
Tentu saja, NSPK bukan startup, tetapi suasana seperti itu berlaku di perusahaan pada tahun-tahun pertama keberadaannya, dan ini adalah tahun yang sangat menarik. Nama saya Dmitry Kornyakov , saya telah mendukung infrastruktur Linux dengan persyaratan ketersediaan tinggi selama lebih dari 10 tahun. Dia bergabung dengan tim NSPK pada Januari 2016 dan, sayangnya, tidak melihat awal dari keberadaan perusahaan, tetapi datang pada tahap perubahan besar.
Secara umum, kita dapat mengatakan bahwa tim kami memasok 2 produk untuk perusahaan. Yang pertama adalah infrastruktur. Mail harus masuk, DNS harus bekerja, dan pengontrol domain harus membiarkan Anda di server yang tidak boleh jatuh. Lanskap IT perusahaan sangat besar! Ini adalah sistem kritis bisnis & misi, persyaratan ketersediaan untuk sebagian adalah 99.999. Produk kedua adalah server itu sendiri, fisik dan virtual. Yang sudah ada perlu dipantau, dan yang baru secara teratur dipasok ke pelanggan dari banyak departemen. Dalam artikel ini, saya ingin fokus pada bagaimana kami mengembangkan infrastruktur yang bertanggung jawab atas siklus hidup server.
Awal jalur
Pada awal jalur, tumpukan teknologi kami tampak seperti ini:
OS CentOS 7
Pengontrol domain FreeIPA
Automation - Ansible (+ Tower), Cobbler
Semua ini terletak di 3 domain, tersebar di beberapa pusat data. Di satu pusat data - sistem kantor dan situs pengujian, di PROD lainnya.
Pada titik tertentu, membuat server tampak seperti ini:
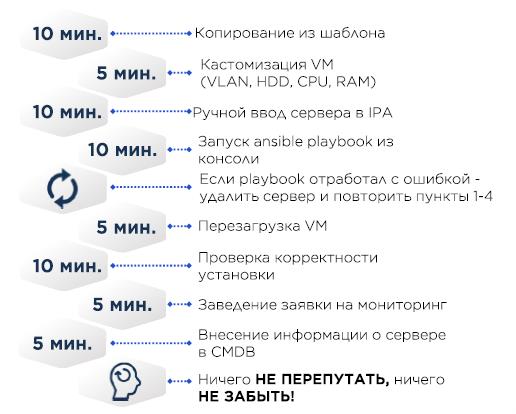
Dalam template minimal VM CentOS dan minimum yang diperlukan, seperti /etc/resolv.conf yang benar, sisanya datang melalui Ansible.
CMDB - Excel.
Jika server bersifat fisik, maka alih-alih menyalin mesin virtual, OS diinstal di atasnya menggunakan Cobbler - alamat MAC dari server target ditambahkan ke konfigurasi Cobbler, server menerima alamat IP melalui DHCP, dan kemudian OS dituangkan.
Pada awalnya, kami bahkan mencoba melakukan semacam manajemen konfigurasi di Cobbler. Namun seiring waktu, ini mulai membawa masalah dengan portabilitas konfigurasi baik ke pusat data lain, dan untuk kode yang mungkin untuk mempersiapkan VM.
Pada saat itu, banyak dari kita yang menganggap Ansible sebagai perpanjangan Bash yang nyaman dan tidak berhemat pada konstruksi menggunakan shell, sed. Secara umum Bashsible. Ini akhirnya mengarah pada fakta bahwa jika playbook karena alasan tertentu tidak berfungsi di server, lebih mudah untuk menghapus server, memperbaiki playbook dan menjalankannya kembali. Faktanya, tidak ada versi skrip, portabilitas konfigurasi juga.
Misalnya, kami ingin mengubah beberapa konfigurasi di semua server:
- Kami mengubah konfigurasi pada server yang ada di segmen logis / pusat data. Terkadang tidak dalam semalam - persyaratan ketersediaan dan undang-undang dalam jumlah besar tidak memungkinkan semua perubahan diterapkan sekaligus. Dan beberapa perubahan berpotensi merusak dan memerlukan memulai kembali apa pun - dari layanan ke OS itu sendiri.
- Memperbaiki dalam Ansible
- Memperbaiki di Cobbler
- Ulangi N kali untuk setiap segmen logis / pusat data
Agar semua perubahan dapat terjadi dengan lancar, banyak faktor harus dipertimbangkan, dan perubahan terus terjadi.
- Refactoring kode yang mungkin, file konfigurasi
- Mengubah praktik terbaik internal
- Perubahan mengikuti analisis insiden / kecelakaan
- Mengubah standar keamanan, baik internal maupun eksternal. Misalnya, PCI DSS diperbarui dengan persyaratan baru setiap tahun
Pertumbuhan infrastruktur dan permulaan jalur.
Jumlah server / domain logis / pusat data bertambah, dan bersama mereka jumlah kesalahan dalam konfigurasi. Pada titik tertentu, kami sampai pada tiga arah, ke arah mana kami perlu mengembangkan manajemen konfigurasi:
- Otomatisasi. Sejauh mungkin, faktor manusia dalam operasi berulang harus dihindari.
- . , . . – , .
- configuration management.
Tetap menambahkan beberapa alat.
Kami memilih GitLab CE sebagai repositori kode kami, paling tidak untuk modul CI / CD bawaan.
Vault of secrets - Hashicorp Vault, termasuk. untuk API yang luar biasa.
Konfigurasi pengujian dan peran yang dimungkinkan - Molekul + Testinfra. Tes berjalan lebih cepat jika terhubung ke mitogen yang dimungkinkan. Pada saat yang sama, kami mulai menulis CMDB kami sendiri dan orkestra untuk penempatan otomatis (dalam gambar di atas Cobbler), tetapi ini adalah cerita yang sama sekali berbeda, yang akan diceritakan oleh kolega saya dan pengembang utama sistem ini di masa mendatang.
Pilihan kami:
Molekul + Testinfra
Ansible + Menara + AWX Server
World + DITNET (Di-rumah)
Cobbler
Gitlab + Pelari GitLab
Hashicorp Vault

Berbicara tentang peran yang mungkin. Pada awalnya itu sendirian, setelah beberapa refactoring ada 17 dari mereka. Saya sangat menyarankan memecah monolith menjadi peran idempoten, yang kemudian dapat dijalankan secara terpisah, Anda juga dapat menambahkan tag. Kami membagi peran berdasarkan fungsi - jaringan, pencatatan, paket, perangkat keras, molekul, dll. Secara umum, kami mengikuti strategi di bawah ini. Saya tidak bersikeras bahwa ini adalah satu-satunya kebenaran, tetapi itu berhasil bagi kita.
- Menyalin server dari "gambar emas" itu jahat!
Kerugian utamanya adalah Anda tidak tahu persis keadaan gambar sekarang, dan bahwa semua perubahan akan terjadi pada semua gambar di semua peternakan virtualisasi. - Gunakan file konfigurasi default seminimal mungkin dan sepakati dengan departemen lain tentang file sistem inti yang menjadi tanggung jawab Anda , misalnya:
- /etc/sysctl.conf , /etc/sysctl.d/. , .
- override systemd .
- , sed
- :
- ! Ansible-lint, yaml-lint, etc
- ! bashsible.
- Ansible molecule .
- , ( 100) 70000 . .

Implementasi kami
Jadi, peran yang memungkinkan telah siap, templated, dan diperiksa oleh linter. Dan bahkan git dibesarkan di mana-mana. Tetapi pertanyaan tentang pengiriman kode yang andal ke segmen yang berbeda tetap terbuka. Kami memutuskan untuk menyinkronkan dengan skrip. Kelihatannya seperti ini:

Setelah perubahan telah tiba, CI diluncurkan, server uji dibuat, peran digulung, diuji dengan molekul. Jika semuanya baik-baik saja, kodenya masuk ke cabang produksi. Tetapi kami tidak menerapkan kode baru ke server yang ada di mesin. Ini adalah semacam penghenti yang diperlukan untuk ketersediaan tinggi sistem kami. Dan ketika infrastruktur menjadi besar, hukum sejumlah besar ikut bermain - bahkan jika Anda yakin bahwa perubahan itu tidak berbahaya, itu dapat menyebabkan konsekuensi yang menyedihkan.
Ada juga banyak opsi untuk membuat server. Kami akhirnya memilih skrip python khusus. Dan untuk CI yang memungkinkan:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"Inilah yang kami datangi, sistem terus hidup dan berkembang.
- 17 peran yang mungkin untuk mengkonfigurasi server. Setiap peran dirancang untuk menyelesaikan tugas logis yang terpisah (pencatatan, audit, otorisasi pengguna, pemantauan, dll.).
- Pengujian peran. Molekul + TestInfra.
- Pengembangan sendiri: CMDB + Orchestrator.
- Waktu pembuatan server ~ 30 menit, otomatis dan praktis independen dari antrian tugas.
- Status / penamaan infrastruktur yang sama di semua segmen - buku pedoman, repositori, elemen virtualisasi.
- Pemeriksaan harian status server dengan pembuatan laporan tentang ketidaksesuaian dengan standar.
Saya harap kisah saya akan bermanfaat bagi mereka yang berada di awal perjalanan. Tumpukan otomatisasi apa yang Anda gunakan?