
Identifikasi diri
Nama saya Alexander, saya mengembangkan arah analisis data dan teknologi untuk keperluan audit internal grup Rosbank. Saya dan tim saya menggunakan pembelajaran mesin dan jaringan saraf untuk mengidentifikasi risiko sebagai bagian dari audit audit internal. Kami memiliki server ~ 300 GB RAM dan 4 prosesor dengan 10 core di gudang senjata kami. Untuk pemrograman algoritmik atau pemodelan, kami menggunakan Python.
pengantar
Kami dihadapkan pada tugas menganalisa foto (potret) nasabah yang diambil oleh pegawai bank pada saat registrasi suatu produk perbankan. Tujuan kami adalah untuk mengidentifikasi risiko yang sebelumnya tidak tertutup dari foto-foto ini. Untuk mengidentifikasi risiko, kami menghasilkan dan menguji serangkaian hipotesis. Pada artikel ini, saya akan menjelaskan hipotesis apa yang kami buat dan bagaimana kami mengujinya. Untuk menyederhanakan persepsi materi, saya akan menggunakan Mona Lisa - standar genre potret.

Periksa jumlah
Awalnya, kami mengambil pendekatan tanpa machine learning dan computer vision, hanya membandingkan checksum file. Untuk membuatnya, kami mengambil algoritma md5 yang banyak digunakan dari pustaka hashlib.
Implementasi Python *:
#
with open(file,'rb') as f:
#
for chunk in iter(lambda: f.read(4096),b''):
#
hash_md5.update(chunk)
Saat membentuk checksum, kami segera memeriksa duplikat menggunakan kamus.
#
for file in folder_scan(for_scan):
#
ch_sum = checksum(file)
#
if ch_sum in list_of_uniq.keys():
# , , dataframe
df = df.append({'id':list_of_uniq[chs],'same_checksum_with':[file]}, ignore_index = True)
Algoritme ini sangat sederhana dalam hal beban komputasi: di server kami, 1000 gambar diproses dalam tidak lebih dari 3 detik.
Algoritme ini membantu kami mengidentifikasi foto duplikat di antara data kami, dan sebagai hasilnya, menemukan tempat untuk potensi perbaikan proses bisnis bank.
Poin-poin penting (visi komputer)
Terlepas dari hasil positif dari metode checksum, kami sangat memahami bahwa jika setidaknya satu piksel dalam gambar diubah, checksumnya akan sangat berbeda. Sebagai pengembangan logis dari hipotesis pertama, kami mengasumsikan bahwa gambar dapat diubah dalam struktur bit: menjalani penyimpanan ulang (yaitu kompresi ulang jpg), pengubahan ukuran, pemotongan, atau rotasi.
Untuk demonstrasi, mari potong tepi sepanjang garis luar merah dan putar Mona Lisa 90 derajat ke kanan.

Dalam hal ini, duplikat harus dicari berdasarkan konten visual gambar. Untuk ini, kami memutuskan untuk menggunakan pustaka OpenCV, metode untuk membangun titik-titik kunci dari sebuah gambar dan menemukan jarak antara titik-titik kunci. Dalam praktiknya, poin utama dapat berupa sudut, gradien warna, atau permukaan joging. Untuk tujuan kami, salah satu metode paling sederhana muncul - Brute-Force Matching. Untuk mengukur jarak antara titik-titik kunci gambar, kami menggunakan jarak Hamming. Gambar di bawah ini menunjukkan hasil pencarian poin-poin penting pada gambar asli dan gambar yang dimodifikasi (20 poin kunci terdekat dari gambar digambar).
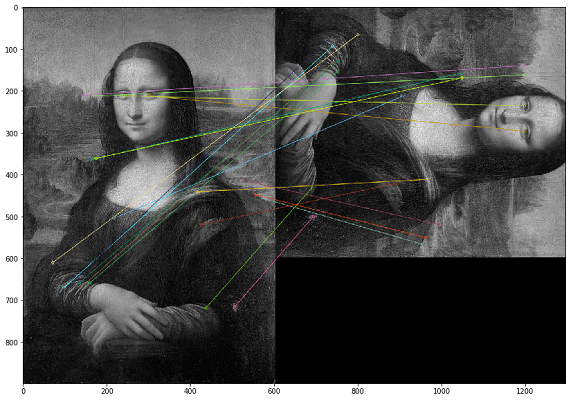
Penting untuk diperhatikan bahwa kami menganalisis gambar dalam filter hitam putih, karena ini mengoptimalkan waktu proses skrip dan memberikan interpretasi yang lebih jelas tentang poin-poin penting. Jika satu gambar dengan filter sepia, dan yang lainnya dalam warna asli, maka saat kami mengonversinya menjadi filter hitam dan putih, poin-poin penting akan diidentifikasi terlepas dari pemrosesan warna dan filter.
Kode contoh untuk membandingkan dua gambar *
img1 = cv.imread('mona.jpg',cv.IMREAD_GRAYSCALE) #
img2 = cv.imread('mona_ch.jpg',cv.IMREAD_GRAYSCALE) #
# ORB
orb = cv.ORB_create()
# ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# Brute-Force Matching
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# .
matches = bf.match(des1,des2)
# .
matches = sorted(matches, key = lambda x:x.distance)
# 20
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
Saat menguji hasil, kami menyadari bahwa dalam kasus gambar balik, urutan piksel dalam titik kunci berubah dan gambar semacam itu tidak diidentifikasi sebagai gambar yang sama. Sebagai ukuran kompensasi, Anda dapat mencerminkan sendiri setiap gambar dan menganalisis volume dua kali lipat (atau bahkan tiga kali lipat), yang jauh lebih mahal dalam hal daya komputasi.
Algoritma ini memiliki kompleksitas komputasi yang tinggi, dan beban terbesar dibuat dengan operasi penghitungan jarak antar titik. Karena kita harus membandingkan setiap gambar dengan masing-masing, maka, seperti yang Anda pahami, perhitungan himpunan Cartesian membutuhkan sejumlah besar siklus komputasi. Dalam satu audit, penghitungan serupa memakan waktu lebih dari sebulan.
Masalah lain dengan pendekatan ini adalah interpretasi hasil tes yang buruk. Kami mendapatkan koefisien jarak antara titik-titik kunci gambar, dan muncul pertanyaan: "Ambang apa dari koefisien ini yang harus dipilih cukup untuk mempertimbangkan gambar digandakan?"
Dengan menggunakan visi komputer, kami dapat menemukan kasus yang tidak tercakup dalam pengujian checksum pertama. Dalam praktiknya, ini ternyata file jpg yang terlalu banyak disimpan. Kami tidak mengidentifikasi kasus perubahan gambar yang lebih kompleks dalam kumpulan data yang dianalisis.
Poin-poin penting Checksum VS
Setelah mengembangkan dua pendekatan yang sangat berbeda untuk menemukan duplikat dan menggunakannya kembali dalam beberapa pemeriksaan, kami sampai pada kesimpulan bahwa untuk data kami, checksum memberikan hasil yang lebih nyata dalam waktu yang lebih singkat. Oleh karena itu, jika kita memiliki cukup waktu untuk memeriksa, maka kita membuat perbandingan berdasarkan poin-poin penting.
Cari gambar yang tidak normal
Setelah menganalisis hasil tes untuk poin-poin penting, kami melihat bahwa foto yang diambil oleh seorang karyawan memiliki jumlah poin kunci yang hampir sama. Dan ini logis, karena jika dia berkomunikasi dengan klien di tempat kerjanya dan berfoto di ruangan yang sama, maka background pada semua fotonya akan sama. Pengamatan ini membuat kami percaya bahwa kami mungkin menemukan foto pengecualian yang tidak seperti foto lain dari karyawan ini, yang mungkin diambil di luar kantor.
Kembali ke contoh pada Mona Lisa, ternyata orang lain akan muncul dengan latar belakang yang sama. Namun sayangnya, kami tidak menemukan contoh tersebut, jadi pada bagian ini kami akan menampilkan metrik data tanpa contoh. Untuk meningkatkan kecepatan komputasi dalam rangka pengujian hipotesis ini, kami memutuskan untuk mengabaikan poin-poin penting dan menggunakan histogram.
Langkah pertama adalah menerjemahkan citra tersebut menjadi suatu objek (histogram) yang dapat kita ukur untuk membandingkan citra tersebut berdasarkan jarak antar histogramnya. Pada dasarnya histogram adalah grafik yang memberikan gambaran umum tentang suatu gambar. Ini adalah grafik dengan nilai piksel pada sumbu absis (sumbu X) dan jumlah piksel yang sesuai pada gambar di sepanjang sumbu ordinat (sumbu Y). Histogram adalah cara mudah untuk menafsirkan dan menganalisis gambar. Dengan menggunakan histogram gambar, Anda bisa mendapatkan ide intuitif tentang kontras, kecerahan, distribusi intensitas, dan sebagainya.
Untuk setiap gambar, kami membuat histogram menggunakan fungsi calcHist dari OpenCV.
histo = cv2.calcHist([picture],[0],None,[256],[0,256])
Dalam contoh yang diberikan untuk tiga gambar, kami mendeskripsikannya menggunakan 256 faktor di sepanjang sumbu horizontal (semua jenis piksel). Tapi kita juga bisa mengatur ulang pikselnya. Tim kami tidak melakukan banyak pengujian pada bagian ini karena hasilnya cukup bagus jika menggunakan 256 faktor. Jika perlu, kita bisa mengubah parameter ini secara langsung di fungsi calcHist.
Setelah kami membuat histogram untuk setiap gambar, kami cukup melatih model DBSCAN pada gambar untuk setiap karyawan yang memotret klien. Poin teknis di sini adalah memilih parameter DBSCAN (epsilon dan min_samples) untuk tugas kita.
Setelah menggunakan DBSCAN, kita dapat melakukan pengelompokan citra, kemudian menerapkan metode PCA untuk memvisualisasikan klaster yang dihasilkan.

Seperti yang dapat dilihat dari distribusi gambar yang dianalisis, kami memiliki dua cluster biru yang jelas. Ternyata, pada hari yang berbeda seorang karyawan dapat bekerja di kantor yang berbeda - foto yang diambil di salah satu kantor akan membuat cluster terpisah.
Sedangkan titik hijau adalah foto pengecualian, yang memiliki latar belakang berbeda dari cluster tersebut.
Setelah menganalisis secara rinci foto-foto tersebut, kami menemukan banyak foto negatif palsu. Kasus yang paling umum adalah foto atau foto yang meledak di mana sebagian besar area ditempati oleh wajah klien. Ternyata metode analisis ini membutuhkan campur tangan manusia wajib untuk memvalidasi hasil.
Dengan menggunakan pendekatan ini, Anda dapat menemukan anomali yang menarik pada foto, tetapi akan membutuhkan waktu lama untuk menganalisis hasilnya secara manual. Karena alasan ini, kami jarang menjalankan pengujian seperti itu sebagai bagian dari audit kami.
Apakah ada wajah di foto itu? (Deteksi wajah)
Jadi, kami telah menguji kumpulan data kami dari berbagai sisi dan, terus mengembangkan kompleksitas pengujian, kami beralih ke hipotesis berikutnya: apakah ada wajah calon klien di foto tersebut? Tugas kita adalah mempelajari cara mengidentifikasi wajah dalam gambar, memberikan fungsi pada input gambar, dan mendapatkan jumlah wajah pada keluarannya.
Penerapan semacam ini sudah ada, dan kami memutuskan untuk memilih MTCNN (Multitasking Cascade Convolutional Neural Network) untuk tugas kami dari modul FaceNet dari Google.
FaceNet adalah arsitektur pembelajaran mesin mendalam yang terdiri dari lapisan konvolusional. FaceNet mengembalikan vektor 128 dimensi untuk setiap wajah. Faktanya, FaceNet adalah beberapa jaringan neural dan sekumpulan algoritme untuk mempersiapkan dan memproses hasil antara jaringan ini. Kami memutuskan untuk mendeskripsikan mekanisme pencarian wajah oleh jaringan saraf ini secara lebih rinci, karena tidak banyak materi tentang ini.
Langkah 1: pra-pemrosesan
Hal pertama yang dilakukan MTCNN adalah membuat berbagai ukuran foto kita.
MTCNN akan mencoba mengenali wajah dalam persegi berukuran tetap di setiap foto. Menggunakan pengenalan ini pada foto yang sama dengan ukuran berbeda akan meningkatkan peluang kami untuk mengenali dengan benar semua wajah di foto.

Wajah mungkin tidak dikenali dalam ukuran gambar normal, tetapi mungkin dikenali dalam gambar ukuran berbeda dalam persegi ukuran tetap. Langkah ini dilakukan secara algoritmik tanpa jaringan saraf.
Langkah 2: P-Net
Setelah membuat salinan berbeda dari foto kita, jaringan saraf pertama, P-Net, ikut bermain. Jaringan ini menggunakan kernel 12x12 (blok) yang akan memindai semua foto (salinan foto yang sama, tetapi berbeda ukuran), mulai dari sudut kiri atas, dan bergerak di sepanjang gambar menggunakan langkah 2 piksel.

Setelah memindai semua gambar dengan ukuran berbeda, MTCNN kembali menstandarisasi setiap foto dan menghitung ulang koordinat blok.
P-Net memberikan koordinat blok dan tingkat kepercayaan (seberapa akurat wajah ini) relatif terhadap permukaan yang dikandungnya untuk setiap blok. Anda dapat meninggalkan blok dengan tingkat kepercayaan tertentu menggunakan parameter ambang batas.
Pada saat yang sama, kami tidak bisa begitu saja memilih blok dengan tingkat kepercayaan maksimum, karena gambar dapat berisi beberapa wajah.
Jika satu blok tumpang tindih dengan yang lain dan menutupi area yang hampir sama, maka blok itu dihilangkan. Parameter ini dapat dikontrol selama inisialisasi jaringan.

Dalam contoh ini, blok kuning akan dihilangkan. Pada dasarnya, hasil P-Net adalah blok presisi rendah. Contoh di bawah ini menunjukkan hasil nyata P-Net:

Langkah 3: R-Net
R-Net melakukan pemilihan blok yang paling sesuai yang dibentuk sebagai hasil kerja P-Net, yang kemungkinan besar dalam grup adalah orang. R-Net memiliki arsitektur yang mirip dengan P-Net. Pada tahap ini, lapisan yang terhubung sepenuhnya terbentuk. Output dari R-Net juga sama dengan output dari P-Net.

Langkah 4: O-Net
Jaringan O-Net adalah bagian terakhir dari jaringan MTCNN. Selain dua jaringan terakhir, itu membentuk lima titik untuk setiap wajah (mata, hidung, sudut bibir). Jika titik-titik ini benar-benar masuk ke dalam blok, maka itu ditentukan sebagai yang paling mungkin mengandung orang tersebut. Poin tambahan ditandai dengan warna biru:

Hasilnya, kami mendapatkan blok terakhir yang menunjukkan keakuratan fakta bahwa ini adalah wajah. Jika wajah tidak ditemukan, maka kita akan mendapatkan jumlah blok wajah nol.
Rata-rata, pemrosesan 1000 foto oleh jaringan semacam itu membutuhkan waktu 6 menit di server kami.
Kami telah berulang kali menggunakan jaringan saraf ini dalam pemeriksaan, dan ini membantu kami secara otomatis mengidentifikasi anomali di antara foto-foto klien kami.
Tentang penggunaan FaceNet, saya ingin menambahkan bahwa jika, alih-alih Mona Lisa, Anda mulai menganalisis kanvas Rembrandt, hasilnya akan seperti gambar di bawah ini, dan Anda harus mengurai seluruh daftar orang yang teridentifikasi:

Kesimpulan
Hipotesis dan pendekatan pengujian ini menunjukkan bahwa dengan benar-benar kumpulan data apa pun, Anda dapat melakukan pengujian menarik dan mencari anomali. Banyak auditor sekarang mencoba mengembangkan praktik serupa, jadi saya ingin menunjukkan contoh praktis penggunaan visi komputer dan pembelajaran mesin.
Saya juga ingin menambahkan bahwa kami menganggap Pengenalan Wajah sebagai hipotesis pengujian berikutnya, tetapi sejauh ini spesifikasi data dan proses tidak memberikan dasar yang wajar untuk menggunakan teknologi ini dalam pengujian kami.
Secara umum, hanya ini yang ingin saya ceritakan kepada Anda tentang cara kami dalam menguji foto.
Saya berharap Anda memiliki analisis yang baik dan data berlabel!
* Kode sampel diambil dari sumber terbuka.