- Singkatnya, rencana apa yang akan kita miliki? Pertama, kita akan membahas mengapa kita akan belajar Python. Kemudian mari kita lihat bagaimana interpreter CPython bekerja secara lebih mendalam, bagaimana mengelola memori, bagaimana sistem tipe dalam Python bekerja, kamus, generator dan pengecualian. Saya pikir ini akan memakan waktu sekitar satu jam.
Mengapa Python?
* insights.stackoverflow.com/survey/2019
** sangat subyektif
*** interpretasi penelitian
**** interpretasi penelitian
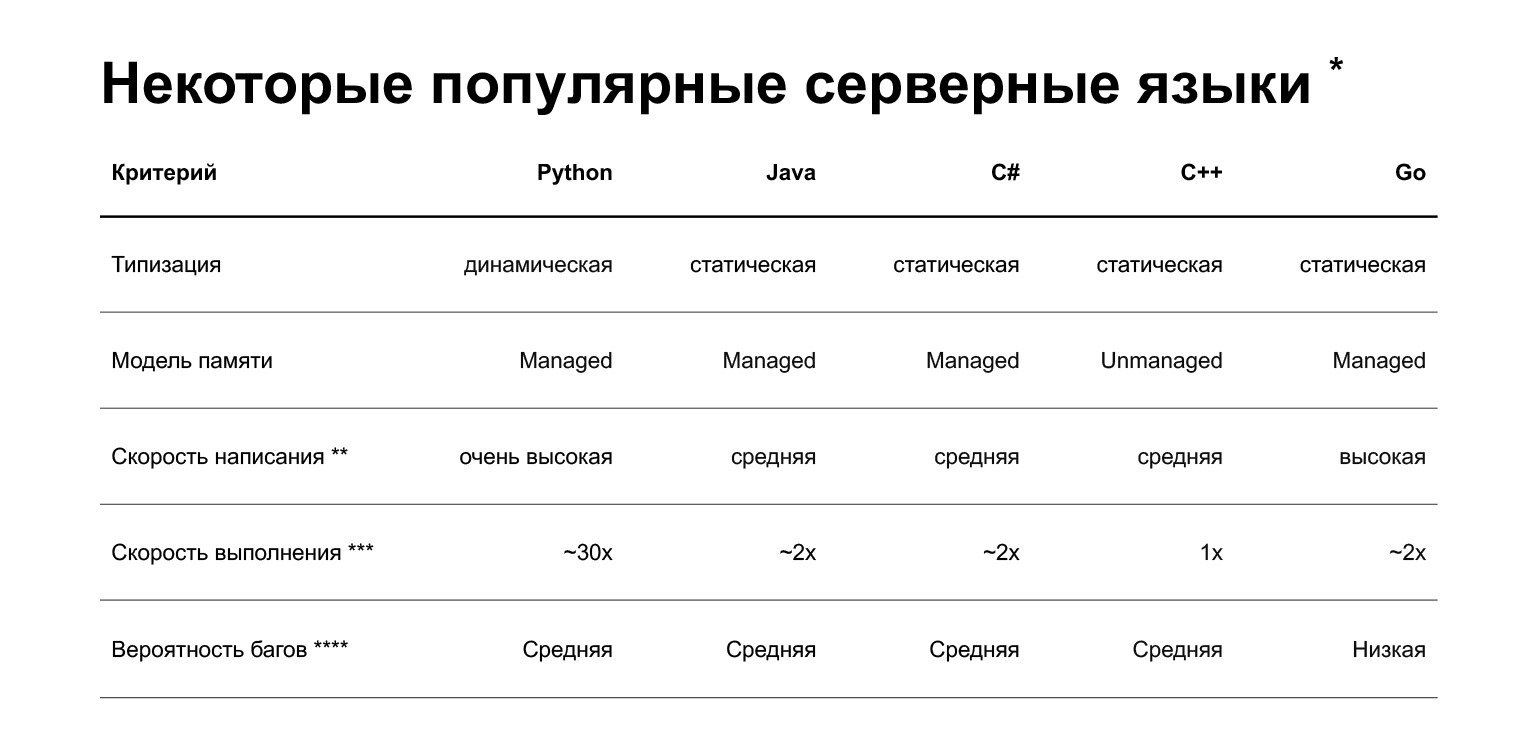
Mari kita mulai. Mengapa Python? Slide tersebut menunjukkan perbandingan beberapa bahasa yang saat ini digunakan dalam pengembangan backend. Tapi singkatnya, apa keunggulan Python? Anda dapat dengan cepat menulis kode di atasnya. Ini, tentu saja, sangat subjektif - orang yang menulis C ++ atau Go yang keren bisa membantahnya. Tapi rata-rata, menulis dengan Python lebih cepat.
Apa kerugiannya? Kerugian pertama dan mungkin utama adalah Python lebih lambat. Ini bisa 30 kali lebih lambat dari bahasa lain, berikut adalahpelajarantentang topik ini. Tetapi kecepatannya tergantung pada tugasnya. Ada dua kelas tugas:
- terikat CPU, tugas terikat CPU, terikat CPU.
- I / O terikat, tugas dibatasi oleh input-output: baik melalui jaringan, atau dalam database.
Jika Anda menyelesaikan masalah terikat CPU, ya, Python akan lebih lambat. Jika I / O terikat, dan ini adalah tugas kelas besar, maka untuk memahami kecepatan eksekusi, Anda perlu menjalankan benchmark. Dan mungkin membandingkan Python dengan bahasa lain, Anda bahkan tidak akan melihat perbedaan performanya.
Selain itu, Python diketik secara dinamis: interpreter tidak memeriksa jenis pada waktu kompilasi. Dalam versi 3.5, petunjuk jenis muncul, memungkinkan Anda untuk menentukan jenis secara statis, tetapi petunjuk tersebut tidak terlalu ketat. Artinya, Anda akan menemukan beberapa kesalahan yang sudah ada dalam produksi, dan bukan pada tahap kompilasi. Bahasa populer lainnya untuk backend - Java, C #, C ++, Go - memiliki pengetikan statis: jika Anda mengirimkan objek yang salah dalam kode, compiler akan memberi tahu Anda.
Lebih membumi, bagaimana Python digunakan dalam pengembangan produk Taksi? Kami bergerak menuju arsitektur layanan mikro. Kami sudah memiliki 160 layanan mikro, yaitu grosir - 35, 15 di antaranya dengan Python, 20 - plus plus. Artinya, kita sekarang menulis hanya dengan Python, atau plus.
Bagaimana kita memilih bahasa? Yang pertama adalah persyaratan beban, yaitu, kami melihat apakah Python dapat menanganinya atau tidak. Jika dia menarik, maka kami melihat kompetensi pengembang tim.
Sekarang saya ingin berbicara tentang penerjemah. Bagaimana cara kerja CPython?
Perangkat penerjemah
Mungkin timbul pertanyaan: mengapa kita perlu tahu bagaimana penerjemah bekerja. Pertanyaannya valid. Anda dapat dengan mudah menulis layanan tanpa mengetahui apa yang ada di balik terpal. Jawabannya mungkin sebagai berikut:
1. Optimasi untuk beban tinggi. Bayangkan Anda memiliki layanan Python. Berhasil, bebannya rendah. Tetapi suatu hari tugas datang kepada Anda - menulis pena, siap untuk beban berat. Anda tidak bisa lepas dari ini, Anda tidak bisa menulis ulang seluruh layanan di C ++. Jadi, Anda perlu mengoptimalkan layanan untuk beban tinggi. Memahami bagaimana penerjemah bekerja dapat membantu dalam hal ini.
2. Debugging kasus yang kompleks. Misalkan layanan berjalan, tetapi memori mulai "bocor" di dalamnya. Di Yandex.Taxi, kami mengalami kasus seperti itu baru-baru ini. Layanan ini menghabiskan 8 GB memori setiap jam dan macet. Kita perlu mencari tahu. Ini tentang bahasa, Python. Diperlukan pengetahuan tentang bagaimana manajemen memori bekerja dengan Python.
3. Ini berguna jika Anda akan menulis pustaka kompleks atau kode kompleks.
4. Dan secara umum - ini dianggap sebagai bentuk yang baik untuk mengetahui alat yang Anda gunakan pada tingkat yang lebih dalam, dan bukan hanya sebagai pengguna. Ini dihargai di Yandex.
5. Mereka mengajukan pertanyaan tentang hal itu saat wawancara, tetapi itu bukan intinya, tetapi pandangan umum TI Anda.

Mari kita ingat secara singkat apa jenis penerjemah itu. Kami memiliki kompiler dan interpreter. Kompiler, seperti yang mungkin Anda ketahui, adalah hal yang menerjemahkan kode sumber Anda langsung ke kode mesin. Sebaliknya, interpreter menerjemahkan terlebih dahulu menjadi bytecode, dan kemudian mengeksekusinya. Python adalah bahasa yang ditafsirkan.
Bytecode adalah sejenis kode perantara yang diperoleh dari aslinya. Itu tidak terikat ke platform dan berjalan pada mesin virtual. Mengapa virtual? Ini bukan mesin sungguhan, tapi semacam abstraksi.

Jenis mesin virtual apa yang ada? Daftar dan susun. Tetapi di sini kita harus mengingat bukan ini, tetapi fakta bahwa Python adalah mesin stack. Selanjutnya, kita akan melihat cara kerja tumpukan.
Dan satu peringatan lagi: di sini kita hanya akan berbicara tentang CPython. CPython adalah implementasi referensi Python, ditulis, seperti yang Anda duga, dalam C. Digunakan secara sinonim: ketika kita berbicara tentang Python, kita biasanya berbicara tentang CPython.
Tapi ada juga penerjemah lain. Ada PyPy, yang menggunakan kompilasi JIT dan mempercepat sekitar lima kali lipat. Jarang digunakan. Sejujurnya saya belum pernah bertemu. Ada JPython, ada IronPython, yang menerjemahkan bytecode untuk Mesin Virtual Java dan untuk mesin Dotnet. Ini di luar ruang lingkup kuliah hari ini - sejujurnya, saya belum menemukannya. Jadi mari kita lihat CPython.

Mari lihat apa yang terjadi. Anda memiliki sumber, garis, Anda ingin mengeksekusinya. Apa yang dilakukan penerjemah? String hanyalah kumpulan karakter. Untuk melakukan sesuatu yang berarti dengannya, pertama-tama Anda menerjemahkan kode tersebut menjadi token. Token adalah sekumpulan karakter yang dikelompokkan, pengenal, angka, atau semacam iterasi. Sebenarnya, penerjemah menerjemahkan kode tersebut menjadi token.

Selanjutnya, Pohon Sintaks Abstrak, AST dibangun dari token ini. Juga, jangan repot-repot, ini hanya beberapa pohon, di node yang Anda operasikan. Katakanlah dalam kasus kami ada BinOp, sebuah operasi biner. Operasi - eksponen, operan: bilangan yang akan dinaikkan, dan daya yang akan dinaikkan.
Lebih lanjut, Anda sudah dapat membuat beberapa kode menggunakan struktur pohon ini. Saya melewatkan banyak langkah, ada langkah pengoptimalan, langkah lainnya. Kemudian pohon sintaks ini diterjemahkan menjadi bytecode.
Yuk simak lebih detail di sini. Sebuah bytecode, seperti namanya, adalah kode yang terdiri dari byte. Dan di Python, mulai dari 3.6, bytecode adalah dua byte.

Byte pertama adalah operator itu sendiri, disebut opcode. Byte kedua adalah argumen oparg. Sepertinya kita punya dari atas. Artinya, urutan byte. Tetapi Python memiliki modul yang disebut dis, dari Disassembler, yang dengannya kita dapat melihat representasi yang lebih dapat dibaca manusia.
Seperti apa bentuknya? Ada nomor baris dari sumber - yang paling kiri. Kolom kedua adalah alamatnya. Seperti yang saya katakan, bytecode di Python 3.6 membutuhkan dua byte, jadi semua alamat genap dan kita melihat 0, 2, 4 ...
Load.name, Load.const - ini adalah opsi kode itu sendiri, yaitu kode dari operasi itu yang Python harus dijalankan. 0, 0, 1, 1 adalah oparg, yaitu argumen dari operasi ini. Mari kita lihat bagaimana hal itu dilakukan selanjutnya.
(...) Mari kita lihat bagaimana bytecode dijalankan dengan Python, struktur apa yang ada untuk ini.

Jika Anda tidak tahu C, tidak apa-apa. Catatan kaki untuk pemahaman umum.
Python memiliki dua struktur yang membantu kita mengeksekusi bytecode. Yang pertama adalah CodeObject, Anda dapat melihat ringkasannya. Padahal, strukturnya lebih besar. Ini adalah kode tanpa konteks. Ini berarti bahwa struktur ini sebenarnya berisi bytecode yang baru saja kita lihat. Ini berisi nama-nama variabel yang digunakan dalam fungsi ini, jika fungsi tersebut berisi referensi ke konstanta, nama konstanta, dan lainnya.

Struktur selanjutnya adalah FrameObject. Ini sudah merupakan konteks eksekusi, struktur yang sudah berisi nilai variabel; referensi ke variabel global; tumpukan eksekusi, yang akan kita bicarakan nanti, dan banyak informasi lainnya. Misalkan jumlah eksekusi instruksi.
Sebagai contoh: jika Anda ingin memanggil suatu fungsi beberapa kali, maka Anda akan memiliki CodeObject yang sama, dan FrameObject baru akan dibuat untuk setiap panggilan. Ini akan memiliki argumennya sendiri, tumpukannya sendiri. Jadi mereka saling berhubungan.

Apa loop interpreter utama, bagaimana bytecode dieksekusi? Anda melihat kami memiliki daftar opcode ini dengan oparg. Bagaimana ini semua dilakukan? Python, seperti interpreter lainnya, memiliki loop yang menjalankan bytecode ini. Artinya, bingkai memasukinya, dan Python hanya melewati bytecode secara berurutan, melihat jenis oparg apa itu, dan pergi ke penangannya menggunakan sakelar besar. Misalnya, hanya satu opcode yang ditampilkan di sini. Misalnya, kita memiliki pengurangan biner di sini, pengurangan biner, katakanlah "AB" akan dilakukan di tempat ini.
Mari kita jelaskan cara kerja pengurangan biner. Sangat sederhana, ini adalah salah satu kode paling sederhana. Fungsi TOP mengambil nilai paling atas dari tumpukan, mengeluarkannya dari yang paling atas, tidak hanya mengeluarkannya dari tumpukan, dan kemudian fungsi PyNumber_Subtract dipanggil. Hasil: Fungsi SET_TOP garis miring didorong kembali ke tumpukan. Jika tumpukan tidak jelas, sebuah contoh akan mengikuti.

Sangat singkat tentang GIL. GIL adalah mutex tingkat proses dengan Python yang mengambil mutex ini dalam loop interpreter utama. Dan hanya setelah itu bytecode mulai dijalankan. Ini dilakukan agar hanya satu utas yang menjalankan bytecode pada satu waktu untuk melindungi struktur internal penerjemah.
Katakanlah, melangkah lebih jauh, bahwa semua objek dengan Python memiliki sejumlah referensi ke sana. Dan jika dua utas mengubah jumlah tautan ini, maka penerjemah akan rusak. Oleh karena itu ada GIL.
Anda akan diberitahu tentang hal ini dalam kuliah tentang pemrograman asynchronous. Bagaimana ini bisa menjadi penting bagi Anda? Multithreading tidak digunakan, karena meskipun Anda membuat beberapa utas, maka secara umum Anda hanya akan menjalankan salah satunya, bytecode akan dijalankan di salah satu utas. Oleh karena itu, gunakan multiprocessing, atau sish extension, atau yang lainnya.

Contoh cepat. Anda dapat menjelajahi bingkai ini dengan aman dari Python. Ada modul sys yang memiliki fungsi garis bawah get_frame. Anda bisa mendapatkan bingkai dan melihat variabel apa yang ada di sana. Ada instruksi. Ini lebih untuk mengajar, dalam kehidupan nyata saya tidak menggunakannya.
Mari kita coba melihat bagaimana tumpukan mesin virtual Python bekerja untuk pemahaman. Kami memiliki beberapa kode yang cukup sederhana yang tidak memahami fungsinya.
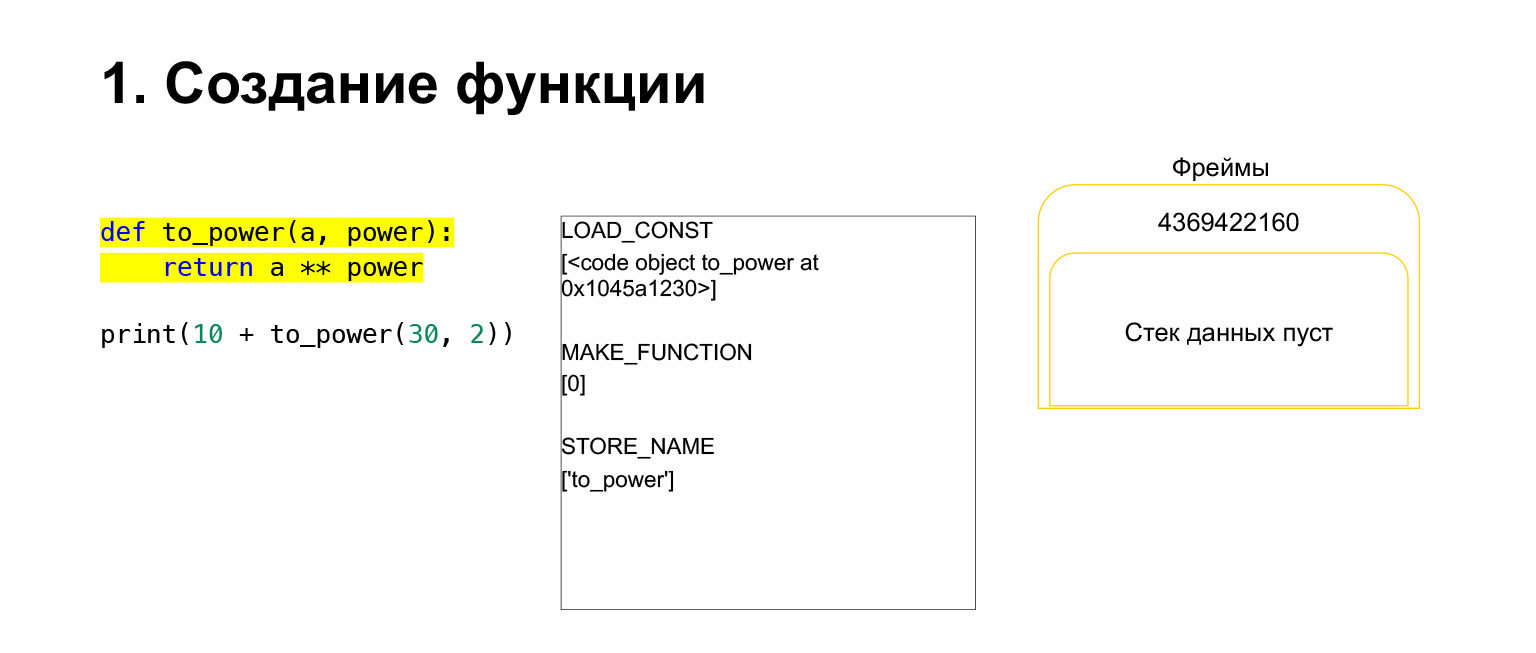
Di sebelah kiri adalah kodenya. Bagian yang sekarang kita periksa disorot dengan warna kuning. Di kolom kedua, kami memiliki bytecode dari bagian ini. Kolom ketiga berisi bingkai bertumpuk. Artinya, setiap FrameObject memiliki tumpukan eksekusinya sendiri.
Apa yang dilakukan Python? Ini hanya berjalan secara berurutan, bytecode, di kolom tengah, mengeksekusi dan bekerja dengan tumpukan.
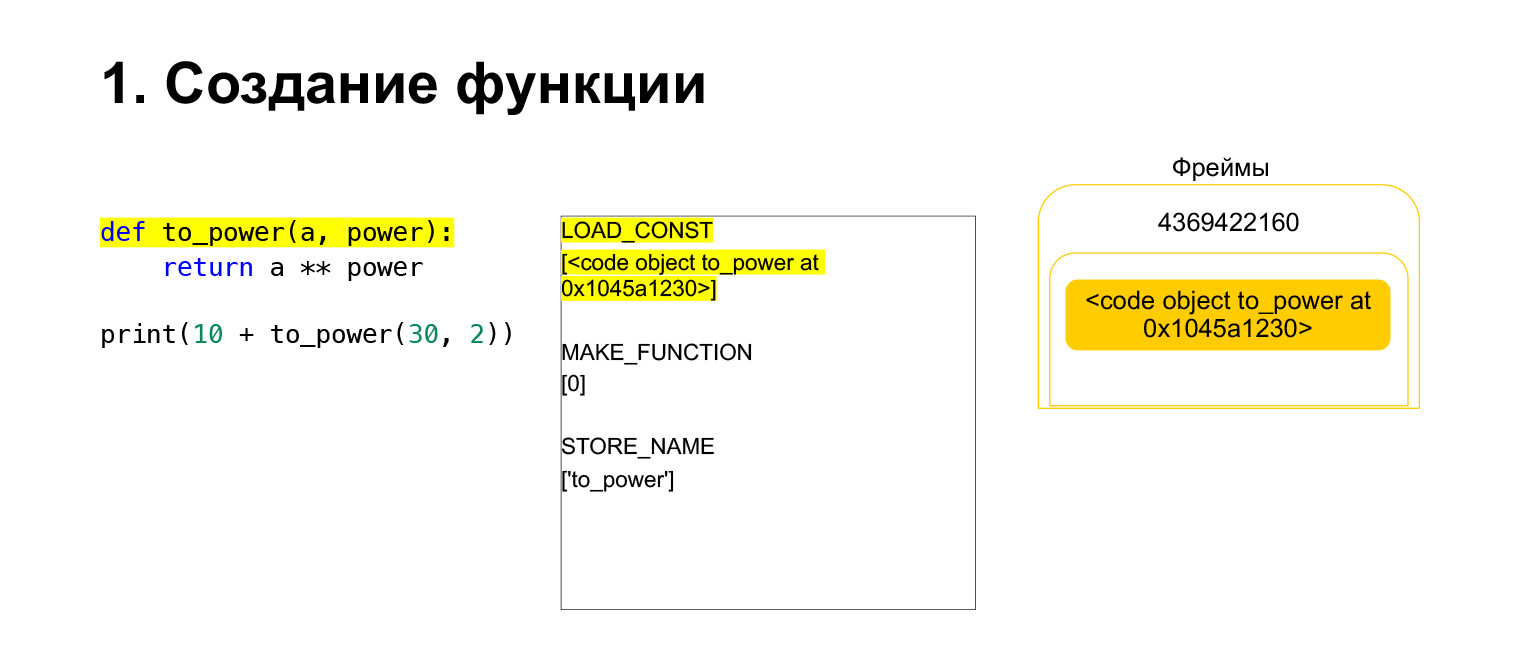
Kami telah menjalankan opcode pertama yang disebut LOAD_CONST. Ini memuat konstanta. Kami melewatkan bagian tersebut, CodeObject dibuat di sana, dan kami memiliki CodeObject di suatu tempat di konstanta. Python memuatnya ke tumpukan menggunakan LOAD_CONST. Kami sekarang memiliki CodeObject di tumpukan dalam bingkai ini. Kita bisa melanjutkan.
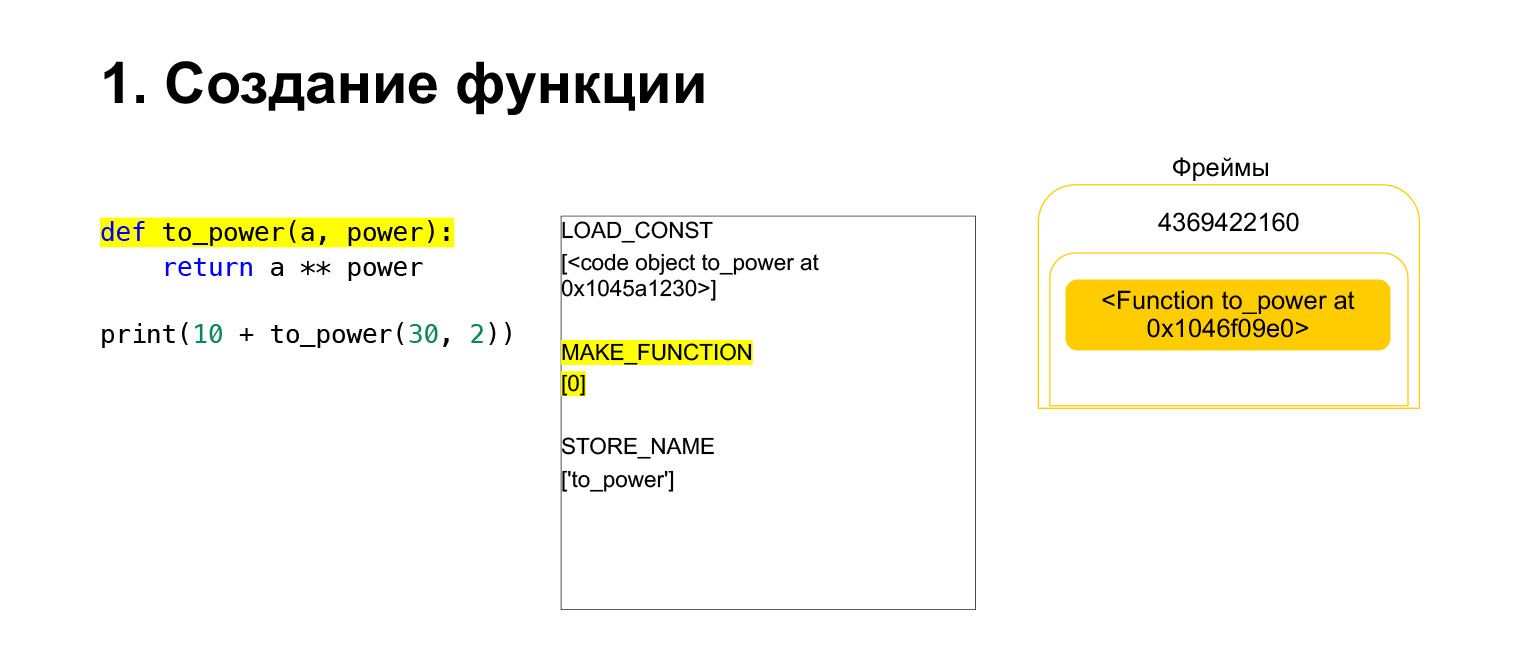
Kemudian Python melakukan opcode MAKE_FUNCTION. MAKE_FUNCTION jelas membuat sebuah fungsi. Ia mengharapkan Anda memiliki CodeObject di tumpukan. Itu melakukan beberapa tindakan, membuat fungsi, dan mendorong fungsi kembali ke tumpukan. Sekarang Anda memiliki FUNCTION, bukan CodeObject yang ada di tumpukan bingkai. Dan sekarang fungsi ini perlu ditempatkan di variabel to_power agar Anda bisa merujuknya.
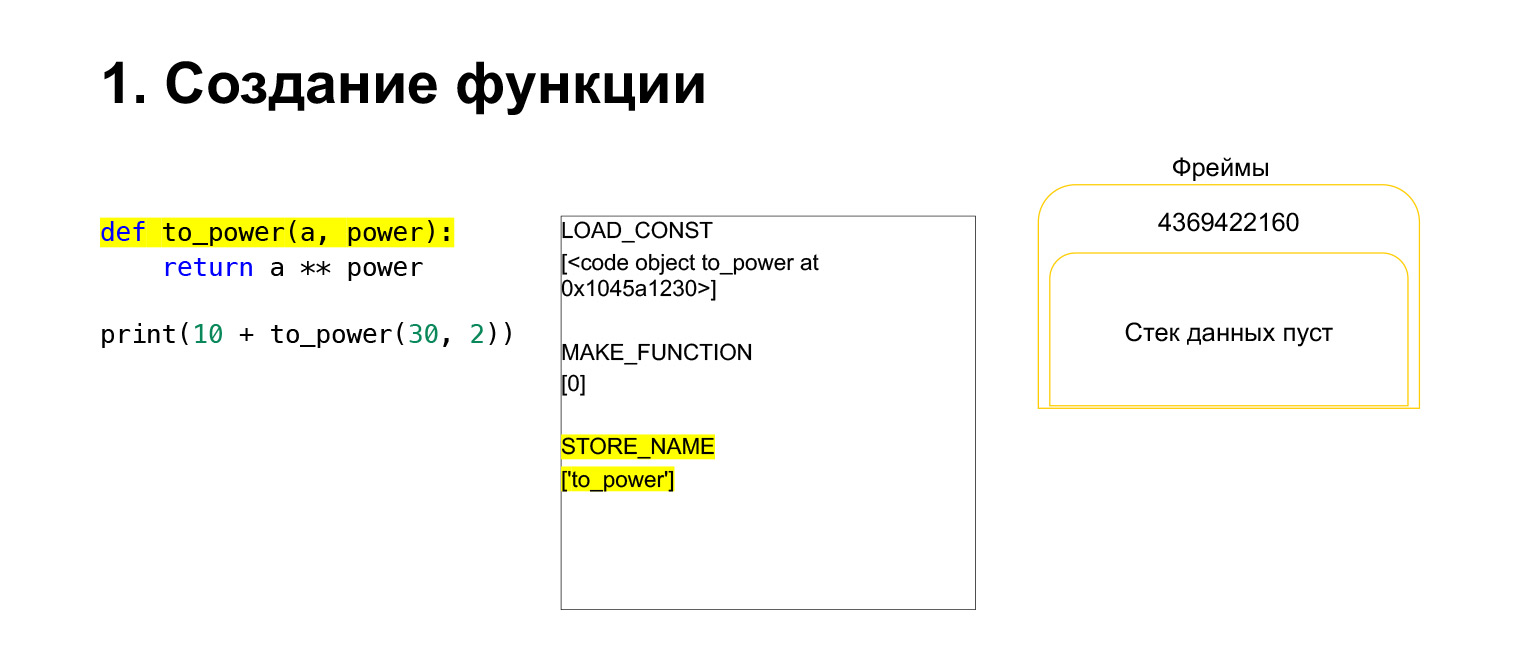
Opcode STORE_NAME dijalankan, itu ditempatkan di variabel to_power. Kami memiliki fungsi di tumpukan, sekarang itu adalah variabel to_power, Anda dapat merujuknya.
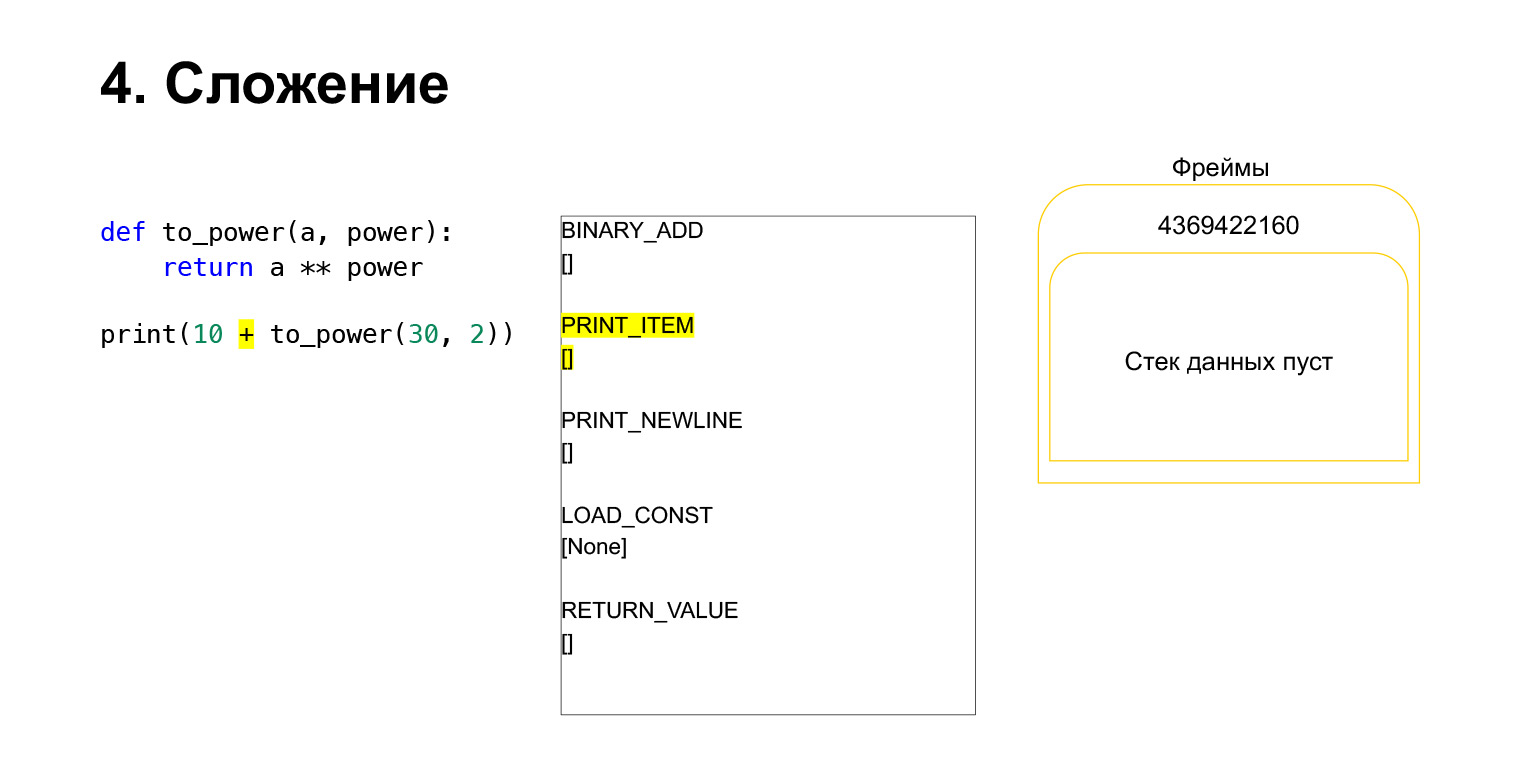
Selanjutnya, kami ingin mencetak 10 + nilai fungsi ini.
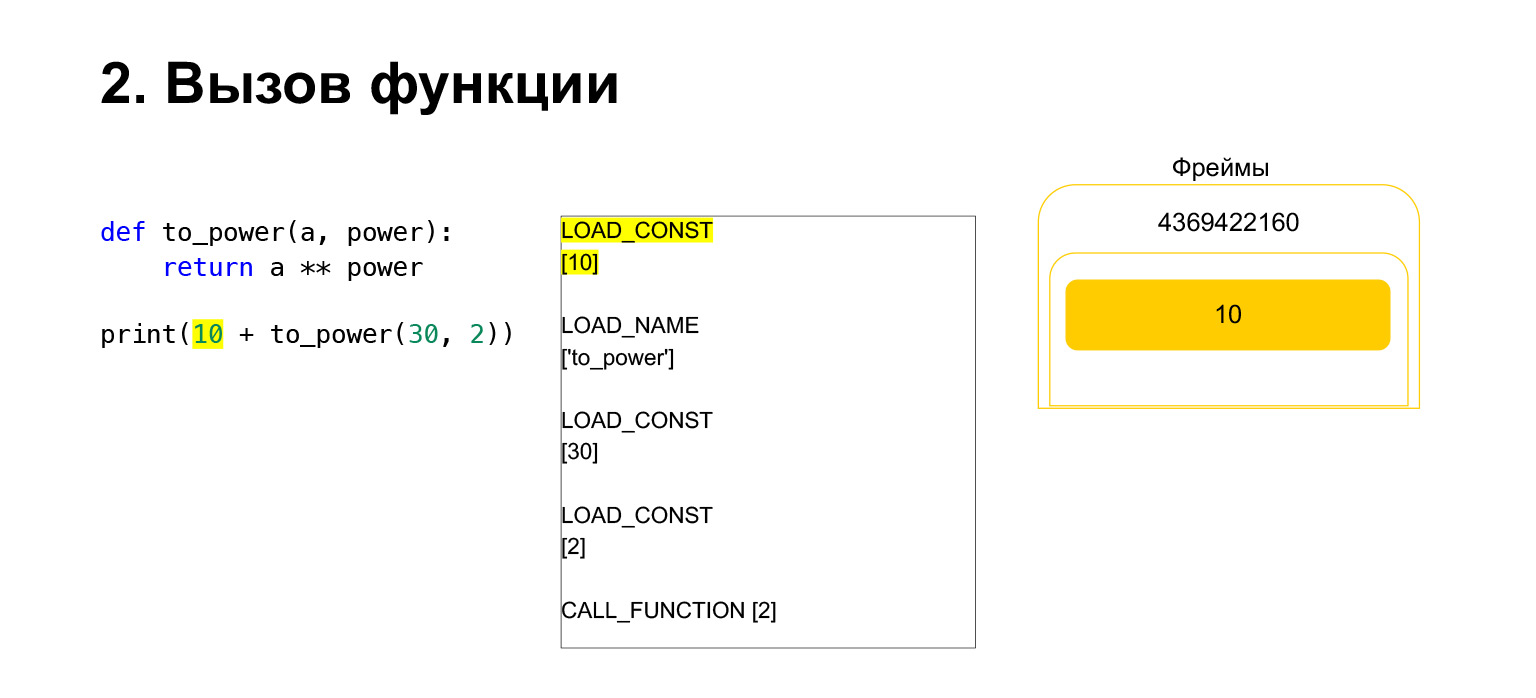
Apa yang dilakukan Python? Ini diubah menjadi bytecode. Opcode pertama yang kami miliki adalah LOAD_CONST. Kami memuat sepuluh teratas ke tumpukan. Selusin muncul di tumpukan. Sekarang kita perlu menjalankan to_power.

Fungsi tersebut dilakukan sebagai berikut. Jika ia memiliki argumen posisi - kami tidak akan melihat sisanya untuk saat ini - maka pertama-tama Python meletakkan fungsinya sendiri di tumpukan. Kemudian ia menempatkan semua argumen dan memanggil CALL_FUNCTION dengan jumlah argumen dari argumen fungsi.
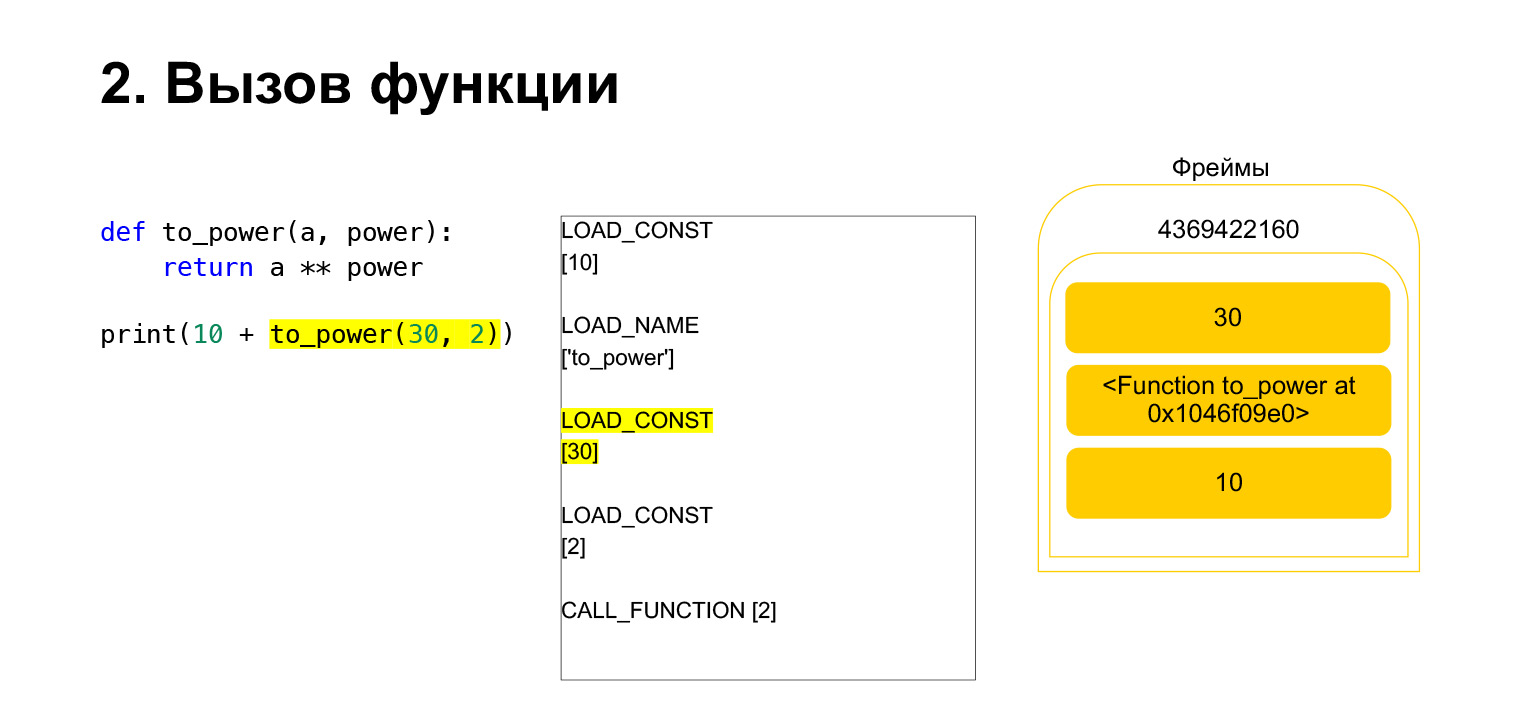
Kami memuat argumen pertama ke tumpukan, ini adalah fungsi.
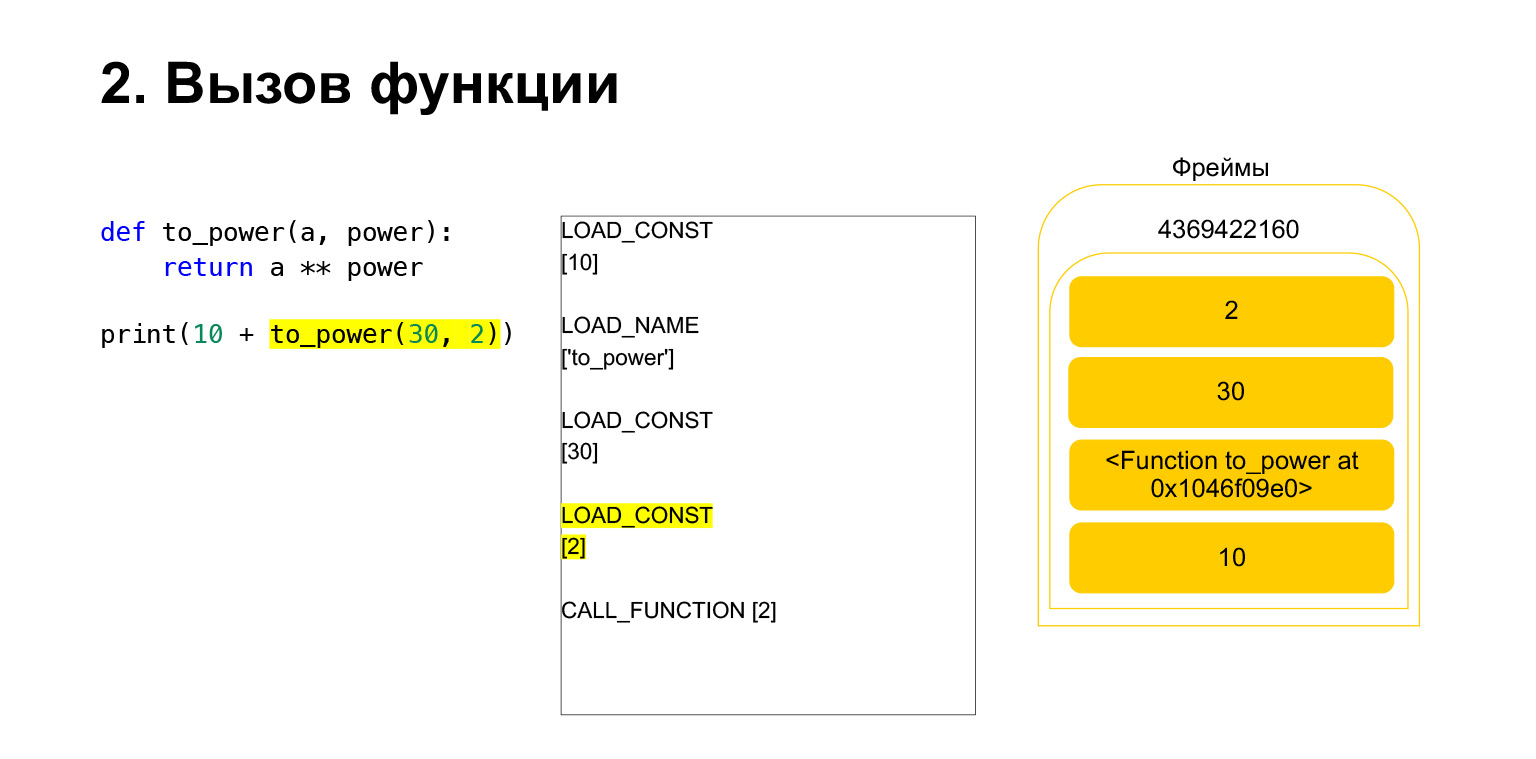
Kami memuat dua argumen lagi ke tumpukan - 30 dan 2. Sekarang kami memiliki fungsi dan dua argumen di tumpukan. Bagian atas tumpukan ada di atas. CALL_FUNCTION menunggu kita. Kami mengatakan: CALL_FUNCTION (2), yaitu, kami memiliki fungsi dengan dua argumen. CALL_FUNCTION mengharapkan untuk memiliki dua argumen di tumpukan, diikuti oleh sebuah fungsi. Kami memilikinya: 2, 30 dan FUNCTION.
Opcode sedang berlangsung.
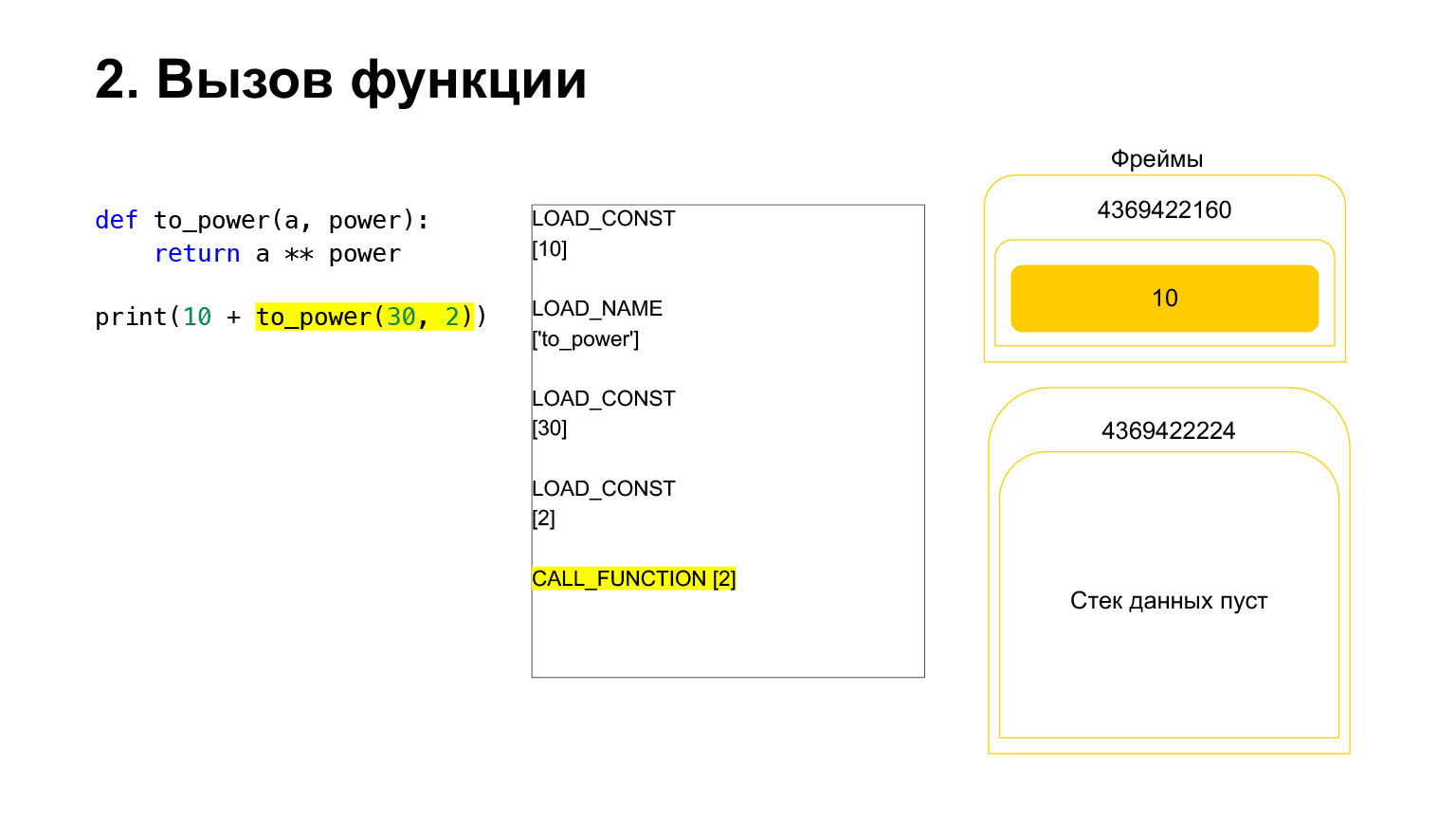
Bagi kami, oleh karena itu, tumpukan itu pergi, fungsi baru dibuat, di mana eksekusi sekarang akan berlangsung.
Bingkai memiliki tumpukannya sendiri. Bingkai baru telah dibuat untuk fungsinya. Masih kosong.
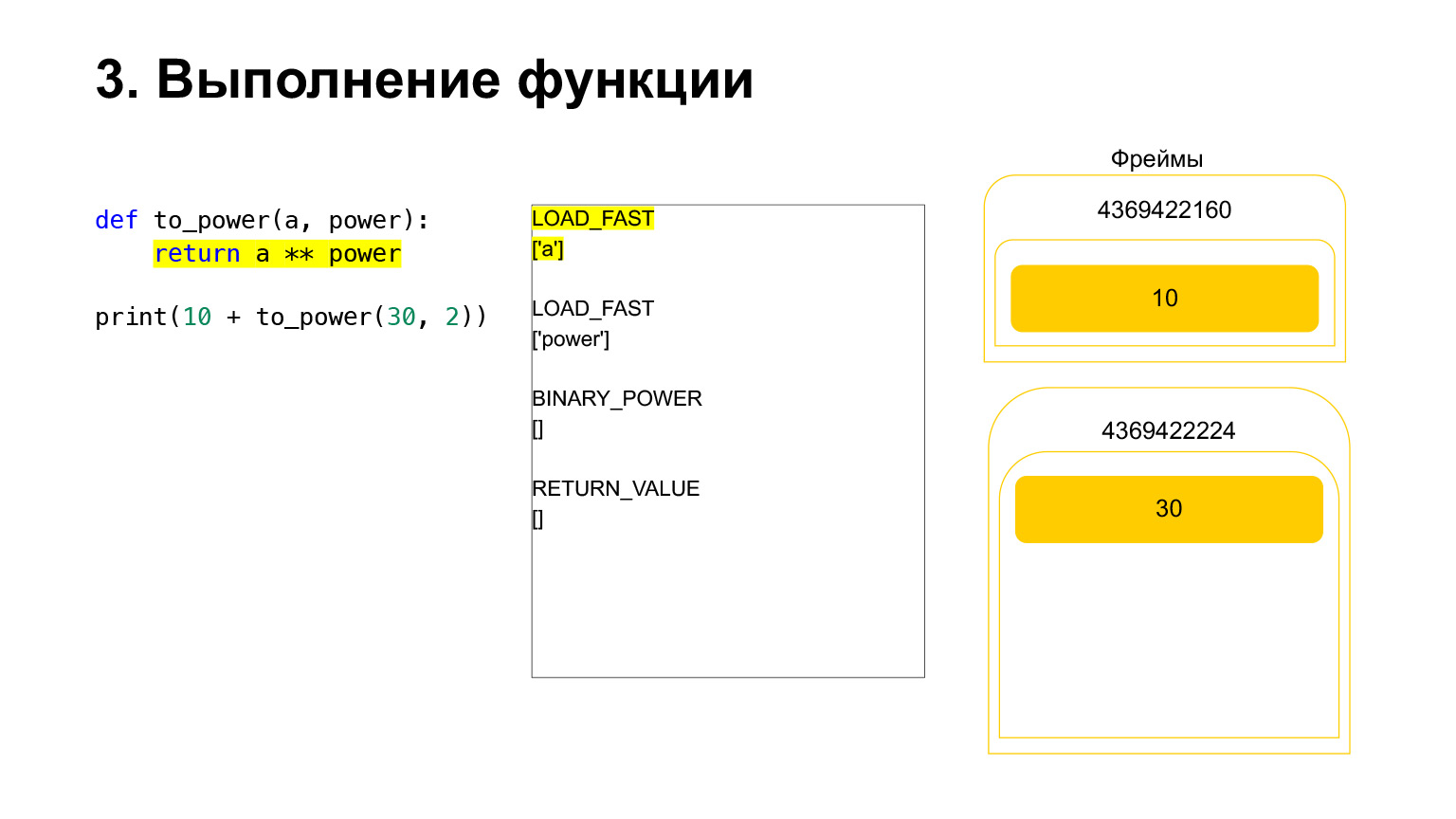
Eksekusi lebih lanjut berlangsung. Di sini sudah lebih mudah. Kita perlu menaikkan A ke tampuk kekuasaan. Kami memuat nilai variabel A - 30 ke tumpukan Nilai daya variabel - 2.
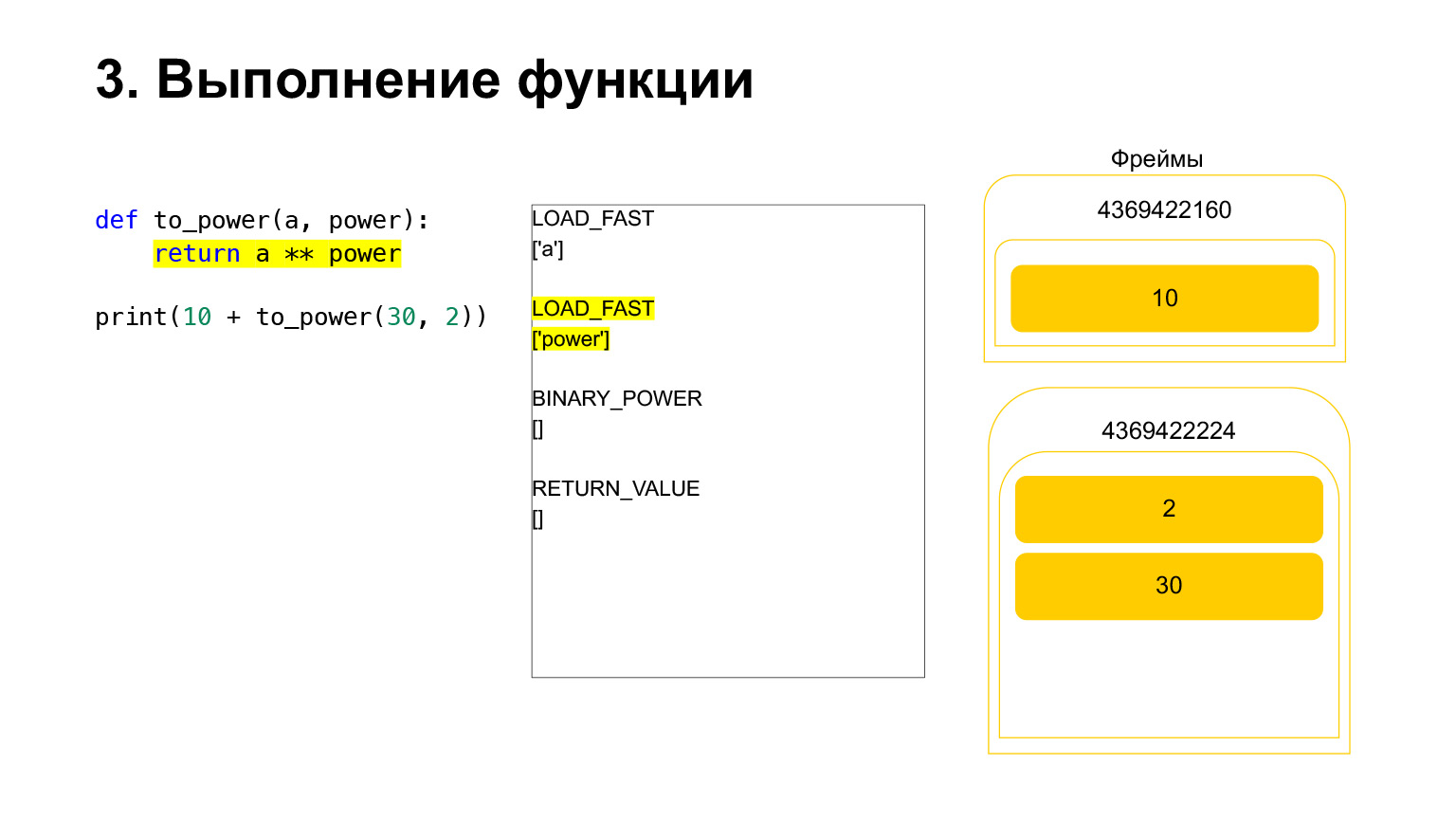
Dan opcode BINARY_POWER dijalankan.
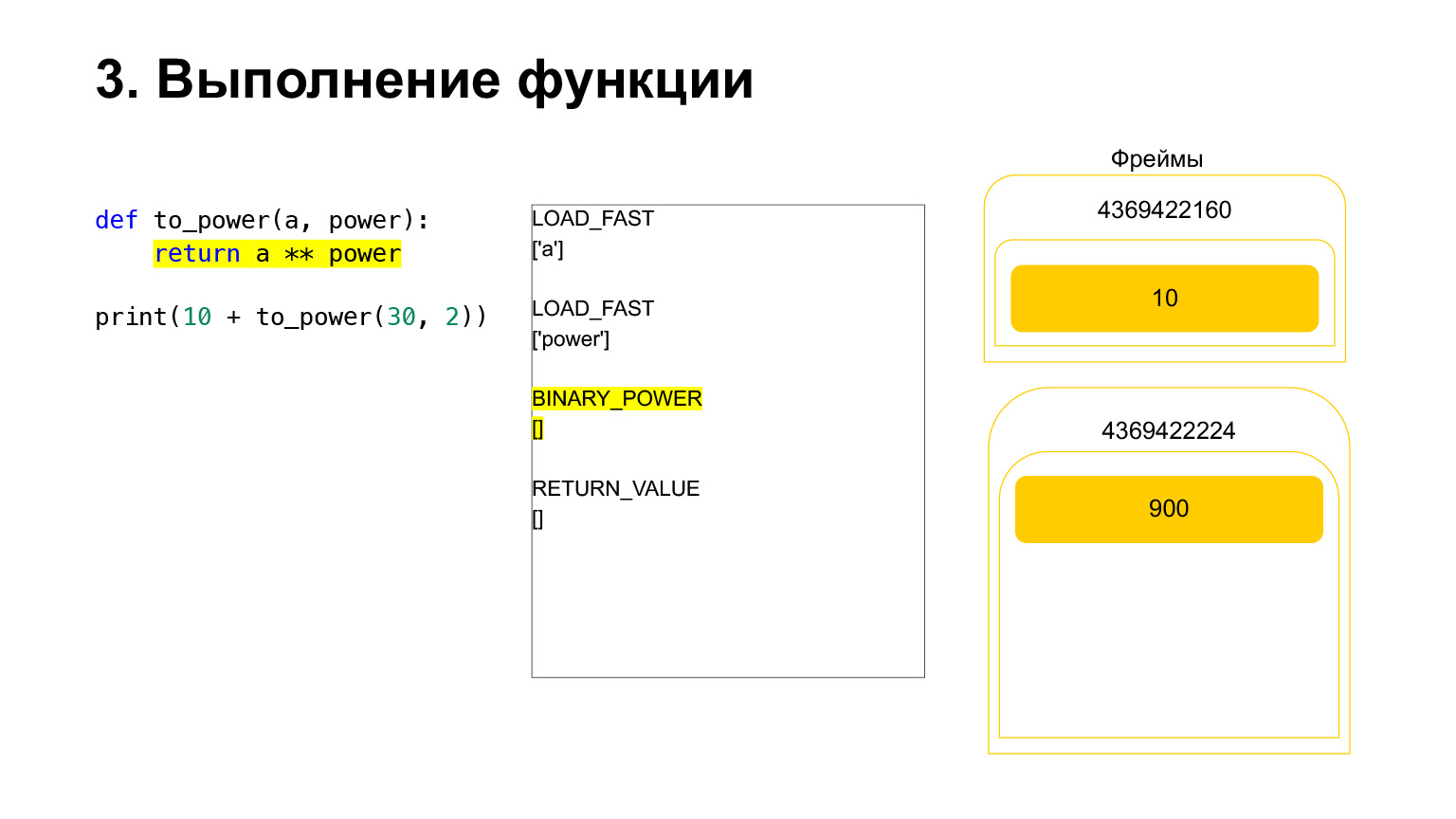
Kami menaikkan satu angka ke pangkat yang lain dan meletakkannya kembali di tumpukan. Ternyata 900 pada tumpukan fungsi.
Opcode berikutnya RETURN_VALUE akan mengembalikan nilai dari tumpukan ke bingkai sebelumnya.

Beginilah pelaksanaannya. Fungsi telah selesai, bingkai kemungkinan besar akan jelas jika tidak memiliki referensi dan akan ada dua angka pada bingkai dari fungsi sebelumnya.

Kemudian semuanya hampir sama. Penambahan terjadi.
(...) Mari kita bicara tentang tipe dan PyObject.
Mengetik

Objek adalah struktur sish, di mana terdapat dua bidang utama: yang pertama adalah jumlah referensi ke objek ini, yang kedua adalah jenis objek, tentu saja, referensi untuk jenis objek tersebut.
Objek lain mewarisi dari PyObject dengan melampirkannya. Artinya, jika kita melihat float, angka floating point, strukturnya adalah PyFloatObject, maka ia memiliki HEAD, yang merupakan struktur PyObject, dan, sebagai tambahan, data, yaitu double ob_fval, di mana nilai float ini sendiri disimpan.

Dan ini adalah tipe objeknya. Kami baru saja melihat tipe di PyObject, itu adalah struktur yang menunjukkan tipe. Sebenarnya, ini juga merupakan struktur-C yang berisi pointer ke fungsi yang mengimplementasikan perilaku objek ini. Artinya, ada struktur yang sangat besar di sana. Ini memiliki fungsi yang ditentukan yang dipanggil jika, misalnya, Anda ingin menambahkan dua objek jenis ini. Atau Anda ingin mengurangi, memanggil objek ini, atau membuatnya. Apa pun yang dapat Anda lakukan dengan tipe harus ditentukan dalam struktur ini.

Sebagai contoh, mari kita lihat int, integer dengan Python. Juga versi yang sangat singkat. Apa yang mungkin menarik bagi kita? Int memiliki tp_name. Anda dapat melihat bahwa ada tp_hash, kita bisa mendapatkan hash int. Jika kita memanggil hash pada int, fungsi ini akan dipanggil. tp_call kita memiliki nol, tidak ditentukan, ini berarti kita tidak dapat memanggil int. tp_str - cast string tidak ditentukan. Python memiliki fungsi str yang dapat diubah menjadi string.
Itu tidak masuk ke slide, tetapi Anda semua sudah tahu bahwa int masih bisa dicetak. Mengapa nol di sini? Karena ada juga tp_repr, Python memiliki dua fungsi penerusan string: str dan repr. Pengecoran lebih detail ke string. Ini sebenarnya ditentukan, hanya tidak masuk ke slide, dan akan dipanggil jika Anda benar-benar mengarah ke sebuah string.
Di bagian paling akhir, kita melihat tp_new - sebuah fungsi yang dipanggil saat objek ini dibuat. tp_init kami memiliki nol. Kita semua tahu bahwa int bukanlah tipe yang bisa berubah, tidak bisa diubah. Setelah membuatnya, tidak ada gunanya mengubahnya, menginisialisasi, jadi ada nol.

Mari kita lihat juga Bool sebagai contoh. Seperti yang mungkin Anda ketahui, Bool dengan Python sebenarnya mewarisi dari int. Artinya, Anda dapat menambahkan Bool, saling berbagi. Ini, tentu saja, tidak dapat dilakukan, tetapi memungkinkan.
Kami melihat bahwa ada tp_base - penunjuk ke objek dasar. Segala sesuatu selain tp_base adalah satu-satunya hal yang telah diganti. Artinya, ia memiliki namanya sendiri, fungsi penyajiannya sendiri, di mana ia bukan angka yang ditulis, melainkan benar atau salah. Representasi sebagai Angka, beberapa fungsi logis diganti di sana. Docstring adalah miliknya dan ciptaannya sendiri. Segala sesuatu yang lain berasal dari int.

Saya akan memberi tahu Anda secara singkat tentang daftar. Dalam Python, list adalah array dinamis. Array dinamis adalah larik yang bekerja seperti ini: Anda menginisialisasi area memori terlebih dahulu dengan beberapa dimensi. Tambahkan elemen di sana. Begitu jumlah elemen melebihi ukuran ini, Anda mengembangkannya dengan margin tertentu, yaitu, bukan per satu, tetapi dengan beberapa nilai lebih dari satu, sehingga ada titik asin yang baik.
Dalam Python, ukurannya tumbuh menjadi 0, 4, 8, 16, 25, yaitu, menurut beberapa jenis rumus yang memungkinkan kita untuk melakukan penyisipan secara asimtotik untuk sebuah konstanta. Dan Anda bisa melihat ada kutipan dari fungsi sisipkan dalam daftar. Artinya, kami sedang melakukan pengubahan ukuran. Jika kami tidak memiliki perubahan ukuran, kami memberikan kesalahan dan menetapkan elemen. Dalam Python, ini adalah larik dinamis normal yang diimplementasikan dalam C.
(...) Mari kita bicara secara singkat tentang kamus. Mereka ada di mana-mana dengan Python.
Kamus
Kita semua tahu bahwa dalam objek, seluruh komposisi kelas terdapat dalam kamus. Banyak hal didasarkan pada mereka. Kamus dengan Python dalam tabel hash.
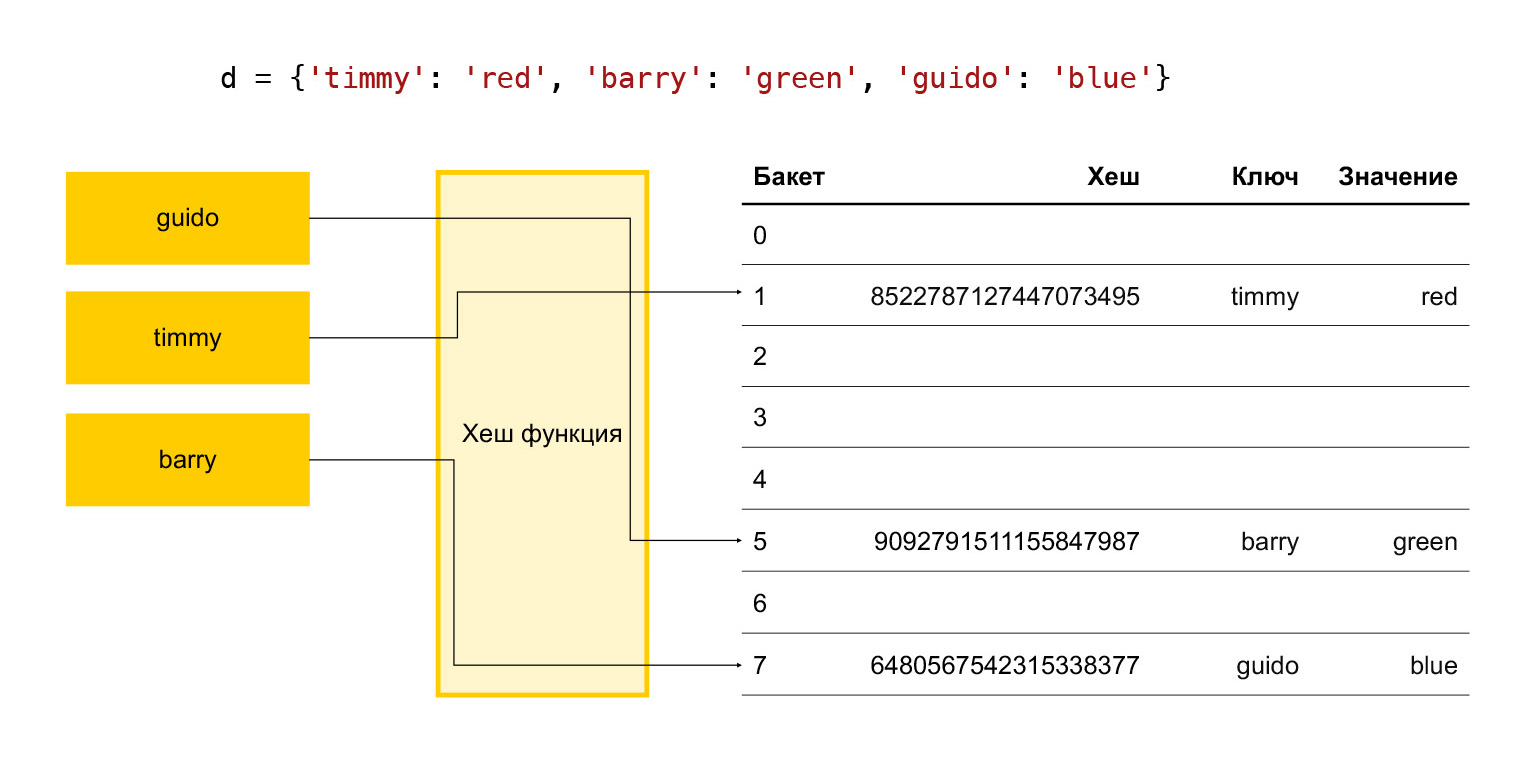
Singkatnya, bagaimana cara kerja tabel hash? Ada beberapa kunci: timmy, barry, guido. Kami ingin memasukkannya ke dalam kamus, kami menjalankan setiap kunci melalui fungsi hash. Ternyata hash. Kami menggunakan hash ini untuk menemukan ember. Keranjang hanyalah angka dalam larik elemen. Pembagian modulo akhir terjadi. Jika ember kosong, kita tinggal memasukkan barang yang diinginkan ke dalamnya. Jika tidak kosong dan sudah ada elemen tertentu di sana, maka ini adalah tabrakan dan kami memilih ember berikutnya, lihat apakah itu gratis atau tidak. Begitu seterusnya sampai kita menemukan ember gratis.
Oleh karena itu, agar operasi penambahan berlangsung dalam waktu yang memadai, kami perlu terus-menerus menyimpan sejumlah bucket kosong. Jika tidak, saat mendekati ukuran larik ini, kami akan mencari bucket gratis untuk waktu yang sangat lama, dan semuanya akan melambat.
Oleh karena itu, diterima secara empiris dalam Python bahwa sepertiga dari elemen array selalu gratis. Jika jumlahnya lebih dari dua pertiga, array akan meluas. Ini tidak baik, karena sepertiga dari elemen terbuang percuma, tidak ada yang berguna disimpan.

Tautan dari slide
Oleh karena itu, sejak versi 3.6, Python telah melakukan hal seperti itu. Di sebelah kiri Anda dapat melihat bagaimana sebelumnya. Kami memiliki larik renggang tempat ketiga elemen ini disimpan. Sejak 3.6, mereka memutuskan untuk membuat larik jarang menjadi larik biasa, tetapi pada saat yang sama menyimpan indeks elemen keranjang dalam indeks larik terpisah.
Jika kita melihat array indeks, maka di keranjang pertama kita memiliki None, di keranjang kedua ada elemen dengan indeks 1 dari array ini, dll.
Hal ini memungkinkan, pertama, untuk mengurangi penggunaan memori, dan kedua, kita juga mengeluarkannya dari kotak secara gratis array yang dipesan. Artinya, kita menambahkan elemen ke array ini, secara kondisional, dengan sish append biasa, dan array secara otomatis diurutkan.
Ada beberapa pengoptimalan menarik yang digunakan Python. Agar tabel hash ini berfungsi, kita perlu memiliki operasi perbandingan elemen. Bayangkan kita meletakkan sebuah elemen dalam tabel hash, dan kemudian kita ingin mengambil sebuah elemen. Kami mengambil hash, pergi ke ember. Kita lihat: embernya penuh, ada sesuatu di sana. Tapi apakah ini elemen yang kita butuhkan? Mungkin ada tabrakan saat ditempatkan dan barang tersebut benar-benar muat di ember lain. Oleh karena itu, kita harus membandingkan kunci. Jika kuncinya salah, kami menggunakan mekanisme penelusuran keranjang berikutnya yang sama yang digunakan untuk resolusi tabrakan. Dan kami melangkah lebih jauh.

Tautan dari slide
Oleh karena itu, kita perlu memiliki fungsi perbandingan kunci. Secara umum, fitur perbandingan objek bisa sangat mahal. Oleh karena itu digunakan optimasi seperti itu. Pertama, kami membandingkan ID item. ID di CPython adalah, seperti yang Anda ketahui, posisi dalam memori.
Jika ID-nya sama, maka mereka adalah objek yang sama dan, tentu saja, sama. Kemudian kami mengembalikan True. Jika tidak, lihat hashnya. Hash harus menjadi operasi yang cukup cepat jika kita belum menimpa. Kami mengambil hash dari dua objek ini dan membandingkan. Jika hashnya tidak sama, maka objeknya pasti tidak sama, jadi kami mengembalikan False.
Dan hanya dalam kasus yang sangat tidak mungkin - jika hash kita sama, tetapi kita tidak tahu apakah itu objek yang sama - baru kemudian kita membandingkan objek itu sendiri.
Hal kecil yang menarik: Anda tidak dapat memasukkan apa pun ke dalam kunci selama iterasi. Ini salah.

Di bawah tenda, kamus memiliki variabel bernama versi, yang menyimpan versi kamus. Ketika Anda mengubah kamus, versi berubah, Python memahami ini dan memberi Anda kesalahan.

Kamus dapat digunakan untuk apa dalam contoh yang lebih praktis? Di Taksi kami memiliki pesanan, dan pesanan memiliki status yang dapat berubah. Saat Anda mengubah status, Anda harus melakukan tindakan tertentu: mengirim SMS, mencatat pesanan.
Logika ini ditulis dengan Python. Agar tidak menulis besar jika formulir "jika status pesanan adalah ini dan itu, lakukan ini," ada dikt di mana kuncinya adalah status pesanan. Dan untuk VALUE ada tupel, yang berisi semua penangan yang harus dijalankan saat bertransisi ke status ini. Ini adalah praktik umum, pada kenyataannya, ini adalah pengganti sakelar.

Beberapa hal lagi berdasarkan tipe. Saya akan memberi tahu Anda tentang kekekalan. Ini adalah tipe data yang tidak dapat diubah, dan dapat diubah, masing-masing, adalah jenis yang dapat diubah: dikte, kelas, instance kelas, sheet, dan mungkin sesuatu yang lain. Hampir semua yang lain adalah string, angka biasa - mereka tidak bisa diubah. Untuk apa tipe yang bisa berubah? Pertama, mereka membuat kode lebih mudah dipahami. Artinya, jika Anda melihat dalam kode bahwa ada sesuatu yang merupakan tupel, apakah Anda memahami bahwa itu tidak berubah lebih jauh, dan ini memudahkan Anda untuk membaca kode? mengerti apa yang akan terjadi selanjutnya. Di tuple ds Anda tidak bisa mengetik item. Anda akan memahami ini, dan ini akan membantu dalam membaca Anda dan semua orang yang akan membaca kode untuk Anda.
Oleh karena itu, ada aturannya: jika Anda tidak mengubah sesuatu, lebih baik menggunakan tipe yang tidak dapat diubah. Ini juga mengarah pada pekerjaan yang lebih cepat. Ada dua konstanta yang digunakan tuple: pit_tuple, tap_tuple, max, dan CC. Apa gunanya? Untuk semua tupel hingga ukuran 20, metode alokasi khusus digunakan, yang mempercepat alokasi ini. Dan bisa ada hingga dua ribu objek seperti itu dari setiap jenis, sangat banyak. Ini jauh lebih cepat daripada sheet, jadi jika Anda menggunakan tuple, Anda akan lebih cepat.
Ada juga pemeriksaan runtime. Jelasnya, jika Anda mencoba menyambungkan sesuatu ke suatu objek, dan itu tidak mendukung fungsi ini, maka akan ada kesalahan, beberapa pemahaman bahwa Anda melakukan sesuatu yang salah. Kunci di dict hanya dapat berupa objek yang memiliki hash yang tidak berubah selama masa pakainya. Hanya objek yang tidak dapat diubah yang memenuhi definisi ini. Hanya mereka yang bisa menjadi kunci dikt.

Seperti apa bentuknya di C? Contoh. Di sebelah kiri adalah tupel, di sebelah kanan adalah daftar biasa. Di sini, tentu saja, tidak semua perbedaan terlihat, tetapi hanya perbedaan yang ingin saya tunjukkan. Dalam daftar di bidang tp_hash kami memiliki NotImplemented, yaitu daftar tidak memiliki hash. Di tuple ada beberapa fungsi yang benar-benar akan mengembalikan hash kepada Anda. Inilah mengapa tuple, antara lain, bisa menjadi kunci dikt, dan daftar tidak bisa.
Hal berikutnya yang disorot adalah fungsi penugasan item, sq_ass_item. Dalam daftar itu, dalam tupel itu nol, yaitu, Anda secara alami tidak dapat menetapkan apa pun ke tupel.

Satu hal lagi. Python tidak menyalin apa pun sampai kami memintanya. Ini juga harus diingat. Jika Anda ingin menyalin sesuatu, gunakan, katakanlah, modul salin, yang memiliki fungsi copy.deepcopy. Apa bedanya? copy menyalin objek, jika itu adalah objek kontainer, seperti daftar saudara. Semua referensi yang ada di objek ini dimasukkan ke dalam objek baru. Dan deepcopy secara rekursif menyalin semua objek di dalam wadah ini dan seterusnya.
Atau, jika Anda ingin menyalin daftar dengan cepat, Anda dapat menggunakan potongan titik dua. Anda akan mendapatkan salinannya, cara pintas seperti itu sederhana.
(...) Selanjutnya, mari kita bicara tentang manajemen memori.
Manajemen memori

Mari kita ambil modul sys kita. Ini memiliki fungsi yang memungkinkan Anda melihat apakah itu menggunakan memori apa pun. Jika Anda memulai penerjemah dan melihat statistik perubahan memori, Anda akan melihat bahwa Anda telah membuat banyak objek, termasuk yang kecil. Dan ini hanya objek yang saat ini dibuat.
Faktanya, Python membuat banyak objek kecil saat runtime. Dan jika kita menggunakan fungsi malloc standar untuk mengalokasikannya, kita akan segera menemukan kenyataan bahwa memori kita terfragmentasi dan, karenanya, alokasi memori menjadi lambat.

Ini menyiratkan kebutuhan untuk menggunakan pengelola memori Anda sendiri. Singkatnya, bagaimana cara kerjanya? Python mengalokasikan blok memori itu sendiri, yang disebut arena, masing-masing 256 kilobyte. Di dalam, dia mengiris dirinya menjadi kumpulan empat kilobyte, ini adalah ukuran halaman memori. Di dalam kolam, kami memiliki blok dengan ukuran berbeda, dari 16 hingga 512 byte.
Ketika kami mencoba untuk mengalokasikan kurang dari 512 byte ke suatu objek, Python memilih dengan caranya sendiri blok yang cocok untuk objek ini dan menempatkan objek di blok ini.
Jika objek dibatalkan alokasinya, dihapus, blok ini ditandai sebagai bebas. Tetapi itu tidak diberikan ke sistem operasi, dan di lokasi berikutnya kita dapat menulis objek ini ke dalam blok yang sama. Ini sangat mempercepat alokasi memori.

Mengosongkan memori. Sebelumnya kita melihat struktur PyObject. Dia memiliki refcnt ini - jumlah referensi. Ini bekerja dengan sangat sederhana. Saat Anda mereferensikan objek ini, Python menambah jumlah referensi. Segera setelah Anda memiliki objek, referensi menghilang, Anda membatalkan alokasi jumlah referensi.
Apa yang disorot dengan warna kuning. Jika refcnt bukan nol, maka kita sedang melakukan sesuatu di sana. Jika refcnt nol, maka kita segera membatalkan alokasi objek. Kami tidak menunggu pengumpul sampah, tidak ada, tetapi saat ini kami menghapus memori.
Jika Anda menemukan metode del, itu hanya menghapus pengikatan variabel ke objek. Dan metode __del__, yang dapat Anda definisikan di kelas, dipanggil saat objek benar-benar dihapus dari memori. Anda akan memanggil del pada objek, tetapi jika masih memiliki referensi, objek tersebut tidak akan dihapus di mana pun. Dan Finalizernya, __del__, tidak akan dipanggil. Meski disebut sangat mirip.
Demo singkat tentang bagaimana Anda dapat melihat jumlah tautan. Ada modul sys favorit kami, yang memiliki fungsi getrefcount. Anda dapat melihat jumlah tautan ke suatu objek.

Aku akan memberitahumu lebih banyak. Sebuah benda dibuat. Jumlah tautan diambil darinya. Detail menarik: variabel A menunjuk ke TaxiOrder. Anda mengambil jumlah tautan, Anda akan mendapatkan cetakan "2". Tampaknya mengapa? Kami memiliki satu referensi objek. Tetapi ketika Anda memanggil getrefcount, objek ini dibungkus di sekitar argumen di dalam fungsi. Oleh karena itu, Anda sudah memiliki dua referensi ke objek ini: yang pertama adalah variabel, yang kedua adalah argumen fungsi. Oleh karena itu, "2" dicetak.
Sisanya sepele. Kami menetapkan satu variabel lagi ke objek, kami mendapatkan 3. Kemudian kami menghapus pengikatan ini, kami mendapatkan 2. Kemudian kami menghapus semua referensi ke objek ini, dan finalizer dipanggil, yang akan mencetak baris kami.

(...) Ada fitur menarik lainnya dari CPython, yang tidak dapat dibangun, dan tampaknya tidak disebutkan di mana pun di dokumen. Integer sering digunakan. Akan sia-sia untuk membuatnya kembali setiap saat. Oleh karena itu, angka yang paling umum digunakan, pengembang Python memilih rentang dari –5 hingga 255, mereka adalah Singleton. Artinya, mereka dibuat sekali, terletak di suatu tempat di penerjemah, dan ketika Anda mencoba mendapatkannya, Anda mendapatkan referensi ke objek yang sama. Kami mengambil A dan B, satu, mencetaknya, membandingkan alamatnya. Benar. Dan kami memiliki, misalnya, 105 referensi ke objek ini, hanya karena sekarang jumlahnya sangat banyak.
Jika kita mengambil beberapa angka yang lebih besar - misalnya, 1408 - objek-objek ini tidak sama untuk kita dan masing-masing, ada dua referensi ke sana. Faktanya, satu.
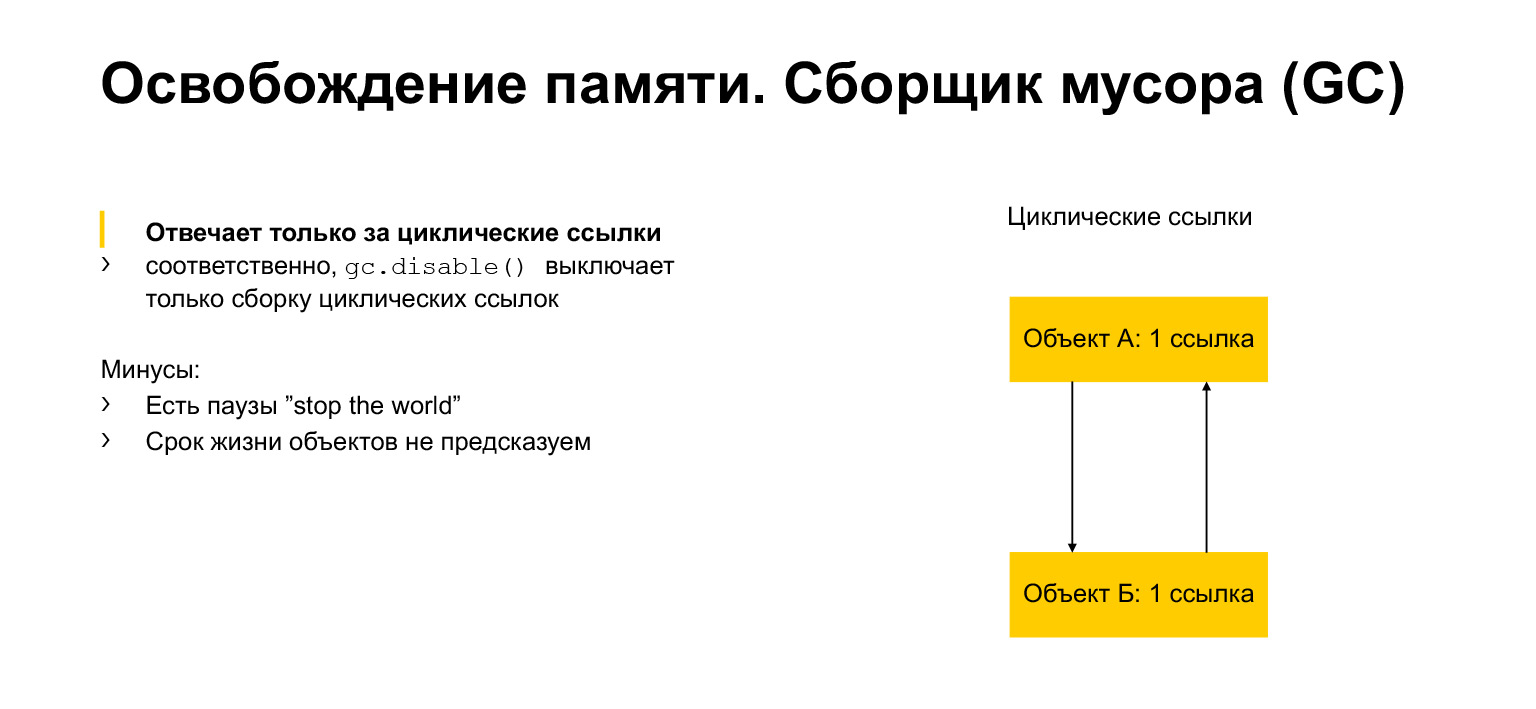
Kami berbicara sedikit tentang alokasi memori dan pembebasan. Sekarang mari kita bicara tentang pengumpul sampah. Untuk apa ini? Tampaknya kami memiliki sejumlah tautan. Setelah tidak ada yang mereferensikan objek tersebut, kami dapat menghapusnya. Tapi kita bisa memiliki hubungan melingkar. Sebuah objek bisa merujuk pada dirinya sendiri, misalnya. Atau, seperti pada contoh, mungkin ada dua objek, masing-masing mengacu pada tetangga. Ini disebut siklus. Dan kemudian benda-benda ini tidak pernah bisa memberikan referensi ke objek lain. Tetapi pada saat yang sama, misalnya, mereka tidak dapat dijangkau dari bagian lain dari program. Kami perlu menghapusnya karena tidak dapat diakses, tidak berguna, tetapi memiliki tautan. Inilah kegunaan modul pengumpul sampah. Ini mendeteksi siklus dan menghapus objek-objek ini.
Bagaimana cara kerjanya? Pertama, saya akan berbicara secara singkat tentang generasi, dan kemudian tentang algoritme.
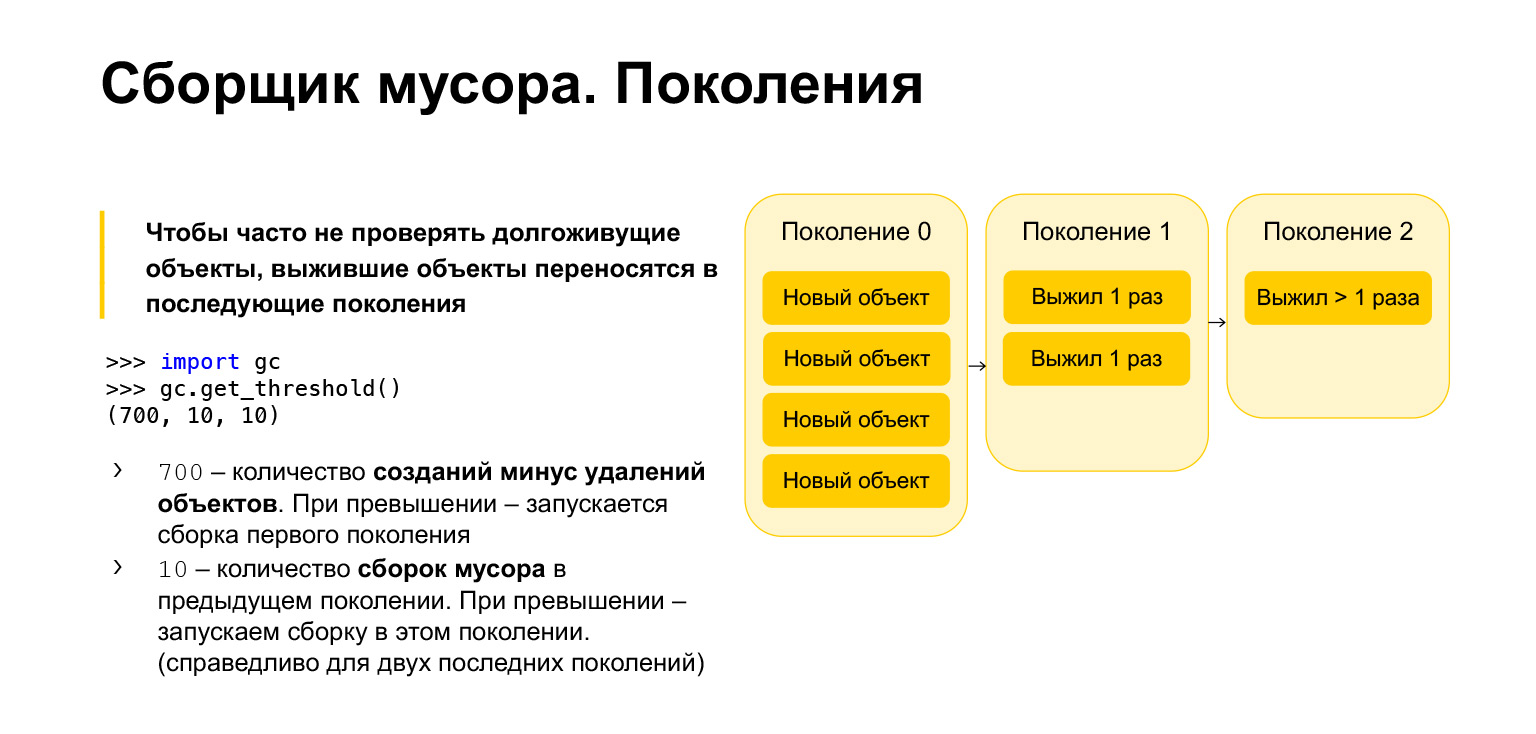
Untuk mengoptimalkan kecepatan pengumpul sampah dengan Python, ini bersifat generasi, yaitu bekerja menggunakan generasi. Ada tiga generasi. Untuk apa mereka dibutuhkan? Jelas bahwa objek yang telah dibuat baru-baru ini lebih mungkin tidak diperlukan daripada objek yang berumur panjang. Katakanlah Anda membuat sesuatu selama menjalankan fungsi. Kemungkinan besar, saat keluar dari fungsi, itu tidak akan diperlukan. Ini sama dengan loop, dengan variabel sementara. Semua benda ini perlu lebih sering dibersihkan daripada yang sudah ada sejak lama.
Oleh karena itu, semua objek baru ditempatkan di generasi nol. Generasi ini dibersihkan secara berkala. Python memiliki tiga parameter. Setiap generasi memiliki parameternya sendiri-sendiri. Anda bisa mendapatkannya, mengimpor pengumpul sampah, memanggil fungsi get_threshold, dan mendapatkan ambang tersebut.
Secara default ada 700, 10, 10. Berapakah 700? Ini adalah jumlah pembuatan objek dikurangi jumlah penghapusan. Begitu jumlahnya melebihi 700, generasi baru pengumpulan sampah dimulai. Dan 10, 10 adalah jumlah pengumpulan sampah pada generasi sebelumnya, setelah itu kita perlu memulai pengumpulan sampah pada generasi saat ini.
Artinya, saat kami menghapus generasi nol 10 kali, kami akan mulai membangunnya di generasi pertama. Setelah membersihkan 10 kali generasi pertama, kami akan mulai membangun di generasi kedua. Karenanya, objek berpindah dari generasi ke generasi. Jika mereka bertahan hidup, mereka pindah ke generasi pertama. Jika mereka selamat dari pengumpulan sampah pada generasi pertama, mereka dipindahkan ke generasi kedua. Dari generasi kedua mereka tidak lagi pindah kemana-mana, mereka tetap disana selamanya.
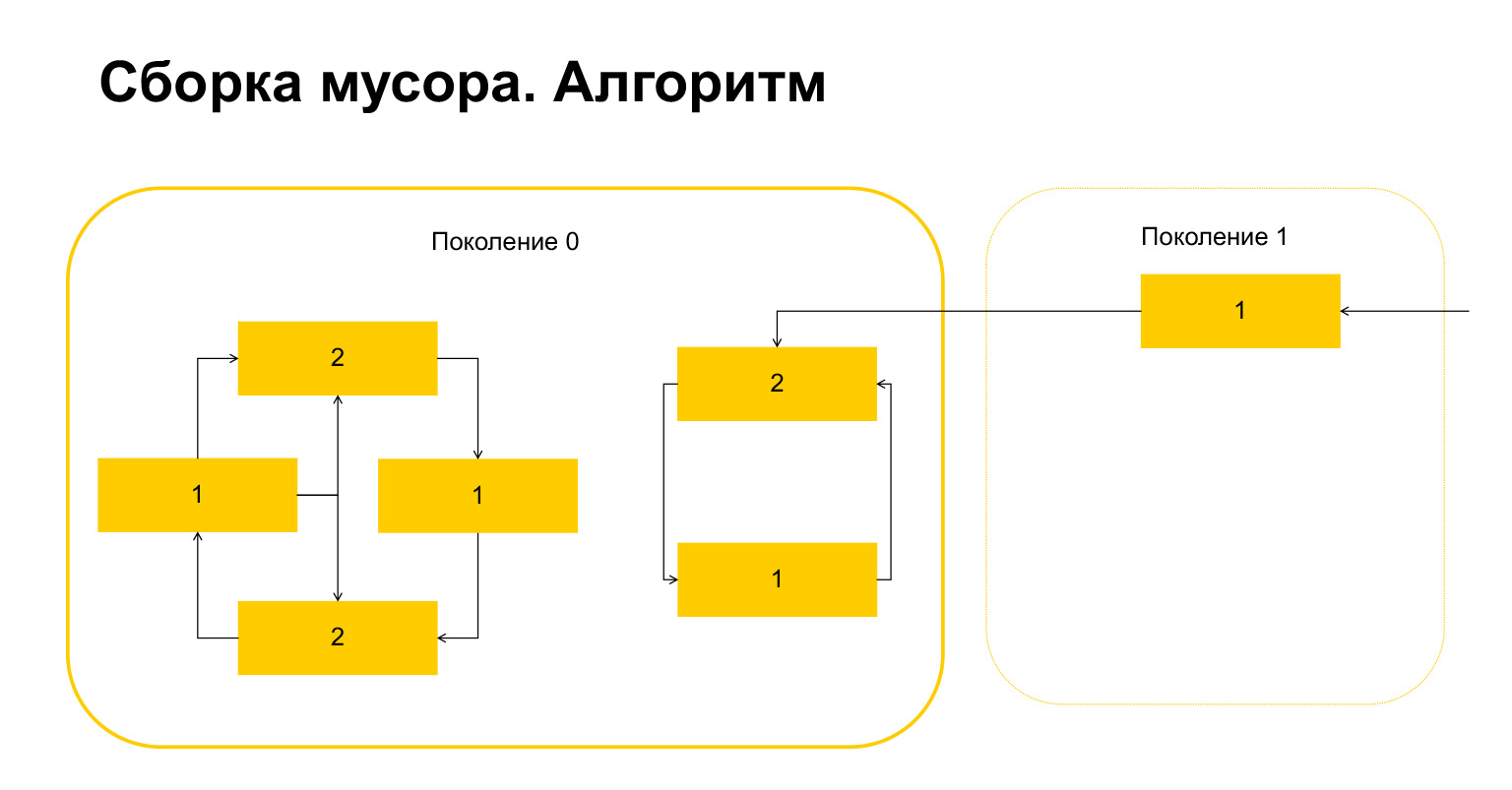
Bagaimana cara kerja pengumpulan sampah dengan Python? Katakanlah kita memulai pengumpulan sampah pada generasi 0. Kita memiliki beberapa objek, mereka memiliki siklus. Ada sekelompok objek di kiri yang merujuk satu sama lain, dan grup di kanan juga merujuk satu sama lain. Detail penting - mereka juga direferensikan dari generasi 1. Bagaimana Python mendeteksi loop? Pertama, variabel sementara dibuat untuk setiap objek dan jumlah referensi ke objek ini ditulis ke dalamnya. Ini tercermin pada slide. Kami memiliki dua tautan ke objek di atas. Sebuah objek dari generasi 1, bagaimanapun, sedang direferensikan dari luar. Python mengingat ini. Kemudian (penting!) Ini melewati setiap objek dalam pembuatan dan menghapus, mengurangi penghitung dengan jumlah referensi dalam generasi ini.
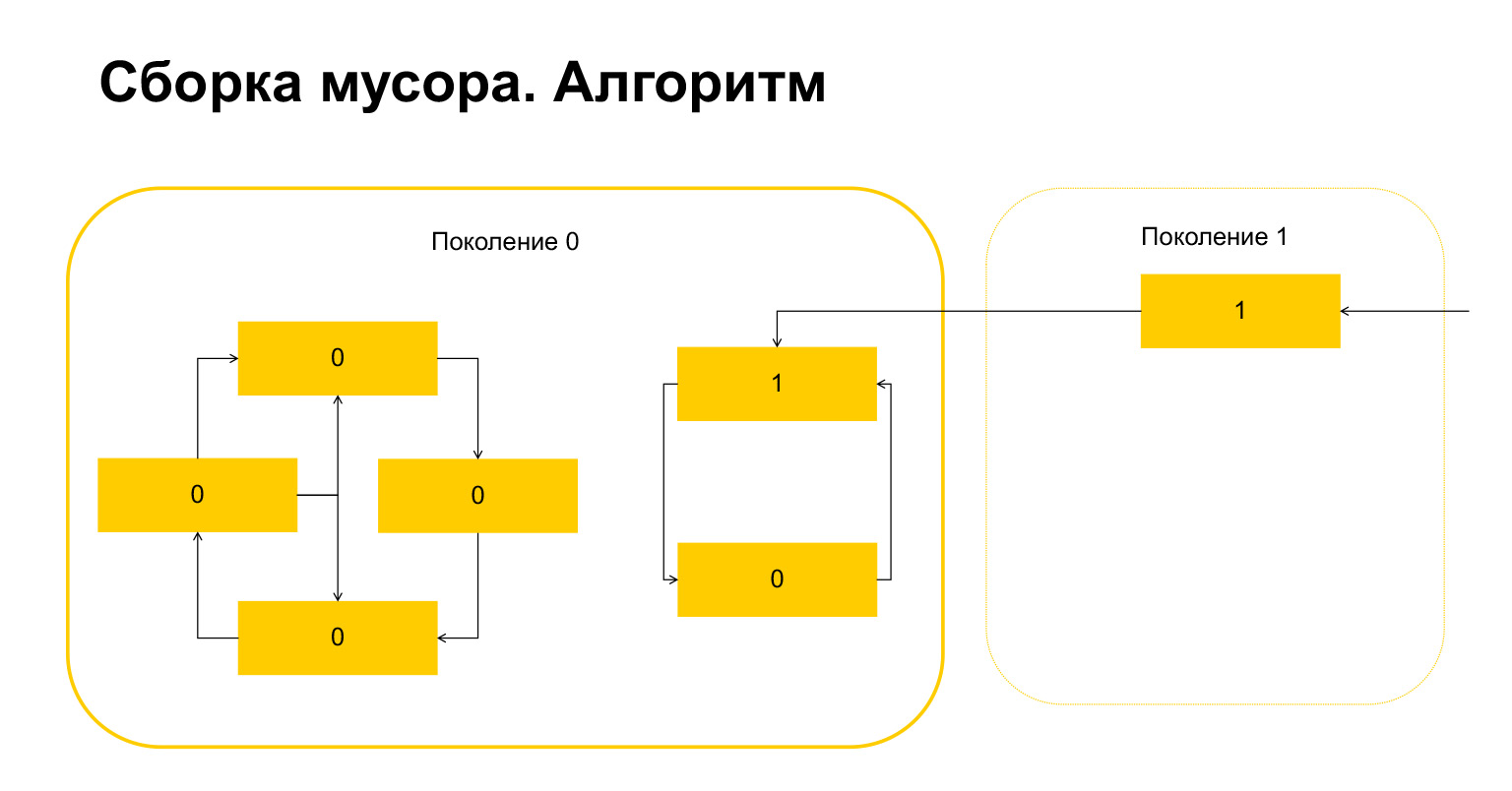
Inilah yang terjadi. Untuk objek yang hanya merujuk satu sama lain dalam satu generasi, variabel ini secara otomatis menjadi sama dengan nol berdasarkan konstruksi. Hanya objek yang direferensikan dari luar yang memiliki unit.
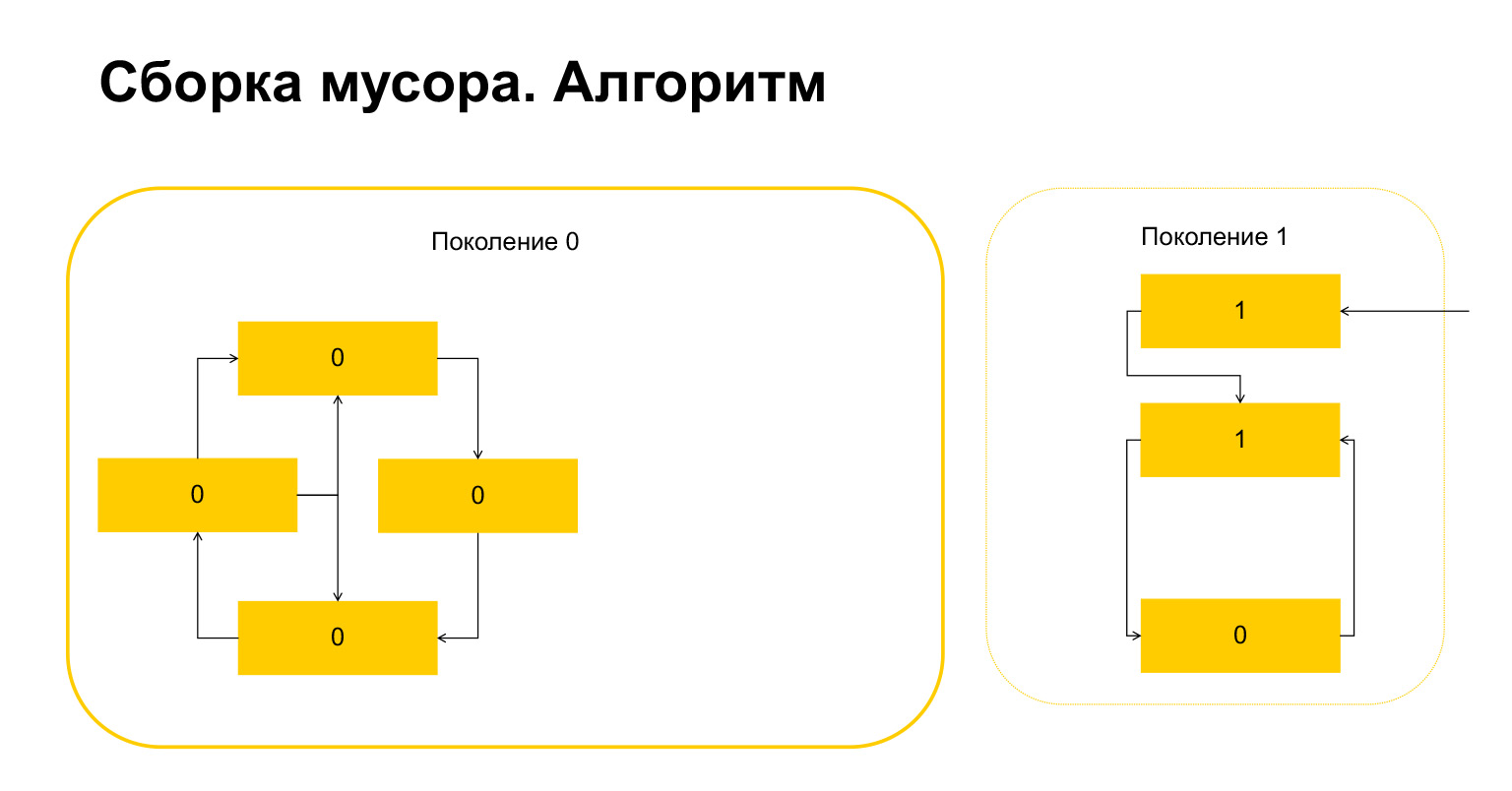
Apa yang dilakukan Python selanjutnya? Dia, karena ada di sini, mengerti bahwa benda-benda ini dirujuk dari luar. Dan kami tidak dapat menghapus objek ini atau yang ini, karena jika tidak, kami akan berakhir dengan situasi yang tidak valid. Oleh karena itu, Python mentransfer objek ini ke generasi 1, dan semua yang tersisa di generasi 0 akan dihapus, dibersihkan. Segala sesuatu tentang pemulung.
(...) Berpindah. Saya akan memberi tahu Anda secara singkat tentang generator.
Generator

Sayangnya, tidak ada pengenalan tentang generator di sini, tetapi mari kita coba memberi tahu Anda apa itu generator. Ini adalah sejenis, secara relatif, fungsi yang mengingat konteks pelaksanaannya menggunakan kata yield. Pada titik ini, ia mengembalikan nilai dan mengingat konteksnya. Anda kemudian dapat merujuknya lagi dan mendapatkan nilai yang diberikannya.
Apa yang dapat Anda lakukan dengan generator? Anda dapat menghasilkan generator, itu akan mengembalikan nilai kepada Anda, ingat konteksnya. Anda dapat kembali untuk generator. Dalam hal ini, eksekusi StopIteration akan dilempar, nilai di dalamnya akan berisi nilai, dalam hal ini Y.
Fakta yang kurang diketahui: Anda dapat mengirim beberapa nilai ke generator. Artinya, Anda memanggil metode kirim pada generator, dan Z - lihat contoh - akan menjadi nilai ekspresi hasil yang akan dipanggil oleh generator. Jika Anda ingin mengontrol generator, Anda dapat meneruskan nilai di sana.
Anda juga dapat memberikan pengecualian di sana. Hal yang sama: ambil objek generator, buang. Anda melempar kesalahan di sana. Anda akan mengalami kesalahan di tempat hasil terakhir. Dan tutup - Anda dapat menutup generator. Kemudian eksekusi GeneratorExit dimunculkan dan generator diharapkan tidak menghasilkan apa-apa lagi.

Di sini saya hanya ingin berbicara tentang cara kerjanya di CPython. Anda sebenarnya memiliki kerangka eksekusi di generator Anda. Dan seperti yang kita ingat, FrameObject berisi seluruh konteks. Dari sini tampak jelas bagaimana konteks itu dipertahankan. Artinya, Anda hanya memiliki bingkai di generator.

Saat Anda menjalankan fungsi generator, bagaimana Python tahu Anda tidak perlu menjalankannya, tetapi membuat generator? CodeObject yang kita lihat memiliki flag. Dan saat Anda memanggil suatu fungsi, Python memeriksa benderanya. Jika flag CO_GENERATOR ada, ia memahami bahwa fungsi tersebut tidak perlu dijalankan, tetapi hanya perlu membuat generator. Dan dia menciptakannya. Fungsi PyGen_NewWithQualName.

Bagaimana eksekusinya? Dari GENERATOR_FUNCTION, generator memanggil GENERATOR_Object terlebih dahulu. Kemudian Anda dapat memanggil GENERATOR_Object menggunakan next untuk mendapatkan nilai berikutnya. Bagaimana panggilan berikutnya terjadi? Kerangkanya diambil dari generator, disimpan dalam variabel F. Dan dikirim ke loop utama interpreter EvalFrameEx. Anda dieksekusi seperti dalam kasus fungsi normal. Kode peta YIELD_VALUE digunakan untuk mengembalikan, menjeda eksekusi generator. Itu mengingat semua konteks dalam bingkai dan berhenti mengeksekusi. Ini adalah topik kedua dari belakang.
(...) Rangkuman singkat tentang apa itu pengecualian dan bagaimana mereka digunakan dalam Python.
Pengecualian

Pengecualian adalah cara untuk menangani situasi kesalahan. Kami memiliki blok percobaan. Kita dapat mencoba menulis hal-hal yang dapat memberikan pengecualian. Katakanlah kita dapat meningkatkan kesalahan menggunakan kata menaikkan. Dengan bantuan kecuali kita dapat menangkap jenis pengecualian tertentu, dalam hal ini SomeError. Dengan kecuali kita menangkap semua pengecualian tanpa ekspresi. Blok else lebih jarang digunakan, tetapi blok itu ada dan hanya akan dijalankan jika tidak ada pengecualian yang dimunculkan. Blok terakhir akan tetap dijalankan.
Bagaimana cara kerja pengecualian di CPython? Selain tumpukan eksekusi, setiap bingkai juga memiliki tumpukan blok. Lebih baik menggunakan contoh.


Tumpukan blok adalah tumpukan di mana blok ditulis. Setiap blok memiliki tipe, Handler, handler. Handler adalah alamat bytecode yang akan dilewati untuk memproses blok ini. Bagaimana cara kerjanya? Katakanlah kita memiliki beberapa kode. Kami membuat blok percobaan, kami memiliki blok pengecualian tempat kami menangkap pengecualian RuntimeError, dan blok terakhir, yang seharusnya ada dalam kasus apa pun.
Ini semua merosot menjadi bytecode ini. Pada permulaan bytecode pada blok percobaan, kita melihat dua opcode SETUP_FINALLY dengan argumen ke 40 dan ke 12. Ini adalah alamat dari penangan. Ketika SETUP_FINALLY dijalankan, sebuah blok ditempatkan pada tumpukan blok, yang mengatakan: untuk memproses saya, dalam satu kasus pergi ke alamat ke-40, di kasus lain - ke alamat ke-12.
12 down stack adalah kecuali, baris yang berisi else RuntimeError. Ini berarti bahwa ketika kita memiliki pengecualian, kita akan melihat tumpukan blok untuk mencari blok dengan tipe SETUP_FINALLY. Temukan blok di mana ada transisi ke alamat 12, pergi ke sana. Dan di sana kami memiliki perbandingan pengecualian dengan tipe: kami memeriksa apakah tipe pengecualian adalah RuntimeError atau bukan. Jika sama, kami menjalankannya, jika tidak, kami melompat ke tempat lain.
AKHIRNYA adalah blok berikutnya dalam tumpukan blok. Ini akan dieksekusi untuk kita jika kita memiliki pengecualian lain. Kemudian pencarian akan dilanjutkan pada tumpukan blok ini, dan kita akan mencapai blok SETUP_FINALLY berikutnya. Akan ada penangan yang memberitahu kita, misalnya, alamat 40. Kita lompat ke alamat 40 - Anda dapat melihat dari kode bahwa ini adalah blok terakhir.

Ia bekerja sangat sederhana di CPython. Kami memiliki semua fungsi yang dapat memunculkan pengecualian mengembalikan kode nilai. Jika semua baik-baik saja, 0 dikembalikan Jika ini adalah kesalahan, -1 atau NULL dikembalikan, tergantung pada jenis fungsinya.
Ambil sidebar seperti itu di C. Kita lihat bagaimana pembagian terjadi. Dan ada pemeriksaan bahwa jika B sama dengan nol dan kita tidak ingin membagi dengan nol, maka kita ingat pengecualian dan mengembalikan NULL. Artinya telah terjadi kesalahan. Oleh karena itu, semua fungsi lain yang lebih tinggi pada tumpukan panggilan juga harus membuang NULL. Kita akan melihat ini di loop utama interpreter dan lompat ke sini.

Ini adalah pelepasan tumpukan. Semuanya seperti yang saya katakan: kami menelusuri seluruh tumpukan blok dan memeriksa bahwa tipenya adalah SETUP_FINALLY. Jika demikian, lompati Handler, sangat sederhana. Ini, faktanya, semuanya.
Tautan
Penerjemah umum:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
Manajemen memori:
arctrix.com/nas/python/gc
rushter.com/blog/python -memory-management
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
Pengecualian:
bugs.python.org/issue17611