Banyak hal dalam kehidupan sebuah proyek bergantung pada seberapa baik pemikiran model objek dan struktur basis di awal.
Pendekatan yang diterima secara umum telah dan tetap menjadi berbagai pilihan untuk menggabungkan skema "bintang" dengan bentuk normal ketiga. Sebagai aturan, menurut prinsip: data awal - 3NF, pajangan - bintang. Pendekatan yang telah teruji oleh waktu ini, didukung oleh banyak penelitian, adalah hal pertama (dan terkadang satu-satunya) yang dipikirkan oleh orang DWH yang berpengalaman ketika memikirkan tentang bagaimana seharusnya tampilan repositori analitik.
Di sisi lain, bisnis secara umum dan kebutuhan pelanggan pada khususnya cenderung berubah dengan cepat, dan data tumbuh baik "mendalam" dan "luas". Dan di sinilah kelemahan utama bintang memanifestasikan dirinya - fleksibilitas terbatas .
Dan jika dalam kehidupan Anda yang tenang dan nyaman sebagai developer DWH, tiba-tiba:
- tugas muncul "untuk melakukan setidaknya sesuatu dengan cepat, dan kemudian kita akan lihat";
- proyek yang berkembang pesat muncul, dengan koneksi sumber-sumber baru dan pengerjaan ulang model bisnis setidaknya sekali seminggu;
- seorang pelanggan telah muncul yang tidak membayangkan bagaimana seharusnya tampilan sistem dan fungsi apa yang harus dilakukannya pada akhirnya, tetapi siap untuk eksperimen dan penyempurnaan yang konsisten dari hasil yang diinginkan dengan pendekatan yang konsisten padanya;
- manajer proyek mampir dengan kabar baik: "Dan sekarang kita telah gesit!"
Atau jika Anda hanya ingin tahu bagaimana lagi Anda dapat membangun penyimpanan - selamat datang di bawah perhatian kucing!

Apa artinya fleksibilitas?
Pertama, mari kita tentukan properti apa yang harus dimiliki sistem agar bisa disebut "fleksibel".
Secara terpisah, perlu dicatat bahwa properti yang dideskripsikan harus berhubungan secara khusus dengan sistem , dan bukan dengan proses pengembangannya. Oleh karena itu, jika Anda ingin membaca tentang Agile sebagai metodologi pengembangan, ada baiknya membaca artikel lainnya. Misalnya di sana, di Habré, ada banyak sekali materi yang menarik (baik survey maupun praktis , dan problematis ).
Ini tidak berarti bahwa proses pengembangan dan struktur CD sama sekali tidak terhubung. Secara umum, akan lebih mudah untuk mengembangkan penyimpanan Agile dari arsitektur fleksibel. Namun, dalam praktiknya, ada lebih banyak opsi dengan pengembangan Agile dari DWH klasik oleh Kimball dan DataVault oleh air terjun daripada kebetulan yang menyenangkan dari fleksibilitas dalam dua hipostasisnya pada satu proyek.
Jadi, kemampuan apa yang harus dimiliki penyimpanan fleksibel? Ada tiga poin di sini:
- Pengiriman awal dan tindak lanjut yang cepat berarti bahwa idealnya, hasil bisnis pertama (misalnya, laporan kerja pertama) harus diterima sedini mungkin, yaitu, bahkan sebelum seluruh sistem sepenuhnya dirancang dan diterapkan. Selain itu, setiap revisi berikutnya juga harus memakan waktu sesedikit mungkin.
- — , . — , , . , , — .
- Adaptasi yang konstan terhadap perubahan kebutuhan bisnis - keseluruhan struktur objek harus dirancang tidak hanya dengan mempertimbangkan kemungkinan perluasan, tetapi dengan harapan bahwa arah perluasan selanjutnya ini bahkan mungkin tidak memimpikan Anda pada tahap desain.
Dan ya, memenuhi semua persyaratan ini dalam satu sistem adalah mungkin (tentu saja, dalam kasus tertentu dan dengan beberapa peringatan).
Di bawah ini saya akan mempertimbangkan dua dari metodologi desain tangkas yang paling populer untuk HD - model Jangkar dan Data Vault.... Di belakang tanda kurung terdapat teknik yang sangat baik seperti EAV, 6NF (dalam bentuk murni) dan segala sesuatu yang berhubungan dengan solusi NoSQL - bukan karena mereka entah bagaimana lebih buruk, dan bahkan bukan karena dalam kasus ini artikel tersebut akan mengancam untuk mendapatkan volume rata-rata dissera. Hanya saja semua ini mengacu pada solusi dari kelas yang sedikit berbeda - baik pada teknik yang dapat Anda terapkan dalam kasus tertentu, terlepas dari arsitektur umum proyek Anda (seperti EAV), atau paradigma global lain dari penyimpanan informasi (seperti database grafik dan opsi lainnya) NoSQL).
Masalah dari pendekatan "klasik" dan solusinya dalam metodologi tangkas
Yang saya maksud dengan pendekatan "klasik" adalah bintang tua yang baik (terlepas dari implementasi spesifik dari lapisan yang mendasarinya, semoga pengikut Kimball, Inmon dan CDM memaafkan saya).
1. Kardinalitas ikatan yang kaku
Model ini didasarkan pada pemisahan data yang jelas menjadi dimensi (Dimensi) dan fakta (Fakta) . Dan ini, sialnya, logis - bagaimanapun juga, analisis data pada sebagian besar kasus bermuara pada analisis indikator numerik (fakta) tertentu di bagian (dimensi) tertentu.
Dalam hal ini, tautan antar objek diletakkan dalam bentuk tautan antar tabel dengan kunci asing. Ini terlihat cukup alami, tetapi segera mengarah pada batasan pertama dari fleksibilitas - definisi kaku dari kardinalitas koneksi .
Ini berarti bahwa pada tahap desain tabel, Anda harus menentukan secara tepat untuk setiap pasangan objek terkait apakah mereka bisa banyak-ke-banyak, atau hanya 1-ke-banyak, dan "ke arah mana". Ini secara langsung menentukan tabel mana yang akan memiliki kunci utama dan yang akan memiliki kunci eksternal. Mengubah sikap ini ketika persyaratan baru diterima kemungkinan besar akan mengarah pada desain ulang pangkalan.
Misalnya, saat mendesain objek "cek kasir", Anda, dengan mengandalkan sumpah dari departemen penjualan, menetapkan kemungkinan satu promosi bertindak pada beberapa posisi cek (tetapi tidak sebaliknya):
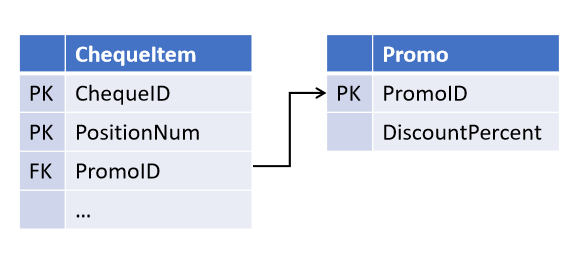
Dan setelah beberapa saat, rekan kerja memperkenalkan strategi pemasaran baru, di mana beberapa promosi dapat bertindak pada posisi yang sama pada waktu yang sama . Dan sekarang Anda perlu memodifikasi tabel dengan memilih tautan ke objek terpisah.
(Semua objek turunan, tempat terjadinya pemeriksaan promo, sekarang juga perlu ditingkatkan).
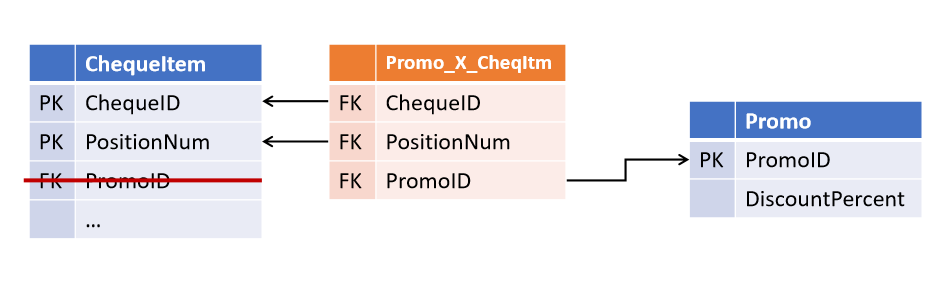
Tautan di Gudang Data dan Model Jangkar
Ternyata cukup sederhana untuk menghindari situasi seperti itu: Anda
Pendekatan ini diusulkan oleh Dan Linstedt sebagai bagian dari paradigma Data Vault dan didukung penuh oleh Lars Rönnbäck dalam Model Jangkar .
Hasilnya, kami mendapatkan fitur pembeda pertama dari metodologi agile:
Hubungan antar objek tidak disimpan dalam atribut entitas induk, tetapi merupakan tipe objek yang terpisah.The data Vault adalah meja-ligamen yang disebut link , dan Model jangkar - yang Tie . Sekilas mereka sangat mirip, meskipun perbedaan mereka tidak terbatas pada nama (yang akan dibahas di bawah). Di kedua arsitektur, tabel tautan dapat menghubungkan sejumlah entitas (tidak harus 2).
Sekilas, redundansi ini memberikan fleksibilitas yang signifikan untuk modifikasi. Struktur seperti itu menjadi toleran tidak hanya untuk mengubah kardinalitas tautan yang ada, tetapi juga untuk menambahkan yang baru - jika sekarang posisi cek juga memiliki tautan ke kasir yang menekannya, tampilan tautan seperti itu hanya akan menjadi tambahan atas tabel yang ada tanpa memengaruhi objek dan objek yang ada. proses.

2. Duplikasi data
Masalah kedua, dipecahkan dengan arsitektur fleksibel, kurang jelas dan melekat terutama pada pengukuran tipe SCD2 (secara perlahan mengubah dimensi tipe kedua), meskipun tidak hanya untuk mereka.
Dalam penyimpanan klasik, dimensi biasanya berupa tabel yang berisi kunci pengganti (sebagai PK) dan sekumpulan kunci bisnis dan atribut di kolom terpisah.

Jika dimensi diversi, batas waktu versi ditambahkan ke kumpulan kolom standar, dan beberapa versi muncul per baris di sumber di Store (satu untuk setiap perubahan pada atribut berversi).
Jika dimensi berisi setidaknya satu atribut berversi yang sering berubah, jumlah versi dari dimensi seperti itu akan mengesankan (meskipun atribut lainnya tidak berversi, atau tidak pernah berubah), dan jika ada beberapa atribut seperti itu, jumlah versi dapat bertambah secara eksponensial dari jumlahnya. Dimensi seperti itu dapat memakan banyak ruang disk, meskipun sebagian besar data yang disimpan di dalamnya hanyalah nilai duplikat dari atribut yang tidak berubah dari baris lain.

Pada saat yang sama, denormalisasi juga sangat sering digunakan - beberapa atribut sengaja disimpan sebagai nilai, dan bukan referensi ke direktori atau dimensi lain. Pendekatan ini mempercepat akses data dengan mengurangi jumlah gabungan saat mengakses dimensi.
Sebagai aturan, ini mengarah pada fakta ituinformasi yang sama disimpan secara bersamaan di beberapa tempat . Misalnya, informasi tentang wilayah tempat tinggal dan milik kategori pelanggan dapat disimpan secara bersamaan dalam dimensi "Pelanggan" dan fakta "Pembelian", "Pengiriman" dan "Panggilan ke pusat panggilan", serta di tabel tautan "Pelanggan - Manajer pelanggan".
Secara umum, hal di atas berlaku untuk pengukuran reguler (non-berversi), tetapi dalam pengukuran berversi, pengukuran dapat memiliki skala yang berbeda: kemunculan versi baru dari sebuah objek (terutama di belakang) tidak hanya mengarah pada pembaruan semua tabel terkait, tetapi juga pada tampilan bertingkat versi baru dari objek terkait - ketika Tabel 1 digunakan untuk membuat Tabel 2, dan Tabel 2 digunakan untuk membuat Tabel 3, dll. Bahkan jika tidak ada atribut Tabel 1 yang terlibat dalam konstruksi Tabel 3 (dan atribut lain dari Tabel 2 yang diperoleh dari sumber lain yang terlibat), pembaruan versi konstruksi ini setidaknya akan menyebabkan biaya overhead tambahan, dan paling banyak - ke versi yang tidak perlu dalam Tabel 3. yang tidak ada hubungannya dengan itu dan selanjutnya di sepanjang rantai.

3. Kompleksitas revisi yang tidak linier
Selain itu, setiap pasar baru, yang dibangun di atas yang lain, meningkatkan jumlah tempat di mana data dapat "menyimpang" saat membuat perubahan pada ETL. Ini, pada gilirannya, mengarah pada peningkatan kompleksitas (dan durasi) dari setiap revisi berikutnya.
Jika masalah di atas menyangkut sistem dengan proses ETL yang jarang dimodifikasi, Anda dapat hidup dalam paradigma seperti itu - Anda hanya perlu memastikan bahwa modifikasi baru diperkenalkan dengan benar ke semua objek terkait. Jika revisi sering terjadi, kemungkinan tidak sengaja "kehilangan" beberapa tautan meningkat secara signifikan.
Sebagai tambahan, jika kita memperhitungkan bahwa ETL "berversi" jauh lebih rumit daripada "non-versi", menjadi sangat sulit untuk menghindari kesalahan dengan seringnya revisi dari keseluruhan ekonomi ini.
Menyimpan objek dan atribut dalam Data Vault dan Model Jangkar
Pendekatan yang diajukan oleh penulis arsitektur agile dapat dirumuskan sebagai berikut:
Penting untuk memisahkan perubahan apa dari apa yang tetap tidak berubah. Artinya, pisahkan kunci dari atribut.Pada saat yang sama, Anda tidak boleh mengacaukan atribut non-berversi dengan atribut yang tidak berubah : yang pertama tidak menyimpan riwayat perubahannya, tetapi dapat berubah (misalnya, saat kesalahan input diperbaiki atau data baru diterima); yang kedua tidak pernah berubah.
Sudut pandang tentang apa yang sebenarnya dapat dianggap tidak berubah di Data Vault dan Model Jangkar berbeda.
Dari sudut pandang arsitektur Data Vault , seluruh rangkaian kunci dapat dianggap tidak berubah - alami (TIN organisasi, kode produk dalam sistem sumber, dll.) Dan pengganti. Pada saat yang sama, atribut yang tersisa dapat dibagi menjadi beberapa grup berdasarkan sumber dan / atau frekuensi perubahan, dan tabel terpisah dengan kumpulan versi independen dapat dipertahankan untuk setiap grup .
Dalam paradigmaModel Jangkar dianggap hanya kunci pengganti entitas yang tidak dapat diubah . Segala sesuatu yang lain (termasuk kunci alami) hanyalah kasus khusus dari atributnya. Pada saat yang sama, semua atribut secara default tidak bergantung satu sama lain , oleh karena itu, tabel terpisah harus dibuat untuk setiap atribut .
Di Data Vault, tabel yang berisi kunci entitas disebut Hub . Hub selalu berisi sekumpulan bidang tetap:
- Kunci alami entitas
- Kunci pengganti
- Tautan ke sumber
- Rekam waktu penambahan
Entri di Hub tidak pernah berubah dan tidak memiliki versi . Secara lahiriah, hub sangat mirip dengan tabel tipe ID-map yang digunakan di beberapa sistem untuk menghasilkan pengganti, namun, disarankan untuk tidak menggunakan urutan integer sebagai pengganti di Data Vault, tetapi hash dari sekumpulan kunci bisnis. Pendekatan ini menyederhanakan pemuatan tautan dan atribut dari sumber (Anda tidak perlu bergabung dengan hub untuk mendapatkan pengganti, Anda hanya perlu menghitung hash dari kunci alami), tetapi dapat menyebabkan masalah lain (terkait, misalnya, dengan benturan, huruf besar dan karakter yang tidak dapat dicetak dalam kunci string, dll.) .p.), oleh karena itu tidak diterima secara umum.
Semua atribut entitas lainnya disimpan dalam tabel khusus yang disebut Satelit... Satu hub dapat memiliki beberapa satelit yang menyimpan kumpulan atribut yang berbeda.
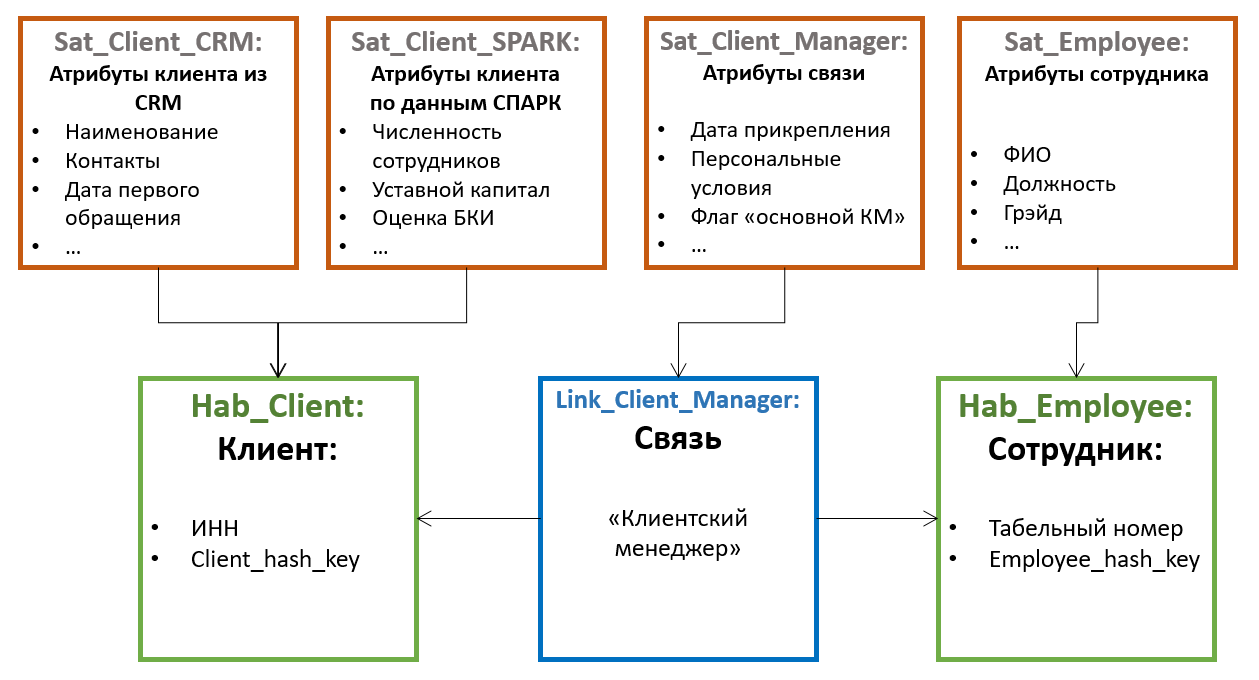
Distribusi atribut di antara satelit didasarkan pada prinsip perubahan bersama - satu satelit dapat menyimpan atribut non-versi (misalnya, tanggal lahir dan SNIL untuk individu), di satelit lain - jarang mengubah versi (misalnya, nama belakang dan nomor paspor), di satelit ketiga - sering berubah (misalnya, alamat pengiriman, kategori, tanggal pemesanan terakhir, dll.). Dalam hal ini, pembuatan versi dilakukan pada tingkat satelit individu, dan bukan pada entitas secara keseluruhan; oleh karena itu, disarankan untuk mendistribusikan atribut sehingga perpotongan versi dalam satu satelit minimal (yang mengurangi jumlah total versi yang disimpan).
Selain itu, untuk mengoptimalkan proses pemuatan data, atribut yang diperoleh dari berbagai sumber sering kali ditempatkan di satelit terpisah.
Satelit berkomunikasi dengan Hub menggunakan kunci asing (yang sesuai dengan kardinalitas 1-ke-banyak). Ini berarti beberapa nilai atribut (misalnya, beberapa nomor telepon kontak untuk pelanggan yang sama) didukung oleh arsitektur "default" ini.
Dalam Model Jangkar, tabel yang memegang kunci disebut Jangkar . Dan mereka menyimpan:
- Hanya kunci pengganti
- Tautan ke sumber
- Rekam waktu penambahan
Kunci alami dianggap sebagai atribut biasa dari sudut pandang Model Jangkar . Pilihan ini mungkin tampak lebih sulit untuk dipahami, tetapi memberikan lebih banyak ruang untuk identifikasi objek.

Misalnya, jika data tentang entitas yang sama dapat berasal dari sistem yang berbeda, yang masing-masing menggunakan kunci alami sendiri. Di Data Vault, hal ini dapat menyebabkan struktur beberapa hub yang agak rumit (satu per sumber + versi master pemersatu), sedangkan dalam model Jangkar, kunci alami dari setiap sumber termasuk dalam atributnya sendiri dan dapat digunakan selama pemuatan secara independen dari semua yang lain.
Tetapi ada satu hal yang berbahaya di sini: jika atribut dari sistem yang berbeda digabungkan dalam satu entitas, kemungkinan besar ada beberapaaturan "perekatan" , yang menurutnya sistem harus memahami bahwa rekaman dari sumber yang berbeda sesuai dengan satu contoh entitas.
Di Data Vault, aturan ini kemungkinan besar akan menentukan pembentukan "hub pengganti" dari entitas master dan tidak akan memengaruhi Hub yang menyimpan kunci alami sumber dan atribut awalnya dengan cara apa pun. Jika pada titik tertentu perubahan aturan splicing (atau pembaruan atribut yang digunakan) datang, itu akan cukup untuk membentuk ulang hub pengganti.
Dalam model Jangkar, bagaimanapun, entitas seperti itu kemungkinan besar akan disimpan dalam satu jangkar.... Ini berarti bahwa semua atribut, terlepas dari sumber mana asalnya, akan terikat ke pengganti yang sama. Memisahkan record yang digabungkan secara keliru dan, secara umum, melacak relevansi penggabungan dalam sistem semacam itu bisa jadi jauh lebih sulit, terutama jika aturannya cukup kompleks dan sering berubah, dan atribut yang sama dapat diperoleh dari sumber yang berbeda (walaupun itu pasti mungkin, karena masing-masing versi atribut mempertahankan tautan ke sumbernya).
Bagaimanapun, jika sistem Anda seharusnya menerapkan fungsionalitas deduplikasi, menggabungkan catatan, dan elemen MDM lainnya, ada baiknya untuk melihat lebih dekat aspek penyimpanan kunci alami dalam metodologi tangkas. Desain Data Vault yang lebih rumit kemungkinan besar akan tiba-tiba terbukti lebih aman dalam hal kesalahan penggabungan.
Model jangkar juga menyediakan jenis objek tambahan yang disebut Simpul, sebenarnya itu adalah jenis jangkar khusus yang hanya dapat berisi satu atribut. Node seharusnya digunakan untuk menyimpan buku referensi flat (misalnya, jenis kelamin, status pernikahan, kategori layanan pelanggan, dll.). Tidak seperti Anchor, Node tidak memiliki tabel atribut terkait, dan atribut satu-satunya (nama) selalu disimpan dalam tabel yang sama dengan kunci. Node ditautkan ke tabel Jangkar dengan Dasi, sama seperti jangkar satu sama lain.
Tidak ada pendapat tegas tentang penggunaan Nodes. Misalnya, Nikolai Golov , yang secara aktif mempromosikan penggunaan model Jangkar di Rusia, percaya (bukan tidak masuk akal) bahwa tanpa buku referensi, tidak mungkin untuk mengatakan dengan pasti bahwa itu akan selalu statis dan satu tingkat, oleh karena itu lebih baik menggunakan Jangkar yang lengkap untuk semua objek sekaligus.
Perbedaan penting lainnya antara Data Vault dan model Jangkar adalah adanya atribut untuk tautan :
Di Gudang Data, Tautan adalah objek lengkap yang sama seperti Hub, dan dapat memilikiatribut sendiri . Dalam model Jangkar, Tautan digunakan hanya untuk menghubungkan Jangkar dan tidak dapat memiliki atributnya sendiri . Perbedaan ini memberikan pendekatan yang sangat berbeda terhadap fakta pemodelan , yang akan dibahas di bawah ini.
Menyimpan fakta
Sebelumnya, kami berbicara terutama tentang pengukuran pemodelan. Dengan fakta, situasinya sedikit kurang mudah.
Di Data Vault, objek khas untuk menyimpan fakta adalah Tautan , di Satelit yang ditambahkan indikator nyata.
Pendekatan ini terlihat intuitif. Ini memberikan akses mudah ke indikator yang dianalisis dan umumnya mirip dengan tabel fakta tradisional (hanya indikator yang disimpan tidak di tabel itu sendiri, tetapi di tabel "berdekatan"). Namun ada juga kekurangannya: salah satu modifikasi model tipikal - memperluas kunci fakta - perlu menambahkan kunci asing baru ke Link . Dan ini, pada gilirannya, "merusak" modularitas dan berpotensi menyebabkan kebutuhan untuk perbaikan pada objek lain.
Dalam Model JangkarTautan tidak dapat memiliki atributnya sendiri, jadi pendekatan ini tidak akan berfungsi - benar-benar semua atribut dan indikator harus terikat pada satu jangkar tertentu. Kesimpulannya sederhana - setiap fakta juga membutuhkan jangkarnya sendiri . Untuk beberapa hal yang biasa kita anggap sebagai fakta, mungkin terlihat wajar - misalnya, fakta pembelian secara sempurna direduksi menjadi objek "pesan" atau "cek", kunjungan ke situs - ke sesi, dll. Tetapi ada juga fakta yang tidak begitu mudahnya menemukan "benda pembawa" yang alami - misalnya, sisa-sisa barang di gudang pada awal setiap hari.
Oleh karena itu, tidak ada masalah dengan modularitas saat memperluas kunci fakta dalam model Jangkar (Anda hanya perlu menambahkan Tautan baru ke Jangkar yang sesuai), tetapi desain model untuk menampilkan fakta kurang jelas, Jangkar "buatan" mungkin muncul yang mencerminkan model objek bisnis tidak jelas.
Bagaimana fleksibilitas dicapai
Konstruksi yang dihasilkan dalam kedua kasus berisi tabel yang jauh lebih banyak daripada dimensi tradisional. Tapi itu bisa memakan ruang disk yang jauh lebih sedikit dengan set atribut berversi yang sama sebagai dimensi tradisional. Secara alami, tidak ada keajaiban di sini - ini semua tentang normalisasi. Dengan mendistribusikan atribut di seluruh Satelit (di Data Vault) atau tabel terpisah (Model Jangkar), kami mengurangi (atau sepenuhnya menghilangkan) duplikasi nilai beberapa atribut saat mengubah yang lain .
Untuk Data Vault, perolehannya akan bergantung pada distribusi atribut di seluruh Satelit, dan untuk Model Jangkar , ini akan hampir berbanding lurus dengan jumlah rata-rata versi per objek pengukuran.
Namun, mendapatkan ruang adalah keuntungan utama tetapi bukan keuntungan utama dari menyimpan atribut secara terpisah. Bersama dengan menyimpan tautan secara terpisah, pendekatan ini membuat repositori menjadi desain modular . Ini berarti bahwa penambahan kedua atribut individu dan seluruh bidang studi baru dalam model terlihat seperti seperti add di lebih dari satu set ada objek tanpa mengubah mereka. Dan inilah yang membuat metodologi yang dijelaskan menjadi fleksibel.
Ini juga menyerupai transisi dari produksi satuan ke produksi massal - jika dalam pendekatan tradisional setiap tabel model unik dan memerlukan perhatian terpisah, maka dalam metodologi yang fleksibel ini sudah menjadi serangkaian "detail" yang khas. Di satu sisi, ada lebih banyak tabel, proses memuat dan mengambil data akan terlihat lebih rumit. Di sisi lain, mereka menjadi tipikal . Artinya, mereka dapat diotomatiskan dan dikelola oleh metadata . Pertanyaan "bagaimana kita akan meletakkannya?", Jawaban yang bisa mengambil bagian penting dari desain perbaikan, sekarang tidak layak (serta pertanyaan tentang dampak perubahan model pada proses kerja).
Ini tidak berarti bahwa analis sama sekali tidak diperlukan dalam sistem seperti itu - seseorang masih harus mengerjakan satu set objek dengan atribut dan mencari tahu di mana dan bagaimana memuat semua ini. Tetapi jumlah pekerjaan, serta kemungkinan dan biaya kesalahan, berkurang secara signifikan. Baik pada tahap analisis maupun selama pengembangan ETL, yang pada bagian esensial dapat direduksi menjadi pengeditan metadata.
Sisi gelap
Semua hal di atas menjadikan kedua pendekatan ini sangat fleksibel, maju secara teknologi, dan cocok untuk penyempurnaan berulang. Tentu saja, ada juga “tong salep”, yang menurut saya sudah Anda tebak.
Dekomposisi data, yang merupakan dasar untuk modularitas arsitektur fleksibel, mengarah pada peningkatan jumlah tabel dan, karenanya, overhead gabungan saat mengambil. Untuk mendapatkan semua atribut dimensi, satu pilihan sudah cukup di repositori klasik, dan arsitektur fleksibel akan memerlukan sejumlah gabungan. Selain itu, jika untuk laporan semua gabungan ini dapat ditulis terlebih dahulu, analis yang terbiasa menulis SQL dengan tangan akan menderita dua kali lipat.
Ada beberapa fakta yang membuat situasi ini lebih mudah:
Saat bekerja dengan dimensi besar, semua atributnya hampir tidak pernah digunakan secara bersamaan. Artinya, kemungkinan gabungan lebih sedikit daripada yang terlihat saat Anda pertama kali melihat model. Di Data Vault, Anda juga dapat memperhitungkan frekuensi berbagi yang diharapkan saat mendistribusikan atribut di seluruh satelit. Pada saat yang sama, Hub atau Jangkar itu sendiri dibutuhkan terutama untuk menghasilkan dan memetakan pengganti pada tahap pemuatan dan jarang digunakan dalam permintaan (terutama untuk Jangkar).
Semua gabungan berdasarkan kunci.Selain itu, cara yang lebih "ringkas" untuk menyimpan data mengurangi overhead tabel pemindaian jika diperlukan (misalnya, saat memfilter berdasarkan nilai atribut). Hal ini dapat mengarah pada fakta bahwa mengambil dari database yang dinormalisasi dengan banyak gabungan akan lebih cepat daripada memindai satu dimensi yang berat dengan banyak versi per baris.
Misalnya, di sini, di artikel ini ada uji kinerja komparatif rinci Model Jangkar dengan pilihan dari satu tabel.
Banyak tergantung pada mesinnya. Banyak platform modern memiliki mekanisme pengoptimalan gabungan internal. Misalnya, MS SQL dan Oracle dapat "melewati" gabungan ke tabel jika datanya tidak digunakan di mana pun kecuali untuk gabungan lainnya dan tidak memengaruhi pilihan akhir (eliminasi tabel / gabungan), sedangkan MPP Vertica digunakanPengalaman rekan kerja dari Avito , terbukti menjadi mesin yang sangat baik untuk model Jangkar, dengan mempertimbangkan beberapa pengoptimalan manual dari rencana kueri. Di sisi lain, mempertahankan Model Jangkar, misalnya, di Rumah Klik, yang memiliki dukungan gabungan terbatas, sepertinya bukan ide yang baik untuk saat ini.
Selain itu, ada teknik khusus untuk kedua arsitektur untuk membuat data lebih mudah diakses (baik dari perspektif kinerja kueri maupun untuk pengguna akhir). Misalnya, tabel Point-In-Time di Data Vault atau fungsi tabel khusus di Model Anchor.
Total
Esensi utama dari arsitektur fleksibel yang dianggap adalah modularitas "desain" mereka.
Properti inilah yang memungkinkan:
- , ETL, , . ( ) .
- ( ) 2-3 , ( ).
- , - .
- Karena dekomposisi menjadi elemen standar, proses ETL dalam sistem semacam itu terlihat jenis yang sama, tulisannya cocok untuk algoritme dan, pada akhirnya, otomatisasi .
Harga dari fleksibilitas ini adalah kinerja . Ini tidak berarti bahwa tidak mungkin mencapai kinerja yang dapat diterima pada model seperti itu. Lebih sering daripada tidak, Anda hanya perlu lebih banyak usaha dan perhatian terhadap detail untuk mencapai metrik yang Anda inginkan.
Aplikasi
Jenis Entitas Data Vault

Baca lebih lanjut tentang Data Vault:
situs Dan Listadt
Semua tentang Data Vault dalam bahasa Rusia
Tentang Data Vault di Habré
Jenis Entitas Model Jangkar

Informasi lebih lanjut tentang Model Jangkar:
Situs pembuat Model Jangkar
Artikel tentang pengalaman menerapkan Model Jangkar di Avito
Tabel ringkasan dengan fitur umum dan perbedaan dari pendekatan yang dipertimbangkan:
