Saya ingin berbagi pengalaman saya dalam menerapkan jaringan saraf modis di perusahaan kami. Semuanya dimulai ketika kami memutuskan untuk membangun Meja Layanan kami sendiri. Mengapa dan mengapa milik Anda sendiri, Anda dapat membaca kolega saya Alexei Volkov (cface) di sini .
Saya akan memberi tahu Anda tentang inovasi terbaru dalam sistem: jaringan neural untuk membantu operator baris pertama dukungan. Jika tertarik, selamat datang di cat.

Klarifikasi tugas
Masalah bagi petugas operator dukungan adalah keputusan cepat untuk dialihkan ke permintaan pelanggan yang masuk. Berikut permintaannya:
Selamat sore.
Saya mengerti benar: untuk berbagi kalender ke pengguna tertentu, apakah Anda perlu membuka akses ke kalender Anda di PC pengguna yang ingin berbagi kalender dan memasukkan email pengguna yang ingin dia beri akses?
Menurut peraturan, operator harus merespons dalam dua menit: mendaftarkan aplikasi, menentukan urgensinya, dan menunjuk unit yang bertanggung jawab. Operator memilih dari 44 divisi perusahaan.
Instruksi petugas operator menjelaskan solusi untuk kueri yang paling umum. Misalnya, menyediakan akses ke pusat data adalah permintaan sederhana. Tetapi permintaan layanan mencakup banyak tugas: menginstal perangkat lunak, menganalisis situasi atau aktivitas jaringan, mencari tahu detail tentang penagihan solusi, memeriksa semua jenis akses. Terkadang sulit untuk memahami dari permintaan yang bertanggung jawab untuk mengirimkan pertanyaan:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
Ada situasi ketika aplikasi pergi ke unit yang salah. Permintaan itu dibawa untuk bekerja dan kemudian ditugaskan kembali ke artis lain atau dikirim kembali ke petugas operator. Ini meningkatkan kecepatan solusi. Waktu untuk menyelesaikan permintaan ditulis dalam perjanjian dengan klien (SLA), dan kami bertanggung jawab untuk memenuhi tenggat waktu.
Di dalam sistem, kami memutuskan untuk membuat asisten operator. Tujuan utamanya adalah menambahkan petunjuk yang membantu karyawan membuat keputusan tentang aplikasi lebih cepat.
Yang terpenting, saya tidak ingin menyerah pada tren bermodel baru dan menempatkan chatbot di baris pertama dukungan. Jika Anda pernah mencoba menulis ke dukungan teknis seperti itu (yang sudah tidak berbuat dosa dengan ini), Anda mengerti apa yang saya maksud.
Pertama, dia sangat kurang memahami Anda dan tidak menjawab sama sekali untuk permintaan yang tidak biasa, dan kedua, sangat sulit untuk menjangkau orang yang masih hidup.
Secara umum, kami jelas tidak berencana mengganti operator dengan bot obrolan, karena kami ingin pelanggan tetap berkomunikasi dengan orang secara langsung.
Pada awalnya, saya berpikir untuk menjadi murah dan ceria dan mencoba pendekatan kata kunci. Kami menyusun kamus kata kunci secara manual, tetapi ini tidak cukup. Solusinya hanya mengatasi aplikasi sederhana, yang tidak ada masalah.
Selama pekerjaan Meja Layanan kami, kami telah mengumpulkan riwayat permintaan yang solid, yang menjadi dasarnya kami dapat mengenali permintaan masuk yang serupa dan segera menugaskannya ke pelaksana yang benar. Berbekal Google dan beberapa waktu, saya memutuskan untuk menyelami lebih dalam opsi saya.
Teori belajar
Ternyata tugas saya adalah tugas klasifikasi klasik. Pada masukan, algoritme menerima teks utama dari aplikasi, pada keluaran itu menugaskan ke salah satu kelas yang diketahui sebelumnya - yaitu divisi perusahaan.
Ada banyak sekali solusi. Ini adalah "jaringan saraf" dan "pengklasifikasi Bayesian naif", "tetangga terdekat", "regresi logistik", "pohon keputusan", "peningkatan", dan banyak lagi opsi lainnya.
Tidak akan ada waktu untuk mencoba semua teknik. Oleh karena itu, saya menetap di jaringan saraf (saya sudah lama ingin mencoba bekerja dengan mereka). Ternyata kemudian, pilihan ini sepenuhnya benar.
Jadi, saya mulai menyelami jaringan saraf dari sini . Algoritma pembelajaran dipelajarijaringan saraf: dengan guru (pembelajaran diawasi), tanpa guru (pembelajaran tanpa pengawasan), dengan keterlibatan sebagian guru (pembelajaran semi-supervisi), atau "pembelajaran penguatan".
Sebagai bagian dari tugas saya, metode mengajar dengan seorang guru muncul. Ada lebih dari cukup data untuk pelatihan: lebih dari 100 ribu aplikasi terpecahkan.
Pilihan implementasi
Saya memilih perpustakaan Encog Machine Learning Framework untuk implementasi . Itu datang dengan dokumentasi yang dapat diakses dan dimengerti dengan contoh-contoh . Selain itu, implementasi untuk Java, yang dekat dengan saya.
Secara singkat, mekanisme kerjanya terlihat seperti ini:
- Kerangka jaringan saraf telah dikonfigurasi sebelumnya: beberapa lapisan neuron dihubungkan oleh koneksi sinaptik.

- Sekumpulan data pelatihan dengan hasil yang telah ditentukan dimuat ke dalam memori.
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
Saya mencoba berbagai contoh kerangka kerja, saya menyadari bahwa perpustakaan mengatasi angka di input dengan keras. Jadi, contoh definisi kelas iris menurut ukuran mangkuk dan kelopak ( Fisher's Iris ) bekerja dengan baik .
Tapi saya punya beberapa teks. Artinya, huruf-huruf itu entah bagaimana harus diubah menjadi angka. Jadi saya pindah ke tahap persiapan pertama - "vektorisasi".
Opsi pertama untuk vektorisasi: dengan huruf
Cara termudah untuk mengubah teks menjadi angka adalah dengan menggunakan alfabet di lapisan pertama jaringan saraf. Ternyata 33 neuron huruf: ABVGDEOZHZYKLMNOPRSTUFHTSZHSHSCHYEYUYA.
Masing-masing diberi nomor: keberadaan huruf dalam sebuah kata dianggap sebagai satu, dan ketidakhadiran dianggap nol.
Kemudian kata "halo" dalam pengkodean ini akan memiliki vektor: Vektor

semacam itu sudah dapat diberikan ke jaringan saraf untuk pelatihan. Bagaimanapun, nomor ini adalah 001001000100000011010000000000000 = 1216454656 Setelah mempelajari
teori ini, saya menyadari bahwa tidak ada poin khusus dalam menganalisis huruf. Mereka tidak membawa makna semantik apa pun. Misalnya, huruf "A" akan ada di setiap teks proposal. Pertimbangkan bahwa neuron ini selalu aktif dan tidak akan berpengaruh pada hasil. Seperti semua vokal lainnya. Dan dalam teks aplikasi akan ada sebagian besar huruf alfabet. Pilihan ini tidak cocok.
Varian kedua dari vektorisasi: menurut kamus
Dan jika Anda tidak mengambil huruf, tapi kata-kata? Katakanlah kamus penjelasan Dahl. Dan untuk menghitung sebagai 1 sudah adanya sebuah kata dalam teks, dan tidak adanya - sebagai 0.
Tapi di sini saya berlari ke jumlah kata. Vektor akan menjadi sangat besar. Sebuah neuron dengan 200k input neuron akan membutuhkan waktu lama dan membutuhkan banyak memori dan waktu CPU. Anda harus membuat kamus sendiri. Selain itu, ada kekhususan IT dalam teks yang tidak diketahui oleh Vladimir Ivanovich Dal.
Saya beralih ke teori lagi. Untuk mempersingkat kosakata saat memproses teks, gunakan mekanisme N-gram - urutan elemen N.
Idenya adalah untuk membagi teks masukan menjadi beberapa segmen, membuat kamus dari mereka, dan memberi makan jaringan saraf ada atau tidaknya frasa dalam teks asli sebagai 1 atau 0. Artinya, alih-alih huruf, seperti dalam kasus alfabet, bukan hanya satu huruf, tetapi seluruh frasa akan diambil sebagai 0 atau 1.
Yang paling populer adalah unigram, bigram, dan trigram. Menggunakan frase "Selamat Datang di DataLine" sebagai contoh, saya akan memberi tahu Anda tentang masing-masing metode.
- Unigram - teks dibagi menjadi kata-kata: "baik", "selamat datang", "v", "DataLine".
- Bigram - kami membaginya menjadi pasangan kata: "selamat datang", "selamat datang di", "ke DataLine".
- Trigram - demikian pula, 3 kata masing-masing: "selamat datang di", "selamat datang di DataLine".
- N-gram - Anda mengerti. Berapa banyak N, begitu banyak kata berturut-turut.
- N-. , . 4- N- : «»,« », «», «» . . .
Saya memutuskan untuk membatasi diri pada unigram. Tapi bukan hanya unigram - kata-katanya masih terlalu berlebihan. Algoritma "Porter's Stemmer"
datang untuk menyelamatkan , yang digunakan untuk menyatukan kata-kata pada tahun 1980.
Inti dari algoritma: hapus sufiks dan akhiran dari kata, hanya menyisakan bagian semantik dasar. Misalnya, kata "penting", "penting", "penting", "penting", "penting", "penting" dibawa ke dasar "penting". Artinya, alih-alih 6 kata, akan ada satu kata di kamus. Dan ini merupakan pengurangan yang signifikan.
Selain itu, saya menghapus semua angka, tanda baca, preposisi dan kata-kata langka dari kamus, agar tidak menimbulkan "suara". Hasilnya, untuk 100 ribu teks, kami mendapat kamus berisi 3 ribu kata. Anda sudah bisa mengerjakan ini.
Pelatihan jaringan saraf
Jadi saya sudah punya:
- Kamus kata 3k.
- Representasi kamus vektor.
- Ukuran lapisan masukan dan keluaran jaringan saraf. Menurut teori, kamus disediakan pada lapisan pertama (masukan), dan lapisan terakhir (keluaran) adalah jumlah kelas solusi. Saya memiliki 44 di antaranya - berdasarkan jumlah divisi perusahaan.
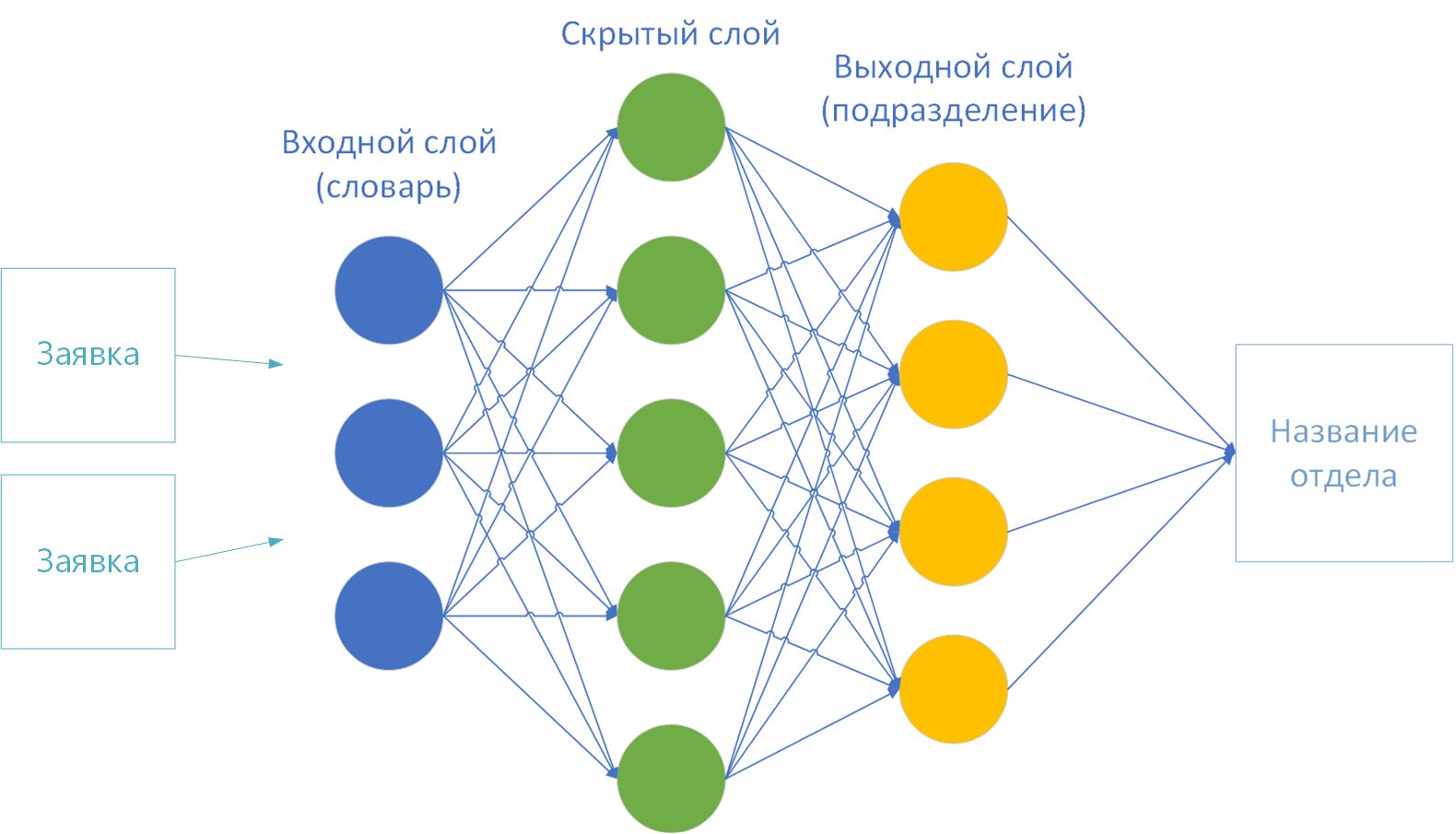
Untuk melatih jaringan saraf, hanya ada sedikit pilihan:
- Metode mengajar.
- Fungsi aktivasi.
- Jumlah lapisan tersembunyi.
Bagaimana saya memilih parameter . Parameter selalu dipilih secara empiris untuk setiap tugas tertentu. Ini adalah proses yang paling lama dan paling membosankan, karena memerlukan banyak eksperimen.
Jadi, saya mengambil sampel referensi dari 11k aplikasi dan melakukan perhitungan neural network dengan berbagai parameter:
- Pada 10k saya melatih jaringan saraf.
- Pada 1k saya memeriksa jaringan yang sudah terlatih.
Artinya, pada 10k kami membangun kamus dan belajar. Dan kemudian kami menunjukkan jaringan saraf terlatih 1k teks tidak dikenal. Hasilnya adalah persentase kesalahan: rasio unit yang ditebak dengan jumlah total teks.
Hasilnya, saya mencapai akurasi sekitar 70% pada data yang tidak diketahui.
Secara empiris, saya menemukan bahwa pelatihan dapat berlanjut tanpa batas waktu jika parameter yang salah dipilih. Beberapa kali, neuron mengalami siklus kalkulasi tanpa akhir dan menggantung mesin yang bekerja untuk malam itu. Untuk mencegah hal ini, untuk diri saya sendiri, saya menerima batas 100 iterasi atau hingga kesalahan jaringan berhenti berkurang.
Berikut adalah parameter terakhir:
Metode pengajaran . Encog menawarkan beberapa opsi untuk dipilih: Backpropagation, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
Ini adalah cara berbeda untuk menentukan bobot pada sinapsis. Beberapa metode bekerja lebih cepat, beberapa lebih tepat, lebih baik untuk membaca lebih lanjut di dokumentasi. Propagasi Tangguh bekerja dengan baik untuk saya .
Fungsi aktivasi . Diperlukan untuk menentukan nilai neuron pada keluaran, tergantung pada hasil penjumlahan bobot masukan dan nilai ambang batas.
Saya memilih dari 16 opsi . Saya tidak punya cukup waktu untuk memeriksa semua fungsi. Oleh karena itu, saya menganggap yang paling populer: sigmoid dan hiperbolik singgung dalam berbagai implementasi.
Pada akhirnya, saya memilih ActivationSigmoid .
Jumlah lapisan tersembunyi... Secara teori, semakin banyak lapisan tersembunyi, semakin lama dan semakin sulit perhitungannya. Saya mulai dengan satu lapisan: kalkulasi cepat, tetapi hasilnya tidak akurat. Saya menetapkan dua lapisan tersembunyi. Dengan tiga lapis, dianggap lebih panjang, dan hasilnya tidak jauh berbeda dengan dua lapis.
Dalam hal ini saya menyelesaikan percobaan. Anda dapat menyiapkan alat untuk produksi.
Untuk produksi!
Lebih jauh soal teknologi.
- Saya mengacaukan Spark sehingga saya dapat berkomunikasi dengan neuron melalui REST.
- Diajarkan untuk menyimpan hasil perhitungan ke file. Tidak setiap kali menghitung ulang saat memulai ulang layanan.
- Menambahkan kemampuan untuk membaca data aktual untuk pelatihan langsung dari Meja Layanan. Sebelumnya dilatih tentang file csv.
- Menambahkan kemampuan untuk menghitung ulang jaringan saraf untuk melampirkan penghitungan ulang ke penjadwal.
- Mengumpulkan semuanya dalam toples tebal.
- Saya meminta kolega saya untuk server yang lebih kuat dari mesin pengembangan.
- Zadeploil dan zashedulil menceritakan seminggu sekali.
- Saya mengencangkan tombol ke tempat yang tepat di Meja Layanan dan menulis kepada rekan-rekan saya bagaimana menggunakan keajaiban ini.
- Saya mengumpulkan statistik tentang apa yang dipilih neuron dan apa yang dipilih orang tersebut (statistik di bawah).
Beginilah tampilan aplikasi tes:
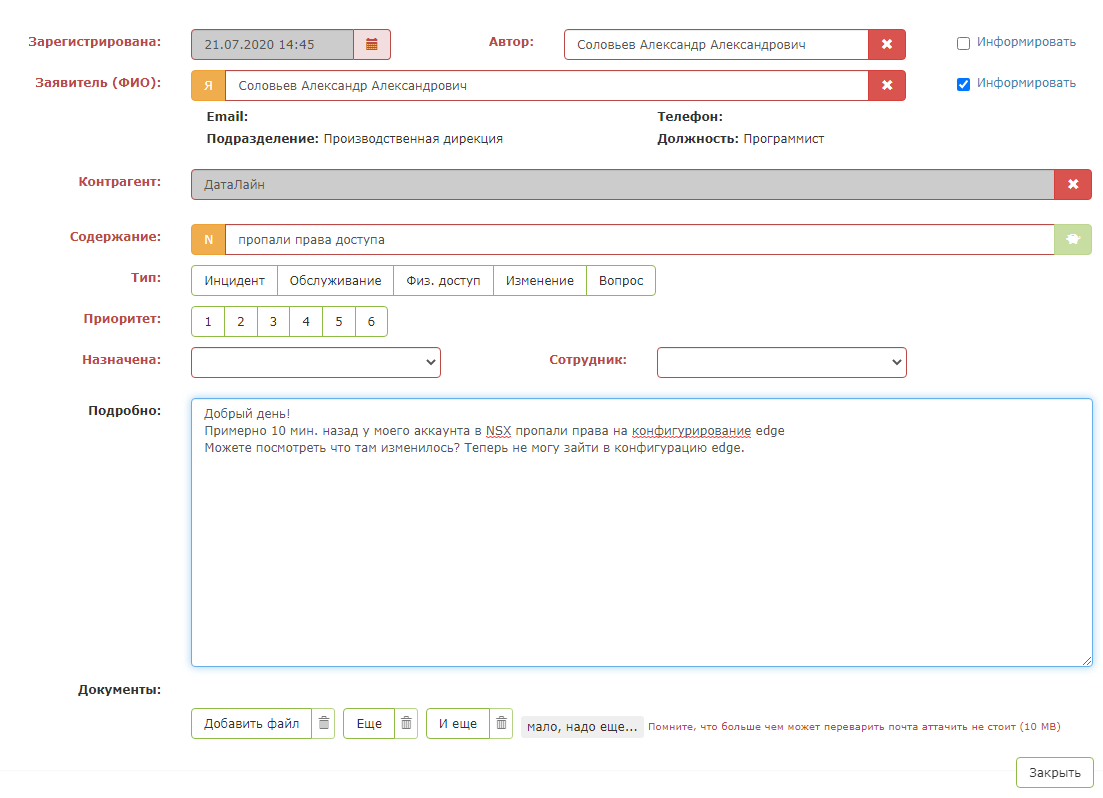
Tetapi segera setelah Anda menekan "tombol hijau ajaib", keajaiban terjadi: bidang kartu terisi. Petugas operator tetap harus memastikan bahwa sistem meminta dengan benar dan menyimpan permintaan tersebut.
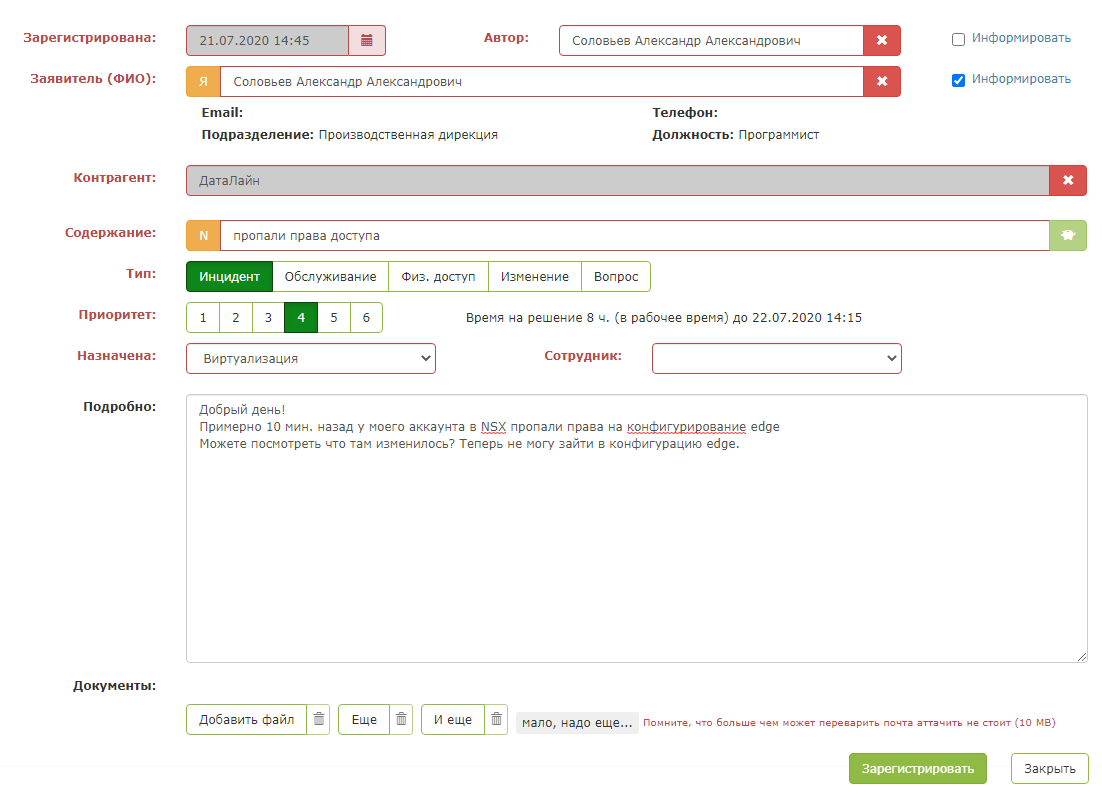
Hasilnya adalah asisten yang cerdas bagi petugas operator.
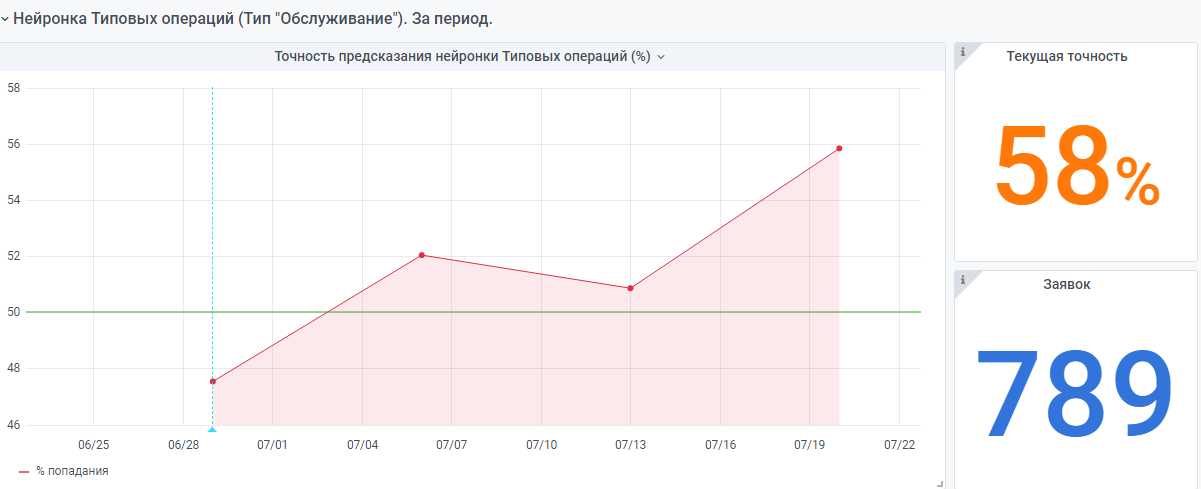
Misalnya statistik dari awal tahun.
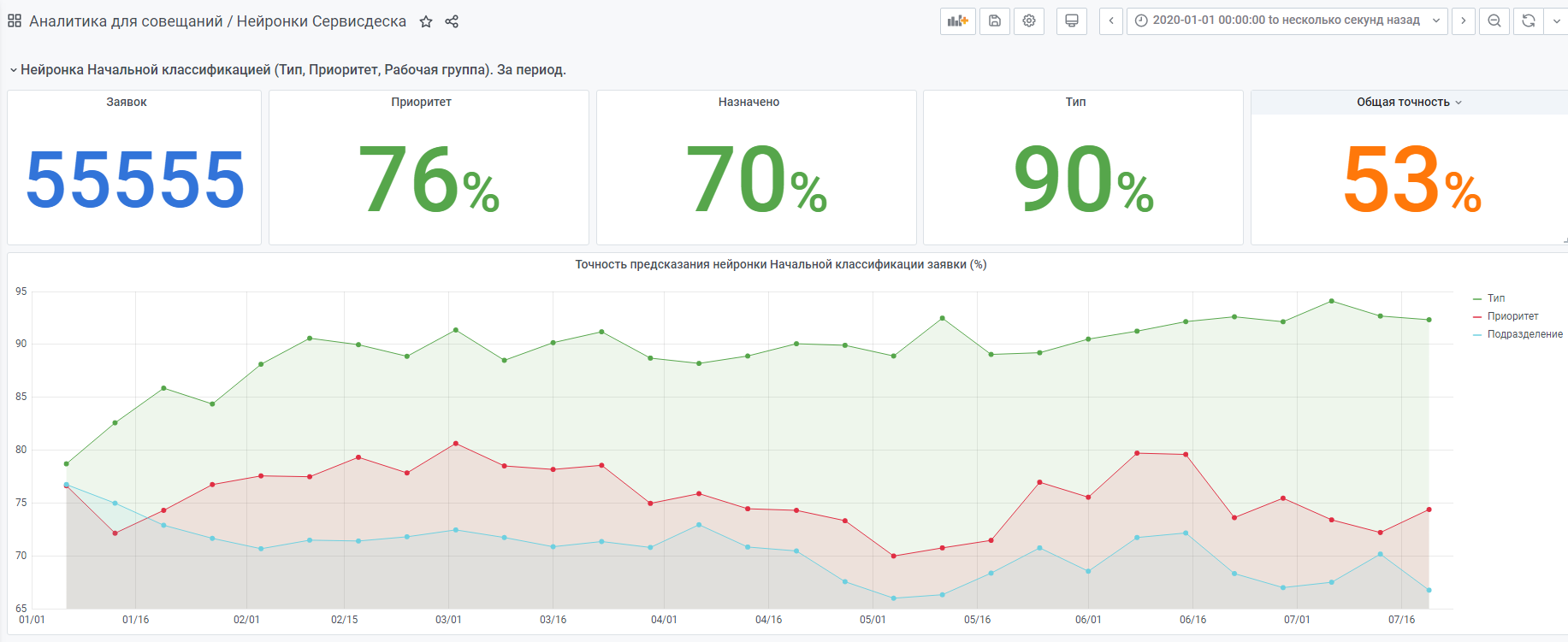
Ada juga jaringan saraf "sangat muda" yang dibuat berdasarkan prinsip yang sama. Tetapi masih sedikit data di sana, dia masih mendapatkan pengalaman.
Saya akan senang jika pengalaman saya akan membantu seseorang dalam membuat jaringan saraf sendiri.
Jika Anda memiliki pertanyaan, saya akan dengan senang hati menjawabnya.