 Kami di ABBYY telah lama
menangani masalah Natural Language Processing (NLP). Teknologi pemrosesan bahasa alami adalah inti dari banyak solusi NLP ABBYY untuk mencari dan mengekstrak data. Dengan bantuan mereka, kami membantu raksasa industri NPO Energomash
untuk melakukan pencarian sesuai dengan dokumen yang dikumpulkan di perusahaan selama hampir 100 tahun, dan salah satu bank besar
menggunakanteknologi kami untuk memantau aliran berita raksasa dan mengelola risiko. Dalam posting ini, kami akan menjelaskan bagaimana teknologi NLP kami bekerja secara internal untuk mengekstraksi informasi dari teks padat. Kami tidak akan berbicara tentang teks dalam tabel dan formulir yang terstruktur dengan jelas, seperti catatan konsinyasi, tetapi tentang dokumen tidak terstruktur multi-halaman: perjanjian sewa, catatan medis, dan banyak lagi.
Kami di ABBYY telah lama
menangani masalah Natural Language Processing (NLP). Teknologi pemrosesan bahasa alami adalah inti dari banyak solusi NLP ABBYY untuk mencari dan mengekstrak data. Dengan bantuan mereka, kami membantu raksasa industri NPO Energomash
untuk melakukan pencarian sesuai dengan dokumen yang dikumpulkan di perusahaan selama hampir 100 tahun, dan salah satu bank besar
menggunakanteknologi kami untuk memantau aliran berita raksasa dan mengelola risiko. Dalam posting ini, kami akan menjelaskan bagaimana teknologi NLP kami bekerja secara internal untuk mengekstraksi informasi dari teks padat. Kami tidak akan berbicara tentang teks dalam tabel dan formulir yang terstruktur dengan jelas, seperti catatan konsinyasi, tetapi tentang dokumen tidak terstruktur multi-halaman: perjanjian sewa, catatan medis, dan banyak lagi.
Kami kemudian akan menunjukkan kepada Anda bagaimana ini bekerja dalam praktik. Misalnya, cara mengekstrak entitas X dari perjanjian bank 200 halaman dalam X menit. Baik pastikan kontrak hukumnya benar, atau dapatkan informasi tentang efek samping langka dengan cepat dari kumpulan artikel medis. Pengalaman kami menunjukkan bahwa perusahaan perlu memperoleh data tersebut dengan cepat dan tanpa kesalahan, karena kesejahteraan bisnis dan orang-orang bergantung padanya.
Di akhir posting, kami akan menyebutkan beberapa kesulitan yang kami temui saat melakukan proyek tersebut, dan berbagi pengalaman kami tentang bagaimana kami berhasil menyelesaikannya. Nah, selamat datang di kucing.
Jadi apa yang kita lakukan?
Secara umum, teknologi pemrosesan dan analisis bahasa alami memungkinkan banyak hal: menyaring spam dalam email, membuat sistem terjemahan mesin, mengenali ucapan, dan mengembangkan serta melatih bot obrolan. Teknologi NLP ABBYY membantu bank, industri, dan organisasi lain dengan cepat mengekstrak dan menyusun sejumlah besar informasi dari dokumen bisnis. Perusahaan besar telah lama mengotomatisasi, atau setidaknya berusaha untuk mengurangi, jumlah manual, operasi rutin. Kita berbicara tentang mencari di dokumen kertas untuk tanggal, nama lengkap, jumlah, NPWP, nomor faktur; mencetak ulang data ke dalam sistem informasi perusahaan, memeriksa apakah semuanya terisi dengan benar.
Ingatlah bahwa awalnya kami dapat mengekstrak teks dari dokumen berdasarkan fitur geometris, khususnya struktur dan susunan garis dan bidang. Dengan demikian, masih nyaman untuk memproses informasi dari kuesioner terstruktur, formulir ketat, kuesioner, aplikasi, formulir sensus, dll. Omong-omong, kami berbicara di Habré tentang kasus seperti itu - dengan bantuan ABBYY FlexiCapture, Kementerian Kesehatan Bangladesh memproses kuesioner sensus medis yang diisi oleh penduduk republik.
Jelas bahwa informasi penting disimpan tidak hanya dalam bentuk, jadi kami melatih solusi NLP kami untuk "mengekstrak" data dari dokumen yang tidak memiliki struktur sama sekali atau sangat kompleks. Mungkin banyak orang yang ingat tentang ABBYY Compreno untuk analisis dan pemahaman bahasa alami. Kami telah mengembangkan dan meningkatkan teknologi, dan selanjutnya menjadi dasar dari banyak solusi NLP kami. Salah satu kasus penggunaan NLP adalah proyek dengan memantau berita di beberapa bank besar Rusia. Singkatnya, mesin kami mampu melakukan pekerjaan penjamin emisi bank - seseorang yang menangkap peristiwa tentang rekanan dari arus informasi yang sangat besar dan menilai risiko. Baca lebih lanjut tentang itu di sini .
Di bawah ini kita akan berbicara tentang aspek lain - ekstraksi informasi dari dokumen tidak terstruktur seperti kontrak, catatan medis, berita dari berbagai sumber.

Bagaimana teknologi NLP kami bekerja
Secara konseptual, pemrosesan dokumen dari saat dimuat ke ABBYY FlexiCapture hingga bidang yang diperlukan diekstraksi terlihat seperti ini:
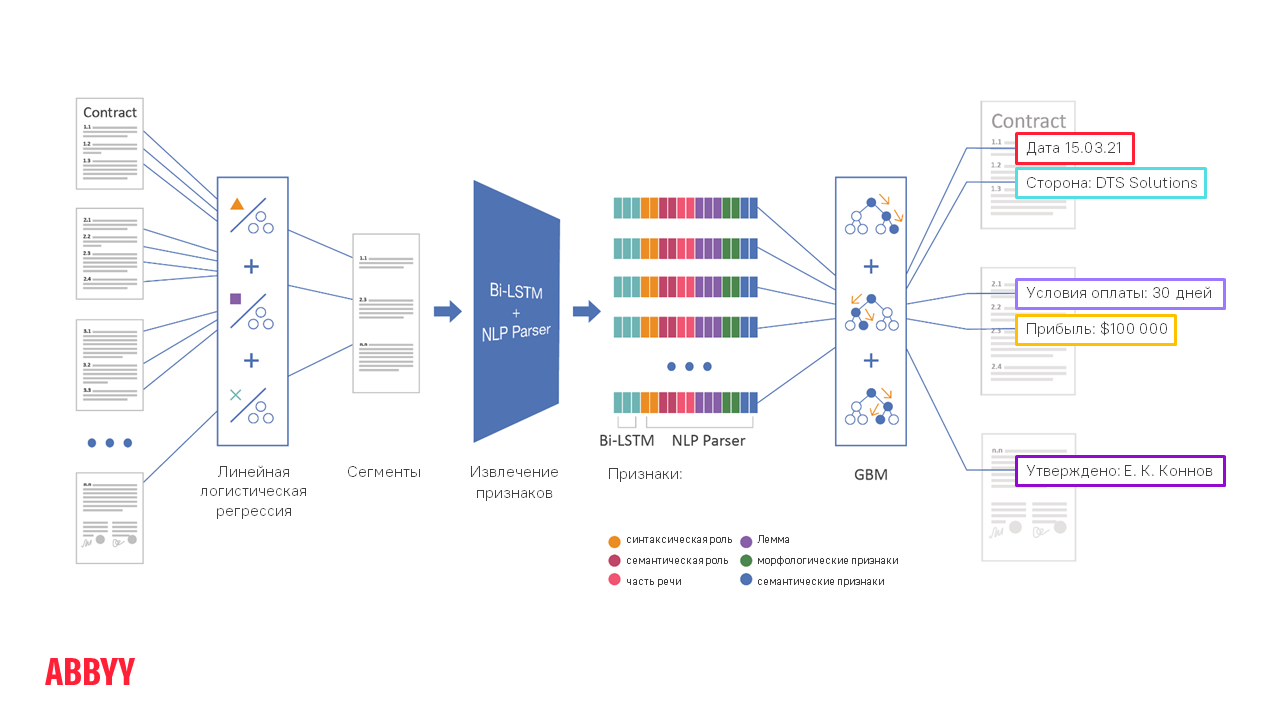
Katakanlah Anda perlu mengekstrak tanggal dan tempat penandatanganan, serta nama perusahaan yang berpartisipasi dari kontrak 50 halaman . 50 halaman, Karl! Dan ada banyak tanggal! Bagaimana cara menemukan halaman yang dicari klien? Teknologi membantu melakukan ini dalam beberapa tahap.
Tahap segmentasi
Selanjutnya, dokumen tersegmentasi , yaitu, kami mempersempit area untuk menemukan informasi dan memproses tidak semua 50 halaman, tetapi hanya, katakanlah, 5 segmen per paragraf, di mana tanggal yang kami butuhkan mungkin. Jadi jauh lebih mudah bagi algoritme untuk bekerja, serta untuk membedakan tanggal yang diperlukan dari yang lain.
Semua tahapan di sebelah kanan segmentasi pada diagram menggambarkan pengoperasian algoritma NLP - studi terperinci, membaca, dan memahami teks. Proses ini memakan waktu 10-20 kali lebih lama daripada klasifikasi dan segmentasi, jadi tidak sepenuhnya benar untuk menjalankannya di seluruh dokumen multi-halaman. Lebih mudah untuk "menghasut" mereka ke sejumlah kecil teks.
Cara Kerja NLP Parser + Bi-LSTM
Dengan bantuan mereka, tanda (fitur) diekstraksi dari setiap kalimat dalam teks. Ini adalah teknologi ABBYY Compreno, yang berfungsi sebagai bagian dari FlexiCapture. Mesin membaca teks secara detail dan mengekstrak banyak fitur generalisasi darinya. Ia tidak hanya mengerti apa yang secara khusus dirumuskan dalam kalimat ini, tetapi juga makna – apa yang sebenarnya dimaksudkan.
Ekstraksi fitur adalah langkah yang panjang. Ada tanda-tanda tingkat tinggi. Secara kasar, mereka menunjukkan bahwa dalam fragmen ini, sesuatu seperti nama melakukan sesuatu seperti tindakan dengan beberapa objek dari beberapa kelas semantik. Kemudian, pada fitur tingkat tinggi yang diekstraksi, diterapkan metode ML-GBM yang cukup sederhana dan klasik. Ini adalah ansambel pohon keputusan yang memberikan solusi umum dan menyoroti bidang yang diekstraksi. Agar GBM dapat belajar dengan cepat dan mengekstrak informasi berkualitas, penting untuk memiliki jumlah dokumen yang cukup untuk pelatihan. Jika jumlahnya sedikit, maka kualitas ekstraksi informasi dapat menurun. Ini disebabkan oleh fakta bahwa inti kasus menjadi lebih kecil dan, karenanya, "mesin" lebih buruk dalam menggeneralisasi - untuk membedakan kasus individu dari yang sering.

Di mana itu digunakan?
Berikut adalah beberapa contoh dari praktik kami - proyek yang diimplementasikan, percontohan, atau kasus konsep.
NLP untuk lembaga keuangan

Pelanggan sering meminta kami untuk memproses faktur (invoice) dan pesanan pembelian. Beberapa data (atau bidang), blok dengan teks atau dengan alamat, dapat diekstraksi menggunakan metode tradisional, mengandalkan kata kunci. Tetapi jika Anda perlu melihat ke dalam blok teks, maka NLP diperlukan. Itu juga terjadi bahwa Anda perlu "mendapatkan" bukan seluruh blok dengan alamat, tetapi hanya sebagian dari alamat ini: jalan, negara bagian, kota, kode pos, negara. Atau Anda perlu mengurai tanggal dan persentase diskon jika faktur memerlukan pembayaran sebelum tanggal tertentu. Teknologi kami membantu mempertimbangkan variabel-variabel tersebut: berapa biaya pesanan jika dibayar di muka atau dalam jumlah besar, dan berapa banyak jika dibayar terlambat.
Kami juga membantu departemen hukum perusahaan besar mengekstrak data penting dari kontrak layanan, laporan kemajuan, NDA (dokumen nondisclosure). Mari kita ambil contoh salah satu proyek kami yang berhubungan dengan perjanjian sewa komersial. Yaitu dokumen sebanyak 30 halaman, data dari field-field pada setiap halaman yang sebelumnya dimasukkan pelanggan ke dalam sistem informasi secara manual. Ini biasanya memakan waktu satu jam untuk satu dokumen. FlexiCapture menyelesaikan tugas dalam dua menit dan, menurut perhitungan klien, menghemat 5.000 jam kerja dalam setahun.
Atau mengambil perjanjian pinjaman. Pinjaman diambil tidak hanya oleh orang-orang, tetapi juga oleh perusahaan besar. Untuk melakukan ini, mereka memberi bank paket dokumen yang besar. Katakanlah informasi tentang pinjaman komersial yang tersedia. Dan ini bukan semacam hipotek untuk 6 juta rubel, tetapi hipotek untuk 100 juta dolar (untuk bangunan, kantor). Dan kemudian bank perlu mengekstrak 50-70 entitas atau kondisi dari dokumen setebal 250 halaman tersebut. Butuh waktu lama untuk memproses secara manual, menurut perhitungan pelanggan kami - 2-3 jam per dokumen. Dengan FlexiCapture, semuanya siap dalam 9 menit. Tidak secara instan, kami mengerti. Alasannya adalah dalam desain dokumen: mereka biasanya memiliki kepadatan teks yang tinggi, dan sejumlah besar entitas yang berbeda harus diekstraksi. Bukan hal kedua :)
Aplikasi Pinjaman juga sering diproses. Ini adalah dokumen awal dengan pertanyaan yang dikirimkan bank kepada klien. Semakin besar jumlah pinjaman, semakin banyak pertanyaan yang ada dalam kuesioner semacam itu. Misalnya, dalam informasi tempat kerja, bank mungkin meminta Anda untuk menunjukkan pengenal dan alamat resminya. Bank sering memerlukan klarifikasi informasi tentang status perkawinan, ketersediaan pinjaman, hutang untuk utilitas, tunjangan dan hal-hal lain yang dapat mengganggu pembayaran kembali pinjaman. Terkadang pertanyaan dalam Aplikasi Pinjaman cukup kompleks, sehingga beberapa perusahaan membantu pelanggan mereka menerjemahkan dari bahasa resmi ke bahasa umum untuk memahami dan menjelaskan secara manusiawi apa yang mereka inginkan dari klien.
Dalam memproses dokumen lengkap seperti itu, kesulitan utama terletak pada banyaknya bidang (dalam kasus kami, ada 105 di antaranya). Sangat mudah bagi karyawan bank untuk menjadi bingung di dalamnya, tetapi ini tidak dapat menurunkan teknologi. FlexiCapture menghabiskan 5 menit untuk semuanya, seorang karyawan - hingga 2-3 jam. Rasakan perbedaannya, seperti yang mereka katakan.
Perawatan Kesehatan
Bagian dari proyek ABBYY terkait dengan ekstraksi informasi dari dokumen medis.

Misalnya, dengan menggunakan NLP, Anda dapat memproses Abstrak artikel medis ilmiah. Ada arah seperti itu dalam farmakologi - Pharmacovigilance. Ini sedang menyelidiki efek samping yang dapat ditimbulkan obat baru pada pasien yang belum dijelaskan. Organisasi medis mengumpulkan informasi tentang kasus kritis tersebut dari pasien dan menyusun laporan rinci tentang mereka - Laporan Keselamatan Kasus Individu (ICSR). Jika pil baru membahayakan seseorang, maka pabrikan harus segera melaporkan hal ini ke badan pengawas, jika tidak, ia bisa menghadapi denda besar. Untuk menghindari konsekuensi seperti itu, karyawan perusahaan farmasi yang berkualifikasi tinggi membaca ICSR dalam jumlah banyak. Tugas yang cukup melelahkan.
Jauh lebih mudah untuk memecahkan teka-teki teknologi dengan ini. Sebagai bagian dari salah satu percontohan Pharmacovigilance, teknologi kami mengekstrak data dari artikel medis seperti jenis kelamin dan usia pasien, informasi tentang peristiwa yang terjadi padanya, dan nama obatnya. Semuanya kecuali yang terakhir diekstraksi menggunakan pembelajaran mesin. Tetapi untuk nama obat, kami menggunakan metode yang lebih sederhana - kamus. Intinya adalah bahwa klien meminta untuk mengekstrak tidak semua obat yang mungkin dari artikel, tetapi obat dari daftar dengan 80 nama. Dalam hal ini, pencocokan kamus bekerja dengan baik. Kamus juga merupakan bagian dari FlexiCapture NLP. Morfologi digunakan untuk mencari nama suatu obat. Tidak masalah dalam bentuk atau daftar apa kata itu ditulis, terutama dalam bahasa Inggris jumlahnya tidak banyak.
Pemrosesan riwayat kasus juga otomatis, karena banyak informasi yang harus dilalui. Ini adalah tabel, kuitansi, dan deskripsi keputusan perusahaan asuransi. Misalnya, salah satu regulator di Amerika Serikat menerima keluhan dari pasien tentang asuransi. Itu terjadi bahwa perusahaan asuransi menolak untuk membayar perawatan. Alasannya mungkin berbeda, tetapi pasien memiliki hak untuk mencari tahu dan mengajukan permohonan ke lembaga pemerintah. Dan regulator harus menganalisis informasi dan mengeluarkan putusan, apakah penolakan itu benar-benar dibenarkan?
Jika tabel mudah diproses menggunakan FlexiLayout, maka potongan teks dengan keputusan asuransi tidak akan diproses. Kami menggunakan NLP untuk mengekstrak solusi itu sendiri dan alasannya dari teks.
Riwayat medis perlu dianalisis secara hati-hati ketika seorang pasien dipindahkan dari satu rumah sakit ke rumah sakit lainnya. Mengingat bahwa kita hidup di masa virus corona, terkadang ada banyak pasien seperti itu, dan sulit bagi staf rumah sakit untuk menangani terlalu banyak dokumen. Kasus di mana kami berpartisipasi tidak ada hubungannya dengan mahkota, tetapi berpotensi pengalaman kami masih berharga.
Real Estat
- Salah satu klien potensial kami menyewakan banyak tanah untuk konstruksi dan kantor. Oleh karena itu, perusahaan mengadakan banyak perjanjian sewa... Dia perlu secara otomatis memproses dokumen-dokumen tersebut: mengekstrak tanggal dan tenggat waktu dari mereka, sehingga nanti dia dapat melacak apakah mereka melewatkan pembayaran, ketika sewa berakhir, di mana kontrak diperpanjang secara otomatis, berapa semua biayanya.
- Perusahaan konstruksi juga memiliki spesialis seperti analis portofolio... Mereka menganalisis kontrak, mencari tahu berapa biaya properti tertentu dan membantu menilai seberapa bagusnya dan berapa banyak pendapatan yang dapat diberikan kepada pemiliknya. Seperti penilaian bank. Di AS, omong-omong, Anda dapat menjual atau membeli sebagian paket hipotek. Ini adalah keamanan, itu juga bisa naik atau turun harganya. Misalnya, jika harga real estat naik, maka hipotek yang lebih murah dapat dibiayai kembali. Dan jika semuanya menjadi lebih murah, maka klien mencoba membuang kertas ini.
Dalam kontrak semacam itu, ada informasi yang diperoleh baik dengan bantuan NLP maupun tanpanya. Data tabular - menggunakan FlexiLayout (ini yang bisa kami lakukan sebelumnya). Dan semua bidang lainnya adalah paragraf yang diekstraksi oleh segmenter, atau bidang di dalam paragraf yang diekstraksi oleh model ekstraksi.
Keuntungan dari teknologi NLP adalah mekanisme lain dimana lebih banyak jenis bidang dan dokumen dapat diproses.

- Salah satu klien kami adalah asosiasi pemilik rumah, dengan syarat SNT kami . Jika peserta baru masuk ke SNT seperti itu, maka dia diberikan paket 9 jenis dokumen - Akta (ini bisa berupa perjanjian jual beli). Kemudian data-data dari dokumen-dokumen lengkap tersebut harus diolah, diverifikasi dan dimasukkan ke dalam sistem informasi. 8 di antaranya terstruktur dan diproses oleh FlexiLayout. Tapi yang ke-9 dengan tangkapan. Untuk menyelesaikan proyek ini, perusahaan kami juga perlu memproses tindakan tidak terstruktur.
Itulah yang kami lakukan menggunakan NLP. Dokumen itu sendiri, di satu sisi, tidak terlalu banyak: 1-2 halaman. Di sisi lain, mereka sangat beragam dan berkualitas buruk. Meskipun demikian, solusi kami dapat mengekstrak informasi yang diperlukan. Proyek ini menarik karena bagian NLP-nya bisa sangat kecil, tetapi pada saat yang sama kritis, karena proyek tidak dapat diselesaikan tanpanya.
- Kebutuhan NLP dan untuk mengotomatisasi proses persetujuan kontrak (Contract Approval Automation). Perusahaan sering mengadakan perjanjian induk - perjanjian kerangka kerja (master) yang menetapkan persyaratan umum untuk sejumlah operasi di masa depan. Misalnya, apa yang harus dipenuhi klien, dalam kerangka waktu apa, sanksi keterlambatan apa, kapan harus membayar layanan.
Proses persetujuan kontrak secara otomatis terlihat seperti ini: kami mengekstrak sejumlah bidang dan ketentuan (klausul) tertentu dari dokumen. Bidang adalah satu atau lebih kata, dan klausa adalah satu atau lebih paragraf yang dapat berisi deskripsi panjang. Perusahaan perlu mengekstrak bidang untuk mengindeks dokumen di dalamnya, menyimpannya di penyimpanan elektronik, dan kemudian mencarinya. Pada klausa, Persetujuan terjadi - memeriksa apakah kondisinya benar. Istilah teknologi yang diekstraksi dibandingkan dengan persyaratan dalam perjanjian induk. Jika semuanya cocok, maka tidak ada risiko bagi perusahaan, Anda dapat secara otomatis menyetujui (meninjau) dan mengirim kontrak ke database. Ini membuat hidup lebih mudah bagi pengacara: alih-alih berurusan dengan jenis kontrak yang sama, mereka dapat beralih ke tugas yang lebih penting.Kontrak harus ditinjau hanya jika sistem mengungkapkan dalam dokumen adanya inkonsistensi dengan yang utama.

Apa yang menyatukan semua proyek NLP
Dalam faktur terstruktur, di mana kami mengenali jumlah dan alamat, segera jelas di mana bidang yang diperlukan berada, dan dokumen itu sendiri menempati satu atau beberapa halaman. Dalam hal dokumen tidak terstruktur, tidak selalu mungkin untuk dengan cepat menentukan data apa dan dari mana mengekstraknya - ini adalah fitur utama proyek NLP. Selain itu, dokumen itu sendiri tidak menempati satu halaman, tetapi 100-200 halaman. Oleh karena itu, pada tahap pengembangan persyaratan, pertama-tama kami meminta pelanggan untuk menyusun daftar beberapa lusin bidang yang perlu diambil. Proyek semacam itu memerlukan partisipasi ahli materi pelajaran - ahli di bidang ini, yang akan menjawab pertanyaan tentang apa dan dalam hal apa perlu diekstraksi dari dokumen dan nuansa apa yang harus diperhatikan.
Terkadang pelanggan meminta untuk mengekstrak beberapa ratus bidang dari dokumen sekaligus. Pendekatan ini tidak konstruktif dan mengarah pada fakta bahwa dibutuhkan lebih dari satu bulan untuk membahas persyaratan proyek. Itulah sebabnya, sebagai suatu peraturan, kami memulai bukan dengan ratusan bidang, tetapi dengan 10, memperjelas persyaratan, menunjukkan bagaimana semuanya akan bekerja. Hasilnya, kami dan pelanggan memahami tahap selanjutnya dari proyek dan pencapaiannya.
Selain itu, untuk pembelajaran mesin apa pun, proyek ML, termasuk NLP, diperlukan sampel yang representatif - sampel dokumen pelanggan tempat sistem akan dilatih. Lebih banyak lebih baik.
Kesimpulan
Dengan menggunakan contoh-contoh ini, kami telah menunjukkan bagaimana teknologi membantu menghemat sumber daya utama kami - waktu. Dalam bahasa Inggris, skema ini disebut win-win: robot melakukan tugas berulang, dan karyawan membebaskan tangan mereka untuk terlibat dalam proyek yang lebih cerdas dan menarik. Perusahaan di mana bukan spesialis, tetapi mesin terlibat dalam rutinitas, dapat membangun interaksi dengan pelanggan lebih efisien, menghindari kesalahan dalam pemrosesan dokumen tertentu dan meningkatkan profitabilitas lebih cepat.