
Danau-danau ini (Danau Data ) sebenarnya menjadi standar bagi bisnis dan perusahaan yang mencoba menggunakan semua informasi yang tersedia bagi mereka. Komponen open source sering kali menjadi pilihan yang menarik saat mengembangkan data lake yang besar. Kami akan melihat pola arsitektur umum yang diperlukan untuk membuat danau data untuk solusi cloud atau hybrid, dan juga menyoroti sejumlah detail penting yang harus diperhatikan saat menerapkan komponen utama.
Desain aliran data
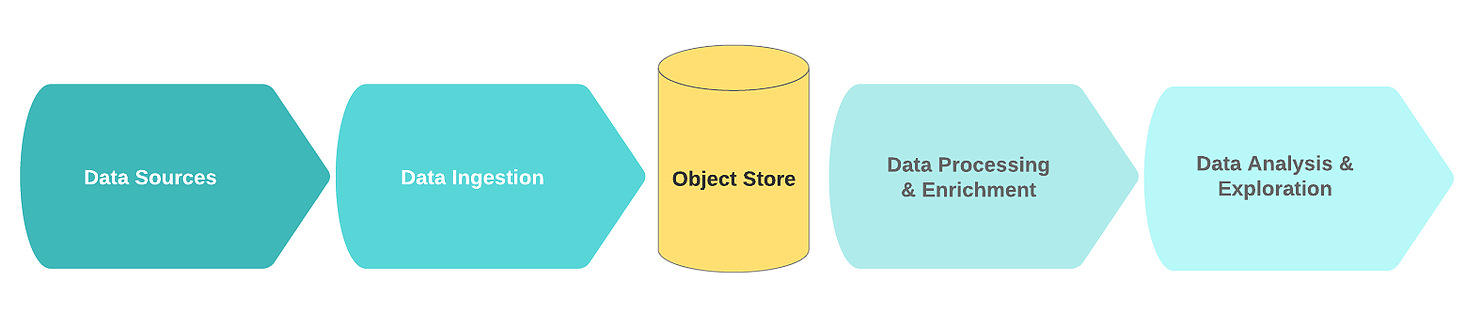
Aliran danau data logis yang khas mencakup blok fungsional berikut:
- Sumber data;
- Menerima data;
- Node penyimpanan;
- Pemrosesan dan pengayaan data;
- Analisis data.
Dalam konteks ini, sumber data biasanya berupa aliran atau kumpulan data peristiwa mentah (misalnya, log, klik, telemetri IoT, transaksi).
Fitur utama dari sumber tersebut adalah bahwa data mentah disimpan dalam bentuk aslinya. Kebisingan dalam data ini biasanya terdiri dari rekaman duplikat atau tidak lengkap dengan bidang yang berlebihan atau salah.
Pada tahap penyerapan, data mentah berasal dari satu atau beberapa sumber data. Mekanisme penerimaan paling sering diimplementasikan dalam bentuk satu atau lebih antrian pesan dengan komponen sederhana yang bertujuan untuk membersihkan dan menyimpan data primer. Untuk membangun data lake yang efisien, dapat diskalakan, dan konsisten, disarankan untuk membedakan antara pembersihan data sederhana dan tugas pengayaan data yang lebih kompleks. Salah satu aturan praktis yang baik adalah bahwa tugas pembersihan memerlukan data dari satu sumber dalam jendela geser.
Teks tersembunyi
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
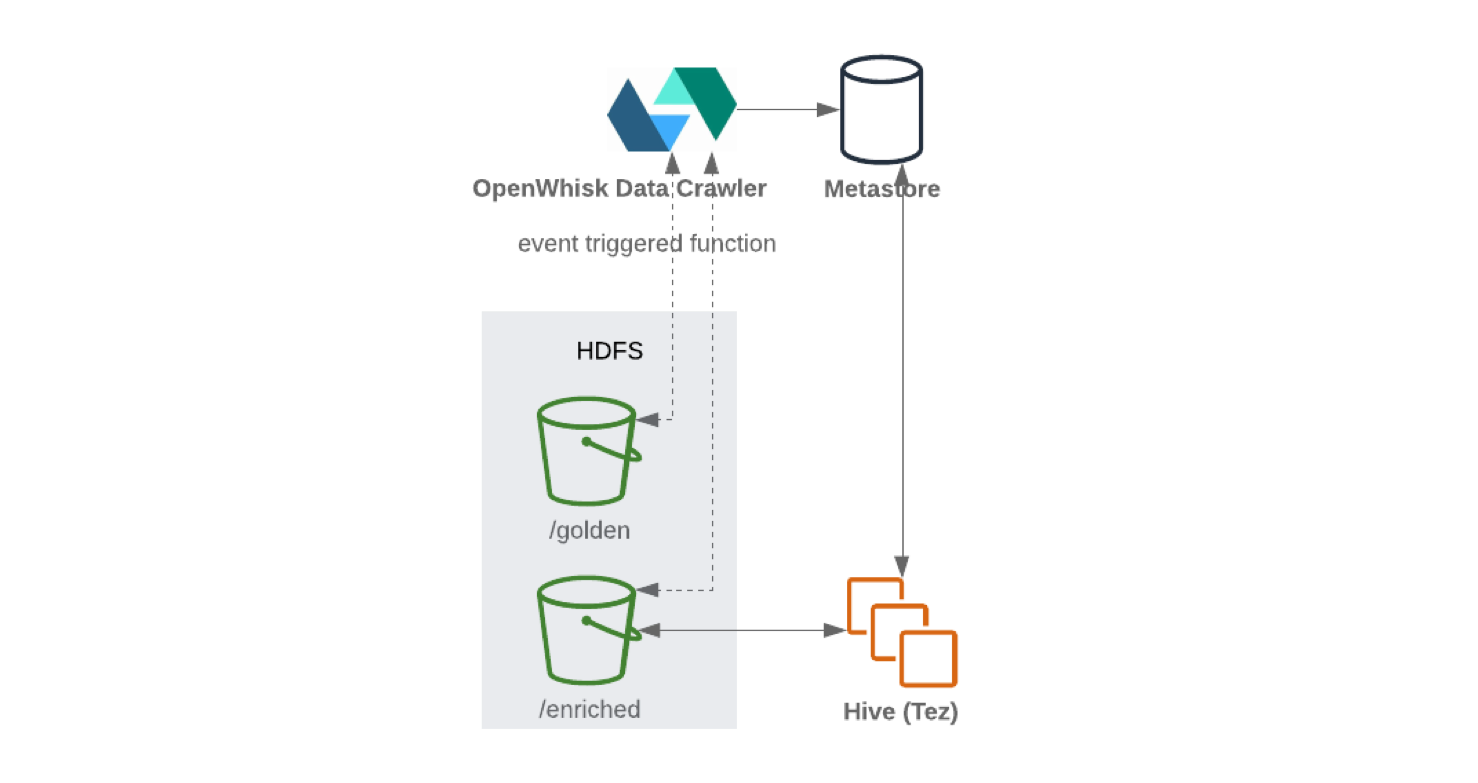
Setelah data diterima dan dibersihkan, data disimpan dalam sistem file terdistribusi (untuk meningkatkan toleransi kesalahan). Data sering kali ditulis dalam format tabel. Saat informasi baru ditulis ke node penyimpanan, katalog data yang berisi skema dan metadata dapat diperbarui menggunakan crawler offline. Peluncuran crawler biasanya dipicu oleh peristiwa, misalnya, saat objek baru tiba di penyimpanan. Repositori biasanya terintegrasi dengan katalog mereka. Mereka membongkar skema yang mendasari sehingga data dapat diakses.
Kemudian data tersebut masuk ke area khusus yang didedikasikan untuk "data emas". Mulai saat ini, data siap untuk diperkaya oleh proses lain.
Teks tersembunyi
, , .
Selama proses pengayaan, data juga diubah dan dibersihkan sesuai dengan logika bisnis. Hasilnya, mereka disimpan dalam format terstruktur di gudang data atau database yang digunakan untuk mengambil informasi, analitik, atau model pelatihan dengan cepat.
Terakhir, penggunaan data adalah analitik dan penelitian. Di sinilah informasi yang diekstrak diubah menjadi ide bisnis melalui visualisasi, dasbor, dan laporan. Selain itu, data ini adalah sumber untuk memperkirakan menggunakan pembelajaran mesin, yang hasilnya membantu membuat keputusan yang lebih baik.
Komponen platform
Infrastruktur cloud data lake memerlukan yang kuat, dan dalam kasus sistem cloud hybrid, lapisan abstraksi terpadu yang dapat membantu menerapkan, mengoordinasikan, dan menjalankan tugas komputasi tanpa kendala penyedia API.
Kubernetes adalah alat yang hebat untuk pekerjaan ini. Ini memungkinkan Anda untuk menyebarkan, mengatur, dan menjalankan berbagai layanan dan tugas komputasi data lake secara efisien dengan cara yang andal dan hemat biaya. Ini menawarkan API terpadu yang akan berfungsi baik di lokal maupun di cloud publik atau pribadi.
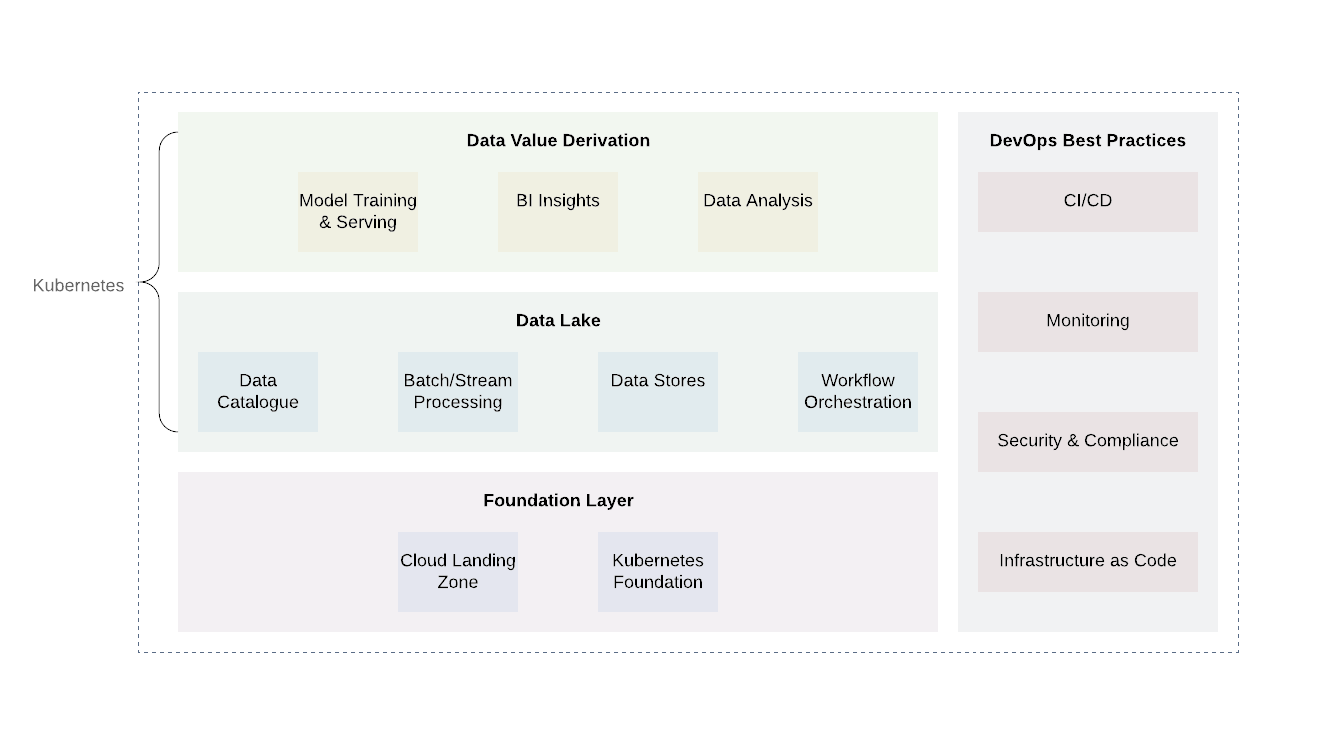
Platform secara kasar dapat dibagi menjadi beberapa lapisan. Lapisan dasar adalah tempat kami menerapkan Kubernetes atau yang setara. Lapisan dasar juga dapat digunakan untuk menangani tugas komputasi di luar domain data lake. Saat menggunakan penyedia cloud, akan menjanjikan untuk menggunakan praktik penyedia cloud yang sudah mapan (logging dan audit, desain akses minimum, pemindaian dan pelaporan kerentanan, arsitektur jaringan, arsitektur IAM, dll.) Ini akan mencapai tingkat keamanan dan kepatuhan yang diperlukan dengan persyaratan lain ...
Ada dua tingkat tambahan di atas tingkat dasar - data lake itu sendiri dan tingkat keluaran nilai. Kedua lapisan ini bertanggung jawab atas inti logika bisnis serta pemrosesan data. Meskipun ada banyak teknologi untuk kedua tingkatan ini, Kubernetes sekali lagi akan terbukti menjadi pilihan yang baik karena fleksibilitasnya untuk mendukung berbagai tugas komputasi.
Lapisan danau data mencakup semua layanan yang diperlukan untuk menerima ( Kafka , Kafka Connect ), pemfilteran, pengayaan, dan pemrosesan ( Flink dan Spark ), manajemen alur kerja ( Aliran Udara ). Selain itu, ini mencakup penyimpanan data dan sistem file terdistribusi ( HDFS) serta database RDBMS dan NoSQL .
Level paling atas adalah mendapatkan nilai data. Intinya, ini adalah tingkat konsumsi. Ini mencakup komponen seperti alat visualisasi untuk memahami kecerdasan bisnis, alat penambangan data ( Jupyter Notebooks ). Proses penting lainnya yang terjadi pada level ini adalah pembelajaran mesin menggunakan sampel pelatihan dari data lake.
Penting untuk dicatat bahwa bagian integral dari setiap data lake adalah penerapan praktik DevOps yang umum: infrastruktur sebagai kode, kemampuan observasi, audit, dan keamanan. Mereka memainkan peran penting dalam memecahkan masalah sehari-hari dan harus diterapkan di setiap tingkat untuk memastikan standarisasi, keamanan, dan kemudahan penggunaan.
, — , opensource-.
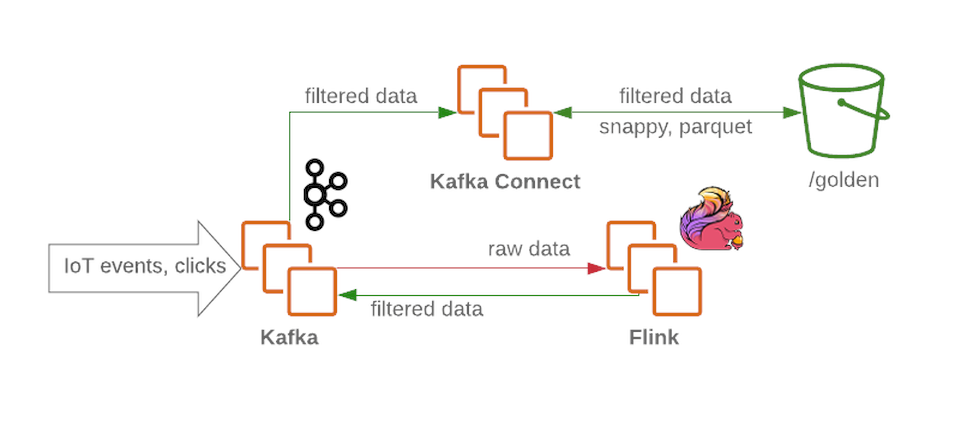
Cluster Kafka akan menerima pesan yang tidak difilter dan belum diproses dan akan berfungsi sebagai node penerima di data lake. Kafka menyediakan pesan throughput tinggi dengan cara yang andal. Sebuah cluster biasanya berisi beberapa bagian untuk data mentah, diproses (untuk streaming), dan data yang tidak terkirim atau rusak.
Flink menerima pesan dari node data mentah dari Kafka , memfilter data dan melakukan pra-memperkaya data jika perlu. Data tersebut kemudian diteruskan kembali ke Kafka (di bagian terpisah untuk data yang difilter dan kaya). Jika terjadi kegagalan, atau saat logika bisnis berubah, pesan ini dapat dipanggil lagi, karena tempat mereka disimpanKafka . Ini adalah solusi umum untuk proses streaming. Sementara itu, Flink menulis semua pesan dalam format yang salah ke bagian lain untuk analisis lebih lanjut.
Dengan menggunakan Kafka Connect, kami mendapatkan kemampuan untuk menyimpan data ke backend penyimpanan data yang diperlukan (seperti zona emas di HDFS ). Kafka Connect mudah diskalakan dan akan membantu Anda dengan cepat meningkatkan jumlah proses bersamaan dengan meningkatkan throughput di bawah beban berat:
Saat menulis dari Kafka Connect ke HDFS, disarankan untuk melakukan pemisahan konten untuk penanganan data yang efisien (semakin sedikit data yang dipindai, semakin sedikit permintaan dan tanggapan). Setelah data ditulis ke HDFS , fungsionalitas tanpa server (seperti OpenWhisk atau Knative ) akan memperbarui metadata dan penyimpanan parameter skema secara berkala. Hasilnya, skema yang diperbarui dapat diakses melalui antarmuka mirip SQL (misalnya, Hive atau Presto ).
Apache Airflow dapat digunakan untuk aliran data dan kontrol proses ETL selanjutnya . Ini memungkinkan pengguna untuk menjalankan piplines multi-langkah pemrosesan data menggunakan objek Python dan Directed Acyclic Graph ( DAG ). Pengguna dapat menentukan dependensi, proses kompleks program, dan melacak tugas melalui antarmuka grafis. Apache Airflow juga dapat menangani semua data eksternal. Misalnya, untuk menerima data melalui API eksternal dan menyimpannya dalam penyimpanan persisten. Spark didukung oleh Apache Airflow
melalui plugin khusus, secara berkala dapat memperkaya data mentah yang difilter sesuai dengan tujuan bisnis, dan menyiapkan data untuk penelitian oleh ilmuwan data dan analis bisnis. Data Scientist dapat menggunakan JupyterHub untuk mengelola beberapa Notebook Jupyter . Oleh karena itu, perlu menggunakan Spark untuk mengonfigurasi antarmuka multi-pengguna untuk bekerja dengan data, mengumpulkan, dan menganalisisnya.

Untuk pembelajaran mesin, Anda dapat menggunakan kerangka kerja seperti Kubeflow , memanfaatkan skalabilitas Kubernetes . Model pelatihan yang dihasilkan dapat dikembalikan ke sistem.
Jika kita menggabungkan teka-teki itu, kita mendapatkan sesuatu seperti ini:

Keunggulan operasional
Kami telah mengatakan bahwa prinsip DevOps dan DevSecOps adalah komponen penting dari setiap data lake dan tidak boleh diabaikan. Dengan banyak kekuatan datang banyak tanggung jawab, terutama ketika semua data terstruktur dan tidak terstruktur tentang bisnis Anda ada di satu tempat.
Prinsip dasarnya adalah sebagai berikut:
- Batasi akses pengguna;
- Pemantauan;
- Enkripsi data;
- Solusi tanpa server;
- Menggunakan proses CI / CD.
Prinsip DevOps dan DevSecOps adalah komponen penting dari data lake mana pun dan tidak boleh diabaikan. Dengan banyak kekuatan datang banyak tanggung jawab, terutama ketika semua data terstruktur dan tidak terstruktur tentang bisnis Anda ada di satu tempat.
Salah satu metode yang direkomendasikan adalah mengizinkan akses hanya untuk layanan tertentu dengan mendistribusikan hak yang sesuai, dan menolak akses pengguna langsung sehingga pengguna tidak dapat mengubah data (ini juga berlaku untuk perintah). Pemantauan penuh dengan tindakan logging juga penting untuk melindungi data.
Enkripsi data adalah mekanisme lain untuk melindungi data. Data yang disimpan dapat dienkripsi menggunakan sistem manajemen kunci ( KMS). Ini akan mengenkripsi sistem penyimpanan dan status Anda saat ini. Pada gilirannya, enkripsi transmisi dapat dilakukan menggunakan sertifikat untuk semua antarmuka dan titik akhir layanan seperti Kafka dan ElasticSearch .
Dan dalam kasus mesin pencari yang mungkin tidak mematuhi kebijakan keamanan, lebih baik memberikan preferensi pada solusi tanpa server . Juga perlu untuk mengabaikan penerapan manual, perubahan situasional di setiap komponen data lake; setiap perubahan harus berasal dari kendali sumber dan lulus serangkaian uji CI sebelum diterapkan ke danau data produk ( pengujian asap , regresi, dll.).
Epilog
Kami telah membahas prinsip-prinsip desain dasar dari arsitektur data lake open source. Seperti yang sering terjadi, pilihan pendekatan tidak selalu jelas dan dapat ditentukan oleh bisnis, anggaran dan kebutuhan waktu yang berbeda. Namun memanfaatkan teknologi cloud untuk membuat data lake, baik itu solusi hybrid atau all-cloud, adalah tren yang muncul di industri. Hal ini karena banyaknya manfaat yang ditawarkan pendekatan ini. Ini memiliki tingkat fleksibilitas yang tinggi dan tidak membatasi pengembangan. Penting untuk dipahami bahwa model kerja yang fleksibel membawa manfaat ekonomi yang signifikan, memungkinkan Anda untuk menggabungkan, mengukur, dan meningkatkan proses yang diterapkan.