
Apa yang telah berubah dalam perbankan konsumen
Di China, bahkan sekitar lima tahun yang lalu, mendapatkan pinjaman bukanlah hal yang cepat - untuk manusia, pastinya. Diperlukan untuk mengisi banyak dokumen, mengirim atau membawanya ke cabang bank, bahkan mungkin mengantre, dan kembali ke rumah, untuk menunggu keputusan. Berapa lama untuk menunggu? Dan bagaimana hasilnya, dari satu minggu sampai beberapa bulan.
Pada tahun 2020, prosedur ini telah disederhanakan secara dramatis. Saya baru-baru ini melakukan percobaan kecil - saya mencoba mendapatkan pinjaman menggunakan aplikasi seluler bank saya. Beberapa ketukan pada layar ponsel cerdas - dan sistem berjanji akan memberi saya jawaban paling lambat dalam seperempat jam. Namun dalam waktu kurang dari lima menit, saya mendapatkan notifikasi push yang menunjukkan besaran pinjaman yang dapat saya andalkan. Setuju, kemajuan yang mengesankan dibandingkan dengan keadaan lima tahun lalu. Anehnya, baru-baru ini butuh berhari-hari dan berminggu-minggu.
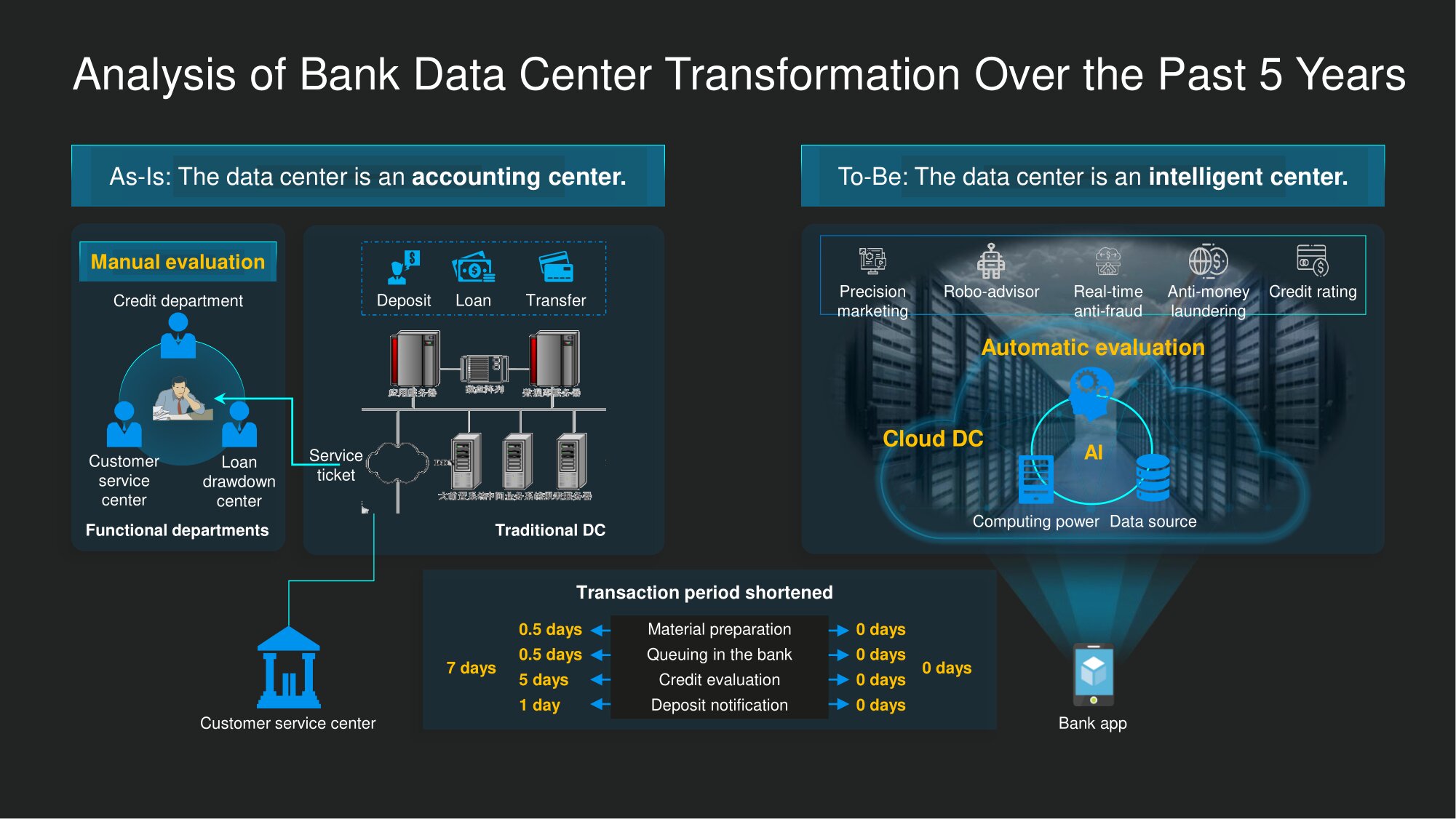
Jadi, sebelumnya, sebagian besar waktu dihabiskan untuk verifikasi data dan penilaian manual. Semua informasi dari kuesioner dan makalah lain harus dimasukkan ke dalam sistem TI bank. Tetapi ini hanya awal dari cobaan berat: pegawai bank secara pribadi memeriksa riwayat kredit Anda, setelah itu mereka membuat keputusan akhir. Mereka meninggalkan kantor pada pukul 17.00 atau 18.00, beristirahat di akhir pekan, dan prosesnya, akibatnya, bisa berlarut-larut dalam waktu yang lama.
Banyak hal berbeda hari ini. Faktor manusia dalam banyak tugas perbankan digital umumnya dikeluarkan dari kurung. Penilaian, termasuk pemeriksaan anti-penipuan dan AML, dilakukan secara otomatis menggunakan algoritma cerdas. Mobil tidak perlu istirahat, jadi mereka beroperasi tujuh hari seminggu dan sepanjang waktu. Selain itu, sejumlah informasi yang diperlukan untuk pengambilan keputusan sudah disimpan dalam database bank. Ini berarti bahwa putusan dijatuhkan dalam waktu yang jauh lebih singkat daripada di "itish antiquity."
Secara umum, sebelumnya pusat data perbankan digunakan bukan untuk memecahkan masalah jenis "pendaftaran". Untuk waktu yang lama hanya menjadi pusat akuntansi dan tidak menghasilkan apa-apa dengan sendirinya. Saat ini ada semakin banyak pusat data "pintar" tempat produk dibuat... Mereka digunakan untuk kalkulasi kompleks dan membantu memperoleh kecerdasan dari data mentah - sebenarnya, pengetahuan dengan nilai tambah yang tinggi. Selain itu, data mining berkelanjutan - jika disiapkan dengan benar, tentu saja - pada akhirnya akan semakin meningkatkan efisiensi proses.
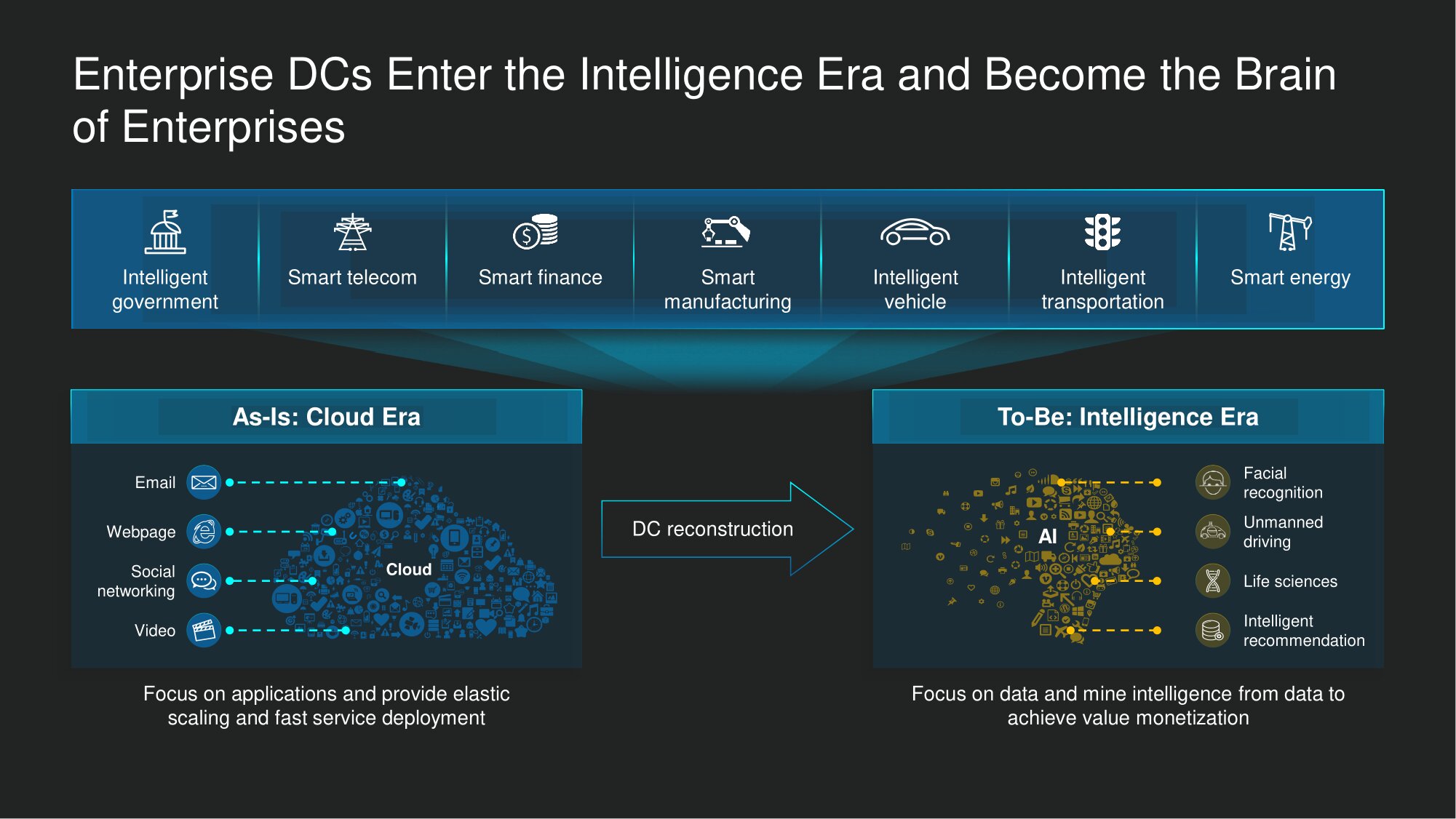
Transformasi ini terjadi tidak hanya di bidang keuangan, tetapi di hampir semua vertikal bisnis. Untuk perusahaan dengan berbagai profil (dan bagi kami, sebagai produsen solusi), pusat data sekarang menjadi pendukung utama di dunia, di mana persaingan antara perkembangan kecerdasan lebih ketat dari sebelumnya. Bahkan lima tahun yang lalu, sudah menjadi arus utama untuk berdebat sejalan dengan fakta bahwa pusat data tertulis di dunia teknologi cloud, dan ini menyiratkan kemampuan untuk secara fleksibel menskalakan total kumpulan sumber daya yang didistribusikan untuk komputasi dan penyimpanan data. Tetapi ini adalah era solusi cerdas, dan di pusat data kami dapat melakukan penggalian data secara berkelanjutan, mengubah hasil yang diperoleh menjadi peningkatan kinerja yang luar biasa. Di sektor keuangan, perubahan ini memimpin - di antara banyak hasil lainnya - pada fakta itubahwa penilaian permintaan pinjaman semakin cepat. Atau, misalnya, mereka memungkinkan untuk langsung merekomendasikan produk keuangan yang paling sesuai untuk klien bank tertentu.
Di sektor publik, di telekomunikasi, di industri energi, pekerjaan cerdas dengan data saat ini berkontribusi pada transformasi digital dengan peningkatan produktivitas organisasi yang dramatis. Secara alami, keadaan baru akan membentuk permintaan baru, dan tidak hanya dalam kaitannya dengan sumber daya komputasi dan sistem penyimpanan data, tetapi juga dalam kaitannya dengan solusi jaringan untuk pusat data.
Apa yang seharusnya menjadi "pusat data pintar"
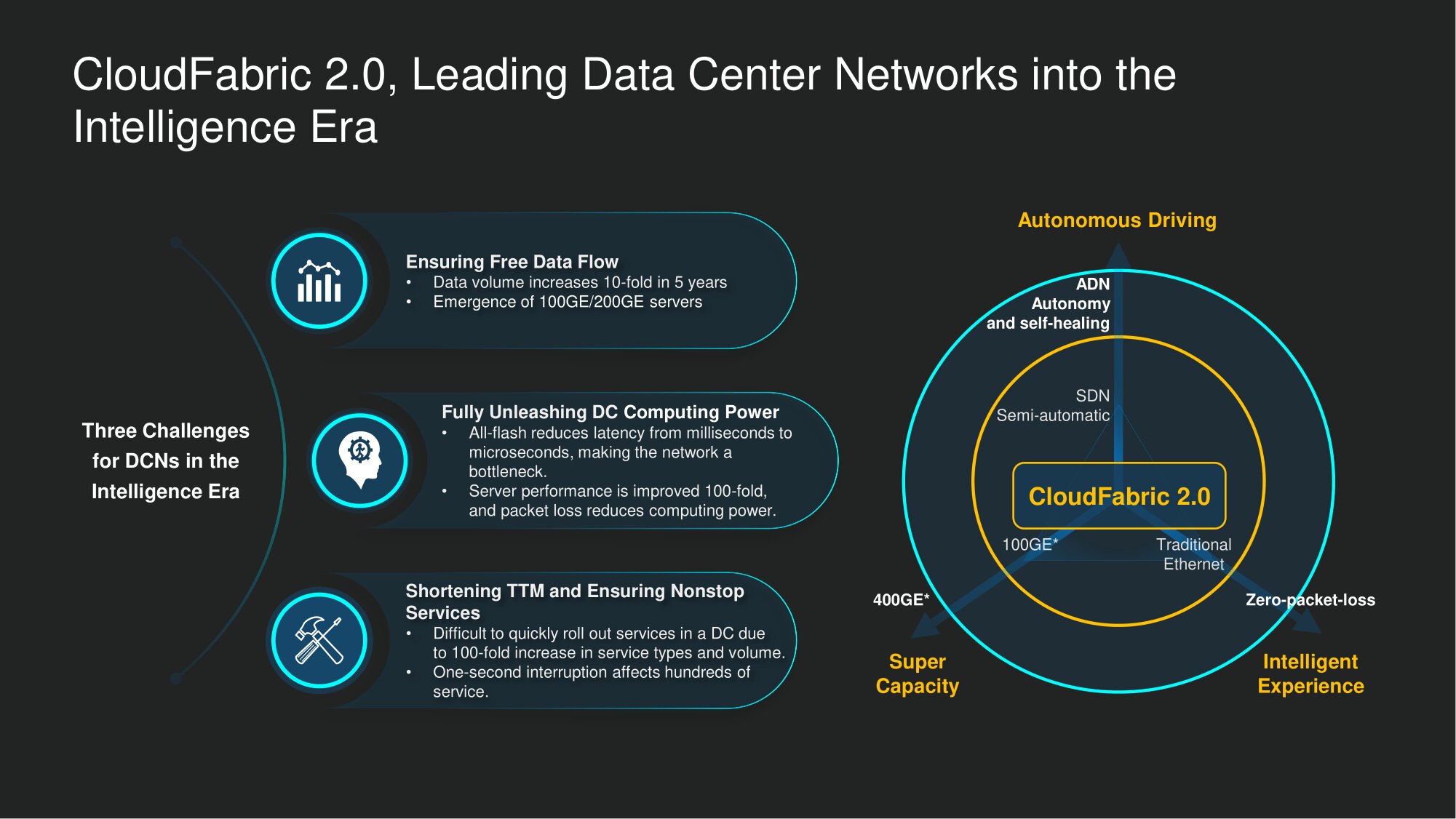
Di Huawei, kami telah mengidentifikasi tiga tantangan utama pusat data di era "pusat data pintar".
Pertama, bandwidth yang luar biasa dibutuhkan untuk menangani aliran data baru yang tidak pernah berakhir.... Menurut pengamatan kami, selama lima tahun terakhir, volume data yang disimpan di pusat data telah tumbuh sepuluh kali lipat. Tapi yang lebih mengesankan adalah berapa banyak lalu lintas yang dihasilkan saat mengakses data tersebut. Di pusat data "tipe pendaftaran", semua informasi ini digunakan untuk memecahkan masalah akuntansi dan sering kali memberikan bobot mati, dan di pusat data jenis baru ini "berfungsi" - kita perlu menyediakan data mining yang konstan. Akibatnya, 10-1000 kali lebih banyak iterasi dilakukan saat mengakses unit data yang disimpan daripada sebelumnya. Misalnya, saat melatih model AI, tugas komputasi dilakukan hampir tanpa henti di latar belakang, dengan fungsi terus-menerus dari algoritme jaringan saraf untuk meningkatkan "kecerdasan" sistem. Dengan demikian, tidak hanya volume data yang disimpan yang bertambah, tetapi juga lalu lintas yang dihasilkan saat mengaksesnya.Jadi sama sekali bukan keinginan vendor telekomunikasi bahwa ada lebih dan lebih dari seratus dua ratus port gigabit pada model baru server datastore.
Kedua, tidak ada paket data yang hilangpada tahun 2020, mutlak harus. Bagaimanapun, dari sudut pandang kami. Sebelumnya, kerugian seperti itu tidak membuat pusing para insinyur pusat data perbankan. Hambatan adalah daya pemrosesan dan efisiensi penyimpanan. Namun nilai rata-rata industri dari kedua indikator tersebut telah meningkat secara signifikan selama lima tahun terakhir dalam skala global. Secara alami, efisiensi infrastruktur jaringan ternyata menjadi penghambat dalam pekerjaan pusat data. Bekerja dengan salah satu klien teratas kami, kami menemukan bahwa setiap persentase yang ditambahkan ke tingkat kehilangan paket mengancam efisiensi pelatihan model AI hingga separuhnya. Oleh karena itu dampaknya sangat besar terhadap produktivitas dan efisiensi penggunaan sumber daya komputasi dan sistem penyimpanan data. Itulah yang perlu diatasiuntuk mendukung transformasi pusat data sederhana menjadi pusat data untuk smart age.
Ketiga, penting untuk memberikan layanan dengan mulus dan lancar . Perbankan digital modern telah mengajarkan, dan telah mengajar dengan benar, orang-orang tentang fakta bahwa layanan lembaga keuangan dapat, atau lebih tepatnya, bahkan harus tersedia 24/7. Situasi umum: pengusaha yang lelah dengan rutinitas harian yang tidak teratur, sangat membutuhkan dana tambahan, bangun mendekati tengah malam dan ingin mencari tahu jalur kredit mana yang dapat ia andalkan. Jalan kembali terputus: bank tidak lagi memiliki kemampuan untuk menangguhkan pekerjaan DC untuk memperbaiki atau meningkatkan sesuatu.
Solusi CloudFabric 2.0 kami dirancang dengan tepat untuk mengatasi tantangan ini. Ini mendukung throughput tertinggi, manajemen jaringan pusat data cerdas, dan fungsi jaringan penggerak otonom (ADN) yang sempurna.
Apa yang ada di CloudFabric 2.0 untuk Pusat Data Cerdas

Berkenaan dengan throughput yang tinggi, kami tidak hanya mengandalkan skalabilitas solusi jaringan kami, tetapi juga pada fleksibilitas dalam bekerja dengannya. Misalnya, sakelar pusat data Huawei dari jalur CloudEngine menjadi perangkat pertama dari kelas ini di industri dengan prosesor tertanam untuk komputasi jaringan saraf secara real time, membantu, antara lain, untuk memecahkan masalah dalam infrastruktur jaringan dan mencegah kehilangan paket data (ini dicapai dengan menggunakan algoritma iLossless, di termasuk untuk skenario iNOF RoCE). Tapi, tentu saja, bandwidth sebenarnya juga penting. Penting untuk menyertakan dukungan untuk antarmuka 400 Gb / dtk, serta kompatibilitas mundur dengan koneksi sepuluh, empat puluh, dan ratus gigabit yang saat ini tersebar luas.
Node pendukung infrastruktur juga harus dapat bekerja dengan koneksi kepadatan tinggi (yang disebut skenario kepadatan tinggi), dengan kemungkinan skalabilitas solusi yang signifikan. Model pusat data andalan kami CloudEngine 16800 mendukung hingga 48 port pada 400 Gbps per slot - tiga kali lebih banyak daripada pesaing terdekatnya.
Sedangkan untuk sistem secara keseluruhan, kemungkinan untuk memperluas throughput per skalabilitas sasis juga mengesankan - 768 port 400 Gbps per sasis , atau enam kali lebih banyak daripada solusi yang dimungkinkan oleh pemain pasar lainnya. Ini memberi kami alasan untuk menyebut CloudEngine 16800 sebagai sakelar pusat data paling kuat di era AI yang unggul.

Komponen intelektual dari solusi jaringan juga tampil kedepan. Secara khusus, ini juga diperlukan untuk memastikan tingkat kehilangan paket data nol. Untuk mencapai hasil ini, kami menggunakan kemajuan teknologi kami yang paling canggih, termasuk prosesor AI terintegrasi untuk komputasi "jaringan saraf", serta algoritma iLossless yang disebutkan sebelumnya. Saat mengerjakan proyek untuk pelanggan utama kami, kami yakin bahwa solusi ini dapat meningkatkan kinerja sistem secara signifikan setidaknya dalam dua skenario umum.
Yang pertama adalah melatih model AI. Ini membutuhkan akses konstan ke data dan penghitungan pada matriks besar atau operasi "berat" dengan TensorFlow. ILossless kami mampu meningkatkan produktivitas model AI pelatihan sebesar 27% - terbukti dalam kasus nyata dan diverifikasi oleh uji lab Tolly Group. Skenario kedua adalah meningkatkan efisiensi sistem penyimpanan. Ini, pada gilirannya, penggunaan pengembangan kami dapat meningkatkannya sekitar 30%.
Antara lain, bersama dengan pelanggan kami, kami berusaha untuk mencoba peluang baru yang terbuka perkembangan kami. Kami yakin bahwa dengan meningkatkan fabric switching berbasis Ethernet untuk pusat data, kami dapat mengubah fabric data center berkinerja tinggi dengan jaringan penyimpanan menjadi infrastruktur tunggal berbasis Ethernet yang koheren. Jadi, untuk tidak hanya meningkatkan produktivitas proses pembelajaran untuk model AI dan meningkatkan akses ke penyimpanan data yang ditentukan perangkat lunak, tetapi juga untuk secara signifikan mengoptimalkan total biaya kepemilikan pusat data melalui integrasi timbal balik dan penggabungan jaringan vertikal yang independen di tingkat fisik.

Banyak klien kami menikmati peluncuran fitur baru ini. Dan salah satu klien tersebut adalah Huawei sendiri. Secara khusus, anggota grup perusahaan kami Huawei Cloud. Bekerja sama dengan kolega kami di divisi ini, kami memastikan bahwa dengan menjamin mereka tidak kehilangan paket data, kami memberikan dorongan untuk meningkatkan proses bisnis mereka secara nyata. Terakhir, di antara pencapaian "internal" kami, kami mencatat fakta bahwa di Atlas 900, cluster AI terbesar di dunia, kami dapat menyediakan daya komputasi yang digunakan untuk melatih kecerdasan buatan pada level di atas 1.000 petaflops - angka tertinggi di komputer industri hari ini.
Skenario lain yang sangat relevan adalah penyimpanan data cloud menggunakan sistem All-Flash. Ini adalah layanan yang sangat trendi menurut standar industri. Meningkatkan sumber daya komputasi dan memperluas fasilitas penyimpanan tentu saja membutuhkan teknologi canggih dari bidang solusi jaringan pusat data. Jadi kami terus bekerja dengan Huawei Cloud dan menerapkan lebih banyak skenario aplikasi menggunakan solusi jaringan kami.
Apa yang Dapat Dilakukan Jaringan ADN Hari Ini

Mari beralih ke Autonomous Networks (ADN). Tidak ada keraguan, jaringan yang ditentukan perangkat lunak (jaringan yang ditentukan perangkat lunak) dari sudut pandang teknologi - langkah maju yang percaya diri dalam pengelolaan komponen jaringan pusat data. Penerapan konsep SDN yang diterapkan secara signifikan mempercepat inisialisasi dan konfigurasi lapisan jaringan pusat data. Namun, tentu saja, kemampuan yang diberikannya tidak cukup untuk sepenuhnya mengotomatiskan O&M pusat data. Untuk melangkah lebih jauh, ada tiga tantangan utama yang perlu ditangani.
Pertama, dalam infrastruktur jaringan pusat data semakin banyak peluang yang terkait dengan penyediaan layanan dan pengaturan untuk fungsinya, khususnya di sektor keuangan. Penting untuk dapat secara otomatis menerjemahkan maksud tingkat layanan ke lapisan jaringan...
Kedua, itu juga turun untuk memverifikasi perintah penyediaan tambahan tersebut. Maklum, jaringan pusat data telah banyak dikonfigurasi sejak lama, berdasarkan pendekatan yang mapan atau bahkan ketinggalan jaman. Bagaimana Anda bisa memastikan bahwa kustomisasi tambahan tidak merusak prosedur debug Anda? Verifikasi otomatis untuk pengaturan tambahan baru sangat diperlukan. Tepatnya otomatis, karena rangkaian pengaturan yang ada di pusat data biasanya sangat besar. Praktis tidak mungkin untuk mengatasinya secara manual.
Ketiga, muncul pertanyaan tentang penghapusan masalah secara efektif dalam infrastruktur jaringan... Saat otomatisasi mencapai level tinggi, administrator dan teknisi layanan pusat data tidak lagi dapat melacak secara real time apa yang terjadi di jaringan. Mereka membutuhkan perangkat yang dapat membuat jaringan yang beribu-ribu perubahan setiap hari secara konsisten transparan bagi mereka, serta membangun basis data yang dibangun di atas grafik pengetahuan untuk menangani masalah dengan cepat.
ADN dapat membantu kami memenuhi tantangan untuk pindah ke pusat data yang benar-benar cerdas. Dan ideologi jaringan dengan kontrol otonom (bermigrasi ke dunia pusat data dari industri tetangga - khususnya di persimpangan IoT dan V2X) memungkinkan kami merevisi pendekatan otomatisasi di berbagai tingkat jaringan pusat data.
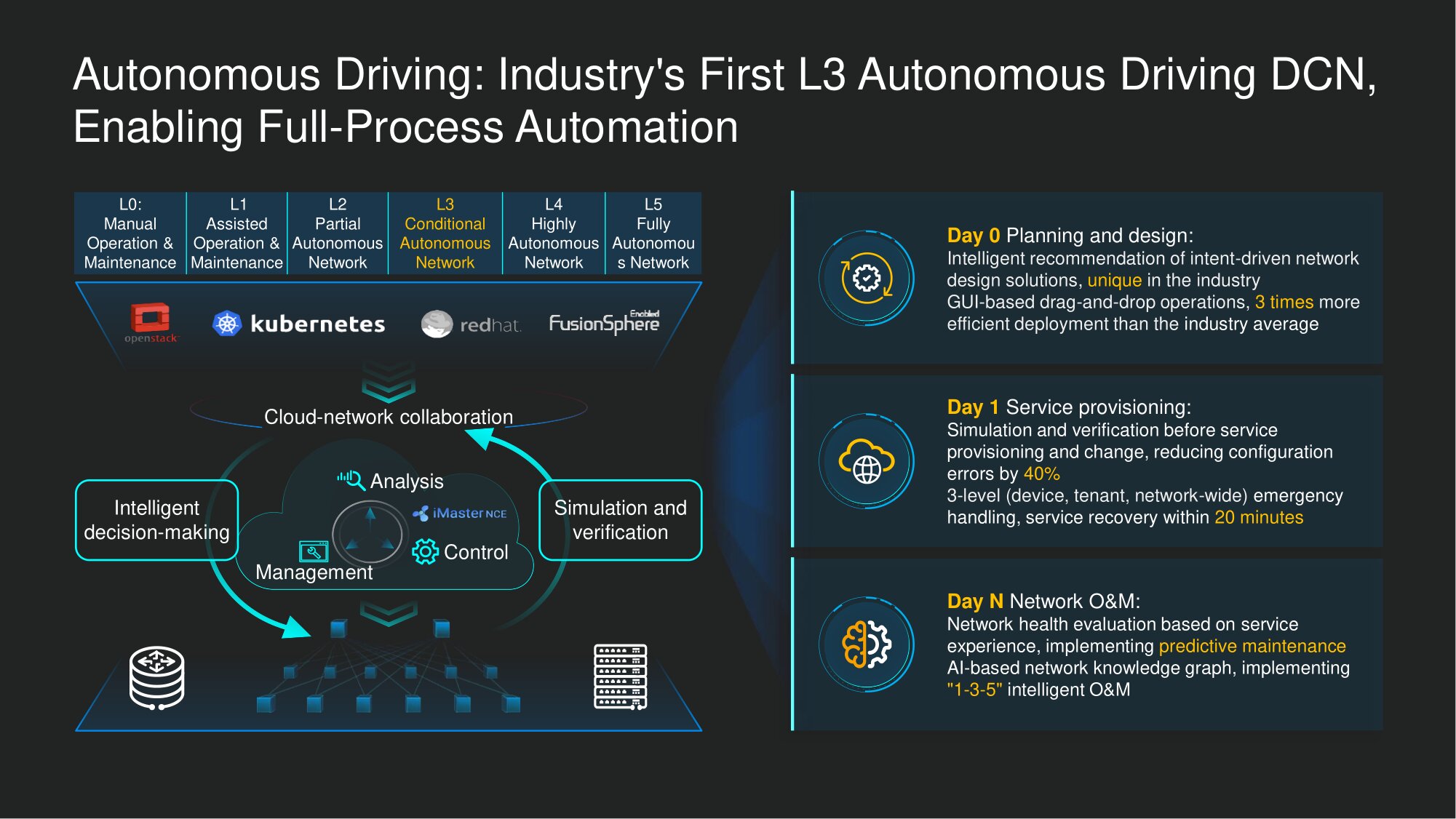
Saat ini, dalam otonomi pengelolaan jaringan untuk pusat data, kami telah mencapailevel L3 (otomatisasi bersyarat). Ini berarti otomatisasi pusat data tingkat tinggi, di mana intervensi manusia diperlukan secara tepat dan hanya dalam kondisi tertentu.
Sementara itu, dalam beberapa skenario, otomatisasi penuh juga dimungkinkan. Kami sudah bekerja dengan klien kami sebagai bagian dari program inovasi bersama untuk otomatisasi komprehensif jaringan pusat data sesuai dengan konsep ADN, terutama dalam konteks pemecahan masalah jaringan, dan dalam kaitannya dengan yang paling mendesak dan memakan waktu, kami telah mencapai kesuksesan: misalnya, dengan bantuan kami teknologi cerdas secara otomatis berhasil menutup sekitar 85% skenario kegagalan yang paling sering berkembang di jaringan pusat data .
Fungsionalitas ini diimplementasikan dalam kerangka konsep O&M 1-3-5 kami: satu menit untuk memastikan bahwa kegagalan telah terjadi atau untuk mengidentifikasi risiko kegagalan, tiga menit untuk menentukan akar masalahnya, dan lima menit untuk menyarankan caranya hilangkan itu. Tentu saja, untuk saat ini, partisipasi manusia diperlukan untuk membuat keputusan akhir - khususnya, memilih salah satu keputusan yang mungkin diambil dan memberikan perintah untuk melaksanakannya. Seseorang harus bertanggung jawab atas pilihan tersebut. Namun, mulai dari praktik, kami percaya bahwa sistem, bahkan dalam penerapannya saat ini, menawarkan solusi yang sangat berkualitas dan tepat.
Berikut adalah beberapa tantangan paling menantang yang dihadapi arsitek pusat data pintar pada tahun 2020, dan kami benar-benar telah mengatasinya. Misalnya, fungsionalitas untuk mentransfer permintaan dari lapisan layanan ke lapisan jaringan dan untuk verifikasi otomatis pengaturan sudah termasuk dalam CloudFabric 2.0.

Kami senang bahwa pencapaian kami telah diakui - dan tahun ini kami menerima Gartner Peer Insights Customer Choice Award, serta F&S Global Data Center Switch Technology Leadership Award untuk CloudEngine 16800 Switch, yang diakui atas hasil yang luar biasa. , kepadatan tertinggi antarmuka 400-gigabit dan skalabilitas keseluruhan sistem, serta untuk teknologi cerdas yang memungkinkan, khususnya, untuk mengurangi tingkat kehilangan paket data ke nol.