
Ada lebih dari 600 pizza di Dodo Pizza di 13 negara di dunia, dan sebagian besar proses dalam pizza dikendalikan oleh sistem informasi IS Dodo , yang kami sendiri tulis dan pelihara. Oleh karena itu, keandalan dan stabilitas sistem sangat penting untuk kelangsungan hidup.
Sekarang stabilitas dan keandalan sistem informasi di perusahaan didukung oleh tim SRE ( Site Reliability Engineering ), tetapi ini tidak selalu terjadi.
Latar Belakang: Dunia Paralel dari Pengembang dan Infrastruktur
Selama bertahun-tahun saya mengembangkan sebagai pengembang fullstack (dan sedikit master scrum), belajar menulis kode yang baik, menerapkan praktik-praktik dari Extreme Programming dan dengan hati-hati mengurangi jumlah WTF dalam proyek yang saya sentuh. Tetapi semakin banyak pengalaman yang saya dapatkan dalam pengembangan perangkat lunak, semakin saya menyadari pentingnya sistem pemantauan dan penelusuran yang andal untuk aplikasi, log berkualitas tinggi, pengujian otomatis total, dan mekanisme yang memastikan keandalan layanan yang tinggi. Dan semakin sering dia mulai mencari "melewati pagar" kepada tim infrastruktur.
Semakin baik saya memahami lingkungan di mana kode saya bekerja, semakin saya terkejut: tes otomatis untuk semuanya dan semua orang, CI, rilis sering, refactoring aman dan kepemilikan kode kolektif di dunia perangkat lunak telah lama menjadi biasa dan akrab. Pada saat yang sama, di dunia "infrastruktur", tidak adanya pengujian otomatis, membuat perubahan pada sistem produksi dalam mode semi-manual masih normal, dan dokumentasi seringkali hanya di kepala individu, tetapi tidak dalam kode.
Kesenjangan budaya dan teknologi ini menyebabkan tidak hanya kebingungan, tetapi juga masalah: di persimpangan pembangunan, infrastruktur dan bisnis. Beberapa masalah infrastruktur sulit ditangani karena kedekatannya dengan perangkat keras dan alat yang relatif kurang berkembang. Tetapi sisanya dapat dikalahkan jika Anda mulai melihat semua buku pedoman dan skrip Bash yang mungkin Anda miliki sebagai produk perangkat lunak lengkap dan menerapkan persyaratan yang sama dengannya.
Segitiga Masalah Bermuda
Namun, saya akan mulai dari jauh - dengan masalah yang dibutuhkan semua tarian ini.
Masalah pengembang
Dua tahun yang lalu, kami menyadari bahwa jaringan besar pizza tidak dapat hidup tanpa aplikasi seluler kami sendiri dan memutuskan untuk menulisnya:
- menyusun tim yang hebat;
- selama enam bulan mereka menulis aplikasi yang nyaman dan indah;
- mendukung peluncuran besar dengan promosi lezat;
- dan pada hari pertama jatuh dengan aman di bawah beban.
Ada banyak kusen pada awalnya, tentu saja, tetapi yang paling penting saya ingat satu. Pada saat pengembangan, server yang lemah dikerahkan pada produksi, hampir kalkulator yang memproses permintaan dari aplikasi. Sebelum pengumuman aplikasi diumumkan kepada publik, aplikasi itu harus ditingkatkan - kami tinggal di Azure, dan ini diselesaikan dengan mengklik tombol.
Tapi tidak ada yang menekan tombol ini: tim infrastruktur bahkan tidak tahu bahwa aplikasi sedang dirilis hari ini. Mereka memutuskan bahwa itu adalah tanggung jawab tim aplikasi untuk mengawasi produksi layanan "tidak kritis". Dan pengembang backend (ini adalah proyek pertamanya di Dodo) memutuskan bahwa orang-orang dari infrastruktur melakukan ini di perusahaan besar.
Pengembang itu adalah saya. Kemudian saya menyimpulkan sendiri aturan yang jelas tapi penting:
, , , . .
Sekarang tidak sulit. Dalam beberapa tahun terakhir, sejumlah besar alat telah muncul yang memungkinkan programmer untuk melihat ke dunia eksploitasi dan tidak merusak apa pun: Prometheus, Zipkin, Jaeger, tumpukan ELK, Kusto.
Namun demikian, banyak pengembang masih memiliki masalah serius dengan apa yang disebut infrastruktur / DevOps / SRE. Akibatnya, programmer:
Bergantung pada tim infrastruktur. Ini menyebabkan rasa sakit, kesalahpahaman, kadang-kadang saling membenci.
Mereka merancang sistem mereka secara terpisah dari kenyataan dan tidak memperhitungkan di mana dan bagaimana kode mereka akan dieksekusi. Misalnya, arsitektur dan desain sistem yang sedang dikembangkan untuk kehidupan di cloud akan berbeda dari sistem yang di-host di lokasi.
Mereka tidak memahami sifat bug dan masalah yang terkait dengan kode mereka.Ini terutama terlihat ketika masalah terkait dengan memuat, menyeimbangkan permintaan, kinerja jaringan atau hard drive. Pengembang tidak selalu memiliki pengetahuan ini.
Tidak dapat mengoptimalkan uang dan sumber daya perusahaan lainnya yang digunakan untuk mempertahankan kode mereka. Dalam pengalaman kami, kebetulan tim infrastruktur hanya mengisi masalah dengan uang, misalnya, meningkatkan ukuran server database pada produksi. Oleh karena itu, masalah kode sering kali tidak mencapai programmer. Hanya karena alasan tertentu infrastruktur mulai membutuhkan biaya lebih besar.
Masalah infrastruktur
Ada juga kesulitan di "sisi lain".
Sulit untuk mengelola lusinan layanan dan lingkungan tanpa kode kualitas. Saat ini kami memiliki lebih dari 450 repositori di GitHub. Beberapa dari mereka tidak memerlukan dukungan operasional, ada yang mati dan disimpan untuk sejarah, tetapi sebagian besar berisi layanan yang perlu didukung. Mereka perlu meng-host di suatu tempat, mereka membutuhkan pemantauan, mengumpulkan log, pipa CI / CD yang seragam.
Untuk mengelola semua ini, kami baru-baru ini secara aktif menggunakan Ansible. Repositori Ansible kami berisi:
- 60 peran;
- 102 buku pedoman;
- mengikat Python dan Bash;
- tes manual di Vagrant.
Itu semua ditulis oleh orang yang cerdas dan ditulis dengan baik. Tetapi, segera setelah pengembang lain dari infrastruktur dan programer mulai aktif bekerja dengan kode ini, ternyata buku pedoman pecah, dan peran digandakan dan "ditumbuhi lumut."
Alasannya adalah bahwa kode ini tidak menggunakan banyak praktik standar di dunia pengembangan perangkat lunak. Itu tidak memiliki pipa CI / CD, dan tesnya rumit dan lambat, jadi semua orang terlalu malas atau "tidak ada waktu" untuk menjalankannya secara manual, apalagi menulis yang baru. Kode semacam itu akan hancur jika lebih dari satu orang mengerjakannya.
Tanpa pengetahuan tentang kode, sulit untuk merespons insiden secara efektif.Ketika peringatan datang ke PagerDuty jam 3 pagi, Anda harus mencari seorang programmer yang akan menjelaskan apa dan bagaimana. Misalnya, bahwa 500 kesalahan ini memengaruhi pengguna, sementara yang lain dikaitkan dengan layanan sekunder, pelanggan akhir tidak melihatnya dan Anda dapat meninggalkan semuanya seperti itu sampai pagi. Tetapi pada jam tiga pagi sulit untuk membangunkan programmer, jadi disarankan untuk memahami bagaimana kode yang Anda dukung bekerja.
Banyak alat memerlukan penyisipan dalam kode aplikasi. Orang-orang dari infrastruktur tahu apa yang harus dipantau, cara login dan hal-hal apa yang harus diperhatikan untuk pelacakan. Tetapi mereka sering tidak dapat menanamkan semua ini ke dalam kode aplikasi. Dan mereka yang tidak bisa tahu apa dan bagaimana menanamkan.
"Telepon rusak".Menjelaskan apa dan bagaimana memonitor untuk keseratus kalinya itu tidak menyenangkan. Lebih mudah untuk menulis perpustakaan bersama untuk meneruskannya ke programmer untuk digunakan kembali dalam aplikasi mereka. Tetapi untuk melakukan ini, Anda harus dapat menulis kode dalam bahasa yang sama, dengan gaya yang sama dan dengan pendekatan yang sama yang digunakan pengembang aplikasi Anda.
Masalah bisnis
Bisnis ini juga memiliki dua masalah besar yang perlu ditangani.
Kerugian langsung dari ketidakstabilan sistem terkait dengan keandalan dan ketersediaan.
Pada tahun 2018, kami memiliki 51 insiden kritis, dan elemen-elemen kritis dari sistem tidak bekerja selama lebih dari 20 jam. Dalam istilah moneter, ini adalah 25 juta rubel kerugian langsung karena pesanan yang tidak terkirim dan tidak terkirim. Dan seberapa banyak kita telah kehilangan kepercayaan karyawan, pelanggan dan pewaralaba tidak mungkin untuk dihitung, itu tidak dihargai dalam uang.
Biaya dukungan infrastruktur saat ini. Pada saat yang sama, perusahaan menetapkan tujuan kami untuk tahun 2018: untuk mengurangi biaya infrastruktur per restoran pizza sebanyak 3 kali. Tetapi baik programmer maupun insinyur DevOps dalam tim mereka bahkan tidak bisa menyelesaikan masalah ini. Ada beberapa alasan untuk ini:
- , ;
- , operations ( DevOps), ;
- , .
?
Bagaimana mengatasi semua masalah ini? Kami menemukan solusinya di Rekayasa Keandalan Situs Google. Ketika kita membaca, kita mengerti - inilah yang kita butuhkan.
Tetapi ada peringatan - untuk melaksanakan semua ini, butuh bertahun-tahun, dan Anda harus mulai dari suatu tempat. Pertimbangkan data awal yang kami miliki pada awalnya.
Seluruh infrastruktur kami hampir seluruhnya hidup di Microsoft Azure. Ada beberapa cluster independen untuk penjualan yang tersebar di berbagai benua: Eropa, Amerika dan Cina. Ada stan beban yang mengulang produksi, tetapi hidup di lingkungan yang terisolasi, serta lusinan lingkungan DEV untuk tim pengembangan.
Praktik SRE yang baik yang telah kami miliki:
- mekanisme untuk memonitor aplikasi dan infrastruktur (spoiler: pada tahun 2018 kami pikir itu bagus, tapi sekarang kami sudah menulis ulang semuanya);
- 24/7 on-call;
- ;
- ;
- CI/CD- ;
- , ;
- SRE .
Tetapi ada juga masalah yang ingin saya pecahkan sejak awal:
Tim infrastruktur kelebihan beban. Tidak ada cukup waktu dan upaya untuk perbaikan global karena sistem operasi saat ini. Misalnya, kami ingin untuk waktu yang sangat lama, tetapi tidak dapat menyingkirkan Elasticsearch di tumpukan kami, atau menduplikasi infrastruktur dari penyedia cloud lain untuk menghindari risiko (di sini mereka yang sudah pernah mencoba multi-cloud mungkin tertawa).
Kekacauan dalam kode. Kode infrastruktur kacau, tersebar di berbagai repositori, dan tidak didokumentasikan di mana pun. Semuanya didasarkan pada pengetahuan individu dan tidak ada yang lain. Ini adalah masalah manajemen pengetahuan raksasa.
"Ada programmer, tetapi ada insinyur infrastruktur."Terlepas dari kenyataan bahwa kami memiliki budaya DevOps yang berkembang cukup baik, masih ada pemisahan ini. Dua kelas orang dengan pengalaman yang sangat berbeda, berbicara bahasa yang berbeda dan menggunakan alat yang berbeda. Mereka, tentu saja, adalah teman dan berkomunikasi, tetapi seringkali tidak saling memahami karena pengalaman yang sama sekali berbeda.
Tim SRE onboarding
Untuk mengatasi masalah ini dan entah bagaimana mulai bergerak ke arah SRE, kami meluncurkan proyek sosialisasi. Hanya saja itu bukan orientasi klasik - melatih karyawan baru (pendatang baru) untuk menambahkan orang ke tim saat ini. Ini adalah pembentukan tim insinyur dan programmer infrastruktur baru - langkah pertama menuju struktur SRE yang lengkap.
Kami mengalokasikan 4 bulan untuk proyek dan menetapkan tiga tujuan:
- Latih programmer dalam pengetahuan dan keterampilan yang diperlukan untuk tugas dan kegiatan operasional di tim infrastruktur.
- Tulis IaC - deskripsi seluruh infrastruktur dalam kode. Selain itu, itu harus menjadi produk perangkat lunak lengkap dengan CI / CD, tes.
- Buat ulang seluruh infrastruktur kami dari kode ini dan lupakan mengklik mesin virtual secara manual dengan mouse di Azure.
Peserta: 9 orang, 6 di antaranya dari tim pengembangan, 3 dari infrastruktur. Selama 4 bulan, mereka harus meninggalkan pekerjaan rutin dan membenamkan diri dalam tugas yang ditentukan. Untuk mempertahankan "kehidupan" dalam bisnis, 3 lebih banyak orang dari infrastruktur tetap bertugas, berurusan dengan sistem operasi dan menutup bagian belakang. Akibatnya, proyek itu terasa membentang dan memakan waktu lebih dari lima bulan (dari Mei hingga Oktober 2019).
Dua Pilar Onboarding: Belajar dan Berlatih
Onboarding terdiri dari dua bagian: belajar dan mengerjakan infrastruktur dalam kode.
Latihan. Setidaknya 3 jam sehari dialokasikan untuk pelatihan:
- untuk membaca artikel dan buku dari daftar referensi: Linux, jaringan, SRE;
- di kuliah tentang alat dan teknologi tertentu;
- ke klub teknologi, misalnya, Linux, tempat kami menangani kasus dan kasus sulit.
Alat pembelajaran lain adalah demo internal. Ini adalah pertemuan mingguan di mana setiap orang (yang memiliki sesuatu untuk dikatakan) dalam 10 menit berbicara tentang teknologi atau konsep yang mereka terapkan dalam kode kita dalam seminggu. Sebagai contoh, Vasya mengubah jalur untuk bekerja dengan modul Terraform, dan Petya menulis ulang perakitan gambar pada Packer.
Setelah demo, kami memulai diskusi di bawah setiap topik di Slack, di mana para peserta yang tertarik dapat secara asinkron mendiskusikan semuanya dengan lebih detail. Jadi kami menghindari pertemuan panjang untuk 10 orang, tetapi pada saat yang sama semua orang di tim memahami dengan baik apa yang terjadi dengan infrastruktur kami dan ke mana kami menuju.

Praktek. Bagian kedua dari orientasi adalah membuat / menggambarkan infrastruktur dalam kode . Bagian ini dibagi menjadi beberapa tahap.
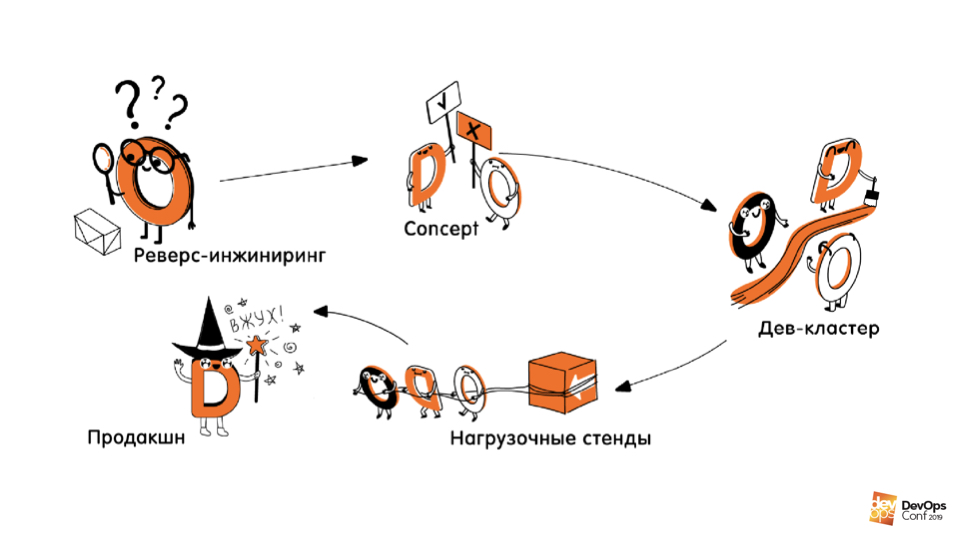
Membalikkan rekayasa infrastruktur.Ini adalah tahap pertama di mana kami menganalisis apa yang digunakan di mana, bagaimana cara kerjanya, di mana layanan apa yang digunakan, di mana mesin apa dan ukurannya. Semuanya didokumentasikan sepenuhnya.
Konsep Kami bereksperimen dengan berbagai teknologi, bahasa, pendekatan, menemukan bagaimana kami dapat menggambarkan infrastruktur kami, alat apa yang harus digunakan untuk ini.
Kode ejaan. Ini termasuk menulis kode itu sendiri, membuat jalur pipa CI / CD, tes, dan proses pembangunan di sekitar itu semua. Kami menulis kode yang menjelaskan dan tahu cara membuat infrastruktur virgo kami dari awal.
Menciptakan kembali singkatan untuk pengujian dan produksi beban.Ini adalah tahap keempat, yang seharusnya setelah onboarding, tetapi telah ditunda untuk saat ini, karena keuntungan dari itu, anehnya, jauh lebih sedikit daripada dari lingkungan perawan yang dibuat / diciptakan kembali sangat sering.
Alih-alih, kami beralih ke kegiatan desain: kami pecah menjadi sub-tim kecil dan menangani proyek infrastruktur global yang tidak pernah kami lakukan. Dan tentu saja, mereka bertugas.
Alat kami untuk IaC
- Terraform .
- Packer Ansible .
- Jsonnet Python .
- Azure, .
- VS Code — IDE, , , , .
- — , .
Praktek Pemrograman Ekstrim dalam Infrastruktur
Hal utama yang kami, sebagai programmer, bawa bersama kami adalah praktik Pemrograman Ekstrim yang kami gunakan dalam pekerjaan kami. XP adalah metodologi pengembangan perangkat lunak yang fleksibel yang memadukan pendekatan, praktik, dan nilai pengembangan terbaik.
Tidak ada programmer tunggal yang tidak akan menggunakan setidaknya beberapa praktik Pemrograman Ekstrim, bahkan jika dia tidak mengetahuinya. Pada saat yang sama, di dunia infrastruktur, praktik-praktik ini dilewati, meskipun faktanya praktik tersebut tumpang tindih dengan praktik dari Google SRE.
Ada artikel terpisah tentang bagaimana kami mengadaptasi XP untuk infrastruktur .... Tetapi singkatnya: praktik XP bekerja untuk kode infrastruktur, meskipun dengan pembatasan, adaptasi, tetapi mereka bekerja. Jika Anda ingin menerapkannya di rumah, undang orang-orang yang berpengalaman dalam menerapkan praktik-praktik ini. Sebagian besar praktik ini dijelaskan dalam satu atau lain cara dalam buku yang sama tentang SRE .
Semuanya bisa berjalan dengan baik, tetapi tidak.
Masalah teknis dan buatan manusia di jalan
Ada dua jenis masalah dalam proyek:
- Teknis : keterbatasan dunia "besi", kurangnya pengetahuan dan peralatan mentah yang harus digunakan karena tidak ada yang lain. Ini adalah masalah umum bagi setiap programmer.
- Manusia : interaksi orang dalam suatu tim. Komunikasi, pengambilan keputusan, pelatihan. Ini lebih buruk, jadi Anda harus berhenti lebih detail.
Kami mulai mengembangkan tim onboarding seperti yang kami lakukan dengan tim pemrograman lain. Kami berharap bahwa akan ada tahapan yang biasa untuk membangun tim Takman : menyerbu, normalisasi, dan pada akhirnya kami akan pergi ke produktivitas dan pekerjaan produktif. Karena itu, kami tidak khawatir bahwa pada awalnya ada beberapa kesulitan dalam komunikasi, pengambilan keputusan, kesulitan untuk mencapai kesepakatan.
Dua bulan berlalu, tetapi fase badai terus berlanjut. Hanya menjelang akhir proyek kami menyadari bahwa semua masalah yang kami perjuangkan dan tidak anggap terkait satu sama lain adalah hasil dari akar masalah yang sama - dua kelompok orang yang sangat berbeda datang bersama dalam tim:
- Pemrogram berpengalaman dengan pengalaman bertahun-tahun di mana mereka mengembangkan pendekatan, kebiasaan, dan nilai-nilai mereka dalam pekerjaan.
- Kelompok lain dari dunia infrastruktur dengan pengalaman mereka sendiri. Mereka memiliki benjolan yang berbeda, kebiasaan yang berbeda, dan mereka juga berpikir mereka tahu bagaimana hidup dengan benar.
Ada bentrokan dua pandangan tentang kehidupan dalam satu tim. Kami tidak melihatnya langsung dan tidak mulai bekerja dengannya, akibatnya kami kehilangan banyak waktu, energi, dan saraf.
Tetapi untuk menghindari tabrakan ini tidak mungkin. Jika Anda mengundang pemrogram yang kuat dan insinyur infrastruktur yang lemah ke proyek, maka Anda akan memiliki pertukaran pengetahuan satu arah. Sebaliknya, itu juga tidak berfungsi - beberapa akan menelan yang lain dan hanya itu. Dan Anda perlu mendapatkan campuran tertentu, jadi Anda harus siap untuk fakta bahwa "penggilingan" bisa sangat lama (dalam kasus kami, kami dapat menstabilkan tim hanya setahun kemudian, sambil mengucapkan selamat tinggal kepada salah satu insinyur yang paling kuat secara teknis).
Jika Anda ingin membuat tim seperti itu, jangan lupa untuk memanggil pelatih Agile, scrum master, atau terapis yang kuat - mana saja yang Anda inginkan. Mungkin mereka akan membantu.
Hasil orientasi
Berdasarkan hasil proyek onboarding (berakhir pada Oktober 2019), kami:
- Kami telah menciptakan produk perangkat lunak lengkap yang mengelola infrastruktur DEV kami, dengan pipa CI sendiri, pengujian, dan atribut lain dari produk perangkat lunak berkualitas.
- Kami menggandakan jumlah orang yang siap bertugas dan mengambil beban dari tim saat ini. Setelah enam bulan, orang-orang ini menjadi SRE penuh. Sekarang mereka dapat memadamkan api di prod, berkonsultasi dengan tim programmer NFT, atau menulis perpustakaan mereka sendiri untuk pengembang.
- SRE. , , .
- : , , , .
: ,
Beberapa wawasan dari pengembang. Jangan menginjak menyapu kami, selamatkan diri Anda dan orang-orang di sekitar Anda saraf dan waktu.
Infrastruktur di masa lalu. Ketika saya masih di tahun pertama saya (15 tahun yang lalu) dan mulai belajar JavaScript, saya menggunakan NotePad ++ dan Firebug untuk debugging. Bahkan kemudian, perlu untuk melakukan beberapa hal yang rumit dan indah dengan alat-alat ini.
Tentang hal yang sama yang saya rasakan sekarang ketika saya bekerja dengan infrastruktur. Alat saat ini hanya sedang dibentuk, banyak dari mereka belum dirilis dan memiliki versi 0.12 (hai, Terraform), dan banyak secara teratur memecah kompatibilitas ke belakang dengan versi sebelumnya.
Bagi saya, sebagai pengembang perusahaan, tidak masuk akal untuk menggunakan hal-hal seperti itu dalam produksi. Tetapi tidak ada yang lain.
Baca dokumentasinya.Sebagai seorang programmer, saya relatif jarang pergi ke dermaga. Saya tahu alat saya cukup dalam: bahasa pemrograman favorit saya, kerangka kerja favorit saya dan database. Semua alat tambahan, misalnya, perpustakaan, biasanya ditulis dalam bahasa yang sama, yang berarti Anda selalu dapat melihat kode sumber. IDE akan selalu memberi tahu Anda parameter mana yang dibutuhkan. Bahkan jika saya salah, saya akan segera mengetahuinya dengan menjalankan tes cepat.
Ini tidak akan berfungsi dalam infrastruktur, ada sejumlah besar teknologi berbeda yang perlu Anda ketahui. Tetapi tidak mungkin untuk mengetahui segalanya secara mendalam, dan banyak yang ditulis dalam bahasa yang tidak dikenal. Karena itu, baca (dan tulis) dokumentasi dengan cermat - tanpa kebiasaan ini mereka tidak tinggal lama di sini.
Komentar dalam kode infrastruktur tidak bisa dihindari.Di dunia pembangunan, komentar adalah tanda kode buruk. Mereka dengan cepat menjadi usang dan mulai berbohong. Ini adalah pertanda bahwa pengembang tidak bisa mengungkapkan pikirannya. Saat bekerja dengan infrastruktur, komentar juga merupakan tanda kode buruk, tetapi Anda tidak dapat melakukannya tanpa itu. Untuk instrumen yang tersebar yang secara longgar terkait satu sama lain dan tidak tahu apa-apa tentang satu sama lain, komentar sangat diperlukan.
Seringkali, di bawah kode, konfigurasi biasa dan DSL disembunyikan. Dalam hal ini, semua logika terjadi di suatu tempat yang lebih dalam di mana tidak ada akses. Ini sangat mengubah pendekatan untuk kode, pengujian dan bekerja dengannya.
Jangan takut untuk membiarkan pengembang masuk ke infrastruktur.Mereka dapat membawa praktik dan pendekatan yang bermanfaat (dan segar) dari dunia pengembangan perangkat lunak. Gunakan praktik dan pendekatan dari Google, yang dijelaskan dalam buku tentang SRE, manfaatkan dan bahagia.
PS: , , , .
PPS: DevOpsConf 2019 . , , : , , DevOps-, .
PPPS: , DevOps-, DevOps Live 2020. : , - . , DevOps-. — « » .
, DevOps Live , , CTO, .