Dalam ceramah saya, saya berbagi pengalaman saya menggunakan Alembic, alat yang terbukti baik untuk mengelola migrasi. Mengapa memilih Alembic, bagaimana menggunakannya untuk mempersiapkan migrasi, bagaimana menjalankannya (secara otomatis atau manual), bagaimana menyelesaikan masalah perubahan yang tidak dapat diubah, mengapa migrasi uji, masalah apa yang dapat diungkapkan oleh tes dan bagaimana menerapkannya - Saya mencoba menjawab semua pertanyaan ini. Pada saat yang sama, saya membagikan beberapa peretasan kehidupan yang akan membuat bekerja dengan migrasi di Alembic menjadi mudah dan menyenangkan.
Sejak hari laporan, kode di GitHub telah sedikit diperbarui, ada lebih banyak contoh. Jika Anda ingin melihat kode persis seperti yang muncul di slide, berikut adalah link ke komit sejak saat itu.
- Halo! Nama saya Alexander, saya bekerja di Edadil. Hari ini saya ingin memberi tahu Anda bagaimana kami hidup dengan migrasi dan bagaimana Anda dapat hidup bersama mereka. Mungkin ini akan membantu Anda hidup lebih mudah.
Apa itu migrasi?
Sebelum kita mulai, ada baiknya membicarakan tentang apa itu migrasi secara umum. Misalnya, Anda memiliki aplikasi dan Anda membuat beberapa tablet agar berfungsi, buka mereka. Kemudian Anda meluncurkan versi baru, di mana sesuatu telah berubah - pelat pertama telah berubah, yang kedua tidak, dan yang ketiga tidak ada sebelumnya, tetapi muncul.

Kemudian versi baru aplikasi muncul, di mana beberapa pelat dihapus, tidak ada yang terjadi pada yang lain. Apa itu? Kita dapat mengatakan bahwa ini adalah keadaan yang dapat dijelaskan dengan migrasi. Ketika kita berpindah dari satu kondisi ke kondisi lain, ini adalah peningkatan, ketika kita ingin kembali - menurunkan versi.
Apa itu migrasi?

Di satu sisi, ini adalah kode yang mengubah status database. Di sisi lain, inilah proses yang kami mulai.

Properti apa yang harus dimiliki migrasi? Penting bahwa status tempat kita beralih dalam versi aplikasi bersifat atomik. Jika, misalnya, kita ingin memiliki dua tabel, tetapi hanya satu yang muncul, ini dapat menyebabkan konsekuensi yang tidak terlalu baik dalam produksi.
Penting bagi kami untuk dapat mengembalikan perubahan kami, karena jika Anda meluncurkan versi baru, versi tersebut tidak lepas landas dan Anda tidak dapat melakukan rollback, semuanya biasanya berakhir dengan buruk.
Penting juga agar versi diurutkan sehingga Anda dapat merangkai cara penggulirannya.
Alat
Bagaimana kita bisa menerapkan migrasi ini?
Ide pertama yang muncul di benak: oke, migrasi adalah SQL, mengapa tidak mengambil dan membuat file SQL dengan kueri. Ada beberapa modul lagi yang bisa mempermudah hidup kita.

Jika kita melihat apa yang terjadi di dalam, maka memang ada beberapa permintaan. Bisa BUAT TABEL, ALTER, dan lainnya. Di file downgrade_v1.sql, kami membatalkan semuanya.

Mengapa Anda tidak melakukan ini? Terutama karena Anda perlu melakukannya dengan tangan Anda. Jangan lupa untuk mulai menulis, kemudian lakukan perubahan Anda. Saat Anda menulis kode, Anda perlu mengingat semua dependensi dan apa yang harus dilakukan dalam urutan apa. Ini adalah pekerjaan yang cukup rutin, sulit dan memakan waktu.
Anda tidak memiliki perlindungan terhadap peluncuran file yang salah secara tidak sengaja. Anda perlu menjalankan semua file dengan tangan. Jika Anda memiliki 15 migrasi, itu tidak mudah. Anda perlu memanggil beberapa psql 15 kali, itu tidak akan terlalu keren.
Yang terpenting, Anda tidak pernah tahu status database Anda. Anda perlu menuliskan di suatu tempat - di selembar kertas, di tempat lain - file mana yang Anda unduh dan mana yang tidak. Kedengarannya juga tidak bagus.

Ada modul migrasi-yoyo . Ini mendukung database paling umum dan menggunakan kueri mentah.

Jika kita melihat apa yang dia tawarkan kepada kita, sepertinya ini. Kami melihat SQL yang sama. Sudah ada kode Python di sebelah kanan yang mengimpor pustaka yoyo.

Jadi, kita sudah bisa memulai migrasi, tepatnya secara otomatis. Dengan kata lain, ada perintah yang membuat dan menambahkan migrasi baru ke rantai, di mana kita dapat menulis kode SQL kita. Dengan menggunakan perintah, Anda dapat menerapkan satu atau lebih migrasi, Anda dapat memutar kembali, ini sudah selangkah lebih maju.

Kelebihannya adalah Anda tidak perlu lagi menulis di selembar kertas permintaan apa yang telah Anda lakukan pada database, file apa yang telah Anda luncurkan dan di mana Anda perlu melakukan rollback jika terjadi sesuatu. Anda memiliki semacam perlindungan yang sangat mudah: Anda tidak akan lagi dapat menjalankan migrasi yang dirancang untuk sesuatu yang lain, untuk transisi antara dua status database lainnya. Nilai tambah yang sangat besar: hal ini melakukan setiap migrasi dalam transaksi terpisah. Ini juga memberikan jaminan seperti itu.

Kerugiannya jelas. Anda masih memiliki SQL mentah. Misalnya, jika Anda memiliki produksi data besar dengan logika sprawling di Python, Anda tidak dapat menggunakannya, karena Anda hanya memiliki SQL.
Selain itu, Anda akan menemukan banyak pekerjaan rutin yang tidak dapat diotomatiskan. Penting untuk melacak semua hubungan antara tabel - apa yang bisa ditulis di suatu tempat, dan apa yang belum mungkin. Secara umum, ada kerugian yang cukup jelas.
Modul lain yang perlu diperhatikan dan yang menjadi topik pembicaraan hari ini adalah Alembic .

Ia memiliki hal yang sama dengan yoyo, dan banyak lagi. Ini tidak hanya memonitor migrasi Anda dan tahu cara membuatnya, tetapi juga memungkinkan Anda untuk menulis logika bisnis yang sangat kompleks, menghubungkan seluruh produksi data Anda, fungsi apa pun dengan Python. Tarik data dan proses secara internal jika Anda mau. Jika Anda tidak mau, Anda tidak perlu melakukannya.
Dia dapat menulis kode untuk Anda secara otomatis dalam banyak kasus. Tidak selalu, tentu saja, tetapi kedengarannya seperti nilai tambah yang bagus setelah Anda harus banyak menulis dengan tangan.
Dia punya banyak hal keren. Misalnya, SQLite tidak sepenuhnya mendukung ALTER TABLE. Dan Alembic memiliki fungsionalitas yang memungkinkan Anda melewati ini dengan mudah dalam beberapa baris, dan Anda bahkan tidak akan memikirkannya.
Dalam slide sebelumnya, ada modul Django-migrations. Ini juga merupakan modul yang sangat bagus untuk migrasi. Prinsipnya sebanding dengan Alembic dalam fungsi. Satu-satunya perbedaan adalah bahwa ini khusus untuk kerangka kerja, dan Alembic tidak.
SQLAlchemy
Karena Alembic didasarkan pada SQLAlchemy, saya sarankan untuk menjalankan sedikit melalui SQLAlchemy untuk mengingat atau mempelajari apa itu.

Sejauh ini, kami telah melihat kueri mentah. Kueri mentah tidak buruk. Ini bisa sangat bagus. Ketika Anda memiliki aplikasi yang sangat banyak, mungkin inilah yang Anda butuhkan. Tidak perlu membuang waktu untuk mengubah beberapa objek menjadi beberapa query.
Tidak ada perpustakaan tambahan yang diperlukan. Anda hanya tinggal mengambil sopir dan itu saja, berhasil. Tetapi misalnya, jika Anda menulis kueri kompleks, itu tidak akan semudah itu: Anda dapat membuat konstanta, memunculkannya, menulis kode banyak baris yang besar. Tetapi jika Anda memiliki 10-20 permintaan seperti itu, itu sudah sangat sulit untuk dibaca. Maka Anda tidak dapat menggunakannya kembali dengan cara apa pun. Anda memiliki banyak teks dan, tentu saja, fungsi untuk bekerja dengan string, f-string, dan sebagainya, tetapi ini kedengarannya tidak terlalu bagus. Sulit dibaca.
Jika, misalnya, Anda memiliki kelas yang di dalamnya Anda juga ingin memiliki kueri dan struktur yang kompleks, indentasi sangat merepotkan. Jika Anda ingin melakukan migrasi mentah, satu-satunya cara untuk menemukan tempat Anda menggunakan sesuatu adalah dengan grep. Dan Anda juga tidak memiliki alat dinamis untuk kueri dinamis.
Misalnya, tugas yang sangat mudah. Anda memiliki entitas, ia memiliki 15 bidang dalam satu pelat. Anda ingin membuat permintaan PATCH. Tampaknya ini sangat sederhana. Cobalah untuk menulis ini pada kueri mentah. Ini tidak akan terlihat sangat bagus, dan permintaan penarikan kemungkinan besar tidak akan disetujui.

Ada alternatif untuk ini - Pembuat kueri. Ini pasti memiliki kekurangan karena memungkinkan Anda untuk merepresentasikan kueri Anda sebagai objek dengan Python.
Anda harus membayar untuk kenyamanan baik pada saat membuat permintaan maupun dalam memori. Tapi ada plusnya. Saat Anda menulis aplikasi yang besar dan kompleks, Anda memerlukan abstraksi. Pembuat kueri dapat memberi Anda abstraksi ini. Kueri ini dapat diuraikan; kita akan melihat bagaimana ini dilakukan nanti. Mereka dapat digunakan kembali, diperpanjang, dibungkus dalam fungsi yang sudah akan disebut nama ramah yang terkait dengan logika bisnis.
Sangat mudah untuk membangun kueri dinamis. Jika Anda perlu mengubah sesuatu, tulis migrasi, analisis statistik kode sudah cukup. Sangat nyaman.
Mengapa SQLAlchemy sih? Mengapa layak untuk mampir?

Ini adalah pertanyaan tidak hanya tentang migrasi, tetapi secara umum. Karena ketika kita memiliki Alembic, masuk akal untuk menggunakan seluruh tumpukan sekaligus, karena SQLAlchemy tidak hanya bekerja dengan driver sinkron. Artinya, Django adalah alat yang sangat keren, tetapi Alkimia dapat digunakan, misalnya, dengan asyncpg dan aiopg . Asyncpg memungkinkan Anda membaca, seperti yang dikatakan Selivanov, satu juta baris per detik - baca dari database dan transfer ke Python. Tentu saja, dengan SQLAlchemy akan ada sedikit biaya, akan ada beberapa overhead. Tapi bagaimanapun juga.
SQLAlchemy memiliki banyak sekali driver yang tahu cara bekerja dengannya. Ada Oracle dan PostgreSQL, dan semuanya untuk setiap selera dan warna. Selain itu, mereka sudah di luar kotak, dan jika Anda memerlukan sesuatu yang terpisah, maka di sana, saya baru-baru ini melihat, bahkan ada Elasticsearch. Benar, hanya untuk membaca, tetapi - apakah Anda mengerti? - Elasticsearch di SQLAlchemy.
Ada dokumentasi yang sangat bagus, komunitas yang besar. Ada banyak sekali perpustakaan. Dan yang terpenting, itu tidak menentukan kerangka kerja dan pustaka untuk Anda. Saat Anda melakukan tugas sempit yang perlu dilakukan dengan baik, ini bisa menjadi alat.
Jadi terdiri dari apa?
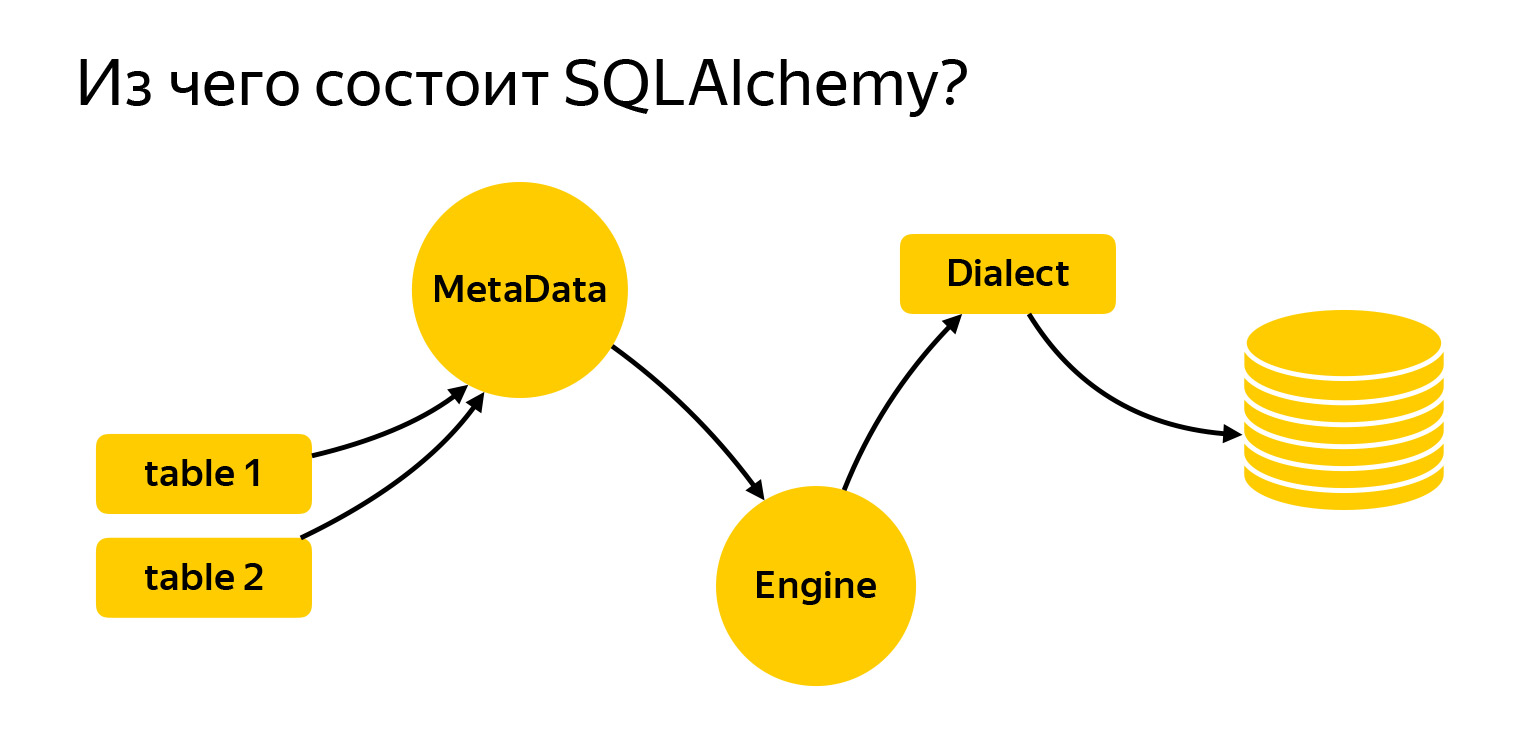
Saya membawa ke sini entitas utama yang akan kita kerjakan hari ini. Ini adalah tabel. Untuk menulis permintaan, Alchemy perlu diberi tahu apa itu dan apa yang sedang kami kerjakan. Selanjutnya adalah registri MetaData. Engine adalah sesuatu yang terhubung ke database dan berkomunikasi dengannya melalui Dialect.
Mari kita lihat lebih dekat apa itu.

MetaData adalah sejenis objek, wadah, di mana Anda akan menambahkan tabel, indeks, dan, secara umum, semua entitas yang Anda miliki. Ini adalah objek yang mencerminkan, di satu sisi, bagaimana Anda ingin melihat database, berdasarkan kode tertulis Anda. Di sisi lain, MetaData bisa pergi ke database, mendapatkan snapshot dari apa yang sebenarnya ada, dan membangun model objek ini sendiri.
Selain itu, objek MetaData memiliki satu fitur yang sangat menarik. Ini memungkinkan Anda untuk menentukan template penamaan default untuk indeks dan batasan. Ini sangat penting saat Anda menulis migrasi, karena setiap database - baik itu PostgreSQL, MySQL, MariaDB - memiliki visinya sendiri tentang bagaimana indeks harus dipanggil.
Beberapa developer juga punya visi sendiri. Dan SQLAlchemy memungkinkan Anda untuk menetapkan standar sekali dan untuk semua cara kerjanya. Saya harus mengembangkan proyek yang perlu bekerja dengan SQLite dan PostgreSQL. Itu sangat nyaman.

Ini terlihat seperti ini: Anda mengimpor objek MetaData dari SQLAlchemy dan ketika Anda membuatnya, Anda menentukan templat menggunakan parameter naming_convention, kunci yang menunjukkan jenis indeks dan batasan: ix adalah indeks biasa, uq adalah indeks unik, fk adalah kunci asing, pk adalah kunci utama.
Dalam nilai parameter naming_convention, Anda dapat menentukan templat yang terdiri dari tipe indeks / batasan (ix / uq / fk, dll.) Dan nama tabel, dipisahkan dengan garis bawah. Di beberapa templat, Anda juga dapat mencantumkan semua kolom. Misalnya, tidak perlu melakukan ini untuk kunci utama, Anda cukup menentukan nama tabel.
Saat Anda mulai membuat proyek baru, Anda menambahkan template penamaan sekali dan lupa. Sejak itu, semua migrasi telah dibuat dengan indeks dan nama batasan yang sama.
Ini penting untuk alasan lain: ketika Anda memutuskan bahwa indeks ini tidak lagi diperlukan dalam model objek Anda dan Anda menghapusnya, Alembic akan tahu apa namanya dan akan menghasilkan migrasi dengan benar. Ini sudah menjadi jaminan keandalan tertentu, bahwa semuanya akan berfungsi sebagaimana mestinya.
Entitas lain yang sangat penting yang pasti akan Anda temukan adalah tabel, objek yang menjelaskan isi tabel.

Tabel memiliki nama, kolom dengan tipe data, dan itu selalu mengacu pada registri MetaData, karena MetaData adalah registri dari semua yang Anda gambarkan. Dan ada kolom dengan tipe data.
Berkat apa yang telah kami jelaskan, SQLAlchemy sekarang bisa dan tahu banyak. Jika kami menentukan kunci asing di sini, dia masih akan tahu bagaimana tabel kami terhubung satu sama lain. Dan dia akan tahu urutan di mana sesuatu perlu dilakukan.

SQLAlchemy juga memiliki Engine. Penting: apa yang kami katakan tentang permintaan dapat digunakan secara terpisah, dan Engine dapat digunakan secara terpisah. Dan Anda dapat menggunakan semuanya bersama-sama, tidak ada yang melarang. Artinya, Mesin mengetahui cara menghubungkan langsung ke server, dan memberi Anda antarmuka yang persis sama. Tidak, tentu saja, driver yang berbeda mencoba untuk mematuhi DBAPI, ada PEP dengan Python yang memberikan rekomendasi. Tetapi Engine memberi Anda antarmuka yang persis sama untuk semua database, dan ini sangat nyaman.

Tonggak utama terakhir adalah Dialek. Ini adalah cara Engine berkomunikasi dengan database yang berbeda. Ada bahasa berbeda, orang berbeda, dan Dialek berbeda di sini.
Mari kita lihat untuk apa semua ini.

Seperti inilah tampilan Sisipan normal. Jika kita ingin menambahkan baris baru, tabel yang telah kita jelaskan sebelumnya, yang didalamnya terdapat field ID dan email, disini kita tentukan emailnya, lakukan Insert, dan segera dapatkan kembali semua yang telah kita sisipkan.
Bagaimana jika kita ingin menambahkan banyak baris? Tidak masalah.

Anda cukup mentransfer daftar dikte di sini. Sepertinya kode yang sempurna untuk pena super sederhana. Data masuk, melewati semacam validasi, beberapa skema JSON, dan hanya itu, masuk ke database. Sangat mudah.
Beberapa pertanyaan cukup rumit. Terkadang permintaan bahkan dapat dilihat dengan cetakan, terkadang Anda harus mengkompilasinya. Ini tidak sulit. Alkimia memungkinkan Anda melakukan semua ini. Dalam kasus ini, kami telah menyusun permintaan tersebut, dan Anda dapat melihat apa yang sebenarnya akan terbang ke database.

Permintaan data terlihat cukup sederhana. Secara harfiah dua baris, Anda bahkan bisa menulis dalam satu.

Mari kembali ke pertanyaan kita tentang bagaimana, misalnya, menulis permintaan PATCH untuk 15 bidang. Di sini Anda harus menulis hanya nama bidang, kunci dan nilainya. Ini semua yang dibutuhkan. Tidak ada file, tidak ada bangunan string, tidak ada sama sekali. Kedengarannya nyaman.
Mungkin fitur Alkimia terpenting yang saya gunakan setiap hari dalam pekerjaan saya adalah dekomposisi kueri dan perluasan.

Misalkan Anda menulis antarmuka di PostgreSQL, aplikasi Anda entah bagaimana harus memberi otorisasi kepada seseorang dan memungkinkannya untuk melakukan CRUD. Oke, tidak banyak yang bisa diurai.
Saat Anda menulis aplikasi yang sangat kompleks yang menggunakan versi data, sekumpulan abstraksi yang berbeda, kueri yang akan Anda hasilkan dapat terdiri dari sejumlah besar subkueri. Subkueri digabungkan dengan subkueri. Ada tugas yang berbeda. Dan terkadang dekomposisi kueri sangat membantu, ini memungkinkan pemisahan logika dan desain kode yang hebat.
Mengapa cara kerjanya seperti ini? Ketika Anda memanggil metode users_table.select (), misalnya, ia mengembalikan sebuah objek. Saat Anda memanggil metode lain pada objek yang dihasilkan, seperti where (), metode tersebut mengembalikan objek yang benar-benar baru. Semua objek kueri tidak dapat diubah. Oleh karena itu, Anda dapat membangun di atas apa pun yang Anda suka.
Migrasi dari alembic
Jadi, kami telah berurusan dengan SQLAlchemy dan sekarang kami akhirnya dapat menulis migrasi Alembic.

Memulai menggunakan Alembic sama sekali tidak sulit, terutama jika Anda telah mendeskripsikan tabel Anda, seperti yang kami katakan sebelumnya, dan menentukan objek MetaData. Anda cukup memasang pip alembic, panggil alembic init alembic. alembic - nama modul, ini adalah baris perintah, Anda akan memilikinya. init adalah sebuah perintah. Argumen terakhir adalah folder untuk meletakkannya.
Saat Anda memanggil perintah ini, Anda akan memiliki beberapa file, yang akan kita lihat lebih dekat sekarang.

Akan ada konfigurasi umum di alembic.ini. script_location tepat di tempat yang Anda inginkan. Selanjutnya, akan ada template untuk nama-nama migrasi yang akan Anda buat, dan informasi untuk menghubungkan ke database.

Ada juga template untuk migrasi baru. Anda berkata, "Saya ingin migrasi baru," dan Alembic akan membuatnya sesuai dengan template tertentu. Anda dapat menyesuaikan semua ini, ini sangat sederhana. Anda masuk ke file ini dan mengedit apa pun yang Anda butuhkan. Semua variabel yang dapat ditentukan di sini ada di dokumentasi. Ini bagian pertama. Ada semacam komentar di bagian atas sehingga lebih mudah untuk melihat apa yang terjadi di sana. Lalu ada satu set variabel yang harus ada di setiap migrasi - revisi, down_revision. Kami akan bekerja dengan mereka hari ini. Lebih lanjut - informasi meta tambahan.

Metode yang paling penting adalah meningkatkan dan menurunkan versi. Alembic akan menggantikan di sini apa pun perbedaan yang ditemukan objek MetaData antara deskripsi skema Anda dan apa yang ada di database.

env.py adalah file paling menarik di Alembic. Ini mengontrol kemajuan eksekusi perintah dan memungkinkan Anda untuk menyesuaikannya sendiri. Di file inilah Anda menghubungkan objek MetaData Anda. Seperti yang saya katakan sebelumnya, objek MetaData adalah registri untuk semua entitas di database Anda.
Anda menghubungkan objek MetaData ini di sini. Dan sejak saat itu, Alembic memahami bahwa ini dia, model saya, ini dia, piring saya. Dia mengerti apa yang dia kerjakan. Selanjutnya, Alembic memiliki kode yang memanggil Alembic baik offline maupun online. Kami sekarang juga akan mempertimbangkan semua ini.
Ini persis garis di mana Anda perlu menghubungkan MetaData di proyek Anda. Jangan khawatir jika ada sesuatu yang tidak terlalu jelas, saya memasukkan semuanya ke dalam proyek dan mempostingnya di GitHub . Anda dapat mengkloningnya dan melihat, merasakan semuanya.

Apa itu mode online? Dalam mode online, Alembic menghubungkan ke database yang ditentukan dalam parameter sqlalchemy.url di file alembic.ini dan mulai menjalankan migrasi.
Mengapa kita melihat potongan kode ini? Alembic dapat disesuaikan dengan sangat fleksibel.
Bayangkan Anda memiliki aplikasi yang perlu hidup dalam skema database yang berbeda. Misalnya, Anda ingin menjalankan banyak instance aplikasi sekaligus, dan masing-masing berada dalam skema sendiri-sendiri. Ini bisa nyaman dan perlu.
Anda tidak dikenakan biaya apa pun. Setelah memanggil metode context.begin_transaction (), Anda dapat menulis perintah "SET search_path = SCHEMA", yang akan memberi tahu PostgreSQL untuk menggunakan skema default yang berbeda. Dan itu saja. Mulai sekarang, aplikasi Anda berada dalam skema yang sama sekali berbeda, migrasi bergulir ke skema yang berbeda. Ini adalah pertanyaan satu baris.

Ada juga mode offline. Perhatikan bahwa Alembic tidak menggunakan Engine di sini. Anda cukup memberikan tautan ke dia di sini. Anda dapat, tentu saja, mentransfer Mesin juga, tetapi tidak terhubung ke mana pun. Itu hanya menghasilkan kueri mentah yang kemudian dapat Anda jalankan di suatu tempat.

Jadi, Anda memiliki Alembic dan beberapa MetaData dengan tabel. Dan Anda akhirnya ingin membuat migrasi untuk diri Anda sendiri. Anda menjalankan perintah ini, dan pada dasarnya hanya itu. Alembic akan pergi ke database dan melihat apa yang ada di sana. Apakah ada label khusus "alembic_versions", yang akan memberi tahu Anda bahwa migrasi telah diluncurkan di database ini? Akan melihat tabel apa saja yang ada disana. Akan melihat data apa yang Anda butuhkan dalam database. Ini akan menganalisis semua ini, menghasilkan file baru, hanya berdasarkan template ini, dan Anda akan mengalami migrasi. Tentu saja, Anda harus melihat apa yang dihasilkan dalam migrasi, karena Alembic tidak selalu menghasilkan apa yang Anda inginkan. Tetapi sebagian besar waktu itu berhasil.

Apa yang telah kami hasilkan? Ada tanda pengguna. Saat kami membuat migrasi, saya menunjukkan pesan awal. Migrasi akan dinamai initial.py dengan beberapa template lain yang sebelumnya ditentukan di alembic.ini.
Ada juga informasi tentang ID apa yang dimiliki migrasi ini. down_revision = Tidak ada - ini adalah migrasi pertama.
Slide berikutnya akan menjadi bagian terpenting: upgrade dan downgrade.

Dalam peningkatan kita melihat bahwa kita memiliki pelat yang sedang dibuat. Dalam downgrade, tanda ini dihapus. Alembic, secara default, secara khusus menambahkan komentar tersebut sehingga Anda pergi ke sana, mengeditnya, setidaknya menghapus komentar ini. Dan untuk berjaga-jaga, kami meninjau migrasi, memastikan bahwa semuanya cocok untuk Anda. Ini masalah satu tim. Anda sudah melakukan migrasi.

Setelah itu, Anda kemungkinan besar ingin menerapkan migrasi ini. Tidak bisa lebih mudah. Anda hanya perlu mengatakan: kepala pemutakhiran alembic. Dia akan menerapkan segalanya.
Jika kami mengatakan kepala, itu akan mencoba memperbarui ke migrasi terbaru. Jika kami menamai migrasi tertentu, migrasi akan diperbarui.
Ada juga perintah penurunan versi - jika Anda, misalnya, berubah pikiran. Semua ini dilakukan dalam transaksi dan berfungsi dengan cukup sederhana.

Jadi, Anda memiliki migrasi, Anda tahu cara menjalankannya. Anda memiliki aplikasi, dan Anda bertanya, misalnya, pertanyaan ini: Saya memiliki CI, pengujian sedang berjalan, dan saya bahkan tidak tahu apakah saya ingin, misalnya, menjalankan migrasi secara otomatis? Mungkin lebih baik melakukannya dengan tangan Anda?
Ada sudut pandang berbeda di sini. Mungkin, perlu mengikuti aturan: jika Anda tidak memiliki akses yang mudah, kemampuan untuk mendapatkan mobil dari database, maka lebih baik, tentu saja, melakukannya secara otomatis.
Jika Anda memiliki akses, Anda membuat layanan yang berfungsi di cloud, dan Anda dapat pergi ke sana dari laptop yang selalu Anda miliki, kemudian Anda dapat melakukannya sendiri dan dengan demikian memberi diri Anda lebih banyak kendali.
Secara umum, ada banyak alat untuk melakukan ini secara otomatis. Misalnya, di Kubernetes yang sama. Ada wadah init yang dapat melakukan ini dan di mana Anda dapat menjalankan perintah ini. Anda dapat menambahkan perintah peluncuran langsung ke Docker untuk melakukan ini.
Anda hanya perlu mempertimbangkan: jika Anda menerapkan migrasi secara otomatis, maka Anda perlu memikirkan tentang apa yang terjadi jika, misalnya, Anda ingin melakukan rollback, tetapi Anda tidak bisa. Misalnya, Anda memiliki pelat data 500 gigabyte. Anda berpikir: oke, data ini tidak lagi diperlukan untuk logika bisnis, Anda mungkin bisa menjatuhkannya. Mereka mengambilnya dan menjatuhkannya. Atau mengubah tipe kolom, yang berubah dengan kehilangan data. Misalnya ada antrean panjang, tapi jadi pendek. Atau ada sesuatu yang hilang. Atau Anda telah menghapus kolom. Anda tidak dapat melakukan rollback bahkan jika Anda mau.
Pada suatu waktu saya membuat produk untuk lokal, yang dimasukkan oleh file exe kepada orang-orang langsung di mesin. Setelah Anda mengerti: ya, Anda menulis migrasi, itu masuk ke produksi, orang sudah menginstalnya. Dalam lima tahun ke depan, ini mungkin berhasil untuk mereka sesuai dengan SLA, dan Anda ingin mengubah sesuatu, sesuatu bisa menjadi lebih baik. Pada saat ini, Anda memikirkan tentang cara menangani perubahan yang tidak dapat diubah.

Tidak ada ilmu roket di sini juga. Idenya adalah Anda dapat menghindari penggunaan kolom ini atau menggunakan tabel sebanyak mungkin. Berhenti menghubungi mereka. Anda dapat, misalnya, menandai bidang di ORM dengan dekorator khusus. Dia akan mengatakan di log bahwa Anda sepertinya tidak ingin menyentuh bidang ini, tetapi Anda masih mengacu padanya. Cukup tambahkan tugas ke backlog dan hapus suatu hari nanti.
Anda, jika ada, akan punya waktu untuk memutar kembali. Dan jika semuanya berjalan dengan baik, Anda akan dengan tenang melakukan tugas ini nanti di backlog. Lakukan migrasi lain yang benar-benar akan menghapus semuanya.
Sekarang untuk pertanyaan paling penting: mengapa dan bagaimana menguji migrasi?

Beberapa orang yang saya minta melakukan ini. Tapi lebih baik melakukannya. Ini adalah aturan yang ditulis dengan rasa sakit, darah dan keringat. Menggunakan migrasi dalam produksi selalu berisiko. Anda tidak pernah tahu bagaimana itu akan berakhir. Bahkan migrasi yang sangat baik pada produksi kerja yang normal, ketika Anda memiliki CI dikonfigurasi, dapat menyentak.
Intinya adalah ketika Anda menguji migrasi, Anda bahkan dapat mengunduh, misalnya, tahap atau sebagian produksi. Produksinya bisa besar, Anda tidak dapat mendownloadnya sepenuhnya untuk pengujian atau tugas lain. Basis pengembangan, pada umumnya, bukanlah basis produksi yang sesungguhnya. Mereka tidak memiliki banyak dari apa yang bisa terkumpul selama bertahun-tahun.

Ini bisa menjadi data yang rusak saat kami memigrasi sesuatu, atau perangkat lunak lama yang membuat data tidak konsisten. Ini juga dapat menjadi ketergantungan tersirat - jika seseorang lupa menambahkan kunci asing. Dia pikir itu terhubung, tetapi rekan-rekannya, misalnya, tidak mengetahuinya. Bidang-bidang ini juga disebut secara tidak sengaja, sama sekali tidak jelas apakah mereka terhubung.
Kemudian seseorang memutuskan untuk masuk dan menambahkan beberapa indeks langsung ke produksi, karena "sekarang melambat, tetapi bagaimana jika mulai bekerja lebih cepat?" Mungkin saya melebih-lebihkan, tetapi terkadang orang benar-benar mengubah sesuatu yang benar di database.
Ada, tentu saja, kesalahan dalam alat, dalam migrasi skema. Sejujurnya, saya belum pernah menemukan ini. Biasanya ada tiga masalah pertama. Dan mungkin lebih banyak kesalahan dalam asumsi tentang bagaimana data harus ditransfer.
Jika Anda memiliki model objek yang sangat besar, mungkin sulit untuk mengingat semuanya. Sulit untuk selalu menulis dokumentasi terkini. Dokumentasi paling baru adalah kode Anda, dan tidak selalu memiliki logika bisnis yang sepenuhnya tertulis: apa dan bagaimana seharusnya bekerja, siapa yang memikirkan apa.

Apa yang bisa kami periksa? Setidaknya fakta bahwa migrasi dimulai. Ini sudah bagus. Dan tidak ada kesalahan ketik yang bodoh dalam kode. Kita bisa memeriksa apakah ada metode downgrade () yang valid, bahwa semua tipe data yang dibuat oleh SQLAlchemy dihapus dalam metode downgrade ().
SQLAlchemy melakukan banyak hal bagus. Misalnya, ketika Anda mendeskripsikan tabel dan menentukan tipe kolom Enum, SQLAlchemy akan secara otomatis membuat tipe data untuk enum tersebut di PostgreSQL. Tetapi kode untuk menghapus tipe data ini dalam metode downgrade () tidak akan dibuat secara otomatis.
Anda perlu mengingat dan memeriksa ini: ketika Anda ingin melakukan rollback dan menerapkan kembali migrasi, upaya untuk membuat tipe data yang sudah ada dalam metode upgrade () akan memunculkan pengecualian. Dan yang paling penting, jika migrasi mengubah data apa pun, Anda perlu memeriksa bahwa data berubah dengan benar dalam peningkatan. Dan sangat penting untuk memeriksa bahwa mereka memutar kembali dengan benar di downgrade tanpa efek samping.

Sebelum melanjutkan ke tes itu sendiri, mari kita lihat cara terbaik mempersiapkan diri untuk menulisnya. Saya telah melihat banyak pendekatan untuk ini. Beberapa orang membuat alas, pelat, lalu menulis perlengkapan yang membersihkan semuanya, menggunakan semacam perlengkapan yang diterapkan secara otomatis . Tetapi cara ideal yang akan melindungi Anda 100% dan akan menjalankan pengujian di ruang yang benar-benar terisolasi adalah dengan membuat database terpisah.
Ada modul sqlalchemy_utils mengagumkan yang dapat membuat dan menghapus database. Di PostgreSQL, dia juga memeriksa: jika salah satu klien tertidur dan tidak memutuskan sambungan, dia tidak akan mogok dengan kesalahan bahwa "seseorang menggunakan database, saya tidak dapat melakukan apa pun dengannya, saya tidak dapat menghapusnya". Sebaliknya, dia dengan tenang akan melihat siapa yang telah terhubung dengan mereka, memutuskan klien ini dan dengan tenang menghapus basisnya.
Membangun database dan menerapkan migrasi ke setiap pengujian tidak selalu merupakan proses yang cepat. Ini dapat diselesaikan sebagai berikut: PostgreSQL mendukung pembuatan database baru dari template, sehingga Anda dapat membagi persiapan database menjadi dua perlengkapan.
Perlengkapan pertama berjalan sekali untuk menjalankan semua tes (scope = sesi), membuat database dan menerapkan migrasi padanya. Perlengkapan kedua (scope = fungsi) membuat basis secara langsung untuk setiap tes berdasarkan basis dari perlengkapan pertama.
Membuat database dari template sangat cepat dan menghemat waktu penerapan migrasi untuk setiap pengujian.

Jika kita hanya berbicara tentang bagaimana kita dapat membuat database sementara, maka kita dapat menulis perlengkapan seperti itu. Apa yang terjadi di sini? Kami akan menghasilkan nama acak. Kami menambahkan, untuk berjaga-jaga, di akhir pytest, sehingga ketika kami pergi ke localhost untuk diri kami sendiri melalui beberapa Postico, kami dapat memahami apa yang dibuat oleh tes dan apa yang tidak.
Kemudian kami menghasilkan dari tautan dengan informasi tentang menghubungkan ke database, yang ditunjukkan orang itu, yang baru, sudah dengan database baru. Kami membuatnya dan mengirimkannya ke pengujian. Setelah seseorang bekerja dengan database ini, kami menghapusnya.

Kami juga dapat menyiapkan Engine untuk terhubung ke database ini. Artinya, di fixture ini kami merujuk ke fixture sebelumnya yang digunakan sebagai dependensi. Kami membuat Mesin dan mengirimkannya ke pengujian.

Jadi tes apa yang bisa kita tulis? Tes pertama hanyalah penemuan brilian dari kolega saya. Sejak muncul, saya rasa saya sudah lupa tentang masalah migrasi.
Ini adalah tes yang sangat sederhana. Anda menambahkannya ke proyek Anda sekali. Itu ada dalam proyek di GitHub... Anda bisa menyeretnya ke Anda, menambah dan melupakan, mungkin, sekitar 80 persen masalah.
Ini melakukan hal yang sangat sederhana: ia mendapat daftar semua migrasi dan mulai mengulanginya. Panggilan upgrade, downgrade, upgrade.

Misalnya, kami memiliki lima migrasi. Mari kita lihat bagaimana ini akan berhasil. Ini migrasi pertama. Kami telah memenuhinya. Rollback migrasi pertama, jalankan lagi. Apa yang terjadi disini? Faktanya, kita melihat di sini bahwa orang tersebut menerapkan metode downgrade () dengan benar, karena dua kali, misalnya, tidak mungkin membuat tabel.
Kami melihat bahwa jika seseorang membuat beberapa tipe data, dia juga menghapusnya, karena tidak ada kesalahan ketik dan secara umum setidaknya entah bagaimana berfungsi.
Kemudian tes berlanjut. Dia melakukan migrasi kedua, segera berlari ke sana, mundur satu langkah, berlari ke depan lagi. Dan ini terjadi berkali-kali selama Anda bermigrasi.
Tujuan dari pengujian ini adalah untuk menemukan kesalahan-kesalahan dasar, masalah-masalah pada saat merubah struktur data.
Tangga dimulai di dasar yang kosong dan biasanya sangat cepat. Artinya, pengujian ini lebih banyak tentang struktur data. Ini bukan tentang mengubah data dalam migrasi. Tapi secara keseluruhan, itu bisa menyelamatkan hidup Anda dengan sangat baik.
Jika Anda ingin perbaikan cepat, ini dia. Aturan ini adalah. Sebagai aturan praktis: masukkan ke dalam proyek Anda, dan itu menjadi lebih mudah bagi Anda.

Tes ini terlihat seperti ini. Kami mendapatkan semua revisi, menghasilkan konfigurasi Alembic. Inilah yang kita lihat sebelumnya, file alembic.ini, di sini adalah fungsi get_alembic_config, ia membaca file ini, menambahkan basis sementara kita ke sana, karena di sana kita menentukan jalur ke basis. Dan setelah itu kita bisa menggunakan perintah Alembic.
Perintah yang dijalankan sebelumnya - alembic upgrade head - juga dapat diimpor dengan aman. Sayangnya, slide ini tidak sesuai dengan semua impor, tetapi percayai kata-kata saya. Ini hanya dari upgrade impor alembic.com. Anda menerjemahkan konfigurasi di sana, katakan ke mana harus melalui peningkatan. Kemudian ucapkan: downgrade.
Dengan downgrade, migrasi digulung kembali ke down_revision, yaitu ke revisi sebelumnya, atau ke "-1".
"-1" adalah cara alternatif untuk memberi tahu Alembic untuk mengembalikan migrasi saat ini. Ini sangat relevan saat migrasi pertama dimulai, down_revision-nya adalah None, sedangkan Alembic API tidak mengizinkan penerusan None ke perintah downgrade.
Kemudian perintah upgrade dijalankan kembali.
Sekarang mari kita bicara tentang cara menguji migrasi dengan data.

Migrasi data adalah jenis hal yang biasanya terlihat sangat sederhana, tetapi paling menyakitkan. Tampaknya Anda dapat menulis pilihan, menyisipkan, mengambil data dari satu tabel, mentransfernya ke tabel lain dalam format yang sedikit berbeda - apa yang lebih sederhana?
Masih harus dikatakan tentang tes ini yang, tidak seperti yang sebelumnya, sangat mahal untuk dikembangkan. Ketika saya melakukan migrasi besar, terkadang saya butuh waktu enam jam untuk melihat semua invarian, tidak apa-apa untuk mendeskripsikan semuanya. Tapi saat saya sudah menggulirkan migrasi ini, saya tenang.

Bagaimana cara kerja tes ini? Idenya adalah kita menerapkan semua migrasi hingga yang sekarang ingin kita uji. Kami memasukkan ke dalam database satu set data yang akan berubah. Kita bisa memikirkan tentang memasukkan data tambahan yang bisa berubah secara implisit. Kemudian kami meningkatkan. Kami memeriksa bahwa data diubah dengan benar, melakukan downgrade, dan memeriksa bahwa data diubah dengan benar.

Kode tersebut terlihat seperti ini. Artinya, ada juga parameterisasi dengan revisi, ada seperangkat parameter. Kami menerima Mesin kami di sini, menerima migrasi yang ingin kami gunakan untuk memulai pengujian.
Kemudian rev_head, yang ingin kami uji. Dan kemudian tiga panggilan balik. Ini adalah callback yang kita definisikan di suatu tempat, dan akan dipanggil setelah sesuatu selesai. Kami dapat memeriksa apa yang terjadi di sana.
Di mana saya bisa melihat contohnya?
Saya mengemas semuanya menjadi contoh di GitHub . Sebenarnya tidak banyak kode di sana, tetapi cukup sulit untuk menambahkannya ke slide. Saya mencoba bertahan yang paling dasar. Anda dapat pergi ke GitHub dan melihat cara kerjanya di proyek itu sendiri, ini akan menjadi cara termudah.
Apa lagi yang perlu diperhatikan? Selama startup, Alembic mencari file konfigurasi alembic.ini di folder tempat peluncurannya. Tentu saja, Anda dapat menentukan jalur menggunakan variabel lingkungan ALEMBIC_CONFIG, tetapi ini tidak selalu nyaman dan jelas.
Masalah lain: informasi untuk menghubungkan ke database ditentukan di alembic.ini, tetapi seringkali Anda harus dapat bekerja dengan beberapa database secara bergantian. Misalnya, jalankan migrasi ke stage dan kemudian ke prod. Secara umum, Anda dapat menentukan informasi koneksi dalam variabel lingkungan SQLALCHEMY_URL, tetapi ini tidak terlalu jelas bagi pengguna akhir perangkat lunak Anda.
Ini juga jauh lebih intuitif bagi pengguna akhir untuk menggunakan utilitas "$ project $ -db" daripada "alembic".
Saat Anda melihat contoh dalam proyek, lihat utilitas staff-db. Ini adalah pembungkus tipis di sekitar Alembic dan cara lain untuk menyesuaikan Alembic untuk Anda. Secara default, ini mencari file alembic.ini dalam proyek relatif terhadap lokasinya. Dari folder mana pun pengguna memanggilnya, dia sendiri yang akan menemukan file konfigurasinya. Selain itu, staff-db menambahkan argumen --db-url, yang dengannya Anda dapat menentukan informasi untuk disambungkan ke database. Dan, yang terpenting, lihatlah dengan melewatkan opsi --help yang diterima secara umum. Bagaimanapun, nama utilitasnya intuitif.
Semua perintah proyek yang dapat dieksekusi dimulai dengan nama modul "staff": staff-api, yang menjalankan REST API, dan staff-db, yang mengelola status dasar. Memahami pola ini, klien akan menulis nama program Anda dan akan dapat melihat semua utilitas yang tersedia dengan menekan tombol TAB, bahkan jika dia lupa nama lengkapnya. Saya memiliki segalanya, terima kasih.