
Matematika sering disebut sebagai "bahasa sains". Ini sangat cocok untuk pemrosesan kuantitatif dari hampir semua informasi ilmiah, apa pun isinya. Dan dengan bantuan formalisme matematika, para ilmuwan dari berbagai bidang dapat, sampai batas tertentu, "memahami" satu sama lain. Saat ini, situasi serupa muncul dengan Ilmu Komputer. Tetapi jika matematika adalah bahasa sains, maka CS adalah pisau Swiss-nya. Memang, sulit membayangkan penelitian modern tanpa menganalisis dan memproses data dalam jumlah besar, kalkulasi kompleks, pemodelan komputer, visualisasi, dan penggunaan perangkat lunak dan algoritme khusus. Mari kita lihat beberapa "cerita" menarik ketika berbagai disiplin ilmu menggunakan metode Ilmu Komputer untuk memecahkan masalah mereka.
Bioinformatika: dari cawan Petri hingga biologi In silico
Bioinformatika bisa disebut sebagai salah satu contoh paling mencolok dari perpotongan Ilmu Komputer dan disiplin ilmu lainnya. Ilmu ini berkaitan dengan analisis data biologi molekuler dengan menggunakan metode komputer. Bioinformatika sebagai arah ilmiah terpisah muncul di awal 70-an abad lalu, ketika urutan nukleotida RNA kecil pertama kali diterbitkan dan algoritme untuk memprediksi struktur sekundernya (pengaturan spasial atom dalam molekul) dibuat.
Era baru bioinformatika telah dimulai dengan Proyek Genom Manusia, yang bertujuan untuk menentukan urutan nukleotida dalam DNA manusia dan mengidentifikasi gen dalam genom. Biaya sekuensing DNA (sekuensing nukleotida) telah turun beberapa kali lipat. Hal ini menyebabkan peningkatan yang luar biasa dalam jumlah urutan dalam database publik. Grafik di bawah ini menunjukkan pertumbuhan jumlah urutan dalam database publik GenBank dari Desember 1982 hingga Februari 2017 dalam skala semi-log. Agar data yang terakumulasi menjadi berguna, mereka perlu dianalisis dengan beberapa cara.

Pertumbuhan jumlah urutan di GenBank dari Desember 1982 hingga Februari 2017. Sumber: www.ncbi.nlm.nih.gov/genbank/statistics
Salah satu metode analisis sekuens dalam bioinformatika adalah penyelarasan sekuens. Inti dari metode ini terletak pada kenyataan bahwa urutan monomer DNA, RNA atau protein ditempatkan di bawah satu sama lain sedemikian rupa untuk melihat area yang serupa. Kesamaan dalam struktur primer (yaitu urutan) dua molekul dapat mencerminkan hubungan fungsional, struktural, atau evolusionernya. Karena urutan dapat direpresentasikan sebagai string dengan alfabet tertentu (4 nukleotida untuk DNA dan 20 asam amino untuk protein), penyelarasan ternyata menjadi tugas kombinatorial dari CS (misalnya, penyelarasan garis juga digunakan dalam pemrosesan bahasa alami - NLP). Namun, konteks biologi menambahkan beberapa kekhususan pada masalah tersebut.
Mari kita lihat penyelarasan menggunakan protein sebagai contoh. Satu residu asam amino dalam protein sesuai dengan satu huruf dalam alfabet Latin dalam urutan tersebut. String ditulis satu di bawah yang lain untuk mendapatkan kecocokan terbaik. Elemen yang cocok adalah satu di bawah yang lain, "celah" diganti dengan "-" (celah). Mereka menunjuk indel , yaitu, tempat kemungkinan penyisipan (pengenalan ke dalam molekul dari satu atau lebih nukleotida atau asam amino) dan penghapusan ("pelepasan" dari nukleotida atau asam amino).

Contoh penyelarasan urutan asam amino dua protein. Leusin (L) dan isoleusin (I), yang merupakan isomer, disorot dengan warna biru - substitusi seperti itu dalam banyak kasus tidak memengaruhi struktur protein
Namun, bagaimana Anda bisa menentukan apakah penjajarannya optimal? Hal pertama yang terlintas dalam pikiran adalah memperkirakan jumlah pertandingan: semakin banyak kecocokan, semakin baik. Namun, dalam konteks biologi, hal tersebut tidak sepenuhnya benar. Substitusi (substitusi satu asam amino dengan yang lain) tidak sama: beberapa substitusi (misalnya, S dan T, D dan E adalah residu yang strukturnya berbeda persis oleh satu atom karbon) secara praktis tidak mempengaruhi struktur protein. Tetapi mengganti serin dengan triptofan akan sangat mengubah struktur molekul. Kriteria kuantitatif (bobot atau skor) dimasukkan untuk menentukan apakah kliring adalah yang terbaik. Untuk menilai substitusi, digunakan yang disebut matriks substitusi, berdasarkan statistik substitusi asam amino dalam protein dengan struktur yang diketahui. Semakin tinggi angka di persimpangan huruf yang cocok, semakin tinggi skornya.

Matriks substitusi baru muncul secara berkala. Berikut adalah matriks BLOSUM62.
Skor tersebut juga memperhitungkan adanya penghapusan. Biasanya, hukuman untuk "membuka" penghapusan beberapa kali lipat lebih besar daripada untuk "melanjutkan". Hal ini disebabkan oleh fakta bahwa bagian dari beberapa celah yang berurutan dianggap sebagai satu mutasi, dan beberapa celah di tempat yang berbeda dianggap beberapa. Dalam contoh di bawah ini, pasangan urutan pertama lebih mirip daripada yang kedua, karena dalam kasus pertama, urutan tersebut secara formal dipisahkan oleh satu peristiwa evolusi:

Sekarang tentang algoritma penyelarasan itu sendiri. Ada dua jenis perataan berpasangan (menemukan area serupa dari dua urutan): global dan lokal. Penjajaran global menyiratkan bahwa urutan homolog (serupa) di sepanjang panjangnya. Ini mencakup kedua urutan secara keseluruhan. Namun, dengan pendekatan ini, area serupa tidak selalu terdefinisi dengan baik jika jumlahnya sedikit. Penjajaran lokal digunakan jika urutan disimpan sebagai homolog (misalnya, karena rekombinasi) dan situs yang tidak terkait. Tapi tidak selalu bisa masuk ke area yang diminati, apalagi ada kemungkinan bertemu area serupa yang tidak disengaja. Untuk mendapatkan keselarasan berpasangan, metode pemrograman dinamis digunakan (memecahkan masalah dengan membaginya menjadi beberapa subtugas identik yang dihubungkan secara berulang). Dalam program untuk penyelarasan global, algoritma Needleman-Wunsch sering digunakan , dan untuk penyelarasan lokal, algoritma Smith-Waterman . Anda dapat membaca lebih lanjut tentang mereka dengan mengikuti tautan.
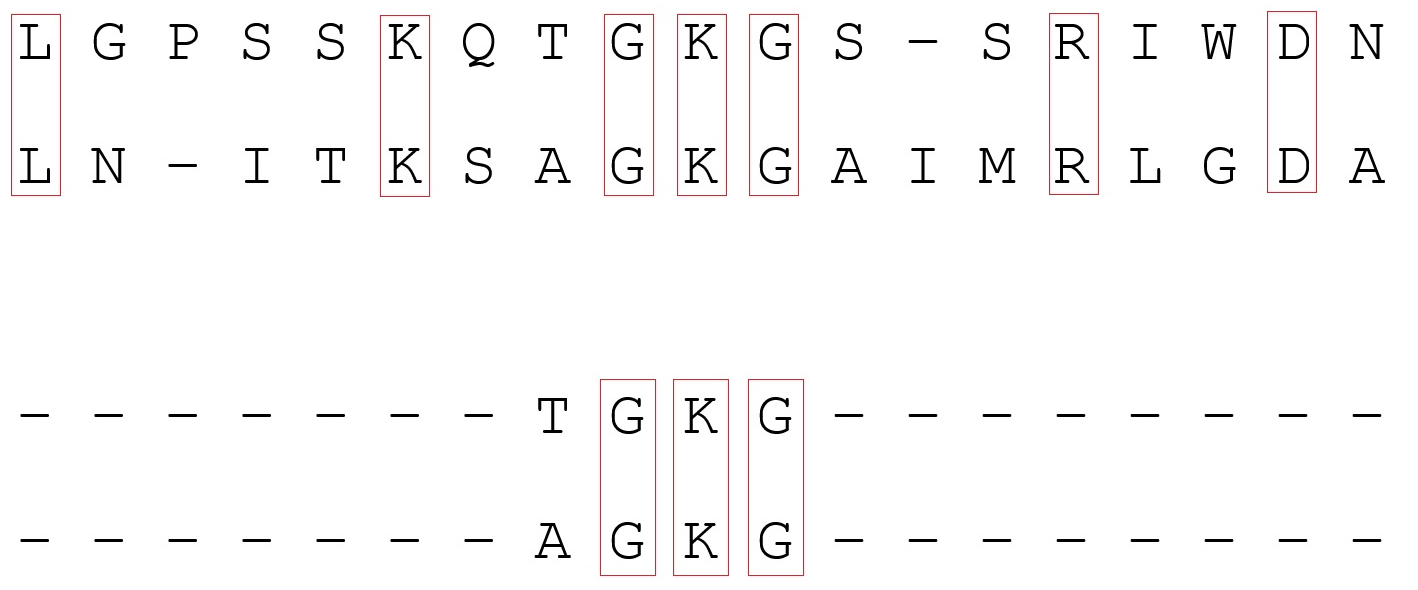
Contoh perataan: atas global, bawah lokal. Dalam kasus pertama, penyelarasan terjadi di sepanjang sekuens; dalam kasus kedua, beberapa daerah homolog ditemukan.
Seperti yang Anda lihat, tugas biologis dapat direduksi menjadi tugas dari CS. Penyelarasan berpasangan menggunakan algoritme yang disebutkan membutuhkan sekitar m * n memori tambahan (m, n adalah panjang urutan), yang dapat ditangani dengan mudah oleh komputer rumah modern. Namun, bioinformatika juga memiliki lebih banyak tugas non-sepele, misalnya, beberapa penyelarasan (penyelarasan beberapa urutan) untuk rekonstruksi pohon filogenetik.... Bahkan jika kita membandingkan 10 protein yang sangat kecil dengan panjang urutan sekitar 100 karakter, maka memori tambahan yang sangat besar akan dibutuhkan (dimensi array adalah 100 ^ 10). Oleh karena itu, dalam hal ini, penyelarasan didasarkan pada berbagai heuristik.
Pemodelan struktur skala besar alam semesta
Tidak seperti biologi, fisika telah berdampingan dengan Ilmu Komputer sejak masa awal komputer. Sebelum komputer pertama diciptakan, kata "komputer" (kalkulator) disebut posisi khusus - ini adalah orang-orang yang melakukan perhitungan matematis pada kalkulator. Jadi, selama Proyek Manhattan, fisikawan Richard Feynman adalah manajer dari seluruh tim "kalkulator" yang memproses persamaan diferensial pada mesin penjumlahan.

"Ruang komputasi" dari Pusat Riset Penerbangan. Armstrong. USA, 1949
Saat ini, metode CS banyak digunakan dalam berbagai bidang fisika. Misalnya, fisika komputasi mempelajari algoritme numerik untuk memecahkan masalah fisik yang telah dikembangkan teori kuantitatifnya. Dalam situasi di mana pengamatan langsung terhadap objek sulit (ini sering terjadi dalam astronomi), pemodelan komputer membantu para ilmuwan. Kasus yang persis seperti itu adalah studi tentang struktur skala besar Alam Semesta : pengamatan objek yang jauh sulit dilakukan karena penyerapan radiasi elektromagnetik di bidang Bima Sakti, sehingga pemodelan telah menjadi metode penelitian utama.

,
Salah satu tugas kosmologi modern adalah menjelaskan gambaran yang diamati tentang keanekaragaman galaksi dan evolusinya. Pada tataran kualitatif, proses fisik yang terjadi di galaksi sekarang sudah diketahui, oleh karena itu upaya para ilmuwan ditujukan untuk memperoleh prediksi kuantitatif. Ini akan memungkinkan menjawab sejumlah pertanyaan mendasar, misalnya, tentang sifat materi gelap. Tetapi, sebelum mengisolasi manifestasi materi gelap yang diamati, perlu dipahami perilaku materi biasa. Dalam skala besar (beberapa juta tahun cahaya), materi biasa secara efektif berperilaku seperti gelap: ia tunduk pada satu gaya gravitasi, Anda bisa melupakan tekanan gas. Ini membuatnya relatif mudah untuk mensimulasikan evolusi struktur skala besar Semesta (Metode numerik,hanya mengandung materi gelap atau seperti debu dan mereproduksi dengan baik struktur distribusi galaksi skala besar, mulai berkembang sejak 1980-an).
Materi gelap dimodelkan sebagai berikut. Kubus maya, berukuran ratusan juta tahun cahaya, hampir seragam diisi dengan partikel - benda uji. Sejak awal, ketidakhomogenan kecil hadir di alam semesta, dari mana seluruh struktur yang diamati muncul, oleh karena itu, pengisiannya "hampir seragam". Kemudian partikel-partikel itu mulai "menjalani hidup mereka sendiri" di bawah pengaruh gravitasi: masalah N benda terpecahkan . Partikel-partikel yang lolos dari kubus dipindahkan ke permukaan yang berlawanan, dan gaya gravitasi juga merambat dengan transfer tersebut. Berkat ini, kubus menjadi, seolah-olah, tak terbatas, seperti alam semesta.

Perkiraan lintasan tiga benda identik yang terletak di simpul segitiga tidak sama kaki dan memiliki kecepatan awal nol.
Salah satu model numerik paling terkenal dari jenis ini adalah Milenium , yang memiliki ukuran kubus lebih dari 1,5 miliar tahun cahaya dan sekitar 10 miliar partikel. Pada tahun-tahun berikutnya, beberapa model yang lebih besar dibuat: Horizon Run dengan sisi kubus 4 kali lebih besar dari Millenium, dan Dark Sky dengan 16 kali Millenium. Model ini dan model serupa telah memainkan peran kunci dalam proyek untuk memvalidasi model Lambda-CDM yang sekarang diterima secara umum. (Alam semesta yang mengandung sekitar 70% energi gelap, 25% materi gelap, dan 5% materi biasa).

Millenium: , ; — . .
Penurunan skala menyebabkan masalah dalam mencocokkan observasi dan model numerik dengan satu materi gelap. Dalam skala yang lebih kecil (skala penyebaran gelombang kejut dari supernova), materi tidak lagi dapat dianggap berdebu. Penting untuk memperhitungkan hidrodinamika, pendinginan dan pemanasan gas oleh radiasi, dan banyak lagi. Untuk memperhitungkan semua hukum fisika dalam pemodelan, beberapa penyederhanaan dilakukan: misalnya, Anda dapat memecah kubus model menjadi kisi-kisi sel (fisika subkisi), dan mengasumsikan bahwa ketika kepadatan dan suhu tertentu dalam sel tercapai , sebagian gas akan langsung berubah menjadi bintang. Kelas model ini mencakup proyek EAGLE dan ilustris . Salah satu hasil dari proyek ini adalah reproduksi hubungan Tully-Fisher antara luminositas galaksi dan kecepatan rotasi piringan.
Linguistik dan pembelajaran mesin: selangkah lebih dekat untuk memecahkan misteri berusia 4.000 tahun
Metode CS menemukan aplikasi di area yang lebih tidak terduga, misalnya, dalam studi bahasa kuno dan sistem penulisan. Jadi, sebuah studi oleh sekelompok ilmuwan yang dipimpin oleh Rajesh P.N. Rao, seorang profesor di Universitas Washington, menjelaskan misteri tulisan Lembah Indus.
Aksara Indus, digunakan antara 2600-1900 SM di tempat yang sekarang menjadi Pakistan Timur dan barat laut India, milik peradaban yang tidak kalah rumit dan misteriusnya dari bangsa Mesopotamia dan Mesir pada zamannya. Hanya ada sedikit sumber tertulis yang tersisa darinya: para arkeolog hanya menemukan sekitar 1.500 prasasti unik pada pecahan keramik, tablet, dan segel. Huruf terpanjang hanya 27 karakter.

Prasasti pada segel dari Lembah Indus
Dalam komunitas ilmiah, ada berbagai hipotesis tentang "simbol misterius". Beberapa ahli menganggap simbol tidak lebih dari sekedar "gambar cantik". Jadi pada tahun 2004, ahli bahasa Steve Farmer menerbitkan sebuah artikel yang menyatakan bahwa tulisan Indus tidak lebih dari simbol politik dan agama. Versinya, meski kontroversial, masih menemukan pendukungnya.
Rajesha P.N. Rao, seorang ilmuwan pembelajaran mesin, membaca tentang tulisan Indus di sekolah menengah. Sekelompok ilmuwan di bawah kepemimpinannya memutuskan untuk melakukan analisis statistik terhadap dokumen terpercaya yang ada. Dalam proses penelitian menggunakan rantai Markov(salah satu disiplin ilmu pertama di mana rantai Markov menemukan penerapan praktis adalah kritik tekstual) entropi bersyarat dibandingkan simbol dari aksara Indus dengan entropi rangkaian tanda linguistik dan non-linguistik. Entropi bersyarat adalah entropi untuk alfabet yang probabilitas satu huruf demi huruf diketahui. Beberapa sistem dipilih untuk perbandingan. Sistem linguistik meliputi: penulisan logografi Sumeria, Abugida Tamil Kuno, Sanskrit dari Rig Veda, Bahasa Inggris modern (kata dan huruf dipelajari secara terpisah) dan bahasa pemrograman Fortran. Sistem non-linguistik dibagi menjadi dua kelompok. Yang pertama mencakup sistem dengan urutan tanda yang kaku (rangkaian tanda buatan No. 1), yang kedua - sistem dengan urutan yang fleksibel (protein bakteri, DNA manusia, rangkaian tanda buatan No. 2). Alhasil, ternyata tulisan proto-India ternyata cukup tertata, seperti tulisan bahasa lisan:entropi dokumen yang ada mirip dengan entropi skrip Sumeria dan Tamil.

Entropi bersyarat untuk berbagai sistem linguistik dan non-linguistik
Hasil ini membantah hipotesis tentang penggunaan ornamen tanda. Dan meskipun metode CS membantu mengonfirmasi versi bahwa simbol dari Lembah Indus kemungkinan besar adalah sistem penulisan, masalahnya belum sampai pada dekripsi.
Kesimpulan
Tentu saja, banyak area di mana metode CS menemukan aplikasi yang berlebihan. Tidak mungkin dalam satu artikel untuk mengungkapkan bagaimana sains modern bergantung pada teknologi komputer. Namun, saya berharap contoh yang diberikan menunjukkan bagaimana berbagai masalah dapat diselesaikan, termasuk dengan metode CS.
Server cloud dari Macleod cepat dan aman.
Daftar menggunakan tautan di atas atau dengan mengklik spanduk dan dapatkan diskon 10% untuk bulan pertama menyewa server dengan konfigurasi apa pun!
