
Dalam linguistik komputasi modern, pemahaman arti dari apa yang tertulis atau dikatakan dicapai dengan menggunakan model bahasa alami (NLU). Dengan pertumbuhan bertahap dari audiens asisten virtual Salyut, muncul pertanyaan untuk mengoptimalkan layanan kami yang bekerja dengan bahasa alami. Untuk melakukan ini, ternyata disarankan untuk menggunakan satu model NLU yang kuat untuk menyelesaikan beberapa masalah pengolah kata sekaligus. Pada artikel ini, kami akan menunjukkan kepada Anda bagaimana Anda dapat menggunakan pembelajaran multitasking untuk meningkatkan representasi vektor dan melatih model NLU yang lebih umum menggunakan SBERT.
Layanan pengolah kata yang dimuat tinggi menyelesaikan sejumlah tugas NLP yang berbeda:
- Mengenali niat.
- Menyoroti entitas bernama.
- Analisis sentimen.
- Analisis toksisitas.
- Telusuri kueri serupa.
Masing-masing tugas ini memiliki spesifikasinya sendiri dan, secara umum, membutuhkan konstruksi dan pelatihan model yang terpisah. Namun, tidak praktis untuk memelihara dan menjalankan model NLU terpisah untuk setiap tugas tersebut - waktu pemrosesan permintaan dan memori (video) yang dikonsumsi sangat meningkat. Sebagai gantinya, kami menggunakan satu model NLU yang kuat untuk mengekstrak fitur generik dari teks. Di atas fitur-fitur ini, kami menerapkan model (adaptor) yang relatif ringan, yang memecahkan masalah NLP yang diterapkan. Pada saat yang sama, NLU dan adaptor dapat dijalankan pada mesin yang berbeda, yang mempermudah penerapan dan penskalaan solusi.

Tetapi bagaimana membuat fitur yang diidentifikasi oleh model NLU dasar cukup universal sehingga model NLP berkualitas tinggi dapat dibangun di atasnya? Mari kita cari tahu.
Secara tradisi, kami menyajikan implementasi pendekatan kami di Python 3 dan TensorFlow 1.15. Panduan langkah demi langkah lengkap dan contoh kode dapat ditemukan di sini - Colab .
Kami juga menampilkan model Rusia terbaru yang tersedia untuk umum, SBERT-NLU class BERT-large [427 juta opsi.] Versi Multitask : memelukface [tensorflow, pytorch] .
Pembelajaran multi-tugas. Mengapa ini dibutuhkan?
Selama pengoperasian model NLU, kami menemukan bahwa fitur yang dialokasikan oleh model yang dilatih untuk satu tugas (misalnya, NLI ) dapat cukup berhasil digunakan kembali untuk tugas hilir lainnya (misalnya, untuk klasifikasi atau analisis sentimental). Untuk melakukan ini, model ringan (adaptor), diasah untuk memecahkan masalah baru, dilatih pada vektor yang dipilih oleh model dasar. Ini tidak mengubah model dasar.
Pada saat yang sama, kualitas model adaptor seperti itu biasanya masih lebih buruk daripada jika kami melatih model NLU kami untuk setiap tugas. Pasalnya, data baru hanya digunakan untuk model adaptor dan tidak memperbaiki model dasar. Pembelajaran multitask membantu kita untuk mengatasi hal ini.
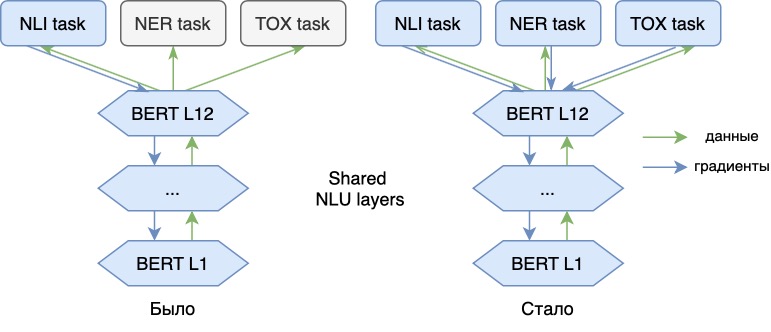
Sekarang kami melatih model bahasa tidak hanya pada masalah NLI utama, tetapi juga pada masalah tambahan (APM, analisis toksisitas). Menambahkan tugas baru memungkinkan kami untuk menambahkan "makna" baru ke vektor model kami, menjadikannya lebih universal. Dengan demikian, model akan dapat mencerminkan informasi vektornya, misalnya, tentang nuansa emosional ucapan suatu frasa atau tentang bagian ucapan setiap kata dalam teks. Dengan representasi vektor dari model seperti itu, masalah ini dapat diselesaikan dengan lebih efisien.
0. Eksperimen
Sebagai contoh, pertimbangkan untuk mengajar NLU pada tiga tugas:
- Representasi kalimat (NLI).
- Pengenalan entitas bernama (NER).
- Analisis sentimen.
Untuk mengajarkan tugas utama vektorisasi kalimat, kami, seperti terakhir kali , menggunakan dataset untuk Natural Language Inference , yang berisi pasangan kalimat dengan label yang menunjukkan konsekuensi ("entailment"), kontradiksi ("kontradiksi") atau ketiadaan hubungan semantik ("netral") antar kalimat. Untuk data ini, berdasarkan model BERT, kita akan mempelajari representasi vektor sedemikian rupa sehingga kesamaan antara pasangan kalimat yang sesuai akan lebih besar daripada kesamaan antara yang bertentangan atau netral satu sama lain.
Kami akan melatih kepala NER menggunakan datasetdari platform kaggle. Model ini akan menetapkan setiap token dalam proposal yang sedang diproses ke salah satu dari beberapa tipe entitas bernama IOB . Tugasnya adalah klasifikasi multi-kelas.
Untuk masalah analisis sentimen, mari kita ambil data dari kompetisi Ekstraksi Sentimen Tweet . Inti dari kontes ini adalah untuk memprediksi warna emosional dari komentar di postingan twitter. Ada tiga kelas dalam dataset - warna replika positif, netral dan negatif. Untuk contoh ini, kami hanya akan menyoroti dua kelas: positif dan negatif. Tugasnya adalah klasifikasi biner.
Kami menggunakan bahasa Inggris BERT-base yang telah dilatih sebelumnya sebagai model vektorisasi dasar.
Rencana percobaan:
- Menyiapkan kumpulan data.
- Implementasi pembangkit batch.
- Penentuan fungsi kerugian.
- Membangun modelnya.
- Persiapan proses validasi.
- Pelatihan model.
- Pembahasan hasil dan kesimpulan.
1. Persiapan data
Pertama, mari kita muat kumpulan data yang diperlukan untuk melatih model vektorisasi kalimat dasar - [ SNLI , MNLI ] dan untuk validasinya - [ STS SICK ]. Selain itu, kami membutuhkan model BERT bahasa Inggris yang telah dilatih sebelumnya. Untungnya, semua ini ada di domain publik:
Selanjutnya, mari kita pergi ke platform kaggle dan mengunduh data dari sana untuk analisis sentimental - di sini kita membutuhkan train.csv. Untuk data ini, mari kita pilih contoh negatif di kelas terpisah, dan gabungkan sisanya ke dalam grup umum (positif, netral):
Tetap mengambil data untuk NER dan menyiapkannya dalam format [text, ner_labels]:
2. Pembangkit batch
Sekarang mari kita tulis prosedur untuk menghasilkan paket contoh untuk melatih jaringan saraf. Karena kenyataan bahwa kami sekarang menerima bukan hanya satu, tetapi sudah tiga
set data sebagai input, kami juga membutuhkan lebih banyak generator: untuk tugas NLI, menggunakan generator triplet, kami akan menghasilkan tiga kali lipat
[jangkar, positif, negatif]:
untuk masalah klasifikasi NER dan Toxic menggunakan pasangan pembangkit data yang sama [sampel, label]. Di sini kami secara acak memilih beberapa contoh dengan label kelasnya dari kumpulan data yang disediakan dan membentuk sebuah paket:
Terakhir, mari gabungkan ketiga generator menjadi generator kompleks umum yang akan menggabungkan ketiga jenis paket data menjadi satu untuk melatih model:
3. Fungsi kerugian
Sekarang, untuk setiap tugas, kami mendefinisikan fungsi kesalahan kami sendiri, dan kemudian menggabungkannya untuk fungsi kerugian akhir:
- Kami juga akan merumuskan masalah "konvergensi" dari kalimat yang diparafrasekan sebagai masalah peringkat dan menggunakan Softmax Loss yang sedikit dimodifikasi, yang sudah diketahui dari pekerjaan sebelumnya, sebagai fungsi kesalahan :
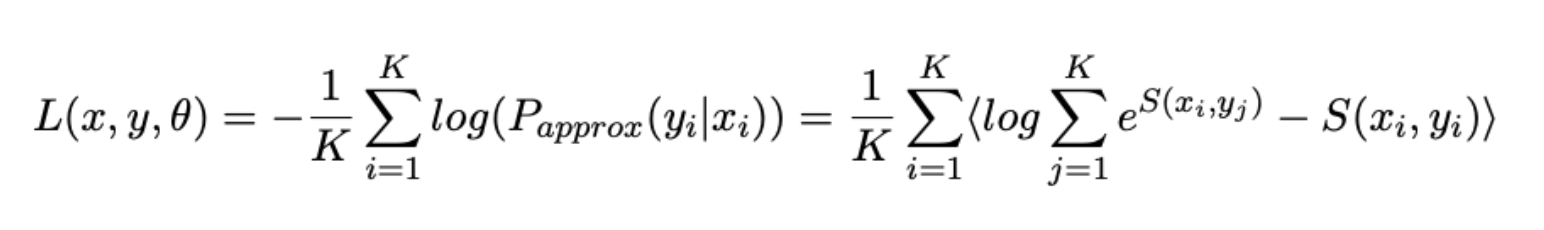
- Binary Cross Entropy Loss:

- NER- -, CrossEnrtopyLoss:

- Joint-loss, :
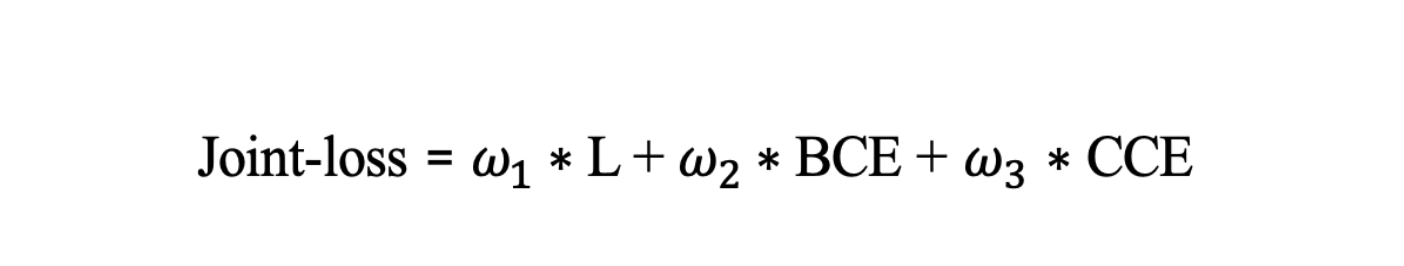
4.
Model kami terdiri dari bagian NLU utama (di sini kami menggunakan basis BERT) dan tiga "kepala" -adaptor, khusus untuk setiap tugas.
Untuk tugas NLI dan Toxic, kami akan mengambil rata-rata penyematan token dari lapisan BERT terakhir (kami menggunakan penyatuan rata-rata bertopeng). Untuk tugas NER, kami akan menggunakan penyematan token dari output lapisan encoder ke-8. Saat mengajarkan representasi tingkat kalimat, embeddings untuk masalah tingkat token paling baik diambil dari lapisan menengah model.
Tampilannya seperti ini: Kode

arsitektur model
multitugas untuk merakit model:
5. Validasi hasil
Untuk memvalidasi model vektorisasi kalimat, kami menggunakan set data STS 2012–2016 dan SICK 2014 .
Seperti SNLI, dataset ini berisi pasangan kalimat. Mari kita vektorkan mereka dengan model menggunakan model dan memperkirakan kesamaan antara kalimat dengan menghitung kedekatan kosinus antara vektor mereka. Sebagai metrik, kami akan menghitung korelasi peringkat dengan label dari kumpulan data.
Kode panggilan balik yang berisi logika ini:
https://Gist.githubusercontent.com/gaphex/f2d2e1a9c849ba9d69a3014da705968f/raw/8ac26c3b236979625a906591dd594b9fd8640483/pearsonr_callback.py .
Tugas menentukan toksisitas komentar akan diuji terhadap metrik AUC. Partisi data bertingkat sehubungan dengan distribusi kelas.
https://Gist.github.com/Ab1992ao/873227b0834ebe43c95b4b5fe029eb95 .
Kualitas markup APM akan dinilai dengan dua metrik - akurasi dan ukuran F1.
https://Gist.github.com/Ab1992ao/e3ea080d36d2bf2d0c1ddc17aa4b9e99 .
6. Proses belajar
Kami berada di peregangan rumah. Sekarang kita memiliki: data, model, dan jalur validasi. Mari beralih ke hyperparameter dan sumber belajar.
Menurut klasik, kami memiliki Colab dengan akselerator video NVIDIA K80 (12GB) / T80 (16GB) yang kami miliki - tergantung pada aktivitas Anda di lingkungan ini. Agar seluruh karya seni multitugas kami dapat masuk ke dalam memori, penting untuk memilih panjang maksimum yang tepat dari urutan yang diproses (seq_len) dan, tentu saja, ukuran batch.
Dalam percobaan ini, kami akan kembali membatasi diri pada 24 token untuk tugas kalimat, yang akan cukup untuk mengkodekan sebagian besar data yang digunakan dalam pelatihan. Untuk sentimen dan ner-tugas, gunakan panjang urutan yang sama.
Peningkatan ukuran batch memiliki efek yang sangat positif pada konvergensi model - kami akan memilih yang maksimum yang sesuai dengan memori GPU kami.
Sebagai pengoptimal, kami akan menggunakan Adam tua yang baik dengan tingkat pembelajaran yang kecil . Kami akan melatih model sebelum konvergensi, 25 epoch sudah cukup.
Parameter pelatihan:
- ukuran batch = 96/72 untuk basis BERT (masing-masing 16 GB memori atau 12 GB);
- max_seq_len = 24;
- Pengoptimal Adam;
- Tingkat pembelajaran ~ 2e-6;
- Metrik - [SpearmanR, F1, AUC];
- Jumlah epoch ~ 25.
Mari kita bandingkan metrik adaptor yang dilatih di atas model SBERT versi lama dan baru.

Seperti yang Anda lihat, karena pelatihan tambahan multitasking, kami berhasil meningkatkan kualitas tugas tambahan NER dan TOX secara signifikan. Penting agar ini tidak merusak fungsi utama model - metrik pada set data STS dan SICK tetap pada level yang sama.
7. Peluang untuk perbaikan lebih lanjut
Augmentasi
Sebagai bagian dari pekerjaan kami, kami menggunakan manipulasi tambahan yang membantu untuk mendapatkan model yang lebih akurat dan stabil.
Selama pembuatan batch, kami menerapkan sejumlah augmentasi, di antaranya dapat dibedakan sebagai berikut: pada level huruf, pada level kata, perubahan huruf besar dan penghapusan tanda baca.
Pada tataran huruf, yaitu:
1) penghapusan "prvet";
2) ulangi "salam";
3) menukar dua simbol yang berdekatan "Prievt";
4) penggantian tombol tutup pada keyboard "selamat datang";
5) penggantian dengan huruf yang menutup secara fonetis "halo".
Pada tataran kata, yaitu:
1) menukar dua kata atau lebih;
2) penyisipan kata-kata parasit - "yah, ini sama saja."
Untuk membuat model lebih tahan terhadap perubahan huruf besar dan tanda baca, tanda baca dapat dihilangkan dalam beberapa contoh. Untuk token acak, register dapat diubah.
Augmentasi terkait dengan perubahan kata dan simbol diterapkan untuk 3% dari kumpulan, dan dengan tanda baca dan kapitalisasi - untuk 30%.
8. Hasil dan kesimpulan
Pada artikel ini, kami berkenalan dengan konsep Multitask Leaning dan menerapkan pengetahuan ini untuk meningkatkan representasi vektor dari model bahasa.
Dengan menggunakan metode ini, kami meningkatkan model NLU untuk bahasa Rusia SBERT-multitask dan menerbitkannya . Kami telah melatih lebih lanjut versi model ini untuk memecahkan masalah NER, analisis sentimen, dan analisis toksisitas.
Kami mengukur metrik untuk kedua versi model SBERT pada tolok ukur model bahasa Rusia RussianGLUE . Meskipun tugas RuGLUE tidak berpartisipasi dalam proses pelatihan ulang multitasking, metrik versi kedua model sedikit meningkat. Mengajarkan model untuk satu masalah memperluas cakrawala dan meningkatkan kualitas pada yang lain.

Kami berencana untuk lebih mengembangkan model bahasa alami SBERT. Di antara arah dapat dibedakan: akselerasi dan distilasi , peningkatan arsitektur dasar dan penambahan tugas baru. Kami akan membicarakannya di artikel berikut. Jika Anda tertarik dengan teknologi NLP dan ingin menerapkannya dalam produk baru untuk khalayak luas - datanglah kepada kami untuk wawancara .
Kami berharap yang terbaik dalam penelitian Anda!
Terima kasih atas bantuan Anda dalam mempersiapkan bahan untuk artikel ini. Andriljo dan Ibrahim_bad...