Di akhir artikel, kami akan membagikan kepada Anda daftar materi paling menarik tentang topik ini.

Pendekatan baru
Pembelajaran penguatan multi-agen adalah bidang penelitian yang berkembang dan kaya. Namun demikian, penggunaan algoritma single-agent yang konstan dalam konteks multi-agen menempatkan kami pada posisi yang sulit. Belajar itu rumit karena berbagai alasan, terutama karena:
- Non-stasiunaritas antara agen independen;
- Pertumbuhan ruang tindakan dan negara secara eksponensial.
Para peneliti telah menemukan banyak cara untuk mengurangi efek dari faktor-faktor ini. Sebagian besar metode ini berada di bawah konsep "perencanaan pusat dengan pelaksanaan desentralisasi."
Perencanaan terpusat
Setiap agen memiliki akses langsung ke pengamatan lokal. Pengamatan ini bisa sangat beragam: gambar lingkungan, posisi relatif terhadap landmark tertentu, atau bahkan posisi relatif terhadap agen lain. Selain itu, selama pelatihan, semua agen dikelola oleh modul pusat atau kritikus.
Terlepas dari kenyataan bahwa setiap agen pelatihan hanya memiliki informasi lokal dan kebijakan lokal, ada entitas yang memantau seluruh sistem agen dan memberi tahu mereka cara memperbarui kebijakan. Dengan demikian, efek ketidakstabilan berkurang. Semua agen dilatih menggunakan modul dengan informasi global.
Eksekusi terdesentralisasi
Selama pengujian, modul pusat dihapus, dan agen dengan kebijakan dan data lokal mereka tetap. Ini mengurangi kerusakan yang disebabkan oleh meningkatnya ruang tindakan dan negara, karena kebijakan agregat tidak pernah dipelajari. Sebagai gantinya, kami berharap bahwa modul pusat memiliki informasi yang cukup untuk mengelola kebijakan pembelajaran lokal sedemikian rupa sehingga optimal untuk seluruh sistem segera setelah saatnya tiba untuk melakukan pengujian.
Openai
Para peneliti dari OpenAI, University of California di Berkeley dan McGill University, telah memperkenalkan pendekatan baru pada pengaturan multi-agen menggunakan Multi-Agent Deep Deterministic Policy Gradient . Pendekatan ini, diilhami oleh mitra agen tunggal, DDPG, menggunakan pelatihan aktor-ke-kritik dan telah menunjukkan hasil yang sangat menjanjikan.
Arsitektur
Artikel ini mengasumsikan bahwa Anda terbiasa dengan versi agen tunggal MADDPG: Gradien Kebijakan Deterministik Dalam atau DDPG. Untuk menyegarkan ingatan Anda, Anda dapat membaca artikel hebat Chris Yoon .
Setiap agen memiliki ruang pengamatan dan ruang tindakan berkelanjutan. Setiap agen juga memiliki tiga komponen:
- , ;
- ;
- , - Q-.
Ketika kritik memeriksa nilai-Q bersama dari suatu fungsi dari waktu ke waktu, ia mengirimkan perkiraan nilai-Q yang tepat kepada aktor untuk membantu pembelajaran. Kami akan melihat lebih dekat interaksi ini di bagian selanjutnya.
Ingatlah bahwa seorang kritikus dapat menjadi jaringan bersama antara semua agen N. Dengan kata lain, alih-alih melatih N jaringan yang mengevaluasi nilai yang sama, cukup latih satu jaringan dan gunakan untuk membantu melatih semua agen lainnya. Hal yang sama berlaku untuk jaringan aktor jika agennya homogen.
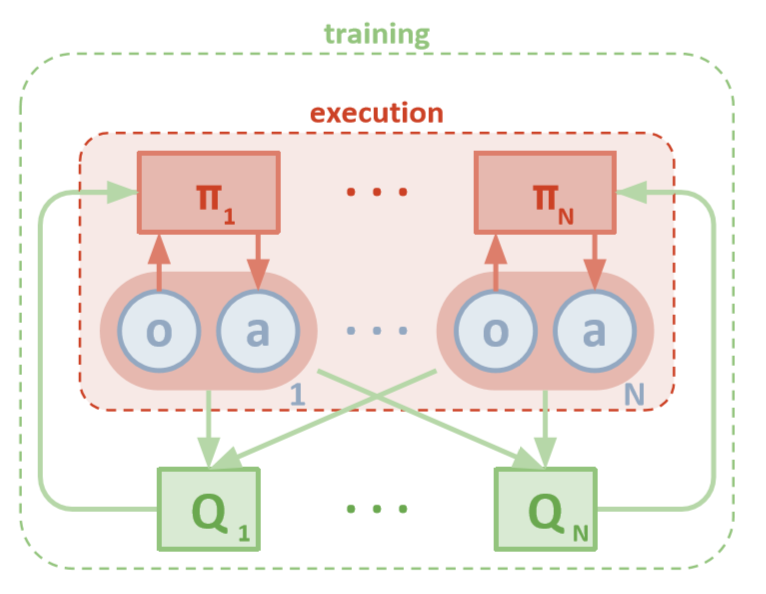
Arsitektur MADDPG (Lowe, 2018)
Latihan
Pertama, MADDPG menggunakan replay pengalaman untuk pembelajaran off-kebijakan yang efektif . Pada setiap interval waktu, agen menyimpan transisi berikut:
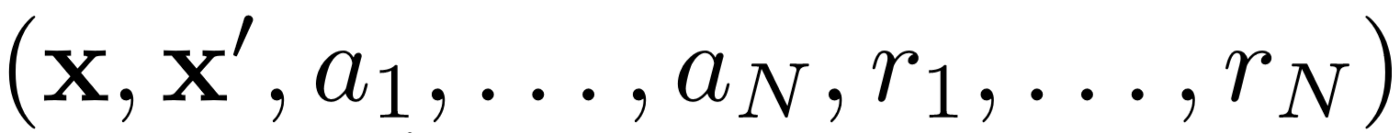
Di mana kita menyimpan keadaan bersama, keadaan bersama berikutnya, aksi bersama dan masing-masing hadiah yang diterima oleh agen. Kemudian kami mengambil serangkaian transisi dari replay pengalaman untuk melatih agen kami.
Pembaruan kritis
Untuk memperbarui kritik pusat agen, kami menggunakan kesalahan TD lookahead:
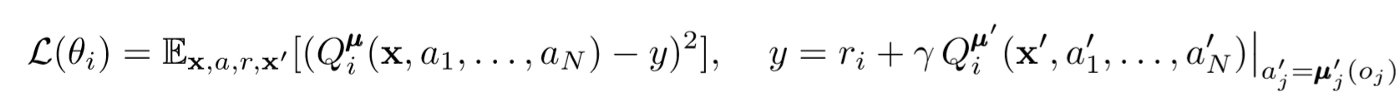
Di mana μ adalah aktor. Ingat bahwa ini adalah kritikus pusat, yaitu, ia menggunakan informasi umum untuk memperbarui parameternya. Ide dasarnya adalah bahwa jika Anda mengetahui tindakan yang dilakukan oleh semua agen, lingkungan akan tetap stasioner meskipun kebijakan berubah.
Perhatikan sisi kanan ekspresi dengan perhitungan nilai-Q. Meskipun kami tidak pernah menyimpan sinergi kami berikutnya, kami menggunakan masing-masing aktor target agen untuk menghitung tindakan selanjutnya selama pembaruan untuk membuat pembelajaran lebih stabil. Parameter aktor target diperbarui secara berkala agar sesuai dengan parameter aktor agen.
Aktor Pembaruan
Mirip dengan agen tunggal DDPG, kami menggunakan gradien kebijakan deterministik untuk memperbarui setiap parameter aktor agen.
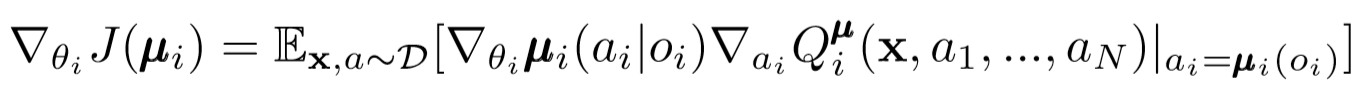
Di mana μ adalah aktor agen.
Mari kita menggali sedikit lebih jauh ke dalam ungkapan pembaruan ini. Kami mengambil gradien relatif terhadap parameter aktor menggunakan kritikus pusat. Hal yang paling penting untuk dicatat adalah bahwa meskipun aktor hanya memiliki pengamatan dan tindakan lokal, selama pelatihan kami menggunakan kritikus pusat untuk mendapatkan informasi tentang optimalitas tindakannya dalam seluruh sistem. Dengan demikian, efek non-stasioneritas berkurang, dan kebijakan pembelajaran tetap berada di ruang negara bagian yang lebih rendah!
Kesimpulan dari politisi dan ansambel politisi
Kita dapat mengambil langkah lain dalam masalah desentralisasi. Dalam pembaruan sebelumnya, kami mengasumsikan bahwa setiap agen akan secara otomatis mengenali tindakan agen lain. Namun, MADDPG mengusulkan untuk menarik kesimpulan dari kebijakan agen lain agar pelatihan lebih mandiri. Bahkan, setiap agen akan menambahkan jaringan N-1 untuk mengevaluasi kebenaran kebijakan semua agen lainnya. Kami menggunakan jaringan probabilistik untuk memaksimalkan probabilitas logaritmik untuk menyimpulkan tindakan yang diamati dari agen lain.
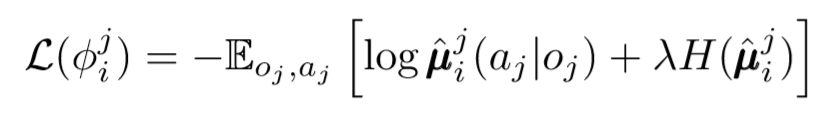
Di mana kita melihat fungsi kerugian untuk agen ke-i mengevaluasi kebijakan agen ke-j menggunakan pengatur entropi. Akibatnya, nilai Q target kami menjadi sedikit berbeda ketika kami mengganti tindakan agen dengan tindakan yang kami prediksi!
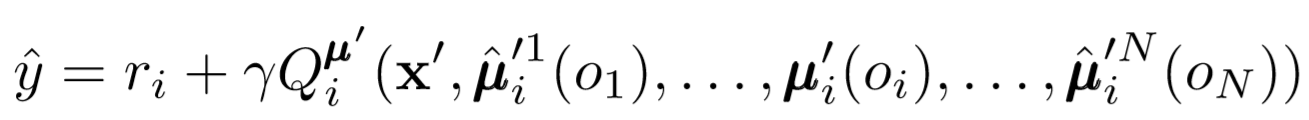
Jadi apa yang terjadi pada akhirnya? Kami menghapus asumsi bahwa agen tahu kebijakan masing-masing. Sebagai gantinya, kami mencoba untuk melatih agen untuk memprediksi kebijakan agen lain berdasarkan serangkaian pengamatan. Faktanya, setiap agen belajar secara mandiri, menerima informasi global dari lingkungan alih-alih memilikinya secara default.
Ensembel Politik
Ada satu masalah besar dalam pendekatan di atas. Dalam banyak pengaturan multi-agen, terutama dalam yang kompetitif, agen dapat membuat kebijakan yang dapat melatih kembali perilaku agen lain. Ini akan membuat politik rapuh, tidak stabil dan, sebagai aturan, tidak optimal. Untuk mengkompensasi kekurangan ini, MADDPG melatih koleksi subpolicy K untuk setiap agen. Pada setiap langkah waktu, agen secara acak memilih salah satu sub-kebijakan untuk memilih tindakan. Dan kemudian dia melakukannya.
Kemiringan politik sedikit berubah. Kami mengambil rata-rata sub-kebijakan K, menggunakan linearitas harapan, dan mendistribusikan pembaruan menggunakan fungsi nilai-Q.
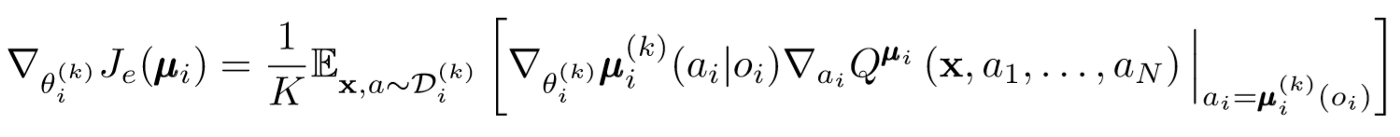
Ambil langkah mundur
Ini adalah bagaimana keseluruhan algoritma terlihat secara umum. Sekarang kita perlu kembali dan menyadari apa yang telah kita lakukan dan secara intuitif memahami mengapa ini berhasil. Pada dasarnya, kami melakukan hal berikut:
- Aktor yang ditetapkan untuk agen yang hanya menggunakan pengamatan lokal. Dengan cara ini, seseorang dapat mengendalikan efek negatif dari peningkatan ruang dan tindakan yang meningkat secara eksponensial.
- Mengidentifikasi kritik pusat untuk setiap agen yang menggunakan informasi bersama. Jadi kami dapat mengurangi pengaruh nonstasioneritas dan membantu aktor untuk menjadi optimal untuk sistem global.
- Jaringan kesimpulan yang teridentifikasi dari kebijakan untuk mengevaluasi kebijakan agen lain. Dengan cara ini, kami dapat membatasi saling ketergantungan agen dan menghilangkan kebutuhan agen untuk memiliki informasi yang sempurna.
- Ensemble kebijakan diidentifikasi untuk mengurangi efek dan kemungkinan pelatihan ulang pada kebijakan agen lain.
Setiap komponen algoritma melayani tujuan khusus dan berbeda. Apa yang membuat MADDPG kuat adalah sebagai berikut: komponen-komponennya secara khusus dirancang untuk mengatasi rintangan utama yang biasanya dihadapi sistem multi-agen. Selanjutnya kita berbicara tentang kinerja algoritma.
hasil
MADDPG telah diuji di banyak lingkungan. Tinjauan lengkap karyanya dapat ditemukan di artikel [1]. Di sini kita hanya akan berbicara tentang masalah komunikasi kooperatif.
Tinjauan Lingkungan
Ada dua agen: pembicara dan pendengar. Pada setiap iterasi, pendengar menerima titik berwarna pada peta yang ingin Anda pindahkan, dan menerima hadiah yang sebanding dengan jarak ke titik ini. Tapi ini masalahnya: pendengar hanya tahu posisinya dan warna titik akhir. Dia tidak tahu ke titik mana dia harus pindah. Namun, pembicara tahu warna titik yang benar untuk iterasi saat ini. Akibatnya, kedua agen harus berinteraksi untuk menyelesaikan tugas ini.
Perbandingan
Untuk mengatasi masalah ini, artikel ini kontras dengan MADDPG dan metode agen tunggal modern. Perbaikan signifikan terlihat dengan penggunaan MADDPG.
Itu juga menunjukkan bahwa kesimpulan dari politisi, bahkan jika politisi tidak dilatih dengan sempurna, mereka mencapai keberhasilan yang sama yang dapat dicapai dengan menggunakan pengamatan yang benar. Selain itu, tidak ada perlambatan konvergensi yang signifikan.
Akhirnya, ansambel kebijakan telah menunjukkan hasil yang sangat menjanjikan. Artikel [1] mengeksplorasi pengaruh ansambel dalam lingkungan yang kompetitif dan menunjukkan peningkatan kinerja yang signifikan atas agen dengan kebijakan tunggal.
Kesimpulan
Itu saja. Di sini kami melihat pendekatan baru untuk pembelajaran penguatan multi-agen. Tentu saja, ada sejumlah metode yang tak terbatas terkait dengan MARL, tetapi MADDPG memberikan dasar yang kuat untuk metode yang memecahkan masalah paling global dari sistem multi-agen.
Sumber
[1] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, I. Mordatch, Aktor-Agen Multi-Agen untuk Lingkungan Koperasi-Kompetitif Campuran (2018).
Daftar artikel yang bermanfaat
- 3 perangkap untuk calon Ilmuwan Data
- Algoritma AdaBoost
- Bagaimana tahun 2019 di bidang matematika dan Ilmu Komputer?
- Pembelajaran mesin menghadapi masalah matematika yang belum terpecahkan
- Memahami Bayes Theorem
- Menemukan kontur wajah dalam satu milidetik menggunakan ansambel pohon regresi
, , , . .