
Di dunia modern Big Data, Apache Spark adalah standar de facto untuk mengembangkan tugas pemrosesan batch. Selain itu juga digunakan untuk membuat aplikasi streaming yang beroperasi dalam konsep micro batch, mengolah dan mengirimkan data dalam porsi kecil (Spark Structured Streaming). Dan ini secara tradisional menjadi bagian dari keseluruhan tumpukan Hadoop, menggunakan YARN (atau, dalam beberapa kasus, Apache Mesos) sebagai pengelola sumber daya. Pada tahun 2020, penggunaan tradisionalnya untuk sebagian besar perusahaan dipertanyakan karena kurangnya distribusi Hadoop yang layak - pengembangan HDP dan CDH telah berhenti, CDH kurang berkembang dan memiliki biaya tinggi, dan penyedia Hadoop lainnya tidak lagi ada atau memiliki masa depan yang tidak jelas.Oleh karena itu, minat yang berkembang di antara komunitas dan perusahaan besar adalah peluncuran Apache Spark menggunakan Kubernetes - yang telah menjadi standar dalam orkestrasi kontainer dan manajemen sumber daya di cloud pribadi dan publik, ini memecahkan masalah penjadwalan sumber daya yang tidak nyaman dari tugas-tugas Spark di YARN dan menyediakan platform yang terus berkembang dengan banyak komersial dan distribusi open source untuk perusahaan dari semua ukuran dan garis. Selain itu, dalam gelombang popularitas, mayoritas telah berhasil memperoleh beberapa instalasi mereka dan meningkatkan keahlian mereka dalam menggunakannya, yang menyederhanakan perpindahan.itu memecahkan penjadwalan sumber daya tugas Spark yang canggung di YARN dan menyediakan platform yang kuat dengan banyak distribusi komersial dan sumber terbuka untuk perusahaan dari semua ukuran dan garis. Selain itu, dalam gelombang popularitas, mayoritas telah berhasil memperoleh beberapa instalasi mereka dan meningkatkan keahlian mereka dalam menggunakannya, yang menyederhanakan perpindahan.itu memecahkan penjadwalan sumber daya tugas Spark yang canggung di YARN dan menyediakan platform yang terus berkembang dengan banyak distribusi komersial dan sumber terbuka untuk perusahaan dari semua ukuran dan garis. Selain itu, dalam gelombang popularitas, mayoritas telah berhasil memperoleh beberapa instalasi mereka dan meningkatkan keahlian mereka dalam menggunakannya, yang menyederhanakan perpindahan.
Dimulai dengan versi 2.3.0, Apache Spark memperoleh dukungan resmi untuk menjalankan tugas di kluster Kubernetes, dan hari ini, kita akan membahas tentang kedewasaan pendekatan ini saat ini, berbagai kasus penggunaan, dan kendala yang akan dihadapi selama implementasi.
Pertama-tama, kami akan mempertimbangkan proses pengembangan tugas dan aplikasi berdasarkan Apache Spark dan menyoroti kasus umum di mana Anda perlu menjalankan tugas pada kluster Kubernetes. Saat menyiapkan posting ini, OpenShift digunakan sebagai kit distribusi dan perintah yang relevan untuk utilitas baris perintah (oc) akan diberikan. Untuk distribusi Kubernetes lain, perintah yang sesuai dari utilitas baris perintah Kubernetes standar (kubectl) atau analognya (misalnya, untuk kebijakan oc adm) dapat digunakan.
Kasus penggunaan pertama adalah spark-submit
Dalam proses pengembangan tugas dan aplikasi, pengembang perlu menjalankan tugas untuk men-debug transformasi data. Secara teoritis, rintisan dapat digunakan untuk tujuan ini, tetapi pengembangan dengan partisipasi contoh nyata (meskipun uji) dari sistem terbatas telah menunjukkan dirinya menjadi lebih cepat dan lebih baik dalam kelas tugas ini. Dalam kasus ketika kami men-debug pada contoh nyata dari sistem akhir, dua skenario mungkin:
- pengembang menjalankan tugas Spark secara lokal dalam mode mandiri;
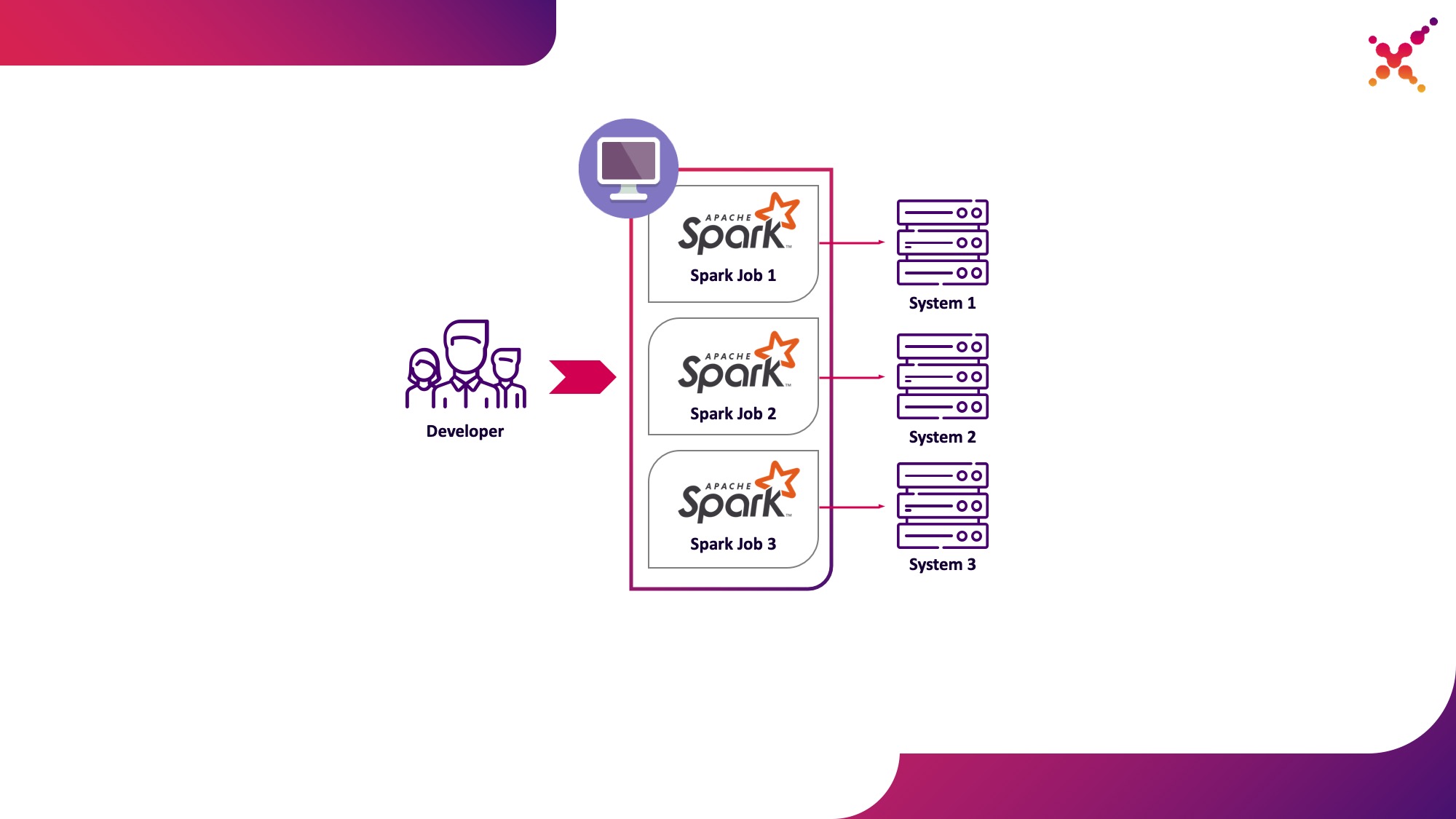
- pengembang menjalankan tugas Spark pada cluster Kubernetes dalam loop pengujian.

Opsi pertama memiliki hak untuk hidup, tetapi memiliki sejumlah kerugian:
- untuk setiap pengembang, diharuskan untuk menyediakan akses dari tempat kerja ke semua salinan sistem akhir yang dia butuhkan;
- mesin yang bekerja membutuhkan sumber daya yang cukup untuk menjalankan tugas yang dikembangkan.
Opsi kedua tanpa kekurangan ini, karena penggunaan cluster Kubernetes memungkinkan Anda mengalokasikan kumpulan sumber daya yang diperlukan untuk menjalankan tugas dan memberinya akses yang diperlukan ke instance sistem akhir, secara fleksibel menyediakan akses ke sana menggunakan model peran Kubernetes untuk semua anggota tim pengembangan. Mari kita soroti sebagai kasus penggunaan pertama - menjalankan tugas Spark dari mesin pengembangan lokal pada cluster Kubernetes dalam loop pengujian.
Mari kita lihat lebih dekat proses konfigurasi Spark agar berjalan secara lokal. Untuk mulai menggunakan Spark, Anda perlu menginstalnya:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Kami mengumpulkan paket yang diperlukan untuk bekerja dengan Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
Build lengkap membutuhkan banyak waktu, dan untuk membuat image Docker serta menjalankannya di cluster Kubernetes, pada kenyataannya, Anda hanya memerlukan file jar dari direktori "assembly /", jadi Anda hanya dapat membuat subproyek ini:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
Untuk menjalankan tugas Spark di Kubernetes, Anda perlu membuat image Docker untuk digunakan sebagai image dasar. 2 pendekatan dimungkinkan di sini:
- Gambar Docker yang dihasilkan menyertakan kode yang dapat dieksekusi untuk tugas Spark;
- Gambar yang dibuat hanya menyertakan Spark dan dependensi yang diperlukan, kode yang dapat dieksekusi dihosting dari jarak jauh (misalnya, dalam HDFS).
Pertama, mari buat image Docker yang berisi contoh uji tugas Spark. Untuk membuat image Docker, Spark memiliki utilitas yang disebut "docker-image-tool". Mari pelajari bantuannya:
./bin/docker-image-tool.sh --help
Ini dapat digunakan untuk membuat image Docker dan mengunggahnya ke register jarak jauh, tetapi secara default memiliki beberapa kelemahan:
- tanpa gagal membuat 3 gambar Docker sekaligus - untuk Spark, PySpark dan R;
- tidak memungkinkan Anda untuk menentukan nama gambar.
Oleh karena itu, kami akan menggunakan versi modifikasi dari utilitas ini, yang ditunjukkan di bawah ini:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
Dengan menggunakannya, kami membuat gambar Spark dasar yang berisi tugas pengujian untuk menghitung nomor Pi menggunakan Spark (di sini {docker-registry-url} adalah URL dari registri gambar Docker Anda, {repo} adalah nama repositori di dalam registri, yang bertepatan dengan proyek di OpenShift , {image-name} adalah nama gambar (jika pemisahan gambar tiga tingkat digunakan, misalnya, seperti di registri gambar terintegrasi Red Hat OpenShift), {tag} adalah tag dari versi gambar ini):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Masuk ke cluster OKD menggunakan utilitas konsol (di sini {OKD-API-URL} adalah URL API cluster OKD):
oc login {OKD-API-URL}
Mari dapatkan token pengguna saat ini untuk otorisasi di Docker Registry:
oc whoami -t
Masuk ke Docker Registry internal cluster OKD (gunakan token yang diperoleh dengan perintah sebelumnya sebagai kata sandi):
docker login {docker-registry-url}
Unggah image Docker bawaan ke Docker Registry OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Mari kita periksa apakah gambar yang dirakit tersedia di OKD. Untuk melakukan ini, buka URL dengan daftar gambar dari proyek yang sesuai di browser (di sini {project} adalah nama proyek di dalam cluster OpenShift, {OKD-WEBUI-URL} adalah URL dari OpenShift Web console) - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / images / {image-name}.
Untuk menjalankan tugas, akun layanan harus dibuat dengan hak istimewa menjalankan pod sebagai root (kita akan membahas poin ini nanti):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Jalankan spark-submit untuk mempublikasikan tugas Spark ke OKD cluster, dengan menentukan akun layanan yang dibuat dan image Docker:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Disini:
--name adalah nama dari tugas yang akan berpartisipasi dalam pembentukan nama pod Kubernetes;
--class - kelas dari file yang dapat dieksekusi yang dipanggil saat tugas dimulai;
--conf - parameter konfigurasi Spark;
spark.executor.instances Jumlah pelaksana Spark yang akan dijalankan.
spark.kubernetes.authenticate.driver.serviceAccountName - Nama akun layanan Kubernetes yang digunakan saat meluncurkan pod (untuk menentukan konteks dan kemampuan keamanan saat berinteraksi dengan Kubernetes API);
spark.kubernetes.namespace - namespace Kubernetes tempat pod driver dan eksekutor akan berjalan;
spark.submit.deployMode - Metode peluncuran Spark ("cluster" digunakan untuk spark-submit standar, "client" untuk Spark Operator dan versi Spark yang lebih baru);
spark.kubernetes.container.image Image Docker yang digunakan untuk menjalankan pod.
spark.master - URL dari Kubernetes API (eksternal ditentukan sehingga panggilan terjadi dari mesin lokal);
local: // adalah jalur ke Spark yang dapat dieksekusi di dalam gambar Docker.
Buka proyek OKD yang sesuai dan pelajari pod yang dibuat - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods.
Untuk menyederhanakan proses pengembangan, opsi lain dapat digunakan, di mana gambar Spark dasar umum dibuat yang digunakan oleh semua tugas untuk dijalankan, dan snapshot dari file yang dapat dieksekusi diterbitkan ke penyimpanan eksternal (misalnya, Hadoop) dan ditentukan saat memanggil spark-submit sebagai link. Dalam kasus ini, Anda dapat menjalankan berbagai versi tugas Spark tanpa membangun kembali gambar Docker, misalnya menggunakan WebHDFS untuk menerbitkan gambar. Kami mengirim permintaan untuk membuat file (di sini {host} adalah host layanan WebHDFS, {port} adalah port dari layanan WebHDFS, {path-to-file-on-hdfs} adalah jalur yang diinginkan ke file di HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
Ini akan menerima tanggapan dalam bentuk (di sini {lokasi} adalah URL yang harus digunakan untuk mengunduh file):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Muat file Spark yang dapat dieksekusi ke dalam HDFS (di sini {path-to-local-file} adalah jalur ke Spark yang dapat dieksekusi pada host saat ini):
curl -i -X PUT -T {path-to-local-file} "{location}"
Setelah itu, kita dapat membuat spark-submit menggunakan file Spark yang diunggah ke HDFS (di sini {class-name} adalah nama kelas yang perlu diluncurkan untuk menyelesaikan tugas):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
Perlu dicatat bahwa untuk mengakses HDFS dan mengaktifkan tugas untuk bekerja, Anda mungkin perlu mengubah skrip Dockerfile dan entrypoint.sh - tambahkan arahan ke Dockerfile untuk menyalin pustaka dependen ke direktori / opt / spark / jars dan menyertakan file konfigurasi HDFS di SPARK_CLASSPATH di entrypoint. SH.
Kasus penggunaan kedua - Apache Livy
Selanjutnya, ketika tugas dikembangkan dan diperlukan untuk menguji hasil yang diperoleh, pertanyaan yang muncul adalah meluncurkannya dalam proses CI / CD dan melacak status pelaksanaannya. Tentu saja, Anda dapat menjalankannya menggunakan panggilan spark-submit lokal, tetapi ini mempersulit infrastruktur CI / CD karena memerlukan penginstalan dan konfigurasi Spark pada agen / runner server CI dan menyiapkan akses ke Kubernetes API. Untuk kasus ini, implementasi target telah memilih untuk menggunakan Apache Livy sebagai REST API untuk menjalankan tugas Spark yang dihosting di dalam cluster Kubernetes. Ini dapat digunakan untuk meluncurkan tugas Spark pada cluster Kubernetes menggunakan permintaan cURL biasa, yang dengan mudah diimplementasikan berdasarkan solusi CI apa pun, dan penempatannya di dalam cluster Kubernetes memecahkan masalah otentikasi saat berinteraksi dengan Kubernetes API.
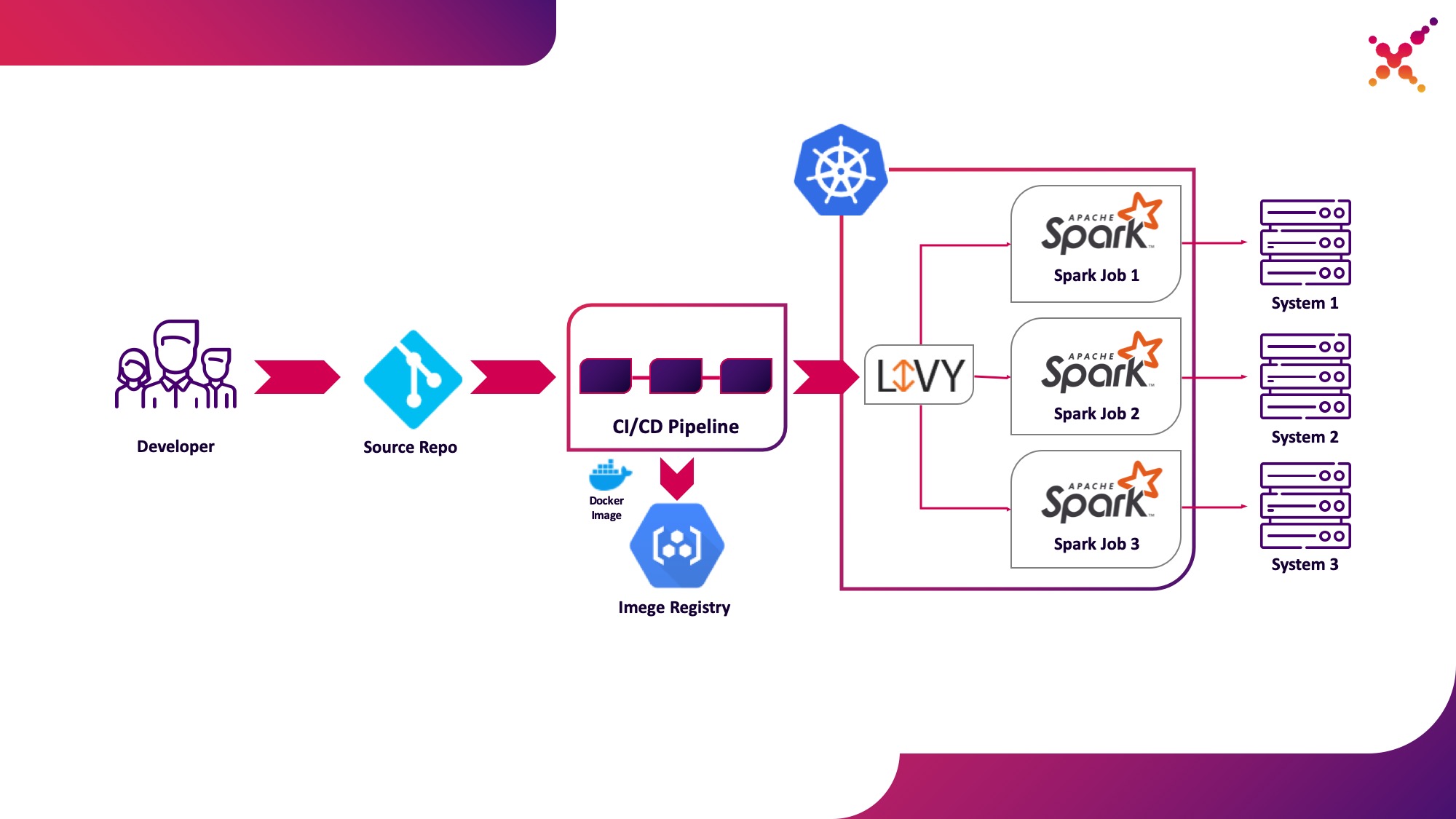
Mari kita soroti sebagai kasus penggunaan kedua - menjalankan tugas Spark sebagai bagian dari proses CI / CD pada cluster Kubernetes dalam loop pengujian.
Sedikit tentang Apache Livy - ini berfungsi sebagai server HTTP yang menyediakan antarmuka Web dan RESTful API yang memungkinkan Anda meluncurkan spark-submit dari jarak jauh dengan meneruskan parameter yang diperlukan. Secara tradisional, ini dikirimkan sebagai bagian dari distribusi HDP, tetapi juga dapat diterapkan ke OKD atau instalasi Kubernetes lainnya menggunakan manifes yang sesuai dan sekumpulan gambar Docker, seperti ini - github.com/ttauveron/k8s-big-data-experiments/tree/master /livy-spark-2.3 . Untuk kasus kami, image Docker serupa telah dibuat, termasuk Spark versi 2.4.5 dari Dockerfile berikut:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
Gambar yang dihasilkan dapat dibuat dan diunggah ke repositori Docker Anda yang sudah ada, misalnya repositori OKD internal. Untuk menerapkannya, manifes berikut digunakan ({registry-url} adalah URL dari registry image Docker, {image-name} adalah nama image Docker, {tag} adalah tag image Docker, {livy-url} adalah URL yang diinginkan di mana server akan tersedia Livy; manifes "Route" digunakan jika Red Hat OpenShift digunakan sebagai distribusi Kubernetes, jika tidak, Ingress atau manifes Layanan jenis NodePort yang sesuai akan digunakan):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
Setelah aplikasi dan peluncuran pod berhasil, antarmuka grafis Livy tersedia di link: http: // {livy-url} / ui. Dengan Livy, kami dapat mempublikasikan tugas Spark kami menggunakan permintaan REST, misalnya dari Postman. Contoh kumpulan dengan permintaan disajikan di bawah ini (dalam larik "args", argumen konfigurasi dapat diteruskan dengan variabel yang diperlukan untuk tugas yang diluncurkan):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Mari jalankan permintaan pertama dari koleksi, buka antarmuka OKD dan periksa apakah tugas telah berhasil diluncurkan - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods. Dalam kasus ini, sebuah sesi akan muncul di antarmuka Livy (http: // {livy-url} / ui), di dalamnya, menggunakan API Livy atau antarmuka grafis, Anda dapat melacak kemajuan tugas dan mempelajari log sesi.
Sekarang mari kita tunjukkan cara kerja Livy. Untuk melakukannya, mari periksa log container Livy di dalam pod dengan server Livy - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods / {livy-pod-name}? Tab = logs. Dari mereka, Anda dapat melihat bahwa saat Anda memanggil Livy REST API dalam container bernama "livy", spark-submit dijalankan, mirip dengan yang kami gunakan di atas (di sini {livy-pod-name} adalah nama pod yang dibuat dengan server Livy). Koleksi ini juga menyediakan permintaan kedua yang memungkinkan Anda menjalankan tugas dengan hosting jarak jauh Spark yang dapat dieksekusi menggunakan server Livy.
Kasus penggunaan ketiga - Operator Spark
Sekarang tugas tersebut telah diuji, muncul pertanyaan untuk menjalankannya secara teratur. Cara asli untuk menjalankan tugas secara teratur di cluster Kubernetes adalah entitas CronJob dan Anda dapat menggunakannya, tetapi saat ini, penggunaan operator untuk mengontrol aplikasi di Kubernetes sangat populer, dan untuk Spark ada operator yang cukup matang, yang, antara lain, digunakan dalam solusi tingkat perusahaan (misalnya, Platform FastData Lightbend). Kami merekomendasikan untuk menggunakannya - versi stabil Spark saat ini (2.4.5) memiliki opsi yang cukup terbatas untuk mengonfigurasi peluncuran tugas Spark di Kubernetes, sedangkan di versi utama berikutnya (3.0.0) dukungan penuh untuk Kubernetes diumumkan, tetapi tanggal rilisnya tetap tidak diketahui. Operator Spark mengkompensasi kekurangan ini dengan menambahkan parameter konfigurasi penting (misalnya,memasang ConfigMap dengan konfigurasi akses ke Hadoop di pod Spark) dan kemampuan untuk menjalankan tugas secara teratur sesuai jadwal.
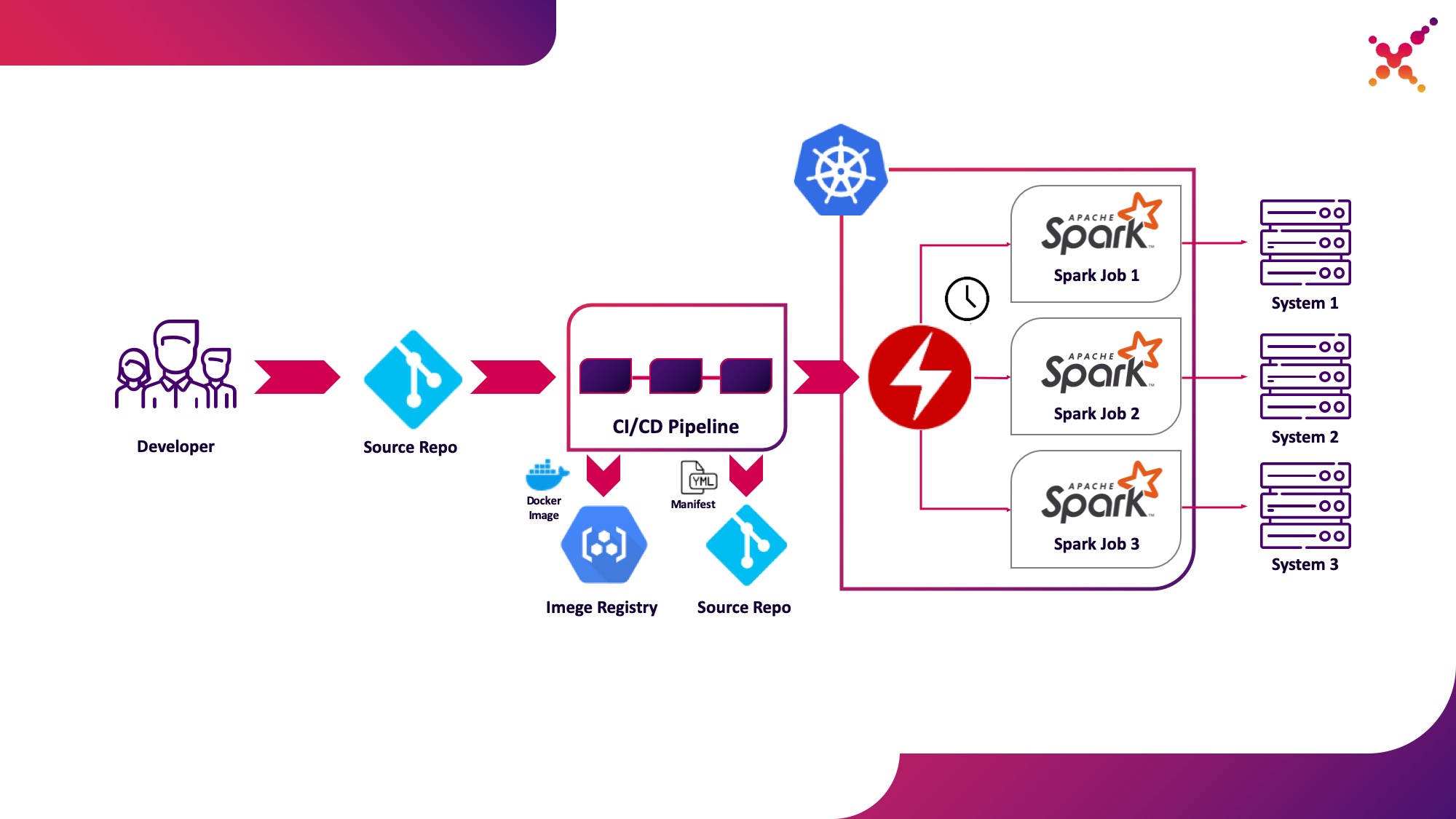
Mari kita soroti sebagai kasus penggunaan ketiga - menjalankan tugas Spark secara teratur pada cluster Kubernetes dalam loop produksi.
Spark Operator adalah open source dan dikembangkan sebagai bagian dari Google Cloud Platform - github.com/GoogleCloudPlatform/spark-on-k8s-operator . Pemasangannya dapat dilakukan dengan 3 cara:
- Sebagai bagian dari instalasi Lightbend FastData Platform / Cloudflow;
- Dengan Helm:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
Jika operator disetel dengan benar, maka pod aktif dengan operator Spark (misalnya, cloudflow-fdp-sparkoperator di ruang Cloudflow untuk menginstal Cloudflow) akan muncul di project yang sesuai dan jenis resource Kubernetes terkait bernama "sparkapplications" akan muncul. Anda dapat memeriksa aplikasi Spark yang tersedia dengan perintah berikut:
oc get sparkapplications -n {project}
Untuk menjalankan tugas dengan Spark Operator, Anda perlu melakukan 3 hal:
- membuat image Docker yang mencakup semua pustaka yang diperlukan, serta konfigurasi dan file yang dapat dieksekusi. Dalam gambar target, ini adalah gambar yang dibuat pada tahap CI / CD dan diuji pada cluster uji;
- mempublikasikan image Docker ke registry yang dapat diakses dari cluster Kubernetes;
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- kamus "spec.sparkVersion" harus menunjukkan versi Spark yang digunakan;
- dalam kamus "spec.driver.serviceAccount" harus ada akun layanan dalam namespace Kubernetes yang sesuai yang akan digunakan untuk meluncurkan aplikasi;
- kamus "spec.executor" harus menunjukkan jumlah sumber daya yang dialokasikan untuk aplikasi;
- kamus "spec.volumeMounts" harus menentukan direktori lokal tempat file tugas Spark lokal akan dibuat.
Contoh pembuatan manifes (di sini {spark-service-account} adalah akun layanan di dalam cluster Kubernetes untuk menjalankan tugas Spark):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Manifes ini menentukan akun layanan yang, sebelum memublikasikan manifes, Anda perlu membuat binding peran yang diperlukan yang memberikan hak akses yang diperlukan untuk aplikasi Spark untuk berinteraksi dengan Kubernetes API (jika diperlukan). Dalam kasus kami, aplikasi membutuhkan hak untuk membuat Pod. Mari buat pengikatan peran yang diperlukan:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
Perlu diperhatikan juga bahwa spesifikasi manifes ini dapat menentukan parameter hadoopConfigMap, yang memungkinkan Anda menentukan ConfigMap dengan konfigurasi Hadoop tanpa harus menempatkan file yang sesuai terlebih dahulu di image Docker. Ini juga cocok untuk meluncurkan tugas secara rutin - dengan menggunakan parameter "jadwal", Anda dapat menentukan jadwal peluncuran untuk tugas ini.
Setelah itu, kami menyimpan manifes kami ke file spark-pi.yaml dan menerapkannya ke cluster Kubernetes kami:
oc apply -f spark-pi.yaml
Ini akan membuat sebuah objek berjenis "sparkapplications":
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
Ini akan membuat sebuah pod dengan sebuah aplikasi, yang statusnya akan ditampilkan di "sparkapplications" yang dibuat. Itu dapat dilihat dengan perintah berikut:
oc get sparkapplications spark-pi -o yaml -n {project}
Setelah menyelesaikan tugas, POD akan beralih ke status "Selesai", yang juga diperbarui menjadi "aplikasi percikan". Log aplikasi dapat dilihat di browser atau menggunakan perintah berikut (di sini {sparkapplications-pod-name} adalah nama pod dari tugas yang sedang berjalan):
oc logs {sparkapplications-pod-name} -n {project}
Tugas percikan juga dapat dikelola menggunakan utilitas sparkctl khusus. Untuk menginstalnya, kami mengkloning repositori dengan kode sumbernya, menginstal Go dan membangun utilitas ini:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Mari kita periksa daftar menjalankan tugas Spark:
sparkctl list -n {project}
Mari buat deskripsi untuk tugas Spark:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Mari kita mulai tugas yang dijelaskan menggunakan sparkctl:
sparkctl create spark-app.yaml -n {project}
Mari kita periksa daftar menjalankan tugas Spark:
sparkctl list -n {project}
Mari kita periksa daftar event dari tugas Spark yang dimulai:
sparkctl event spark-pi -n {project} -f
Mari kita periksa status tugas Spark yang sedang berjalan:
sparkctl status spark-pi -n {project}
Sebagai kesimpulan, saya ingin mempertimbangkan kerugian yang ditemukan dari pengoperasian versi stabil Spark (2.4.5) saat ini di Kubernetes:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- Menjalankan tugas Spark dengan Kubernetes secara resmi masih dalam mode eksperimental, dan mungkin ada perubahan signifikan pada artefak yang digunakan (file konfigurasi, gambar dasar Docker, dan skrip startup) di masa mendatang. Memang, ketika menyiapkan materi, versi 2.3.0 dan 2.4.5 diuji, perilakunya berbeda secara signifikan.
Kami akan menunggu pembaruan - versi baru dari Spark (3.0.0) baru-baru ini telah dirilis, yang membawa perubahan nyata pada pekerjaan Spark di Kubernetes, tetapi mempertahankan status eksperimental dukungan untuk pengelola sumber daya ini. Mungkin pembaruan berikutnya akan benar-benar memungkinkan untuk sepenuhnya merekomendasikan untuk meninggalkan YARN dan menjalankan tugas-tugas Spark di Kubernetes, tanpa mengkhawatirkan keamanan sistem Anda dan tanpa perlu memperbaiki komponen fungsional secara mandiri.
Sirip.