Pada X5, sistem yang akan melacak barang berlabel dan bertukar data dengan pemerintah dan pemasok disebut "Markus". Mari kita beri tahu bagaimana dan siapa yang mengembangkannya, jenis teknologi apa yang dimilikinya, dan mengapa kita memiliki sesuatu yang bisa dibanggakan.
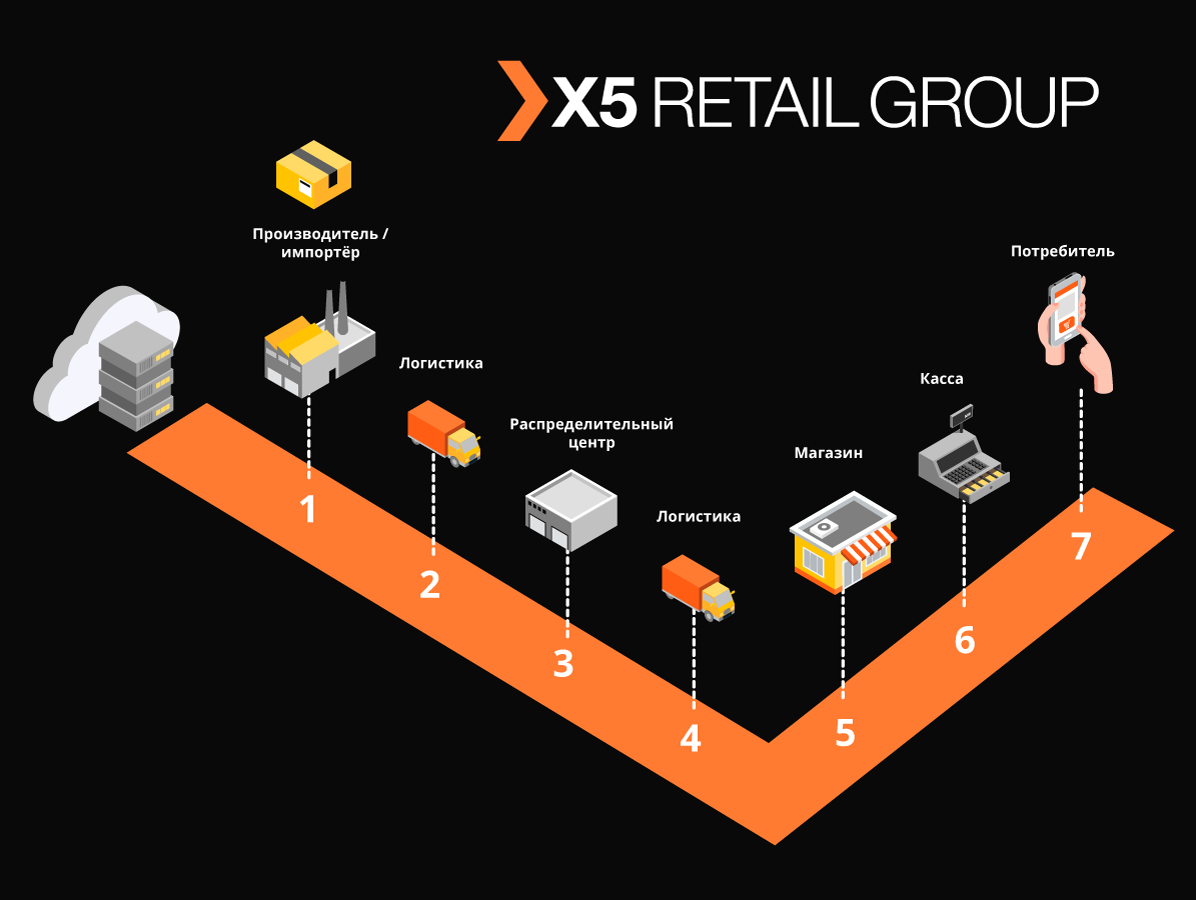
HighLoad nyata
"Markus" memecahkan banyak masalah, yang utamanya adalah interaksi integrasi antara sistem informasi X5 dan sistem informasi status produk berlabel (GIS MP) untuk melacak pergerakan produk berlabel. Platform ini juga menyimpan semua kode penandaan yang diterima oleh kami dan seluruh sejarah pergerakan kode-kode ini di seluruh objek, membantu menghilangkan penyortiran ulang produk yang ditandai. Pada contoh produk tembakau, yang termasuk dalam kelompok barang berlabel pertama, hanya satu truk rokok berisi sekitar 600.000 bungkus, masing-masing memiliki kode uniknya sendiri. Dan tugas sistem kami adalah untuk melacak dan memeriksa legalitas pergerakan masing-masing paket antara gudang dan toko, dan pada akhirnya memeriksa diterimanya penerapannya kepada pelanggan akhir. Dan kami mencatat transaksi tunai sekitar 125.000 per jam,dan juga perlu mencatat bagaimana setiap paket tersebut masuk ke toko. Dengan demikian, dengan mempertimbangkan semua pergerakan antar objek, kami mengharapkan puluhan miliar catatan per tahun.
Tim m
Terlepas dari kenyataan bahwa "Markus" dianggap sebagai proyek dalam X5, itu sedang dilaksanakan sesuai dengan pendekatan produk. Tim bekerja di Scrum. Awal proyek adalah musim panas lalu, tetapi hasil pertama datang hanya pada bulan Oktober - tim mereka sendiri sepenuhnya dirakit, arsitektur sistem dikembangkan dan peralatan dibeli. Sekarang tim memiliki 16 orang, enam di antaranya terlibat dalam pengembangan backend dan frontend, tiga dalam analisis sistem. Enam orang lagi terlibat dalam manual, pemuatan, pengujian otomatis, dan dukungan produk. Selain itu, kami memiliki spesialis SRE.
Kode dalam tim kami ditulis tidak hanya oleh pengembang, hampir semua orang tahu cara memprogram dan menulis protes otomatis, memuat skrip, dan skrip otomatisasi. Kami memberikan perhatian khusus pada ini, karena bahkan dukungan produk memerlukan otomatisasi tingkat tinggi. Kami selalu berusaha memberi saran dan membantu kolega kami yang belum memprogram sebelumnya, untuk memberikan beberapa tugas kecil untuk bekerja.
Sehubungan dengan pandemi coronavirus, kami memindahkan seluruh tim ke pekerjaan jarak jauh, ketersediaan semua alat manajemen pengembangan, alur kerja yang dibangun di Jira dan GitLab membuatnya mudah untuk melewati tahap ini. Berbulan-bulan yang dihabiskan di lokasi terpencil menunjukkan bahwa produktivitas tim tidak menderita karena hal ini, karena banyak kenyamanan dalam pekerjaan meningkat, satu-satunya hal adalah bahwa tidak ada komunikasi langsung yang cukup.
Pertemuan tim sebelum kejauhan

Rapat jarak jauh
Tumpukan teknologi solusi
Repositori dan alat CI / CD standar untuk X5 adalah GitLab. Kami menggunakannya untuk penyimpanan kode, pengujian berkelanjutan, penyebaran untuk menguji dan server produksi. Kami juga menggunakan praktik tinjauan kode, ketika setidaknya 2 rekan kerja harus menyetujui perubahan yang dilakukan oleh pengembang terhadap kode tersebut. Penganalisis kode statis SonarQube dan JaCoCo membantu kami menjaga kode tetap bersih dan memberikan tingkat cakupan tes unit yang diperlukan. Semua perubahan dalam kode harus melalui pemeriksaan ini. Semua skrip uji yang dijalankan secara manual selanjutnya otomatis.
Untuk keberhasilan pelaksanaan proses bisnis oleh "Markus", kami harus menyelesaikan sejumlah masalah teknologi, masing-masing secara berurutan.
Tugas 1. Kebutuhan skalabilitas horisontal sistem
Untuk mengatasi masalah ini, kami telah memilih pendekatan microservice untuk arsitektur. Pada saat yang sama, sangat penting untuk memahami bidang tanggung jawab layanan. Kami mencoba membaginya dalam operasi bisnis, dengan mempertimbangkan secara spesifik prosesnya. Sebagai contoh, penerimaan di gudang bukanlah kegiatan yang sangat sering, tetapi merupakan operasi yang sangat banyak, di mana perlu untuk memperoleh dari regulator negara secepat mungkin informasi tentang unit barang yang diterima, jumlah yang dalam satu pengiriman mencapai 600.000, memeriksa kelayakan menerima produk ini ke gudang dan memberikan semua informasi yang diperlukan untuk sistem otomasi gudang. Tetapi pengiriman dari gudang memiliki intensitas yang jauh lebih tinggi, tetapi pada saat yang sama beroperasi dengan sejumlah kecil data.
Kami menerapkan semua layanan berdasarkan prinsip kewarganegaraan dan bahkan mencoba membagi operasi internal menjadi beberapa langkah, menggunakan apa yang kami sebut topik mandiri Kafka. Ini adalah ketika layanan mikro mengirim pesan ke dirinya sendiri, yang memungkinkan menyeimbangkan beban untuk operasi yang lebih intensif sumber daya dan menyederhanakan pemeliharaan produk, tetapi lebih pada itu nanti.
Kami memutuskan untuk memisahkan modul untuk interaksi dengan sistem eksternal menjadi layanan terpisah. Ini memungkinkan untuk memecahkan masalah API yang sering berubah dari sistem eksternal, dengan praktis tidak berdampak pada layanan dengan fungsionalitas bisnis.
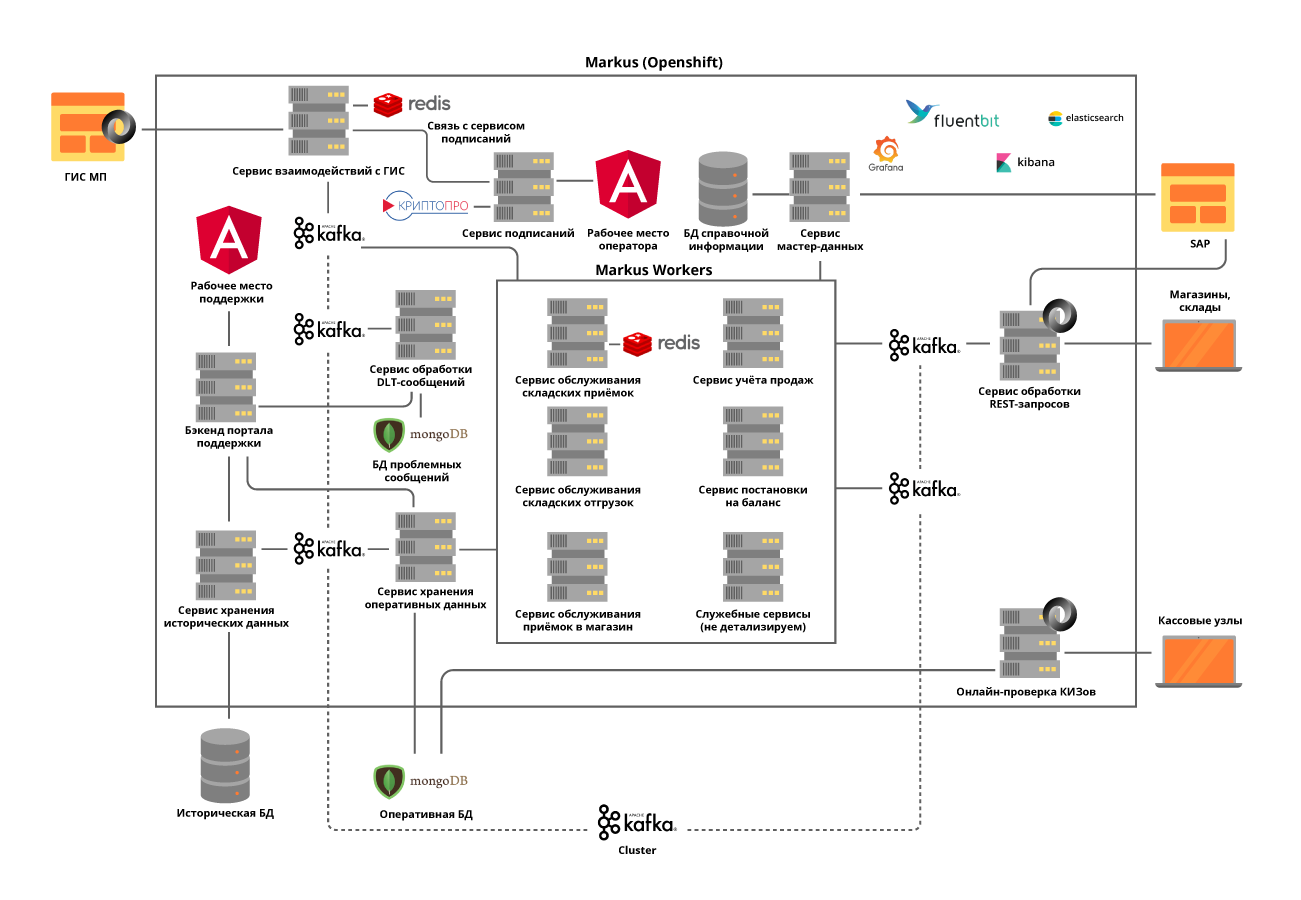
Semua layanan microsoft digunakan dalam klaster OpenShift, yang memecahkan masalah penskalaan masing-masing layanan microser dan memungkinkan kita untuk tidak menggunakan alat Layanan Penemuan pihak ketiga.
Tugas 2. Perlunya mempertahankan beban tinggi dan pertukaran data yang sangat intensif antara layanan platform: hanya pada tahap peluncuran proyek, sekitar 600 operasi per detik dilakukan. Kami berharap nilai ini meningkat hingga 5.000 op / detik karena objek perdagangan terhubung ke platform kami.
Tugas ini diselesaikan dengan menggunakan cluster Kafka dan hampir sepenuhnya meninggalkan komunikasi sinkron antara layanan platform Microsoft. Ini memerlukan analisis yang sangat hati-hati terhadap persyaratan sistem, karena tidak semua operasi dapat asinkron. Pada saat yang sama, kami tidak hanya mengirimkan peristiwa melalui broker, tetapi juga mengirimkan semua informasi bisnis yang diperlukan dalam pesan. Dengan demikian, ukuran pesan dapat mencapai beberapa ratus kilobyte. Keterbatasan volume pesan di Kafka mengharuskan kami untuk secara akurat memprediksi ukuran pesan, dan, jika perlu, kami membaginya, tetapi pembagiannya logis, terkait dengan operasi bisnis.
Sebagai contoh, barang tiba di mobil, kami membaginya ke dalam kotak. Untuk operasi sinkron, layanan microser terpisah dialokasikan dan pengujian beban yang ketat dilakukan. Menggunakan Kafka merupakan tantangan lain bagi kami - menguji layanan kami dengan integrasi Kafka membuat semua unit test kami tidak sinkron. Kami memecahkan masalah ini dengan menulis metode utilitarian kami sendiri menggunakan Embedded Kafka Broker. Ini tidak meniadakan kebutuhan untuk menulis unit test untuk metode individual, tetapi kami lebih memilih untuk menguji kasus kompleks menggunakan Kafka.
Kami membayar banyak perhatian untuk melacak log sehingga TraceId mereka tidak hilang ketika pengecualian dilemparkan selama pengoperasian layanan atau ketika bekerja dengan batch Kafka. Dan jika tidak ada pertanyaan khusus dengan yang pertama, maka dalam kasus kedua kita dipaksa untuk menulis ke log semua TraceId dengan mana batch datang dan memilih satu untuk melanjutkan penelusuran. Kemudian, saat mencari TraceId awal, pengguna akan dengan mudah menemukan jejak yang dilanjutkan.
Tujuan 3. Kebutuhan untuk menyimpan sejumlah besar data: lebih dari 1 miliar label per tahun untuk tembakau saja dikirim ke X5. Mereka memerlukan akses konstan dan cepat. Secara total, sistem harus memproses sekitar 10 miliar catatan tentang sejarah pergerakan barang-barang yang ditandai ini.
Untuk mengatasi masalah ketiga, database MongoDB NoSQL dipilih. Kami telah membangun beling 5 node dan di setiap node satu Set Replica dari 3 server. Ini memungkinkan Anda untuk skala sistem secara horizontal, menambahkan server baru ke cluster, dan memastikan toleransi kesalahannya. Di sini kami menghadapi masalah lain - memastikan transaksionalitas dalam klon mongo, dengan mempertimbangkan penggunaan layanan microsal yang dapat diskalakan secara horizontal. Misalnya, salah satu tugas sistem kami adalah mendeteksi upaya penjualan kembali barang dengan kode penandaan yang sama. Di sini overlay muncul dengan pemindaian yang salah atau dengan operasi kasir yang salah. Kami menemukan bahwa duplikat tersebut dapat terjadi baik dalam satu batch yang sedang diproses di Kafka, dan dalam dua batch yang diproses secara paralel. Jadi, memeriksa duplikat dengan menanyakan database tidak memberi apa-apa.Untuk setiap layanan Microsoft, kami memecahkan masalah secara terpisah berdasarkan logika bisnis dari layanan ini. Misalnya, untuk tanda terima, kami menambahkan bets cek di dalam dan pemrosesan terpisah untuk tampilan duplikat saat dimasukkan.
Agar pekerjaan pengguna dengan riwayat operasi tidak memengaruhi hal terpenting - berfungsinya proses bisnis kami, kami telah memisahkan semua data historis menjadi layanan terpisah dengan database terpisah, yang juga menerima informasi melalui Kafka. Dengan demikian, pengguna bekerja dengan layanan terisolasi tanpa mempengaruhi layanan yang memproses data pada operasi saat ini.
Tugas 4. Memproses ulang antrian dan pemantauan:
Dalam sistem terdistribusi, masalah dan kesalahan dalam ketersediaan basis data, antrian, dan sumber data eksternal pasti muncul. Dalam kasus Markus, sumber kesalahan tersebut adalah integrasi dengan sistem eksternal. Itu perlu untuk menemukan solusi yang akan memungkinkan permintaan berulang untuk tanggapan yang salah dengan batas waktu yang ditentukan, tetapi pada saat yang sama tidak berhenti memproses permintaan yang berhasil di antrian utama. Untuk ini, konsep "coba berdasarkan topik" dipilih. Untuk setiap topik utama, satu atau beberapa topik coba lagi dibuat, yang pesannya salah dikirim, dan pada saat yang sama, penundaan dalam memproses pesan dari topik utama dihilangkan. Skema interaksi -
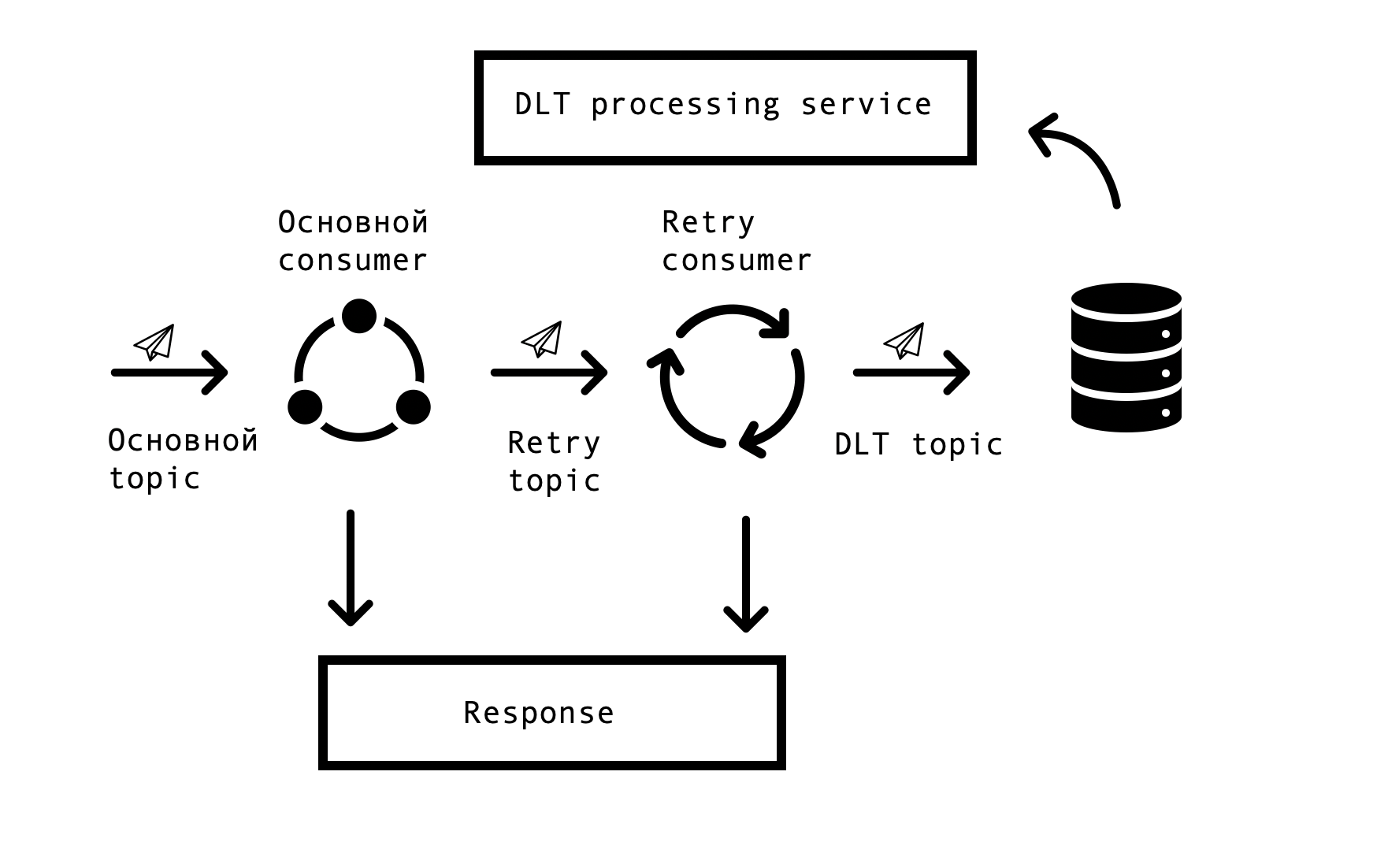
Untuk mengimplementasikan skema semacam itu, kami membutuhkan yang berikut - untuk mengintegrasikan solusi ini dengan Spring dan menghindari duplikasi kode. Dalam luasnya jaringan, kami menemukan solusi serupa yang didasarkan pada Spring BeanPostProsesor, tetapi bagi kami tampaknya tidak rumit. Tim kami membuat solusi yang lebih sederhana yang memungkinkan kami untuk berintegrasi ke dalam siklus penciptaan konsumen Spring dan juga menambahkan Retry Consumers. Kami menawarkan prototipe solusi kami kepada tim Spring, Anda bisa melihatnya di sini . Jumlah Retry Consumers dan jumlah upaya masing-masing konsumen dikonfigurasikan melalui parameter, tergantung pada kebutuhan proses bisnis, dan agar semuanya berfungsi, yang tersisa hanyalah meletakkan anotasi org.springframework.kafka.annotation.KafkaListener, yang akrab bagi semua pengembang Spring.
Jika pesan tidak dapat diproses setelah semua coba lagi, itu dikirim ke DLT (topik surat mati) menggunakan Spring DeadLetterPublishingRecoverer. Atas permintaan dukungan, kami telah memperluas fungsi ini dan membuat layanan terpisah yang memungkinkan Anda melihat pesan, stackTrace, traceId, dan informasi berguna lainnya tentang mereka yang masuk ke DLT. Selain itu, pemantauan dan peringatan ditambahkan ke semua topik DLT, dan sekarang, pada kenyataannya, penampilan pesan dalam topik DLT adalah alasan untuk menguraikan dan membuat cacat. Ini sangat mudah - dengan nama topik, kami segera memahami pada tahap proses mana masalah muncul, yang secara signifikan mempercepat pencarian untuk penyebab dasarnya.

Baru-baru ini, kami telah mengimplementasikan antarmuka yang memungkinkan kami mengirim kembali pesan dengan dukungan kami, setelah menghilangkan penyebabnya (misalnya, memulihkan pengoperasian sistem eksternal) dan, tentu saja, membuat cacat yang sesuai untuk analisis. Di sinilah topik-mandiri kami berguna, agar tidak memulai kembali rantai pemrosesan yang panjang, Anda dapat memulai kembali dari langkah yang diinginkan.
Operasi platform
Platform sudah beroperasi secara produktif, setiap hari kami melakukan pengiriman dan pengiriman, menghubungkan pusat distribusi dan toko baru. Sebagai bagian dari uji coba, sistem bekerja dengan kelompok barang "Tembakau" dan "Sepatu".
Seluruh tim kami terlibat dalam melakukan uji coba, menganalisis masalah yang muncul dan membuat proposal untuk meningkatkan produk kami dari meningkatkan kayu gelondongan ke proses perubahan.
Agar tidak mengulangi kesalahan kami, semua kasus yang ditemukan selama uji coba tercermin dalam tes otomatis. Kehadiran sejumlah besar pengujian otomatis dan unit memungkinkan Anda untuk melakukan pengujian regresi dan melakukan perbaikan terbaru hanya dalam beberapa jam.
Sekarang kami terus mengembangkan dan meningkatkan platform kami, dan terus-menerus menghadapi tantangan baru. Jika Anda tertarik, kami akan memberi tahu Anda tentang solusi kami di artikel berikut.