
Saya harus mengatakan segera: Saya bukan spesialis TI, tetapi seorang penggemar di bidang statistik. Selain itu, saya telah berpartisipasi dalam berbagai kompetisi prediksi Formula 1 selama bertahun-tahun. Karenanya tugas-tugas yang dihadapi model saya: untuk mengeluarkan perkiraan yang tidak akan lebih buruk daripada yang dibuat "oleh mata". Dan idealnya, model itu, tentu saja, harus mengalahkan lawan manusia.
Model ini hanya berfokus pada memprediksi hasil kualifikasi, karena kualifikasi lebih dapat diprediksi daripada ras dan lebih mudah untuk dimodelkan. Namun, tentu saja, di masa depan saya berencana untuk membuat model yang memungkinkan memprediksi hasil balapan dengan akurasi yang cukup baik.
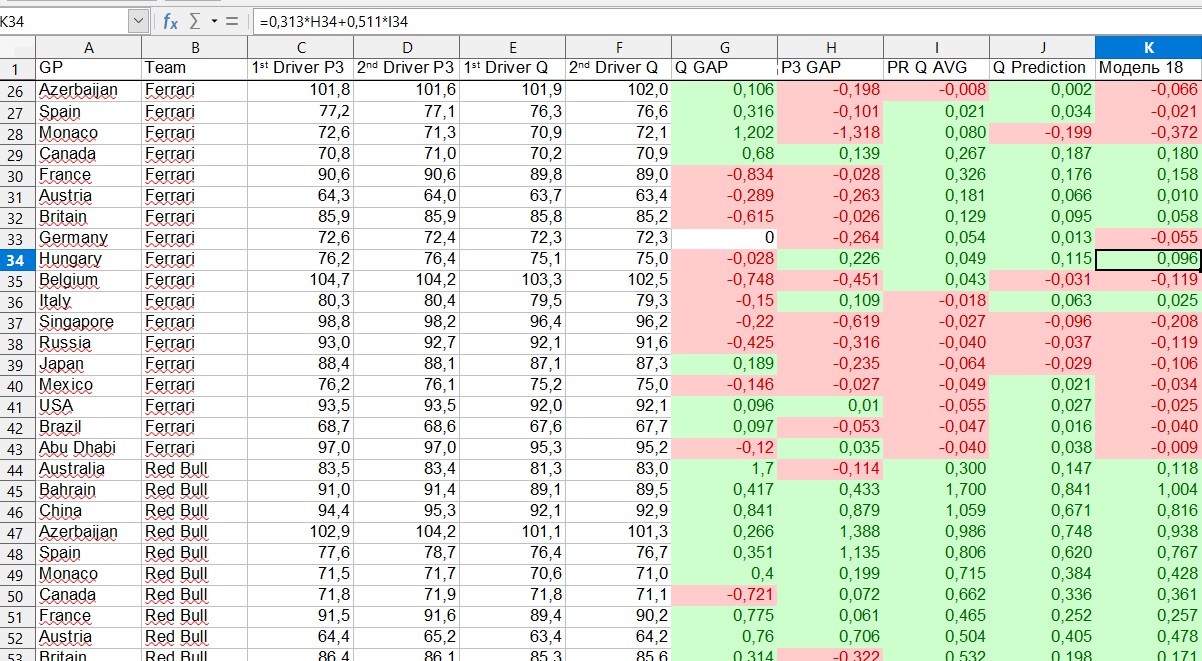
Untuk membuat model, saya merangkum semua hasil praktik dan kualifikasi untuk musim 2018 dan 2019 dalam satu tabel, 2018 dijadikan sebagai sampel pelatihan, dan 2019 sebagai sampel uji. Berdasarkan data ini, kami membangun regresi linier . Untuk menempatkan regresi sesederhana mungkin, data kami adalah kumpulan poin pada bidang koordinat. Kami telah menarik garis lurus yang menyimpang paling sedikit dari totalitas poin-poin ini. Dan fungsinya, grafik yang merupakan garis ini - ini adalah regresi linier kami.
Dari rumus itu diketahui dari kurikulum sekolahfungsi kita hanya dibedakan oleh fakta bahwa kita memiliki dua variabel. Variabel pertama (X1) adalah kelambanan dalam praktik ketiga, dan variabel kedua (X2) adalah kelambanan rata-rata dalam kualifikasi sebelumnya. Variabel-variabel ini tidak setara, dan salah satu tujuan kami adalah untuk menentukan bobot masing-masing variabel dalam rentang dari 0 hingga 1. Semakin jauh suatu variabel dari nol, semakin penting dalam menjelaskan variabel dependen. Dalam kasus kami, variabel dependen adalah waktu putaran, dinyatakan dalam lag di belakang pemimpin (atau, lebih tepatnya, dari "lingkaran ideal" tertentu, karena nilai ini positif untuk semua pilot).
Penggemar buku Moneyball (yang tidak dijelaskan dalam film) dapat mengingat bahwa dengan menggunakan regresi linier, mereka menentukan bahwa persentase basis, alias OBP (persentase dasar), lebih erat terkait dengan luka yang diperoleh daripada statistik lainnya. Tujuan kami kira-kira sama: untuk memahami faktor-faktor mana yang paling terkait dengan hasil kualifikasi. Salah satu keuntungan besar dari regresi adalah tidak membutuhkan pengetahuan matematika yang canggih: kita hanya memasukkan data, dan kemudian Excel atau editor spreadsheet lain memberi kita koefisien yang sudah jadi.
Pada dasarnya, kami ingin mengetahui dua hal dengan regresi linier. Pertama, sejauh mana variabel independen yang kami pilih menjelaskan perubahan fungsi. Dan kedua, seberapa penting masing-masing variabel independen ini. Dengan kata lain, apa yang lebih baik menjelaskan hasil kualifikasi: hasil balapan di trek sebelumnya atau hasil sesi pelatihan di trek yang sama.
Poin penting harus diperhatikan di sini. Hasil akhirnya adalah jumlah dari dua parameter independen, yang masing-masing dihasilkan dari dua regresi independen. Parameter pertama adalah kekuatan tim pada tahap ini, lebih tepatnya, lag pilot terbaik tim dari pemimpin. Parameter kedua adalah distribusi kekuatan dalam tim.
Apa artinya ini dengan contoh? Katakanlah kita mengambil Grand Prix Hongaria 2019. Model ini menunjukkan bahwa Ferrari akan berada 0,218 detik di belakang pemimpin. Tapi ini lag dari pilot pertama, dan siapa mereka - Vettel atau Leclair - dan berapa jarak di antara mereka, ditentukan oleh parameter lain. Dalam contoh ini, model menunjukkan bahwa Vettel akan berada di depan, dan Leclair akan kehilangan 0,096 detik untuknya.
Mengapa kesulitan seperti itu? Bukankah lebih mudah untuk mempertimbangkan setiap pilot secara terpisah alih-alih uraian ini menjadi kelambanan tim dan kelambanan pilot pertama dari yang kedua dalam tim? Mungkin memang demikian, tetapi pengamatan pribadi saya menunjukkan bahwa jauh lebih dapat diandalkan untuk melihat hasil tim daripada hasil setiap pilot. Satu pilot dapat membuat kesalahan, atau terbang keluar jalur, atau dia akan memiliki masalah teknis - semua ini akan membawa kekacauan pada model, kecuali jika Anda secara manual melacak setiap situasi force majeure, yang membutuhkan terlalu banyak waktu. Pengaruh force majeure pada hasil tim jauh lebih sedikit.
Tetapi kembali ke titik di mana kami ingin mengevaluasi seberapa baik variabel penjelas yang kami pilih menjelaskan perubahan fungsi. Ini dapat dilakukan dengan menggunakan koefisien determinasi. Ini akan menunjukkan sejauh mana hasil kualifikasi dijelaskan oleh hasil magang dan kualifikasi sebelumnya.
Karena kami membangun dua regresi, kami juga memiliki dua koefisien determinasi. Regresi pertama bertanggung jawab untuk tingkat tim di panggung, yang kedua untuk konfrontasi antara pilot dari tim yang sama. Dalam kasus pertama, koefisien determinasi adalah 0,82, yaitu, 82% dari hasil kualifikasi dijelaskan oleh faktor-faktor yang telah kami pilih, dan 18% lainnya - oleh beberapa faktor lain yang tidak kami perhitungkan. Ini hasil yang cukup bagus. Dalam kasus kedua, koefisien determinasi adalah 0,13.
Metrik ini, pada dasarnya, berarti bahwa model memprediksi tingkat tim dengan cukup baik, tetapi mengalami kesulitan menentukan kesenjangan antara rekan satu tim. Namun, untuk tujuan akhir, kita tidak perlu mengetahui kesenjangannya, kita hanya perlu tahu yang mana dari dua pilot yang akan lebih tinggi, dan model pada dasarnya mengatasi ini. Dalam 62% kasus, model peringkat lebih tinggi dari pilot yang benar-benar lebih tinggi dalam kualifikasi.
Pada saat yang sama, ketika menilai kekuatan tim, hasil dari pelatihan terakhir adalah satu setengah kali lebih penting daripada hasil kualifikasi sebelumnya, tetapi dalam duel antar tim itu adalah sebaliknya. Tren terwujud dalam data 2018 dan 2019.
Rumus akhir terlihat seperti ini:
Pilot pertama:
Pilot kedua:
Biarkan saya mengingatkan Anda bahwa X1 adalah keterlambatan dalam latihan ketiga, dan X2 adalah kelambatan rata-rata dalam kualifikasi sebelumnya.
Apa arti angka-angka ini? Mereka berarti bahwa tingkat tim dalam kualifikasi adalah 60% ditentukan oleh hasil latihan ketiga dan 40% - oleh hasil kualifikasi pada tahap sebelumnya. Dengan demikian, hasil dari latihan ketiga adalah faktor satu setengah kali lebih signifikan daripada hasil kualifikasi sebelumnya.
Penggemar Formula 1 mungkin tahu jawaban untuk pertanyaan ini, tetapi untuk sisanya, Anda harus mengomentari mengapa saya mengambil hasil latihan ketiga. Ada tiga latihan di Formula 1. Namun, pada yang terakhir inilah tim secara tradisional melatih kualifikasi. Namun, dalam kasus di mana latihan ketiga gagal karena hujan atau force majeure lainnya, saya mengambil hasil dari latihan kedua. Sejauh yang saya ingat, pada tahun 2019 hanya ada satu kasus seperti itu - di Grand Prix Jepang, ketika karena topan panggung diadakan dalam format singkat.
Juga, seseorang mungkin memperhatikan bahwa model menggunakan kelambatan rata-rata dalam kualifikasi sebelumnya. Tapi bagaimana dengan tahap pertama musim ini? Saya menggunakan lag dari tahun sebelumnya, tetapi tidak membiarkannya, tetapi secara manual menyesuaikannya berdasarkan akal sehat. Sebagai contoh, pada tahun 2019, Ferrari rata-rata lebih cepat 0,3 detik dari Red Bull. Namun, tampaknya tim Italia tidak akan memiliki keunggulan seperti tahun ini, atau mungkin mereka akan sepenuhnya ketinggalan. Karena itu, untuk tahap pertama musim 2020, Grand Prix Austria, saya secara manual membawa Red Bull lebih dekat ke Ferrari.
Dengan cara ini saya mendapatkan lag dari masing-masing pilot, memberi peringkat pilot berdasarkan lag dan mendapatkan prediksi akhir untuk kualifikasi. Penting untuk dipahami, bahwa pilot pertama dan kedua adalah konvensi murni. Kembali ke contoh dengan Vettel dan Leclair, di Grand Prix Hongaria, model menganggap Sebastian sebagai pilot pertama, tetapi pada banyak tahap lain dia lebih suka Leclair.
hasil
Seperti yang saya katakan, tugasnya adalah membuat model yang memungkinkan untuk diprediksi juga orang. Sebagai dasar, saya mengambil ramalan dan ramalan rekan satu tim saya, yang diciptakan "dengan mata", tetapi dengan studi yang cermat tentang hasil praktik dan diskusi bersama.
Sistem peringkat adalah sebagai berikut. Hanya sepuluh pilot teratas yang diperhitungkan. Untuk pukulan akurat, ramalan menerima 9 poin, untuk ketinggalan di posisi 1 6 poin, untuk ketinggalan di posisi 2 4 poin, untuk ketinggalan di posisi 3 2 poin dan untuk ketinggalan di posisi 4 - 1 poin. Artinya, jika dalam peramalan pilot berada di posisi ke-3, dan sebagai akibatnya ia mengambil posisi terdepan, maka ramalan itu mendapat 4 poin.
Dengan sistem ini, jumlah maksimum poin untuk 21 Grand Prix adalah 1890.
Peserta manusia mencetak 1056, 1048 dan 1034 poin, masing-masing.
Model mencetak 1031 poin, meskipun dengan manipulasi cahaya dari koefisien, saya juga menerima 1.045 dan 1053 poin.
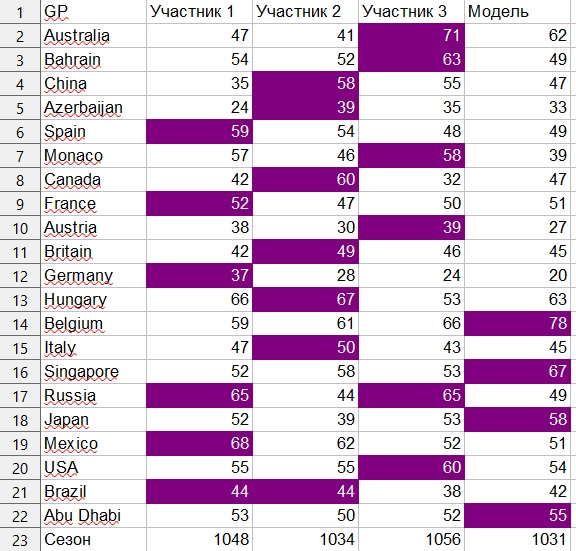
Secara pribadi, saya senang dengan hasilnya, karena ini adalah pengalaman pertama saya dalam membangun regresi, dan itu menghasilkan hasil yang cukup dapat diterima. Tentu saja, saya ingin memperbaikinya, karena saya yakin bahwa dengan bantuan model bangunan, bahkan sesederhana yang ini, Anda dapat mencapai hasil yang lebih baik daripada hanya mengevaluasi data "dengan mata". Dalam kerangka model ini, mungkin saja, misalnya, untuk memperhitungkan faktor bahwa beberapa tim lemah dalam latihan, tetapi “menembak” dalam kualifikasi. Misalnya, ada pengamatan bahwa Mercedes sering bukan tim terbaik selama pelatihan, tetapi tampil jauh lebih baik dalam kualifikasi. Namun, pengamatan manusia ini tidak tercermin dalam model. Jadi pada musim 2020, yang dimulai pada bulan Juli (jika tidak ada yang tidak terduga terjadi), saya ingin menguji model ini dalam kompetisi melawan peramal langsung dan juga menemukan,bagaimana itu bisa dibuat lebih baik.
Selain itu, saya berharap untuk beresonansi dengan komunitas penggemar Formula 1 dan percaya bahwa melalui pertukaran ide kita dapat lebih memahami apa yang merupakan hasil kualifikasi dan balapan, dan ini pada akhirnya adalah tujuan setiap orang yang membuat prediksi.