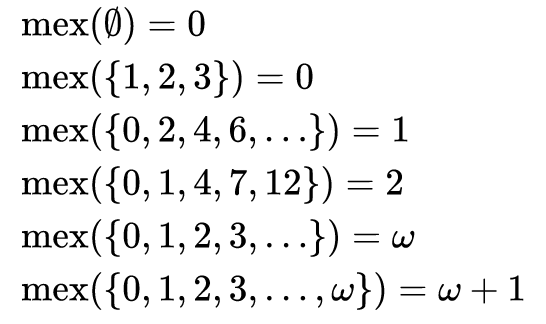
Kami akan memecah tiga algoritma dan melihat kinerjanya.
Selamat datang di bawah luka
Kata pengantar
Sebelum memulai, saya ingin memberi tahu Anda - mengapa saya memulai algoritma ini sama sekali?
Semuanya dimulai dengan teka-teki di OZON.

Seperti yang Anda lihat dari soal, dalam matematika, hasil dari fungsi MEX pada himpunan bilangan adalah nilai terkecil dari seluruh himpunan yang bukan milik himpunan ini. Artinya, ini adalah nilai minimum dari himpunan tambahan. Nama "MEX" adalah singkatan dari nilai "Minimum EXcluded".
Dan setelah mencari-cari di jaringan, ternyata tidak ada algoritma yang diterima secara umum untuk menemukan MEX ...
Ada solusi langsung , ada opsi dengan array tambahan, grafik, tetapi entah bagaimana semua ini tersebar di berbagai sudut Internet dan tidak ada satu pun artikel normal tentang hal ini. Jadi ide itu lahir - untuk menulis artikel ini. Pada artikel ini, kami akan menganalisis tiga algoritma untuk menemukan MEX dan melihat apa yang kami dapatkan dalam hal kecepatan dan memori.
Kode akan berada di C #, tetapi secara umum tidak akan ada konstruksi khusus.
Kode dasar untuk cek akan seperti ini.
static void Main(string[] args)
{
//MEX = 2
int[] values = new[] { 0, 12, 4, 7, 1 };
//MEX = 5
//int[] values = new[] { 0, 1, 2, 3, 4 };
//MEX = 24
//int[] values = new[] { 11, 10, 9, 8, 15, 14, 13, 12, 3, 2, 0, 7, 6, 5, 27, 26, 25, 4, 31, 30, 28, 19, 18, 17, 16, 23, 22, 21, 20, 43, 1, 40, 47, 46, 45, 44, 35, 33, 32, 39, 38, 37, 36, 58, 57, 56, 63, 62, 60, 51, 49, 48, 55, 53, 52, 75, 73, 72, 79, 77, 67, 66, 65, 71, 70, 68, 90, 89, 88, 95, 94, 93, 92, 83, 82, 81, 80, 87, 86, 84, 107, 106, 104 };
//MEX = 1000
//int[] values = new int[1000];
//for (int i = 0; i < values.Length; i++) values[i] = i;
//
int total = 0;
int mex = GetMEX(values, ref total);
Console.WriteLine($"mex: {mex}, total: {total}");
Console.ReadKey();
}
Dan satu poin lagi dalam artikel tersebut, saya sering menyebut kata "array", meskipun "set" akan lebih tepat, maka saya ingin meminta maaf sebelumnya kepada mereka yang akan dipotong oleh asumsi ini.
Catatan 1 berdasarkan komentar : Banyak yang menemukan kesalahan dengan O (n), mereka mengatakan semua algoritma adalah O (n) dan tidak peduli bahwa "O" berbeda di mana-mana dan tidak benar-benar membandingkan jumlah iterasi. Kemudian, untuk ketenangan pikiran, kami mengubah O menjadi T. Di mana T adalah operasi yang kurang lebih dapat dimengerti: cek atau penugasan. Jadi, seperti yang saya pahami, akan lebih mudah bagi semua orang
Catatan 2 berdasarkan komentar : kami sedang mempertimbangkan kasus ketika set asli TIDAK dipesan. Menyortir set ini juga membutuhkan waktu.
1) Keputusan di dahi
Bagaimana kita menemukan "nomor yang hilang minimum"? Opsi termudah adalah membuat penghitung dan mengulangi array sampai kita menemukan angka yang sama dengan penghitung.
static int GetMEX(int[] values, ref int total)
{
for (int mex = 0; mex < values.Length; mex++)
{
bool notFound = true;
for (int i = 0; i < values.Length; i++)
{
total++;
if (values[i] == mex)
{
notFound = false;
break;
}
}
if (notFound)
{
return mex;
}
}
return values.Length;
}
}
Kasus paling mendasar. Kompleksitas algoritma adalah T (n * sel (n / 2)) ... untuk kasus {0, 1, 2, 3, 4} kita perlu mengulangi semua angka karena melakukan 15 operasi. Dan untuk deretan 100 yang benar-benar lengkap, termasuk 5050 operasi ... Kinerja biasa saja.
2) Pemutaran
Opsi implementasi paling kompleks kedua cocok dengan T (n) ... Yah, atau hampir T (n), matematikawan itu licik dan tidak memperhitungkan persiapan data ... Untuk, setidaknya, kita perlu mengetahui jumlah maksimum di set.
Dari sudut pandang matematika, terlihat seperti ini.
Sebuah bit array S dengan panjang m diambil (di mana m adalah panjang dari array V) diisi dengan 0. Dan dalam satu lintasan himpunan asli (V) dalam larik (S) diset ke 1. Setelah itu, dalam satu lintasan, kami menemukan nilai kosong pertama. Semua nilai yang lebih besar dari m dapat diabaikan begitu saja. jika array berisi nilai "tidak cukup" hingga m, maka itu jelas akan kurang dari panjang m.
static int GetMEX(int[] values, ref int total)
{
bool[] sieve = new bool[values.Length];
for (int i = 0; i < values.Length; i++)
{
total++;
var intdex = values[i];
if (intdex < values.Length)
{
sieve[intdex] = true;
}
}
for (int i = 0; i < sieve.Length; i++)
{
total++;
if (!sieve[i])
{
return i;
}
}
return values.Length;
}
Karena "Ahli matematika" adalah orang yang licik. Kemudian mereka mengatakan bahwa hanya ada satu yang melewati array asli, algoritma T (n) ... Mereka
duduk dan bersukacita bahwa algoritma yang keren telah ditemukan, tetapi kenyataannya adalah demikian.
Pertama, Anda harus menelusuri larik asli dan menandai nilai ini dalam larik S T1 (n)
.Kedua, Anda harus menelusuri larik S dan menemukan sel T2 (n) pertama yang tersedia di sana
. semua operasi secara umum tidak rumit, semua perhitungan dapat disederhanakan menjadi T (n * 2)
Tapi ini jelas lebih baik daripada solusi langsung ... Mari kita periksa data pengujian kami:
- Untuk kasus {0, 12, 4, 7, 1}: Dahi : 11 iterasi, pengayakan : 8 iterasi
- { 0, 1, 2, 3, 4 }: : 15 , : 10
- { 11,…}: : 441 , : 108
- { 0,…,999}: : 500500 , : 2000
Faktanya adalah bahwa jika "nilai yang hilang" adalah angka kecil, maka dalam hal ini, keputusan langsung ternyata lebih cepat, karena tidak memerlukan triple melintasi array. Tetapi secara umum, pada dimensi besar jelas kalah dengan penyaringan, yang tidak terlalu mengejutkan.
Dari sudut pandang "ahli matematika" - algoritme sudah siap, dan itu bagus, tetapi dari sudut pandang "programmer" - ini mengerikan karena jumlah RAM yang terbuang, dan umpan terakhir untuk ditemukan nilai kosong pertama jelas ingin dipercepat.
Mari lakukan ini dan optimalkan kodenya.
static int GetMEX(int[] values, ref int total)
{
var max = values.Length;
var size = sizeof(ulong) * 8;
ulong[] sieve = new ulong[(max / size) + 1];
ulong one = 1;
for (int i = 0; i < values.Length; i++)
{
total++;
var intdex = values[i];
if (intdex < values.Length)
{
sieve[values[i] / size] |= (one << (values[i] % size));
}
}
var maxInblock = ulong.MaxValue;
for (int i = 0; i < sieve.Length; i++)
{
total++;
if (sieve[i] != maxInblock)
{
total--;
for (int j = 0; j < size; j++)
{
total++;
if ((sieve[i] & (one << j)) == 0)
{
return i * size + j;
}
}
}
}
return values.Length;
}
Apa yang telah kita lakukan di sini. Pertama, jumlah RAM yang dibutuhkan telah berkurang 64 kali lipat.
var size = sizeof(ulong) * 8;
ulong[] sieve = new ulong[(max / size) + 1];
Hasilnya, algoritma sieve memberi kita hasil berikut:
- Untuk kasus {0, 12, 4, 7, 1}: penyaringan : 8 iterasi, penyaringan optimasi : 8 iterasi
- Untuk kasus {0, 1, 2, 3, 4}: penyaringan : 10 iterasi, penyaringan optimasi : 11 iterasi
- Untuk kasus {11, ...}: pengayakan : 108 iterasi, pengayakan dengan optimasi : 108 iterasi
- Untuk kasus {0, ..., 999}: penyaringan : 2000 iterasi, penyaringan dengan optimasi : 1056 iterasi
Jadi, apa intinya dalam teori kecepatan?
Kami mengubah T (n * 3) menjadi T (n * 2) + T (n / 64) secara keseluruhan, sedikit meningkatkan kecepatan, dan bahkan mengurangi jumlah RAM sebanyak 64 kali. apa baik)
3) Penyortiran
Seperti yang Anda duga, cara termudah untuk menemukan elemen yang hilang dalam suatu himpunan adalah dengan mengurutkan himpunan.
Algoritma pengurutan tercepat adalah "quicksort", yang memiliki kompleksitas T1 (n log (n)). Dan secara total, kami mendapatkan kompleksitas teoretis untuk menemukan MEX di T1 (n log (n)) + T2 (n)
static int GetMEX(int[] values, ref int total)
{
total = values.Length * (int)Math.Log(values.Length);
values = values.OrderBy(x => x).ToArray();
for (int i = 0; i < values.Length - 1; i++)
{
total++;
if (values[i] + 1 != values[i + 1])
{
return values[i] + 1;
}
}
return values.Length;
}
Menawan. Tidak ada tambahan.
Periksa jumlah iterasi
- Untuk kasus {0, 12, 4, 7, 1}: penyaringan dengan optimisasi : 8, pengurutan : ~ 7 iterasi
- Untuk kasus {0, 1, 2, 3, 4}: penyaringan dengan optimasi : 11 iterasi, sorting : ~ 9 iterasi
- { 11,…}: : 108 , : ~356
- { 0,…,999}: : 1056 , : ~6999
Ini adalah nilai rata-rata, dan tidak sepenuhnya adil. Tetapi secara umum: pengurutan tidak memerlukan memori tambahan dan jelas memungkinkan Anda untuk menyederhanakan langkah terakhir dalam iterasi.
Catatan : values.OrderBy (x => x) .ToArray () - ya, saya tahu bahwa memori telah dialokasikan di sini, tetapi jika Anda melakukannya dengan bijak, Anda dapat mengubah array, bukan menyalinnya ...
Jadi saya punya ide untuk mengoptimalkan quicksort untuk pencarian MEX. Saya tidak menemukan versi algoritma ini di Internet, baik dari sudut pandang matematika, dan terlebih lagi dari sudut pandang pemrograman. Kemudian kita akan menulis kode dari 0 di jalan, muncul dengan tampilannya: D
Tapi pertama-tama, mari kita ingat bagaimana quicksort bekerja secara umum. Saya akan memberikan tautan, tetapi sebenarnya tidak ada penjelasan normal tentang quicksort di jari, tampaknya penulis manual sendiri memahami algoritme saat membicarakannya ...
Jadi inilah quicksort:
Kami memiliki array yang tidak berurutan {0, 12, 4, 7 , 1}
Kita membutuhkan "angka acak", tetapi lebih baik untuk mengambil salah satu dari array - ini disebut nomor referensi (T).
Dan dua pointer: L1 - melihat elemen pertama dari array, L2 melihat elemen terakhir dari array.
0, 12, 4, 7, 1
L1 = 0, L2 = 1, T = 1 (T mengambil yang terakhir bodoh)
Tahap iterasi pertama :
Sampai kita bekerja hanya dengan pointer L1.
Geser sepanjang array ke kanan sampai kita menemukan angka yang lebih besar dari referensi kita.
Dalam kasus kita, L1 sama dengan 8. Tahap
kedua dari iterasi :
Sekarang kita menggeser pointer L2, menggesernya
sepanjang array ke kiri sampai kita menemukan angka yang kurang dari atau sama dengan referensi kita.
Dalam hal ini, L2 sama dengan 1. Karena Saya mengambil nomor referensi yang sama dengan elemen ekstrim dari array, dan melihat L2 di sana juga.
Tahap ketiga dari iterasi :
Ubah angka pada pointer L1 dan L2, jangan memindahkan pointer.
Dan kita lolos ke tahap pertama dari iterasi.
Kami mengulangi langkah-langkah ini sampai pointer L1 dan L2 sama, bukan nilainya, tetapi pointernya. itu. mereka harus menunjuk ke satu item.
Setelah pointer bertemu pada beberapa elemen, kedua bagian array tetap tidak akan diurutkan, tetapi yang pasti, di satu sisi "penggabungan pointer (L1 dan L2)" akan ada elemen yang kurang dari T, dan pada lainnya, lebih dari T. Yaitu fakta ini memungkinkan kita untuk membagi array menjadi dua kelompok independen yang dapat diurutkan dalam aliran yang berbeda dalam iterasi lebih lanjut.
Sebuah artikel di wiki, jika saya tidak mengerti apa yang tertulis
Mari kita menulis Quicksort
static void Quicksort(int[] values, int l1, int l2, int t, ref int total)
{
var index = QuicksortSub(values, l1, l2, t, ref total);
if (l1 < index)
{
Quicksort(values, l1, index - 1, values[index - 1], ref total);
}
if (index < l2)
{
Quicksort(values, index, l2, values[l2], ref total);
}
}
static int QuicksortSub(int[] values, int l1, int l2, int t, ref int total)
{
for (; l1 < l2; l1++)
{
total++;
if (t < values[l1])
{
total--;
for (; l1 <= l2; l2--)
{
total++;
if (l1 == l2)
{
return l2;
}
if (values[l2] <= t)
{
values[l1] = values[l1] ^ values[l2];
values[l2] = values[l1] ^ values[l2];
values[l1] = values[l1] ^ values[l2];
break;
}
}
}
}
return l2;
}
Mari kita periksa jumlah iterasi sebenarnya:
- { 0, 12, 4, 7, 1 }: : 8, : 11
- { 0, 1, 2, 3, 4 }: : 11 , : 14
- { 11,…}: : 108 , : 1520
- { 0,…,999}: : 1056 , : 500499
Coba kita renungkan berikut ini. Larik {0, 4, 1, 2, 3} tidak memiliki elemen yang hilang, dan panjangnya adalah 5. Artinya, ternyata array tanpa elemen yang hilang sama dengan panjang array - 1. Artinya, m = {0, 4, 1, 2, 3}, Panjang (m) == Max (m) + 1. Dan yang terpenting pada saat ini adalah kondisi ini benar jika nilai-nilai dalam array adalah diatur ulang. Dan yang penting adalah kondisi ini dapat diperluas ke bagian-bagian dari array. Yaitu, seperti ini:
{0, 4, 1, 2, 3, 12, 10, 11, 14} mengetahui bahwa di sisi kiri array, semua angka kurang dari nomor referensi tertentu, misalnya 5, dan di sebelah kanan, segala sesuatu yang lebih besar tidak masuk akal untuk mencari jumlah minimum di sebelah kiri.
itu. jika kita tahu pasti bahwa di salah satu bagian tidak ada elemen yang lebih besar dari nilai tertentu, maka nomor yang hilang ini sendiri harus dicari di bagian kedua dari array. Secara umum, beginilah cara kerja algoritma pencarian biner.
Akibatnya, saya mendapat ide untuk menyederhanakan quicksort untuk pencarian MEX dengan menggabungkannya dengan pencarian biner. Biarkan saya memberi tahu Anda segera bahwa kita tidak perlu mengurutkan seluruh array sepenuhnya, hanya bagian-bagian yang akan kita cari.
Hasilnya, kami mendapatkan kode
static int GetMEX(int[] values, ref int total)
{
return QuicksortMEX(values, 0, values.Length - 1, values[values.Length - 1], ref total);
}
static int QuicksortMEX(int[] values, int l1, int l2, int t, ref int total)
{
if (l1 == l2)
{
return l1;
}
int max = -1;
var index = QuicksortMEXSub(values, l1, l2, t, ref max, ref total);
if (index < max + 1)
{
return QuicksortMEX(values, l1, index - 1, values[index - 1], ref total);
}
if (index == values.Length - 1)
{
return index + 1;
}
return QuicksortMEX(values, index, l2, values[l2], ref total);
}
static int QuicksortMEXSub(int[] values, int l1, int l2, int t, ref int max, ref int total)
{
for (; l1 < l2; l1++)
{
total++;
if (values[l1] < t && max < values[l1])
{
max = values[l1];
}
if (t < values[l1])
{
total--;
for (; l1 <= l2; l2--)
{
total++;
if (values[l2] == t && max < values[l2])
{
max = values[l2];
}
if (l1 == l2)
{
return l2;
}
if (values[l2] <= t)
{
values[l1] = values[l1] ^ values[l2];
values[l2] = values[l1] ^ values[l2];
values[l1] = values[l1] ^ values[l2];
break;
}
}
}
}
return l2;
}
Periksa jumlah iterasi
- Untuk kasus {0, 12, 4, 7, 1}: penyaringan dengan optimasi : 8, MEX sort : 8 iterasi
- { 0, 1, 2, 3, 4 }: : 11 , MEX: 4
- { 11,…}: : 108 , MEX: 1353
- { 0,…,999}: : 1056 , MEX: 999
Kami mendapat opsi pencarian MEX yang berbeda. Mana yang lebih baik terserah Anda.
Umumnya. Saya paling suka screening , dan inilah alasannya:
Dia memiliki waktu eksekusi yang sangat mudah ditebak. Selain itu, algoritma ini dapat dengan mudah digunakan dalam mode multi-threaded. itu. bagi array menjadi beberapa bagian dan jalankan setiap bagian dalam utas terpisah:
for (int i = minIndexThread; i < maxIndexThread; i++)
sieve[values[i] / size] |= (one << (values[i] % size));
Satu-satunya hal yang Anda butuhkan adalah kunci saat menulis saringan [nilai [i] / ukuran] . Dan satu hal lagi - algoritma ini ideal untuk membongkar data dari database. Anda dapat memuat dalam kemasan 1000 buah, misalnya, di setiap aliran dan itu akan tetap berfungsi.
Tetapi jika kita memiliki kekurangan memori yang parah, maka penyortiran MEX jelas terlihat lebih baik.
PS
Saya memulai cerita saya dengan kompetisi untuk OZON di mana saya mencoba untuk berpartisipasi, membuat "versi awal" dari algoritma penyaringan, saya tidak pernah menerima hadiah untuk itu, OZON merasa itu tidak memuaskan ... Untuk alasan apa - dia tidak pernah mengaku . .. Dan kode pemenangnya juga belum saya lihat. Adakah yang bisa punya ide tentang cara menyelesaikan masalah pencarian MEX dengan lebih baik?