Oleh karena itu, ketika konsumsi sumber daya yang tidak normal (CPU, memori, disk, jaringan, ...) terjadi pada salah satu dari ribuan server yang dikendalikan , ada kebutuhan untuk mencari tahu "siapa yang harus disalahkan dan apa yang harus dilakukan."
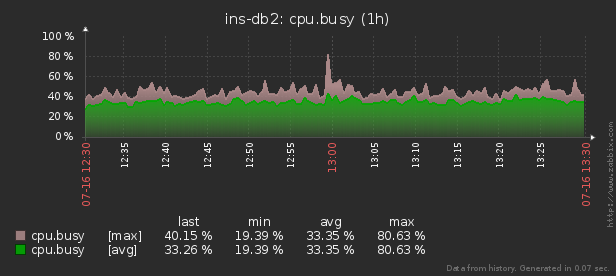
Utilitas pidstat tersedia untuk pemantauan waktu nyata dari penggunaan sumber daya server Linux "saat ini" . Artinya, jika puncak beban bersifat periodik, mereka dapat "ditetaskan" tepat di konsol. Tapi kami ingin menganalisis data ini setelah fakta , mencoba menemukan proses yang menciptakan beban maksimum pada sumber daya.
Artinya, saya ingin dapat mencari data yang dikumpulkan sebelumnya berbagai laporan indah dengan pengelompokan dan detail pada berbagai jenis ini:
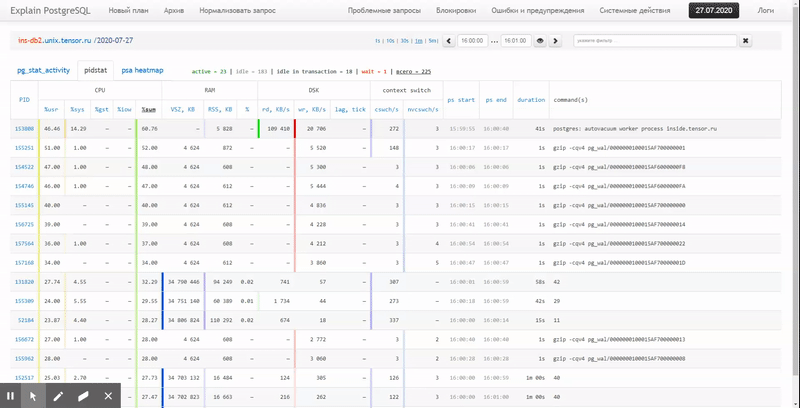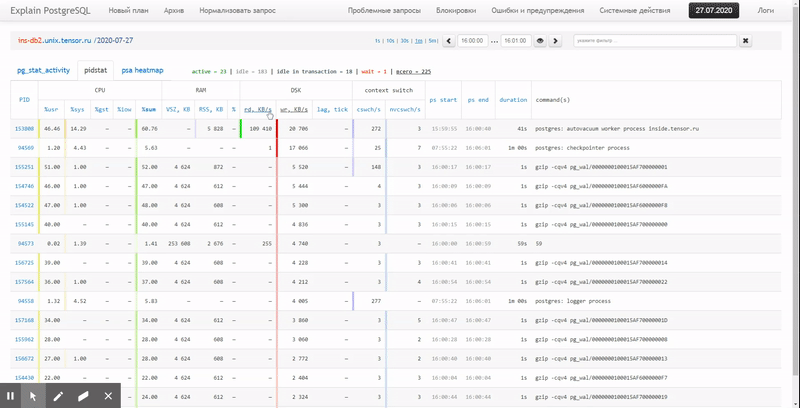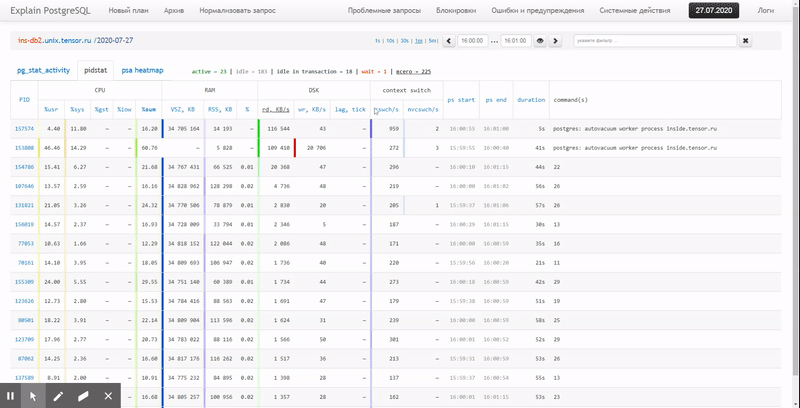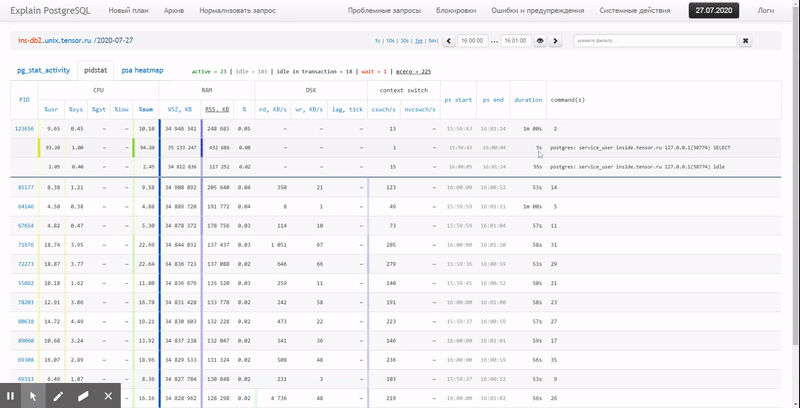
Dalam artikel ini, mari kita pertimbangkan bagaimana secara ekonomis dapat ditempatkan dalam database, dan bagaimana membangun yang paling efektif dari laporan data ini dengan menggunakan fungsi jendela dan SET PENGELOMPOKAN .
Pertama, mari kita lihat jenis data apa yang dapat kita ekstrak jika kita menggunakan "semuanya secara maksimal":
pidstat -rudw -lh 1| Waktu | UID | PID | % usr | % sistem | % tamu | % CPU | CPU | minflt / dtk | majflt / s | VSZ | Rss | % MEM | kB_rd / dtk | kB_wr / dtk | kB_ccwr / dtk | cswch / s | nvcswch / s | Perintah |
| 1594893415 | 0 | 1 | 0,00 | 13.08 | 0,00 | 13.08 | 52 | 0,00 | 0,00 | 197312 | 8512 | 0,00 | 0,00 | 0,00 | 0,00 | 0,00 | 7.48 | / usr / lib / systemd / systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | sembilan | 0,00 | 0.93 | 0,00 | 0.93 | 40 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 350.47 | 0,00 | rcu_sched |
| 1594893415 | 0 | tigabelas | 0,00 | 0,00 | 0,00 | 0,00 | 1 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 1.87 | 0,00 | migrasi / 11.87 |
Semua nilai ini dibagi menjadi beberapa kelas. Beberapa dari mereka berubah secara konstan (CPU dan aktivitas disk), yang lain jarang (alokasi memori), dan Command tidak hanya jarang berubah dalam proses yang sama, tetapi juga berulang secara teratur pada PID yang berbeda.
Struktur dasar
Demi kesederhanaan, mari batasi diri kita pada satu metrik untuk setiap "kelas" yang akan kita hemat:% CPU, RSS, dan Command.
Karena kita tahu sebelumnya bahwa Perintah diulang secara teratur, kita hanya akan memindahkannya ke kamus tabel terpisah, di mana hash MD5 akan bertindak sebagai kunci UUID:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);Dan untuk datanya sendiri, tabel jenis ini cocok untuk kita:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);Izinkan saya menarik perhatian Anda pada fakta bahwa karena% CPU selalu datang kepada kita dengan akurasi 2 tempat desimal dan tentunya tidak melebihi 100,00, maka kita dapat dengan mudah mengalikannya dengan 100 dan memasukkannya
smallint. Di satu sisi, hal ini akan menyelamatkan kita dari masalah akurasi akuntansi selama operasi, di sisi lain masih lebih baik menyimpan hanya 2 byte dibandingkan dengan 4 byte realatau 8 byte double precision.
Anda dapat membaca lebih lanjut tentang cara mengemas record secara efisien di penyimpanan PostgreSQL di artikel "Menghemat uang dalam jumlah besar" , dan tentang meningkatkan throughput database untuk menulis - di "Menulis di sublight: 1 host, 1 hari, 1TB" .
Penyimpanan "Gratis" dari NULL
Untuk menghemat kinerja subsistem disk database kami dan volume yang ditempati oleh database, kami akan mencoba merepresentasikan data sebanyak mungkin dalam bentuk NULL - penyimpanannya praktis "gratis", karena hanya dibutuhkan sedikit di header record.
Informasi lebih lanjut tentang mekanisme internal merepresentasikan catatan di PostgreSQL dapat ditemukan dalam ceramah Nikolai Shaplov di PGConf.Russia 2016 "Apa yang ada di dalamnya: penyimpanan data pada tingkat rendah . " Slide # 16 dikhususkan untuk penyimpanan NULL .Mari kita lihat lebih dekat jenis data kita:
- CPU / DSK
Berubah secara konstan, tetapi sangat sering berubah menjadi nol - jadi bermanfaat untuk menulis NULL daripada 0 ke basis . -
Perubahan RSS / CMD sangat jarang - jadi kita akan menulis NULL bukannya mengulang dalam PID yang sama.
Ternyata gambarannya seperti ini, jika Anda melihatnya dalam konteks PID tertentu:

Jelas bahwa jika proses kami mulai menjalankan perintah lain, maka nilai memori yang digunakan juga mungkin akan berbeda dari sebelumnya - jadi kami akan setuju bahwa ketika mengubah CMD, nilai RSS juga akan menjadi perbaiki terlepas dari nilai sebelumnya.
Artinya , entri dengan nilai CMD yang terisi juga memiliki nilai RSS . Mari kita kenang momen ini, ini akan tetap berguna bagi kita.
Menyusun laporan yang indah
Sekarang mari kita kumpulkan kueri yang akan menunjukkan kepada kita konsumen sumber daya dari host tertentu pada interval waktu tertentu.
Tapi mari kita lakukan segera dengan penggunaan sumber daya yang minimal - mirip dengan artikel tentang SELF JOIN dan fungsi jendela .
Menggunakan parameter yang masuk
Agar tidak menentukan nilai parameter laporan (atau $ 1 / $ 2) di beberapa tempat selama kueri SQL, kami memilih CTE dari satu-satunya bidang json di mana parameter ini ditempatkan oleh kunci:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
Mengambil data mentah
Karena kami tidak menemukan agregat kompleks, satu-satunya cara untuk menganalisis data adalah dengan membacanya. Untuk ini kita membutuhkan indeks yang jelas:
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
Analisis pengelompokan kunci
Untuk setiap PID yang ditemukan, kami menentukan interval aktivitasnya dan mengambil CMD dari rekaman pertama dalam interval ini.
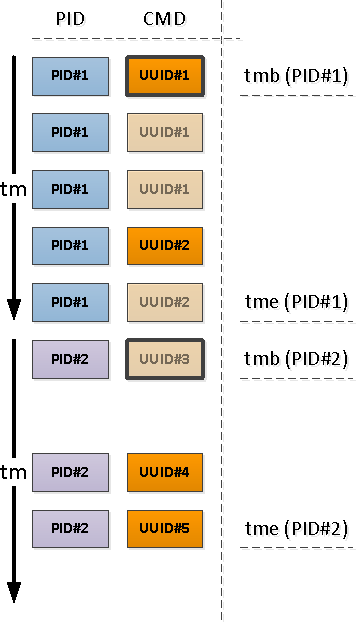
Untuk melakukan ini, kami akan menggunakan fungsi unikisasi melalui
DISTINCT ONdan jendela:
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
Proses batas aktivitas
Perhatikan bahwa relatif terhadap awal interval kita, catatan pertama yang muncul mungkin salah satu yang sudah memiliki bidang CMD terisi (PID # 1 pada gambar di atas), atau dengan NULL, menunjukkan kelanjutan dari nilai "di atas" yang terisi dalam kronologi (PID # 2 ).
PID yang dibiarkan tanpa CMD sebagai akibat dari operasi sebelumnya dimulai lebih awal dari awal interval kami, yang berarti bahwa "permulaan" ini perlu ditemukan:

Karena kami mengetahui dengan pasti bahwa segmen aktivitas berikutnya dimulai dengan nilai CMD yang terisi (dan terdapat RSS yang terisi, yang berarti ), indeks bersyarat akan membantu kita di sini:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
Jika kita ingin (dan ingin) mengetahui waktu berakhirnya aktivitas segmen tersebut, maka untuk setiap PID kita harus menggunakan "dua arah" untuk menentukan batas bawah.
Kami telah menggunakan teknik serupa di artikel PostgreSQL Antipatterns: Registry Navigation .

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
Konversi JSON dari format posting
Perhatikan bahwa kami
precmd/pstcmdhanya memilih bidang yang memengaruhi baris berikutnya, dan CPU / DSK apa pun yang terus berubah - tidak. Oleh karena itu, format rekaman dalam tabel asli dan CTE ini berbeda untuk kami. Tidak masalah!
- row_to_json - mengubah setiap record dengan bidang menjadi objek json
- array_agg - kumpulkan semua entri di '{...}' :: json []
- array_to_json - mengubah array-from-JSON menjadi JSON-array '[...]' :: json
- json_populate_recordset - menghasilkan pilihan struktur tertentu dari larik JSON
Di sini kami menggunakan satu panggilanKami merekatkan "awal" dan "akhir" yang ditemukan ke dalam heap umum dan menambahkan ke kumpulan rekaman asli:json_populate_recordsetalih-alih panggilan gandajson_populate_record, karena itu basi jauh lebih cepat.
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
Mengisi celah kosong dalam pengulangan
Mari kita gunakan model yang dibahas dalam artikel "SQL HowTo: Membangun Rantai dengan Fungsi Jendela" .Pertama, pilih grup "ulangi":
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
Selain itu, menurut CMD dan RSS, grup akan independen satu sama lain, sehingga mereka mungkin terlihat seperti ini:
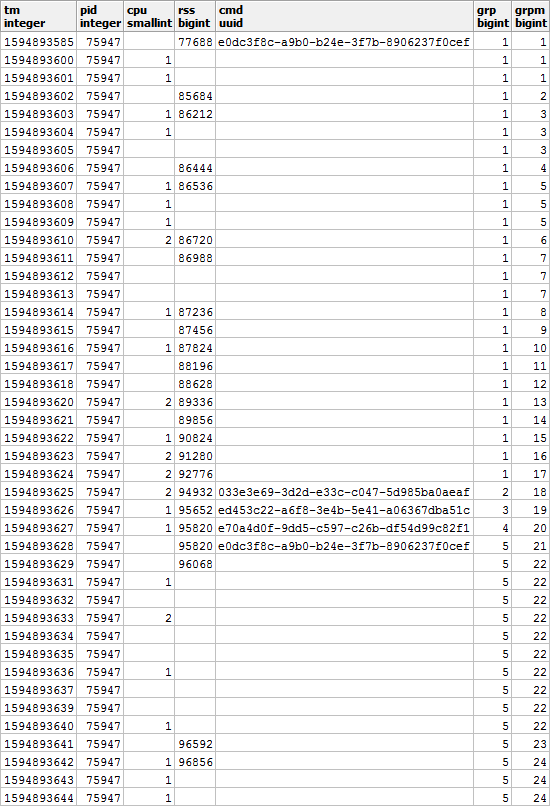
Isi celah di RSS dan hitung durasi setiap segmen untuk memperhitungkan distribusi muatan dengan benar dari waktu ke waktu:
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
Multi-grouping dengan GROUPING SETS
Karena kita ingin melihat hasilnya baik informasi ringkasan untuk keseluruhan proses dan perinciannya berdasarkan segmen aktivitas yang berbeda, kita akan menggunakan pengelompokan dengan beberapa set kunci sekaligus menggunakan GROUPING SETS :
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
Kasus penggunaan (array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]memungkinkan kita untuk mendapatkan nilai non-kosong pertama (meskipun bukan yang pertama) dari seluruh rangkaian tepat saat mengelompokkan, tanpa gerakan tubuh tambahan .Opsi untuk mendapatkan beberapa bagian dari sampel target sekaligus sangat nyaman untuk menghasilkan berbagai laporan dengan perincian, sehingga semua data perincian tidak perlu dibuat ulang, tetapi agar muncul di UI bersama dengan sampel utama.
Kamus, bukan GABUNG
Buat "kamus" CMD untuk semua segmen yang ditemukan:
Anda dapat membaca lebih lanjut tentang teknik "mastering" di artikel "Antipattern PostgreSQL: Let's Hit a Heavy JOIN with a Dictionary" .
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
Dan sekarang kami menggunakannya sebagai gantinya
JOIN, mendapatkan data "cantik" terakhir:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;
Terakhir, mari kita pastikan bahwa seluruh kueri kita ternyata cukup ringan saat dijalankan:

[lihat menjelaskan.tensor.ru]
Hanya 44 md dan 33 MB data yang dibaca!