
Pada artikel ini, saya akan berbicara tentang salah satu metode untuk memperbaiki ketidakseimbangan kelas yang diprediksi. Penting untuk diklarifikasi bahwa banyak metode yang membangun model probabilistik bekerja dengan baik tanpa mengoreksi ketidakseimbangan. Namun, ketika kita beralih ke membangun model kemustahilan atau ketika kita mempertimbangkan masalah klasifikasi dengan sejumlah besar kelas, ada baiknya untuk memperhatikan masalah ketidakseimbangan kelas.
, ́ , , , . , .
NearMiss — . ́ . , .
. pip cmd:
pip install pandas
pip install numpy
pip install sklearn
pip install imblearn
, - -.
import pandas as pd
import numpy as np
df = pd.read_csv('online_shoppers_intention.csv')
df.shape
(12330, 18)
«Revenue» 2 : True ( ) False ( ). , .
df['Revenue'].value_counts()
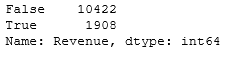
, , 85% 15%.
:
Y = df['Revenue']
X = df.drop('Revenue', axis = 1)
feature_names = X.columns
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 97)
:
print(' X_train: ', X_train.shape)
print(' Y_train: ', Y_train.shape)
print(' X_test: ', X_test.shape)
print(' Y_test: ', Y_test.shape)

.
from sklearn.linear_model import LogisticRegression
lregress1 = LogisticRegression()
lregress1.fit(X_train, Y_train.ravel())
prediction = lregress1.predict(X_test)
print(classification_report(Y_test, prediction))
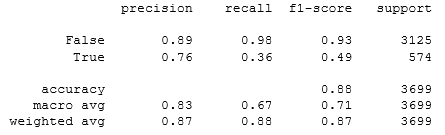
, 88%. «recall» , . , , .
NearMiss :
print(' - True: {}'.format(sum(y_train == True)))
print(' - False: {}'.format(sum(y_train == False)))
True: 1334
False: 7297
.
from imblearn.under_sampling import NearMiss
nm = NearMiss()
X_train_miss, Y_train_miss = nm.fit_resample(X_train, Y_train.ravel())
print(' - True: {}'.format(sum(Y_train_miss == True)))
print(' - False: {}'.format(sum(Y_train_miss == False)))
True: 1334
False: 1334
Dapat dilihat bahwa metode telah meratakan kelas, mengurangi dimensi kelas dominan. Mari gunakan regresi logistik dan tampilkan laporan dengan indikator klasifikasi utama.
lregress2 = LogisticRegression()
lregress2.fit(X_train_miss, Y_train_miss.ravel())
prediction = lregress2.predict(X_test)
print(classification_report(Y_test, prediction))

Nilai ulasan minoritas naik menjadi 84%. Tetapi karena fakta bahwa sampel kelas yang lebih besar berkurang secara signifikan, akurasi model menurun menjadi 61%. Jadi metode ini sangat membantu untuk mengatasi ketidakseimbangan kelas.