Memantau endpoint dan API internal Kubernetes bisa menjadi masalah, terutama jika tujuannya adalah untuk memanfaatkan infrastruktur otomatis sebagai layanan. Kami di Smarkets belum mencapai tujuan ini, tetapi untungnya, kami sudah cukup dekat dengannya. Saya berharap pengalaman kami di bidang ini akan membantu orang lain untuk menerapkan hal serupa.
Kami selalu bermimpi bahwa pengembang akan dapat memantau aplikasi atau layanan apa pun secara langsung. Sebelum pindah ke Kubernetes, tugas ini dilakukan baik menggunakan metrik Prometheus atau menggunakan statsd, yang mengirimkan statistik ke host yang mendasarinya, yang kemudian diubah menjadi metrik Prometheus. Saat kami terus memanfaatkan Kubernetes, kami mulai memisahkan cluster, dan kami ingin membuatnya sehingga developer dapat mengekspor metrik langsung ke Prometheus melalui anotasi layanan. Sayangnya, metrik ini hanya tersedia dalam kluster, sehingga tidak dapat dikumpulkan secara global.
Batasan ini adalah hambatan untuk konfigurasi pra-Kubernetes kami. Pada akhirnya, mereka terpaksa memikirkan kembali arsitektur dan cara layanan pemantauan. Perjalanan ini akan dibahas di bawah.
Titik awal
Untuk metrik terkait Kubernetes, kami menggunakan dua layanan yang menyediakan metrik:
-
kube-state-metricsmenghasilkan metrik untuk objek Kubernetes berdasarkan informasi dari server API K8s; -
kube-eaglemengekspor metrik Prometheus untuk pod: permintaan, batas, penggunaan mereka.
Dimungkinkan (dan untuk beberapa waktu kami telah melakukan ini) untuk mengekspos layanan dengan metrik di luar cluster atau membuka koneksi proxy ke API, tetapi kedua opsi itu tidak ideal, karena mereka memperlambat pekerjaan dan tidak memberikan kemandirian dan keamanan sistem yang diperlukan.
Biasanya, solusi pemantauan diterapkan, yang terdiri dari cluster pusat server Prometheus yang berjalan di dalam Kubernetes dan mengumpulkan metrik dari platform itu sendiri, serta metrik Kubernetes internal dari cluster ini. Alasan utama kami memilih pendekatan ini adalah karena selama transisi ke Kubernetes, kami mengumpulkan semua layanan dalam cluster yang sama. Setelah menambahkan cluster Kubernetes tambahan, arsitektur kami terlihat seperti ini:
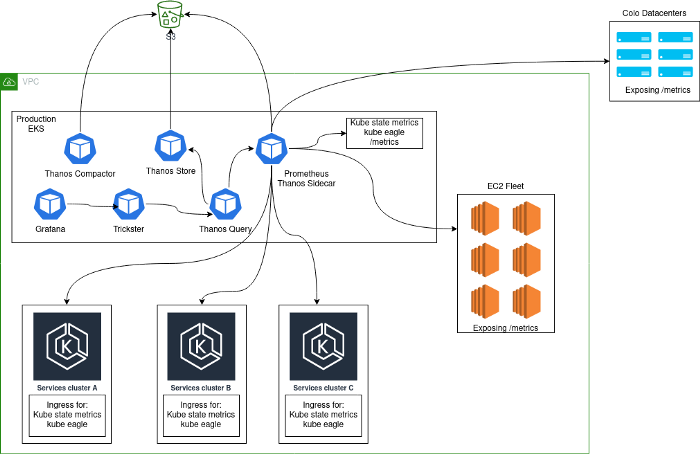
Masalah
Arsitektur seperti itu tidak dapat disebut stabil, efisien, atau produktif: bagaimanapun juga, pengguna dapat mengekspor metrik statsd dari aplikasi, yang menyebabkan kardinalitas yang sangat tinggi dari beberapa metrik. Anda mungkin akrab dengan masalah seperti ini jika urutan besarnya tidak asing lagi.
Saat menganalisis blok Prometheus 2 jam:
- 1,3 juta metrik;
- 383 nama label;
- kardinalitas maksimum per metrik adalah 662.000 (sebagian besar masalah justru disebabkan oleh hal ini).
Kardinalitas tinggi ini terutama disebabkan oleh eksposur pengatur waktu statsd yang menyertakan jalur HTTP. Kami tahu ini tidak ideal, tetapi metrik ini digunakan untuk melacak bug kritis dalam penerapan canary.
Di masa tenang, sekitar 40.000 metrik dikumpulkan per detik, tetapi jumlahnya dapat bertambah hingga 180.000 jika tidak ada masalah.
Beberapa kueri khusus untuk metrik berkardinalitas tinggi menyebabkan Prometheus (dapat diprediksi) kehabisan memori - situasi yang sangat membuat frustrasi ketika (Prometheus) digunakan untuk memperingatkan dan mengevaluasi penerapan canary.
Masalah lainnya adalah bahwa dengan tiga bulan data yang disimpan di setiap instance Prometheus, waktu startup (replay WAL) sangat tinggi, dan ini biasanya mengakibatkan permintaan yang sama dialihkan ke instance Prometheus kedua dan " menjatuhkannya.
Untuk memperbaiki masalah ini, kami telah menerapkan Thanos dan Trickster:
- Thanos mengizinkan lebih sedikit data untuk disimpan di Prometheus dan mengurangi jumlah insiden yang disebabkan oleh penggunaan memori yang berlebihan. Di samping kontainer, Prometheus Thanos meluncurkan kontainer bantuan yang menyimpan blok data di S3, di mana thanos-compact kemudian mengompresnya. Karenanya, dengan bantuan Thanos, penyimpanan data jangka panjang di luar Prometheus dilaksanakan.
- Trickster, pada bagiannya, bertindak sebagai reverse proxy dan cache untuk database deret waktu. Itu memungkinkan kami untuk menyimpan hingga 99,53% dari semua permintaan. Sebagian besar permintaan datang dari dasbor yang berjalan di workstation / TV, dari pengguna dengan panel kontrol terbuka, dan dari peringatan. Proksi yang hanya dapat mengeluarkan delta dalam deret waktu sangat bagus untuk jenis beban kerja ini.
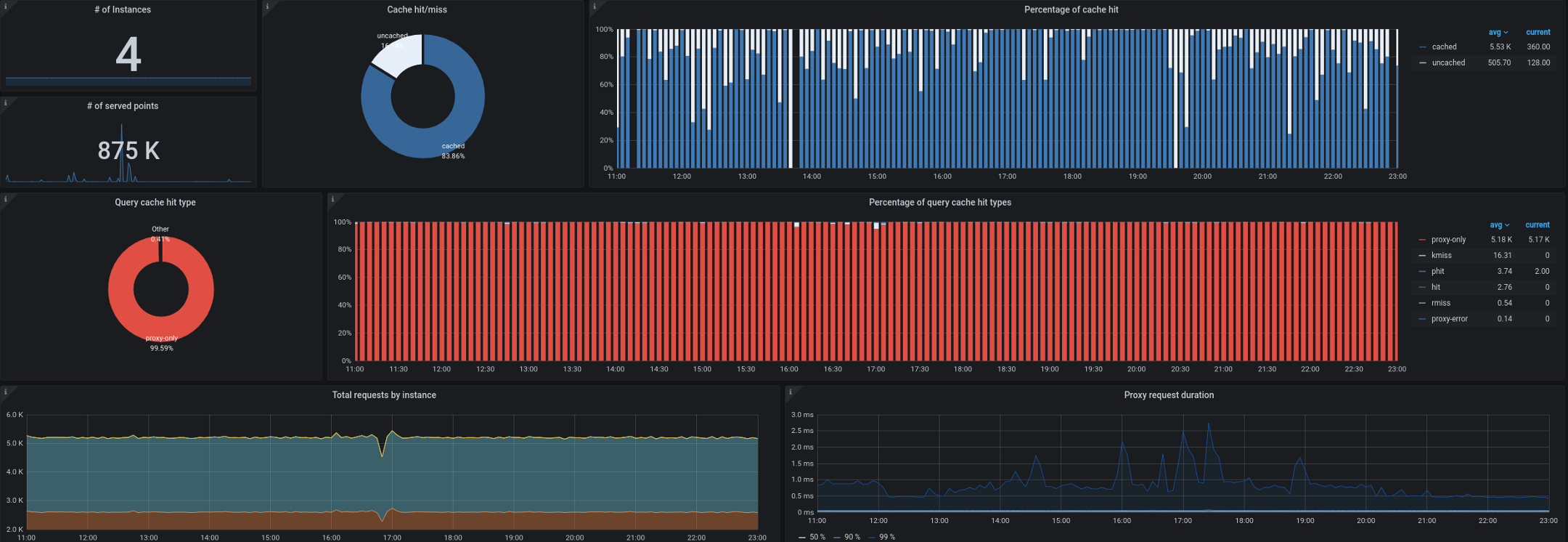
Kami juga mulai mengalami masalah saat mengumpulkan kube-state-metrics dari luar cluster. Seperti yang Anda ingat, kami sering kali harus memproses hingga 180.000 metrik per detik, dan pengumpulannya melambat bahkan saat 40.000 metrik disetel dalam satu metrik status kube masuk. Kami memiliki interval 10 detik target untuk mengumpulkan metrik, dan selama periode beban tinggi SLA ini sering dilanggar oleh pengumpulan jarak jauh kube-state-metrics atau kube-eagle.
Pilihan
Sambil memikirkan tentang cara meningkatkan arsitektur, kami melihat tiga opsi berbeda:
- Prometheus + Cortex ( https://github.com/cortexproject/cortex );
- Prometheus + Thanos Receive ( https://thanos.io );
- Prometheus + VictoriaMetrics ( https://github.com/VictoriaMetrics/VictoriaMetrics ).
Informasi terperinci tentang mereka dan perbandingan karakteristik dapat ditemukan di Internet. Dalam kasus khusus kami (dan setelah pengujian pada data dengan kardinalitas tinggi) VictoriaMetrics adalah pemenang yang jelas.
Keputusan
Prometheus
Dalam upaya meningkatkan arsitektur yang dijelaskan di atas, kami memutuskan untuk mengisolasi setiap cluster Kubernetes sebagai entitas terpisah dan menjadikan Prometheus bagian darinya. Sekarang setiap cluster baru hadir dengan pemantauan yang disertakan "di luar kotak" dan metrik yang tersedia di dasbor global (Grafana). Untuk ini, layanan kube-eagle, kube-state-metrics, dan Prometheus telah diintegrasikan ke dalam cluster Kubernetes. Prometheus kemudian dikonfigurasi dengan label eksternal untuk mengidentifikasi cluster dan
remote_writediarahkan ke insertVictoriaMetrics (lihat di bawah).
VictoriaMetrics
VictoriaMetrics Time Series Database mengimplementasikan protokol Graphite, Prometheus, OpenTSDB dan Influx. Ini tidak hanya mendukung PromQL, tetapi juga menambahkan fitur dan templat baru ke dalamnya, menghindari pemfaktoran ulang kueri Grafana. Plus, kinerjanya luar biasa.
Kami menerapkan VictoriaMetrics dalam mode cluster dan membaginya menjadi tiga komponen terpisah:
1. Penyimpanan VictoriaMetrics (vmstorage)
Komponen ini bertanggung jawab untuk menyimpan data yang diimpor
vminsert. Kami membatasi diri kami pada tiga replika komponen ini, digabungkan menjadi sebuah StatefulSet Kubernetes.
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
VictoriaMetrics memasukkan (vminsert)
Komponen ini menerima data dari penerapan dengan Prometheus dan meneruskannya ke
vmstorage. Parameter replicationFactor=2mereplikasi data ke dua dari tiga server. Jadi, jika salah satu instance vmstoragemengalami masalah atau dimulai ulang, masih ada satu salinan data yang tersedia.
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics pilih (vmselect)
Menerima permintaan PromQL dari Grafana (Trickster) dan meminta data mentah dari
vmstorage. Saat ini, kami telah menonaktifkan cache ( search.disableCache), karena arsitekturnya berisi Trickster, yang bertanggung jawab untuk menyimpan cache; oleh karena itu, harus vmselectselalu mengambil data lengkap terbaru.
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
Gambar besar
Implementasi saat ini terlihat seperti ini:
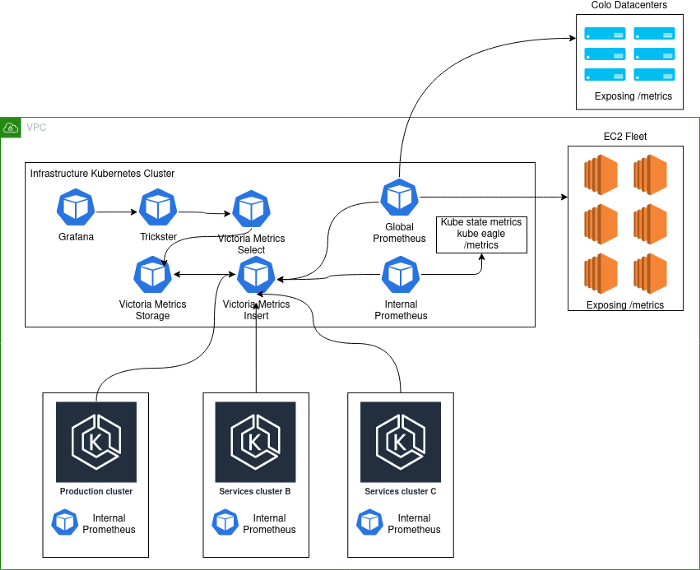
Catatan Skema:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
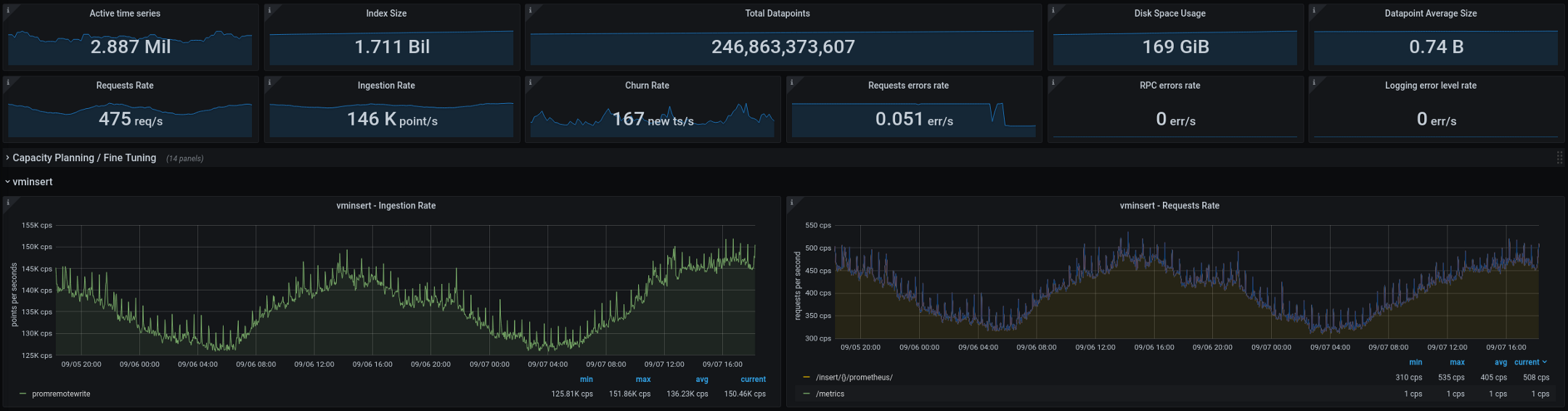
Di bawah ini adalah metrik yang saat ini sedang diproses oleh VictoriaMetrics (total dua minggu, grafik menunjukkan jeda dua hari): Arsitektur baru berkinerja baik setelah ditransfer ke produksi. Pada konfigurasi lama, kami memiliki dua atau tiga "ledakan" kardinalitas setiap beberapa minggu, pada konfigurasi baru jumlahnya turun menjadi nol. Ini adalah indikator yang bagus, tetapi ada beberapa hal lagi yang kami rencanakan untuk ditingkatkan dalam beberapa bulan mendatang:
- Kurangi kardinalitas metrik dengan meningkatkan integrasi statsd.
- Bandingkan caching di Trickster dan VictoriaMetrics - Anda perlu mengevaluasi dampak setiap solusi terhadap efisiensi dan kinerja. Ada kecurigaan bahwa Trickster bisa ditinggalkan sama sekali tanpa kehilangan apapun.
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
Jika Anda memiliki saran atau ide untuk perbaikan yang diuraikan di atas, silakan hubungi kami . Jika Anda sedang bekerja untuk meningkatkan pemantauan Kubernetes, kami harap artikel ini, yang menjelaskan perjalanan sulit kami, dapat membantu.
PS dari penerjemah
Baca juga di blog kami:
- " Masa depan Prometheus dan ekosistem proyek (2020) ";
- " Monitoring dan Kubernetes " (ulasan dan laporan video);
- " Perangkat dan mekanisme Operator Prometheus di Kubernetes ."