Model berbasis transformator telah mencapai hasil yang luar biasa dalam berbagai disiplin ilmu, termasuk percakapan AI , pemrosesan bahasa alami , pemrosesan gambar , dan bahkan musik . Komponen utama dari arsitektur apa pun adalah modul perhatian Transformers (modul perhatian), yang menghitung kesamaan untuk semua pasangan dalam urutan masukan. Namun, itu tidak berskala baik dengan peningkatan panjang urutan input, membutuhkan peningkatan kuadrat dalam waktu komputasi untuk mendapatkan semua perkiraan kesamaan, serta peningkatan kuadrat dalam jumlah memori yang digunakan untuk membuat matriks untuk menyimpan perkiraan ini.
Untuk aplikasi yang memerlukan perhatian lebih, beberapa proxy yang lebih cepat dan lebih ringkas telah diusulkan, seperti teknik cache memori , tetapi solusi yang lebih umum adalah menggunakan perhatian yang jarang . Perhatian renggang mengurangi waktu komputasi dan persyaratan memori untuk mekanisme perhatian dengan menghitung hanya sejumlah skor kesamaan yang terbatas dari suatu urutan daripada semua pasangan yang mungkin, menghasilkan matriks renggang daripada matriks lengkap. Kejadian jarang ini dapat disarankan secara manual, ditemukan menggunakan teknik pengoptimalan, dipelajari, atau bahkan diacak, seperti yang ditunjukkan oleh teknik seperti Sparse Transformers , Longformers, Routing Transformers , Reformers dan Big Bird . Karena matriks renggang juga dapat direpresentasikan oleh grafik dan tepi , metode renggang juga dimotivasi oleh literatur jaringan saraf tiruan grafik , terutama mengenai mekanisme perhatian yang diuraikan dalam Graph Attention Networks. Arsitektur ketersebaran seperti itu biasanya memerlukan lapisan tambahan untuk secara implisit membuat mekanisme perhatian penuh.
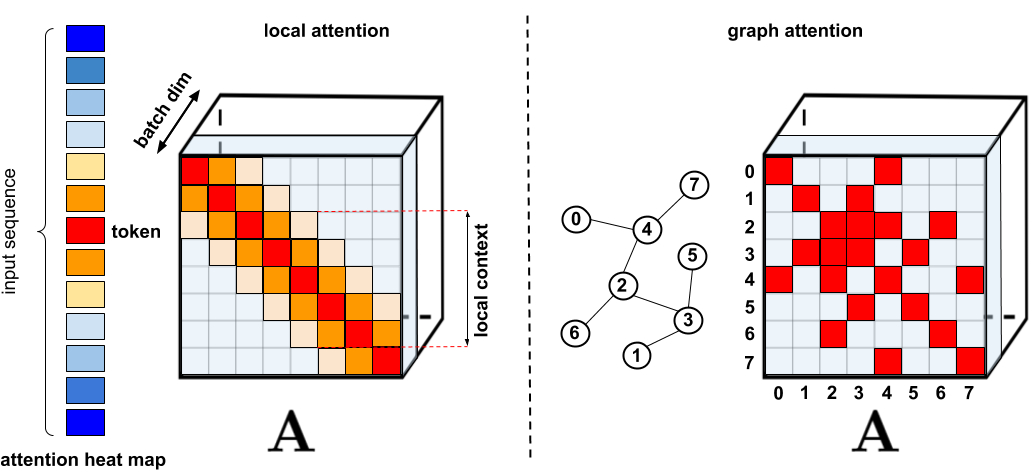
. : , . : Graph Attention Networks, , , . . « : » .
, . (1) , ; (2) ; (3) , , ; (4) , , . , , , Pointer Networks. , , , (softmax), .
, Performer, , . , , , ImageNet64, , PG-19. Performer () , , () . (Fast Attention Via Positive Orthogonal Random Features, FAVOR+), . ( , -). , .
, , , . , - . , , .
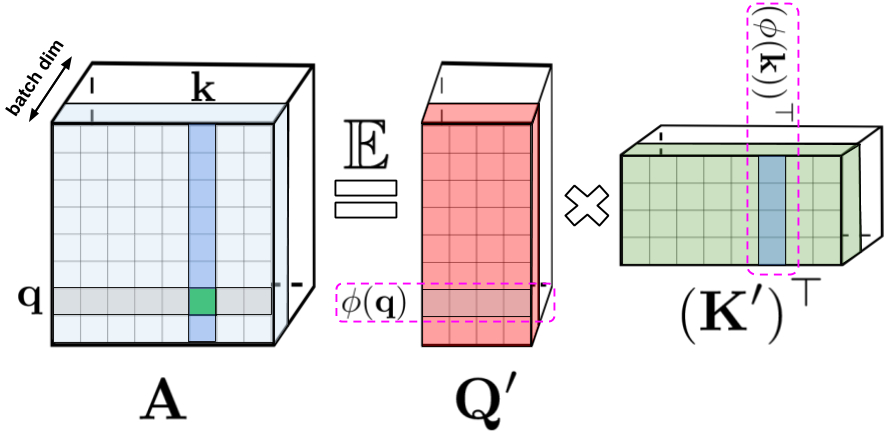
: , , , q k. : Q' K' , /. - , .
, , . , , , , -.
FAVOR+:
, . , . , , . , FAVOR+.
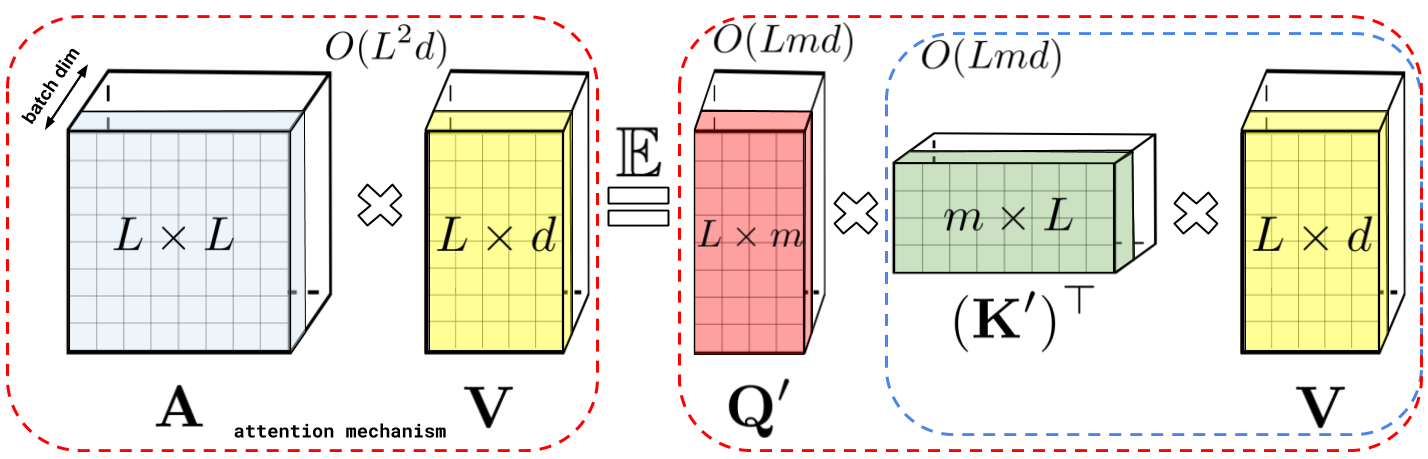
: , A V. : Q' K', A , , , , A .
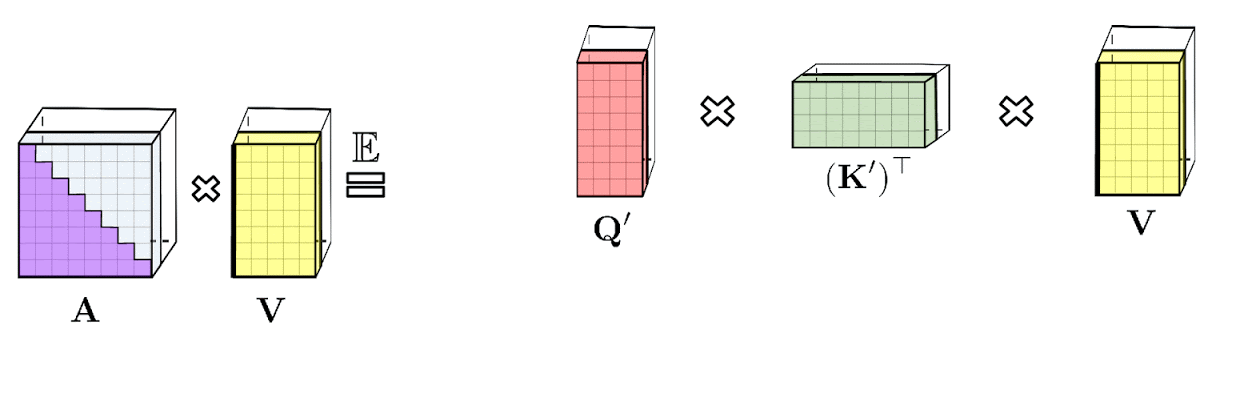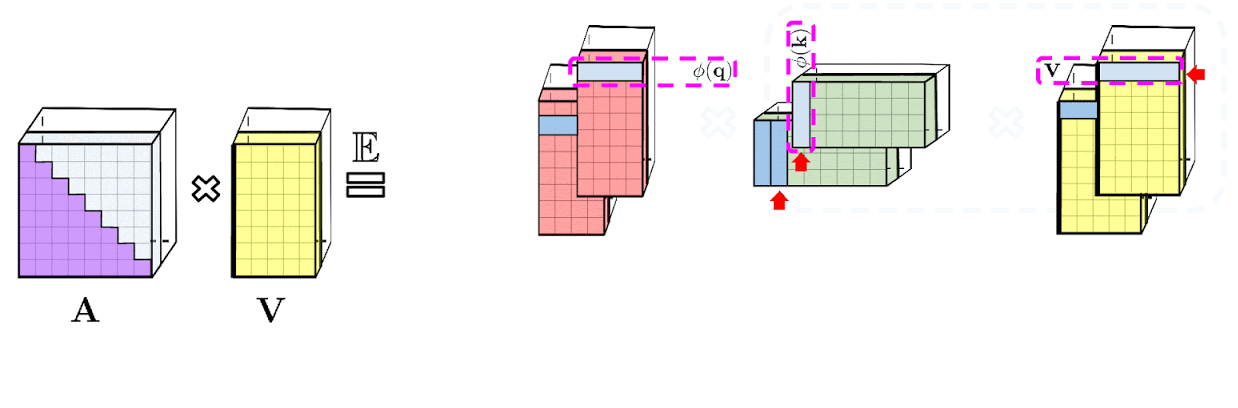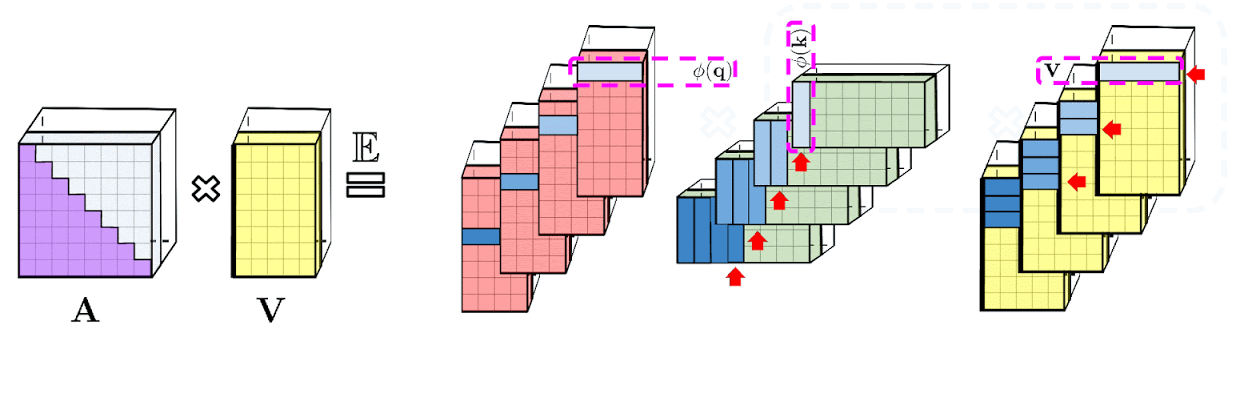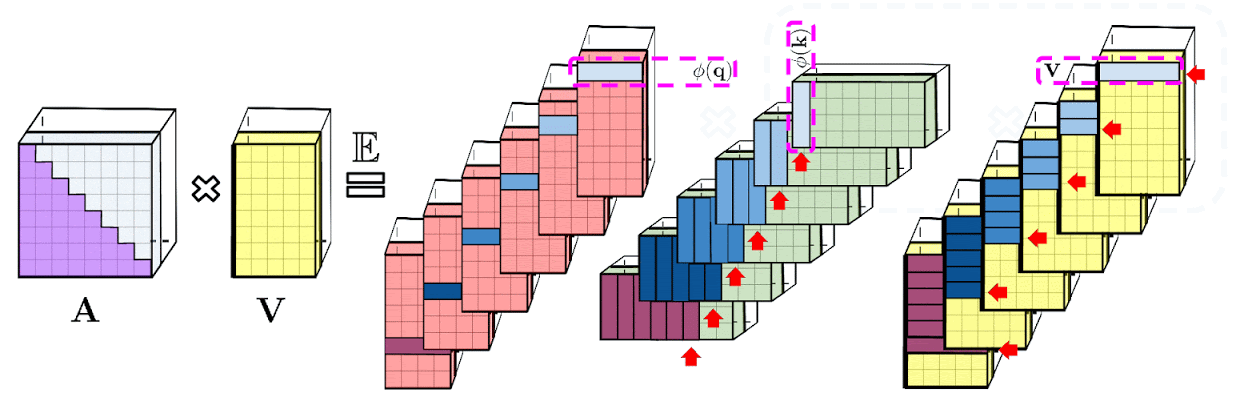
: , . : , .
Performer , , , .
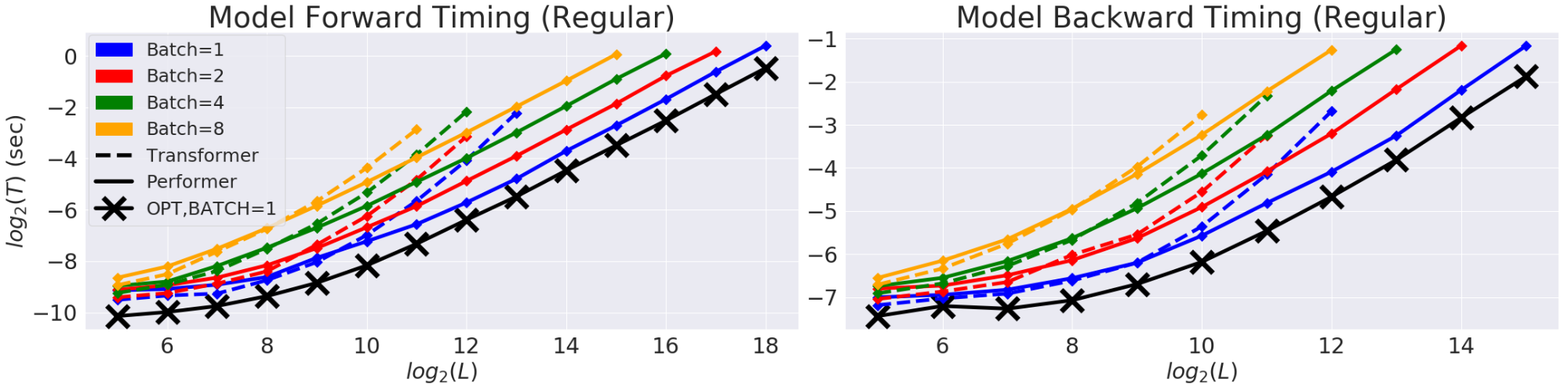
(T) (L). GPU. (X) «» , , , . Performer .
, Performer, -, , .
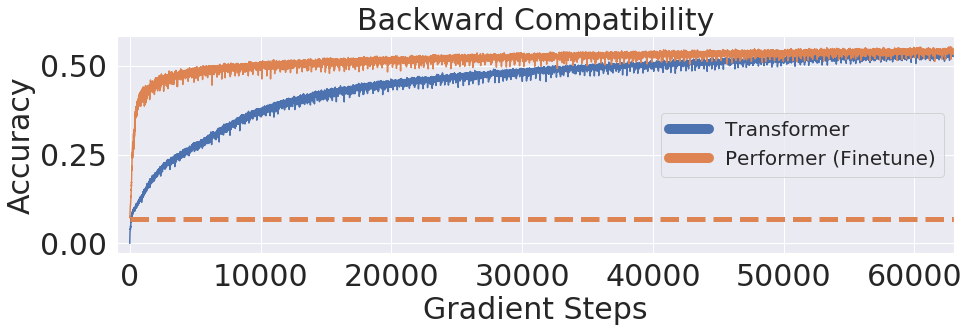
One Billion Word Benchmark (LM1B), Performer, 0.07 ( ). Performer .
:
— , . , , 20 . (, UniRef) , . Performer-ReLU ( ReLU, , ) , Performer-Softmax (accuracy) , .
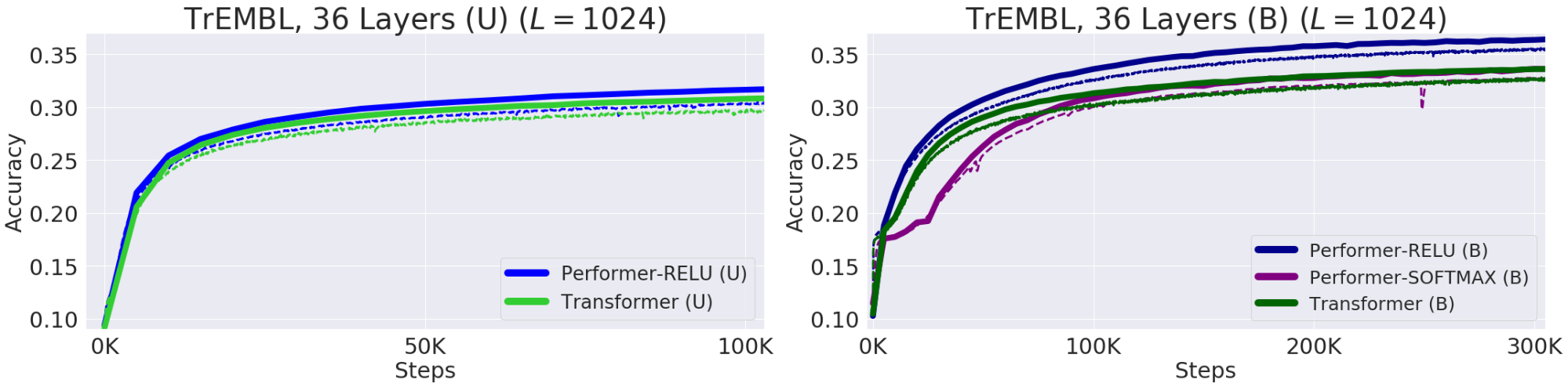
. (Train) — , (Validation) – , — (U), — (B). 36 ProGen (2019) , 16x16 TPU-v2. .
Protein Performer, ReLU. Performer , , . , , . Performer' . , , Performer - .
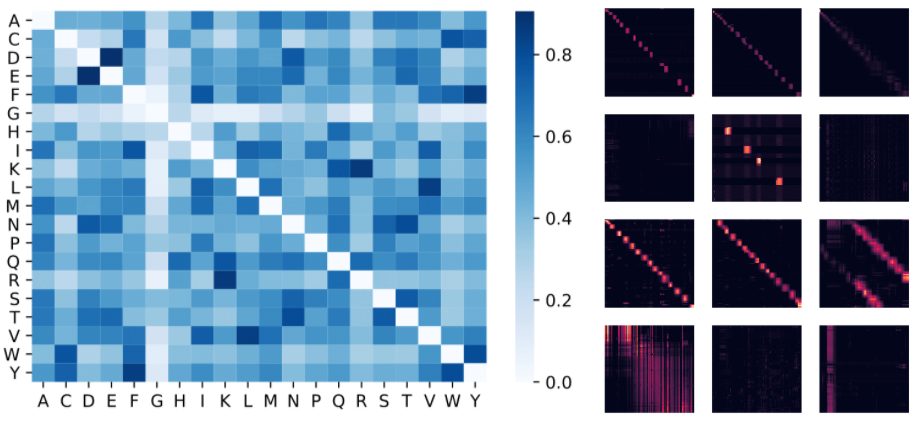
: , . , (D, E) (F, Y), . : 4 () 3 «» () BPT1_BOVIN, .
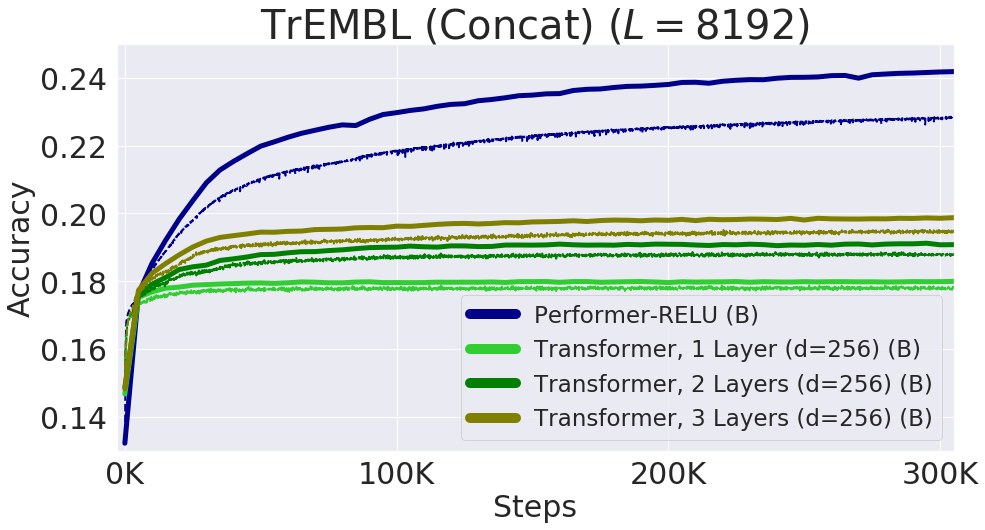
8192, . TPU, ( ) .
, . , , FAVOR Reformer. , Performer' . , , .
- — Krzysztof Choromanski, Lucy Colwell
- —
- Pengeditan dan tata letak - Sergey Shkarin