 Dialogue 2020 , sebuah konferensi ilmiah internasional tentang linguistik komputasi dan teknologi cerdas, baru-baru ini berakhir . Untuk pertama kalinya, Sekolah Phystech Matematika dan Informatika Terapan (FPMI) MIPT menjadi mitra konferensi . Secara tradisional, salah satu peristiwa utama dari Dialog adalah Dialog Evaluation , sebuah kompetisi antara pengembang sistem otomatis untuk analisis teks linguistik. Kami telah berbicara tentang Habré tentang tugas-tugas yang diselesaikan oleh para peserta kompetisi tahun lalu, misalnya, tentang menghasilkan judul dan menemukan kata-kata yang hilang dalam teks.. Hari ini kami berbicara dengan para pemenang dari dua lagu Evaluasi Dialog tahun ini - Vladislav Korzun dan Daniil Anastasyev - tentang mengapa mereka memutuskan untuk berpartisipasi dalam kompetisi teknologi, masalah apa dan dalam cara apa mereka memecahkan, apa yang orang-orang tertarik, di mana mereka belajar dan apa yang mereka rencanakan untuk dilakukan di masa depan. Selamat datang di kucing!
Dialogue 2020 , sebuah konferensi ilmiah internasional tentang linguistik komputasi dan teknologi cerdas, baru-baru ini berakhir . Untuk pertama kalinya, Sekolah Phystech Matematika dan Informatika Terapan (FPMI) MIPT menjadi mitra konferensi . Secara tradisional, salah satu peristiwa utama dari Dialog adalah Dialog Evaluation , sebuah kompetisi antara pengembang sistem otomatis untuk analisis teks linguistik. Kami telah berbicara tentang Habré tentang tugas-tugas yang diselesaikan oleh para peserta kompetisi tahun lalu, misalnya, tentang menghasilkan judul dan menemukan kata-kata yang hilang dalam teks.. Hari ini kami berbicara dengan para pemenang dari dua lagu Evaluasi Dialog tahun ini - Vladislav Korzun dan Daniil Anastasyev - tentang mengapa mereka memutuskan untuk berpartisipasi dalam kompetisi teknologi, masalah apa dan dalam cara apa mereka memecahkan, apa yang orang-orang tertarik, di mana mereka belajar dan apa yang mereka rencanakan untuk dilakukan di masa depan. Selamat datang di kucing!
Vladislav Korzun, pemenang trek Dialog Evaluation RuREBus-2020

Apa yang kamu kerjakan?
Saya seorang pengembang di NLP Advanced Research Group di ABBYY. Kami saat ini sedang menyelesaikan tugas pembelajaran satu langkah untuk mengekstraksi entitas. Artinya, dengan memiliki sampel pelatihan kecil (5-10 dokumen), Anda perlu mempelajari cara mengekstraksi entitas tertentu dari dokumen serupa. Untuk ini, kita akan menggunakan output dari model NER yang dilatih pada tipe entitas standar (Person, Lokasi, Organisasi) sebagai fitur untuk menyelesaikan masalah ini. Kami juga berencana untuk menggunakan model bahasa khusus, yang dilatih tentang dokumen yang serupa dengan tugas kami.
Tugas apa yang Anda selesaikan di Evaluasi Dialog?
Di Dialog, saya ikut serta dalam kompetisi RuREBus yang didedikasikan untuk mengekstraksi entitas dan hubungan dari dokumen spesifik korpus Kementerian Pembangunan Ekonomi. Kasing ini sangat berbeda dari kasing yang digunakan, misalnya, dalam kompetisi Conll . Pertama, jenis-jenis entitas itu sendiri tidak standar (Orang, Lokasi, Organisasi), di antara mereka bahkan ada tindakan yang tidak disebutkan namanya dan substantif. Kedua, teks-teks itu sendiri bukan set kalimat terverifikasi, tetapi dokumen nyata, yang mengarah ke berbagai daftar, judul, dan bahkan tabel. Akibatnya, kesulitan utama muncul justru dengan pemrosesan data, dan bukan dengan menyelesaikan masalah. sebenarnya, ini adalah tugas klasik Named Entity Recognition dan Relation Extraction.
Dalam kompetisi itu sendiri, ada 3 lagu: NER, RE dengan entitas yang diberikan, dan RE end-to-end. Saya mencoba memecahkan dua yang pertama. Dalam tugas pertama, saya menggunakan pendekatan klasik. Pertama, saya mencoba menggunakan jaringan berulang sebagai model, dan embt embt kata cepat, pola kapitalisasi, embaut simbolis dan tag POS sebagai fitur [1]. Kemudian saya telah menggunakan berbagai BERT yang dipra-latihan sebelumnya, yang cukup unggul dari pendekatan saya sebelumnya. Namun, ini tidak cukup untuk mengambil tempat pertama di trek ini.
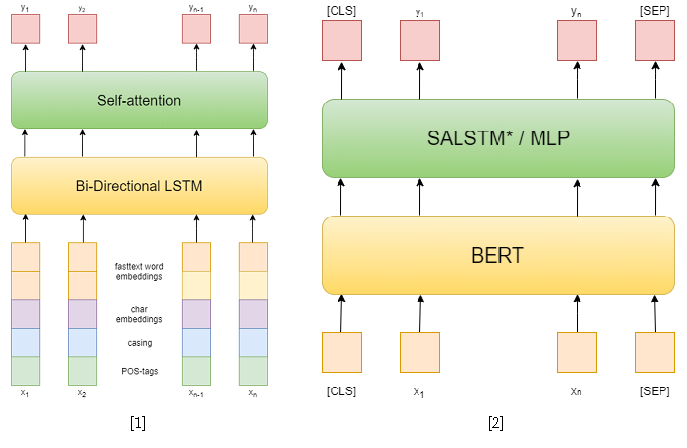
Tetapi di jalur kedua saya berhasil. Untuk memecahkan masalah mengekstraksi relasi, saya menguranginya menjadi masalah mengklasifikasikan relasi, mirip dengan SemEval 2010 Tugas 8 . Dalam masalah ini, untuk setiap kalimat, sepasang entitas diberikan, yang hubungannya harus diklasifikasikan. Dan dalam sebuah lagu, setiap kalimat dapat berisi sebanyak entitas yang Anda inginkan, namun, itu hanya mengurangi yang sebelumnya dengan mengambil sampel kalimat untuk setiap pasangan entitas. Juga, selama pelatihan, saya mengambil contoh negatif secara acak untuk setiap kalimat dalam ukuran tidak melebihi dua kali jumlah yang positif untuk mengurangi sampel pelatihan.
Sebagai pendekatan untuk memecahkan masalah mengklasifikasikan hubungan, saya menggunakan dua model berdasarkan BERT-e. Dalam yang pertama, saya hanya menggabungkan output BERT dengan embedded NER dan kemudian rata-rata fitur untuk setiap token menggunakan Self-attention [3]. Salah satu solusi terbaik untuk SemEval 2010 Tugas 8 - R-BERT [4] diambil sebagai model kedua. Inti dari pendekatan ini adalah sebagai berikut: menyisipkan token khusus sebelum dan setelah setiap entitas, rata-rata output BERT untuk token masing-masing entitas, menggabungkan vektor yang dihasilkan dengan output yang sesuai dengan token CLS, dan mengklasifikasikan vektor fitur yang dihasilkan. Akibatnya, model ini menempati posisi pertama di lintasan. Hasil kompetisi tersedia di sini .
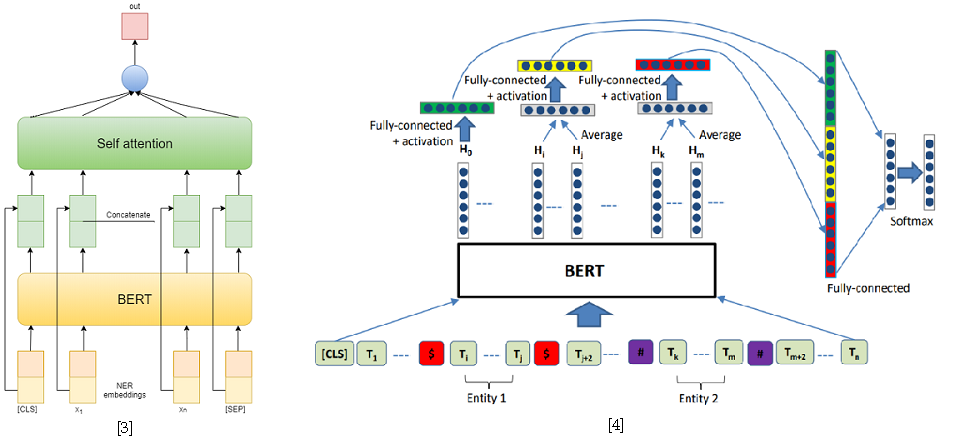
[4] Wu, S., He, Y. (2019, November). Memperkaya model bahasa pra-terlatih dengan informasi entitas untuk klasifikasi hubungan. Dalam Prosiding Konferensi Internasional ACM ke-28 tentang Manajemen Informasi dan Pengetahuan ( hlm. 2361-2364 ).
Apa yang menurut Anda paling sulit dalam tugas-tugas ini?
Yang paling bermasalah adalah pemrosesan kasus. Tugas-tugas itu sendiri adalah seringkas mungkin, untuk solusi mereka sudah ada kerangka kerja yang sudah jadi, misalnya, AllenNLP. Tetapi jawabannya perlu diberikan dengan menghemat rentang token, jadi saya tidak bisa hanya menggunakan pipa yang sudah jadi tanpa menulis banyak kode tambahan. Oleh karena itu, saya memutuskan untuk menulis seluruh pipa dalam PyTorch murni agar tidak ketinggalan apa pun. Meskipun saya masih menggunakan beberapa modul dari AllenNLP.
Ada juga banyak kalimat yang agak panjang di dalam corpus, yang menyebabkan ketidaknyamanan ketika mengajar transformer besar, misalnya, BERT, karena mereka menjadi menuntut pada memori video dengan bertambahnya panjang kalimat. Namun, sebagian besar kalimat-kalimat ini adalah penghitungan titik koma dan dapat dipisahkan oleh karakter itu. Saya hanya membagi penawaran yang tersisa dengan jumlah token maksimum.
Sudahkah Anda berpartisipasi dalam Dialog dan trek sebelumnya?
Tahun lalu saya berbicara dengan gelar master saya di sesi siswa.
Mengapa Anda memutuskan untuk berpartisipasi dalam kompetisi tahun ini?
Pada saat ini, saya baru saja menyelesaikan masalah penggalian hubungan, tetapi untuk korps yang berbeda. Saya mencoba menggunakan pendekatan berbeda berdasarkan pohon parse. Jalur di pohon dari satu entitas ke entitas lain digunakan sebagai input. Tetapi pendekatan ini, sayangnya, tidak menunjukkan hasil yang kuat, meskipun itu setingkat dengan pendekatan yang didasarkan pada jaringan berulang, menggunakan token embeddings dan fitur lainnya sebagai tanda, seperti panjang jalan dari token ke root atau salah satu entitas di pohon sintaksis. parsing, serta posisi relatif entitas.
Dalam kompetisi ini, saya memutuskan untuk berpartisipasi, karena saya sudah memiliki beberapa dasar untuk menyelesaikan masalah yang sama. Dan mengapa tidak menerapkannya dalam kompetisi dan dipublikasikan? Ternyata tidak semudah yang saya kira, tapi itu lebih karena masalah dengan interaksi dengan lambung. Sebagai hasilnya, bagi saya itu lebih merupakan tugas rekayasa daripada penelitian.
Sudahkah Anda berpartisipasi dalam kompetisi lain?
Pada saat yang sama, tim kami berpartisipasi di SemEval . Ilya Dimov terutama terlibat dalam tugas itu, saya hanya menyarankan beberapa ide. Ada tugas mengklasifikasikan propaganda: rentang teks dipilih dan perlu untuk mengklasifikasikannya. Saya menyarankan menggunakan pendekatan R-BERT, yaitu, untuk memilih entitas ini dalam token, masukkan token khusus di depannya dan setelah itu, dan rata-rata hasilnya. Hasilnya, ini memberi sedikit peningkatan. Ini adalah nilai ilmiah: untuk menyelesaikan masalah, kami menggunakan model yang dirancang untuk sesuatu yang sama sekali berbeda.
Saya juga ambil bagian dalam ABBYY hackathon, di ACM icpc - kompetisi dalam pemrograman olahraga di tahun-tahun pertama. Kami tidak pergi terlalu jauh, tapi itu menyenangkan. Kompetisi seperti ini sangat berbeda dari yang disajikan di Dialog, di mana ada cukup waktu untuk dengan tenang mengimplementasikan dan menguji beberapa pendekatan. Di hackathon, Anda perlu melakukan segalanya dengan cepat, tidak ada waktu untuk bersantai, tidak ada teh. Tapi ini keindahan acara semacam itu - mereka memiliki atmosfer yang spesifik.
Apa masalah paling menarik yang Anda selesaikan di kompetisi atau di tempat kerja?
Ada kompetisi generasi gesture GENEA segera hadir dan saya akan pergi ke sana. Saya pikir ini akan menarik. Ini adalah lokakarya di ACM - Konferensi Internasional tentang Agen Virtual Cerdas . Dalam kompetisi ini, diusulkan untuk menghasilkan gerakan untuk model manusia 3D berdasarkan suara. Saya berbicara tahun ini di Dialog dengan topik yang sama, membuat ikhtisar kecil pendekatan untuk masalah generasi otomatis ekspresi wajah dan gerakan dari suara. Saya perlu mendapatkan pengalaman, karena saya masih harus mempertahankan disertasi saya pada topik yang sama. Saya ingin mencoba membuat agen baca virtual, dengan ekspresi wajah, gerakan, dan tentu saja, suara. Pendekatan saat ini untuk sintesis pidato memungkinkan untuk menghasilkan pidato yang cukup realistis dari teks, sementara pendekatan generasi gerakan memungkinkan untuk menghasilkan gerakan dari suara. Jadi mengapa tidak menggabungkan pendekatan ini.
Ngomong-ngomong, di mana kamu belajar sekarang?
Saya seorang mahasiswa pascasarjana di Departemen Linguistik Komputasi di ABBYY di Sekolah Phystech Matematika dan Informatika Terapan di MIPT . Saya akan mempertahankan tesis saya dalam dua tahun.
Pengetahuan dan keterampilan apa yang diperoleh di universitas membantu Anda sekarang?
Cukup aneh, matematika. Meskipun saya tidak mengintegrasikan setiap hari dan tidak melipatgandakan matriks di kepala saya, matematika mengajarkan pemikiran analitis dan kemampuan untuk mencari tahu apa pun. Lagipula, ujian apa pun mencakup pembuktian teorema, dan mencoba mempelajarinya tidak berguna, tetapi memahami dan membuktikan diri sendiri, hanya mengingat ide, adalah mungkin. Kami juga memiliki kursus pemrograman yang baik, di mana kami belajar dari tingkat rendah untuk memahami bagaimana semuanya bekerja, menganalisis berbagai algoritma dan struktur data. Dan sekarang tidak akan menjadi masalah untuk berurusan dengan kerangka kerja baru atau bahkan bahasa pemrograman. Ya, tentu saja, kami memiliki kursus dalam pembelajaran mesin, dan di NLP, khususnya, tetapi tetap saja, tampaknya bagi saya keterampilan dasar lebih penting.
Daniil Anastasyev, pemenang trek Dialog Evaluation GramEval-2020

Apa yang kamu kerjakan?
Saya mengembangkan asisten suara "Alice", saya bekerja dalam mencari kelompok makna. Kami menganalisis permintaan yang datang ke Alice. Contoh standar permintaan adalah "Bagaimana cuaca di Moskow besok?" Anda perlu memahami bahwa ini adalah permintaan tentang cuaca, bahwa permintaan menanyakan tentang lokasi (Moskow) dan ada indikasi waktu (besok).
Ceritakan kepada kami tentang masalah yang Anda selesaikan tahun ini di salah satu trek Evaluasi Dialog.
Saya melakukan tugas yang sangat dekat dengan apa yang dilakukan ABBYY. Itu perlu untuk membangun model yang akan menganalisis kalimat, membuat analisis morfologis dan sintaksis, dan mendefinisikan lemma. Ini sangat mirip dengan apa yang mereka lakukan di sekolah. Butuh waktu sekitar 5 hari libur untuk membangun model.

Model itu dipelajari dalam bahasa Rusia normal, tetapi, seperti yang Anda lihat, model ini juga berfungsi dalam bahasa yang ada dalam masalah.
Apakah ini terdengar seperti apa yang Anda lakukan di tempat kerja?
Mungkin tidak. Di sini Anda perlu memahami bahwa tugas ini sendiri tidak memiliki banyak arti - tugas ini diselesaikan sebagai subtugas dalam kerangka penyelesaian beberapa masalah bisnis yang penting. Jadi, misalnya, di ABBYY, tempat saya pernah bekerja, analisis morfo-sintaksis adalah tahap awal dalam menyelesaikan masalah ekstraksi informasi. Dalam kerangka tugas saya saat ini, saya tidak perlu analisis seperti itu. Namun, pengalaman tambahan bekerja dengan model bahasa pra-pelatihan seperti BERT terasa seperti itu tentu berguna untuk pekerjaan saya. Secara umum, ini adalah motivasi utama untuk berpartisipasi - saya tidak ingin menang, tetapi untuk berlatih dan mendapatkan beberapa keterampilan yang berguna. Selain itu, diploma saya sebagian terkait dengan topik masalah.
Sudahkah Anda berpartisipasi dalam Evaluasi Dialog sebelumnya?
Berpartisipasi dalam trek MorphoRuEval-2017 pada tahun ke-5 dan juga menempati posisi pertama. Maka itu perlu untuk mendefinisikan hanya morfologi dan lemma, tanpa hubungan sintaksis.
Apakah realistis untuk menerapkan model Anda ke tugas lain sekarang?
Ya, model saya dapat digunakan untuk tugas-tugas lain - Saya telah memposting semua kode sumber. Saya berencana untuk memposting kode menggunakan model yang lebih ringan dan lebih cepat tetapi kurang akurat. Secara teori, jika ada yang mau, model saat ini dapat digunakan. Masalahnya adalah itu akan terlalu besar dan lambat bagi kebanyakan orang. Dalam kompetisi, tidak ada yang peduli dengan kecepatan, menarik untuk mencapai kualitas setinggi mungkin, tetapi dalam aplikasi praktis, semuanya biasanya sebaliknya. Oleh karena itu, manfaat utama dari model besar tersebut adalah mengetahui kualitas apa yang paling dapat dicapai untuk memahami apa yang Anda korbankan.
Mengapa Anda berpartisipasi dalam Evaluasi Dialog dan kompetisi serupa lainnya?
Hackathon dan kompetisi semacam itu tidak terkait langsung dengan pekerjaan saya, tetapi itu masih merupakan pengalaman yang berharga. Misalnya, ketika saya berpartisipasi dalam hackathon AI Journey tahun lalu, saya belajar beberapa hal yang kemudian saya gunakan dalam pekerjaan saya. Tugasnya adalah mempelajari cara lulus ujian dalam bahasa Rusia, yaitu menyelesaikan tes dan menulis esai. Jelas bahwa semua ini tidak ada hubungannya dengan pekerjaan. Tetapi kemampuan untuk dengan cepat menghasilkan dan melatih model yang memecahkan beberapa masalah sangat berguna. Ngomong-ngomong, tim saya dan saya memenangkan tempat pertama.
Pendidikan apa yang Anda dapatkan dan apa yang Anda lakukan setelah universitas?
Dia lulus dari gelar Sarjana dan Master dari Departemen Linguistik Komputasi ABBYY di Institut Fisika dan Teknologi Moskow, lulus pada 2018. Dia juga belajar di School of Data Analysis (SHAD). Ketika tiba saatnya untuk memilih departemen dasar di tahun ke-2, sebagian besar kelompok kami pergi ke departemen ABBYY - linguistik komputasi atau pengenalan gambar dan pemrosesan teks. Di program sarjana kami diajarkan untuk memprogram dengan baik - ada kursus yang sangat berguna. Dari tahun ke-4 saya bekerja di ABBYY selama 2,5 tahun. Pertama, dalam grup morfologi, maka saya terlibat dalam tugas yang berkaitan dengan model bahasa untuk meningkatkan pengenalan teks di ABBYY FineReader. Saya menulis kode, model yang terlatih, sekarang saya melakukan hal yang sama, tetapi untuk produk yang sama sekali berbeda.
Bagaimana Anda menghabiskan waktu luang Anda?
Saya suka membaca buku. Tergantung pada musim, saya mencoba lari atau ski. Saya suka fotografi saat bepergian.
Apakah Anda memiliki rencana atau sasaran untuk 5 tahun ke depan?
5 tahun terlalu jauh perencanaan horizon. Saya bahkan tidak memiliki 5 tahun pengalaman kerja. Selama 5 tahun terakhir, banyak yang telah berubah, sekarang ada perasaan yang berbeda dari kehidupan. Saya hampir tidak bisa membayangkan apa lagi yang bisa berubah, tetapi ada pemikiran untuk mendapatkan gelar PhD di luar negeri.
Apa saran yang dapat Anda berikan kepada pengembang muda yang terlibat dalam linguistik komputasi dan berada di awal perjalanan mereka?
Yang terbaik adalah berlatih, mencoba dan bersaing. Pemula yang lengkap dapat mengikuti salah satu dari banyak kursus: misalnya, dari SHAD , DeepPavlov, atau bahkan saya sendiri, yang pernah saya ajarkan di ABBYY.
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .