Kesimpulan apa yang bisa ditarik? Hasilnya bukan yang terbaik, tapi juga bukan yang terburuk. Berdasarkan tabel tersebut, kita dapat mengatakan bahwa ini bukan sisi terkuatnya: pertama, algoritme perlu ditingkatkan untuk mengenali pertanyaan klien dengan benar (chatbot tidak selalu memahami pertanyaan klien yang berisi kesalahan dan kesalahan ketik), dan juga tidak selalu mendukung dialog tentang topik abstrak ... Perbedaan yang lebih detail dapat dilihat saat membandingkan dengan chatbot peringkat pertama.
Chatbot, yang menempati posisi ketiga, berkinerja lebih buruk: pertama, memerlukan revisi serius dari basis pengetahuan tentang layanan perbankan dan informasi referensi, dan kedua, kurang terlatih untuk berdialog dengan klien tentang topik abstrak. Jelas bahwa tingkat otomatisasi chatbot semacam itu berada pada level yang lebih rendah dibandingkan dengan pesaing yang menempati posisi I dan II.
Dengan demikian, berdasarkan hasil benchmarking tersebut, diketahui kekuatan dan kelemahan dalam kerja chat bot, serta dibuat perbandingan chat bot yang saling bersaing satu sama lain. Langkah selanjutnya adalah mengidentifikasi area masalah ini. Bagaimana ini bisa dicapai? Mari pertimbangkan beberapa pendekatan berdasarkan analisis data: AutoML, Process-mining, DE-approach.
AutoML
Saat ini, kecerdasan buatan telah merambah dan terus merambah banyak bidang bisnis, yang tentunya memerlukan peningkatan permintaan akan kompetensi di bidang DataScience. Namun, permintaan akan spesialis tersebut tumbuh lebih cepat dari tingkat keahlian mereka. Faktanya adalah bahwa pengembangan model pembelajaran mesin membutuhkan banyak sumber daya dan tidak hanya membutuhkan banyak pengetahuan dari seorang spesialis, tetapi juga banyak waktu yang dihabiskan untuk membangun model dan membandingkannya. Untuk mengurangi tekanan yang diciptakan oleh kelangkaan, serta mengurangi waktu untuk mengembangkan model, banyak perusahaan mulai membuat algoritme yang dapat mengotomatiskan pekerjaan DataScientists. Algoritme semacam itu disebut AutoML.
AutoML, juga dikenal sebagai pembelajaran mesin otomatis, membantu DataScientist mengotomatiskan tugas yang memakan waktu dan berulang untuk mengembangkan model pembelajaran mesin sambil menjaga kualitasnya. Meskipun model AutoML dapat menghemat waktu Anda, model tersebut hanya akan efektif jika masalah yang diselesaikannya terus-menerus dan berulang. Dalam kondisi ini, model AutoML bekerja dengan baik dan menunjukkan hasil yang dapat diterima.
Sekarang mari kita gunakan AutoML untuk menyelesaikan masalah kita: identifikasi area masalah dalam pekerjaan bot obrolan. Seperti disebutkan di atas, chatbot adalah robot, atau program khusus. Dia tahu cara mengekstrak kata kunci dari pesan dan mencari jawaban yang sesuai di database-nya. Mencari jawaban yang benar itu satu hal, yang lainnya adalah menjaga dialog logis, meniru komunikasi dengan orang sungguhan. Proses ini bergantung pada seberapa baik skrip chatbot tersebut.
Bayangkan situasi ketika klien memiliki pertanyaan, dan chatbot menjawabnya dengan aneh, tidak logis, atau secara umum tentang topik lain. Akibatnya, klien tidak puas dengan jawaban seperti itu, dan paling baik menulis tentang kesalahpahamannya tentang jawabannya, paling buruk - pesan negatif terhadap chatbot. Oleh karena itu, tugas AutoML adalah mengidentifikasi dialog negatif dari jumlah total (berdasarkan log chatbot yang diturunkan dari database), setelah itu perlu untuk mengidentifikasi skenario mana yang terkait dengan dialog ini. Hasil yang didapat akan menjadi dasar penyempurnaan skenario tersebut.
Pertama, mari kita tandai dialog klien dengan chatbot. Dalam setiap dialog, kami hanya menyisakan pesan dari klien. Jika di pesan klien ada yang negatif ke arah chatbot, atau tidak mengerti jawabannya, setel flag = 1, di kasus lain = 0:

Menandai pesan dari klien
Selanjutnya, kita mendeklarasikan model AutoML, melatihnya pada data yang di-markup, dan menyimpannya (semua parameter model yang diperlukan juga diteruskan, tetapi tidak ditampilkan pada contoh di bawah).
automl = saa.AutoML
res_df, feat_imp = automl.train('test.csv', 'test_preds.csv', 'classification', cache_dir = 'tmp_dir', use_ids = False)
automl.save('prec')Kami memuat model yang dihasilkan, setelah itu kami memprediksi variabel target untuk file pengujian:
automl = saa.AutoML
automl.load('text_model.pkl')
preds_df, score, res_df = automl.predict('test.csv', 'test_preds.csv', cache_dir = 'tmp_dir')
preds_df.to_csv('preds.csv', sep=',', index=False)Selanjutnya, kami mengevaluasi model yang dihasilkan:
test_df = pd.read_csv('test.csv')
threshold = 0.5
am_test = preds_df['prediction'].copy()
am_test.loc[am_test>=threshold] = 1
am_test.loc[am_test<threshold] = 0
clear_output()
print_result(test_df[target_col], am_test.apply(int))Matriks kesalahan yang dihasilkan:

Dalam proses pembuatan model, kami mencoba meminimalkan kesalahan tipe 1 (mengklasifikasikan dialog yang baik sebagai dialog yang buruk), oleh karena itu, untuk pengklasifikasi yang dihasilkan, kami berhenti pada ukuran f1 yang sama dengan 0,66. Dengan bantuan model yang terlatih, dimungkinkan untuk mengidentifikasi 65 ribu sesi "buruk", yang, pada gilirannya, memungkinkan untuk mengidentifikasi 7 skenario yang kurang efektif.
Proses Penambangan
Untuk mengidentifikasi skenario bermasalah, kami juga dapat menggunakan alat berdasarkan Process Mining - nama umum untuk sejumlah metode dan pendekatan yang dirancang untuk menganalisis dan meningkatkan proses dalam sistem informasi atau proses bisnis berdasarkan studi log peristiwa.
Dengan menggunakan metode ini, kami dapat mengidentifikasi 7 skenario yang terlibat dalam dialog yang panjang dan tidak efektif:
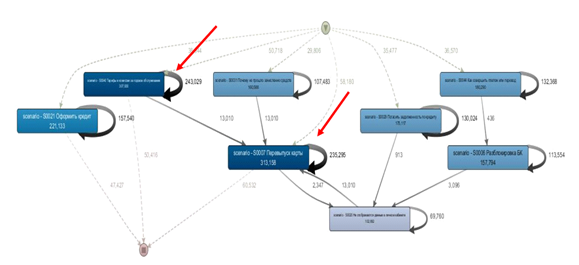
18% dialog memiliki lebih dari 4 pesan dari chatbot.
Setiap elemen pada grafik di atas adalah sebuah skenario. Seperti yang Anda lihat dari gambar, skrip diulang, dan panah perulangan yang tebal menunjukkan dialog yang agak panjang antara klien dan chatbot.
Selanjutnya, untuk menemukan skenario buruk, kami menyiapkan kumpulan data terpisah, dan membuat grafik berdasarkan itu. Untuk melakukan ini, hanya dialog yang tersisa di mana tidak ada akses ke operator, setelah itu mereka memfilter dialog dengan masalah yang belum terselesaikan. Hasilnya, kami mengidentifikasi 5 skenario untuk perbaikan, di mana chatbot tidak menyelesaikan pertanyaan klien.
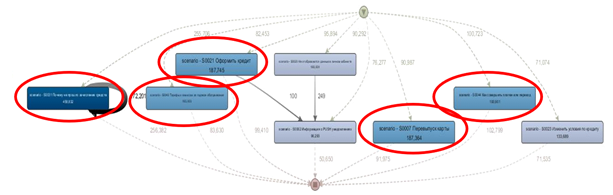
Skenario yang teridentifikasi muncul di sekitar 15% dari semua dialog
Pendekatan DE (Data Engineering)
Pendekatan analitik sederhana juga digunakan untuk mencari skenario masalah: dialog diidentifikasi, peringkat umpan balik di mana (dari sisi klien) berkisar dari 1 hingga 7 poin, kemudian skenario yang paling umum dalam sampel ini dipilih.
Misalnya, menggunakan pendekatan berdasarkan AutoML, Process Mining, dan DE secara komprehensif, kami mengidentifikasi area masalah di chatbot perusahaan yang perlu ditingkatkan.
Sekarang chatbot menjadi lebih baik!