
Bahkan, ini adalah kisah pencarian cacat pada tata letak situs perbankan, yang menyebabkan tampilan halaman utama pada pencarian tidak akurat. Masalah serupa sering dijumpai pada situs yang dikompilasi, misalnya, di perancang online, atau dibuat-buat misalnya oleh penata huruf yang tidak terbiasa dengan dasar-dasar pengoptimalan mesin pencari.
Dan kisah ini akan tetap menarik hanya untuk lingkaran sempit berlatih seoshnik jika tidak menyentuh satu fitur pengindeksan yang tidak berdokumen, yang mungkin ingin diketahui oleh spesialis pemeliharaan situs web lain. Saya mengundang mereka di bawah kucing.
Intro pendek
Setiap SEO-master berpengalaman tahu aturan penguraian semantik halaman situs oleh robot pencari-pengindeks. Aturan-aturan ini didasarkan pada ketentuan individu dari beberapa standar teknis di Internet. Sebagai contoh:
- tag <title> adalah nama unik untuk seluruh dokumen dan hanya digunakan di bagian tajuknya, dan hanya sekali;
- tag <h1> memberi nama bagian tertentu dari dokumen dan dapat digunakan kembali, tetapi hanya di bagian yang berbeda dan tetap mempertahankan keunikan di antara semua tag <h1> dari dokumen yang sama;
- tag <h2> adalah subtitle bagian yang dapat digunakan kembali bahkan di bagian yang sama jika itu unik di antara subtitle rekan bagiannya;
- tag <h3> adalah subtitle dari subtitle superior;
- ... dll.
Tentu saja, ada nuansa yang berbeda dalam aturan ini untuk parsing halaman sebelum mengindeksnya, yang ditafsirkan oleh setiap server pencarian dengan caranya sendiri:
- , «», — , <p> ;
- (outlines), «» — , <h2> <p> () ;
- … .
Untuk saat ini, aturan analisis dan nuansa semantik ini tidak penting bagi kami. Dan jika Anda sangat tertarik dengan ketentuan standar teknis yang menjadi dasar pengindeksan konten, maka bagian utama dari ketentuan ini dinyatakan dengan jelas dalam publikasi ikhtisar [1] tentang diterimanya beberapa tag <h1> pada satu halaman situs.
Saya hanya akan mencatat bahwa master SEO terbiasa dengan nuansa seperti itu, ini bukan pertama kalinya mereka memverifikasi validitasnya berdasarkan pengalaman mereka sendiri, dan telah lama mempromosikan situs dalam pencarian dengan mempertimbangkan pandangan ini tentang prioritas tag. Memang, memahami prinsip-prinsip pengindeksan memungkinkan untuk sebagian "mengelola" teks yang akan ditampilkan cuplikan pencarian sebagai tanggapan terhadap permintaan pengguna.
Tetapi beberapa hari yang lalu, informasi orang dalam muncul bahwa dalam hasil pencarian organik mengenai situs resmi Monobank Ukraina, perilaku potongan yang tidak dapat dipahami terungkap: judul mesin pencari sama sekali tidak dengan tag <title> atau <h1>. Artinya, seorang copywriter dapat menulis judul dan teks yang paling unik, seorang manajer konten dapat memasukkan teks ke dalam situs, tetapi pencarian tetap salah.
Itu perlu untuk mencari tahu alasannya, yang akan saya bicarakan lebih lanjut.
Langkah pertama penelitian
Jadi, pertama, saya membersihkan cache dan riwayat browser, menyalakannya kembali, membuka kotak pencarian Google dan memasukkan nama bank. Sehingga bahkan orang yang tidak berpengalaman dalam SEO dapat memahami setiap langkah yang saya ambil, saya mengambil gambar dari langkah pertama.
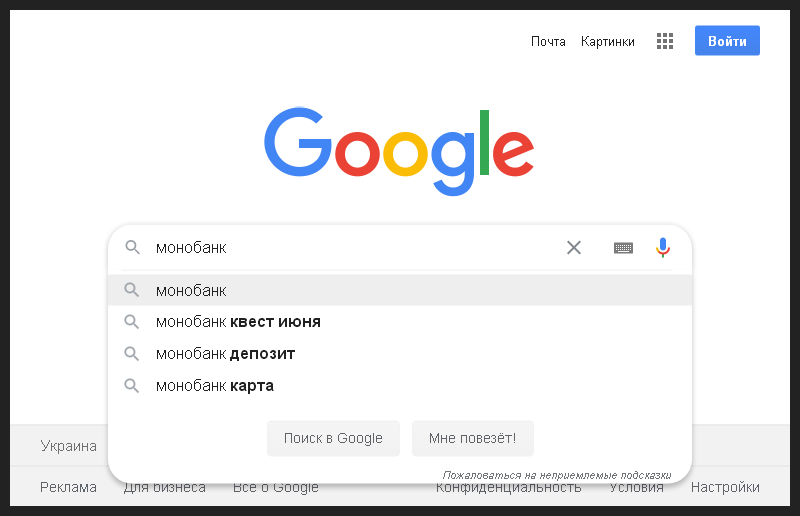
Ini adalah permintaan informasi bermerek, yang berarti bahwa di tempat pertama hasil organik adalah logis untuk mengharapkan tampilan potongan untuk halaman utama bank.
Semuanya terjadi seperti yang diharapkan, cuplikan adalah yang pertama dalam pencarian, dan juga berisi blok tautan cepat ke bagian utama situs. Saya menangkap momen ini di gambar berikutnya.
Sejauh ini, semuanya tampak normal.

Untuk memastikan bahwa situasi yang tidak jelas hanya terjadi di hasil Google, saya mengulangi permintaan yang sama dalam pencarian Yandex dan dengan senang hati mencatat bahwa raksasa pencarian ini mematuhi aturan yang biasa: cuplikan diberi judul monobank - bank seluler - persis seperti yang tertulis dalam tag <title> yang diinginkan halaman.

Jawaban dalam snapshot pencarian Google pada dasarnya berbeda, setidaknya di bagian judul. Yah, dan selain itu, saya agak bingung dengan teks-teks konyol di bawah judul cuplikan Google.
Saya berasumsi bahwa ini hanya konsekuensi dari kenyataan bahwa setelah SMM mempromosikan merek dan aplikasi mobile-nya, yang diimplementasikan oleh Promodo pada 2017-2018 [2] untuk domain mantan monobank.com.ua , untuk mempekerjakan lebih banyak master SEO untuk melayani domain monobank baru .ua tidak lagi masuk akal. Bagaimanapun, kampanye iklan telah membuahkan hasil yang diharapkan. Dan manajemen bank kemungkinan besar mencetak gol dalam promosi mesin pencari dari domain baru, atau menugaskan tanggung jawab kepada spesialis IT penuh waktu.
Oleh karena itu, saya mengaitkan kecanggungan dari teks saat ini dengan keengganan anggota staf yang dapat dimengerti untuk memeriksa hasil kueri, yang tidak akan pernah diketik oleh pengguna bank biasa.
Bagaimanapun, klien bank pergi ke situs untuk sebagian besar melalui aplikasi mobile, praktis tanpa mengamati bagaimana halaman bank terlihat dalam pencarian. Dan bagian dari klien yang pergi melalui pencarian Internet terutama menggunakan permintaan formulir:
- Kurs dolar Monobank;
- nilai tukar monobank;
- buka akun monobank;
- membuat kartu monobank;
- buat kartu monobank;
- kartu kredit monobank;
- dapatkan pinjaman monobank;
- mengambil pinjaman monobank;
- ... dll.
Bank mana pun tahu daftar lengkap frasa pencarian seperti itu yang cocok dengan pola "apa yang harus ditemukan + di mana" atau "di mana + apa" dan mendatangkan lalu lintas masuk tertinggi dari pencarian organik.
Memeriksa kueri "enak"
Betapa terkejutnya saya ketika sebagian besar dari kueri ini cuplikan yang sama muncul di hasil pencarian dengan judul yang tidak berubah-ubah dan seringkali teks bodoh yang hampir tidak berhubungan dengan kueri yang dimasukkan.
Saya memotret contoh permintaan seperti itu pada gambar berikut dan mengidentifikasi tempat masalahnya.

Selain itu, alamat target (URL) cuplikan untuk hampir semua permintaan mengarah ke awal halaman utama, bahkan tanpa menjangkar bagian di alamat yang relevan dengan permintaan saat ini.
Nah, katakanlah jika permintaannya adalah tentang nilai tukar dan bagian yang sesuai memiliki halaman arahan yang sesuai, akan logis untuk melabuhkan tautan ke bagian tersebut dengan beberapa hash seperti monobank.ua/#kurs-valut dengan kanonisasi URL berlabuh yang sama sehingga robot pencarian mengerti bahwa laman landas memiliki beberapa titik pendaratan untuk frasa pencarian yang sesuai, yang akan dijabarkan oleh SEO reguler dalam teks jangkar tautan yang ditempatkan oleh mereka di suatu tempat di situs atau di luar situs, misalnya, di jejaring sosial.
Jika tidak, semuanya tampak seolah-olah pengembang situs menetapkan peran pendaratan multi-bagian ke halaman utama, tetapi mereka tidak memberi tahu para hadirin, dan mereka memasang tautan promosi dengan teks jangkar yang direncanakan, tetapi tanpa jangkar bagian. Akibatnya, semua tautan untuk berbagai jenis permintaan tampaknya masuk ke titik entri awal halaman utama dan mau tidak mau menerima satu cuplikan tunggal dengan judul yang berkaitan dengan bagian utama halaman utama.
Penyimpangan kecil
Untuk berjaga-jaga, saya akan menunjukkan pada gambar berikutnya contoh markup HTML, bagaimana mereka menggunakan tata letak semantik untuk memecahkan masalah beberapa titik pendaratan pada satu halaman pendaratan situs.

Tentu saja, skema ini akan berfungsi asalkan kami menempatkan tautan ke halaman arahan dengan jangkar yang sesuai dengan kasus informasi. Yaitu:
- monobank.ua - informasi dasar;
- monobank.ua/#kurs-valut - tentang nilai tukar;
- monobank.ua/#otkryt-schet - tentang membuka akun;
- monobank.ua/#kreditnaja-karta - tentang kartu kredit.
Tetapi kembali ke jamb SEO yang ditemukan
Kesalahannya, meskipun tidak terlalu serius, karena arus utama pelanggan masih melalui aplikasi mobile, namun, karena kesalahan ini, bank kehilangan sebagian dari lalu lintas pencariannya. Karena pengguna pencarian dibagi menjadi 2 jenis - mayoritas yang tergesa-gesa dan minoritas yang santai:
- yang pertama hanya membaca tajuk cuplikan dan mengkliknya jika arti tajuk dan permintaan yang dimasukkan cocok;
- yang terakhir hati-hati membaca judul dan teks di bawahnya dan juga mengklik hanya ketika maknanya bertepatan.
Jelas bahwa makna pesan dalam cuplikan pencarian yang diverifikasi untuk halaman bank hanya bertepatan dengan persentase permintaan yang sangat kecil. Itu perlu untuk memahami di mana kesalahan itu dibuat.
Lihat tata letak halaman rumah
Saya membuka halaman utama bank menggunakan tautan dari cuplikan. Kode sumber untuk halaman ini berisi tag <h1> tunggal, biasanya digunakan untuk menulis judul halaman utama, yang biasanya juga termasuk dalam header snippet.
Selain itu, tag tajuk utama ini digunakan dalam kode halaman sebelum tajuk <h> tajuk lainnya. Jadi sekilas semuanya sepertinya tidak memiliki kesalahan SEO.
Saya mengambil gambar dari halaman itu dan menandai posisi dua tag <h> judul pertama di atasnya.
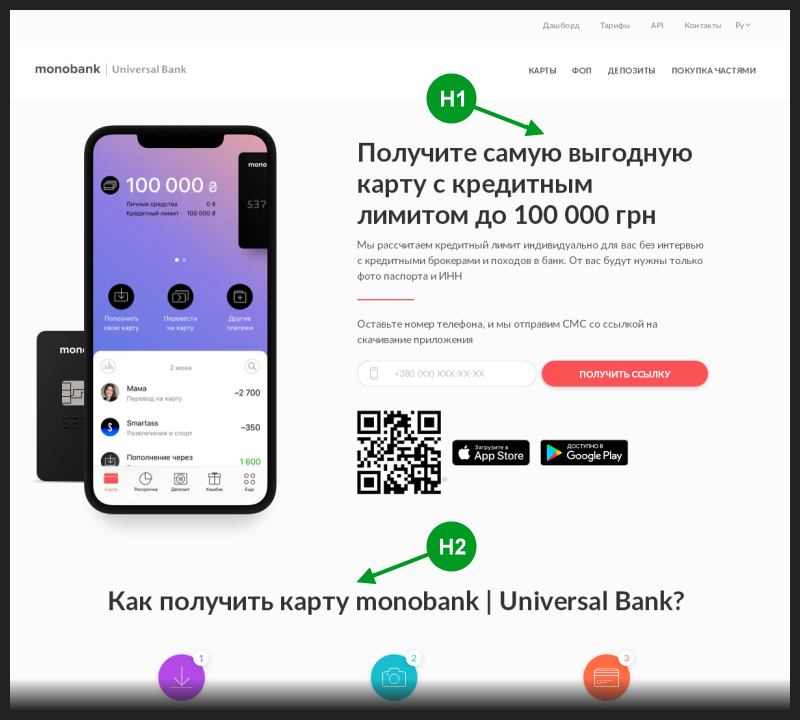
Adalah logis untuk mengharapkan bahwa tag <h1> akan menggantikan header potongan pencarian. Tetapi untuk beberapa alasan, tag dari peringkat yang lebih rendah sampai di sana setiap waktu.
Awalnya saya berasumsi bahwa kasus tersebut hanya menyangkut pertanyaan yang termasuk nama bank. Tag <h1> tidak memilikinya, tetapi tag <h2> memiliki - sehingga tag tersebut, meskipun peringkatnya lebih rendah, masih mendapatkan keuntungan dari mengambil alih judul cuplikan.
Namun, asumsi ini mudah untuk diuji: Anda harus menulis permintaan persis sama dengan tag <h1>, dan kemudian tag heading ini dijamin memiliki hak untuk menempati judul cuplikan berdasarkan kecocokan mutlak dengan permintaan tersebut. Yang saya lakukan, sambil memperbaiki hasil di tembakan berikutnya.

Ini mengikuti dari snapshot bahwa server pencarian masih melihat dan memahami teks dari tag <h1>, tetapi karena alasan tertentu ia tidak menganggapnya sebagai judul utama di situs web bank ini. Ini dimungkinkan dalam 2 kasus:
- baik master SEO menambahkan markup mikro semantik spesifik ke tata letak halaman, yang memerintahkan tag lain untuk menjadi tajuk utama;
- atau ada yang disebut "masalah desainer online" ketika, karena suboptimalitas pencarian blok bangunan, tag teks mereka muncul di berbagai bagian dokumen HTML, sedangkan tag judul utama dihilangkan lebih dalam daripada tag judul non-utama dari garis besar bagiannya.
Saya memutuskan untuk memeriksa kasus pertama dan membuka situs di alat validasi data terstruktur. Namun, hanya markup mikro Open Graph yang ditemukan, tidak ada petunjuk tentang pemindahan paksa tag semantik.
Saya menangkap momen ini di gambar berikutnya.

Lalu saya membuka kode sumber dari halaman masalah, memformat spasi untuk belajar dengan mudah, menghapus atribut tag untuk tujuan yang sama, dan kemudian mencatat esensi masalah pada gambar berikutnya.

Sebagai hasilnya, kami memiliki keadaan hubungan yang ditafsirkan di bawah ini, dari mana saya akan menuliskan kesimpulan penting sebelumnya : setelah sebulan (ini kira-kira waktu merangkak rata-rata untuk robot pengindeksan) dari peluncuran situs, pastikan untuk memeriksa beberapa pertanyaan kunci bagaimana mesin pencari merasakan markup halaman Anda, yaitu, bagian mana Dia benar-benar mengindeks kontennya.
Interpretasi hasil
Halaman penguraian Yandex pada domain baru Monobanka tidak menemukan vorstku semantik (karena semua ditata <div> s), dan tidak memiliki perintah untuk menganalisis semantik implisit tidak berspekulasi pada kelas tag, dan pemilihan judul cuplikan hanya mengambil keuntungan dari aturan spesifikasi: tag <title> adalah judul utama dokumen.
Google, ketika mem-parsing halaman yang sama, juga tidak menemukan tata letak semantik, tetapi kecerdasan buatannya mampu menganalisis fitur semantik tersembunyi, jadi Google memperhatikan empat <div> dengan konten kelas semantik yang implisitmenunjukkan garis besar bagian dalam situasi penandaan saat ini. Akibatnya, aturan tentang tag <title> ditolak, dan mesin pencari menggunakan aturan dari spesifikasi bagian garis besar, mencoba menemukan bagian yang sesuai dari keempat yang dinyatakan. Bagian pertama tidak tepat karena tag posnya lebih jauh dari garis besar daripada tag pos di bagian 2, 3, dan 4. Dari bagian yang lebih tepat ini, bagian kedua dipilih berdasarkan kedekatannya dengan awal dokumen. Begitulah gelarnya masuk ke cuplikan.
Faktanya, logika untuk memilih judul untuk snippet identik untuk kedua mesin pencari. Yandex cukup memilih tag heading pertama dari jalur pertama (tag <head> secara implisit) dalam dokumen, dan Google memilih tag heading pertama dari jalur yang ditandai secara semantik (tag <div class = "content"> jelas-jelas itu).
Ini adalah fitur luar biasa dari pencarian, yang disebut "tidak berdokumen" pada awal penyelidikan saya. Tag <h1> tidak benar-benar memiliki tanda penting. Berdasarkan permintaan pencarian pengguna, garis besar bagian pencocokan dalam dokumen dan judul pertama dalam garis besar dipilih tanpa memperhitungkan tingkat judul numerik yang digunakan.
Bahan bekas
[1] Satu H1 atau beberapa - mengapa ini benar? , Maret 2020. Impera, Dokumen SEO. Kutipan dari spesifikasi standar HTML menunjukkan bahwa menulis satu atau lebih tag H1 pada halaman dianggap benar dalam kedua kasus.
[2] Kasus Promosi Aplikasi Seluler Monobank , Agustus 2017 - Maret 2018. Promodo, Kasus. Contoh peristiwa yang digunakan oleh agensi tersebut adalah cara mempromosikan aplikasi seluler di iOS dan Android menggunakan AdWords, Facebook, Instagram, Twitter, YouTube, dan juga mengoptimalkannya di App Store dan Google Play.