Prolog
Mari kita mulai dengan pemrograman logika dan bahasa Prolog. Pengetahuan tentang bidang pelajaran disajikan di dalamnya sebagai sekumpulan fakta dan aturan. Fakta menggambarkan pengetahuan langsung. Fakta-fakta tentang pelanggan (ID, nama dan alamat email) dan invoice (ID akun, pelanggan, tanggal, jumlah jatuh tempo dan jumlah yang dibayarkan) dari contoh posting sebelumnya akan terlihat seperti ini
client(1, "John", "john@somewhere.net").
bill(1, 1,"2020-01", 100, 50).Aturan menggambarkan pengetahuan abstrak yang dapat disimpulkan dari aturan dan fakta lain. Aturannya terdiri dari kepala dan badan. Di bagian atas aturan, Anda perlu menentukan namanya dan daftar argumen. Badan aturan adalah daftar predikat yang dihubungkan dengan operasi logika AND (ditentukan dengan koma) dan OR (ditentukan dengan titik koma). Predikat dapat berupa fakta, aturan, atau predikat bawaan, seperti operasi perbandingan, operasi aritmatika, dll. Hubungan antara argumen kepala aturan dan argumen predikat dalam tubuhnya diatur menggunakan variabel boolean - jika variabel yang sama berada pada posisi dua argumen berbeda, Artinya, argumen ini identik. Aturan dianggap benar jika ekspresi logis dari badan aturan adalah benar. Model domain dapat didefinisikan sebagai sekumpulan aturan referensi:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid.
debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).Kami telah menetapkan dua aturan. Di bagian pertama, kami menegaskan bahwa semua faktur yang kurang dari jumlah jatuh tempo adalah faktur yang belum dibayar. Kedua, debitur adalah klien yang memiliki setidaknya satu faktur yang belum dibayar.
Sintaks Prolog sangat sederhana: elemen utama program adalah aturan, elemen utama aturan adalah predikat, operasi logis, dan variabel. Dalam aturan tersebut, perhatian difokuskan pada variabel - mereka memainkan peran sebagai objek dunia model, dan predikat menggambarkan properti dan hubungan di antara mereka. Dalam definisi aturan debitur, kami menyatakan bahwa jika ClientId, Name, dan objek Email terkait dengan klien dan hubungan unpaidBill, maka mereka juga akan dikaitkan dengan hubungan debitur. Prolog berguna ketika masalah dirumuskan sebagai seperangkat aturan, pernyataan atau pernyataan logis. Misalnya, saat bekerja dengan tata bahasa alami, kompiler, dalam sistem pakar, saat menganalisis sistem yang kompleks seperti komputer, jaringan komputer, objek infrastruktur. Kompleks,Sistem aturan yang berbelit-belit paling baik dijelaskan secara eksplisit dan diserahkan kepada runtime Prolog untuk menanganinya secara otomatis.
Prolog didasarkan pada logika orde pertama (dengan beberapa elemen logika orde tinggi disertakan). Inferensi dilakukan menggunakan prosedur yang disebut resolusi SLD (resolusi klausa Selektif Linear Definite). Sederhananya, algoritmanya adalah traversal pohon dari semua solusi yang mungkin. Prosedur inferensi menemukan semua solusi untuk predikat pertama badan aturan. Jika predikat saat ini dalam basis pengetahuan diwakili hanya oleh fakta, maka solusinya adalah yang sesuai dengan ikatan variabel saat ini dengan nilai. Jika menurut aturan, maka pemeriksaan rekursif dari predikat bersarangnya diperlukan. Jika tidak ada solusi yang ditemukan, maka cabang pencarian saat ini gagal. Kemudian cabang baru dibuat untuk setiap solusi parsial yang ditemukan. Di setiap cabang, prosedur inferensi mengikat nilai yang ditemukan ke variabel,disertakan dalam predikat saat ini, dan secara rekursif mencari solusi untuk daftar predikat yang tersisa. Pekerjaan berakhir ketika akhir daftar predikat tercapai. Pencarian solusi bisa memasuki loop tanpa akhir jika aturan didefinisikan secara rekursif. Hasil dari prosedur pencarian adalah daftar semua kemungkinan binding nilai ke variabel boolean.
Dalam contoh di atas untuk aturan debitur, aturan resolusi pertama-tama akan menemukan satu solusi untuk predikat klien dan mengaitkannya dengan boolean: ClientId = 1, Name = "John", Email = "john@somewhere.net". Kemudian, untuk varian nilai variabel ini, solusi akan dilakukan untuk predikat unpaidBill berikutnya. Untuk melakukan ini, pertama-tama Anda perlu mencari solusi untuk tagihan predikat, asalkan ClientId = 1. Hasilnya adalah binding untuk variabel BillId = 1, Date = "2020-01", AmoutToPay = 100, AmountPaid = 50. Pada akhirnya, AmoutToPay <AmountPaid akan dicentang dalam predikat perbandingan bawaan.
Jaringan semantik
Salah satu cara paling populer untuk merepresentasikan pengetahuan adalah jaringan semantik. Semantic Web adalah model informasi dari domain dalam bentuk grafik berarah. Simpul dari grafik sesuai dengan konsep domain, dan busur menentukan hubungan di antara keduanya.
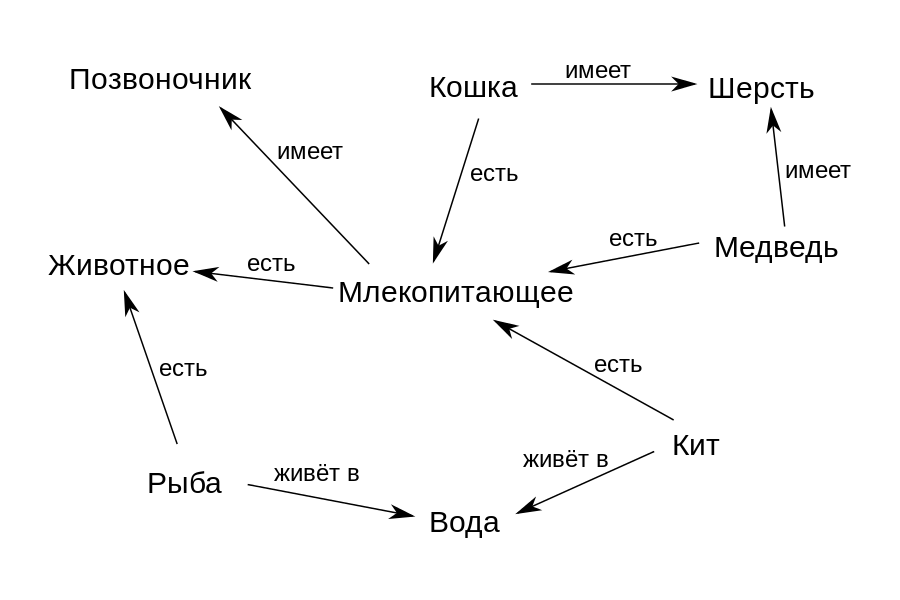
Misalnya menurut grafik pada gambar di atas, konsep "Paus" dikaitkan dengan hubungan "sedang" ("ada") dengan konsep "Mamalia" dan "tinggal di" dengan konsep "Air". Dengan demikian, kami dapat secara formal mengatur struktur bidang subjek - konsep apa yang termasuk dan bagaimana mereka terkait satu sama lain. Dan kemudian grafik semacam itu dapat digunakan untuk menemukan jawaban atas pertanyaan dan memperoleh pengetahuan baru darinya. Sebagai contoh, kita dapat menyimpulkan pengetahuan bahwa Paus memiliki "Spine" jika kita memutuskan bahwa relasi "adalah" menunjukkan hubungan kelas-subkelas, dan subkelas "Paus" harus mewarisi semua properti kelasnya "Mamalia".
RDF
Web semantik adalah upaya membangun jaringan semantik global berdasarkan sumber daya World Wide Web dengan standarisasi penyajian informasi dalam bentuk yang sesuai untuk pemrosesan mesin. Untuk ini, informasi juga disematkan di halaman HTML dalam bentuk atribut khusus dari tag HTML, yang memungkinkan untuk mendeskripsikan makna kontennya dalam bentuk ontologi - sekumpulan fakta, konsep abstrak, dan hubungan di antara mereka.
Pendekatan standar untuk menggambarkan model semantik sumber daya WEB adalah RDF (Resource Description Framework atau Resource Description Framework). Menurutnya, semua pernyataan harus berbentuk triplet "subjek - predikat - objek". Misalnya, pengetahuan tentang konsep "Paus" akan direpresentasikan sebagai berikut: "Paus" adalah subjek, "tinggal di" - predikat, "Air" - objek. Seluruh rangkaian pernyataan seperti itu dapat dijelaskan menggunakan grafik terarah, subjek dan objek adalah simpulnya, dan predikatnya adalah busur, busur predikat diarahkan dari objek ke subjek. Misalnya, contoh ontologi dari hewan dapat dijelaskan sebagai berikut:
@prefix : <...some URL...>
@prefix rdf: <http://www.w3.org/1999/02/rdf-schema#>
@prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#>
:Whale rdf:type :Mammal;
:livesIn :Water.
:Fish rdf:type :Animal;
:livesIn :Water.Notasi ini disebut Turtle dan dimaksudkan agar dapat dibaca oleh manusia. Tetapi hal yang sama dapat ditulis dalam format XML, JSON atau menggunakan tag dan atribut dari dokumen HTML. Meskipun dalam notasi Turtle, predikat dan objek dapat dikelompokkan bersama berdasarkan subjek agar mudah dibaca, pada tingkat semantik setiap triplet bersifat independen.
RDF berguna dalam kasus di mana model datanya kompleks dan berisi banyak tipe objek dan hubungan di antara mereka. Misalnya, Wikipedia menyediakan akses ke konten artikelnya dalam format RDF. Fakta-fakta yang dijelaskan dalam artikel terstruktur, properti dan hubungannya dijelaskan, termasuk fakta dari artikel lain.
RDFS
Model RDF adalah grafik; secara default, tidak ada semantik tambahan yang disertakan di dalamnya. Setiap orang dapat menafsirkan tautan dalam grafik sesuai keinginan mereka. Anda dapat menambahkan beberapa tautan standar ke sana menggunakan Skema RDF - sekumpulan kelas dan properti untuk membangun ontologi di atas RDF. RDFS memungkinkan Anda untuk mendeskripsikan hubungan standar antar konsep, seperti milik sumber daya ke kelas tertentu, hierarki antar kelas, hierarki properti, dan untuk membatasi kemungkinan jenis subjek dan objek.
Misalnya, pernyataan
:Mammal rdfs:subClassOf :Animal.menentukan bahwa "Mamalia" adalah subkelas dari konsep "Hewan" dan mewarisi semua propertinya. Sejalan dengan itu, konsep "Paus" juga dapat dikaitkan dengan kelas "Hewan". Tapi untuk ini perlu ditunjukkan bahwa konsep "Mamalia" dan "Hewan" adalah kelas:
:Animal rdf:type rdfs:Class.
:Mammal rdf:type rdfs:Class.Selain itu, predikat dapat ditetapkan sebagai batasan pada nilai yang mungkin dari subjek dan objeknya.
Pernyataan
:livesIn rdfs:range :Environment.menunjukkan bahwa objek dari hubungan "tinggal di" harus selalu menjadi sumber daya milik kelas "Lingkungan". Oleh karena itu, kita harus menambahkan pernyataan bahwa konsep "Air" merupakan subkelas dari konsep "Lingkungan":
:Water rdf:type :Environment.
:Environment rdf:type rdfs:ClassRDFS memungkinkan Anda untuk menjelaskan skema data - untuk menghitung kelas, properti, mengatur hierarki dan batasan pada nilainya. Dan RDF akan mengisi skema ini dengan fakta-fakta konkret dan mendefinisikan hubungan di antara mereka. Sekarang kita bisa bertanya tentang grafik ini. Ini dapat dilakukan dalam bahasa kueri khusus SPARQL, yang menyerupai SQL:
SELECT ?creature
WHERE {
?creature rdf:type :Animal;
:livesIn :Water.
} Kueri ini akan mengembalikan kita 2 nilai: "Whale" dan "Fish".
Contoh dari publikasi sebelumnya dengan akun dan pelanggan dapat diterapkan kira-kira sebagai berikut. Dengan RDF, Anda dapat mendeskripsikan skema data dan mengisinya dengan nilai:
:Client1 :name "John";
:email "john@somewhere.net".
:Client2 :name "Mary";
:email "mary@somewhere.net".
:Bill_1 :client :Client1;
:date "2020-01";
:amountToPay 100;
:amountPaid 50.
:Bill_2 :client :Client2;
:date "2020-01";
:amountToPay 80;
:amountPaid 80.Tetapi konsep abstrak seperti "Debitur" dan "Tagihan yang Belum Dibayar" dari artikel pertama dalam seri ini mencakup operasi dan perbandingan aritmatika. Mereka tidak cocok dengan struktur statis dari jaringan konsep semantik. Konsep-konsep ini dapat diekspresikan menggunakan kueri SPARQL:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid
WHERE {
?client :name ?clientName;
:email ?clientEmail.
?bill :client ?client;
:date ?billDate;
:amountToPay ?amountToPay;
:amountPaid ?amountPaid.
FILTER(?amountToPay > ?amountPaid).
}Klausa WHERE adalah daftar pola rangkap tiga dan kondisi filter. Variabel Boolean dapat diganti menjadi triplet, yang namanya diawali dengan "?" Tugas pelaksana kueri adalah menemukan semua kemungkinan nilai variabel yang semua pola tripletnya akan dimuat dalam grafik dan kondisi pemfilteran akan terpenuhi.
Tidak seperti Prolog, di mana aturan dapat digunakan untuk membuat aturan lain, di RDF kueri bukan bagian dari Semantic Web. Permintaan tidak dapat dirujuk sebagai sumber data untuk permintaan lain. Benar, SPARQL memiliki kemampuan untuk merepresentasikan hasil kueri sebagai grafik. Jadi, Anda dapat mencoba menggabungkan hasil kueri dengan grafik asli dan menjalankan kueri baru pada grafik gabungan. Tapi keputusan seperti itu jelas akan melampaui ideologi RDF.
BURUNG HANTU
Komponen penting dari teknologi Semantic Web adalah OWL (Web Ontology Language), bahasa untuk mendeskripsikan ontologi. Dengan kosakata RDFS, Anda hanya dapat mengekspresikan hubungan paling dasar antara konsep - hierarki kelas dan hubungan. OWL menawarkan kosakata yang lebih kaya. Misalnya, Anda dapat menentukan bahwa dua kelas (atau dua entitas) adalah setara (atau berbeda). Tugas ini sering dijumpai saat menggabungkan ontologi.
Anda dapat membuat kelas komposit berdasarkan persimpangan, penyatuan, atau pelengkap kelas lain:
- Saat berpotongan, semua instance kelas komposit juga harus berlaku untuk semua kelas sumber. Misalnya, "Mamalia Laut" harus menjadi "Mamalia" dan "Penghuni Laut" pada saat yang bersamaan.
- . , , «» «», «» «». «».
- , . , «» «».
- . , .
- — , .
Ekspresi yang memungkinkan Anda untuk menghubungkan konsep bersama-sama disebut konstruktor.
OWL juga memungkinkan Anda menyetel banyak properti hubungan penting:
- Transitivitas. Jika relasi P (x, y) dan P (y, z) berlaku, maka relasi P (x, z) juga terpenuhi. Contoh hubungan tersebut adalah "Lebih Banyak" - "Lebih Sedikit", "Orang Tua" - "Anak", dll.
- Simetri. Jika relasi P (x, y) terpenuhi, maka relasi P (y, x) juga terpenuhi. Misalnya, Relative relationship.
- Ketergantungan fungsional. Jika relasi P (x, y) dan P (x, z) berlaku, maka nilai y dan z harus identik. Contohnya adalah hubungan Ayah - seseorang tidak dapat memiliki dua ayah yang berbeda.
- Inversi hubungan. Anda dapat menentukan bahwa jika relasi P1 (x, y) terpenuhi, maka satu relasi lagi P2 (y, x) harus dipenuhi. Contoh dari hubungan tersebut adalah hubungan orang tua-anak.
- Rantai hubungan. Anda dapat mengatur bahwa jika A dikaitkan dengan beberapa properti dengan B, dan B - dengan C, maka A (atau C) milik kelas yang diberikan. Misalnya, jika A memiliki ayah dari B, dan ayah B memiliki ayah C, maka A adalah cucu C.
Anda juga dapat mengatur batasan pada nilai argumen relasi. Misalnya, tentukan bahwa argumen harus selalu dimiliki oleh kelas tertentu, atau bahwa kelas harus memiliki setidaknya satu hubungan dari tipe tertentu, atau batasi jumlah hubungan untuk tipe ini. Atau Anda dapat menentukan bahwa semua contoh yang terkait dengan hubungan tertentu ke nilai yang diberikan milik kelas tertentu.
OWL sekarang menjadi alat standar de facto untuk membangun ontologi. Bahasa ini lebih cocok untuk membangun ontologi yang besar dan kompleks daripada RDFS. Sintaks OWL memungkinkan Anda untuk mengekspresikan properti konsep yang lebih berbeda dan hubungan di antara keduanya. Tapi itu juga memperkenalkan sejumlah batasan tambahan, misalnya, konsep yang sama tidak dapat dideklarasikan secara bersamaan baik sebagai kelas maupun sebagai instance dari kelas lain. Ontologi OWL lebih ketat, lebih terstandarisasi, dan karenanya lebih mudah dibaca. Jika RDFS hanyalah beberapa kelas tambahan di atas grafik RDF, maka OWL memiliki dasar matematika yang berbeda - logika deskripsi. Oleh karena itu, prosedur inferensi formal tersedia yang memungkinkan Anda mengekstrak informasi baru dari ontologi OWL, memeriksa konsistensi, dan menjawab pertanyaan.
Logika deskriptif adalah bagian dari logika orde pertama. Hanya predikat satu tempat (misalnya, konsep milik kelas), predikat dua tempat (konsep memiliki properti dan nilainya), serta konstruktor kelas dan properti hubungan, yang tercantum di atas, diizinkan di dalamnya. Semua ekspresi lain dari logika orde pertama dalam logika deskriptif telah dihapus. Misalnya, pernyataan bahwa konsep "Faktur yang belum dibayar" termasuk dalam kelas "Faktur", konsep "Faktur" memiliki properti "Jumlah yang harus dibayar" dan "Jumlah yang dibayarkan" akan dapat diterima. Tetapi untuk membuat pernyataan bahwa konsep "Faktur yang belum dibayar" properti "Jumlah yang harus dibayar" harus lebih besar dari properti "Jumlah yang dibayarkan" tidak akan berfungsi. Ini membutuhkan aturan yang menyertakan predikat untuk membandingkan properti ini. Sayangnya,Konstruktor OWL tidak mengizinkan Anda melakukan ini.
Jadi, ekspresi logika deskriptif lebih rendah daripada logika orde pertama. Namun di sisi lain, algoritma inferensi dalam logika deskriptif jauh lebih cepat. Selain itu, ia memiliki sifat desidabilitas - solusinya dapat ditemukan dijamin dalam waktu yang terbatas. Diyakini bahwa dalam praktiknya kosakata semacam itu cukup untuk membangun ontologi yang kompleks dan banyak, dan OWL adalah kompromi yang baik antara ekspresi dan efisiensi inferensi.
Yang juga perlu disebutkan adalah SWRL (Semantic Web Rule Language), yang menggabungkan kemampuan untuk membuat kelas dan properti di OWL dengan aturan penulisan dalam versi terbatas bahasa Datalog. Gaya aturan ini sama seperti di Prolog. SWRL mendukung predikat bawaan untuk perbandingan, matematika, string, tanggal, dan manipulasi daftar. Inilah yang kurang kami miliki untuk menerapkan konsep "Faktur yang belum dibayar" dengan bantuan satu ekspresi sederhana.
Flora-2
Sebagai alternatif jaringan semantik, pertimbangkan teknologi seperti bingkai. Bingkai adalah struktur yang menggambarkan objek kompleks, gambar abstrak, model sesuatu. Ini terdiri dari nama, sekumpulan properti (karakteristik) dan nilainya. Nilai properti dapat berupa bingkai lain. Selain itu, properti dapat memiliki nilai default. Fungsi untuk menghitung nilainya dapat dilampirkan ke properti. Bingkai juga dapat mencakup prosedur layanan, termasuk penangan untuk kejadian seperti itu, seperti membuat, menghapus bingkai, mengubah nilai properti, dll. Properti penting dari bingkai adalah kemampuan untuk mewarisi. Bingkai anak mencakup semua properti dari bingkai induk.
Sistem bingkai tertaut membentuk jaringan semantik yang sangat mirip dengan grafik RDF. Namun dalam tugas membuat ontologi, bingkai digantikan oleh OWL, yang sekarang menjadi standar de facto. OWL lebih ekspresif, memiliki dasar teoritis yang lebih maju - logika deskriptif formal. Tidak seperti RDF dan OWL, di mana properti konsep dijelaskan secara terpisah satu sama lain, dalam model bingkai, konsep dan propertinya dianggap sebagai satu kesatuan - bingkai. Jika dalam model RDF dan OWL, simpul dari grafik berisi nama-nama konsep, dan tepinya berisi propertinya, maka dalam model bingkai, simpul dari graf tersebut berisi konsep dengan semua propertinya, dan tepinya berisi hubungan antara propertinya atau relasi pewarisan antar konsep.
Dalam hal ini, model bingkai sangat dekat dengan model pemrograman berorientasi objek. Mereka sebagian besar sama, tetapi memiliki cakupan yang berbeda - bingkai ditujukan untuk memodelkan jaringan konsep dan hubungan di antara mereka, dan OOP - untuk memodelkan perilaku objek, interaksinya satu sama lain. Oleh karena itu, OOP menyediakan mekanisme tambahan untuk menyembunyikan detail implementasi satu komponen dari yang lain, membatasi akses ke metode dan bidang kelas.
Bahasa framing modern (seperti KL-ONE, PowerLoom, Flora-2) menggabungkan tipe data komposit model objek dengan logika orde pertama. Dalam bahasa-bahasa ini, Anda tidak hanya dapat mendeskripsikan struktur objek, tetapi juga beroperasi dengan objek-objek ini dalam aturan, membuat aturan yang menjelaskan kondisi objek yang termasuk dalam kelas tertentu, dll. Mekanisme pewarisan dan komposisi kelas menerima interpretasi logis, yang tersedia untuk digunakan oleh prosedur inferensi. Bahasa-bahasa ini lebih ekspresif daripada OWL dan tidak terbatas pada predikat dua tempat.
Sebagai contoh, mari coba implementasikan contoh kita dengan debitur dalam bahasa Flora-2... Bahasa ini mencakup 3 komponen: logika bingkai logika-F, yang menggabungkan bingkai dan logika orde pertama, logika orde tinggi HiLog, yang menyediakan alat untuk membentuk pernyataan tentang struktur pernyataan lain dan meta-pemrograman, dan logika perubahan Transactional Logic, yang memungkinkan dalam bentuk logis menjelaskan perubahan data dan efek samping perhitungan. Sekarang kita hanya tertarik pada logika frame logika-F . Untuk memulainya, kami akan menggunakannya untuk mendeklarasikan struktur frame yang menjelaskan konsep (kelas) klien dan debitur:
client[|name => \string,
email => \string
|].
bill[|client => client,
date => \string,
amountToPay => \number,
amountPaid => \number,
amountPaid -> 0
|].Sekarang kita dapat mendeklarasikan instance (objek) dari konsep ini:
client1 : client[name -> 'John', email -> 'john@somewhere.net'].
client2 : client[name -> 'Mary', email -> 'mary@somewhere.net'].
bill1 : bill[client -> client1,
date -> '2020-01',
amountToPay -> 100
].
bill2 : bill[client -> client2,
date -> '2020-01',
amountToPay -> 80,
amountPaid -> 80
].Simbol '->' berarti hubungan atribut dengan nilai tertentu dalam objek dan nilai default dalam deklarasi kelas. Dalam contoh kami, bidang jumlahPaid dari kelas tagihan memiliki nilai default nol. Simbol ':' berarti membuat entitas kelas: klien1 dan klien2 adalah entitas kelas klien.
Sekarang kami dapat menyatakan bahwa konsep "Faktur yang belum dibayar" dan "Debitur" adalah subkelas dari konsep "Akun" dan "Klien":
unpaidBill :: bill.
debtor :: client.Simbol '::' mendeklarasikan hubungan pewarisan antar kelas. Struktur kelas diwarisi, metode dan nilai default untuk semua bidangnya. Tetap mendeklarasikan aturan yang menentukan milik kelas unpaidBill dan debitur:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b.
?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x]. Pernyataan pertama menyatakan bahwa variabel
?adalah entitas unpaidBill jika itu adalah entitas tagihan dan bidang jumlahToPay lebih besar dari jumlahPaid. Yang kedua, apa yang ?termasuk kelas unpaidBill, jika kelas itu milik kelas klien dan setidaknya ada satu entitas dari kelas unpaidBill di mana nilai bidang klien sama dengan variabel ?. Entitas kelas unpaidBill ini akan dikaitkan dengan variabel anonim ?_, yang nilainya tidak digunakan lebih lanjut.
Anda bisa mendapatkan daftar debitur menggunakan kueri:
?- ?x:debtor.Kami meminta Anda untuk menemukan semua nilai yang terkait dengan kelas debitur. Hasilnya adalah daftar semua nilai yang mungkin untuk variabel
?x:
?x = client1Logika bingkai menggabungkan visibilitas model berorientasi objek dengan kekuatan pemrograman logika. Akan lebih mudah ketika bekerja dengan database, memodelkan sistem yang kompleks, mengintegrasikan data yang berbeda - dalam kasus di mana Anda perlu fokus pada struktur konsep.
SQL
Terakhir, mari kita lihat fitur utama sintaks SQL. Dalam publikasi terakhir, kami mengatakan bahwa SQL memiliki basis teori logis - kalkulus relasional, dan mempertimbangkan implementasi contoh dengan debitur di LINQ. Dalam hal semantik, SQL dekat dengan bahasa framing dan model OOP - dalam model data relasional, elemen utamanya adalah tabel, yang dianggap sebagai keseluruhan, dan bukan sebagai sekumpulan properti terpisah.
Sintaks SQL sangat cocok dengan orientasi tabel ini. Permintaan tersebut dibagi menjadi beberapa bagian. Entitas model, yang diwakili oleh tabel, tampilan, dan kueri bertingkat, telah dipindahkan ke bagian DARI. Tautan di antara mereka ditentukan menggunakan operasi GABUNG. Dependensi antara kolom dan kondisi lain ada di klausa WHERE dan HAVING. Alih-alih variabel boolean yang mengikat argumen predikat, kami beroperasi pada bidang tabel secara langsung dalam kueri. Sintaks ini menjelaskan struktur model domain lebih jelas daripada sintaks Prolog "linier".
Bagaimana saya melihat gaya sintaks dari bahasa pemodelan
Dengan menggunakan contoh faktur belum dibayar, kita dapat membandingkan pendekatan seperti pemrograman logika (Prolog), logika bingkai (Flora-2), teknologi web semantik (RDFS, OWL, dan SWRL), dan kalkulus relasional (SQL). Saya merangkum karakteristik utama mereka dalam sebuah tabel:
| Bahasa | Dasar matematika | Orientasi gaya | Lingkup aplikasi |
|---|---|---|---|
| Prolog | Logika urutan pertama | Tentang peraturan | Sistem berbasis aturan, pencocokan pola. |
| RDFS | Grafik | Tentang hubungan antar konsep | Skema data sumber daya WEB |
| BURUNG HANTU | Logika deskriptif | Tentang hubungan antar konsep | Ontologi |
| SWRL | Versi logika urutan pertama Datalog yang dipreteli | Tentang aturan di atas tautan antar konsep | Ontologi |
| Flora-2 | Bingkai + logika urutan pertama | Tentang aturan di atas struktur objek | Basis data, pemodelan sistem yang kompleks, mengintegrasikan data yang berbeda |
| SQL | Kalkulus relasional | Di atas struktur meja | Database |
Sekarang Anda perlu menemukan dasar matematika dan gaya sintaksis untuk bahasa pemodelan yang dirancang untuk bekerja dengan data semi-terstruktur dan integrasi data dari sumber yang berbeda, yang akan dikombinasikan dengan bahasa pemrograman fungsional dan berorientasi objek tujuan umum.
Bahasa yang paling ekspresif adalah Prolog dan Flora-2 - mereka didasarkan pada logika orde pertama penuh dengan elemen logika orde tinggi. Pendekatan lainnya adalah bagian dari itu. Kecuali untuk RDFS - itu tidak ada hubungannya dengan logika formal sama sekali. Pada tahap ini, logika urutan pertama yang lengkap menurut saya merupakan opsi yang lebih disukai. Untuk memulainya, saya berencana untuk memikirkannya. Tetapi opsi terbatas dalam bentuk kalkulus relasional atau logika database deduktif juga memiliki kelebihannya. Ini memberikan kinerja luar biasa saat bekerja dengan data dalam jumlah besar. Ini harus dipertimbangkan secara terpisah di masa depan. Logika deskriptif tampaknya terlalu terbatas dan tidak mampu mengungkapkan hubungan dinamis antar konsep.
Dari sudut pandang saya, untuk bekerja dengan data semi-terstruktur dan mengintegrasikan sumber data yang berbeda, logika bingkai lebih cocok daripada Prolog yang berorientasi pada aturan, atau OWL, yang berfokus pada tautan dan kelas konsep. Model bingkai secara eksplisit mendeskripsikan struktur objek dan memusatkan perhatian padanya. Dalam kasus objek dengan banyak properti, bentuk bingkai jauh lebih mudah dibaca daripada aturan atau triplet subjek-properti-objek. Pewarisan juga merupakan mekanisme yang sangat berguna yang dapat secara dramatis mengurangi jumlah kode berulang. Dibandingkan dengan model relasional, logika bingkai memungkinkan Anda mendeskripsikan struktur data kompleks seperti pohon dan grafik dengan cara yang lebih alami. Dan yang terpenting,Kedekatan model bingkai untuk mendeskripsikan pengetahuan dengan model OOP akan memungkinkan pengintegrasian mereka dalam satu bahasa secara alami.
Saya ingin meminjam struktur kueri dari SQL. Pengertian suatu konsep bisa memiliki bentuk yang kompleks dan tidak ada salahnya untuk memecahnya menjadi beberapa bagian guna mempertegas bagian-bagian penyusunnya dan memudahkan persepsi. Selain itu, untuk sebagian besar pengembang, sintaks SQL cukup familiar.
Jadi, saya ingin mengambil logika bingkai sebagai dasar bahasa pemodelan. Tetapi karena tujuannya adalah untuk mendeskripsikan struktur data dan mengintegrasikan sumber data yang berbeda, saya akan mencoba untuk meninggalkan sintaks yang berorientasi pada aturan dan menggantinya dengan versi terstruktur yang dipinjam dari SQL. Elemen utama dari model domain adalah "konsep" (konsep). Dalam definisinya, saya ingin memasukkan semua informasi yang diperlukan untuk mengekstrak entitasnya dari data sumber:
- nama konsep;
- satu set atributnya;
- () , ;
- , ;
- , .
Definisi konsep akan menyerupai kueri SQL. Dan seluruh model domain akan berbentuk konsep yang saling terkait.
Saya berencana untuk menunjukkan sintaks yang dihasilkan dari bahasa pemodelan di publikasi berikutnya. Bagi mereka yang ingin mengenalnya sekarang, ada teks lengkap dalam gaya ilmiah dalam bahasa Inggris, tersedia di sini:
Pemrograman Berorientasi Ontologi Hibrid untuk Pemrosesan Data Semi-Terstruktur
Tautan ke publikasi sebelumnya:
Merancang bahasa pemrograman multi-paradigma. Bagian 1 - Untuk apa ini?
Kami merancang bahasa pemrograman multi-paradigma. Bagian 2 - Perbandingan Pembuatan Model di PL / SQL, LINQ dan GraphQL