Bagian 2
Di artikel ini, Anda akan mempelajari:
- Tentang ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
- Tentang arsitektur CNN apa yang ada:
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- Tentang masalah apa yang muncul dengan arsitektur jaringan baru, bagaimana mereka diselesaikan dengan yang berikutnya:
- masalah gradien menghilang
- meledak masalah gradien
ILSVRC
Tantangan Pengenalan Visual Skala Besar ImageNet adalah kompetisi tahunan di mana Peneliti membandingkan kisi mereka untuk deteksi dan klasifikasi objek dalam foto.
Persaingan ini adalah pendorong untuk pengembangan:
- Arsitektur jaringan saraf
- metode dan praktik pribadi yang digunakan hingga hari ini.
Grafik ini menunjukkan bagaimana algoritme klasifikasi telah berevolusi dari waktu ke waktu:
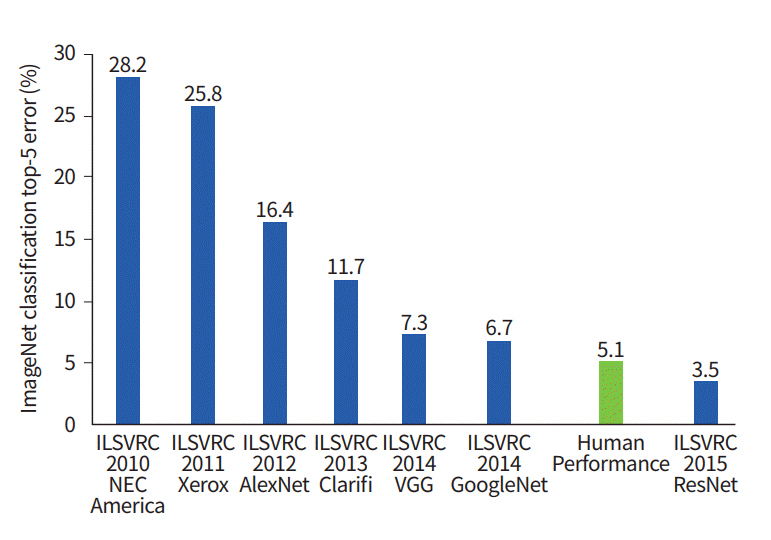
Pada sumbu x - tahun dan algoritme (sejak 2012 - saraf konvolusional jaringan).
Sumbu y adalah persentase kesalahan dalam sampel dari 5 kesalahan teratas.
Kesalahan 5 teratas adalah cara mengevaluasi model: model mengembalikan distribusi probabilitas tertentu dan jika di antara 5 probabilitas teratas terdapat nilai benar (label kelas) dari kelas tersebut, maka jawaban model dianggap benar. Karenanya, (1 - top-1 error) adalah akurasi yang sudah dikenal.
Arsitektur CNN
LeNet-5
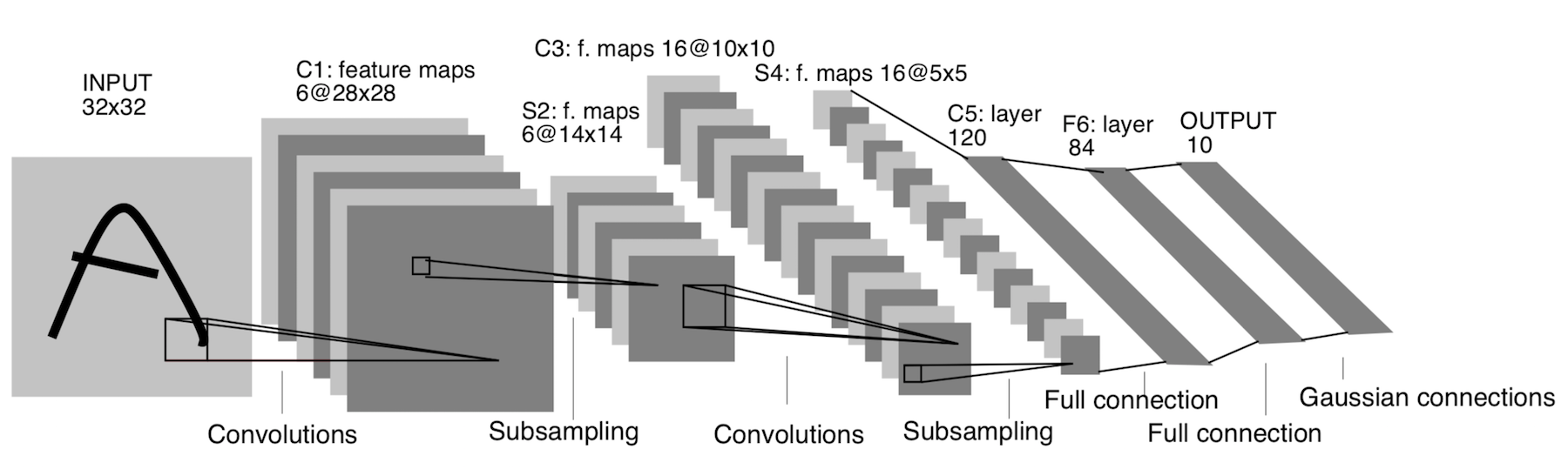
Itu sudah muncul pada tahun 1998! Itu dirancang untuk mengenali huruf dan angka tulisan tangan. Subsampling di sini mengacu pada lapisan penggabungan.
Arsitektur:
CONV 5x5, langkah = 1
POOL 2x2, langkah = 2
CONV 5x5, langkah = 1
POOL 5x5, langkah = 2
FC (120, 84)
FC (84, 10)
Sekarang arsitektur ini hanya memiliki makna historis. Arsitektur ini mudah diterapkan dengan tangan dalam kerangka pembelajaran mendalam modern apa pun.
AlexNet

Gambar tidak diduplikasi. Beginilah arsitektur digambarkan, karena arsitektur AlexNet tidak muat pada satu perangkat GPU pada saat itu, sehingga "setengah" jaringan berjalan pada satu GPU, dan yang lainnya di sisi lain.
Itu muncul pada 2012. Sebuah terobosan dalam ILSVRC dimulai dengan dia - dia mengalahkan semua model stat-of-art pada waktu itu. Setelah itu, orang-orang menyadari bahwa jaringan saraf benar-benar berfungsi :)
Arsitektur lebih spesifiknya:

Jika Anda mencermati arsitektur AlexNet, Anda dapat melihat bahwa selama 14 tahun (sejak kemunculan LeNet-5) hampir tidak ada perubahan, kecuali jumlah lapisan.
Penting:
- Kami mengambil gambar asli 227x227x3 dan menurunkan dimensinya (dalam tinggi dan lebar), tetapi menambah jumlah saluran. Bagian arsitektur ini "menyandikan" representasi asli dari objek (pembuat enkode).
- ReLU. ReLu .
- 60 .
- .
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- Catatan seperti Conv 11x11s4, 96 berarti lapisan konvolusi memiliki filter 11x11xNc, langkah = 4, jumlah filter tersebut adalah 96. Sekarang jumlah filter tersebut adalah jumlah saluran untuk lapisan berikutnya (Nc yang sama). Kami berasumsi bahwa gambar awal memiliki tiga saluran (R, G dan B).
VGGNet
Arsitektur:
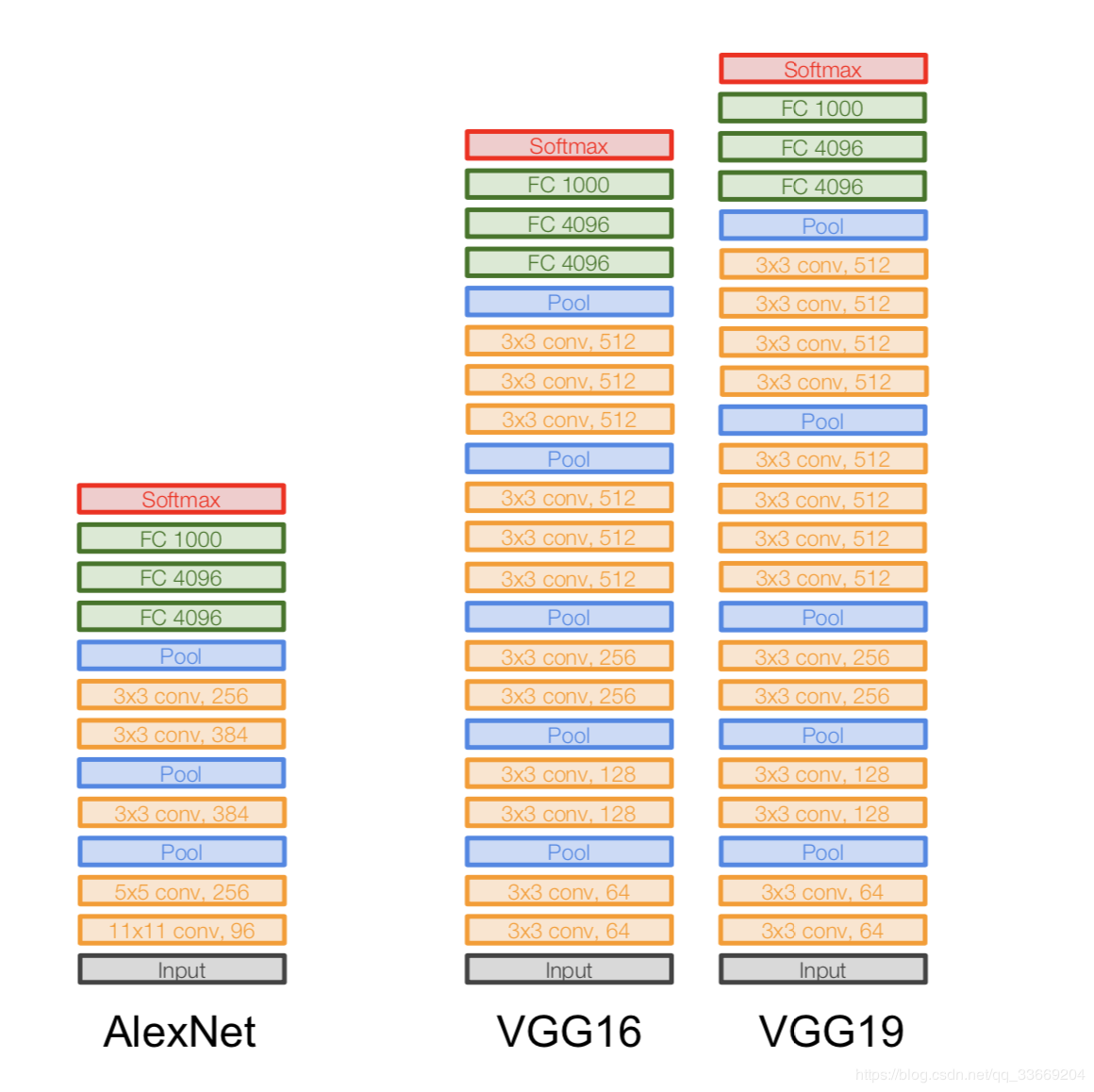
Diperkenalkan pada tahun 2014.
Dua versi - VGG16 dan VGG19. Ide utamanya adalah menggunakan yang kecil (3x3), bukan yang besar (11x11 dan 5x5). Intuisi untuk menggunakan konvolusi besar itu sederhana - kami ingin mendapatkan lebih banyak informasi dari piksel tetangga, tetapi jauh lebih baik menggunakan filter kecil lebih sering .
Dan itulah kenapa:
- . , . .. , , .
- => .
- — , — , — , .
Penting:
- Saat melatih jaringan neural untuk algoritma error backpropagation, penting untuk mempertahankan representasi objek (bagi kami, gambar asli) di semua tahap (konvolusi, kumpulan) propagasi maju (forward pass adalah saat kita memasukkan gambar ke input dan pindah ke output, untuk hasilnya). Representasi suatu objek ini bisa mahal dalam hal memori. Coba lihat:
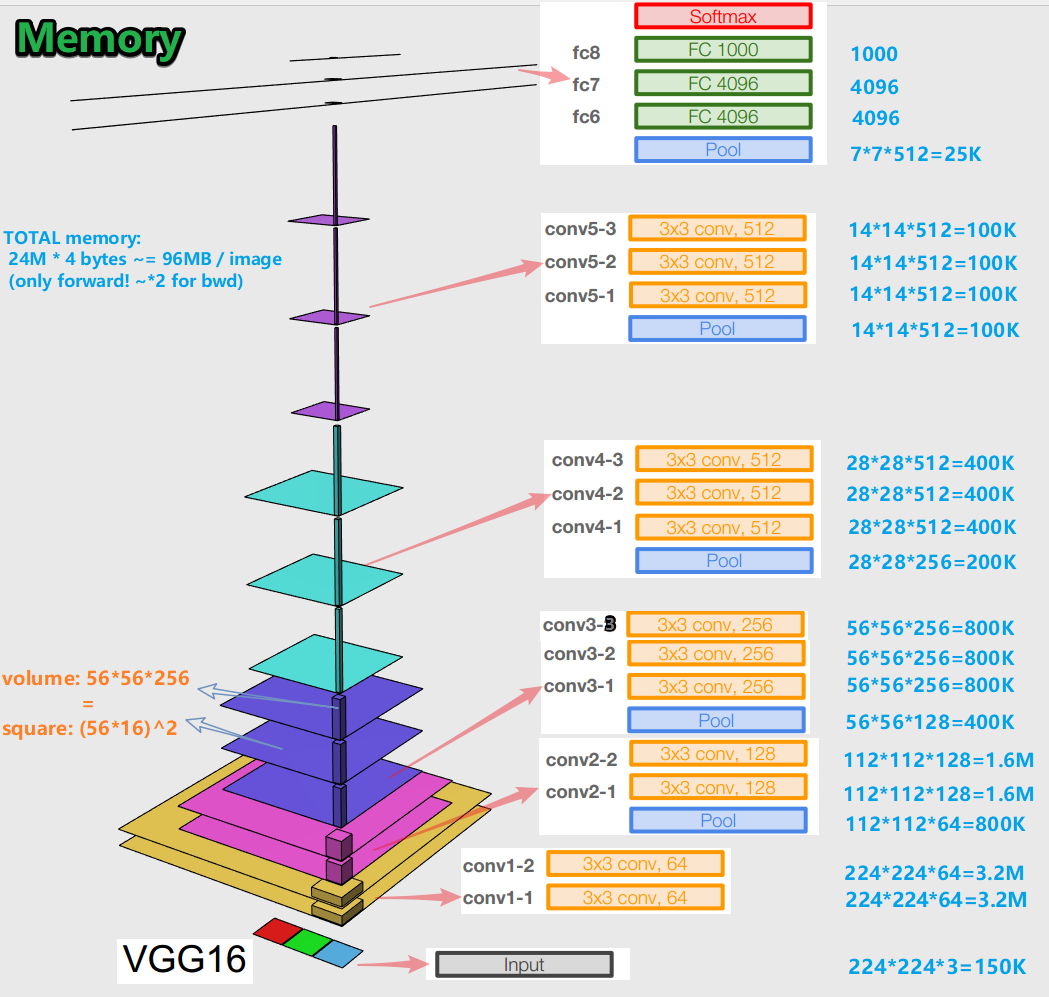
Ternyata sekitar 96 MB per gambar - dan itu hanya untuk penerusan. Untuk backward pass (bwd dalam gambar) - saat menghitung gradien - sekitar dua kali lipat. Gambar yang menarik muncul: jumlah terbesar dari parameter terlatih terletak di lapisan yang sepenuhnya terhubung, dan memori terbesar ditempati oleh representasi objek setelah lapisan konvolusional dan penyatuan . C - sinergi.
- Jaringan memiliki 138 juta parameter pelatihan dalam 16 variasi lapisan dan 143 juta parameter dalam 19 variasi lapisan.
GoogLeNet
Arsitektur:
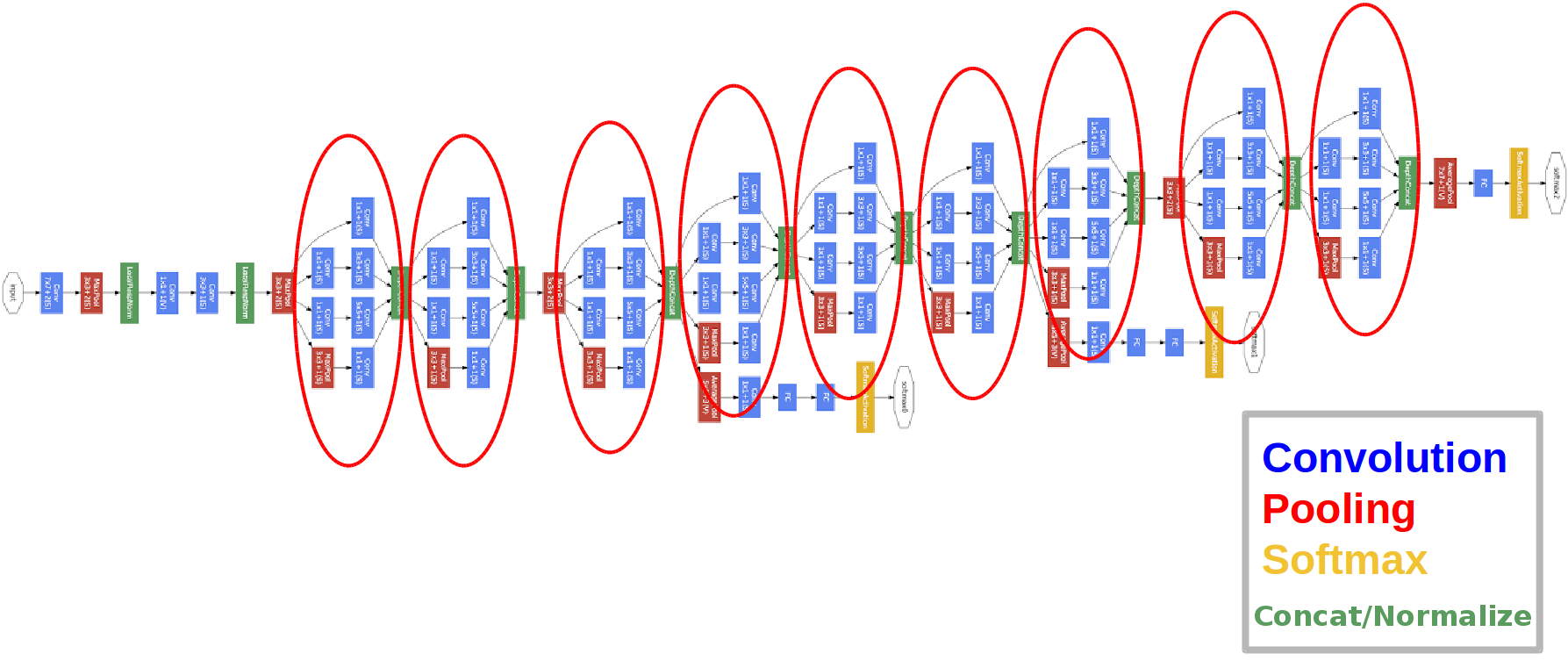
Diperkenalkan pada tahun 2014.
Lingkaran merah inilah yang disebut modul Inception.
Mari kita lihat lebih dekat:
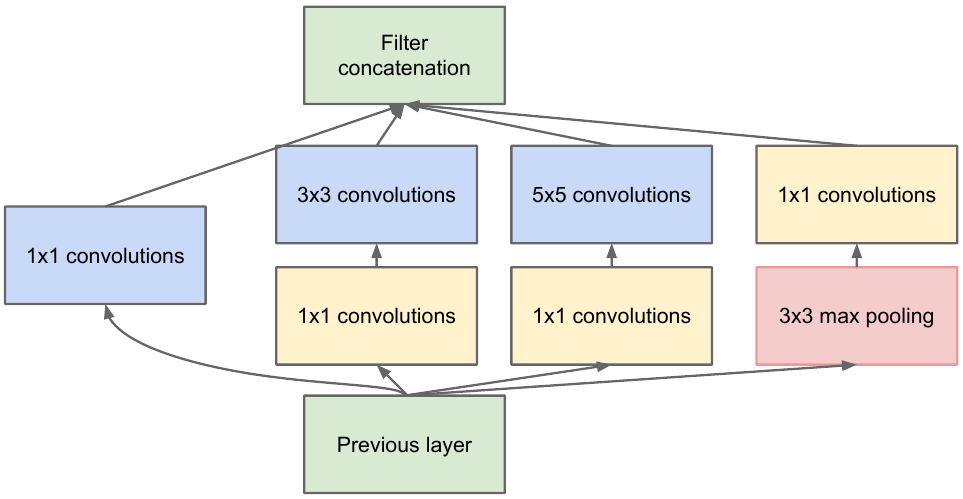
Kami mengambil peta fitur dari lapisan sebelumnya, menerapkan sejumlah konvolusi dengan filter yang berbeda, lalu menggabungkan yang dihasilkan. Intuisi sederhana: kami ingin mendapatkan representasi berbeda dari peta fitur kami menggunakan filter dengan ukuran berbeda. Konvolusi 1x1 digunakan agar tidak menambah jumlah saluran terlalu banyak setelah setiap blok awal tersebut. Itu. jika peta fitur memiliki banyak saluran, dan mereka ingin mengurangi jumlah ini tanpa mengubah tinggi dan lebar peta fitur, gunakan konvolusi 1x1.
Ada juga tiga blok pengklasifikasi dalam jaringan, ini adalah salah satu dari mereka terlihat (yang di sebelah kanan untuk kami):

Dengan konstruksi ini, gradien "lebih baik" mencapai dari lapisan keluaran ke lapisan masukan selama propagasi kembali kesalahan.
Mengapa kita membutuhkan dua keluaran jaringan tambahan? Ini semua tentang apa yang disebut masalah gradien lenyap :
Intinya adalah bahwa ketika melakukan propagasi mundur kesalahan, gradien cenderung sepele ke nol. Semakin dalam jaringan, semakin rentan terhadap fenomena ini. Mengapa ini terjadi? Saat kita melakukan backward pass, kita beralih dari output ke input, menghitung gradien fungsi kompleks. Turunan dari fungsi kompleks ( aturan rantai) Pada dasarnya adalah perkalian. Jadi, mengalikan beberapa nilai di sepanjang jalan dari keluaran ke masukan, kami menemukan angka yang mendekati nol, dan, sebagai hasilnya, bobot jaringan saraf praktis tidak diperbarui. Ini sebagian merupakan masalah dengan fungsi aktivasi sigmoid yang keluarannya dalam beberapa kisaran tetap. Nah, masalah ini sebagian diselesaikan dengan menggunakan fungsi aktivasi ULT. Mengapa sebagian? Karena tidak ada yang memberi jaminan untuk nilai parameter yang dilatih dan representasi objek masukan di semua peta fitur.
Penting:
- Jaringan memiliki 22 lapisan (ini sedikit lebih banyak dari yang dimiliki jaringan sebelumnya).
- Jumlah parameter yang dilatih sama dengan lima juta, yang beberapa kali lebih sedikit dibandingkan dengan dua jaringan sebelumnya.
- Munculnya bundel 1x1.
- Blok awal digunakan.
- Alih-alih lapisan yang sepenuhnya terhubung, sekarang konvolusi 1x1, yang menurunkan kedalaman dan, akibatnya, menurunkan dimensi lapisan yang sepenuhnya terhubung dan yang disebut penggabungan avegare global (Anda dapat membaca lebih lanjut di sini ).
- Arsitektur memiliki 3 keluaran (jawaban akhir ditimbang).
ResNet
Arsitektur (varian ResNet-34): Diperkenalkan
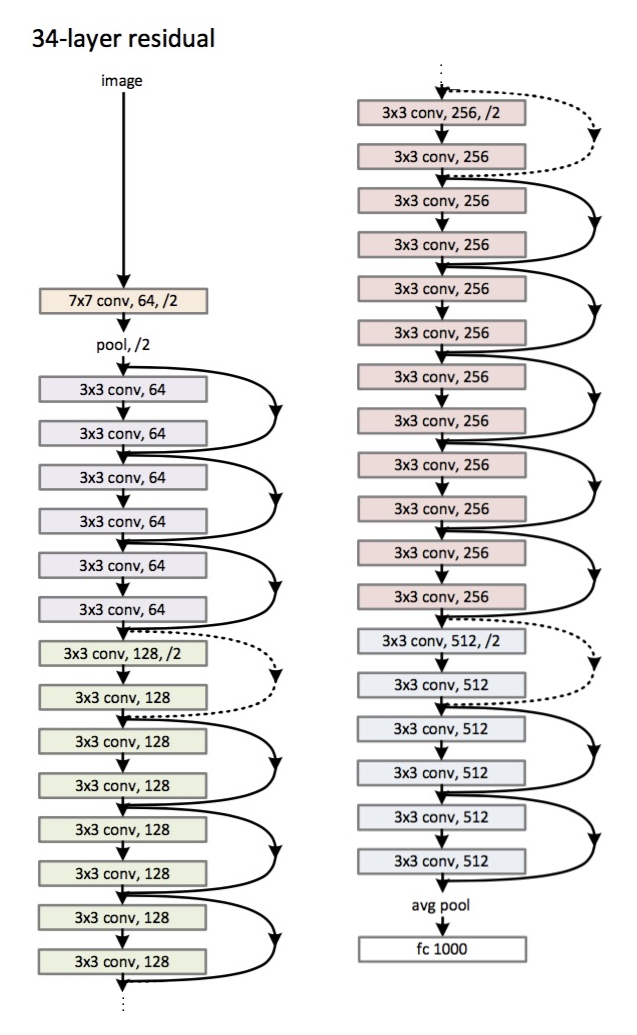
pada tahun 2015.
Inovasi utama adalah sejumlah besar lapisan dan yang disebut blok residual. Blok-blok ini digunakan untuk mengatasi masalah gradien yang memudar. Hubungan antara sisa-blok disebut jalan pintas (panah di gambar). Sekarang, dengan menggunakan pintasan ini, gradien akan mencapai semua parameter yang diperlukan, dengan demikian melatih jaringan :)
Penting:
- Alih-alih lapisan yang sepenuhnya terhubung - penggabungan global rata-rata.
- Blok sisa.
- Jaringan telah melampaui manusia dalam mengenali gambar pada dataset ImageNet (kesalahan 5 teratas).
- Normalisasi batch digunakan untuk pertama kalinya.
- Teknik inisialisasi bobot digunakan (intuisi: dari inisialisasi bobot tertentu, jaringan berkumpul (belajar) lebih cepat dan lebih baik).
- Kedalaman maksimum 152 lapisan!
Penyimpangan kecil
Masalah gradien memudar relevan untuk semua jaringan neural dalam.
Ada juga antagonisnya - masalah gradien yang meledak, yang juga relevan untuk semua jaringan neural dalam. Intinya jelas dari namanya - gradien menjadi terlalu besar, yang menyebabkan NaN (bukan angka, tak terbatas). Solusinya jelas - untuk membatasi nilai gradien, jika tidak - untuk mengurangi nilainya (menormalkan). Teknik ini disebut "clipping".
Kesimpulan
Pada 2019, sebuah artikel muncul tentang keluarga arsitektur baru - EfficientNet.
Saya merekomendasikan untuk mengikuti tren terbaru dalam berbagai tugas dan area yang terkait dengan Pembelajaran Mesin di sini . Pada sumber daya ini, Anda dapat memilih tugas (misalnya, klasifikasi gambar) dan kumpulan data (misalnya, ImageNet) dan melihat kualitas arsitektur tertentu, informasi tambahan tentangnya. Misalnya, kisi FixEfficientNet-L2 menempati tempat pertama yang terhormat dalam klasifikasi gambar pada set data ImageNet (akurasi 1 teratas).
Di artikel berikutnya, kita akan berbicara tentang pembelajaran transfer, deteksi objek, segmentasi.