Halo semuanya! Saya bekerja dengan model generatif, salah satu proyek saya adalah pengembangan DeepFake. Saya berencana membuat beberapa artikel tentang proyek ini. Artikel ini adalah yang pertama, di mana saya akan mempertimbangkan arsitektur yang dapat digunakan, kelebihan dan kekurangannya. Dari pendekatan yang ada untuk membuat DeepFake, berikut ini dapat dibedakan:
Arsitektur berbasis codec
Jaringan adversarial generatif (GAN)
Arsitektur encoder-decoder
Pendekatan ini mencakup metode pembuatan berdasarkan autoencoder. Mereka disatukan oleh penggunaan kerugian piksel (gambar masukan dibandingkan piksel demi piksel dengan gambar keluaran, MSE, MAE, dll. Fungsi kerugian dioptimalkan) kerugian, yang menentukan keuntungan dan kerugian skema ini. Keuntungannya adalah autoencoder relatif mudah (dibandingkan dengan GAN) untuk dilatih. Sisi negatifnya adalah bahwa pengoptimalan dengan metrik piksel tidak memungkinkan pencapaian fotorealisme yang sebanding dengan metode lain (sekali lagi, dalam perbandingan GAN). Opsi pertama yang saya anggap adalah rangkaian decoder ganda. Lebih jelasnya dapat ditemukan di sini. Arsitekturnya ditunjukkan pada gambar di bawah ini.
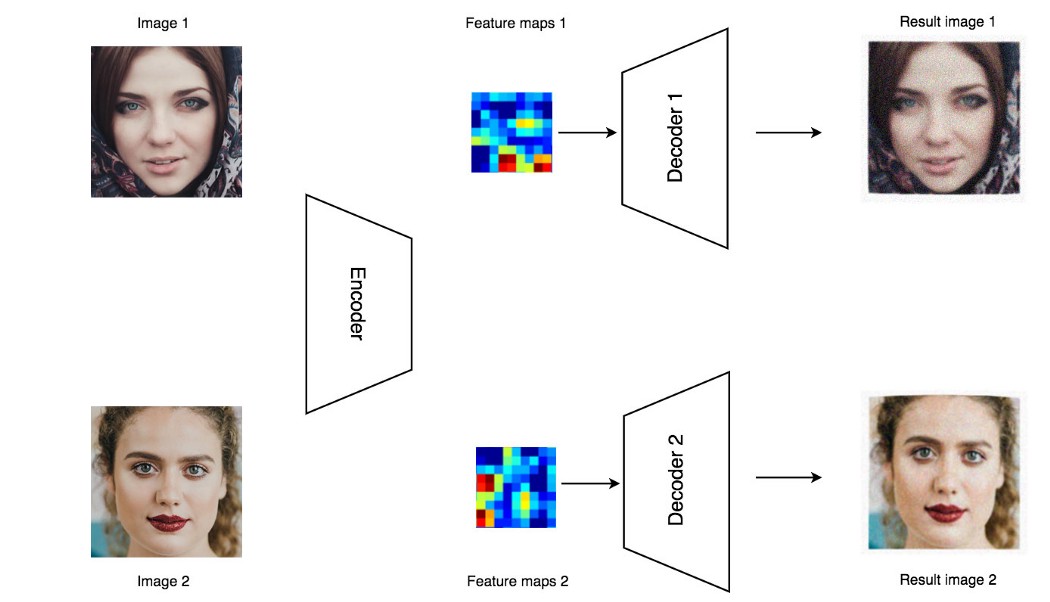
: - , , , . , . , . , DeepFake , , .. , . - , ( ) . " - " , .
Condtional Autoencoder
. .

: . latent_dim . , / ( ), , .. .. , . .. , atrributes vectors , , , , .. atrributes vectors , , , . , , .. atrributes vectors . .

, - , - . - "", . , .. .
Conditional GAN
GAN , . .. DeepFake ( - , ), Conditional GAN. GAN Conditional GAN . , .

GAN, . , .. , , . Conditional Gan - Z ( label). . , . Conditional GAN .

( - , - ). attributes vectors , . X GAN . , , GAN . , - DeepFake, , . . DeepFake GAN :
Perkembangan proyek terus berlanjut hingga saat ini. Banyak perbaikan yang direncanakan, pertama-tama - meningkatkan resolusi, mengerjakan pemandangan dengan pencahayaan yang kompleks. Jika tertarik, begitu hasil baru muncul, akan ada publikasi baru.