Jadi, ada dua jenis bot web - sah dan berbahaya. Yang sah termasuk mesin pencari, pembaca RSS. Contoh bot web berbahaya adalah pemindai kerentanan, pencakar, pengirim spam, bot serangan DDoS, dan Trojan penipuan kartu pembayaran. Setelah jenis bot web diidentifikasi, berbagai kebijakan dapat diterapkan padanya. Jika bot itu sah, Anda dapat menurunkan prioritas permintaannya ke server atau menurunkan tingkat akses ke sumber daya tertentu. Jika bot diidentifikasi sebagai berbahaya, Anda dapat memblokirnya atau mengirimkannya ke kotak pasir untuk analisis lebih lanjut. Mendeteksi, menganalisis, dan mengklasifikasikan bot web sangatlah penting karena dapat membahayakan, misalnya, membocorkan data penting bisnis. Ini juga akan mengurangi beban pada server dan mengurangi apa yang disebut kebisingan dalam lalu lintas, karena hingga 66% lalu lintas bot web tepat.lalu lintas berbahaya .
Pendekatan yang ada
Ada beberapa teknik berbeda untuk mendeteksi bot web dalam lalu lintas jaringan, mulai dari membatasi frekuensi permintaan ke host, memasukkan alamat IP ke daftar hitam, menganalisis nilai header HTTP Agen Pengguna, mengambil sidik jari perangkat - dan diakhiri dengan penerapan CAPTCHA, dan analisis perilaku aktivitas jaringan menggunakan pembelajaran mesin.
Namun mengumpulkan informasi reputasi tentang situs dan memperbarui daftar hitam menggunakan berbagai basis pengetahuan dan intelijen ancaman adalah proses yang mahal dan melelahkan, dan tidak disarankan saat menggunakan server proxy.
Analisis bidang Agen-Pengguna dalam perkiraan pertama mungkin tampak berguna, tetapi tidak ada yang mencegah bot web atau pengguna mengubah nilai bidang ini menjadi yang valid, menyamar sebagai pengguna biasa dan menggunakan Agen-Pengguna yang valid untuk browser, atau sebagai bot yang sah. Sebut saja peniru webbots seperti itu. Menggunakan berbagai sidik jari perangkat (melacak pergerakan mouse atau memeriksa kemampuan klien untuk merender halaman HTML) memungkinkan kami untuk menyorot bot web yang lebih sulit dideteksi yang meniru perilaku manusia, misalnya, meminta halaman tambahan (file gaya, ikon, dll.), Mengurai JavaScript. Pendekatan ini didasarkan pada injeksi kode sisi klien, yang sering kali tidak dapat diterima, karena kesalahan saat memasukkan skrip tambahan dapat merusak aplikasi web.
Perlu dicatat bahwa bot web juga dapat dideteksi secara online: sesi akan dievaluasi secara real time. Penjelasan tentang rumusan masalah ini dapat ditemukan di Cabri et al. [1], serta dalam karya Zi Chu [2]. Pendekatan lain adalah menganalisis hanya setelah sesi berakhir. Yang paling menarik, jelas, adalah opsi pertama, yang memungkinkan Anda membuat keputusan lebih cepat.
Pendekatan yang diusulkan
Kami menggunakan teknik pembelajaran mesin dan tumpukan teknologi ELK (Elasticsearch Logstash Kibana) untuk mengidentifikasi dan mengklasifikasikan bot web. Objek penelitian adalah sesi HTTP. Sesi adalah urutan permintaan dari satu node (nilai unik dari alamat IP dan kolom User-Agent di permintaan HTTP) dalam interval waktu yang tetap. Derek dan Gohale menggunakan interval 30 menit untuk menentukan batas sesi [3]. Iliu et al. Berargumen bahwa pendekatan ini tidak menjamin keunikan sesi yang sebenarnya, tetapi masih dapat diterima. Karena kenyataan bahwa bidang Agen-Pengguna dapat diubah, lebih banyak sesi mungkin muncul daripada yang sebenarnya. Oleh karena itu Nikiforakis dan rekan penulis mengusulkan lebih banyak penyesuaian berdasarkan apakah ActiveX didukung, apakah Flash diaktifkan, resolusi layar, versi OS.
Kami akan mempertimbangkan kesalahan yang dapat diterima dalam pembentukan sesi terpisah jika bidang Agen-Pengguna berubah secara dinamis. Dan untuk mengidentifikasi sesi bot, kami akan membuat model klasifikasi biner yang jelas dan menggunakan:
- aktivitas jaringan otomatis yang dihasilkan oleh bot web (tag bot);
- aktivitas jaringan yang dibuat manusia (tag human).
Untuk mengklasifikasikan bot web berdasarkan jenis aktivitas, mari buat model kelas jamak dari tabel di bawah ini.
| Nama | Deskripsi | Label | Contoh dari |
|---|---|---|---|
| Crawler | Bot
web
mengumpulkan halaman web |
crawler | SemrushBot,
360Spider, Heritrix |
| Jaringan sosial | Bot web dari berbagai
jejaring sosial |
jaringan sosial | LinkedInBot,
Bot WhatsApp, bot Facebook |
| Pembaca RSS | -,
RSS |
rss | Feedfetcher,
Feed Reader, SimplePie |
| -
|
search_engines | Googlebot, BingBot,
YandexBot |
|
| -,
|
libs_tools | Curl, Wget,
python-requests, scrapy |
|
| - | bots | ||
| ,
User-Agent |
unknown |
Kami juga akan memecahkan masalah pelatihan model online.
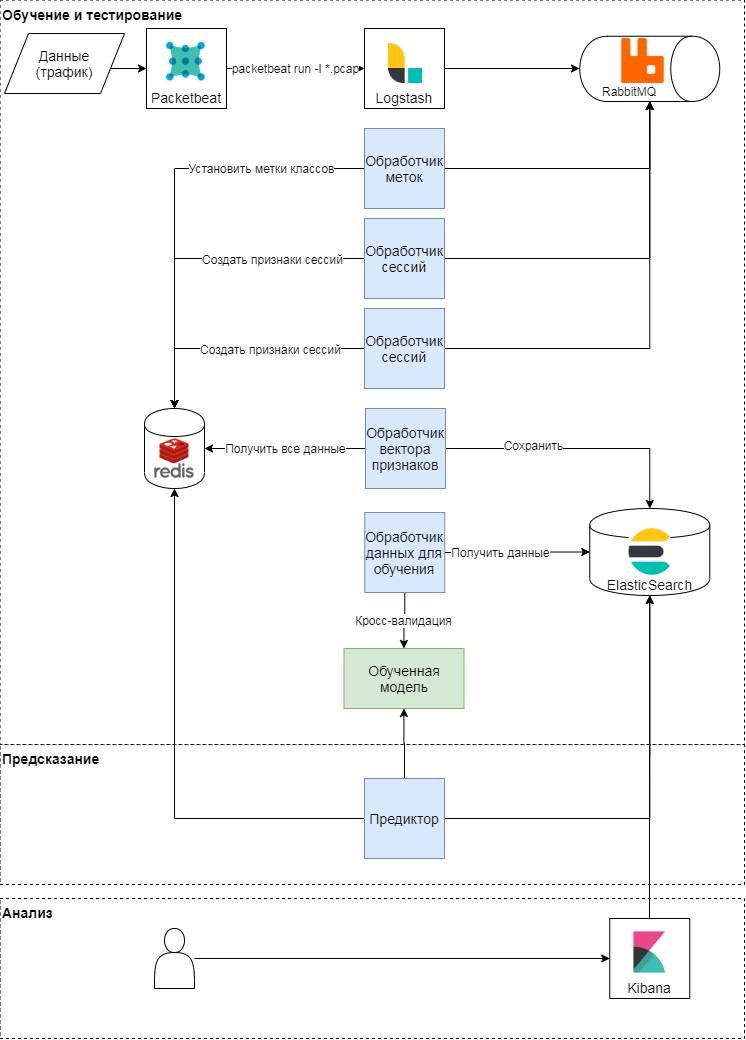
Skema konseptual dari pendekatan yang diusulkan Pendekatan
ini memiliki tiga tahap: pelatihan dan pengujian, prediksi, analisis hasil. Mari kita pertimbangkan dua yang pertama secara lebih rinci. Secara konseptual, pendekatan tersebut mengikuti pola klasik pembelajaran dan penerapan model pembelajaran mesin. Pertama, metrik kualitas dan atribut untuk klasifikasi ditentukan. Setelah itu, vektor fitur dibentuk dan serangkaian percobaan (berbagai pemeriksaan silang) dilakukan untuk memvalidasi model dan memilih hyperparameter. Pada tahap terakhir, model terbaik dipilih dan kualitas model diperiksa pada sampel yang ditangguhkan.
Pelatihan dan pengujian model
Modul packetbeat digunakan untuk mengurai lalu lintas. Permintaan HTTP mentah dikirim ke logstash, di mana tugas dibuat menggunakan skrip Ruby dalam istilah Celery. Masing-masing beroperasi dengan pengenal sesi, waktu permintaan, isi permintaan, dan header. Session identifier (key) - nilai fungsi hash dari penggabungan alamat IP dan User-Agent. Pada tahap ini, dua jenis tugas dibuat:
- tentang pembentukan vektor fitur untuk sesi,
- dengan memberi label kelas berdasarkan teks permintaan dan User-Agent.
Tugas ini dikirim ke antrian dimana penangan pesan menjalankannya. Dengan demikian, penangan labeler melakukan tugas pelabelan kelas menggunakan penilaian ahli dan data terbuka dari layanan browscap berdasarkan Agen-Pengguna yang digunakan; hasilnya ditulis ke penyimpanan nilai kunci. Prosesor Sesi menghasilkan vektor fitur (lihat tabel di bawah) dan menulis hasil untuk setiap kunci dalam penyimpanan nilai kunci, dan juga menyetel masa pakai kunci (TTL).
| Tanda | Deskripsi |
|---|---|
| len | Jumlah permintaan per sesi |
| len_pages | Jumlah permintaan per sesi di halaman
(URI diakhiri dengan .htm, .html, .php, .asp, .aspx, .jsp) |
| len_static_request | Jumlah permintaan per sesi di
halaman statis |
| len_sec | Waktu sesi dalam hitungan detik |
| len_unique_uri | Jumlah permintaan per sesi yang
berisi URI unik |
| headers_cnt | Jumlah tajuk per sesi |
| has_cookie | Apakah ada tajuk cookie |
| has_referer | Apakah ada header Referer |
| mean_time_page | Waktu rata-rata per halaman per sesi |
| mean_time_request | Waktu rata-rata per permintaan per sesi |
| mean_headers | Jumlah rata-rata tajuk per sesi |
Beginilah cara pembentukan matriks fitur dan label kelas target untuk setiap sesi ditetapkan. Berdasarkan matriks ini, pelatihan model berkala dan pemilihan hyperparameter berikutnya terjadi. Untuk pelatihan, kami menggunakan: regresi logistik, mesin vektor pendukung, pohon keputusan, peningkatan gradien pada pohon keputusan, algoritma hutan acak. Hasil yang paling relevan diperoleh dengan menggunakan algoritma hutan acak.
Ramalan
Selama penguraian lalu lintas, vektor atribut sesi diperbarui di penyimpanan nilai kunci: saat permintaan baru muncul di sesi, atribut yang menjelaskannya akan dihitung ulang. Misalnya, jumlah rata - rata header dalam satu sesi (mean_headers) dihitung setiap kali permintaan baru ditambahkan ke sesi. Predictor mengirimkan vektor fitur sesi ke model, dan menulis respons dari model ke Elasticsearch untuk dianalisis.
Percobaan
Kami menguji solusi kami pada lalu lintas portal SecurityLab.ru . Volume data - lebih dari 15 GB, lebih dari 130 jam. Jumlah sesi lebih dari 10.000. Karena model yang diusulkan menggunakan fitur statistik, sesi yang berisi kurang dari 10 permintaan tidak dilibatkan dalam pelatihan dan pengujian. Kami menggunakan metrik kualitas klasik sebagai metrik kualitas - akurasi, kelengkapan, dan pengukuran F untuk setiap kelas.
Menguji model deteksi bot web
Kami akan membangun dan mengevaluasi model klasifikasi biner, yaitu, kami akan mendeteksi bot, dan kemudian mengklasifikasikannya berdasarkan jenis aktivitas. Berdasarkan hasil validasi silang bertingkat lima (inilah yang dibutuhkan untuk data yang sedang dipertimbangkan, karena ada ketidakseimbangan kelas yang kuat), dapat dikatakan bahwa model yang dibangun cukup baik (akurasi dan kelengkapan - lebih dari 98%) mampu memisahkan kelas pengguna manusia dan bot.
| Akurasi rata-rata | Kepenuhan rata-rata | Rata-rata ukuran F. | |
|---|---|---|---|
| bot | 0.86 | 0.90 | 0.88 |
| manusia | 0.98 | 0.97 | 0.97 |
Hasil pengujian model pada sampel yang ditangguhkan disajikan pada tabel di bawah ini.
| Ketepatan | Kelengkapan | F-ukuran | Jumlah
contoh |
|
|---|---|---|---|---|
| bot | 0.88 | 0.90 | 0.89 | 1816 |
| manusia | 0.98 | 0.98 | 0.98 | 9071 |
Nilai metrik kualitas pada sampel yang ditangguhkan kira-kira sama dengan nilai metrik kualitas selama validasi model, yang berarti bahwa model pada data ini dapat menggeneralisasi pengetahuan yang diperoleh selama pelatihan.
Mari kita pertimbangkan kesalahan jenis pertama. Jika data ini ditandai dengan ahli, maka matriks kesalahan akan berubah secara signifikan. Artinya, beberapa kesalahan telah dibuat saat mem-markup data untuk model, tetapi model masih dapat mengenali sesi tersebut dengan benar.
| Ketepatan | Kelengkapan | F-ukuran | Jumlah
contoh |
|
|---|---|---|---|---|
| bot | 0.93 | 0.92 | 0.93 | 2446 |
| manusia | 0.98 | 0.98 | 0.98 | 8441 |
Mari kita lihat contoh peniru sesi. Ini berisi 12 pertanyaan serupa. Salah satu permintaan tersebut ditunjukkan pada gambar di bawah ini.
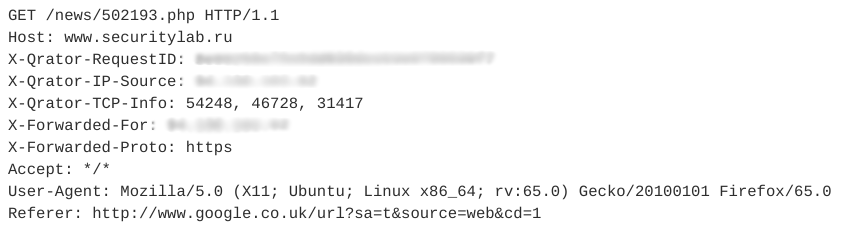
Semua permintaan berikutnya dalam sesi ini memiliki struktur yang sama dan hanya berbeda di URI.
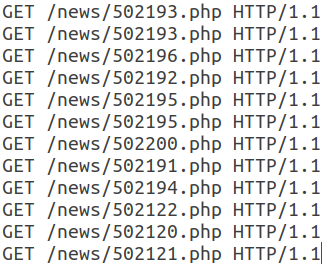
Perhatikan bahwa webbot ini menggunakan Agen-Pengguna yang valid, menambahkan bidang Perujuk, biasanya digunakan secara tidak otomatis, dan jumlah tajuk dalam satu sesi sedikit. Selain itu, karakteristik temporal permintaan - waktu sesi, waktu rata-rata per permintaan - memungkinkan kami untuk mengatakan bahwa aktivitas ini otomatis dan termasuk dalam kelas pembaca RSS. Dalam hal ini, bot itu sendiri menyamar sebagai pengguna biasa.
Menguji model klasifikasi bot web
Untuk mengklasifikasikan web bot berdasarkan jenis aktivitas, kita akan menggunakan data dan algoritma yang sama seperti pada percobaan sebelumnya. Hasil pengujian model pada sampel yang ditangguhkan disajikan pada tabel di bawah ini.
| Ketepatan | Kelengkapan | F-ukuran | Jumlah
contoh |
|
|---|---|---|---|---|
| bot | 0.82 | 0.81 | 0.82 | 194 |
| crawler | 0.87 | 0.72 | 0.79 | 65 |
| libs_tools | 0.27 | 0.17 | 0.21 | delapan belas |
| rss | 0.95 | 0.97 | 0.96 | 1823 |
| mesin pencari | 0.84 | 0.76 | 0.80 | 228 |
| jaringan sosial | 0.80 | 0.79 | 0.84 | 73 |
| tidak diketahui | 0.65 | 0.62 | 0.64 | 45 |
Kualitas untuk kategori libs_tools rendah, tetapi kurangnya contoh untuk evaluasi tidak memungkinkan kita untuk berbicara tentang kebenaran hasil. Rangkaian percobaan kedua harus dilakukan untuk mengklasifikasikan bot web pada lebih banyak data. Kami dapat mengatakan dengan yakin bahwa model saat ini dengan akurasi dan kelengkapan yang cukup tinggi dapat memisahkan kelas pembaca RSS, mesin telusur, dan bot umum.
Menurut eksperimen ini pada data yang sedang dipertimbangkan, lebih dari 22% sesi (dengan total volume lebih dari 15 GB) dibuat secara otomatis, dan di antaranya 87% terkait dengan aktivitas bot dengan orientasi umum, bot tidak dikenal, pembaca RSS, bot web menggunakan berbagai pustaka dan utilitas ... Jadi, jika Anda memfilter lalu lintas jaringan bot web menurut jenis aktivitasnya, pendekatan yang diusulkan akan mengurangi beban pada sumber daya server yang digunakan setidaknya 9-10%.
Menguji model klasifikasi bot web secara online
Inti dari percobaan ini adalah sebagai berikut: secara real time, setelah mengurai lalu lintas, fitur diidentifikasi dan vektor fitur dibentuk untuk setiap sesi. Secara berkala, setiap sesi dikirim ke model untuk prediksi, yang hasilnya disimpan.
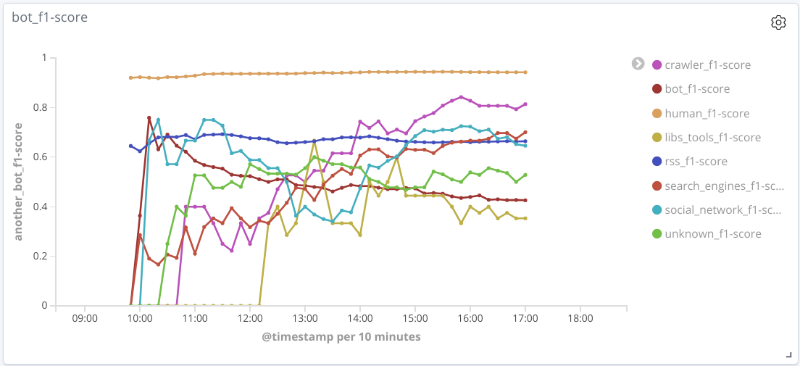
F-pengukuran model dari waktu ke waktu untuk setiap kelas
Grafik di bawah ini menggambarkan perubahan nilai metrik kualitas dari waktu ke waktu untuk kelas yang paling menarik. Besar kecilnya poin terkait dengan jumlah sesi dalam sampel pada waktu tertentu.

Presisi, kelengkapan, Pengukuran-F untuk kelas mesin pencari

Presisi, kelengkapan, Pengukuran-F untuk kelas alat libs
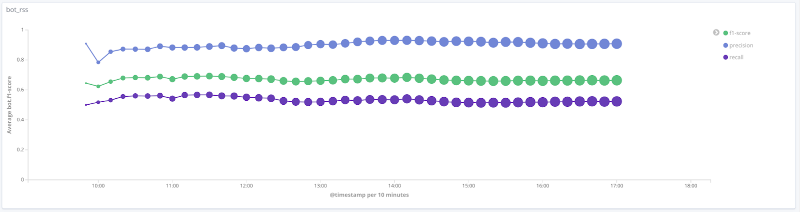
Presisi, kelengkapan, Pengukuran-F untuk kelas rss

Presisi, kelengkapan, Pengukuran-F untuk kelas perayap

Presisi, kelengkapan, Pengukuran-F untuk kelas manusia
Untuk sejumlah kelas (human, rss, search_engines) pada data yang dipertimbangkan, kualitas model dapat diterima (akurasi dan kelengkapan lebih dari 80%). Untuk kelas perayap, dengan peningkatan jumlah sesi dan perubahan kualitatif dalam vektor fitur untuk sampel ini, kualitas model meningkat: kelengkapan meningkat dari 33% menjadi 80%. Tidak mungkin untuk menarik kesimpulan yang masuk akal untuk kelas libs_tools, karena jumlah contoh untuk kelas ini kecil (kurang dari 50); oleh karena itu, hasil negatif (kualitas buruk) tidak dapat dikonfirmasi.
Hasil utama dan pengembangan lebih lanjut
Kami telah menjelaskan satu pendekatan untuk mendeteksi dan mengklasifikasikan bot web menggunakan algoritme pembelajaran mesin dan menggunakan fitur statistik. Pada data yang dipertimbangkan, rata-rata akurasi dan kelengkapan solusi yang diusulkan untuk klasifikasi biner lebih dari 95%, yang menunjukkan bahwa pendekatan tersebut menjanjikan. Untuk kelas bot web tertentu, akurasi dan kelengkapan rata-rata sekitar 80%.
Validasi model yang dibangun membutuhkan penilaian sesi yang sebenarnya. Seperti yang ditunjukkan sebelumnya, kinerja model meningkat secara signifikan ketika markup yang benar tersedia untuk kelas target. Sayangnya, sekarang sulit untuk secara otomatis membangun markup seperti itu dan Anda harus menggunakan markup ahli, yang memperumit konstruksi model pembelajaran mesin, tetapi memungkinkan Anda menemukan pola tersembunyi dalam data.
Untuk pengembangan lebih lanjut masalah klasifikasi dan deteksi bot web, disarankan untuk:
- alokasikan kelas bot tambahan dan latih kembali, uji modelnya;
- tambahkan tanda tambahan untuk mengklasifikasikan bot web. Misalnya, menambahkan atribut robots.txt, yang merupakan biner dan bertanggung jawab atas ada atau tidaknya akses ke halaman robots.txt, memungkinkan Anda untuk meningkatkan skor F rata-rata untuk kelas bot web sebesar 3%, tanpa memperburuk kualitas metrik lainnya untuk kelas lain;
- membuat markup yang lebih tepat untuk kelas target, dengan mempertimbangkan fitur meta tambahan dan penilaian ahli.
Penulis : Nikolay Lyfenko, Spesialis Terkemuka, Grup Teknologi Canggih, Teknologi Positif
Sumber
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.