
Di bulan Oktober, secara tradisional, GPT-3 kembali menjadi sorotan. Ada beberapa berita terkait model dari OpenAI - bagus dan tidak terlalu bagus.
Kesepakatan OpenAI dan Microsoft
Kita harus mulai dengan yang kurang menyenangkan - Microsoft mengambil alih hak eksklusif untuk GPT-3. Kesepakatan itu memicu kemarahan - Elon Musk, pendiri OpenAI dan sekarang mantan anggota dewan direksi perusahaan, mengatakan Microsoft telah secara efektif mengambil alih OpenAI.
Faktanya adalah bahwa OpenAI pada awalnya dibuat sebagai organisasi nirlaba dengan misi tinggi - tidak membiarkan kecerdasan buatan berada di tangan negara atau perusahaan yang terpisah. Para pendiri organisasi menyerukan keterbukaan penelitian di bidang ini, agar teknologi berfungsi untuk kepentingan seluruh umat manusia.
Microsoft, dalam pembelaan mereka, mengatakan mereka tidak akan membatasi akses ke model API. Jadi, pada kenyataannya, tidak ada yang berubah - sebelumnya OpenAI juga tidak mempublikasikan kode tersebut, tetapi jika sebelumnya bahkan perusahaan mitra diizinkan untuk bekerja dengan GPT-3 hanya melalui API, sekarang Microsoft memiliki hak eksklusif untuk menggunakan.
ruGPT3 dari Sberbank
Sekarang ke berita yang lebih menyenangkan - peneliti dari Sberbank telah menerbitkan model dalam akses terbuka yang mengulangi arsitektur GPT-3 dan didasarkan pada kode GPT-2 dan, yang paling penting, dilatih dalam korpus bahasa Rusia.
Kumpulan literatur Rusia, data Wikipedia, snapshot berita dan situs tanya jawab, materi dari portal Pikabu, 22century.ru banki.ru, Omnia Russica digunakan sebagai dataset untuk pelatihan. Pengembang juga menyertakan data dari GitHub dan StackOverflow untuk mengajarkan cara membuat dan memprogram kode. Jumlah total data yang dibersihkan lebih dari 600 GB.
Beritanya pasti bagus, tetapi ada beberapa peringatan. Model ini mirip dengan GPT-3, tetapi tidak. Penulis sendiri mengakuinyabahwa 230 kali lebih kecil dari versi terbesar GPT-3, yang memiliki 175 miliar bobot, yang berarti tidak dapat mengulangi hasil benchmark secara tepat. Artinya, jangan berharap model ini menulis teks yang tidak bisa dibedakan dengan teks jurnalistik.
Perlu juga dipertimbangkan bahwa arsitektur GPT-3 yang dijelaskan mungkin berbeda dari implementasi sebenarnya. Anda dapat mengatakan dengan pasti hanya setelah membaca parameter pelatihan, dan jika sebelum bobot diterbitkan dengan penundaan, maka dalam terang kejadian baru-baru ini mereka tidak dapat diharapkan.
Faktanya adalah bahwa anggaran proyek bergantung pada jumlah parameter pelatihan, dan menurut para ahli, biaya pelatihan GPT-3 setidaknya $ 10 juta. Dengan demikian, hanya perusahaan besar dengan spesialis ML yang kuat dan sumber daya komputasi yang kuat yang dapat mereproduksi pekerjaan OpenAI.
Status Laporan AI 2020
Semua hal di atas menegaskan kesimpulan dari laporan tahunan ketiga tentang keadaan saat ini di bidang pembelajaran mesin. Nathan Benaich dan Ian Hogarth, investor yang berspesialisasi dalam startup AI, telah menerbitkan presentasi terperinci yang mencakup teknologi, sumber daya manusia, aplikasi industri, dan seluk-beluk hukum.
Anehnya, sebanyak 85% penelitian dipublikasikan tanpa kode sumber. Jika organisasi komersial dapat dibenarkan oleh fakta bahwa kode sering dijalin ke dalam infrastruktur proyek, lalu bagaimana dengan lembaga penelitian dan perusahaan nirlaba seperti DeepMind dan OpenAI?
Dikatakan juga bahwa peningkatan dataset dan model menyebabkan peningkatan anggaran, dan mengingat bahwa bidang pembelajaran mesin stagnan, setiap terobosan baru membutuhkan anggaran yang tidak proporsional (bandingkan ukuran GPT-2 dan GPT-3), yang berarti mereka mampu membelinya hanya perusahaan besar.
Kami menyarankan Anda untuk membaca dokumen ini, karena ditulis dengan ringkas dan jelas, bergambar dengan baik. Selain itu, empat perkiraan untuk tahun 2020 dari laporan terakhir telah menjadi kenyataan.
Kami tidak akan melebih-lebihkan, masih ada cerita bagus, kalau tidak koleksi ini tidak akan ada.
Buka model multibahasa dari Google dan Facebook
mT5
Google telah menerbitkan kode sumber dan kumpulan data dari keluarga model multibahasa T5. Karena hype yang terkait dengan OpenAI, berita ini hampir tidak diperhatikan, meskipun skalanya mengesankan - model terbesar memiliki 13 miliar parameter.
Untuk pelatihan, kumpulan data 101 bahasa digunakan, di antaranya bahasa Rusia berada di posisi kedua. Ini dapat dijelaskan oleh fakta bahwa yang agung dan perkasa adalah tempat terpopuler kedua di web.
M2M-100
Facebook juga tidak ketinggalan dan telah meletakkan model multibahasa , yang menurut pernyataan mereka, memungkinkan secara langsung, tanpa bahasa perantara, menerjemahkan 100x100 pasangan bahasa.
Di bidang terjemahan mesin, biasanya membuat dan melatih model untuk setiap bahasa dan tugas individu. Namun dalam kasus Facebook, pendekatan ini tidak dapat menskalakan secara efektif, karena pengguna jejaring sosial mempublikasikan konten dalam lebih dari 160 bahasa.
Biasanya, sistem multibahasa yang menangani banyak bahasa sekaligus mengandalkan bahasa Inggris. Terjemahan dimediasi dan tidak tepat. Sulit untuk menjembatani kesenjangan antara bahasa sumber dan bahasa target karena data yang tidak mencukupi, karena akan sangat sulit menemukan terjemahan dari bahasa Mandarin ke bahasa Prancis dan sebaliknya. Untuk melakukan ini, pencipta harus menghasilkan data sintetis dengan terjemahan terbalik.
Artikel ini memberikan tolok ukur, model menangani terjemahan lebih baik daripada analog yang mengandalkan bahasa Inggris, serta tautan ke kumpulan data .

Kemajuan dalam konferensi video
Di bulan Oktober, beberapa berita menarik dari Nvidia langsung muncul.
StyleGAN2
Pertama, kami memposting pembaruan untuk StyleGAN2 . Arsitektur model sumber daya rendah sekarang memberikan peningkatan kinerja pada set data dengan kurang dari 30 ribu gambar. Versi baru memperkenalkan dukungan untuk presisi campuran: pelatihan dipercepat ~ 1,6x kali, inferensi ~ 1,3x kali, konsumsi GPU menurun ~ 1,5x kali. Kami juga menambahkan pilihan otomatis hyperparameter model: solusi siap pakai untuk kumpulan data dengan resolusi berbeda dan sejumlah prosesor grafis yang tersedia.
NeMo
Neural Modules adalah perangkat sumber terbuka yang membantu Anda membuat, melatih, dan menyesuaikan model percakapan dengan cepat. NeMo terdiri dari inti yang menyediakan satu "tampilan dan nuansa" untuk semua model dan koleksi, yang terdiri dari modul yang dikelompokkan berdasarkan ruang lingkup.
Maxine
Produk lain yang diumumkan kemungkinan akan menggunakan kedua teknologi di atas secara internal. Platform panggilan video Maxine menggabungkan seluruh kebun binatang algoritma ML. Ini termasuk peningkatan resolusi yang sudah dikenal, penghapusan kebisingan, penghapusan latar belakang, tetapi juga koreksi pandangan dan bayangan, pemulihan gambar dengan fitur wajah utama (yaitu, deepfakes), pembuatan subtitle dan terjemahan ucapan ke bahasa lain secara real time. Artinya, hampir semua yang sebelumnya ditemui terpisah, Nvidia digabungkan menjadi satu produk digital. Sekarang Anda dapat mendaftar untuk Akses Awal.
Perkembangan baru Google
Karena karantina, tahun ini ada perlombaan nyata untuk kepemimpinan di bidang konferensi video. Google Meet membagikan studi kasus tentang cara membuat algoritme mereka untuk penghapusan latar belakang berkualitas tinggi berdasarkan framework dari Mediapipe (yang dapat melacak pergerakan mata, kepala, dan tangan).
Google juga telah meluncurkan fitur baru untuk layanan YouTube Stories di iOS yang meningkatkan kualitas ucapan. Ini adalah kasus yang menarik , karena lebih banyak penyempurnaan yang tersedia untuk video daripada untuk audio. Algoritme ini melacak dan menangkap korelasi antara ucapan dan penanda visual, seperti ekspresi wajah, gerakan bibir, yang kemudian digunakan untuk memisahkan ucapan dari suara latar, termasuk suara dari speaker lain.
Perusahaan juga menghadirkan upaya barudi bidang pengenalan bahasa isyarat.
Berbicara tentang perangkat lunak konferensi video, ada baiknya juga menyebutkan algoritma deepfake yang baru.
MakeItTalk
Baru-baru ini, kode algoritme yang menganimasikan foto, hanya mengandalkan aliran audio, diterbitkan di akses terbuka . Ini penting, karena biasanya algoritma deepfake mengambil video sebagai masukan.

Tidak masuk akal
Algoritme deepfake generasi baru menetapkan sendiri tugas untuk menggantikan tidak hanya wajah, tetapi seluruh tubuh, termasuk warna rambut, warna kulit, dan bentuk tubuh. Teknologi ini terutama akan diterapkan di bidang belanja online, sehingga Anda dapat menggunakan foto barang yang disediakan oleh merek itu sendiri, tanpa harus menyewa model individu. Lebih banyak aplikasi dapat dilihat di demo video . Sejauh ini, tampaknya tidak meyakinkan, tetapi semuanya akan segera berubah.
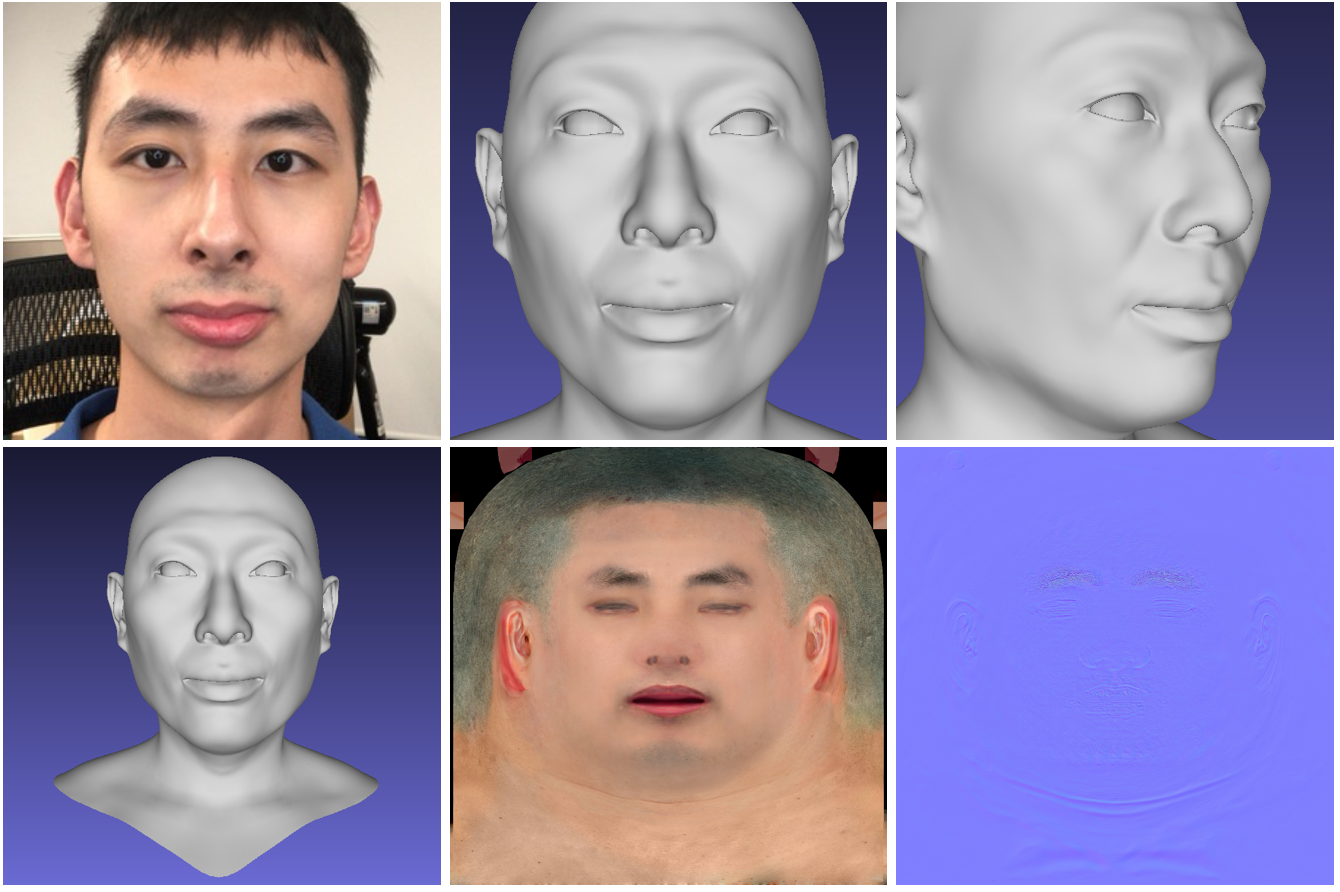
Wajah 3D Hi-Fi
Jaringan saraf menghasilkan model 3D berkualitas tinggi dari wajah seseorang dari foto. Model menerima video pendek dari kamera RGB-D biasa sebagai input, dan pada output memberikan model 3D wajah yang dihasilkan. Kode proyek dan model 3DMM tersedia untuk umum .

SkyAR
Penulis menyajikan teknologi open source untuk menggantikan langit dengan video secara real time, yang juga memungkinkan Anda mengontrol gaya. Efek cuaca seperti kilat dapat dihasilkan pada video target.
Model saluran pipa menyelesaikan sejumlah tugas secara bertahap: kisi membuat langit tampak kusam, melacak objek bergerak, membungkus dan mengecat ulang gambar agar sesuai dengan skema warna skybox.

Sea-thru
Alat ini memecahkan tugas yang tidak biasa untuk mengembalikan warna asli dalam foto bawah air. Artinya, algoritme memperhitungkan kedalaman dan jarak ke objek untuk memulihkan pencahayaan dan menghilangkan air dari gambar. Sejauh ini, hanya dataset yang tersedia.
Model MIT untuk mendiagnosis Covid-19
Sebagai kesimpulan, kami akan membagikan kasus menarik tentang topik yang relevan - para peneliti MIT telah mengembangkan model yang membedakan pasien asimtomatik dengan infeksi virus corona dari orang sehat yang menggunakan rekaman batuk paksa.
Model tersebut telah dilatih pada puluhan ribu rekaman audio sampel batuk. Menurut MIT , algoritme tersebut mengidentifikasi orang-orang yang telah dipastikan memiliki Covid-19 dengan akurasi 98,5%.
Otoritas pemerintah telah menyetujui pembuatan aplikasi. Pengguna akan dapat mengunduh rekaman audio batuknya dan, berdasarkan hasilnya, menentukan apakah perlu melakukan analisis lengkap di laboratorium.
Sekian terima kasih atas perhatiannya!