Untuk memahami bagaimana indeks B-tree terbentuk, mari kita bayangkan dunia tanpa indeks dan mencoba memecahkan masalah yang khas. Sepanjang jalan, kita akan membahas masalah yang akan kita hadapi dan cara mengatasinya.

pengantar
Dalam dunia database, ada dua cara paling umum untuk menyimpan informasi:
- Berdasarkan struktur berbasis Log.
- Berdasarkan halaman.
Keuntungan dari metode pertama adalah memungkinkan Anda untuk membaca dan menyimpan data dengan mudah dan cepat. Informasi baru hanya dapat ditulis di akhir file (perekaman berurutan), yang memastikan kecepatan perekaman tinggi. Metode ini digunakan oleh basis seperti Leveldb, Rocksdb, Cassandra.
Metode kedua (berbasis halaman) membagi data menjadi potongan berukuran tetap dan menyimpannya ke disk. Bagian ini disebut "halaman" atau "blok". Mereka berisi catatan (baris, tupel) dari tabel.
Metode penyimpanan data ini digunakan oleh MySQL, PostgreSQL, Oracle dan lainnya. Dan karena kita berbicara tentang indeks di MySQL, inilah pendekatan yang akan kita pertimbangkan.
Penyimpanan data di MySQL
Jadi, semua data di MySQL disimpan ke disk sebagai halaman. Ukuran halaman diatur oleh pengaturan database dan 16 KB secara default.
Setiap halaman berisi 38 byte header dan akhir 8-byte (seperti yang ditunjukkan pada gambar). Dan ruang yang dialokasikan untuk penyimpanan data tidak sepenuhnya terisi, karena MySQL menyisakan ruang kosong di setiap halaman untuk perubahan di masa mendatang.
Lebih lanjut dalam perhitungan, kami akan mengabaikan informasi layanan, dengan asumsi bahwa semua 16 KB halaman diisi dengan data kami. Kami tidak akan masuk jauh ke dalam organisasi halaman InnoDB, ini adalah topik untuk artikel terpisah. Anda dapat membaca lebih lanjut tentang ini di sini .

Karena kita telah sepakat di atas bahwa indeks belum ada, misalnya, kita akan membuat tabel sederhana tanpa indeks apa pun (sebenarnya, MySQL akan tetap membuat indeks, tetapi kita tidak akan memperhitungkannya dalam perhitungan):
CREATE TABLE `product` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` CHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`category_id` INT NOT NULL,
`price` INT NOT NULL,
) ENGINE=InnoDB;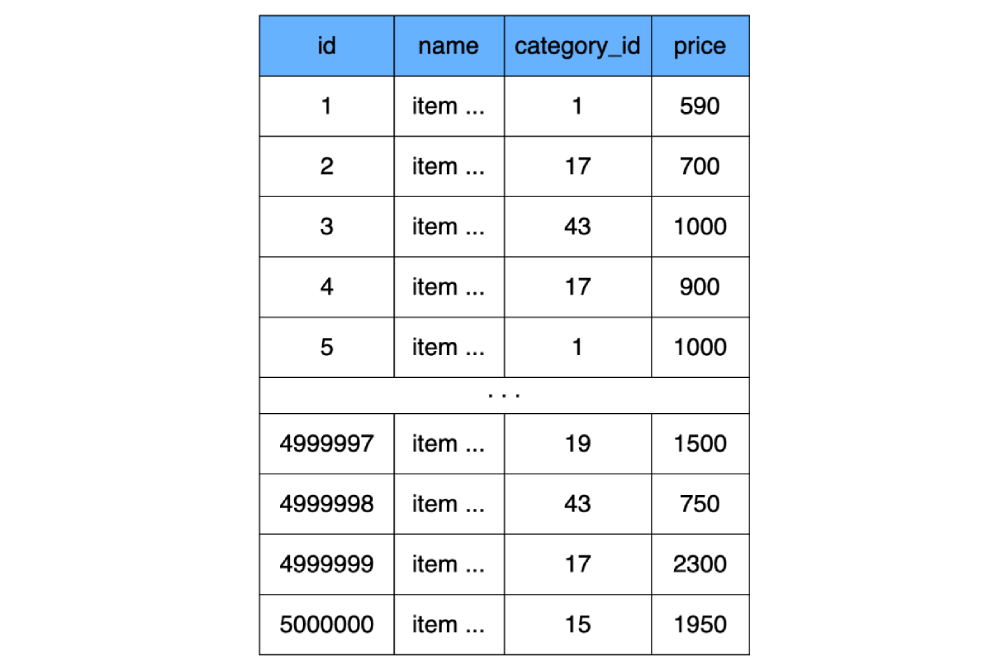
dan jalankan permintaan berikut:
SELECT * FROM product WHERE price = 1950;MySQL akan membuka file tempat data dari tabel disimpan
productdan mulai mengulang semua catatan (baris) untuk mencari yang diperlukan, membandingkan bidang pricedari setiap baris yang ditemukan dengan nilai dalam kueri. Untuk kejelasan, saya secara khusus mempertimbangkan opsi dengan pemindaian penuh file, jadi kasus ketika MySQL menerima data dari cache tidak cocok untuk kami.
Masalah apa yang bisa kita hadapi dengan ini?
HDD
Karena kita memiliki semua yang tersimpan di hard drive, mari kita lihat perangkatnya. Hard disk membaca dan menulis data di sektor (blok). Ukuran sektor seperti itu bisa dari 512 byte hingga 8 KB (tergantung pada disk). Beberapa sektor yang berurutan dapat digabungkan menjadi beberapa cluster.
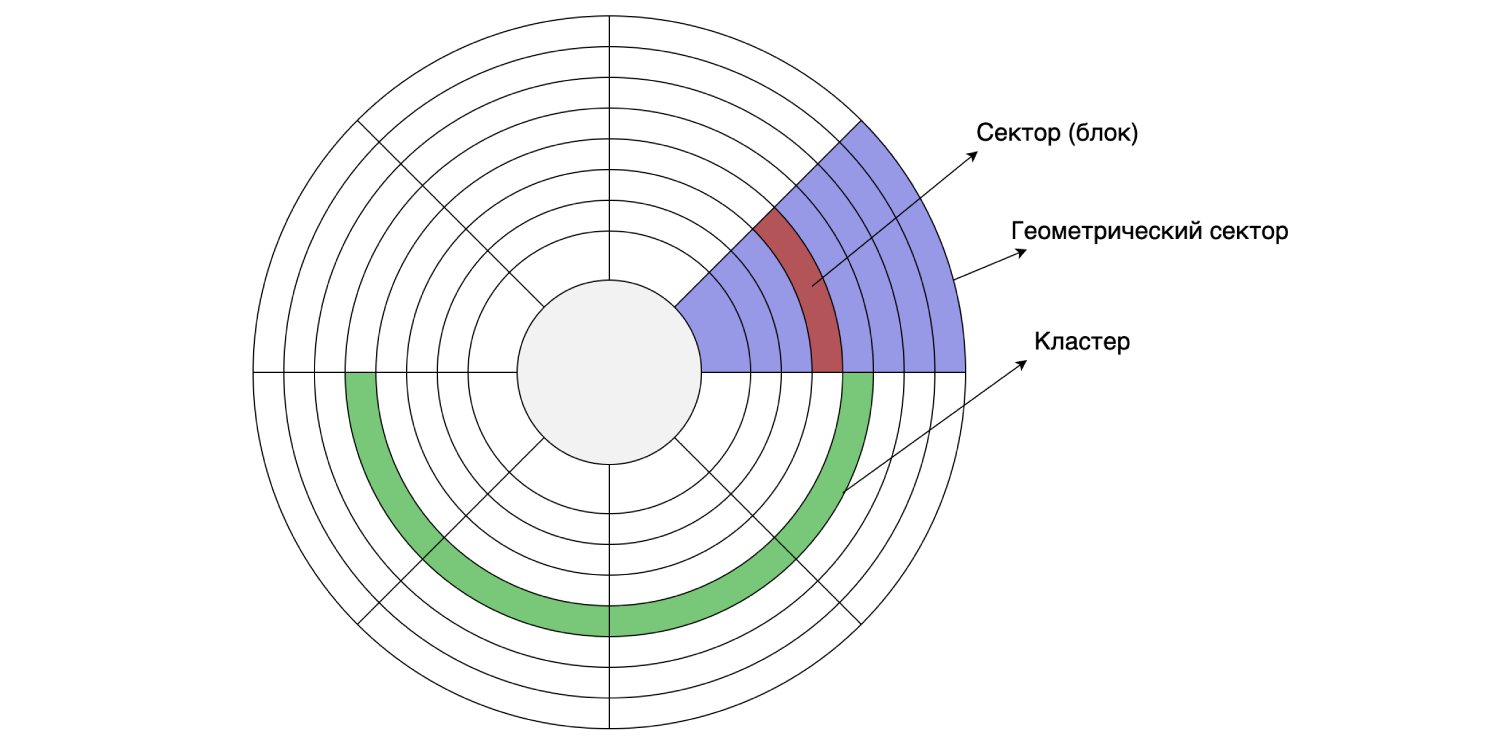
Ukuran cluster dapat diatur saat memformat / mempartisi disk, yaitu dilakukan secara terprogram. Misalkan ukuran sektor pada disk adalah 4 KB, dan sistem file dipartisi dengan ukuran cluster 16 KB: satu cluster terdiri dari empat sektor. Seperti yang kita ingat, MySQL secara default menyimpan data pada disk dalam 16 halaman KB, jadi satu halaman cocok untuk satu cluster disk.
Mari kita hitung berapa banyak ruang yang akan digunakan oleh plat produk kita, dengan asumsi plat tersebut menyimpan 500.000 item. Kami memiliki tiga bidang empat-byte
id, pricedan category_id. Mari kita sepakati bahwa field nama untuk semua record diisi sampai akhir (semua 100 karakter), dan setiap karakter membutuhkan 3 byte. (3 * 4) + (100 * 3) = 312 byte - ini adalah berat satu baris tabel kita, dan mengalikannya dengan 500.000 baris, kita mendapatkan bobot tabel product156 megabyte.
Jadi, untuk menyimpan label ini, diperlukan 9750 cluster pada hard disk (9750 halaman 16 KB).
Saat menyimpan ke disk, kluster bebas diambil, yang mengarah ke "noda" kluster dari satu pelat (file) di seluruh disk (ini disebut fragmentasi). Membaca blok memori yang ditempatkan secara acak pada disk disebut pembacaan acak. Pembacaan ini lebih lambat karena Anda harus menggerakkan kepala hard disk berkali-kali. Untuk membaca seluruh file, kita harus melompati seluruh disk untuk mendapatkan cluster yang diperlukan.
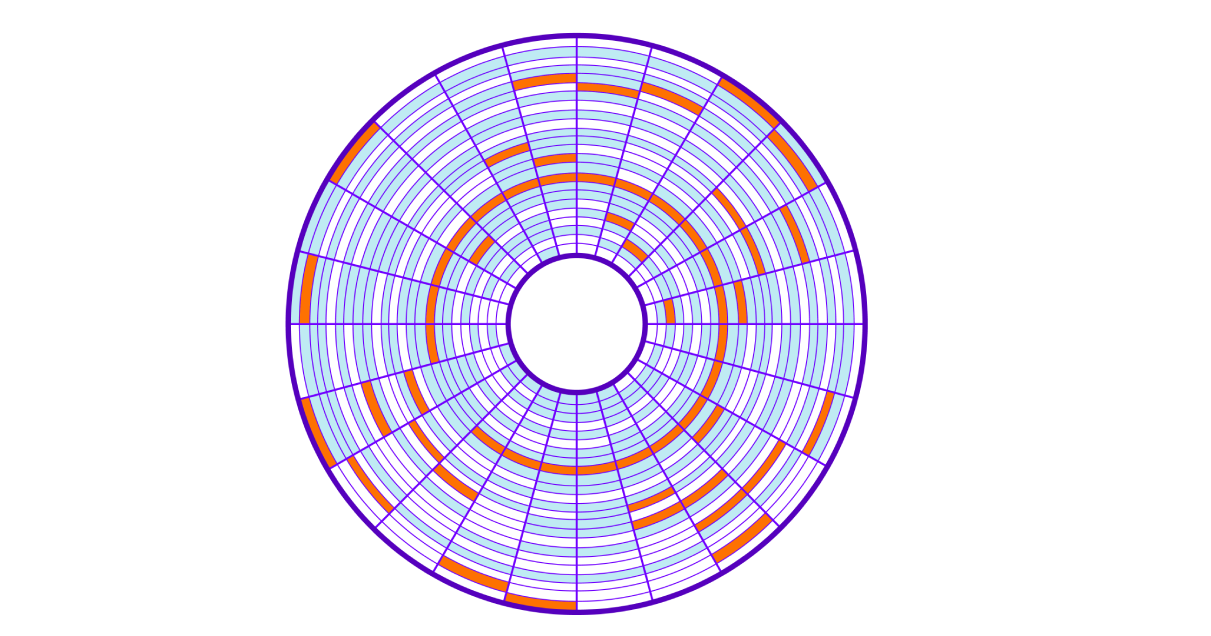
Mari kembali ke kueri SQL kami. Untuk menemukan semua baris, server harus membaca semua 9750 cluster yang tersebar di seluruh disk, dan akan membutuhkan banyak waktu untuk memindahkan kepala baca disk. Semakin banyak cluster yang kami gunakan data kami, semakin lambat data itu akan dicari. Selain itu, operasi kami akan menyumbat sistem I / O sistem operasi.
Pada akhirnya, kami mendapatkan kecepatan baca yang rendah; "Menunda" OS, menyumbat sistem I / O; dan melakukan banyak perbandingan, memeriksa kondisi kueri untuk setiap baris.
Sepedaku sendiri
Bagaimana kita bisa mengatasi masalah ini sendiri?
Kita perlu mencari cara untuk meningkatkan pencarian tabel
product. Mari buat tabel lain di mana kita hanya akan menyimpan field pricedan link ke record (area pada disk) di tabel kita product. Mari segera kita anggap sebagai aturan bahwa saat menambahkan data ke tabel baru, kita akan menyimpan harga dalam bentuk yang diurutkan.
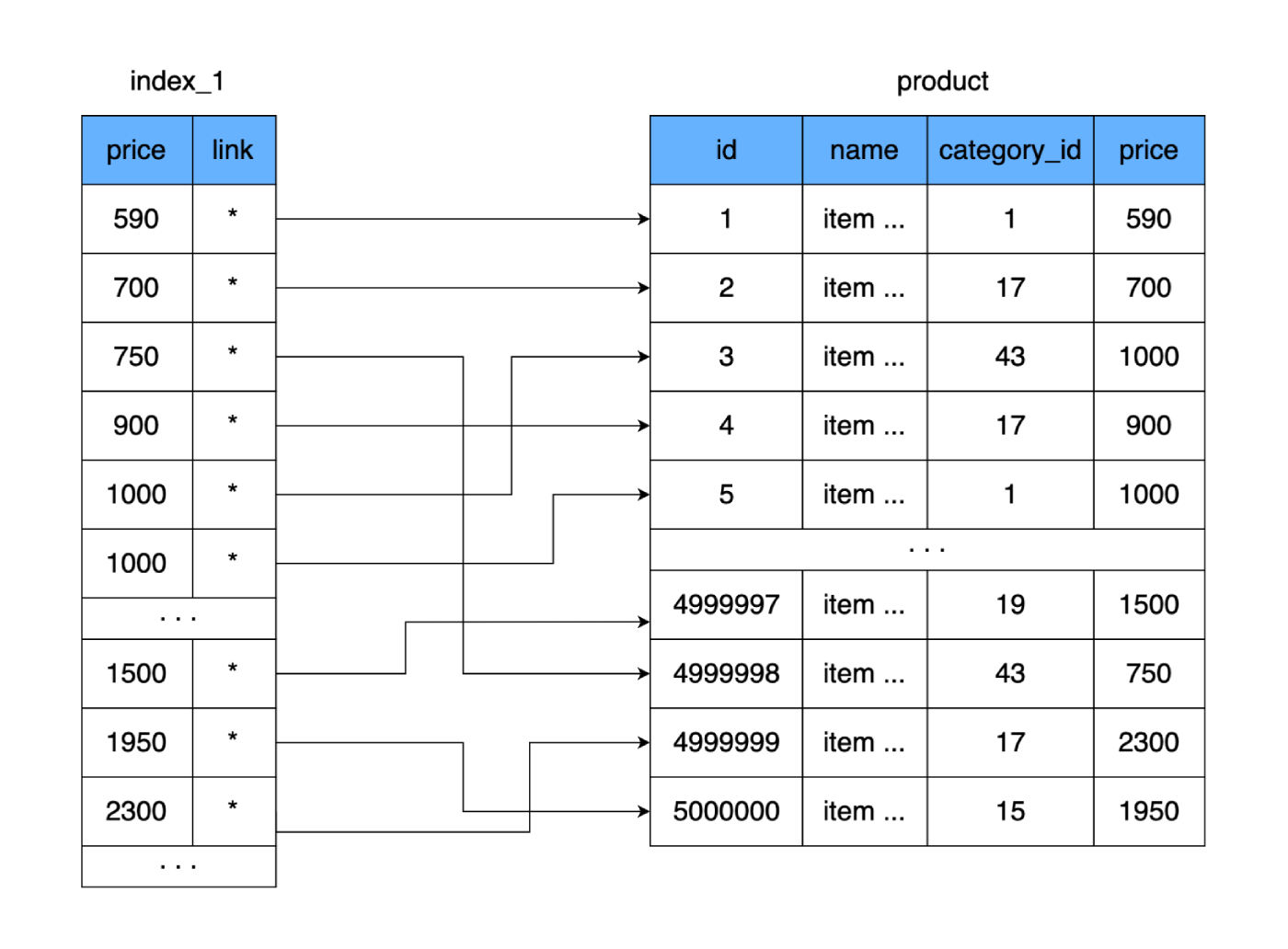
Apa yang diberikannya kepada kita? Tabel baru, seperti yang utama, disimpan pada disk halaman demi halaman (dalam blok). Ini berisi harga dan tautan ke meja utama. Mari kita hitung berapa banyak ruang yang dibutuhkan tabel seperti itu. Harganya membutuhkan 4 byte, dan biarkan referensi ke tabel utama (alamat) menjadi 4 byte juga. Untuk 500.000 baris, tabel baru kami hanya akan berbobot 4 MB. Dengan begitu, lebih banyak baris dari tabel baru akan muat di satu halaman data, dan lebih sedikit halaman yang dibutuhkan untuk menyimpan semua harga kami.
Jika tabel lengkap memerlukan 9.750 cluster hard disk (skenario terburuk, 9.750 hard disk hop), maka tabel baru hanya cocok untuk 250 cluster. Ini akan sangat mengurangi jumlah cluster yang digunakan pada disk, dan karenanya waktu yang dihabiskan untuk pembacaan acak. Bahkan jika kita membaca seluruh tabel baru dan membandingkan nilai untuk menemukan harga yang tepat, dalam kasus terburuk, akan membutuhkan 250 lompatan di seluruh kluster tabel baru. Dan setelah menemukan alamat yang dibutuhkan, kita akan membaca cluster lain dimana data lengkap berada. Hasil: 251 bacaan versus 9750 asli. Perbedaannya signifikan.
Selain itu, untuk mencari tabel seperti itu, Anda dapat menggunakan, misalnya, algoritma pencarian biner (karena daftarnya diurutkan). Ini akan menghemat lebih banyak lagi jumlah operasi pembacaan dan perbandingan.
Mari kita sebut tabel kedua kita sebagai indeks.
Hore! Kami telah membuat indeks
Tapi hentikan: seiring pertumbuhan tabel, indeks juga akan semakin besar, dan akhirnya kita akan kembali ke masalah semula. Pencarian akan memakan waktu lama lagi.
Indeks lain
Dan jika Anda membuat indeks lain di atas yang sudah ada?
Hanya saja kali ini kami tidak akan menuliskan setiap nilai bidang
price, tetapi kami akan mengasosiasikan satu nilai dengan seluruh halaman (blok) dari indeks. Artinya, level indeks tambahan akan muncul, yang akan mengarah ke kumpulan data dari indeks sebelumnya (halaman di disk tempat data dari indeks pertama disimpan).
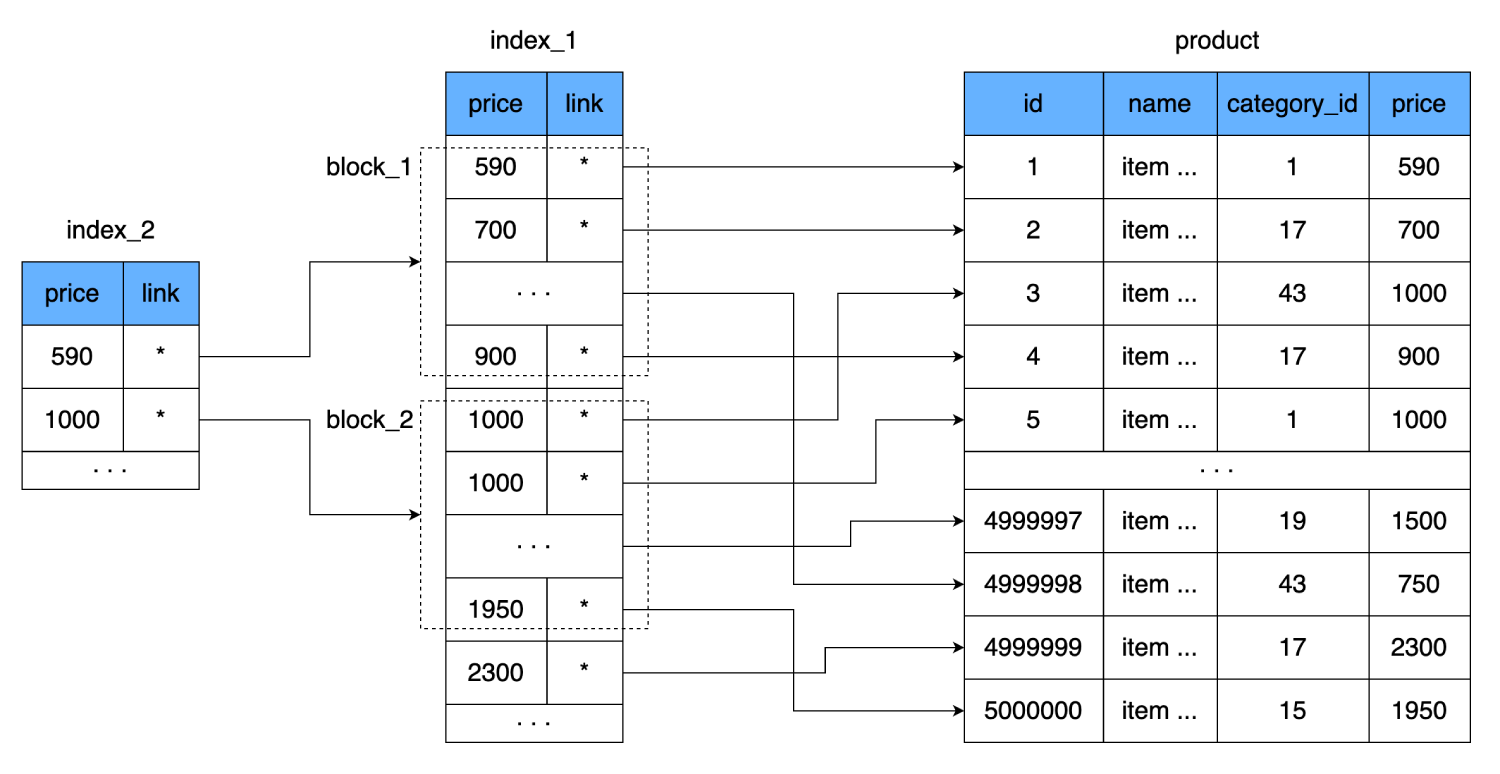
Ini selanjutnya akan mengurangi jumlah pembacaan. Satu baris indeks kami membutuhkan 8 byte, yaitu, kami dapat memuat 2000 baris seperti itu pada satu halaman 16-kilobyte. Indeks baru akan berisi link ke blok 2000 baris dari indeks pertama dan harga dari mana blok ini dimulai. Satu baris seperti itu juga membutuhkan 8 byte, tetapi jumlahnya berkurang tajam: bukannya 500.000, hanya 250. Mereka bahkan masuk ke dalam satu cluster hard disk. Jadi, untuk menemukan harga yang dibutuhkan, kita akan dapat menentukan dengan tepat di blok mana dari 2000 garis itu berada. Dan dalam kasus terburuk, untuk menemukan catatan yang sama, kami:
- Mari kita membaca dari indeks baru.
- Setelah menjalankan 250 baris, kami menemukan tautan ke blok data dari indeks kedua.
- Pertimbangkan satu cluster yang berisi 2000 baris dengan harga dan link ke tabel utama.
- Setelah memeriksa 2000 baris ini, kita akan menemukan satu kali lagi lompatan yang diperlukan melintasi disk untuk membaca blok data terakhir.
Kami akan mendapatkan total 3 lompatan cluster.
Namun cepat atau lambat level ini juga akan terisi banyak data. Oleh karena itu, kami harus mengulangi semua yang telah kami lakukan, menambahkan level baru berulang kali. Artinya, kita memerlukan struktur data untuk menyimpan indeks, yang akan menambah level baru seiring dengan bertambahnya ukuran indeks dan secara independen menyeimbangkan data di antara keduanya.
Jika kita membalik tabel sehingga indeks terakhir berada di atas dan tabel utama dengan data di bawah, kita mendapatkan struktur yang sangat mirip dengan pohon.
Struktur data B-tree bekerja dengan prinsip yang sama, sehingga dipilih untuk tujuan ini.
Singkatnya B-tree
Indeks yang paling umum digunakan di MySQL adalah indeks terurut B-tree (balanced search tree) .
Ide umum dari pohon-B mirip dengan tabel indeks kami. Nilai disimpan secara berurutan dan semua daun pohon berada pada jarak yang sama dari akar.
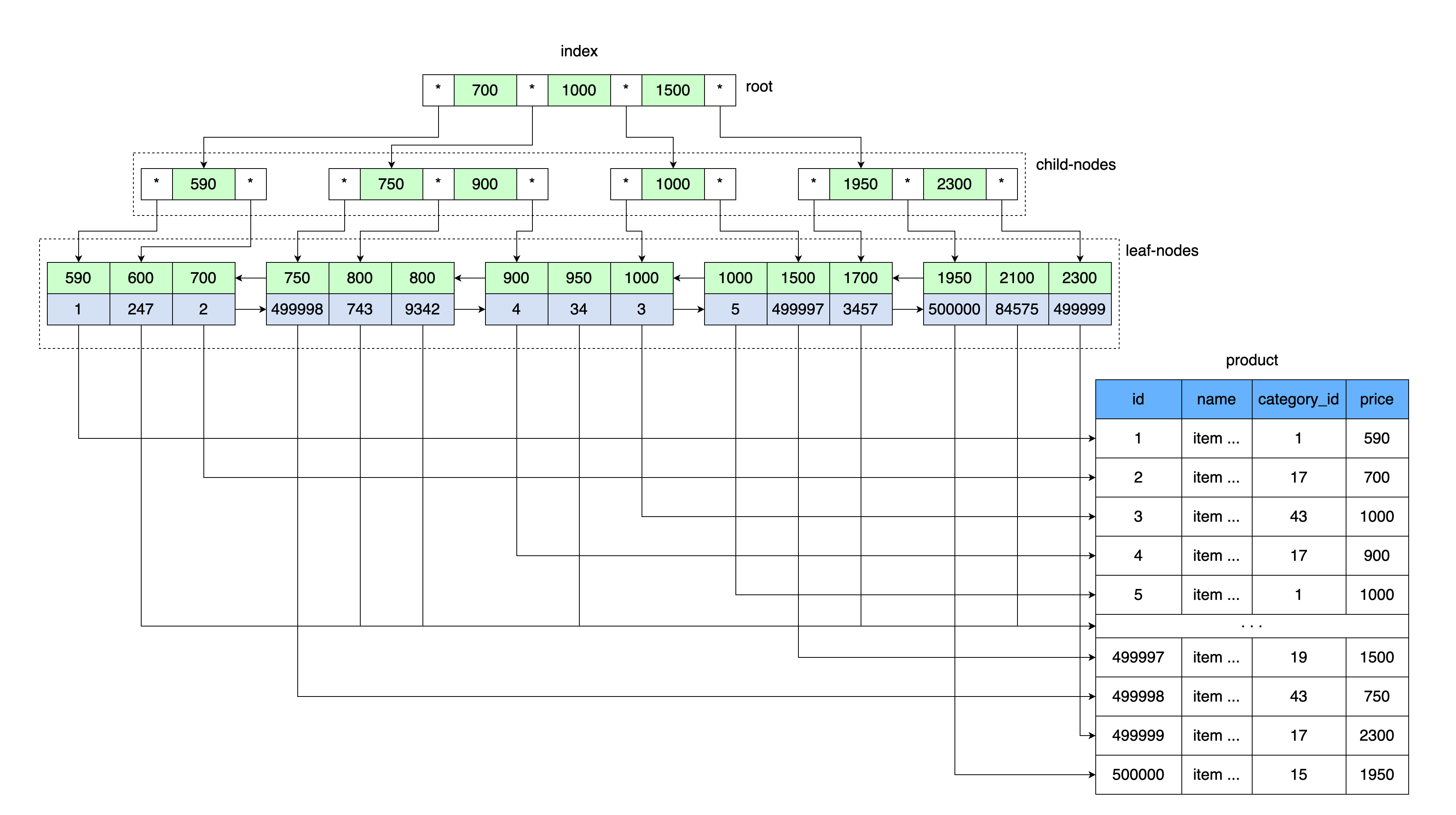
Sama seperti tabel kami dengan indeks yang menyimpan nilai harga dan tautan ke blok data yang berisi rentang nilai dengan harga ini, demikian pula akar pohon-B menyimpan nilai harga dan tautan ke area memori pada disk.
Pertama, halaman yang berisi root dari B-tree dibaca. Selanjutnya, setelah memasukkan rentang kunci, ada penunjuk ke simpul anak yang diinginkan. Halaman node anak dibaca, dari mana link ke lembar data diambil dari nilai kunci, dan halaman dengan data dibaca dari link ini.
B-tree di InnoDB
Lebih khusus lagi, InnoDB menggunakan struktur data pohon B +.
Setiap kali Anda membuat tabel, Anda secara otomatis membuat pohon B +, karena MySQL menyimpan indeks seperti itu untuk kunci primer dan sekunder.
Kunci sekunder juga menyimpan nilai kunci primer (cluster) sebagai referensi ke baris data. Akibatnya, kunci sekunder tumbuh sesuai ukuran nilai kunci primer.
Selain itu, pohon B + menggunakan tautan tambahan di antara node turunan, yang meningkatkan kecepatan penelusuran di berbagai nilai. Baca lebih lanjut tentang struktur indeks b + tree di InnoDB di sini .
Menyimpulkan
Indeks b-tree memberikan keuntungan besar saat mencari data pada berbagai nilai dengan secara dramatis mengurangi jumlah informasi yang dibaca dari disk. Ini berpartisipasi tidak hanya selama pencarian berdasarkan kondisi, tetapi juga selama sortir, penggabungan, pengelompokan. Baca bagaimana MySQL menggunakan indeks di sini .
Sebagian besar kueri ke database hanyalah kueri untuk menemukan informasi berdasarkan nilai atau rentang nilai. Oleh karena itu, di MySQL, indeks yang paling umum digunakan adalah indeks b-tree.
Juga, indeks b-tree membantu saat mengambil data. Karena kunci utama (indeks berkerumun) dan nilai kolom tempat indeks non-cluster dibuat (kunci sekunder) disimpan di daun indeks, Anda tidak dapat lagi mengakses tabel utama untuk data ini dan mengambilnya dari indeks. Ini disebut indeks penutup. Anda dapat menemukan informasi selengkapnya tentang indeks berkerumun dan non-berkerumun di artikel ini .
Indeks, seperti tabel, juga disimpan di disk dan menghabiskan ruang. Setiap kali Anda menambahkan informasi ke tabel, indeks harus selalu diperbarui, untuk memantau kebenaran semua tautan antar node. Ini menciptakan overhead dalam menulis informasi, yang merupakan kelemahan utama indeks b-tree. Kami mengorbankan kecepatan tulis untuk meningkatkan kecepatan baca.
- MySQL . 3-
: ,
: 2018 - blog.jcole.us/innodb
- dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html