Kepala Antifraud Andrey Popov Nox_andrymemberikan presentasi tentang bagaimana kami dapat memenuhi semua persyaratan yang saling bertentangan ini. Topik utama dari laporan ini adalah model untuk menghitung faktor kompleks pada aliran data dan memastikan toleransi kesalahan sistem. Andrey juga menjelaskan secara singkat iterasi antifraud yang lebih cepat, yang saat ini sedang kami kembangkan.
Tim anti-fraud pada dasarnya menyelesaikan masalah klasifikasi biner. Oleh karena itu, laporan ini mungkin menarik tidak hanya untuk spesialis anti-penipuan, tetapi juga untuk mereka yang membuat berbagai sistem yang membutuhkan faktor yang cepat, dapat diandalkan dan fleksibel pada sejumlah besar data.
- Hai Nama saya Andrey. Saya bekerja di Yandex, saya bertanggung jawab atas pengembangan anti-penipuan. Saya diberi tahu bahwa orang lebih suka menggunakan kata "fitur", jadi saya akan menyebutkannya di sepanjang pembicaraan, tetapi judul dan pengantar tetap sama, dengan kata "faktor".
Apa itu antifraud?
Apa itu antifraud? Ini adalah sistem yang melindungi pengguna dari dampak negatif pada layanan. Dengan pengaruh negatif, maksud saya tindakan yang disengaja yang dapat menurunkan kualitas layanan dan, dengan demikian, memperburuk pengalaman pengguna. Ini bisa menjadi pengurai dan robot yang cukup sederhana yang memperburuk statistik kami, atau dengan sengaja melakukan kegiatan penipuan yang rumit. Yang kedua, tentu saja, lebih sulit dan lebih menarik untuk didefinisikan.
Apa yang ditentang oleh antifraud? Beberapa contoh.
Misalnya, meniru tindakan pengguna. Ini dilakukan oleh orang-orang yang kita sebut "SEO hitam" - mereka yang tidak ingin meningkatkan kualitas situs dan konten di situs. Sebagai gantinya, mereka menulis robot yang masuk ke pencarian Yandex, klik di situs mereka. Mereka berharap situs mereka naik lebih tinggi dengan cara ini. Untuk jaga-jaga, saya mengingatkan Anda bahwa tindakan tersebut bertentangan dengan perjanjian pengguna dan dapat menyebabkan sanksi serius dari Yandex.

Atau, misalnya, ulasan curang. Ulasan seperti itu dapat dilihat dari organisasi di Maps, yang menempatkan jendela plastik. Dia sendiri membayar ulasan ini.
Arsitektur anti-penipuan tingkat atas terlihat seperti ini: serangkaian peristiwa mentah jatuh ke dalam sistem anti-penipuan itu sendiri seperti kotak hitam. Di pintu keluar darinya, acara yang ditandai akan dibuat.
Yandex memiliki banyak layanan. Semua dari mereka, terutama yang besar, dengan satu atau lain cara menghadapi berbagai jenis penipuan. Cari, Pasar, Peta, dan banyak lainnya.
Di mana kita dua atau tiga tahun lalu? Setiap tim selamat dari serangan penipuan semampu mereka. Dia menghasilkan tim anti-penipuan, sistemnya, yang tidak selalu berfungsi dengan baik, tidak nyaman untuk berinteraksi dengan analis. Dan yang paling penting, mereka tidak terintegrasi satu sama lain.
Saya ingin memberi tahu Anda bagaimana kami menyelesaikan ini dengan membuat satu platform.

Mengapa kita membutuhkan satu platform? Penggunaan kembali pengalaman dan data. Pemusatan pengalaman dan data di satu tempat memungkinkan Anda untuk merespons lebih cepat dan lebih baik terhadap serangan besar - mereka biasanya lintas layanan.
Toolkit terpadu. Orang memiliki alat yang biasa mereka gunakan. Dan jelas kecepatan koneksi. Jika kami meluncurkan layanan baru yang saat ini sedang diserang aktif, maka kami harus dengan cepat menghubungkan antifraud berkualitas tinggi ke sana.
Kita dapat mengatakan bahwa kita tidak unik dalam hal ini. Semua perusahaan besar menghadapi masalah serupa. Dan setiap orang yang kami ajak berkomunikasi datang untuk menciptakan platform tunggal mereka.
Saya akan memberi tahu Anda sedikit tentang bagaimana kami mengklasifikasikan anti-penipuan.
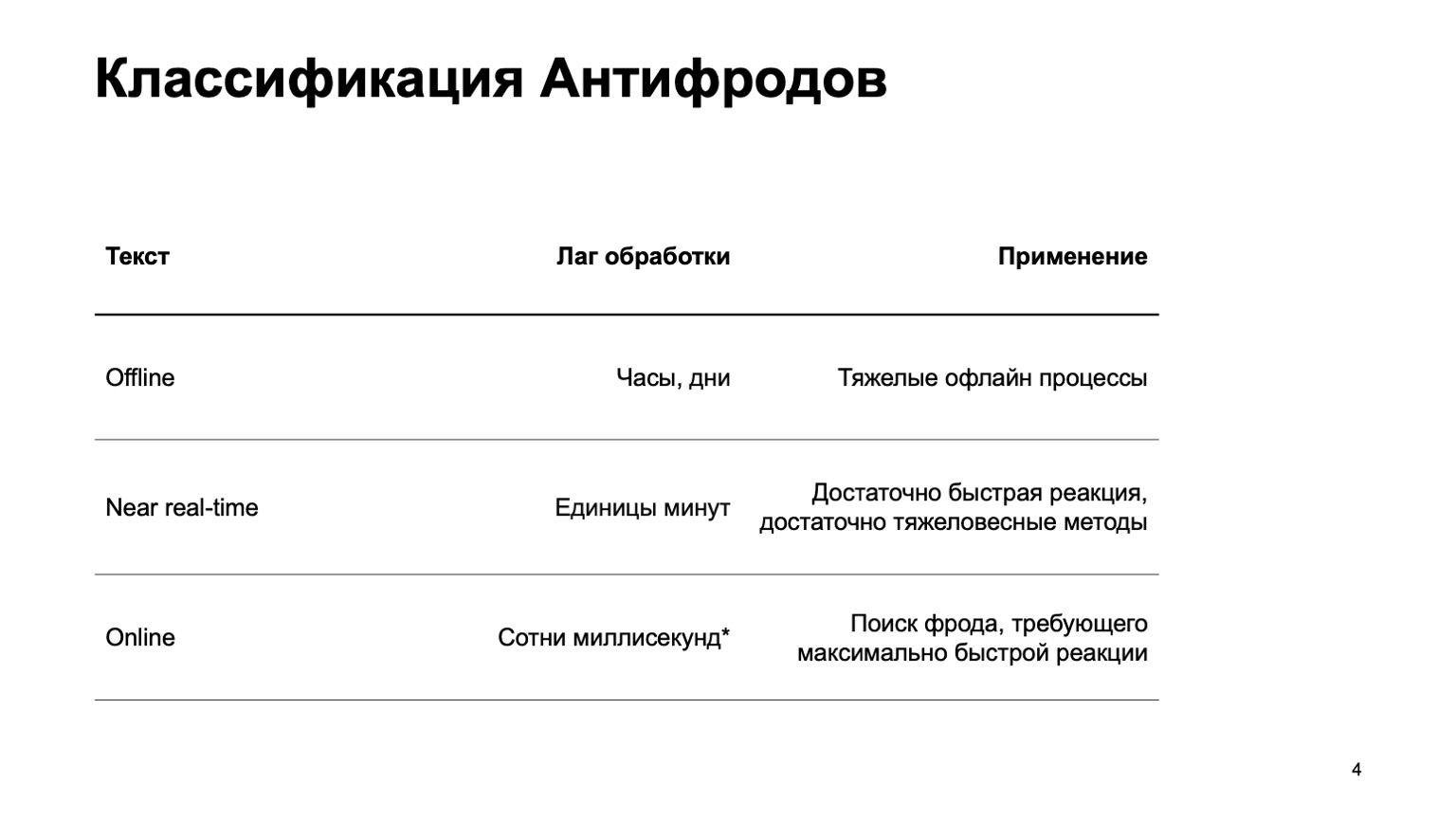
Ini bisa berupa sistem offline yang menghitung jam, hari, dan proses offline berat: misalnya, pengelompokan kompleks atau pelatihan ulang kompleks. Saya praktis tidak akan menyentuh bagian ini dalam laporan. Ada bagian waktu dekat yang bekerja dalam beberapa menit. Ini adalah jenis emas berarti, dia memiliki reaksi cepat dan metode yang berat Pertama-tama, saya akan fokus padanya. Tetapi sama pentingnya untuk mengatakan bahwa pada tahap ini kami menggunakan data dari tahap di atas.
Ada juga bagian-bagian online yang diperlukan di tempat-tempat di mana respons cepat diperlukan dan sangat penting untuk menghilangkan penipuan bahkan sebelum kami menerima acara tersebut dan meneruskannya kepada pengguna. Di sini kita menggunakan kembali algoritma pembelajaran mesin dan data yang dihitung pada tingkat yang lebih tinggi lagi.
Saya akan berbicara tentang bagaimana platform terpadu ini disusun, tentang bahasa untuk menggambarkan fitur dan berinteraksi dengan sistem, tentang jalan kita menuju peningkatan kecepatan, yaitu, hanya tentang transisi dari tahap kedua ke tahap ketiga.
Saya tidak akan menyentuh metode ML sendiri. Pada dasarnya, saya akan berbicara tentang platform yang membuat fitur, yang kemudian kami gunakan dalam pelatihan.
Siapa yang mungkin tertarik dengan ini? Jelas, bagi mereka yang menulis anti-penipuan atau melawan scammers. Tetapi juga bagi mereka yang baru memulai aliran data dan membaca fitur-fiturnya, ML mempertimbangkan. Karena kami telah membuat sistem yang cukup umum, mungkin Anda akan tertarik pada beberapa di antaranya.
Apa persyaratan sistem? Ada beberapa dari mereka, berikut adalah beberapa di antaranya:
- Aliran data besar. Kami memproses ratusan juta acara dalam lima menit.
- Fitur yang sepenuhnya dapat dikonfigurasi.
- .
- , - exactly-once- , . — , , , , .
- , , .
Selanjutnya saya akan memberi tahu Anda tentang masing-masing poin ini secara terpisah.
Karena untuk alasan keamanan saya tidak dapat berbicara tentang layanan nyata, mari kita perkenalkan layanan Yandex baru. Sebenarnya tidak, lupakan, ini adalah layanan fiksi yang saya buat untuk menunjukkan contoh. Biarkan itu menjadi layanan di mana orang memiliki database dari semua buku yang ada. Mereka masuk, memberikan peringkat dari satu hingga sepuluh, dan para penyerang ingin mempengaruhi peringkat akhir sehingga buku-buku mereka dibeli.
Semua kebetulan dengan layanan nyata, tentu saja, acak. Pertama-tama mari kita pertimbangkan versi waktu nyata yang dekat, karena online tidak diperlukan secara khusus di sini pada perkiraan pertama.
Data besar
Yandex memiliki cara klasik untuk menyelesaikan masalah data besar: gunakan MapReduce. Kami menggunakan implementasi MapReduce kami sendiri yang disebut YT . Ngomong-ngomong, Maxim Akhmedov punya cerita tentangnya malam ini . Anda dapat menggunakan implementasi Anda atau implementasi open source seperti Hadoop.
Mengapa kita tidak langsung menggunakan versi online? Itu tidak selalu dibutuhkan, itu bisa menyulitkan perhitungan ulang ke masa lalu. Jika kami telah menambahkan algoritme baru, fitur baru, kami sering ingin menghitung ulang data di masa lalu untuk mengubah putusan di atasnya. Lebih sulit menggunakan metode kelas berat - saya pikir sudah jelas mengapa. Dan versi online, karena sejumlah alasan, dapat lebih menuntut dalam hal sumber daya.
Jika kita menggunakan MapReduce, kita mendapatkan sesuatu seperti ini. Kami menggunakan semacam mini-batching, yaitu, kami membagi batch menjadi bagian terkecil yang mungkin. Dalam hal ini, itu adalah satu menit. Tetapi mereka yang bekerja dengan MapReduce tahu bahwa kurang dari ukuran ini, mungkin, sudah ada overhead yang terlalu besar dari sistem itu sendiri - overhead. Secara konvensional, itu tidak akan dapat mengatasi pemrosesan dalam satu menit.
Selanjutnya, kita menjalankan set Reduce pada set batch ini dan mendapatkan batch yang ditandai.

Dalam tugas kami, seringkali perlu untuk menghitung nilai fitur yang tepat. Misalnya, jika kami ingin menghitung jumlah buku yang telah dibaca pengguna pada bulan lalu, maka kami akan menghitung nilai ini untuk setiap kumpulan dan harus menyimpan semua statistik yang dikumpulkan di satu tempat. Dan kemudian hapus nilai lama dari itu dan tambahkan yang baru.
Mengapa tidak menggunakan metode penghitungan kasar? Jawaban singkat: kami juga menggunakannya, tetapi kadang-kadang dalam masalah anti-penipuan penting untuk memiliki nilai tepat untuk beberapa interval. Misalnya, perbedaan antara dua dan tiga buku yang dibaca bisa sangat signifikan untuk metode tertentu.
Sebagai konsekuensinya, kita memerlukan riwayat data yang besar di mana kita akan menyimpan statistik ini.
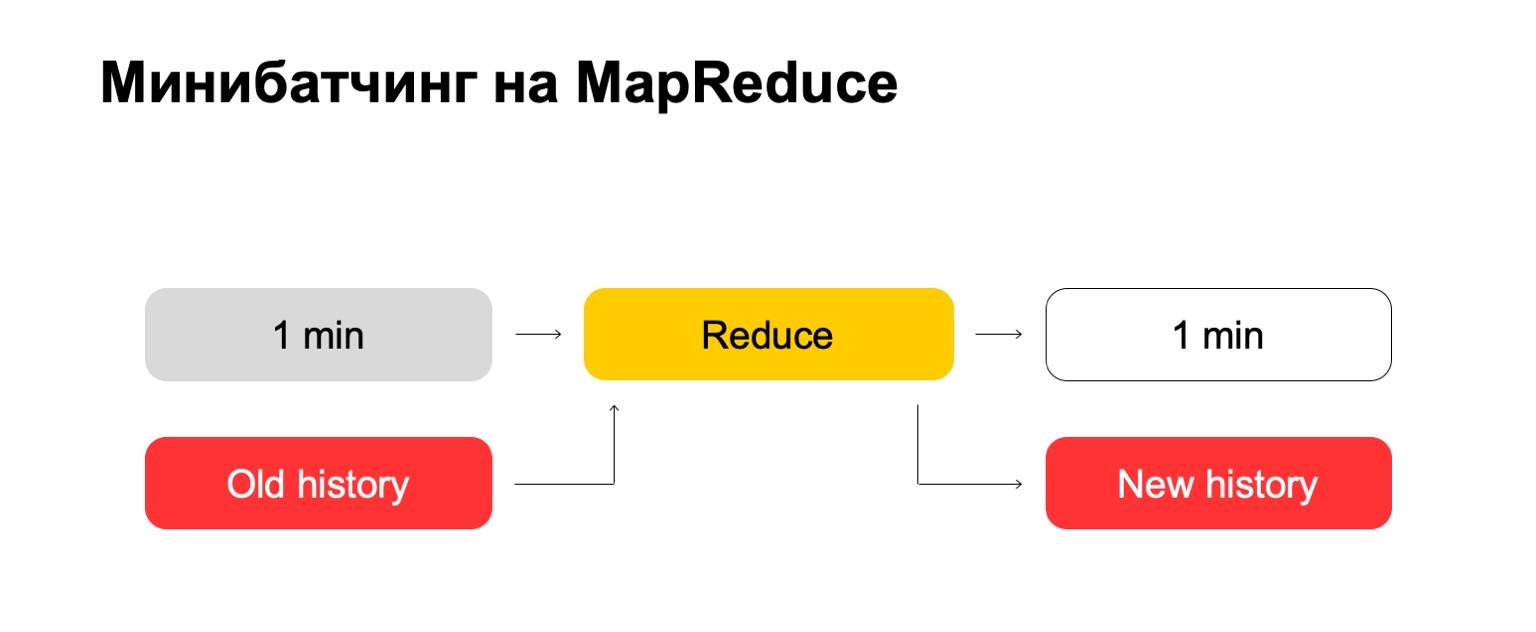
Mari kita coba "langsung". Kami punya satu menit dan cerita lama yang besar. Kami memasukkannya ke dalam Mengurangi input dan menampilkan riwayat yang diperbarui dan log yang ditandai, data.
Bagi Anda yang telah bekerja dengan MapReduce, Anda mungkin tahu bahwa ini dapat bekerja dengan sangat buruk. Jika sejarah bisa ratusan, atau bahkan ribuan, puluhan ribu kali lebih besar dari bets itu sendiri, maka pemrosesan tersebut dapat bekerja secara proporsional dengan ukuran sejarah, dan bukan ukuran bets.
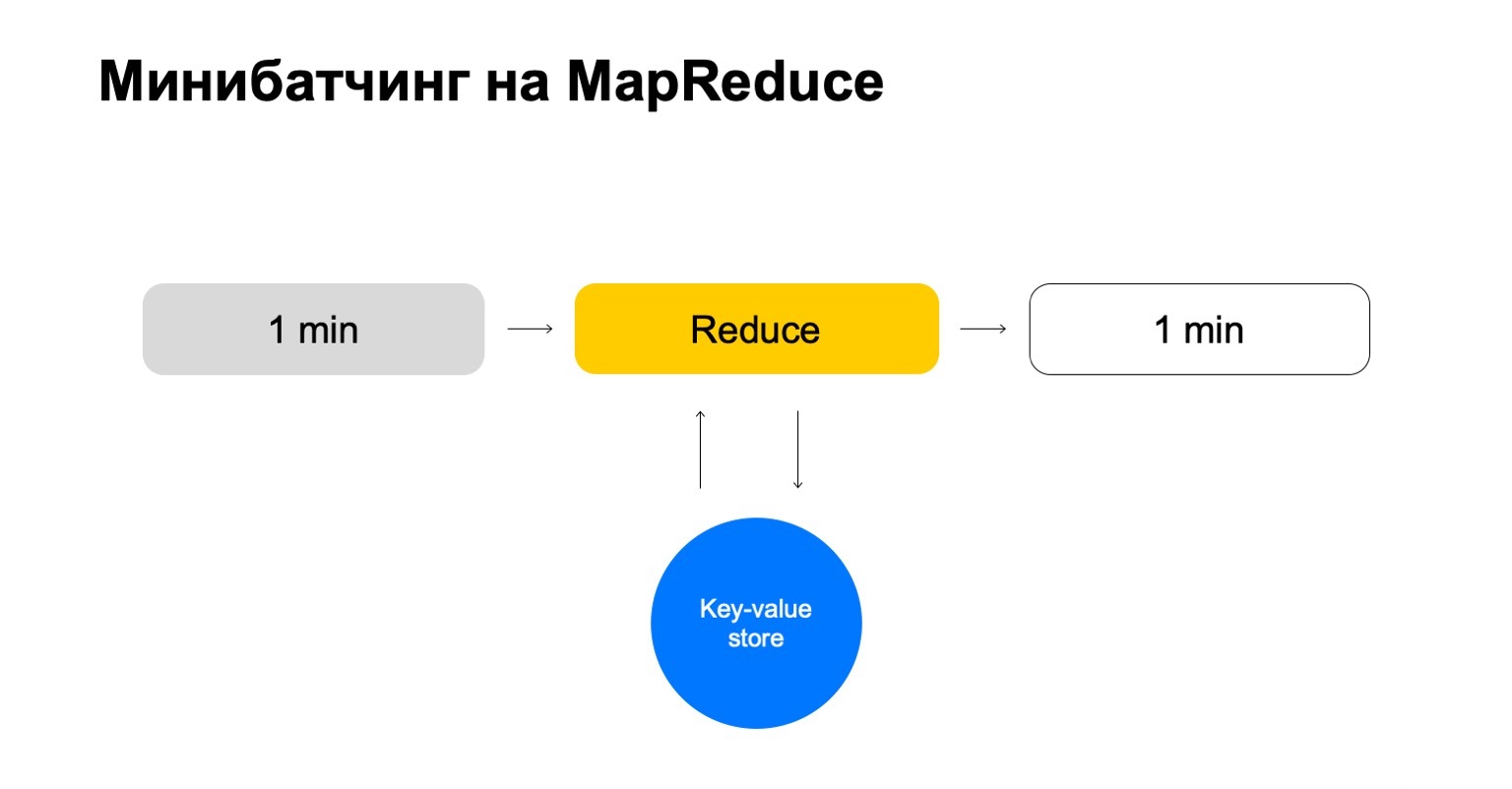
Mari kita ganti ini dengan beberapa key-value store. Sekali lagi ini adalah implementasi kami sendiri, penyimpanan nilai kunci, tetapi menyimpan data dalam memori. Mungkin analog terdekat adalah semacam Redis. Tapi kami mendapat sedikit keuntungan di sini: implementasi kami dari key-value store sangat terintegrasi dengan MapReduce dan cluster MapReduce tempat ia beroperasi. Ternyata transaksionalitas yang nyaman, transfer data yang nyaman di antara mereka.
Tetapi skema umum adalah bahwa dalam setiap pekerjaan Reduce ini kita akan pergi ke penyimpanan nilai kunci ini, memperbarui data dan menulisnya kembali setelah membuat putusan.
Kita berakhir dengan sebuah cerita yang hanya menangani kunci yang kita butuhkan dan skala dengan mudah.
Fitur yang dapat dikonfigurasi
Sedikit tentang cara kami mengkonfigurasi fitur. Penghitung sederhana seringkali tidak cukup. Untuk mencari scammers, Anda memerlukan berbagai fitur, Anda memerlukan sistem yang cerdas dan nyaman untuk mengonfigurasinya.
Mari kita bagi menjadi tiga langkah:
- Ekstrak, tempat kami mengekstrak data untuk kunci yang diberikan dan dari log.
- Gabungkan, tempat kami menggabungkan data ini dengan statistik yang ada dalam riwayat.
- Build, tempat kami membentuk nilai akhir fitur.
Misalnya, mari kita hitung persentase cerita detektif yang dibaca oleh pengguna.
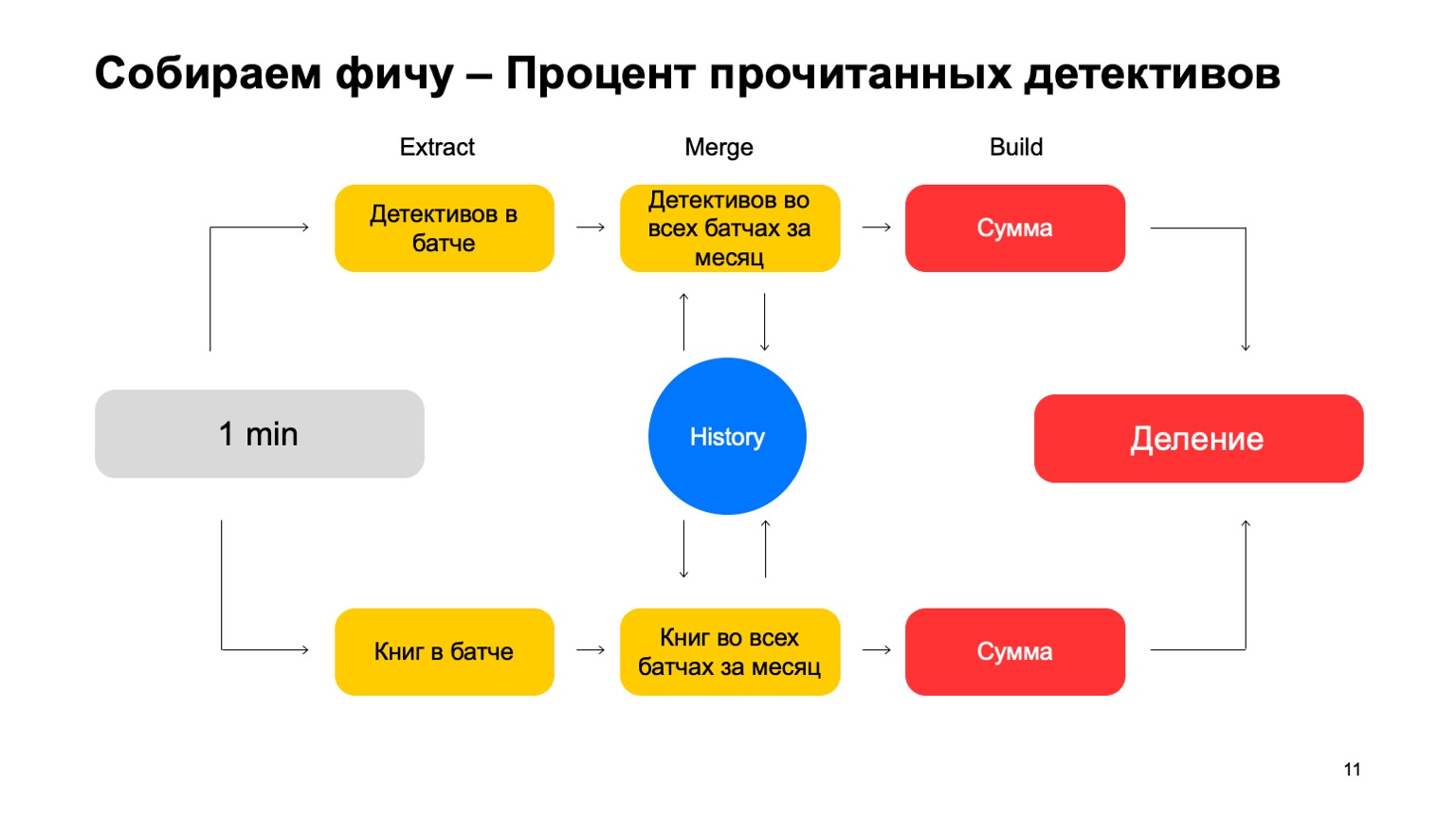
Jika pengguna membaca terlalu banyak cerita detektif, ia terlalu curiga. Tidak pernah jelas apa yang diharapkan darinya. Kemudian Ekstrak adalah penghapusan jumlah detektif yang dibaca pengguna dalam kumpulan ini. Gabungkan - mengambil semua detektif, semua data ini dari batch selama satu bulan. Dan Build adalah jumlah tertentu.
Kemudian kami melakukan hal yang sama untuk nilai semua buku yang ia baca, dan kami berakhir dengan pembagian.
Bagaimana jika kita ingin menghitung nilai yang berbeda, misalnya, jumlah penulis berbeda yang dibaca pengguna?
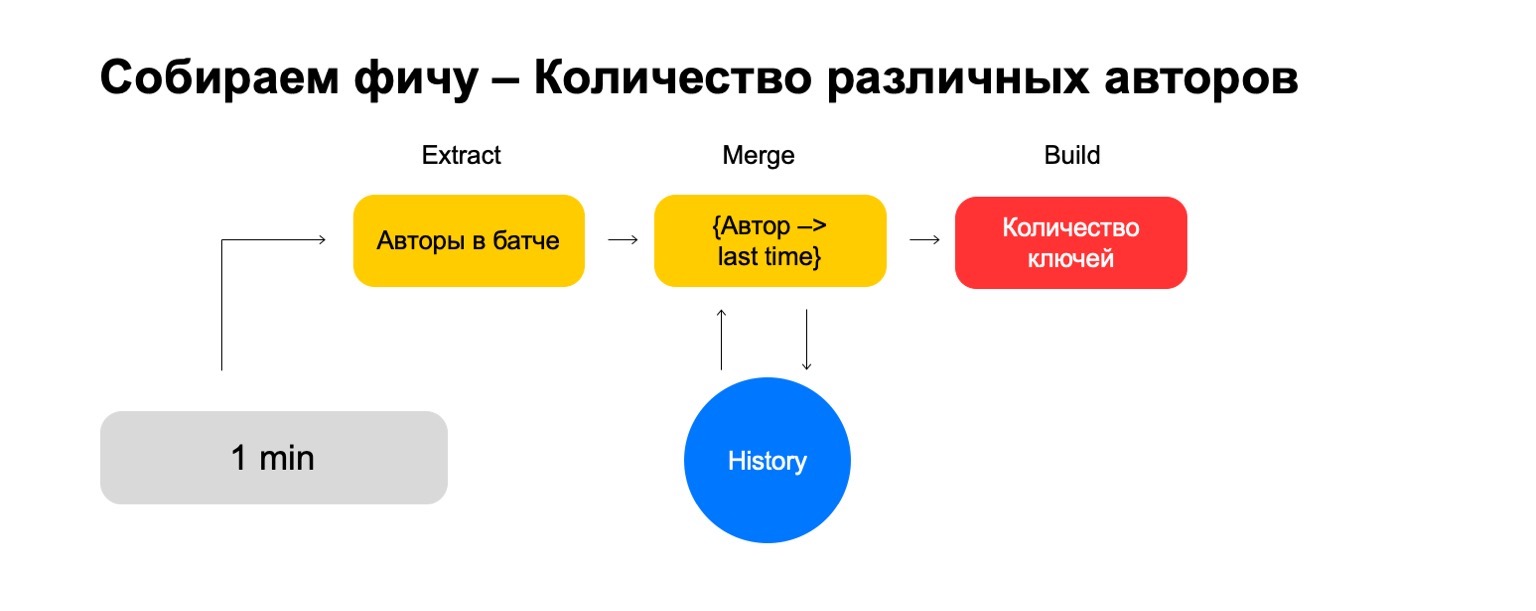
Kemudian kita dapat mengambil jumlah penulis berbeda yang telah dibaca pengguna dalam kumpulan ini. Selanjutnya, simpan beberapa struktur tempat kami membuat asosiasi penulis baru-baru ini, ketika pengguna membacanya. Jadi, jika kami bertemu penulis ini lagi di pengguna, maka kami memperbarui kali ini. Jika kami perlu menghapus acara lama, kami tahu apa yang harus dihapus. Untuk menghitung fitur terakhir, kami cukup menghitung jumlah kunci di dalamnya.

Tetapi dalam sinyal yang berisik, fitur-fitur seperti itu tidak cukup untuk satu potong, kita membutuhkan sistem untuk menempelkan sambungan mereka, menempelkan fitur ini dari potongan yang berbeda.
Misalnya, mari kita perkenalkan potongan tersebut - pengguna, penulis, dan genre.

Mari kita hitung sesuatu yang sulit. Misalnya, rata-rata loyalitas penulis. Dengan kesetiaan, maksud saya pengguna yang membaca penulis - mereka hampir hanya membacanya. Selain itu, nilai rata-rata ini cukup rendah untuk jumlah rata-rata penulis yang dibaca oleh pengguna yang membacanya.
Ini bisa menjadi sinyal potensial. Dia, tentu saja, dapat berarti bahwa penulis seperti itu: hanya ada penggemar di sekitarnya, semua orang yang membacanya hanya membaca dia. Tapi itu juga bisa berarti bahwa penulis sendiri sedang mencoba menipu sistem dan membuat para pengguna palsu yang konon membacanya.
Mari kita coba menghitungnya. Mari kita hitung fitur yang menghitung jumlah penulis yang berbeda dalam interval yang panjang. Misalnya, di sini nilai kedua dan ketiga tampak mencurigakan bagi kami, jumlahnya terlalu sedikit.
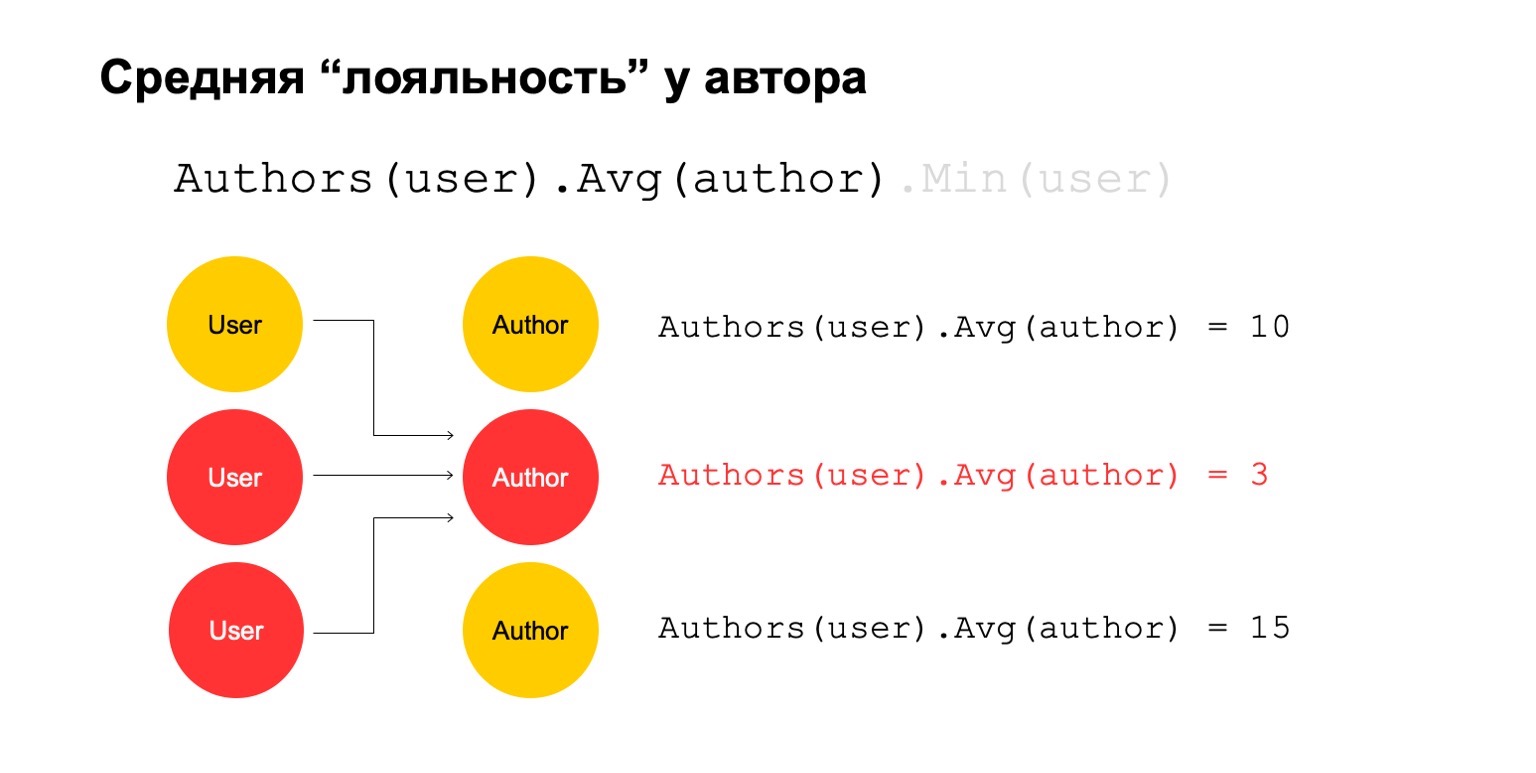
Kemudian mari kita hitung nilai rata-rata untuk penulis yang terkait dalam interval besar. Dan kemudian di sini nilai rata-rata sekali lagi sangat rendah: 3. Untuk beberapa alasan, penulis ini tampaknya mencurigakan kepada kita.
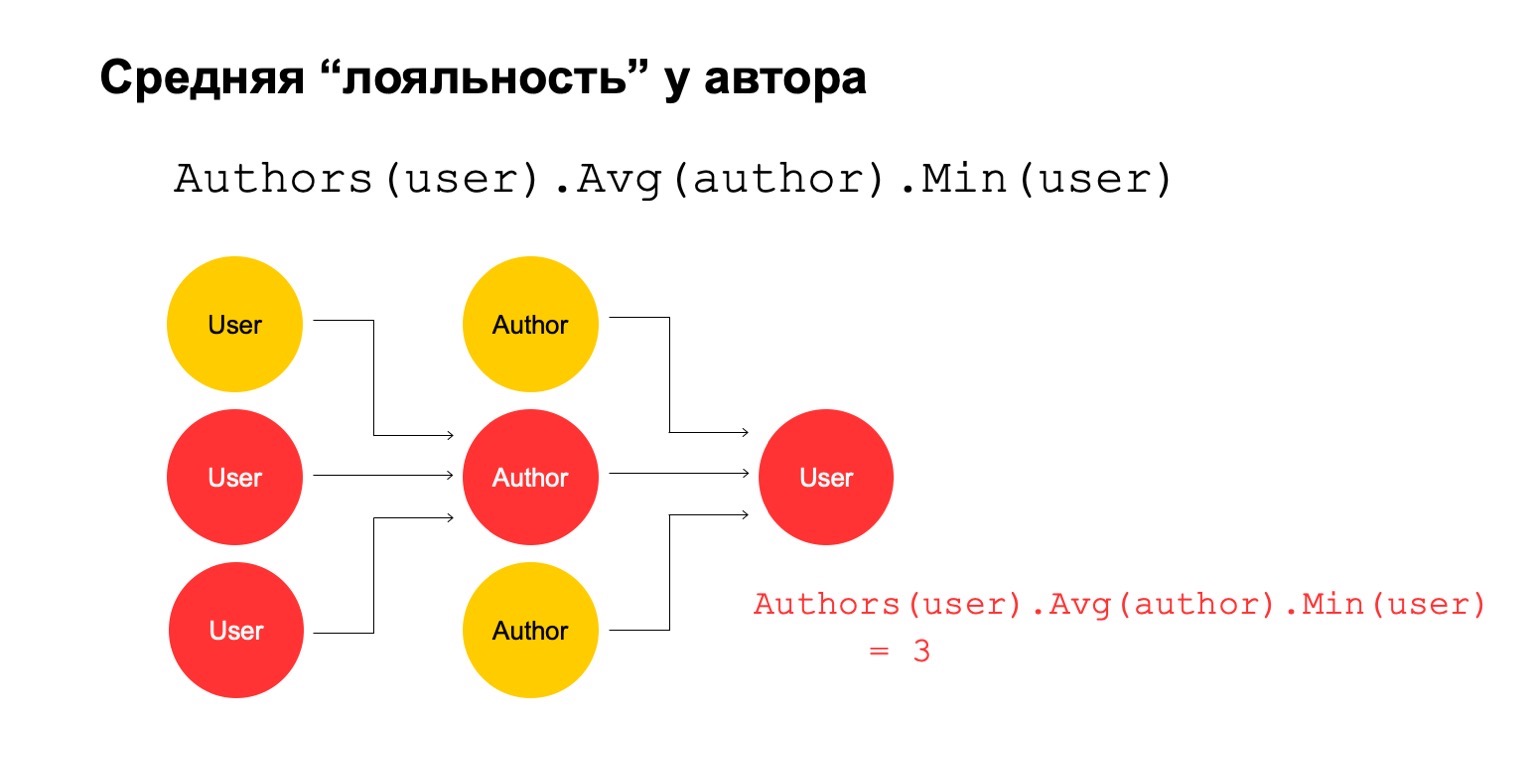
Dan kami dapat mengembalikannya kepada pengguna untuk memahami bahwa pengguna khusus ini memiliki koneksi dengan penulis, yang tampaknya mencurigakan bagi kami.
Jelas bahwa ini sendiri tidak dapat menjadi kriteria eksplisit bahwa pengguna harus difilter atau semacamnya. Tapi ini bisa menjadi salah satu sinyal yang bisa kita gunakan.
Bagaimana melakukan ini dalam paradigma MapReduce? Mari kita lakukan beberapa pengurangan berturut-turut dan dependensi di antara mereka.

Kami mendapatkan grafik reduksi. Ini mempengaruhi irisan yang kita hitung, yang secara umum diperbolehkan, pada jumlah sumber daya yang dikonsumsi: jelas, semakin banyak pengurangan, semakin banyak sumber daya. Dan Latency, throughput.
Mari kita buat, misalnya, grafik seperti itu.
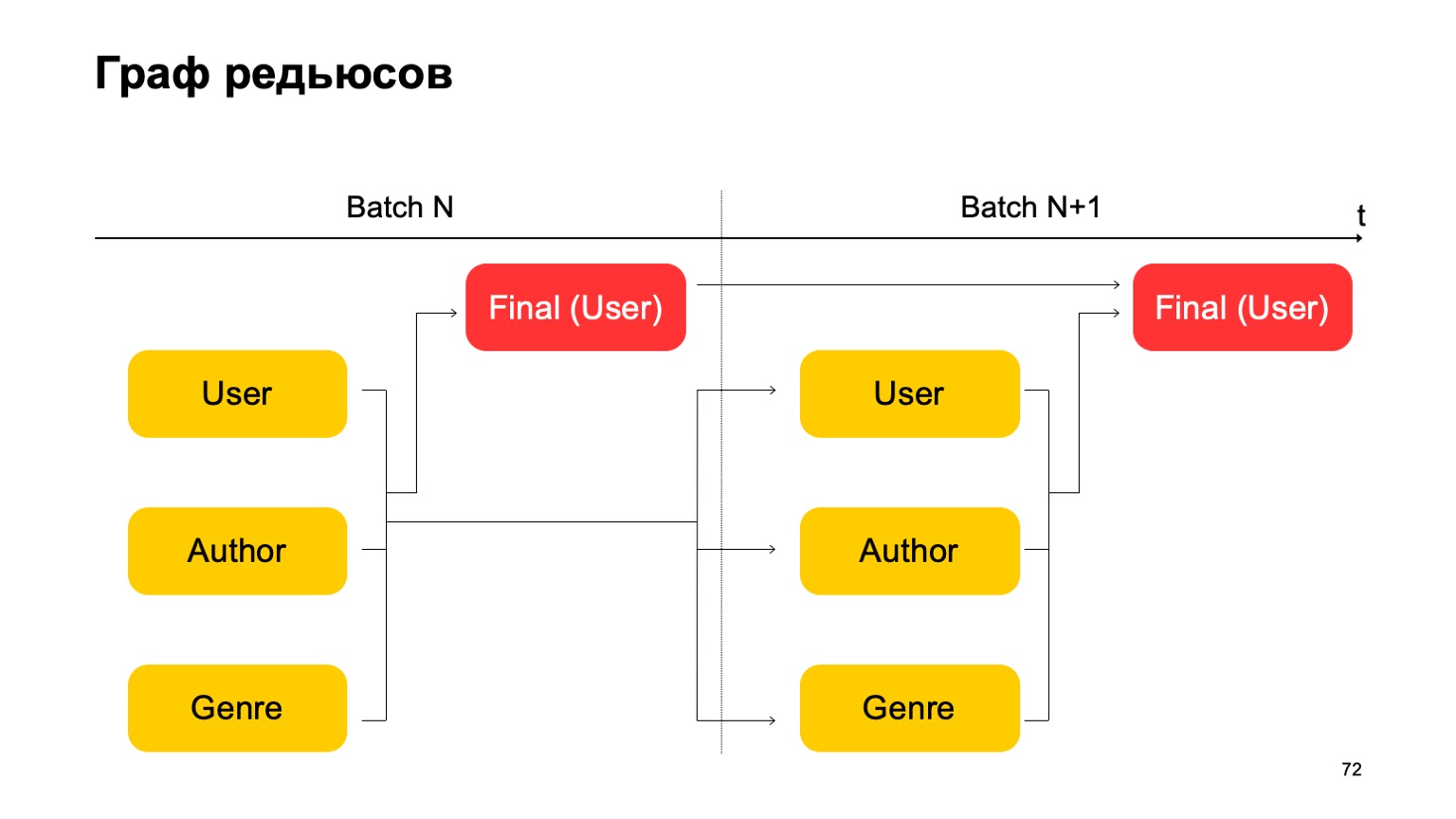
Artinya, kami akan membagi pengurangan yang kami miliki menjadi dua tahap. Pada tahap pertama, kami akan menghitung pengurangan yang berbeda secara paralel untuk bagian yang berbeda - pengguna, penulis, dan genre kami. Dan kita membutuhkan semacam tahap kedua, di mana kita akan mengumpulkan fitur dari berbagai pengurangan ini dan menerima putusan akhir.
Untuk angkatan berikutnya, kami melakukan hal yang sama. Selain itu, kami memiliki ketergantungan pada tahap pertama dari setiap kumpulan pada tahap pertama dari masa lalu dan tahap kedua pada tahap kedua dari masa lalu.
Penting di sini bahwa kita tidak memiliki ketergantungan seperti itu:
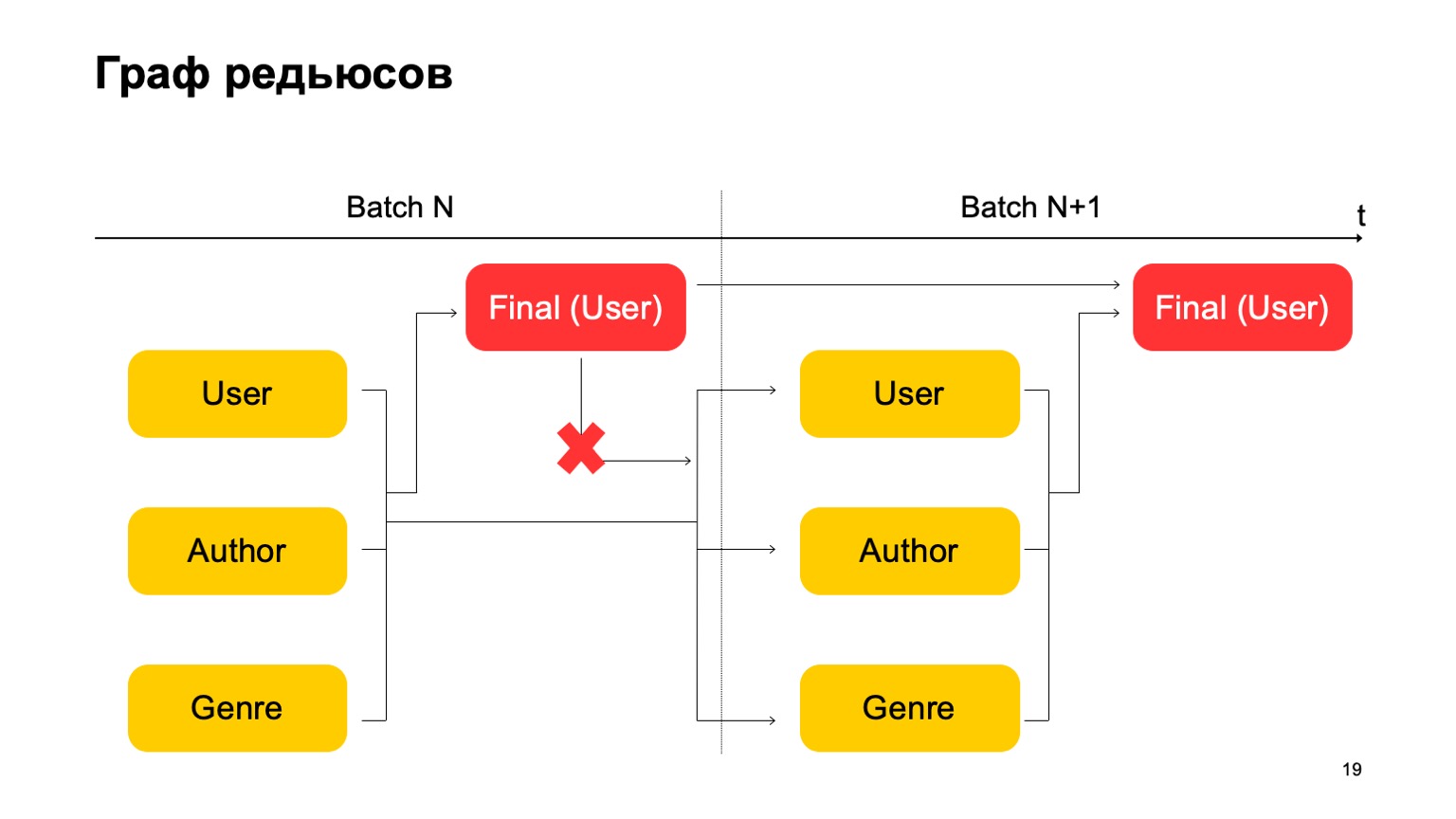
Artinya, kita benar-benar mendapatkan conveyor. Artinya, tahap pertama dari batch berikutnya dapat bekerja secara paralel dengan tahap kedua dari batch pertama.
Bagaimana kita bisa membuat statistik tiga tahap dalam hal ini, yang saya berikan di atas, jika kita hanya memiliki dua tahap? Sangat sederhana. Kita dapat membaca nilai pertama pada tahap pertama dari batch N.
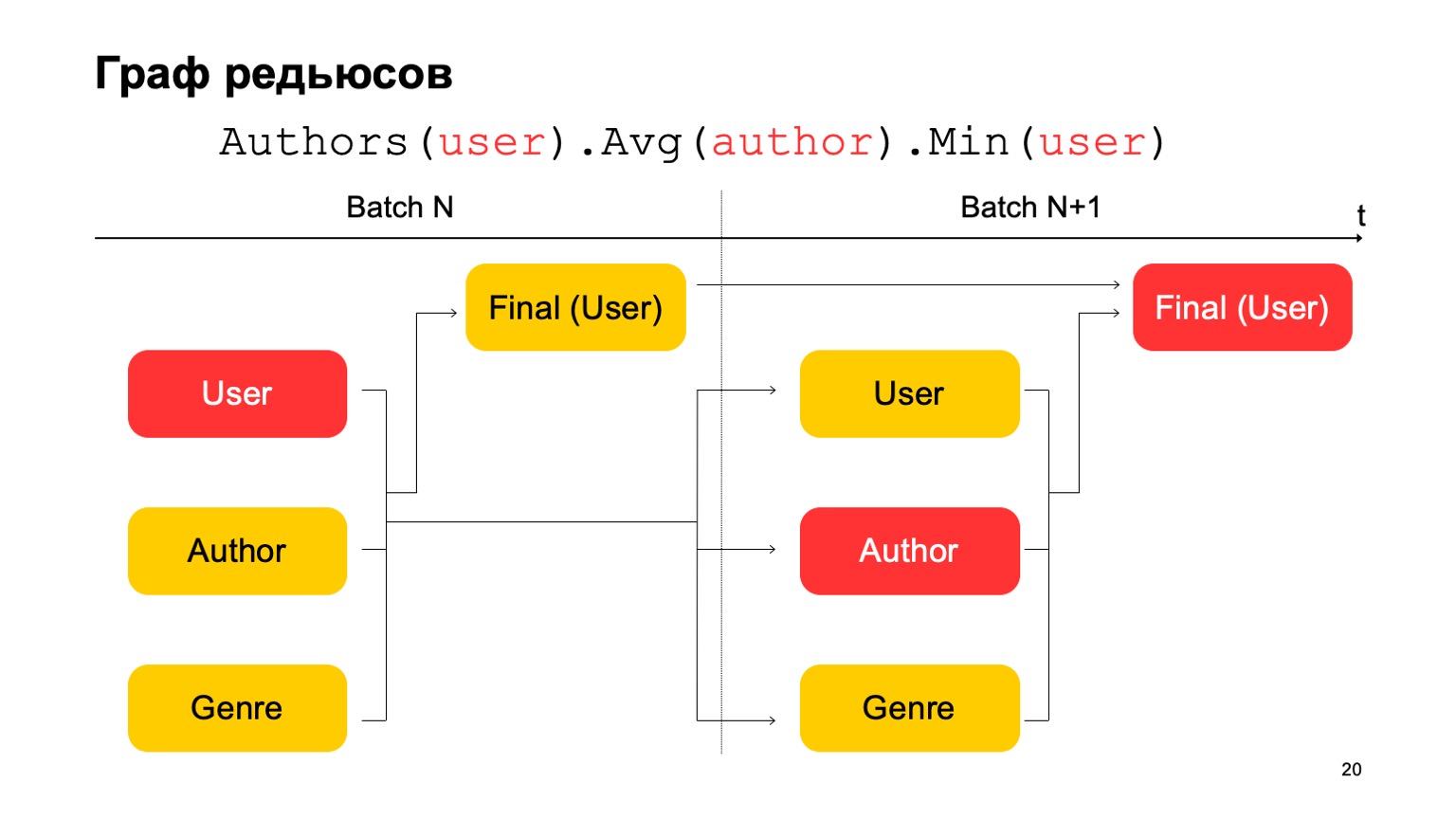
Nilai kedua pada tahap pertama dari batch adalah N + 1, dan nilai akhir harus dibaca pada tahap kedua dari batch N + 1. Jadi, selama transisi antara tahap pertama dan yang kedua, mungkin, mungkin, statistik yang tidak cukup akurat untuk kumpulan N + 1. Tapi biasanya ini sudah cukup untuk perhitungan seperti itu.

Memiliki semua hal ini, Anda dapat membangun fitur yang lebih kompleks dari kubus. Misalnya, penyimpangan peringkat buku saat ini dari peringkat rata-rata pengguna. Atau proporsi pengguna yang menilai buku sangat positif atau sangat negatif. Juga mencurigakan. Atau peringkat buku rata-rata oleh pengguna yang memiliki lebih dari N peringkat untuk buku yang berbeda. Ini mungkin penilaian yang lebih akurat dan adil dari beberapa sudut pandang.

Yang ditambahkan ke sini adalah apa yang kita sebut hubungan antar acara. Seringkali duplikat muncul di log atau dalam data yang dikirimkan kepada kami. Ini bisa berupa acara teknis atau perilaku robot. Kami juga menemukan duplikat tersebut. Atau, misalnya, beberapa acara terkait. Katakanlah sistem Anda menampilkan rekomendasi buku, dan pengguna mengklik rekomendasi ini. Agar statistik akhir yang memengaruhi peringkat tidak rusak, kita perlu memastikan bahwa jika kita memfilter tayangan, maka kita juga harus memfilter klik pada rekomendasi saat ini.
Tetapi karena aliran kami mungkin datang tidak merata, pertama klik, kami harus menunda sampai kami melihat pertunjukan dan menerima vonis berdasarkan itu.
Bahasa deskripsi fitur
Saya akan memberi tahu Anda sedikit tentang bahasa yang digunakan untuk menggambarkan semua ini.

Anda tidak harus membacanya, ini misalnya. Kami mulai dengan tiga komponen utama. Yang pertama adalah deskripsi unit data dalam sejarah, secara umum, dari tipe arbitrer.

Ini adalah semacam fitur, angka yang dapat dibatalkan.

Dan semacam aturan. Apa yang kita sebut aturan? Ini adalah serangkaian kondisi untuk fitur-fitur ini dan sesuatu yang lain. Kami memiliki tiga file terpisah.
Masalahnya adalah bahwa di sini satu rangkaian tindakan tersebar di berbagai file. Sejumlah besar analis perlu bekerja dengan sistem kami. Mereka tidak nyaman.
Bahasa berubah menjadi imperatif: kita menggambarkan bagaimana cara menghitung data, dan bukan deklaratif, ketika kita akan menggambarkan apa yang perlu kita hitung. Ini juga sangat tidak nyaman, cukup mudah untuk membuat kesalahan dan ambang masuk yang tinggi. Orang-orang baru datang, tetapi mereka sama sekali tidak mengerti cara bekerja dengannya.
Solusi - mari kita buat DSL kita sendiri. Ini menggambarkan skenario kami lebih jelas, lebih mudah bagi orang baru, lebih tinggi. Kami mengambil inspirasi dari SQLAlchemy, C # Linq dan sejenisnya.
Saya akan memberikan beberapa contoh yang mirip dengan yang saya berikan di atas.

Persentase cerita detektif yang dibaca. Kami menghitung jumlah buku yang dibaca, yaitu kami mengelompokkan berdasarkan pengguna. Kami menambahkan pemfilteran untuk kondisi ini, dan jika kami ingin menghitung persentase akhir, kami hanya menghitung peringkat. Semuanya sederhana, jelas, dan intuitif.

Jika kami menghitung jumlah penulis yang berbeda, maka kami mengelompokkan berdasarkan pengguna, menetapkan penulis yang berbeda. Untuk ini, kami dapat menambahkan beberapa kondisi, misalnya, jendela perhitungan atau batas jumlah nilai yang kami simpan karena kendala memori. Akibatnya, kami menghitung hitungan, jumlah kunci di dalamnya.

Atau kesetiaan rata-rata yang saya bicarakan. Sekali lagi, kita memiliki semacam ekspresi yang dihitung dari atas. Kami mengelompokkan berdasarkan penulis dan menetapkan beberapa nilai rata-rata di antara ungkapan ini. Lalu kami mempersempitnya kembali ke pengguna.

Untuk ini, kita dapat menambahkan kondisi filter. Yaitu, filter kami dapat, misalnya, sebagai berikut: loyalitas tidak terlalu tinggi dan persentase detektif adalah antara 80 dari 100.
Apa yang kami gunakan untuk ini di bawah tenda?
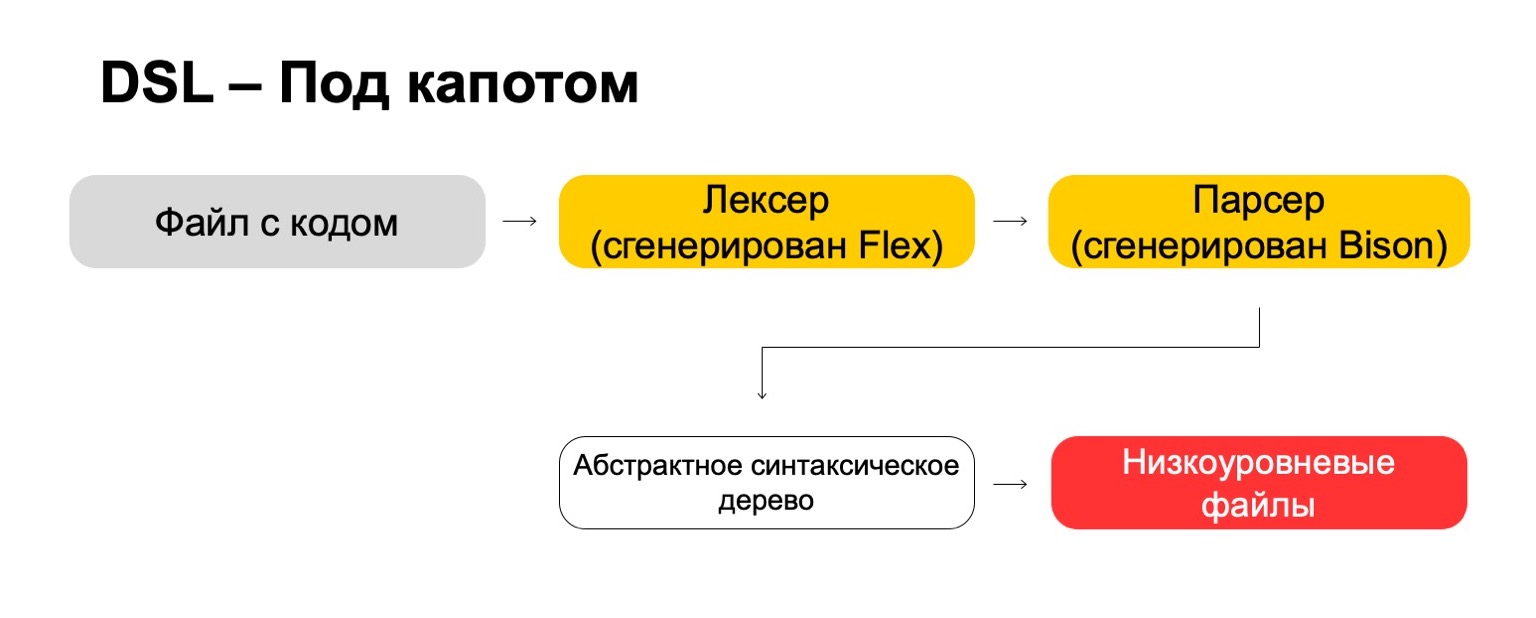
Di bawah tenda, kami menggunakan teknologi paling modern langsung dari tahun 70-an, seperti Flex, Bison. Mungkin Anda pernah mendengarnya. Mereka menghasilkan kode. File kode kami melewati lexer kami, yang dihasilkan dalam Flex, dan melalui parser, yang dihasilkan dalam Bison. Lexer menghasilkan simbol atau kata-kata terminal dalam bahasa, parser menghasilkan ekspresi sintaksis.
Dari sini kita mendapatkan pohon sintaksis abstrak, yang dengannya kita sudah bisa melakukan transformasi. Dan pada akhirnya, kami mengubahnya menjadi file tingkat rendah yang dipahami oleh sistem.
Apa intinya? Ini lebih rumit daripada yang terlihat pada pandangan pertama. Dibutuhkan banyak sumber daya untuk memikirkan hal-hal kecil seperti prioritas untuk operasi, kasus tepi, dan sejenisnya. Anda perlu mempelajari teknologi langka yang sepertinya tidak akan berguna bagi Anda di kehidupan nyata, kecuali Anda menulis kompiler, tentu saja. Tetapi pada akhirnya itu sepadan. Artinya, jika Anda, seperti kami, memiliki sejumlah besar analis yang sering datang dari tim lain, maka pada akhirnya ini memberikan keuntungan yang signifikan, karena menjadi lebih mudah bagi mereka untuk bekerja.
Keandalan
Beberapa layanan memerlukan toleransi kesalahan: lintas-DC dan pemrosesan tepat-sekali. Pelanggaran dapat menyebabkan perbedaan dalam statistik dan kerugian, termasuk kerugian moneter. Solusi kami untuk MapReduce adalah sedemikian sehingga kami membaca data pada satu waktu hanya pada satu cluster dan menyinkronkannya pada yang kedua.
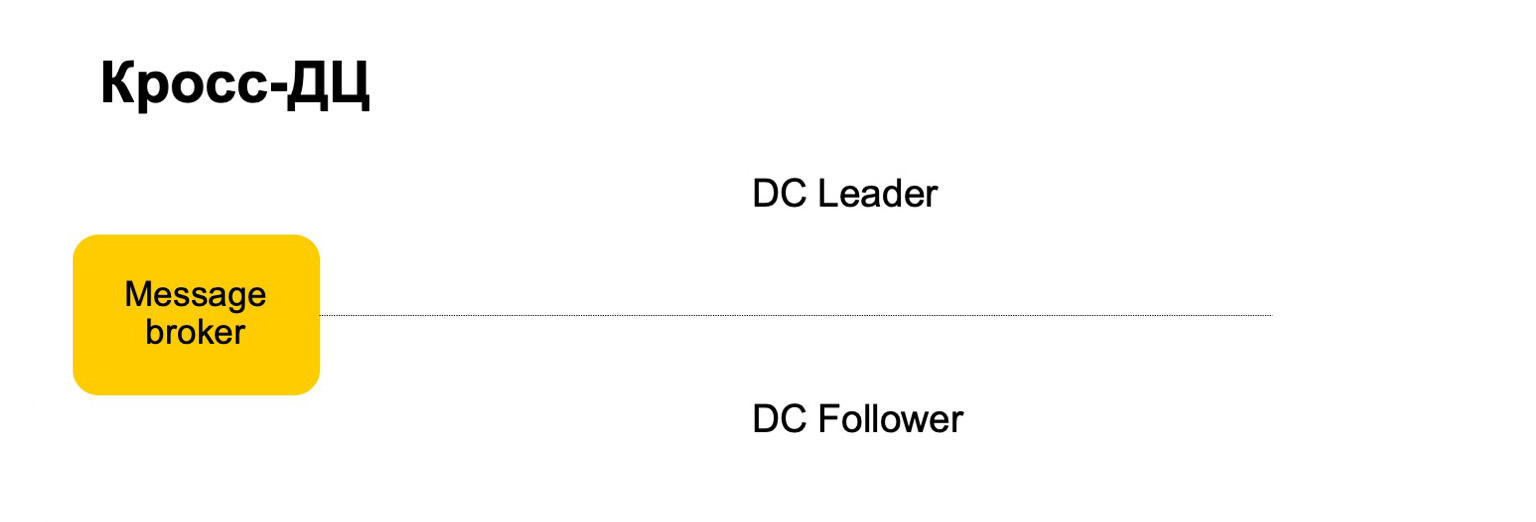
Misalnya, bagaimana kita akan bersikap di sini? Ada broker pemimpin, pengikut dan pesan. Dapat dianggap bahwa ini adalah kafka bersyarat, meskipun di sini, tentu saja, implementasinya sendiri.
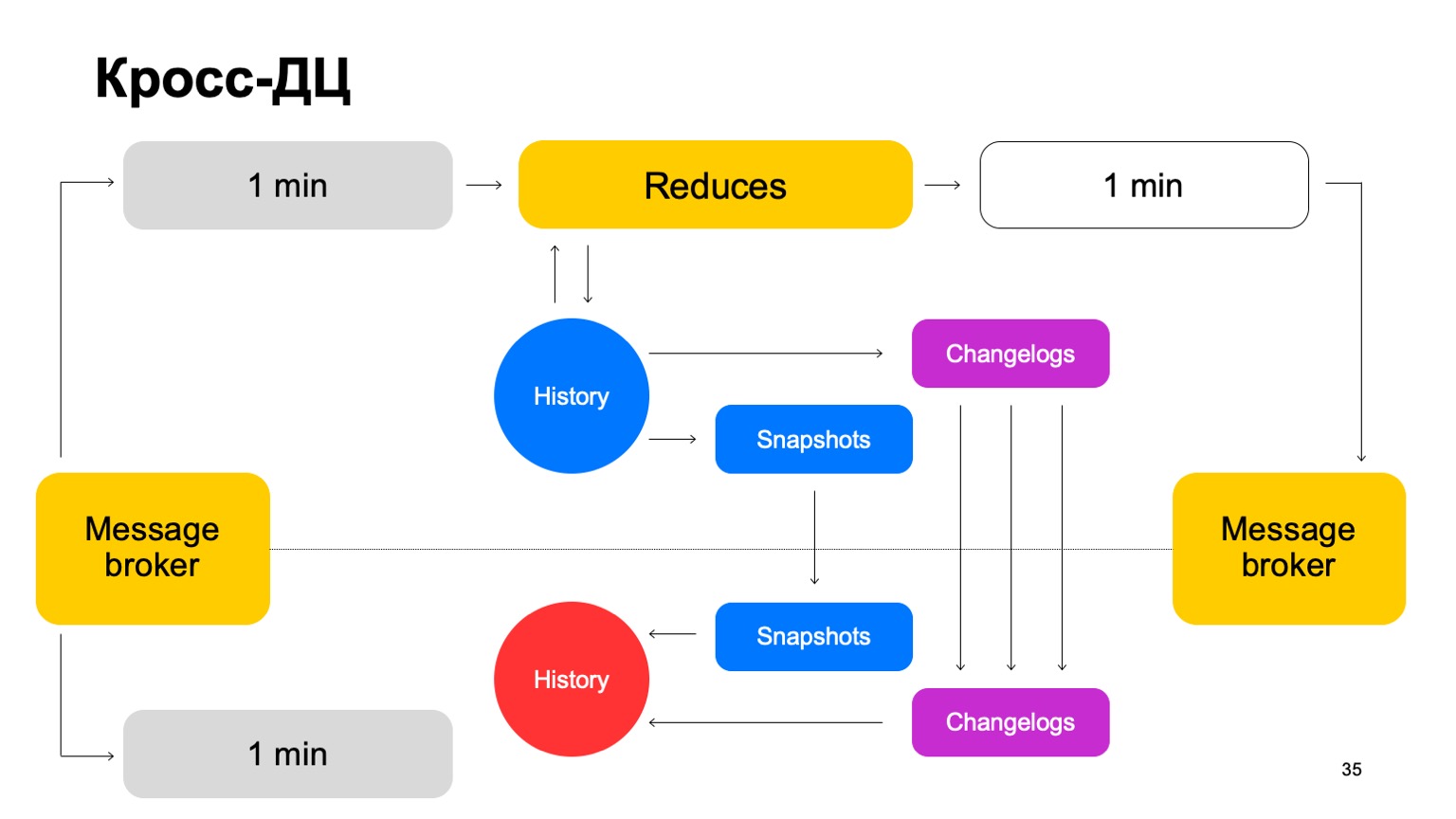
Kami mengirimkan kumpulan kami ke kedua kluster, meluncurkan serangkaian pengurangan pada pemimpin yang sama, menerima putusan akhir, memperbarui sejarah dan mengirim hasilnya kembali ke layanan ke broker pesan.
Sesekali, kita tentu harus melakukan replikasi. Artinya, kami mengumpulkan foto, mengumpulkan perubahan - perubahan untuk setiap batch. Kami menyinkronkan keduanya ke pengikut kelompok kedua. Dan juga memunculkan cerita yang sangat panas. Biarkan saya mengingatkan Anda bahwa sejarah tersimpan di sini.
Jadi, jika satu DC karena alasan tertentu menjadi tidak tersedia, kita dapat dengan cepat, dengan kelambatan minimal, beralih ke cluster kedua.
Mengapa tidak mengandalkan dua cluster secara paralel? Data eksternal dapat berbeda pada dua cluster, mereka dapat disediakan oleh layanan eksternal. Apa itu data eksternal? Ini adalah sesuatu yang naik dari level yang lebih tinggi ini. Artinya, pengelompokan yang kompleks dan sejenisnya. Atau hanya tambahan data untuk perhitungan.
Kami membutuhkan solusi yang disepakati. Jika kami menghitung putusan secara paralel menggunakan data yang berbeda dan secara berkala beralih antara hasil dari dua kelompok yang berbeda, konsistensi di antara mereka akan turun secara dramatis. Dan, tentu saja, menghemat sumber daya. Karena kami menggunakan sumber daya CPU hanya pada satu cluster pada satu waktu.
Bagaimana dengan cluster kedua? Ketika kita bekerja, dia praktis menganggur. Mari kita gunakan sumber dayanya untuk pra-produksi penuh. Dengan pra-produksi penuh, maksud saya di sini instalasi penuh yang menerima aliran data yang sama, bekerja dengan volume data yang sama, dll.

Jika cluster tidak tersedia, kami mengubah instalasi ini dari penjualan ke pra-produksi. Jadi, kami memiliki preprod untuk beberapa waktu, tetapi tidak apa-apa.
Keuntungannya adalah kita dapat menghitung lebih banyak fitur pada preproses. Mengapa ini perlu? Karena jelas bahwa jika kita ingin menghitung sejumlah besar fitur, maka kita sering tidak perlu menghitung semuanya yang dijual. Di sana, kami hanya menghitung apa yang diperlukan untuk mendapatkan putusan akhir.
(00:25:12)
Tetapi pada saat yang sama, kami memiliki semacam cache panas di preproses, besar, dengan beragam fitur. Jika terjadi serangan, kita dapat menggunakannya untuk menutup masalah dan mentransfer fitur-fitur ini ke produksi.
Ditambah dengan ini adalah manfaat pengujian B2B. Artinya, kita semua meluncurkan, tentu saja, pertama untuk pra-penjualan. Kami sepenuhnya membandingkan perbedaan apa pun, dan, dengan demikian, kami tidak akan salah, kami meminimalkan kemungkinan bahwa kami dapat membuat kesalahan ketika meluncurkan untuk dijual.
Sedikit tentang penjadwal. Jelas bahwa kami memiliki beberapa jenis mesin yang menjalankan tugas di MapReduce. Ini semacam pekerja. Mereka secara teratur menyinkronkan data mereka ke Database Cross-DC. Ini hanya keadaan dari apa yang mereka berhasil hitung saat ini.
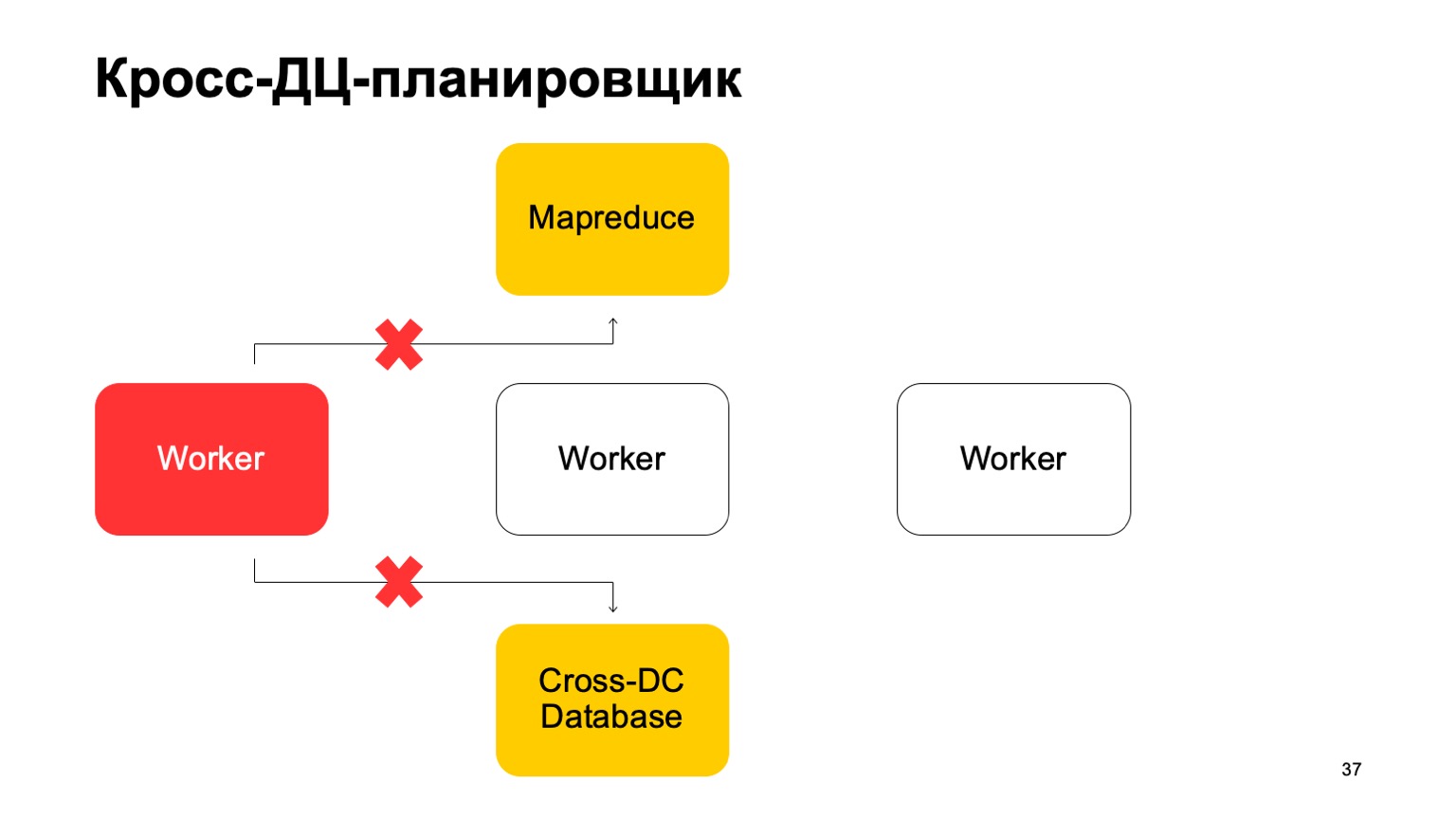
Jika seorang pekerja menjadi tidak tersedia, maka pekerja lain mencoba untuk mengambil log, ambil negara.
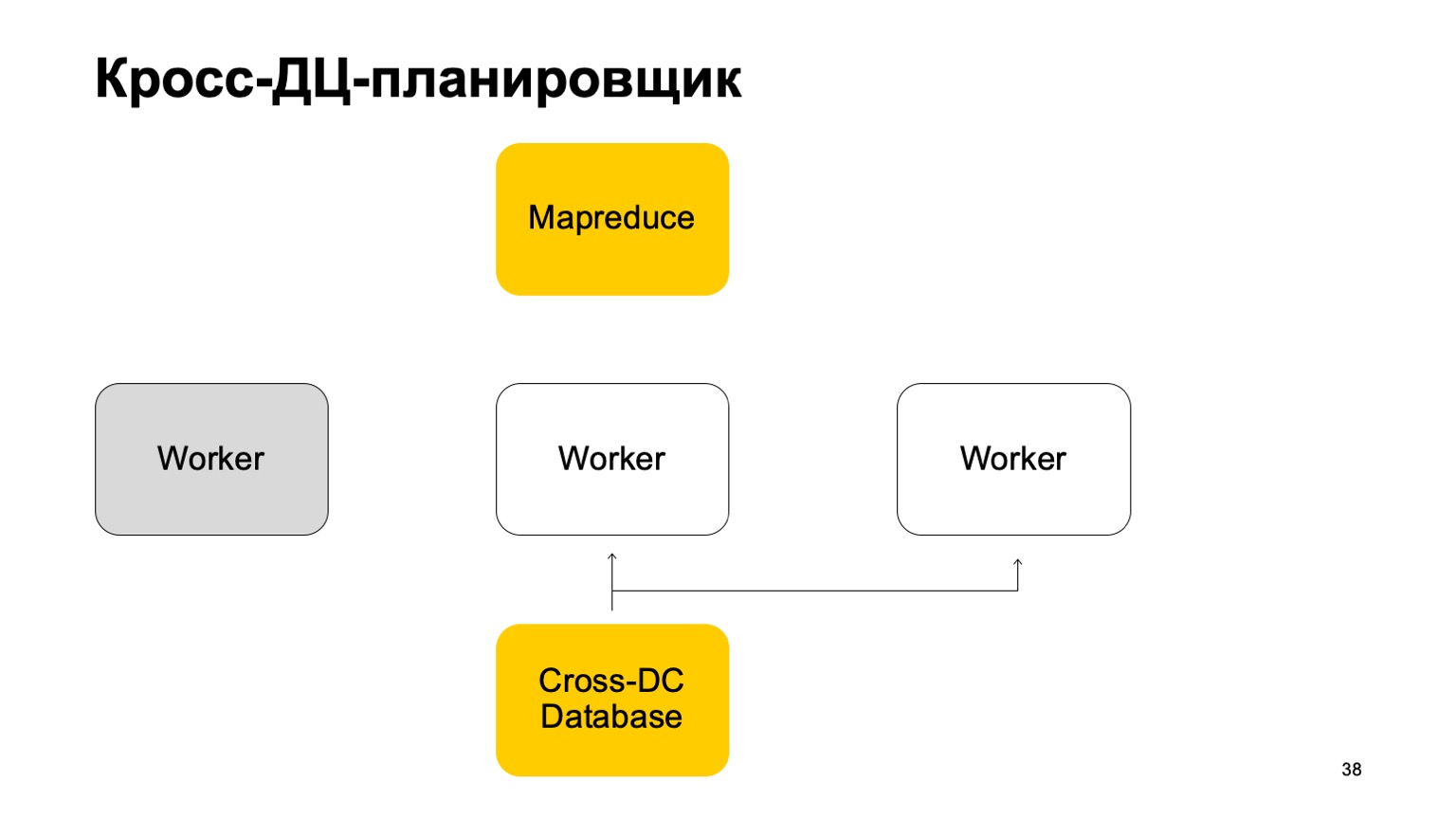
Bangun dari situ dan terus bekerja. Lanjutkan mengatur tugas pada MapReduce ini.
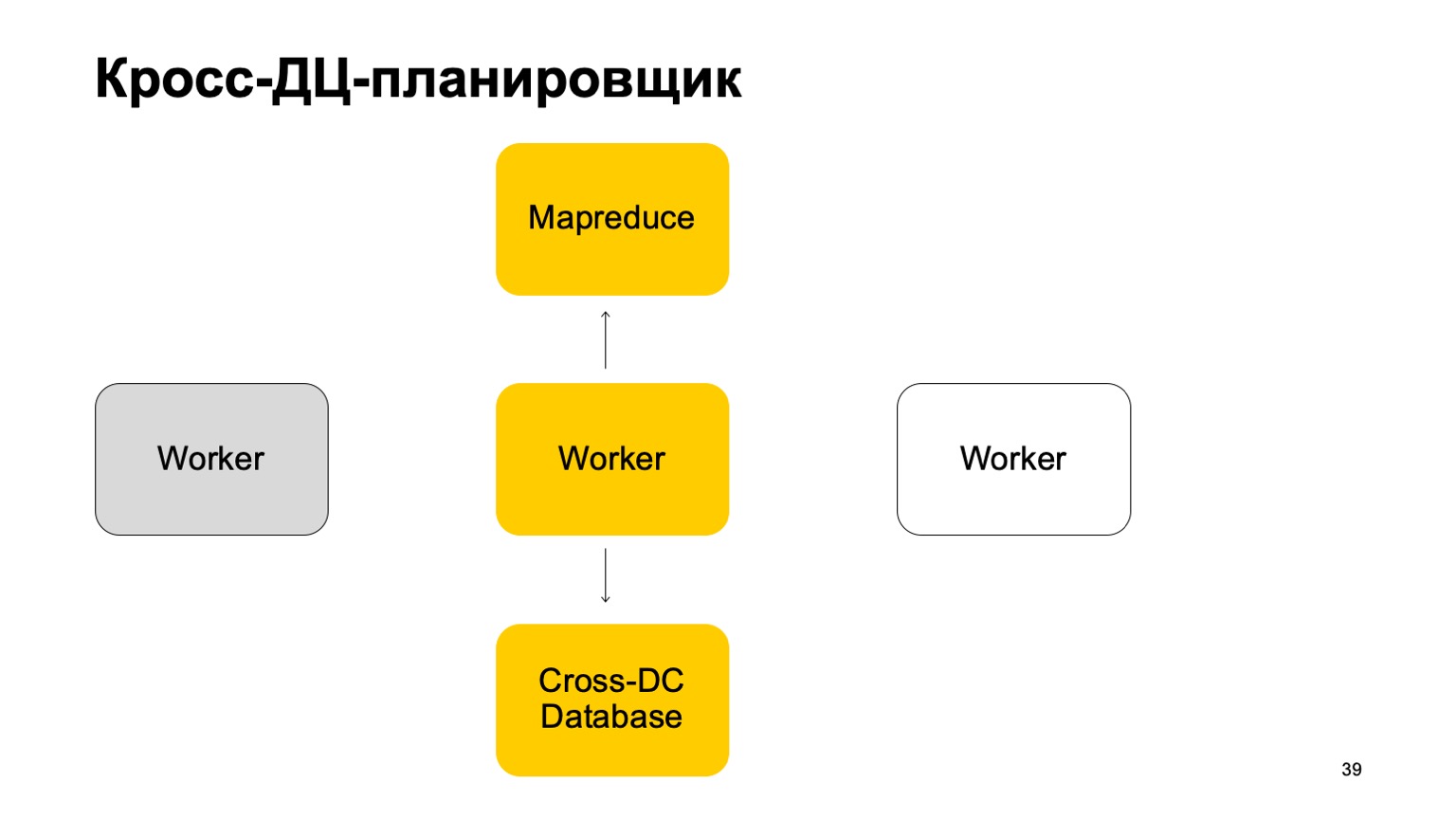
Jelas bahwa dalam kasus mengesampingkan tugas-tugas ini, beberapa dari mereka mungkin dimulai kembali. Oleh karena itu, ada properti yang sangat penting bagi kami di sini: idempotensi, kemampuan untuk memulai kembali setiap operasi tanpa konsekuensi.
Artinya, semua kode harus ditulis sedemikian rupa sehingga ini berfungsi dengan baik.

Saya akan memberi tahu Anda sedikit tentang persis sekali. Kami sedang mencapai vonis dalam konser, ini sangat penting. Kami menggunakan teknologi yang memberi kami jaminan semacam itu, dan, tentu saja, kami memantau semua perbedaan, kami menguranginya menjadi nol. Bahkan ketika tampaknya ini telah berkurang, dari waktu ke waktu muncul masalah yang sangat rumit yang tidak kami perhitungkan.
Instrumen
Sangat singkat tentang alat yang kami gunakan. Mempertahankan banyak antifraud untuk sistem yang berbeda adalah tugas yang sulit. Kami benar-benar memiliki lusinan layanan yang berbeda, kami membutuhkan semacam tempat di mana Anda dapat melihat keadaan pekerjaan mereka saat ini.
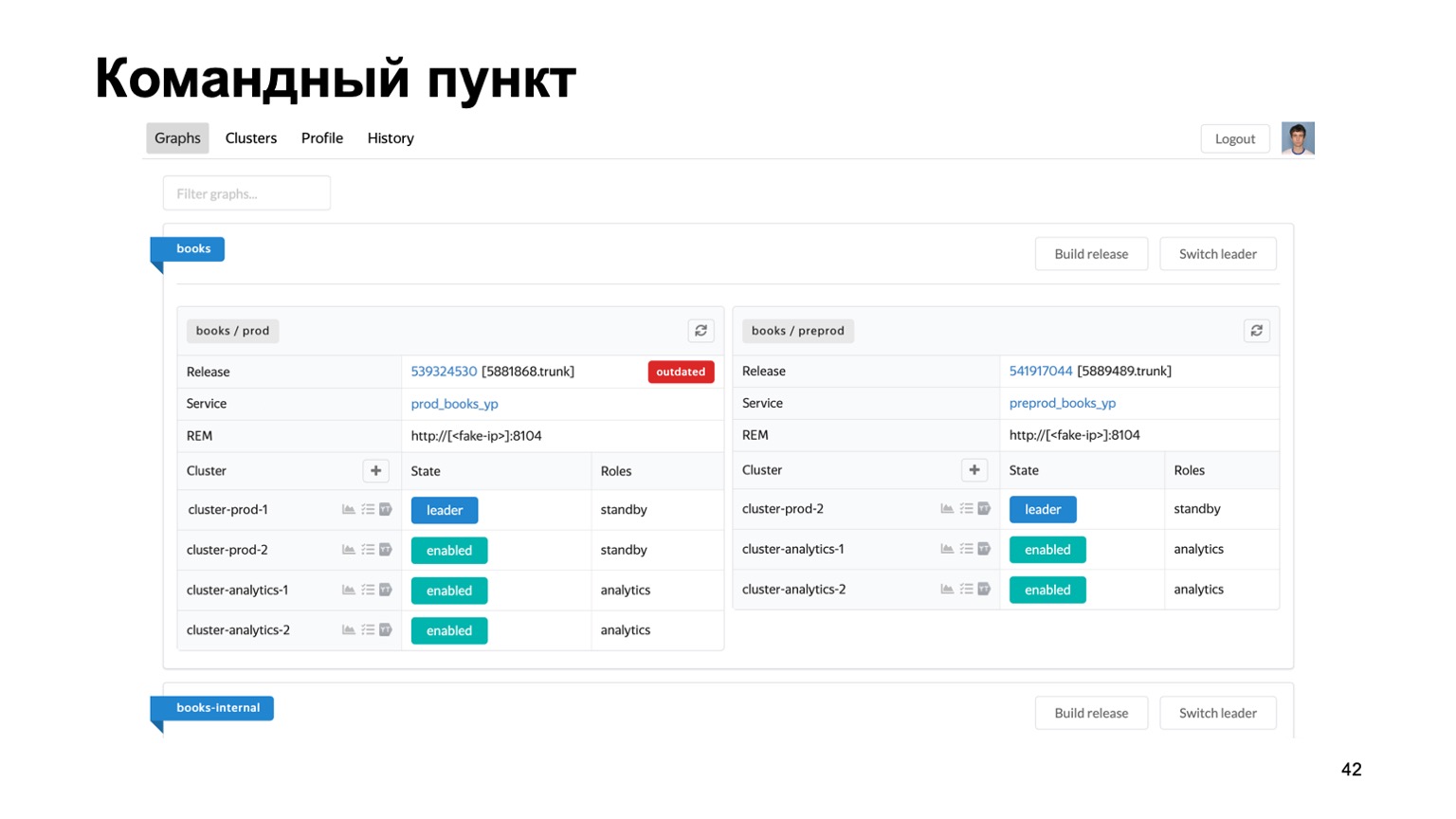
Ini adalah pos komando kami, di mana Anda dapat melihat status cluster yang saat ini kami bekerja. Anda dapat beralih satu sama lain, meluncurkan rilis, dll.
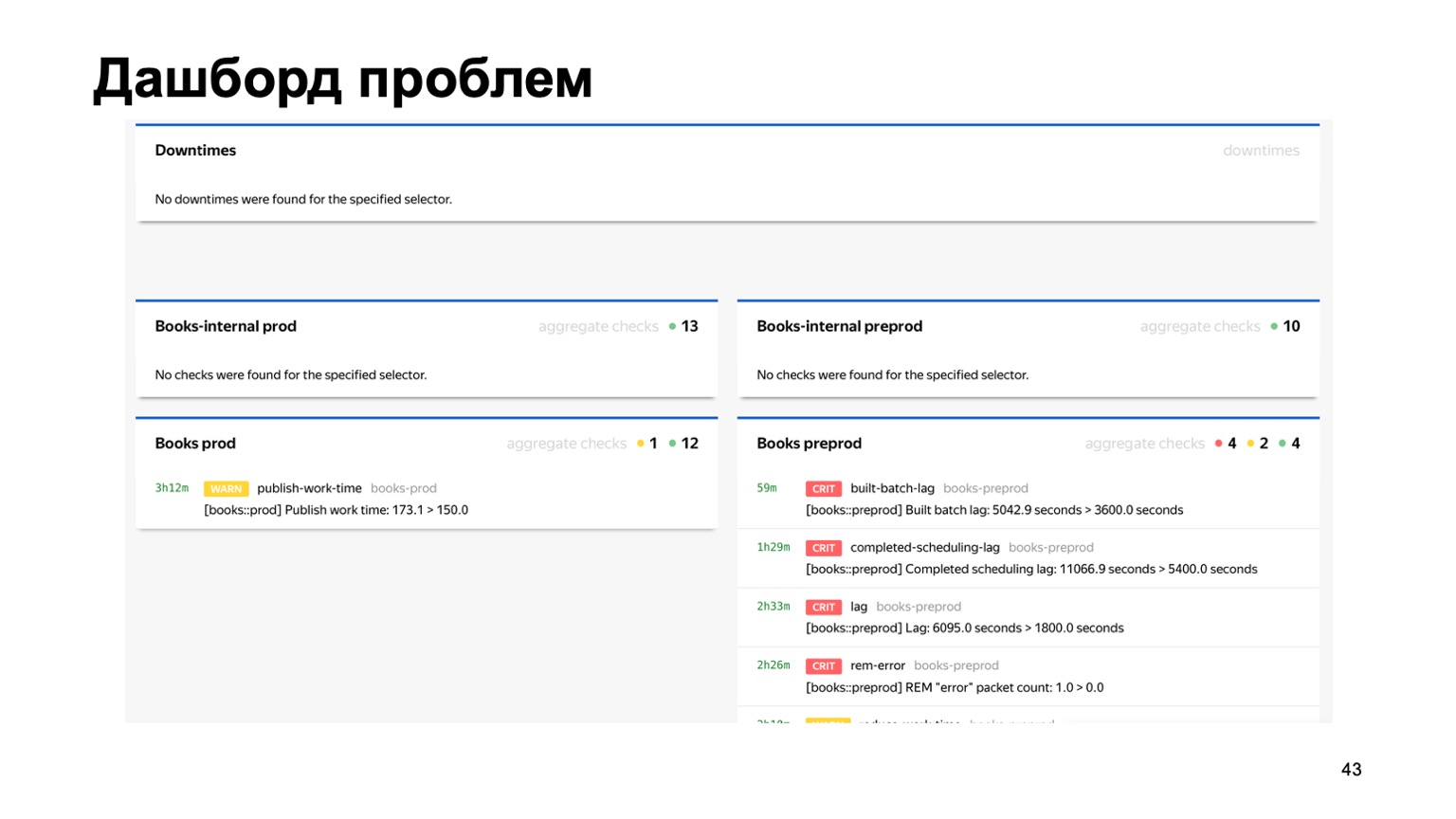
Atau, misalnya, dashboard masalah, di mana kita segera melihat pada satu halaman semua masalah semua antifraud layanan berbeda yang terhubung ke kami. Di sini Anda dapat melihat bahwa ada sesuatu yang salah dengan layanan Buku kami saat ini. Tetapi pemantauan akan berhasil, dan orang yang bertugas akan melihatnya.
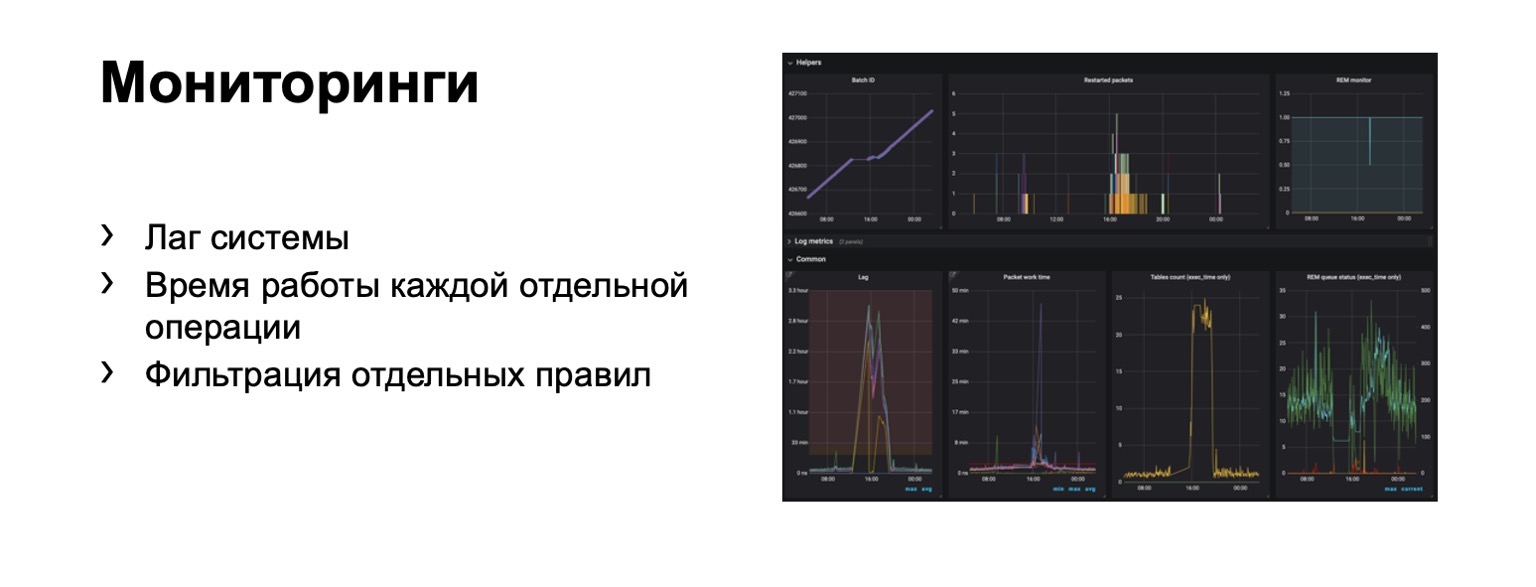
Apa yang kita pantau sama sekali? Jelas, kelambatan sistem sangat penting. Jelas, waktu berjalan setiap tahap individu dan, tentu saja, penyaringan aturan individu. Ini adalah persyaratan bisnis.
Ratusan grafik dan dasbor muncul. Misalnya, di dasbor ini, Anda dapat melihat bahwa konturnya cukup buruk sekarang karena kami mengalami kelambatan yang signifikan.
Mempercepat
Saya akan memberi tahu Anda tentang transisi ke bagian online. Masalahnya di sini adalah bahwa kelambatan dalam rangkaian penuh dapat mencapai beberapa menit. Itu ada di garis besar di MapReduce. Dalam beberapa kasus, kita perlu melarang, mendeteksi penipu lebih cepat.
Apa itu? Misalnya, layanan kami sekarang memiliki kemampuan untuk membeli buku. Dan pada saat yang sama, jenis penipuan pembayaran baru telah muncul. Anda perlu bereaksi lebih cepat. Timbul pertanyaan - bagaimana mentransfer seluruh skema ini, idealnya mempertahankan sebanyak mungkin bahasa interaksi yang akrab bagi analis? Mari kita coba mentransfernya "ke dahi".
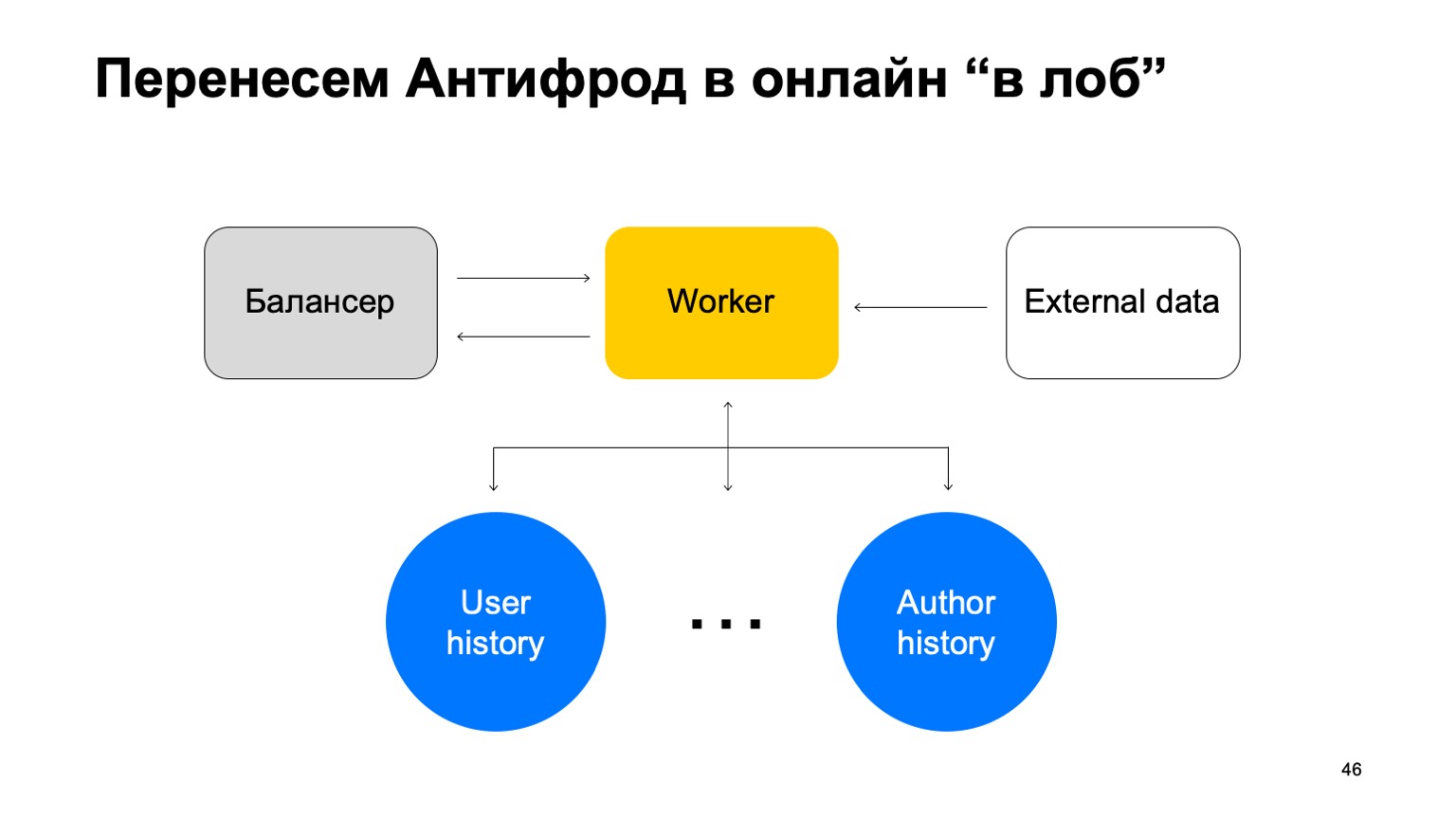
Katakanlah kita memiliki penyeimbang dengan data dari layanan dan sejumlah pekerja di mana kita membuang data dari penyeimbang. Ada data eksternal yang kami gunakan di sini, mereka sangat penting, dan satu set cerita ini. Saya ingatkan Anda bahwa setiap cerita berbeda untuk pengurangan yang berbeda, karena memiliki kunci yang berbeda.
Dalam skema semacam itu, masalah berikut mungkin muncul.
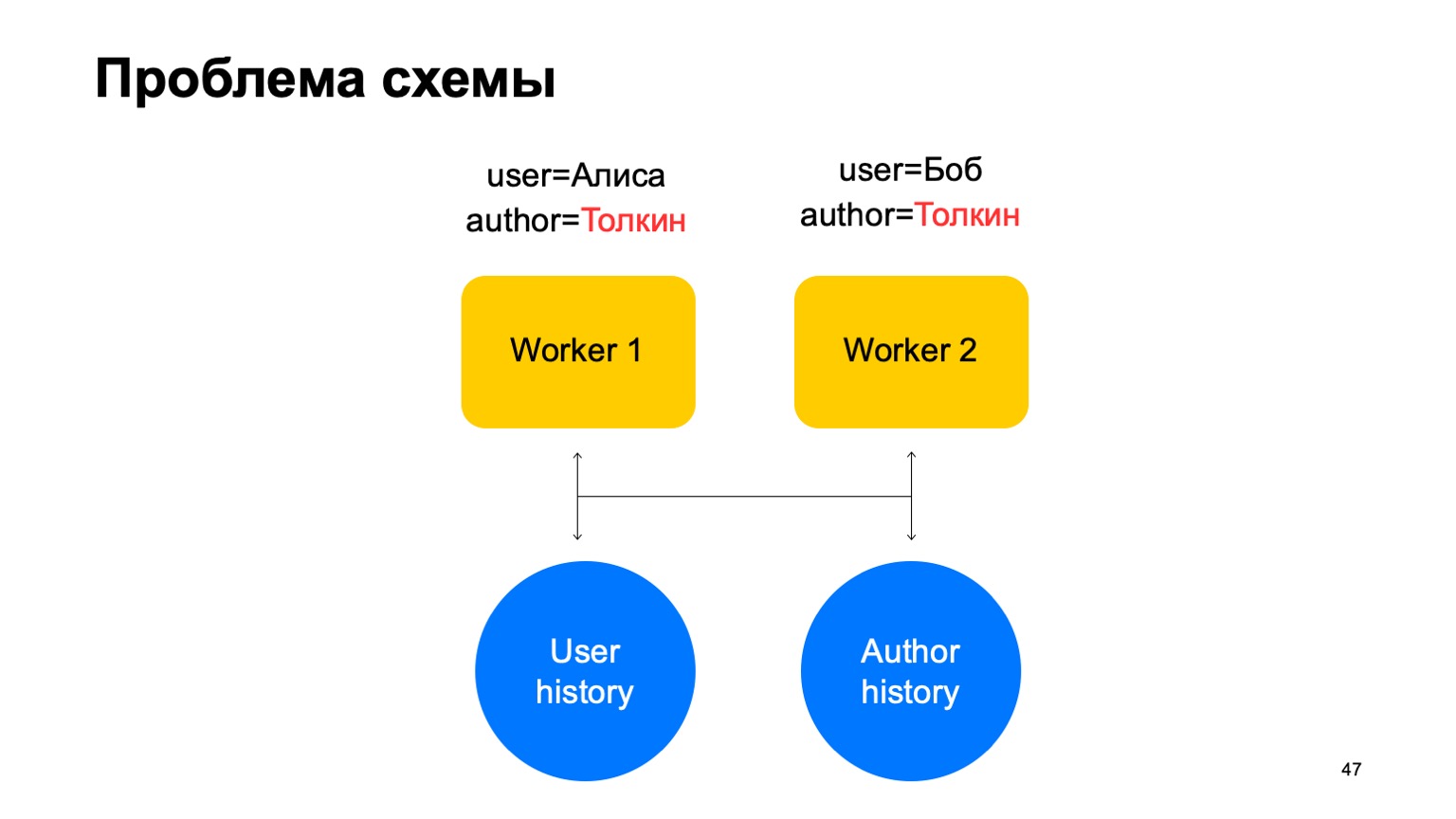
Katakanlah kita memiliki dua acara tentang pekerja kita. Dalam hal ini, dengan pecahan apa pun dari para pekerja ini, sebuah situasi dapat muncul ketika satu kunci mencapai pekerja yang berbeda. Dalam hal ini, ini adalah penulis Tolkien, ia masuk ke dua pekerja.
Kemudian kami membaca data dari penyimpanan bernilai kunci ini untuk kedua pekerja dari sejarah, kami akan memperbaruinya dengan cara yang berbeda dan perlombaan akan muncul ketika kami mencoba membalas.
Solusi: Mari kita membuat asumsi bahwa membaca dan menulis dapat dipisahkan, bahwa menulis dapat terjadi dengan sedikit penundaan. Ini biasanya tidak terlalu penting. Dengan penundaan kecil, maksud saya unit detik di sini. Ini penting, khususnya, karena implementasi kami terhadap penyimpanan nilai kunci ini membutuhkan waktu lebih lama untuk menulis data daripada membacanya.
Kami akan memperbarui statistik dengan lag. Rata-rata, ini bekerja kurang lebih baik, mengingat fakta bahwa kita akan tetap menyimpan cache pada mesin.
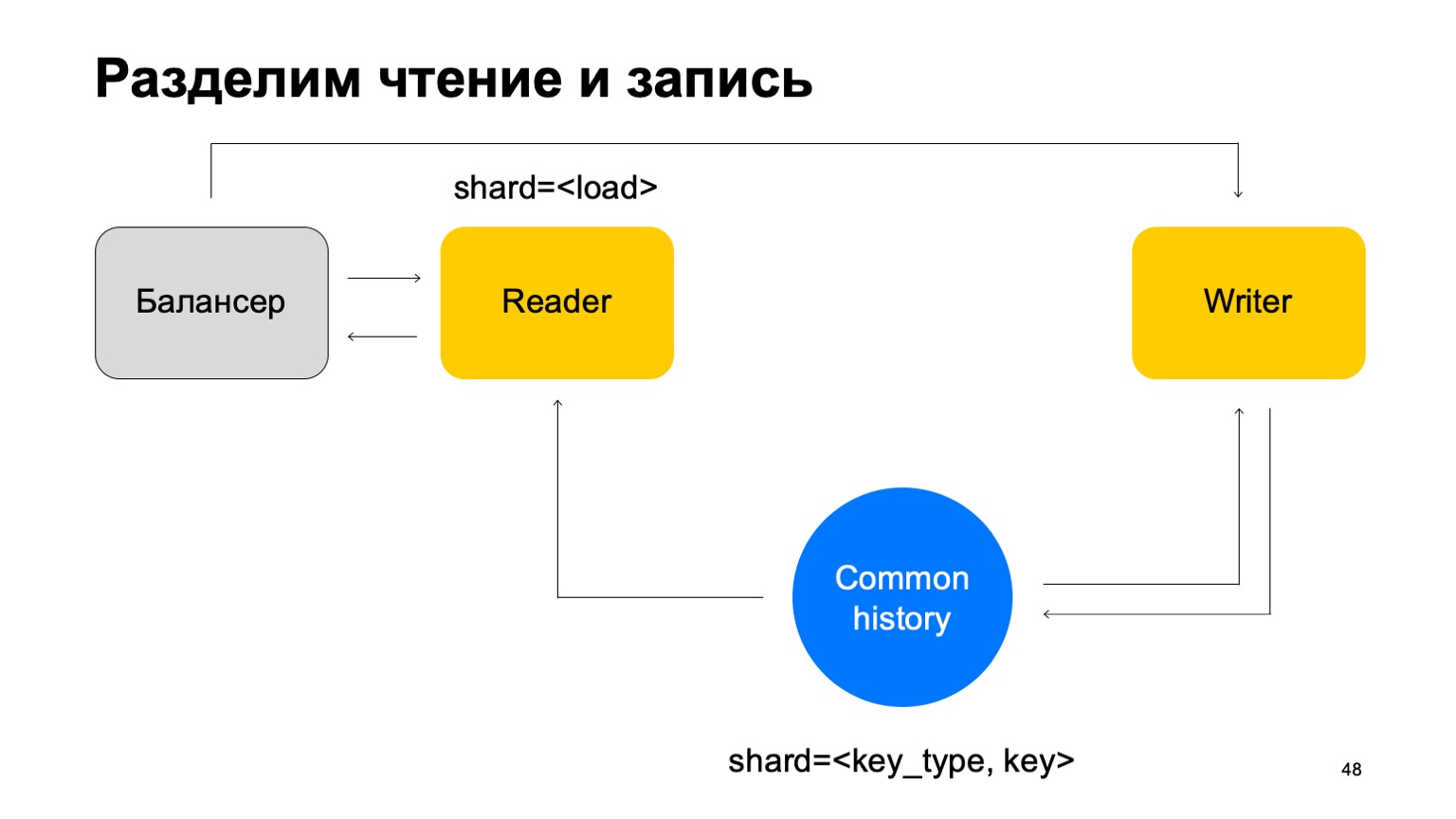
Dan hal lainnya. Untuk kesederhanaan, mari gabungkan cerita-cerita ini menjadi satu dan catat dengan jenis dan kunci potongannya. Kami memiliki semacam sejarah bersama.
Kemudian kita akan menambahkan penyeimbang lagi, menambahkan mesin pembaca, yang dapat di-shard dengan cara apa pun - misalnya, cukup dengan memuat. Mereka hanya akan membaca data ini, menerima putusan akhir dan mengembalikannya ke penyeimbang.
Dalam hal ini, kita membutuhkan seperangkat mesin penulis yang datanya akan dikirim secara langsung. Penulis akan memperbarui cerita yang sesuai. Tapi di sini masalahnya masih muncul, yang saya tulis di atas. Mari kita ubah struktur penulis sedikit.
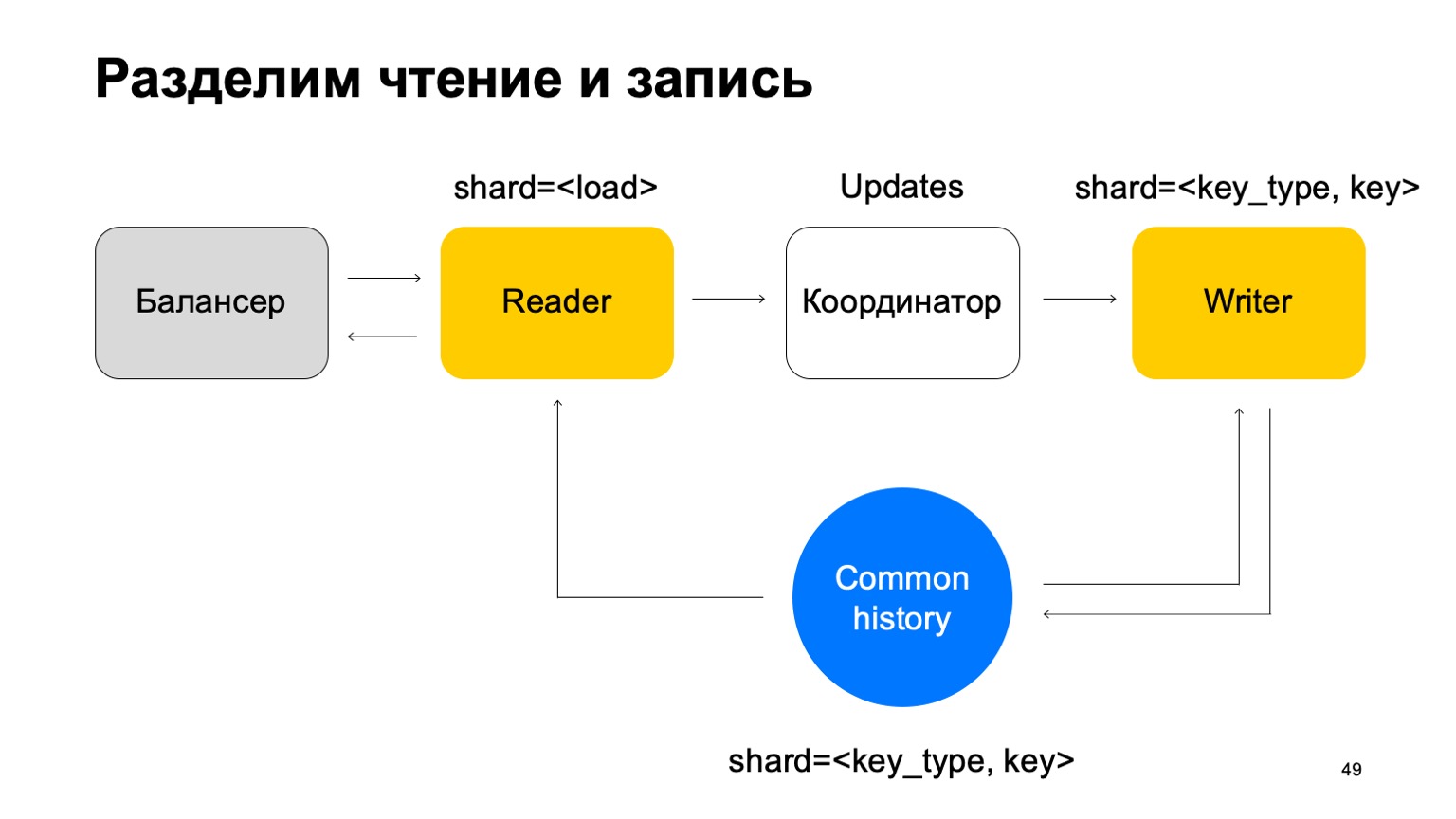
Kami akan membuatnya sehingga terbagi dalam cara yang sama seperti sejarah - berdasarkan jenis dan nilai kunci. Dalam hal ini, ketika pecahannya sama dengan sejarah, kita tidak akan memiliki masalah yang saya sebutkan di atas.
Di sini misinya berubah. Dia tidak lagi menerima vonis. Sebaliknya, ia hanya menerima pembaruan dari Pembaca, mencampurnya, dan menerapkannya dengan benar ke riwayat.
Jelas bahwa komponen diperlukan di sini, koordinator yang mendistribusikan pembaruan ini antara pembaca dan penulis.
Untuk ini, tentu saja, ditambahkan fakta bahwa pekerja perlu mempertahankan cache terbaru. Akibatnya, ternyata kami bertanggung jawab atas ratusan milidetik, terkadang kurang, dan kami memperbarui statistik dalam sedetik. Secara umum itu bekerja dengan baik, untuk layanan itu sudah cukup.

Apa yang kita dapatkan? Analis mulai melakukan pekerjaan mereka lebih cepat dan dengan cara yang sama untuk semua layanan. Ini telah meningkatkan kualitas dan konektivitas semua sistem. Anda dapat menggunakan kembali data antara anti-penipuan dari berbagai layanan, dan layanan baru mendapatkan anti-penipuan berkualitas tinggi dengan cepat.

Beberapa pemikiran di akhir. Jika Anda menulis sesuatu seperti itu, segera pikirkan tentang kenyamanan analis dalam hal dukungan dan perpanjangan sistem ini. Buat semuanya dapat dikonfigurasi, Anda membutuhkannya. Kadang-kadang properti cross-DC dan tepat-sekali sulit untuk dicapai, tetapi mereka bisa. Jika Anda merasa telah mencapainya, periksa kembali. Terima kasih atas perhatian anda