
Hari ini kami akan memberi tahu Anda, tanpa mengacu pada model spesifik peralatan jaringan, bagaimana prinsip "dari otomatisasi ke otonomi" diwujudkan dalam kemampuan baru produk FabricInsight. Memang, dalam beberapa tahun terakhir, tidak hanya komposisinya yang berubah, tetapi juga banyak skenario baru telah muncul yang memungkinkan untuk menentukan status jaringan saat ini dan memprediksi kemungkinan masalah di dalamnya.
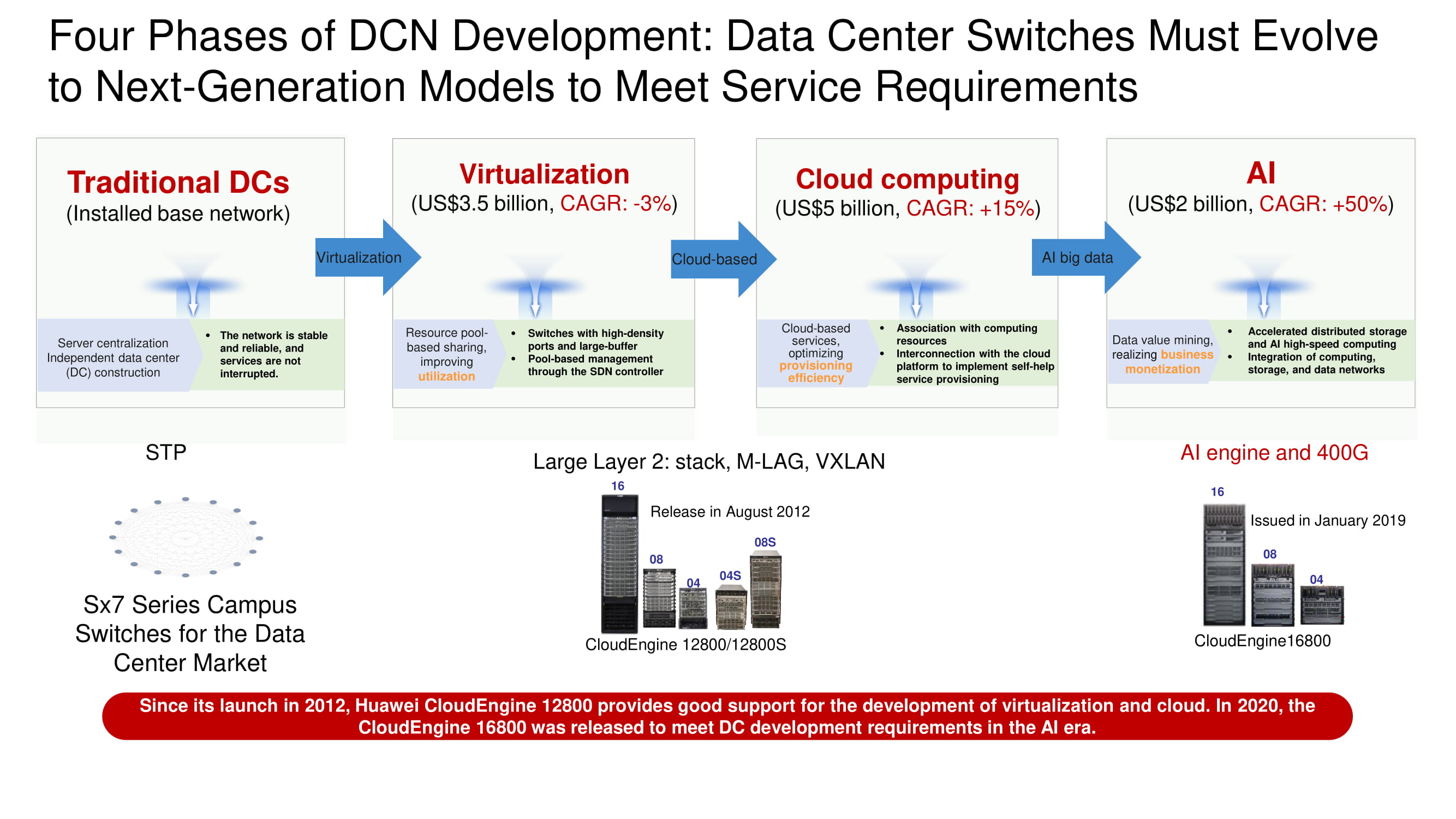
Empat tahap pengembangan pusat data
Menentukan vektor pengembangan jaringan pusat data, mudah untuk melihat bagaimana arsitektur pusat data tradisional secara bertahap jatuh di bawah serangan sistem virtualisasi, kemudian selamat dari migrasi besar-besaran sumber daya dan layanan ke cloud, dan sekarang mendekati pengenalan luas sistem kecerdasan buatan dan antarmuka berkecepatan tinggi 400 Gb / s. Kemampuan AI diperlukan untuk membangun jaringan Ethernet lossless dan membuat aplikasi yang sepenuhnya kebal terhadap latensi.
Area lain dari penerapan AI adalah menganalisis dan memantau operasi pusat data. Kita harus beralih dari ideologi yang menyiratkan pemantauan terbatas secara fungsional dari beberapa "kotak hitam" ke konsep jaringan yang sepenuhnya transparan yang semuanya diketahui.

Sebagai unit jaringan infrastruktur utama untuk membangun jaringan pusat data, Huawei kini menawarkan jajaran switch CloudEngine 16800 empat, delapan, dan enam belas slot dengan uplink 400 Gbps; rilis mereka dijadwalkan untuk tahun ini. Juga di antara produk baru, kami mencatat sakelar ToR CloudEngine 6881 dan 6863 yang dibangun di atas basis elemen kami sendiri dengan antarmuka 10 dan 25 Gbps, masing-masing.

Ilustrasi menunjukkan model sakelar dari lini CloudEngine 16800 dengan arsitektur ortogonal klasik, yang dilengkapi dengan sistem pendingin depan-ke-belakang, serta kartu saluran yang kompatibel dengan antarmuka 10, 40 dan 100 Gb / dtk.
Dari fungsi dasar penting CloudEngine 16800, kami menyoroti kemampuannya untuk bekerja dengan NSH (Network Service Header), yang memungkinkan penerapan mikro-segmentasi didistribusikan di beberapa sakelar di pusat data (isolasi di tingkat mesin virtual), menyediakan kemampuan telemetri yang luas dan menganalisis lalu lintas di tepi jaringan (kecerdasan tepi ) menggunakan teknologi kecerdasan buatan berdasarkan chip AI Huawei.
V1R19C10 akan benar-benar revolusioner. Di dalamnya banyak fungsi yang ditunggu-tunggu harus diimplementasikan, termasuk EVPN Multihoming tanpa "jumper" dalam bentuk M-LAG (Multi-Switch Link Aggregation) berdasarkan jenis rute pertama dan keempat dalam perutean EVPN VXLAN.
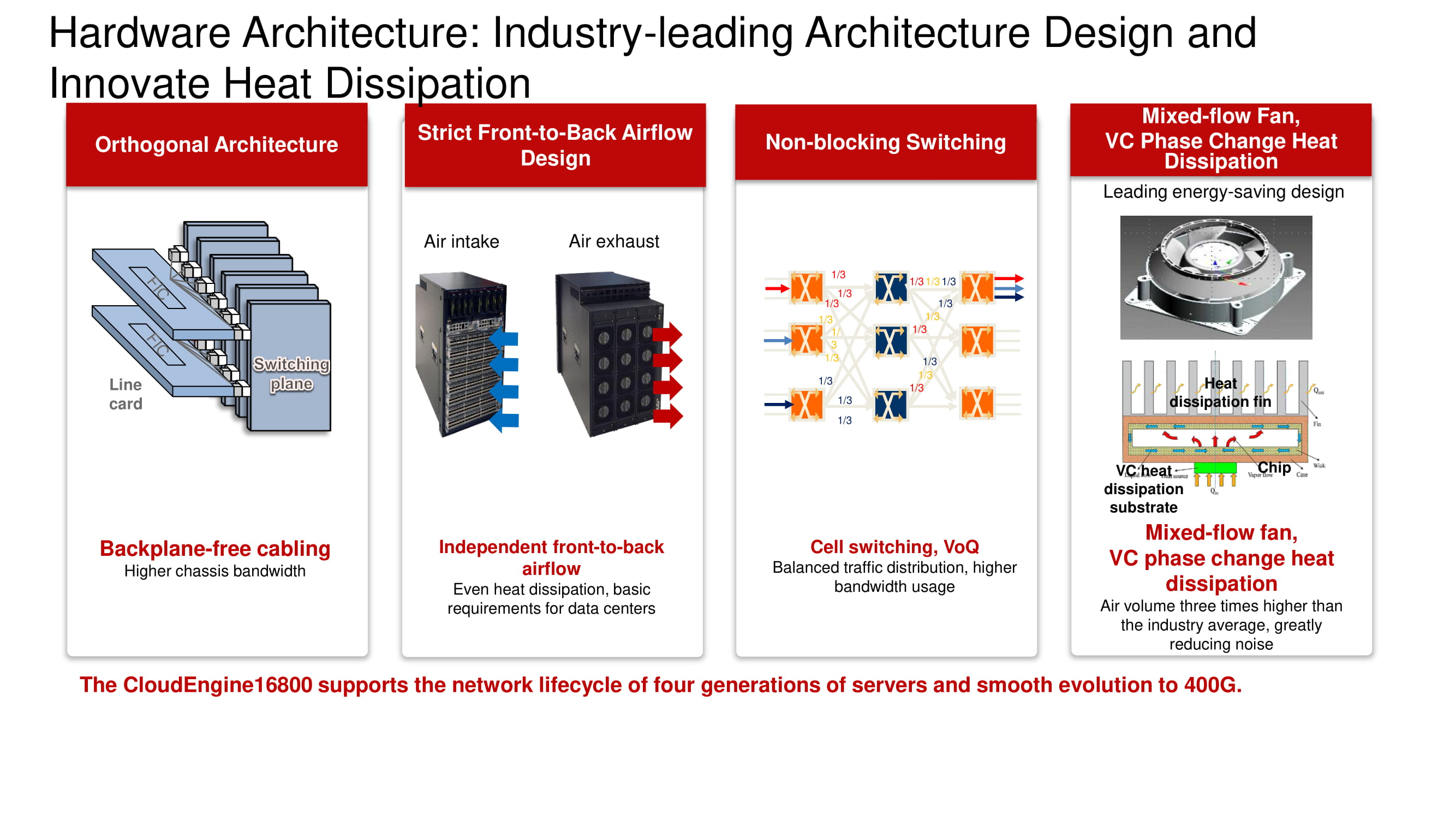
Arsitektur yang familiar dan kemungkinan baru
Diagram menunjukkan arsitektur ortogonal yang sudah dikenal dari Sakelar Non-pemblokiran "pabrik" tiga tingkat. Keuntungan utamanya meliputi pengaturan optimal dari papan "pabrik", kartu saluran, konektor dan sistem blower berdasarkan kipas kecepatan variabel.
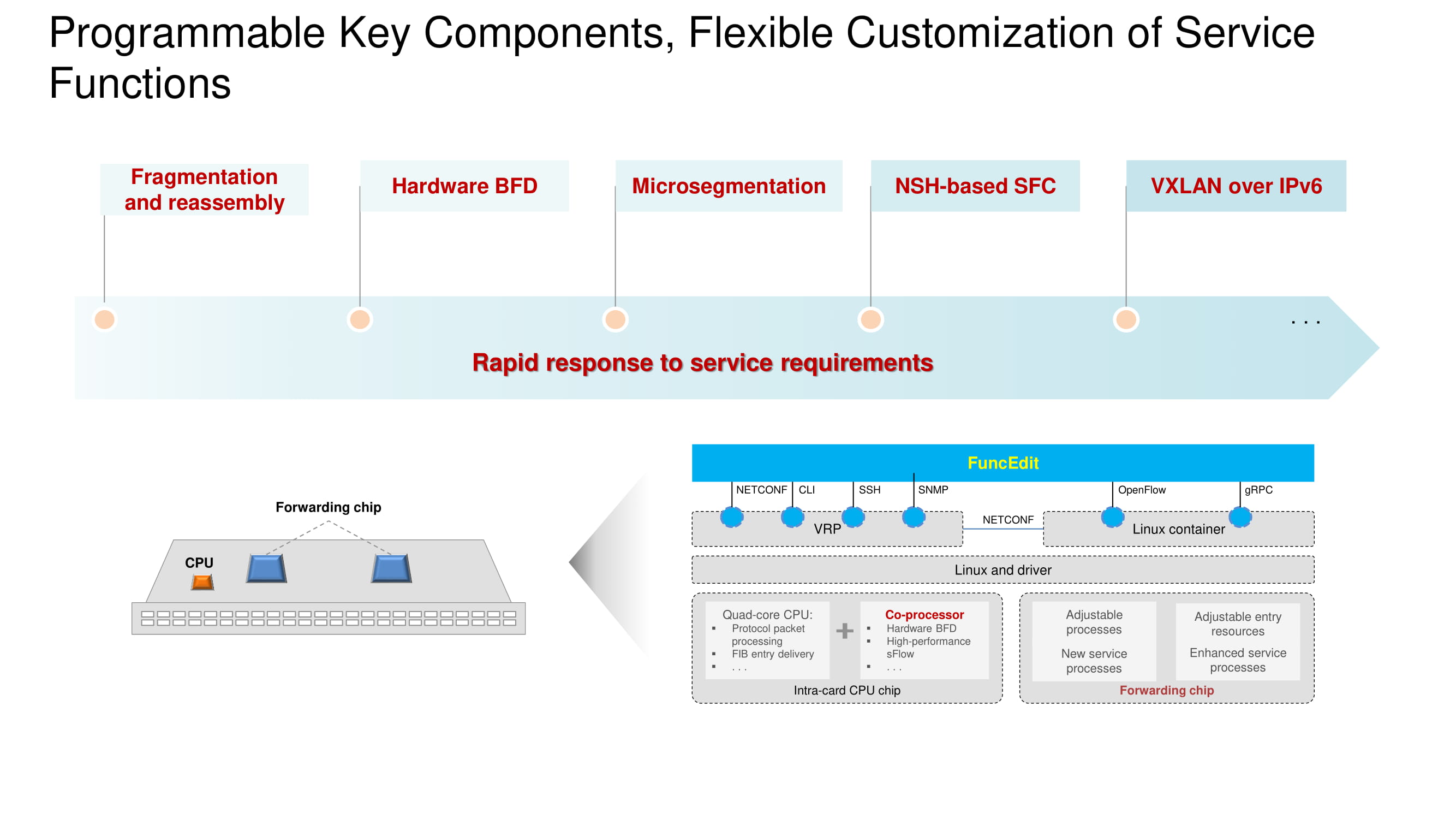
Penting bahwa protokol BFD (Deteksi Penerusan Dua Arah) adalah perangkat keras yang diimplementasikan pada model sakelar baru dan dimungkinkan untuk mengkonfigurasi VXLAN di ruang alamat IPv6. Arsitektur dasarnya tetap sama dan didasarkan pada prosesor, koprosesor, dan chip penerusan. Fungsionalitas masing-masing node ditunjukkan pada diagram. Perubahan utama pada tahun 2020 adalah transisi ke chip Huawei sendiri di switch andalan, yang sepenuhnya bersaing dengan rekan-rekan mereka dari Broadcom.
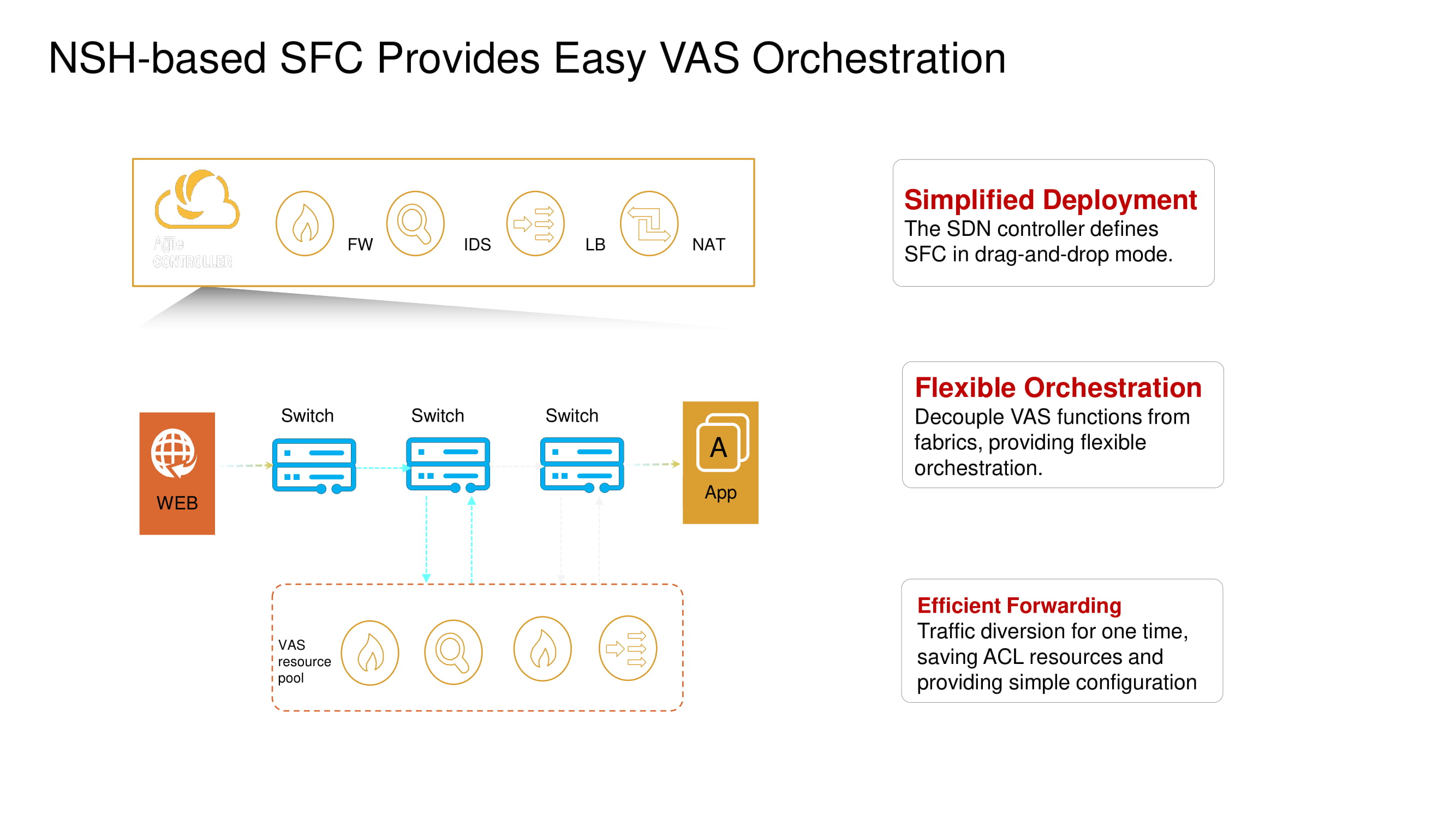
Dukungan untuk operasi Network Service Header memungkinkan sakelar baru untuk mengubah rute paket VXLAN default dan mengaktifkan layanan seperti firewall (FW), sistem deteksi intrusi (IDS), penyeimbang beban (SLB), dan NAT.
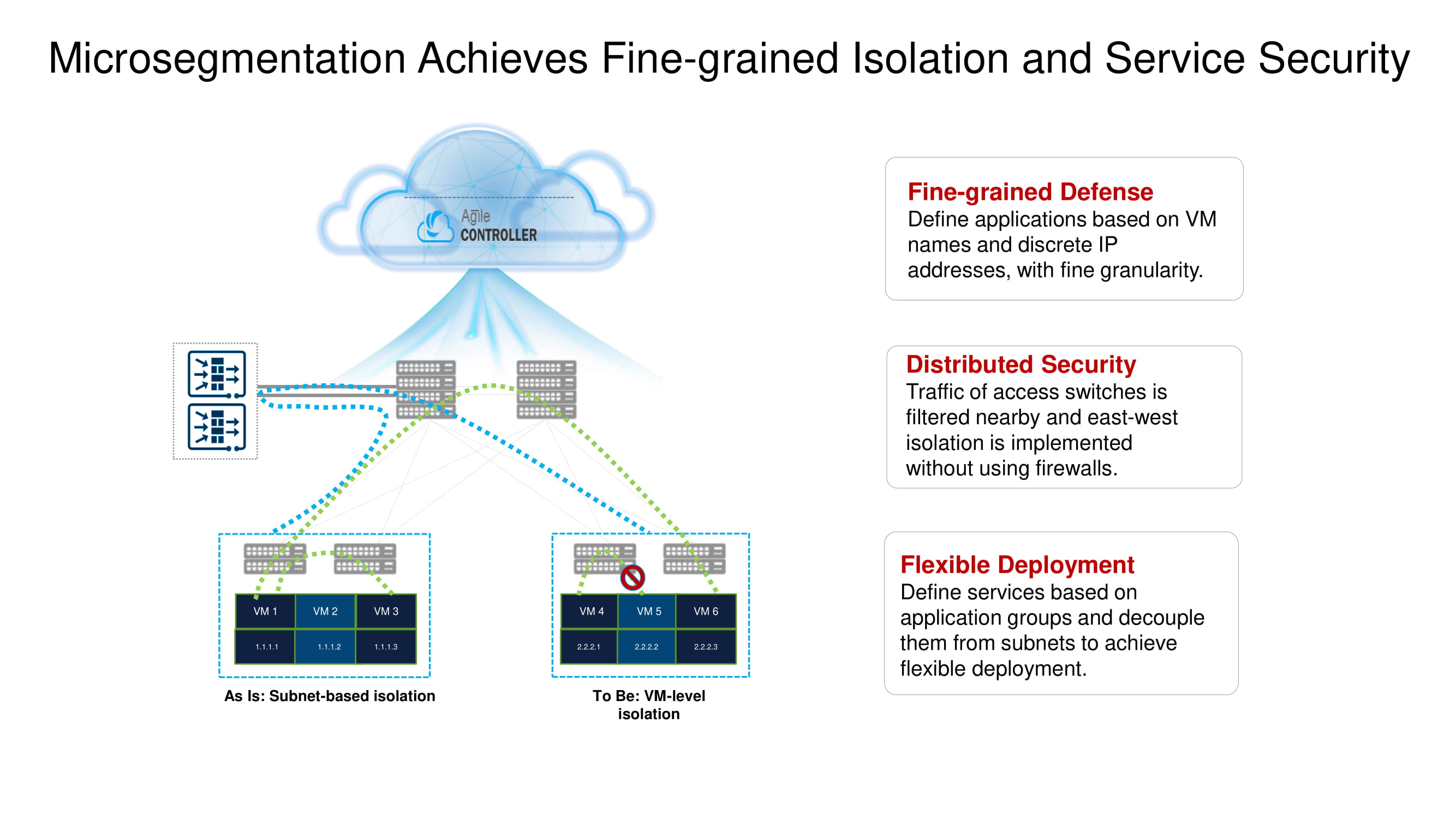
Mari kita kembali secara singkat ke mikro-segmentasi split yang disebutkan sebelumnya. Sakelar ToR Huawei baru dengan bantuan NSH yang sama memungkinkan Anda mengisolasi beban kerja di tingkat nama mesin virtual. Mesin ini selanjutnya dapat dikelompokkan pada level subnet berdasarkan nomor port, protokol superior, dll., Sehingga membentuk grup aplikasi.
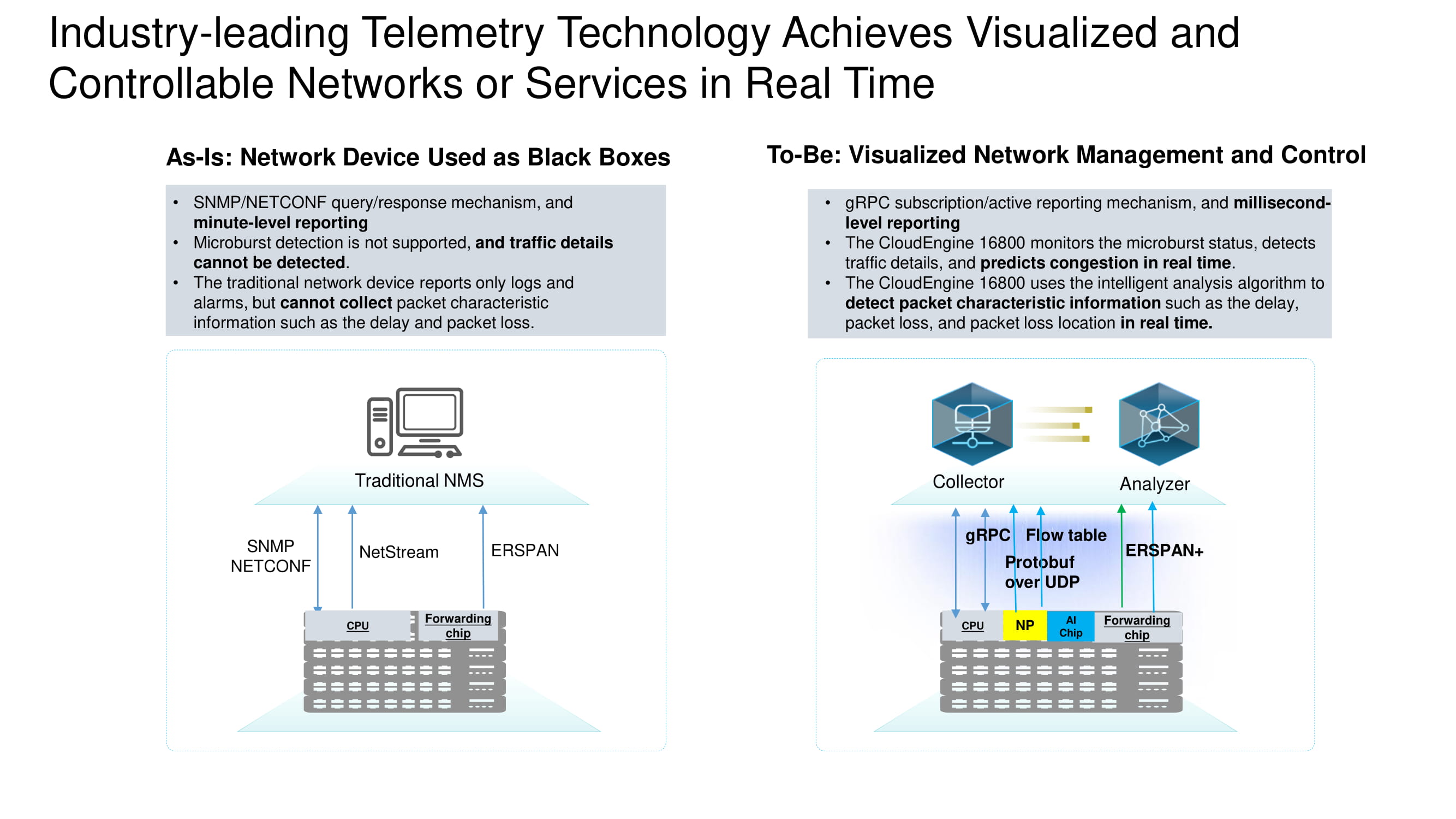
Berbagai macam data telemetri
Informasi dari perangkat dikumpulkan secara real time menggunakan beberapa protokol utama. Tugas ERSPAN + adalah mengumpulkan header TCP untuk analisis mendetail berikutnya dari aliran TCP di pusat data. Data tambahan ditambang menggunakan protokol gRPC dan tabel alur. Semua ini dikumpulkan dengan Protobuf melalui UDP.
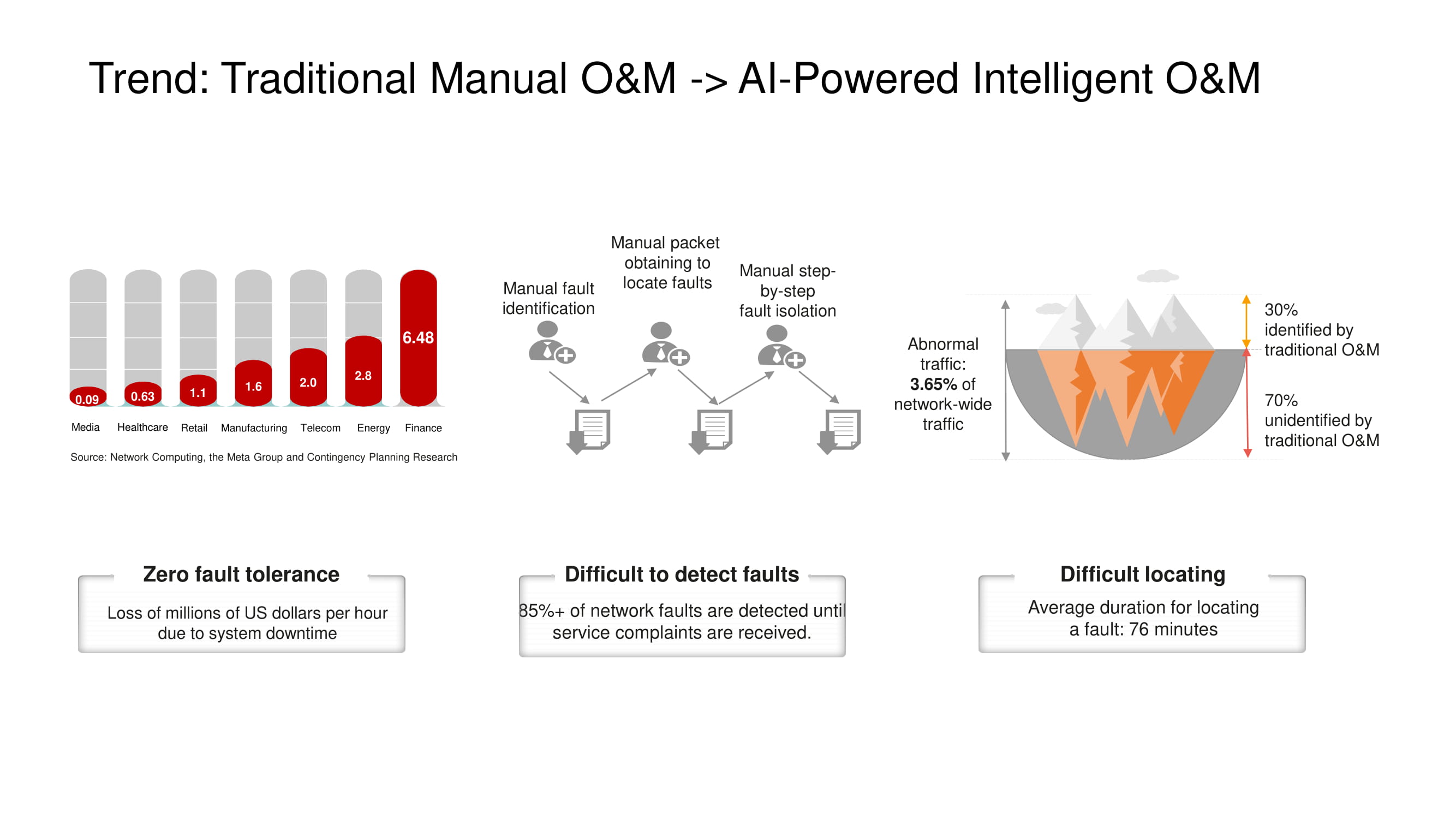
Arah utama pengembangan alat O&M di Huawei adalah transisi dari kontrol jaringan manual atau semi-otomatis ke otomatis penuh , berdasarkan teknologi kecerdasan buatan. Sistem telemetri yang mencakup semua dari situs yang cukup besar menghasilkan data dalam jumlah besar, yang analisisnya dalam waktu singkat hanya dapat dilakukan dengan penggunaan AI. Hal ini sangat penting di pusat data tersebut, di mana kegagalan dan waktu henti tidak dapat diterima.
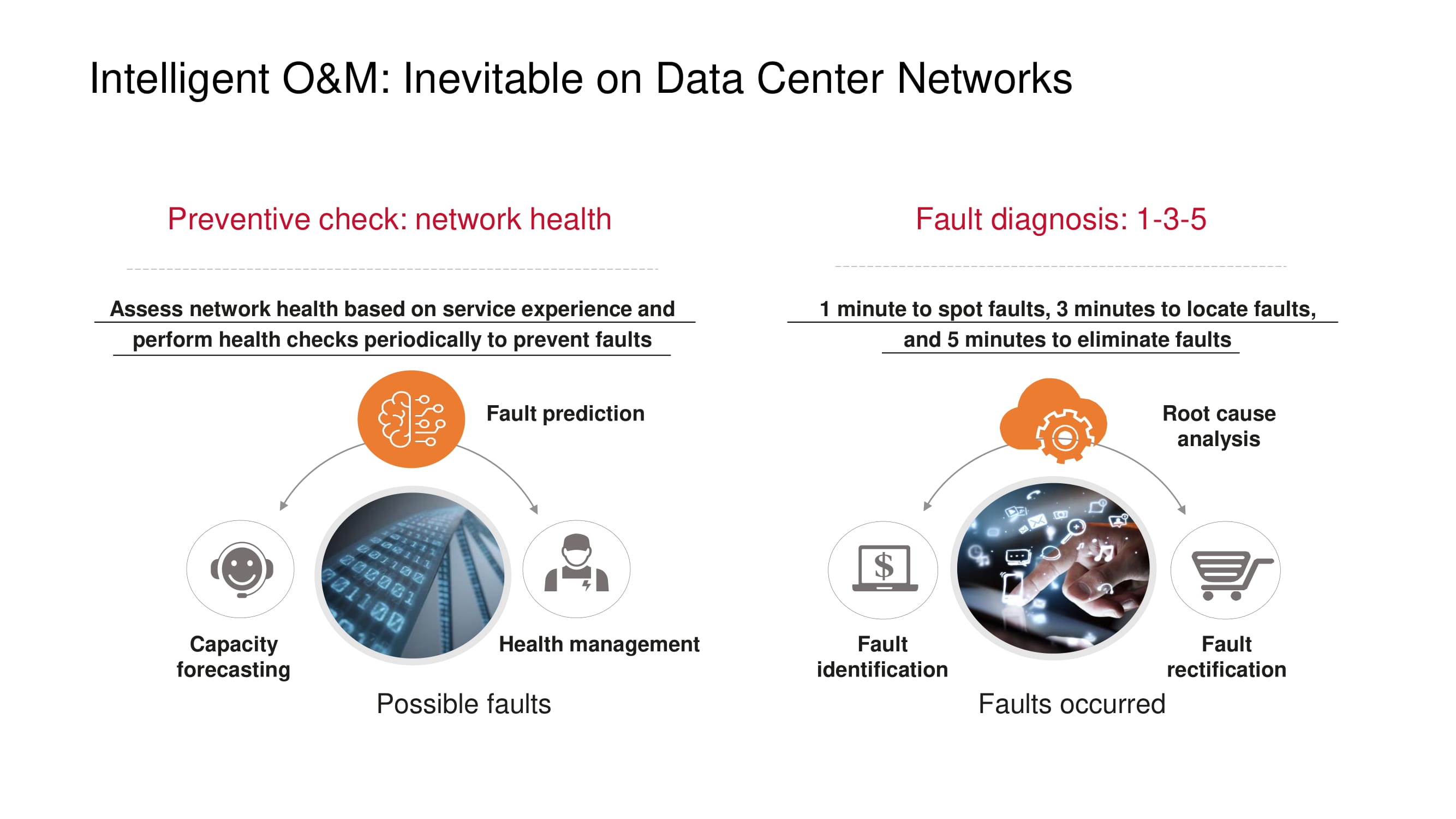
Langkah-langkah pencegahan yang dirancang untuk mencegah masalah dengan jaringan, pertama-tama, termasuk memantau "kesehatan" jaringan: memantau beban saluran, mengidentifikasi alasan kehilangan paket (misalnya, mencari korelasi dengan waktu atau periode operasi aplikasi), mendeteksi " kemacetan (perkiraan kapasitas), dll.
Jika masalah masih terlihat, prinsip 1-3-5 yang dikemukakan oleh Huawei membantu meminimalkan waktu diagnostik dan pemulihan: satu menit untuk mencari, tiga menit untuk melokalkan, lima menit untuk menghilangkan masalah. Untuk mempertahankan kerangka kerja ini, produk Huawei mendukung daftar kesalahan tipikal yang terus bertambah yang terdeteksi secara otomatis.

Model V100R019C10 untuk pusat data kecil
Salah satu inovasi utama di V100R019C10 adalah dukungan visualisasi berbasis data telemetri di semua jenis skenario. Faktanya, kita berbicara tentang tampilan visual dari setiap perubahan dalam jaringan. Selain itu, perangkat sekarang dapat menentukan lebih dari 75 akar penyebab masalah tertentu dan membantu menguraikan tindakan untuk menghilangkannya (meluncurkan skrip, dll.).
Berita penting adalah munculnya versi Standalone, yang menyertakan iMaster NCE dan FabricInsight, dan ditujukan terutama untuk pusat data kecil yang tidak memerlukan banyak server untuk mengelola jaringan.
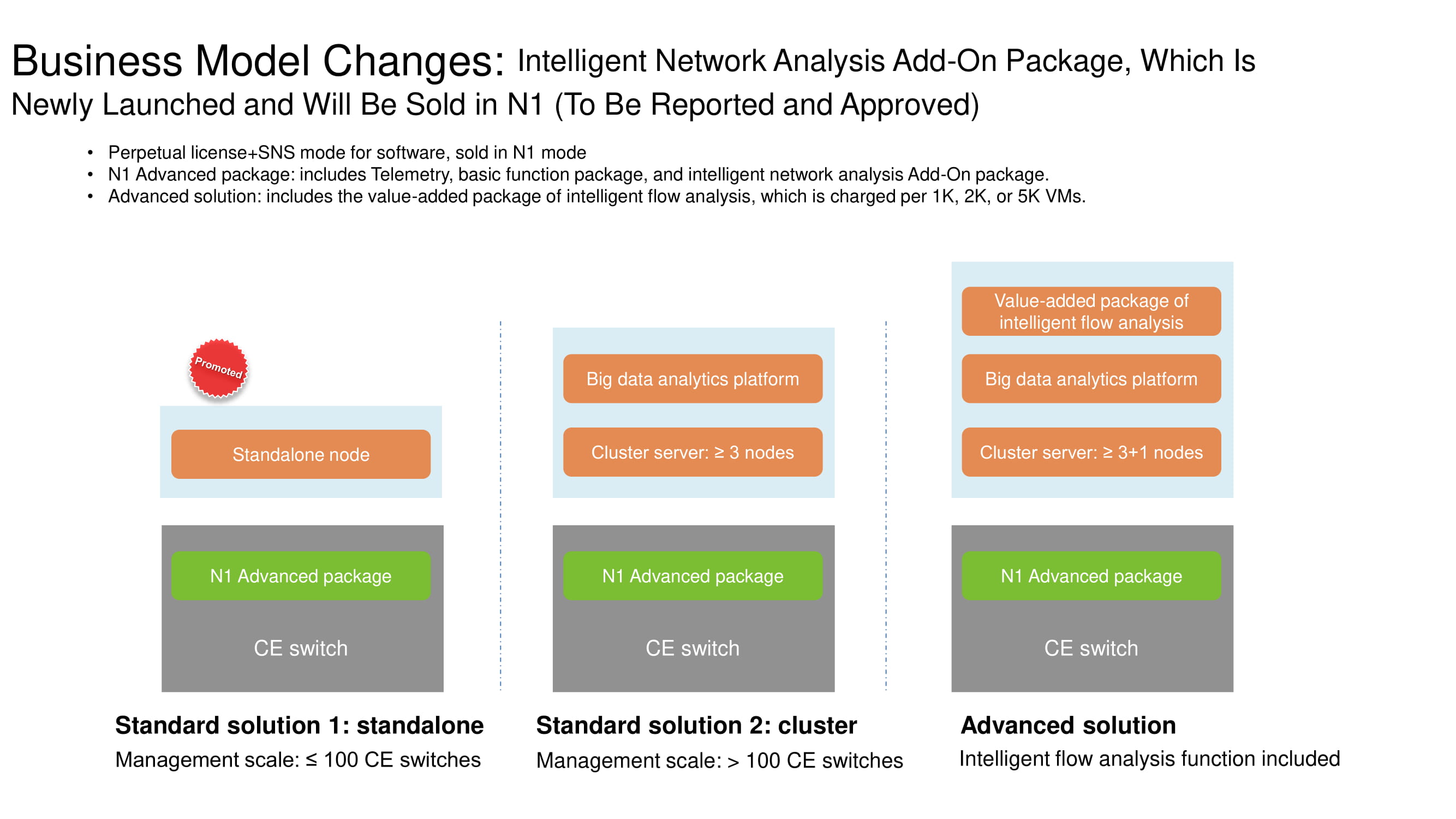
Perubahan dalam sistem perizinan
Untuk pemahaman yang lebih baik tentang fitur fungsional FabricInsight, harus dijelaskan perubahan apa yang telah terjadi dalam model bisnis untuk distribusi produk jaringan Huawei. Jika jumlah sakelar tidak mencapai seratus, opsi ini diklasifikasikan sebagai edisi mandiri dan menyiratkan lisensi N1. Sekelompok tiga atau lebih server sudah dibundel dengan platform analitik data besar. Solusi Lanjutan, yang mencakup beberapa ratus sakelar, direkomendasikan untuk digunakan bersama dengan alat untuk menganalisis aliran jaringan. Ketiga opsi memungkinkan fitur FabricInsight dengan lisensi N1.
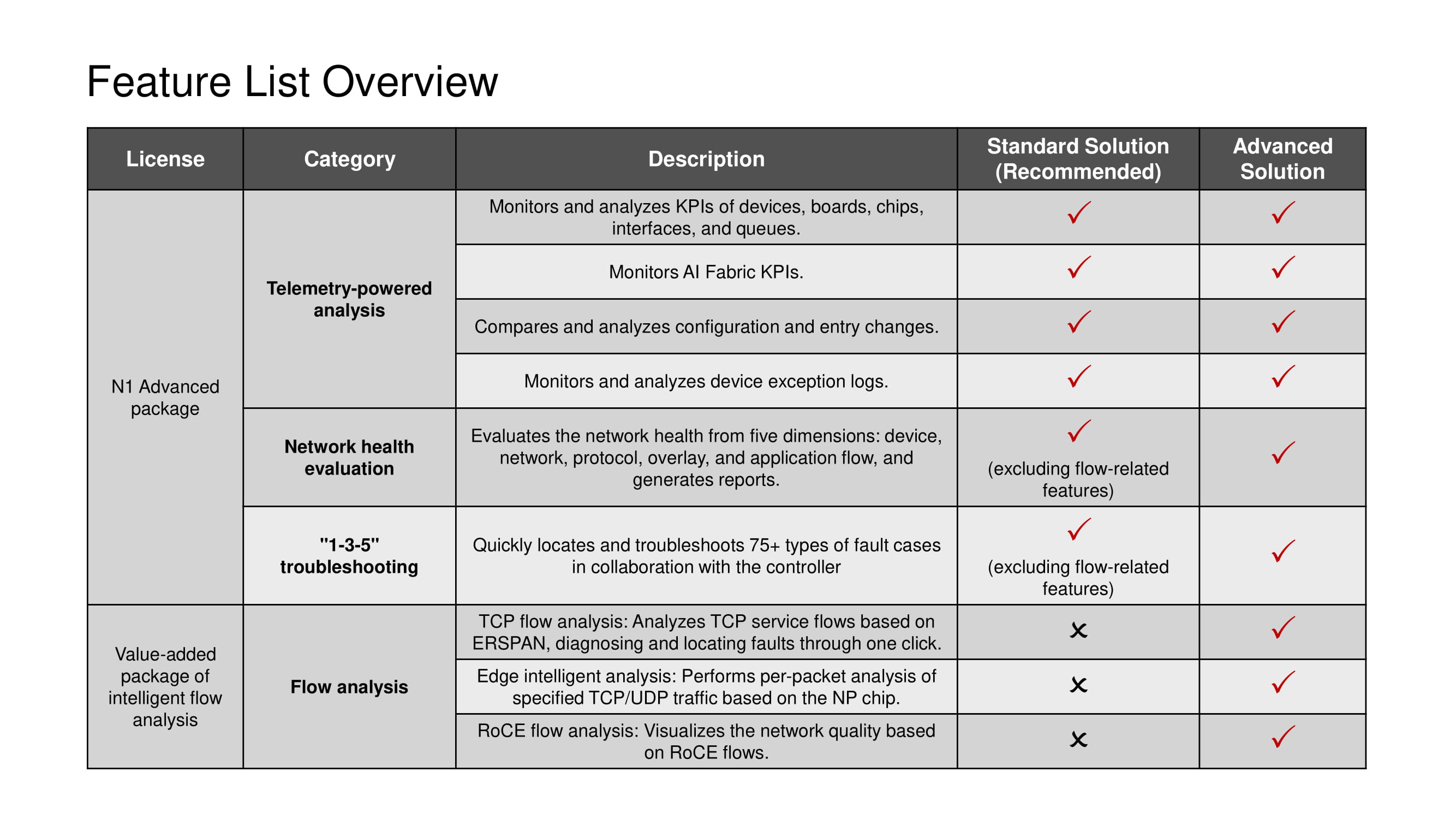
Lisensi apa pun menyiratkan penggunaan seluruh rangkaian alat telemetri dan skenario 1-3-5, dengan pengecualian alat analisis aliran TCP yang hanya tersedia dalam solusi Lanjutan.
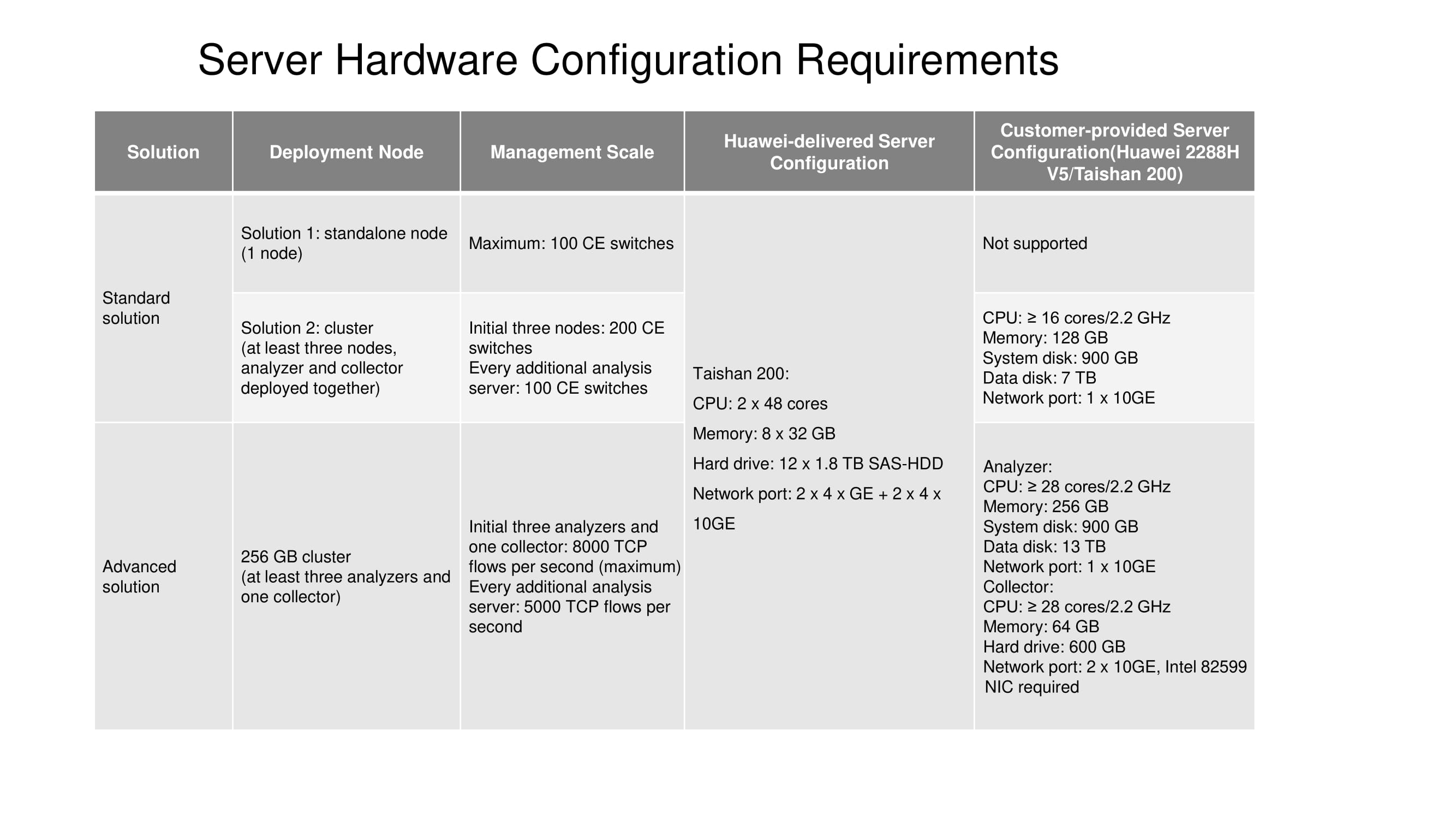
Ini tetap memberi tahu Anda tentang konfigurasi server yang dirancang untuk solusi Standar dan Lanjutan. Saat ini, node mandiri (satu node) hanya tersedia di server Taishan 200. Cluster tiga node memerlukan 16 core komputasi atau lebih, RAM 128 GB, dll. (Lihat diagram). Ukuran disk data secara langsung bergantung pada berapa lama statistik harus disimpan.

Pemantauan KPI
Mari kita lihat lebih dekat pemantauan KPI. Untuk menggunakannya, cukup dengan mengatur interval waktu dan nilai ambang tertentu, yang pencapaiannya akan diperiksa berdasarkan data telemetri yang diterima. Ada banyak jenis metrik yang tersedia, termasuk:
- Penggunaan CPU dan memori;
- penggunaan FIB / MAC;
- penggunaan memori asosiatif terner (TCAM) dari chip;
- parameter port;
- ukuran buffer untuk antrian;
- metrik AI Fabric yang berbeda;
- tingkat sinyal, suhu dan parameter lain dari modul optik;
- kehilangan paket.
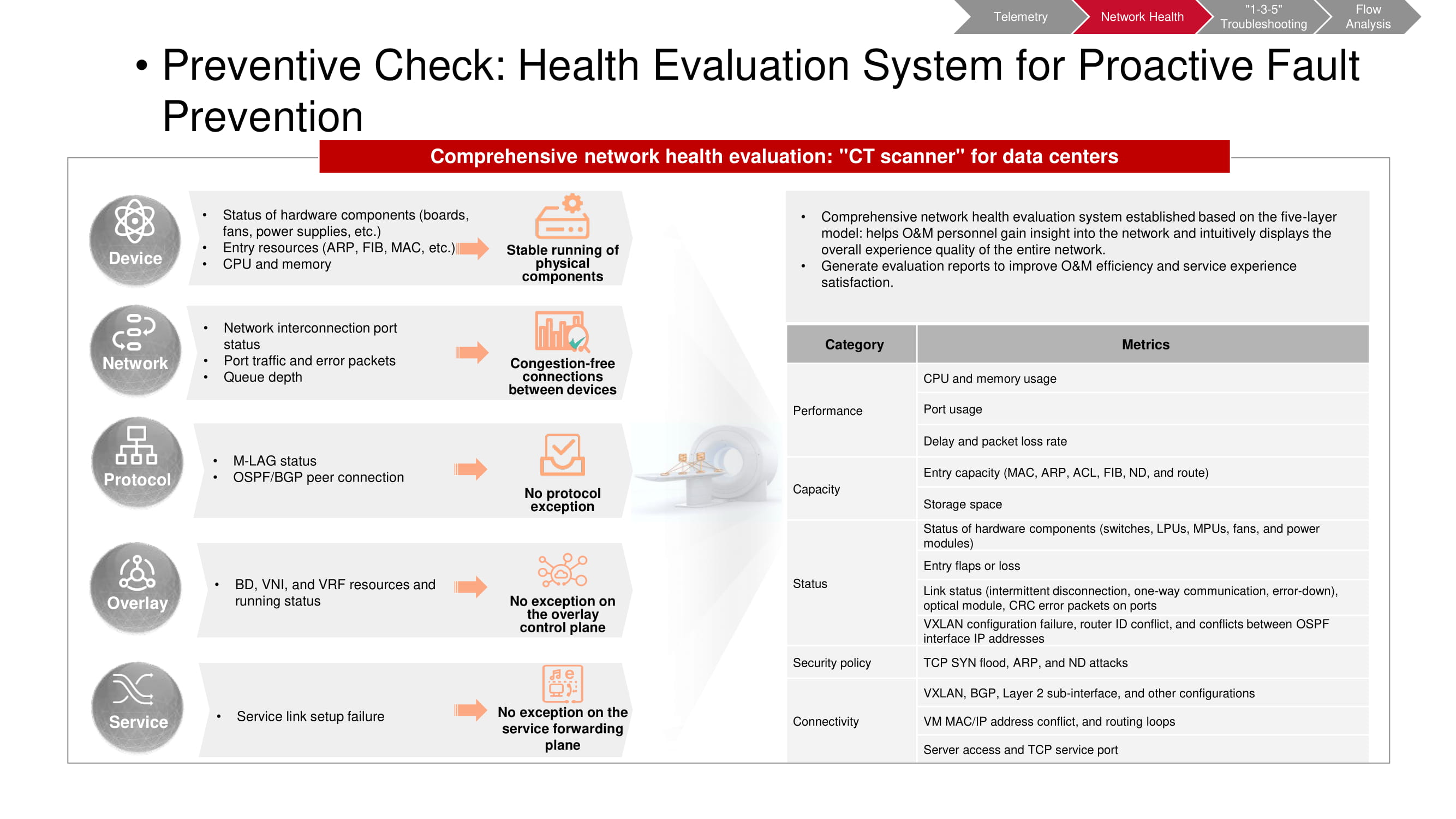
Pemeriksaan pendahuluan
Alat pra-periksa juga beroperasi pada data telemetri. Pemindai CT memungkinkan Anda untuk memahami apakah peristiwa tertentu yang tidak diinginkan telah terjadi di jaringan. Beberapa metrik sesuai dengan metrik pemantauan KPI dari "pabrik" (terutama terkait dengan kapasitas dan kinerja). Sisanya didasarkan pada hasil analisis tingkat atas (VXLAN, BGP, dll.) Dan analisis konfigurasi. Setelah memulai pemindai CT, ia mengumpulkan informasi yang diperlukan dan menghasilkan laporan komprehensif tentang status jaringan.
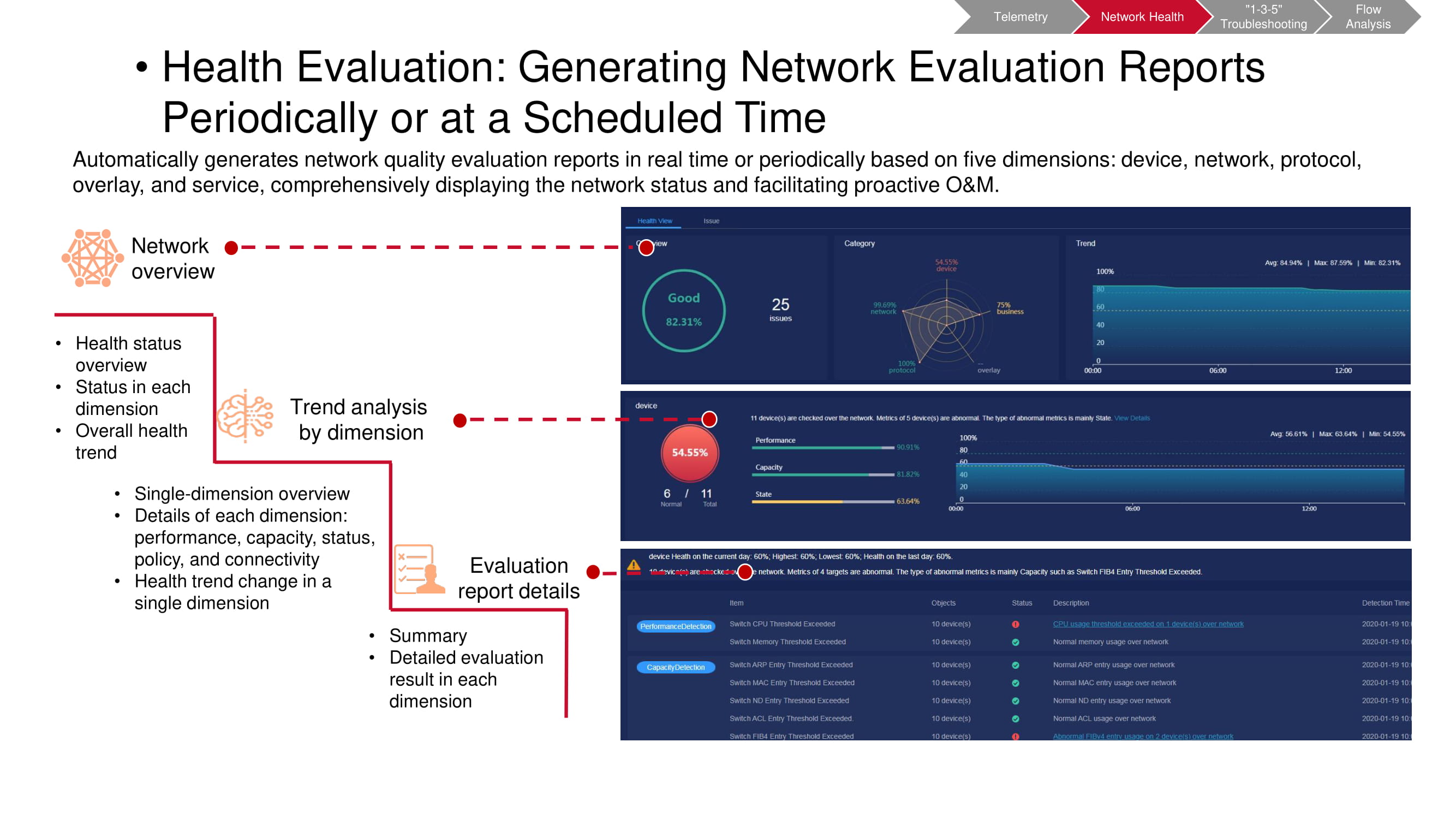
Diperlukan untuk melakukan pemeriksaan semacam itu secara teratur, setelah interval waktu yang ditentukan sebelumnya. Hal ini mempermudah untuk melihat tren yang muncul di jaringan tepat waktu, termasuk perubahan periodik dan non-periodik. Ini memungkinkan Anda untuk memahami dengan lebih lengkap dan cepat apa yang sebenarnya terjadi. Selain itu, setiap parameter yang diminati dapat dipilih untuk pemantauan yang lebih rinci.
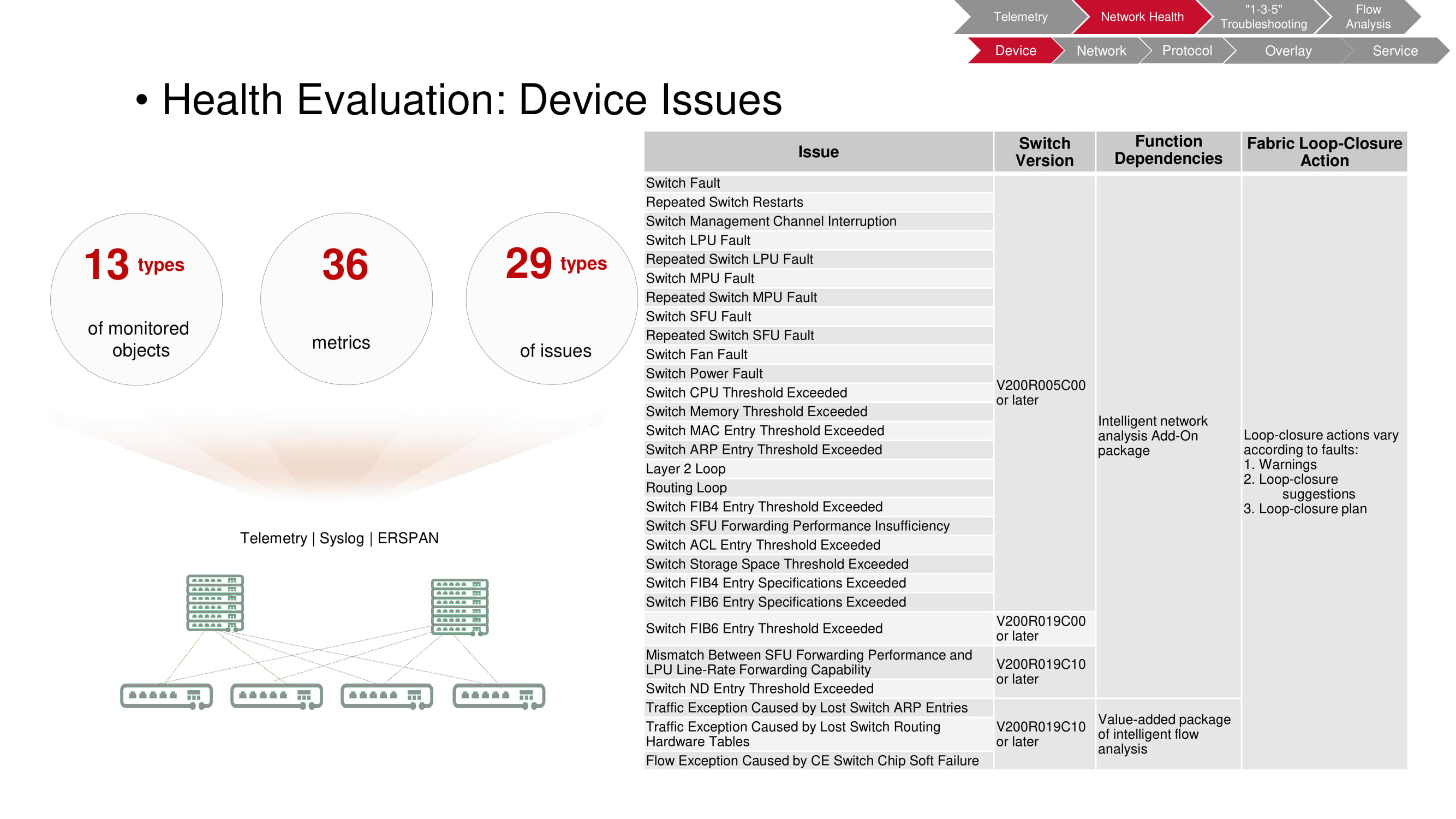
Masalah perangkat
Pemantauan memungkinkan Anda mengidentifikasi berbagai macam masalah yang muncul di tingkat perangkat. Dalam hal ini, objek verifikasi adalah sakelar, 36 parameter terdaftar yang memungkinkan untuk mendeteksi 29 jenis kesalahan.
Tabel pada diagram mencantumkan jenis kesalahan; ganti model yang memungkinkan FabricInsight mendeteksi masalah; fungsi yang digunakan oleh FabricInsight; tindakan otomatis diambil ketika masalah terdeteksi (peringatan, rekomendasi, peluncuran skrip).
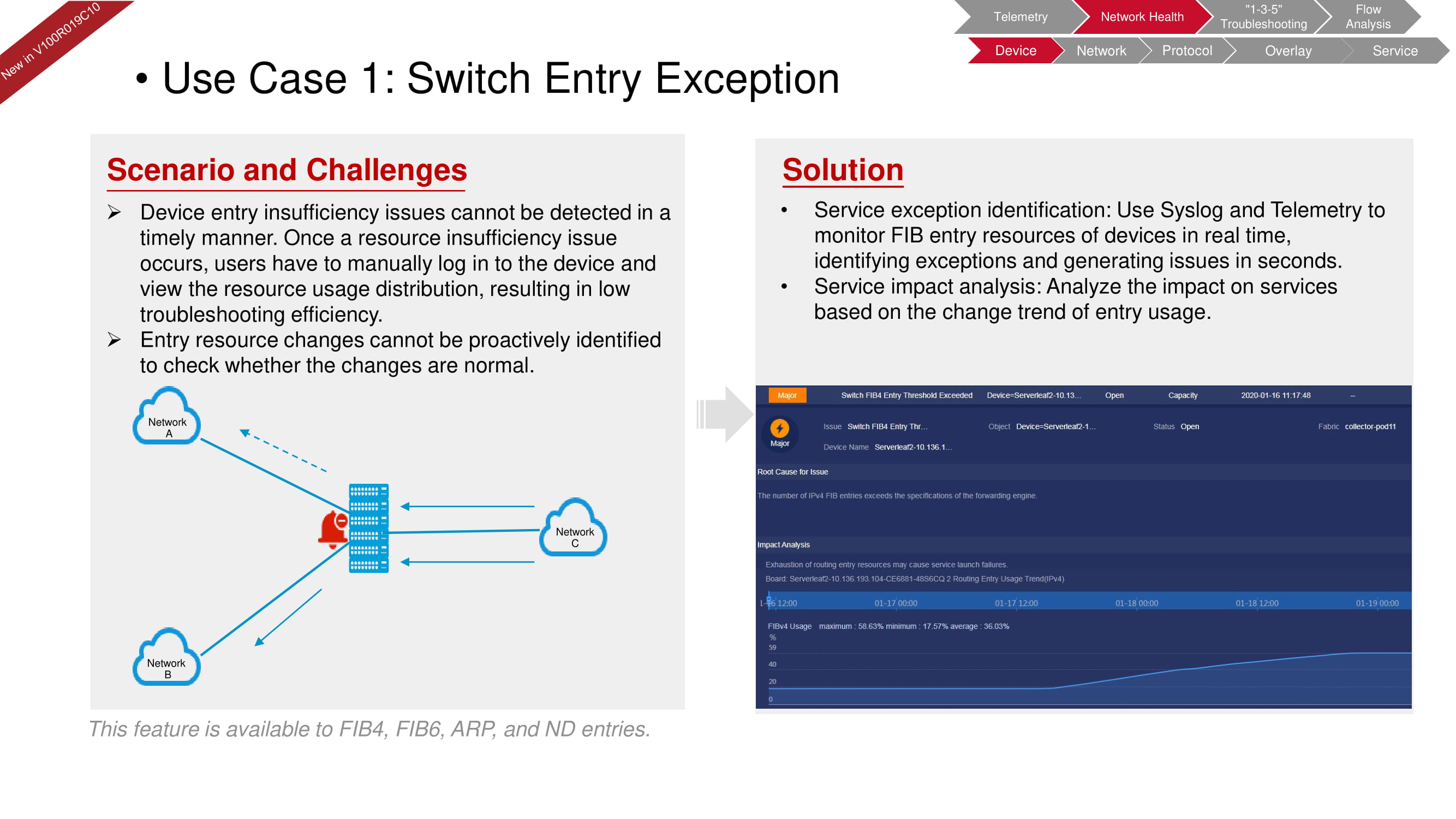
Misalkan perangkat memiliki kekurangan sumber daya yang menyebabkan penurunan tingkat layanan. Data dari log sistem, dikombinasikan dengan data telemetri sumber daya FIB, memungkinkan Anda menilai situasi dengan cepat dalam mode pemeriksaan manual.
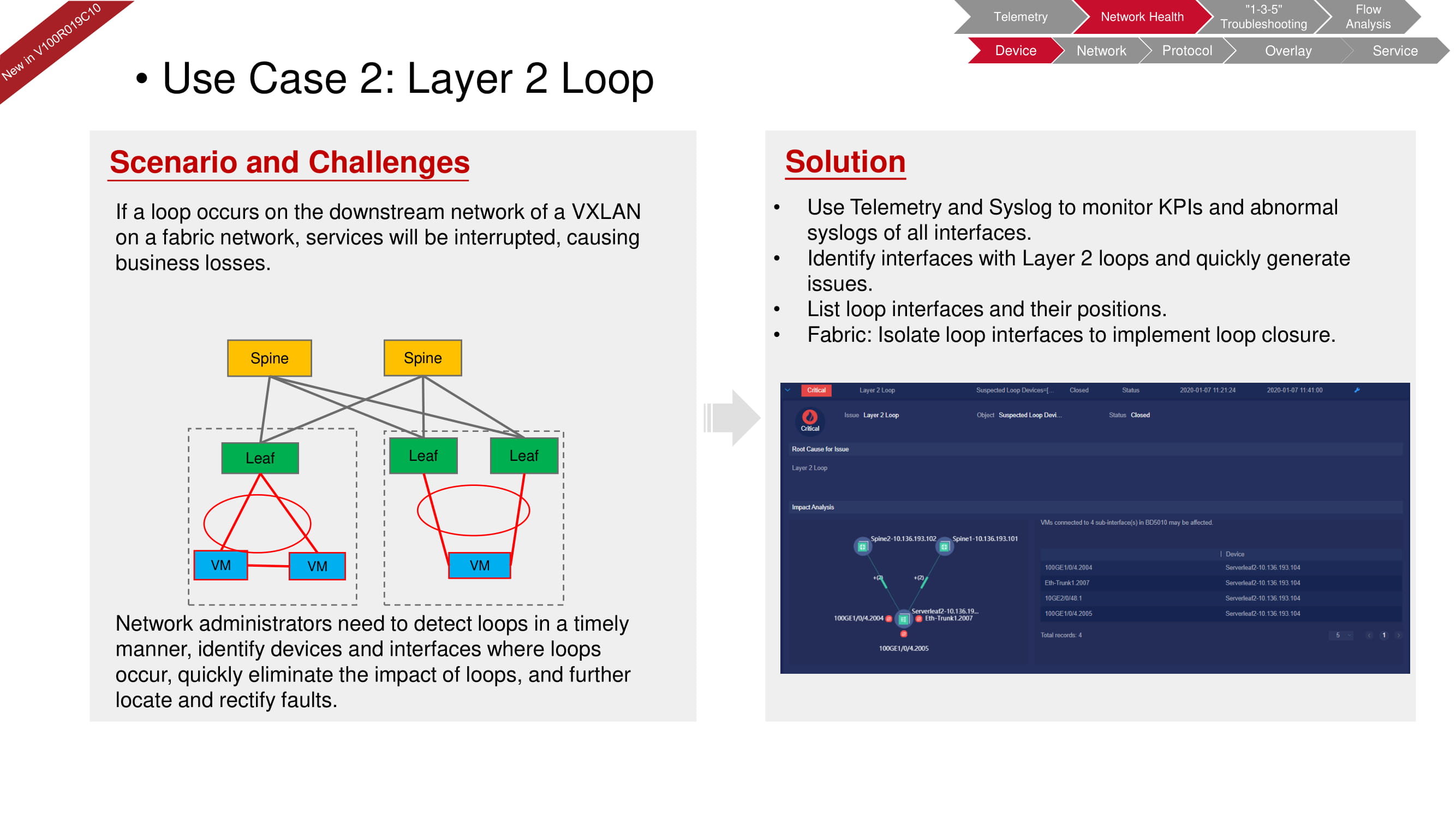
Tidak mungkin terjadi loop pada tingkat perangkat keras, karena perangkat tidak akan mengizinkan kesalahan seperti itu dimasukkan ke dalam konfigurasi. Namun, loop dapat terjadi, misalnya, pada level kedua (pada level mesin virtual) karena sakelar perangkat lunak yang tidak dikonfigurasi dengan benar, seperti pada diagram di atas. Dengan FabricInsight, Anda tidak hanya dapat mendeteksi masalah, tetapi juga mengisolasi bagian jaringan yang diinginkan untuk menghilangkan dampaknya pada fungsi seluruh "fabric".

Masalah jaringan
Berdasarkan 18 metrik yang tersedia untuk analisis, FabricInsight mengidentifikasi 10 jenis masalah jaringan. Diagram ini memberikan daftar lengkapnya, serta - jika ada masalah perangkat - model sakelar yang memungkinkan FabricInsight mendeteksi masalah, fungsi yang digunakan, dan tindakan otomatis yang tersedia.

Misalkan degradasi atau kerusakan modul optik menyebabkan penurunan kinerjanya: tautan menjadi tidak stabil. Situasi ini terjadi secara tidak teratur dan sulit untuk direproduksi. Ini bisa memakan waktu lama untuk menemukan masalahnya. Dengan FabricInsight, Anda dapat segera melihat penurunan level sinyal atau perubahan voltase di seluruh modul.
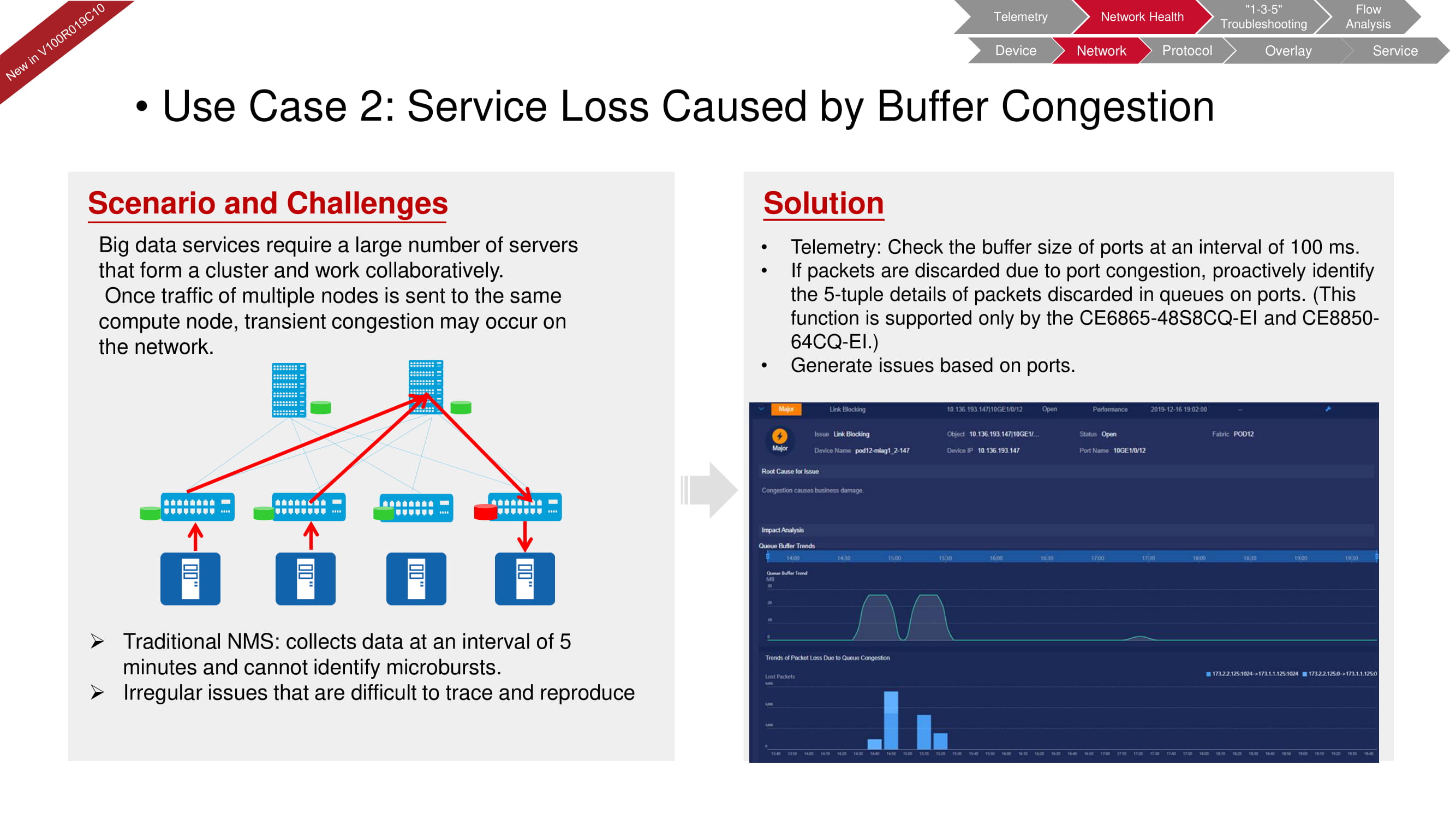
Diagnostik jaringan fabricInsight juga dapat segera mengidentifikasi masalah buffer yang sering terjadi di sistem dengan sejumlah besar server yang didedikasikan untuk pemrosesan data besar. NMS tradisional (Sistem Manajemen Jaringan) memeriksa parameter terkait buffer setiap lima menit. Kemampuan telemetri FabricInsight dapat mengurangi interval ini hingga 100 md dan mendeteksi insiden mikro terpendek sekalipun.

Masalah di tingkat protokol
Di sini FabricInsight dapat mengidentifikasi enam jenis masalah, termasuk konflik antara dua sakelar utama di M-LAG; masalah dengan interaksi sakelar tetangga, dll. Fungsionalitas ini tersedia saat menggunakan sakelar V200R005C00 dan yang lebih baru.

Pertimbangkan konflik sakelar utama. Dengan semua keunggulan teknologi M-LAG, jika terjadi kerusakan tautan dan kegagalan jaringan peer-to-peer, dua sakelar utama muncul di sistem. FabricInsight dapat secara proaktif menanggapi situasi seperti itu dengan terus memantau status peer-link dan DFS.

Masalah jaringan overlay
Tujuh jenis masalah jaringan overlay dapat diidentifikasi dengan memantau sepuluh metrik yang berbeda. FabricInsight dapat memeriksa status lisensi VXLAN, menemukan kesalahan konfigurasi, mendeteksi kerusakan sub-antarmuka, dll. Opsi respons mirip dengan yang dijelaskan sebelumnya.

Masalah layanan
Tujuh metrik dipantau untuk mengidentifikasi enam jenis masalah tingkat layanan. Konflik alamat IP, masalah koneksi, serangan banjir TCP SYN, dll. Dapat dideteksi. Harap diperhatikan bahwa untuk mendukung kapabilitas FabricInsight ini, Anda mungkin memerlukan penganalisis aliran TCP.
Melihat pemecahan masalah yang lebih luas, FabricInsight lebih dari sekadar kolektor perangkat, tetapi pustaka skrip yang dapat diperluas yang menangani berbagai jenis masalah.

Dari otomatisasi ke otonomi
Sebagai ringkasan, katakanlah ideologi Intent-Driven Network didasarkan pada model respons tiga tahap, yang mencakup pengumpulan informasi, analisisnya menggunakan AI, dan proposal untuk mengubah status jaringan, termasuk dalam mode otomatis.
***
Kami mengingatkan Anda bahwa para ahli kami secara teratur menyelenggarakan webinar tentang produk Huawei dan teknologi yang mereka gunakan. Daftar webinar untuk beberapa minggu mendatang tersedia di sini .