
Sebuah fitur hebat baru - baru ini ditambahkan ke jalur utama compiler Clang . Dengan menggunakan atribut
[[clang::musttail]]
or ,
__attribute__((musttail))
Anda sekarang bisa mendapatkan panggilan tail terjamin di C, C ++, dan Objective-C.
int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
( Kompiler online )
Biasanya panggilan ini dikaitkan dengan pemrograman fungsional, tetapi saya hanya tertarik pada mereka dari sudut pandang kinerja. Dalam beberapa kasus, dengan bantuan mereka, Anda bisa mendapatkan kode yang lebih baik dari compiler - setidaknya dengan teknologi kompilasi yang tersedia - tanpa menggunakan assembler.
Penggunaan pendekatan ini dalam mengurai protokol serialisasi memberikan hasil yang luar biasa: kami dapat mengurai dengan kecepatan lebih dari 2 Gb / dtk. , lebih dari dua kali lebih cepat dari solusi terbaik sebelumnya. Speedup ini akan berguna dalam banyak situasi, jadi tidak benar jika membatasi dirinya hanya pada pernyataan "tail calls == double speedup". Namun, tantangan ini adalah elemen kunci yang memungkinkan peningkatan kecepatan tersebut.
Saya akan memberi tahu Anda apa keuntungan dari panggilan ekor, bagaimana kita mengurai protokol yang menggunakannya, dan bagaimana kita dapat memperluas teknik ini ke penerjemah. Saya pikir berkat itu, interpreter dari semua bahasa utama yang ditulis dalam C (Python, Ruby, PHP, Lua, dll.) Dapat memperoleh peningkatan kinerja yang signifikan. Kelemahan utama terkait dengan portabilitas: sekarang ini
musttail
adalah ekstensi compiler non-standar. Meskipun saya berharap ini akan berhasil, perlu beberapa saat sebelum ekstensi menyebar cukup luas agar kompiler C di sistem Anda mendukungnya. Saat membangun, Anda dapat mengorbankan efisiensi dengan imbalan portabilitas jika ternyata
musttail
tidak tersedia.
Dasar-dasar Tail Call
Tail call adalah panggilan ke fungsi apa pun di posisi ekor, tindakan terakhir sebelum fungsi tersebut mengembalikan hasil. Saat mengoptimalkan panggilan tail, compiler mengkompilasi instruksi untuk panggilan tail
jmp
, bukan
call
. Ini tidak melakukan tindakan overhead yang biasanya memungkinkan callee untuk
g()
kembali ke pemanggil
f()
, seperti membuat stack frame baru atau meneruskan alamat pengirim. Sebaliknya, ini
f()
merujuk langsung
g()
seolah-olah itu adalah bagian dari dirinya sendiri, dan
g()
mengembalikan hasilnya langsung ke pemanggil
f()
. Optimasi ini aman karena stack frame
f()
tidak lagi diperlukan setelah dimulainya panggilan tail, karena variabel lokal tidak dapat diakses
f()
.
Meski terlihat sepele, pengoptimalan ini memiliki dua fitur penting yang membuka kemungkinan baru untuk penulisan algoritme. Pertama, dengan menjalankan n panggilan ekor berurutan, tumpukan memori dikurangi dari O (n) menjadi O (1). Ini penting karena tumpukan terbatas dan luapan dapat merusak program. Jadi, tanpa pengoptimalan ini, beberapa algoritme berbahaya. Kedua, ini
jmp
menghilangkan overhead
call
dan sebagai hasilnya pemanggilan fungsi menjadi seefisien cabang lainnya. Kedua fitur ini memungkinkan panggilan ekor untuk digunakan sebagai alternatif yang efisien untuk struktur kontrol berulang konvensional seperti
for
dan
while
.
Ide ini sama sekali tidak baru dan berasal dari tahun 1977, ketika Guy Steele menulis seluruh makalah di mana dia berpendapat bahwa panggilan prosedur lebih bersih daripada arsitektur
GOTO
, sementara mengoptimalkan panggilan ekor tidak kehilangan kecepatan. Itu adalah salah satu "Karya Lambda" yang ditulis antara tahun 1975 dan 1980, yang merumuskan banyak ide di balik Lisp dan Skema.
Pengoptimalan panggilan ekor bukanlah hal baru, bahkan untuk Clang. Dia dapat mengoptimalkannya sebelumnya, seperti GCC dan banyak kompiler lainnya. Faktanya, atribut
musttail
dalam contoh ini tidak mengubah output compiler sama sekali: Clang telah mengoptimalkan panggilan tail untuk
-O2
.
Baru di sini adalah jaminan . Meskipun compiler sering berhasil dalam mengoptimalkan tail call, ini adalah hal yang "terbaik" dan Anda tidak dapat mengandalkannya. Secara khusus, pengoptimalan pasti tidak akan berfungsi dalam build yang tidak dioptimalkan: compiler online . Dalam contoh ini, panggilan ekor dikompilasi menjadi
call
, jadi kita kembali ke tumpukan ukuran O (n). Inilah mengapa kita membutuhkan
musttail
: Hingga kami memiliki jaminan dari compiler bahwa panggilan tail kami akan selalu dioptimalkan di semua mode assembly, tidak aman untuk menulis algoritme dengan panggilan seperti itu untuk iterasi. Dan tetap berpegang pada kode yang hanya berfungsi dengan pengoptimalan diaktifkan adalah kendala yang cukup sulit.
Masalah dengan loop interpreter
Kompiler adalah teknologi yang luar biasa, tetapi tidak sempurna. Mike Pall, penulis LuaJIT, memutuskan untuk menulis penerjemah LuaJIT 2.x dalam bahasa assembly, bukan C, dan dia menyebut ini faktor utama yang membuat penerjemah begitu cepat . Paul kemudian menjelaskan secara lebih rinci mengapa kompiler C kesulitan menemukan loop interpreter utama . Dua poin utama:
- , .
- , .
Pengamatan ini mencerminkan dengan baik pengalaman kami dalam mengoptimalkan penguraian protokol serialisasi. Dan panggilan ekor akan membantu kita menyelesaikan kedua masalah tersebut.
Anda mungkin merasa aneh untuk membandingkan loop interpreter dengan parser protokol serialisasi. Namun, kemiripan tak terduga mereka ditentukan oleh sifat dari format kabel protokol: ini adalah sekumpulan pasangan nilai kunci di mana kunci berisi nomor bidang dan tipenya. Kuncinya berfungsi seperti opcode di interpreter: ia memberi tahu kita operasi apa yang perlu dilakukan untuk mengurai bidang ini. Nomor bidang dalam protokol dapat berurutan apa pun, jadi Anda harus siap untuk melompat ke bagian mana pun dari kode kapan saja.
Adalah logis untuk menulis pengurai seperti itu menggunakan perulangan
while
dengan ekspresi bertingkat
switch
... Ini telah menjadi pendekatan terbaik untuk mem-parsing protokol serialisasi selama masa pakai protokol. Misalnya, berikut adalah kode parsing dari versi C ++ saat ini . Jika kami mewakili aliran kontrol secara grafis, kami mendapatkan skema berikut:
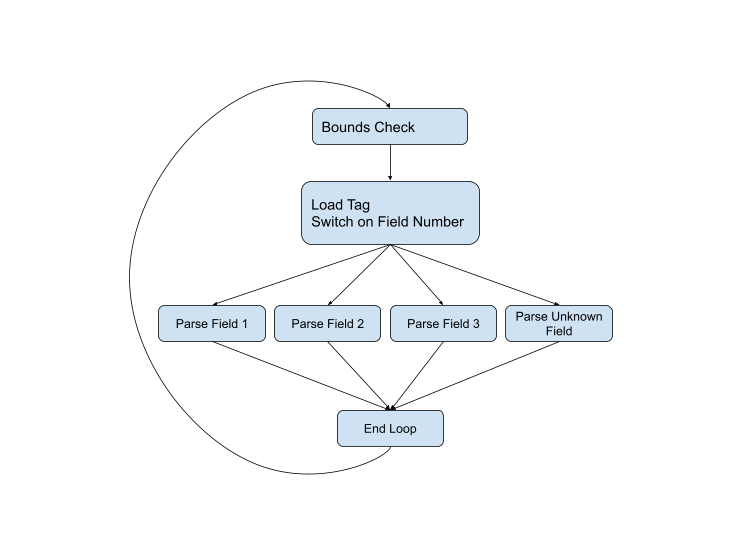
Tetapi diagram tersebut tidak lengkap, karena masalah dapat muncul di hampir setiap tahap. Jenis bidang mungkin salah, atau datanya mungkin rusak, atau kita mungkin melompat ke akhir buffer saat ini. Diagram lengkapnya terlihat seperti ini:
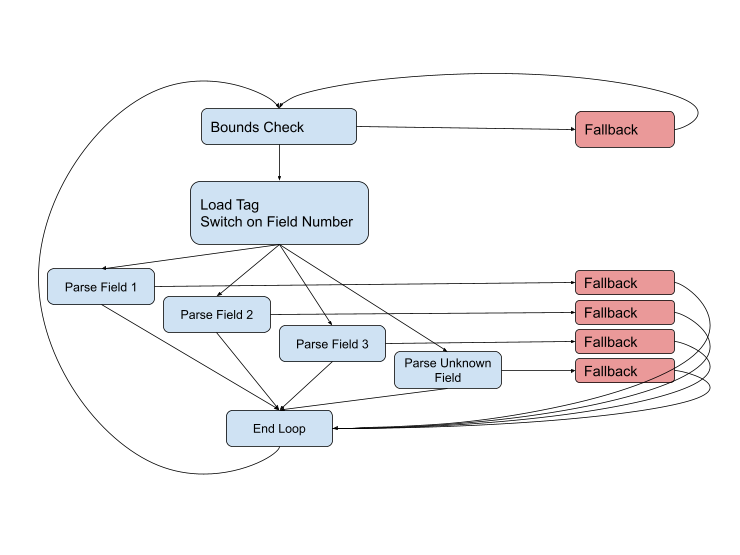
Kita harus tetap berada di jalur cepat (biru) selama mungkin, tetapi ketika dihadapkan pada situasi yang sulit, kita harus menanganinya menggunakan kode fallback. Jalur tersebut biasanya lebih panjang dan lebih kompleks daripada jalur cepat, jalur tersebut melibatkan lebih banyak data dan sering menggunakan panggilan canggung ke fungsi lain untuk menangani kasus yang bahkan lebih kompleks.
Secara teori, jika Anda menggabungkan skema ini dengan profil, kompilator akan mendapatkan semua informasi yang dibutuhkan untuk menghasilkan kode yang paling optimal. Namun dalam praktiknya, dengan ukuran fungsi dan jumlah koneksi ini, seringkali kita harus berkutat dengan compiler. Ini mengeluarkan variabel penting yang ingin kita simpan di register. Ini menerapkan manipulasi frame stack yang ingin kita bungkus di sekitar panggilan ke fungsi fallback. Ini menggabungkan jalur kode identik yang ingin kita pisahkan untuk prediksi cabang. Semuanya terlihat seperti mencoba bermain piano dengan sarung tangan.
Memperbaiki loop interpreter dengan panggilan ekor
Alasan yang dijelaskan di atas sebagian besar merupakan pengungkapan ulang dari pengamatan Paulus tentang siklus utama penafsir . Namun alih-alih menggunakan assembler, kami menemukan bahwa arsitektur yang disesuaikan dapat memberi kami kontrol yang kami butuhkan untuk mendapatkan kode yang hampir optimal dari C. Saya mengerjakan ini dengan kolega saya Gerben Stavenga, yang menghasilkan sebagian besar arsitektur. Pendekatan kami mirip dengan interpreter WebAssembly wasm3 , yang menyebut pola ini "metamachine" .
Kami menempatkan kode untuk parser 2- gigabit kami di upb, pustaka protobuf kecil di C. Ia bekerja sepenuhnya dan melewati semua tes untuk kepatuhan dengan protokol serialisasi, tetapi belum diterapkan di mana pun, dan arsitekturnya belum diimplementasikan dalam versi C ++ dari protokol. Tetapi ketika ekstensi datang ke Clang
musttail
(dan upb diperbarui untuk menggunakannya ), salah satu hambatan utama untuk implementasi penuh pengurai cepat kami turun.
Kami telah beralih dari satu fungsi parsing besar dan menerapkan fungsi kecilnya sendiri untuk setiap operasi. Setiap fungsi ekor memanggil operasi berikutnya secara berurutan. Misalnya, di sini adalah fungsi untuk mem-parsing satu bidang dengan ukuran tetap (kodenya disederhanakan dibandingkan dengan upb, saya telah menghapus banyak detail kecil dari arsitektur).
Kode
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
Untuk fungsi yang kecil dan sederhana, Clang menghasilkan kode yang hampir tidak mungkin dikalahkan:
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
Perhatikan bahwa tidak ada prolog atau epilog, tidak ada preemption register, tidak ada penggunaan stack sama sekali. Keluar hanya
jmp
dari panggilan dua ekor, tetapi tidak ada kode yang diperlukan untuk meneruskan parameter, karena argumen sudah ada di register yang benar. Mungkin satu-satunya peningkatan yang mungkin kita lihat di sini adalah lompatan bersyarat untuk panggilan ekor,
jne fallback
bukan panggilan
jne
berikutnya
jmp
.
Jika Anda melihat pembongkaran kode ini tanpa informasi simbolis, Anda tidak akan menyadari bahwa ini adalah keseluruhan fungsi. Ini juga bisa menjadi unit dasar dari fungsi yang lebih besar. Dan itulah yang kami lakukan: kami mengambil interpreter loop, yang merupakan fungsi besar dan kompleks, dan memprogramnya blok demi blok, meneruskan aliran kontrol di antara mereka melalui panggilan tail. Kami memiliki kendali penuh atas distribusi register di batas setiap blok (setidaknya enam register), dan karena fungsinya cukup sederhana dan tidak mendahului register, kami telah mencapai tujuan kami untuk menyimpan status paling penting di sepanjang semua puasa. jalur.
Kami secara independen dapat mengoptimalkan setiap urutan instruksi. Dan kompilator juga akan menangani semua urutan secara independen, karena mereka terletak di fungsi yang terpisah (jika perlu, Anda dapat mencegah penyejajaran dengan
noinline
). Ini adalah cara kami menyelesaikan masalah yang dijelaskan di atas, di mana kode dari jalur fallback menurunkan kualitas kode jalur cepat. Dengan menempatkan jalur lambat dalam fungsi yang benar-benar terpisah, stabilitas kecepatan jalur cepat dapat dijamin. Perakit cantik tetap tidak berubah, tidak terpengaruh oleh perubahan apa pun di bagian lain parser.
Jika kita menerapkan pola ini pada contoh Paulus dari LuaJIT , maka secara kasar kita bisa menghubungkan assembler tulisan tangannya dengan sedikit penurunan kualitas kode :
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Assembler yang dihasilkan:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
Satu-satunya peningkatan yang saya lihat di sini selain di atas adalah
jne fallback
bahwa untuk beberapa alasan compiler tidak ingin menghasilkan
jmp qword ptr [rsi + 8*rax]
, malah memuat
rax
dan kemudian mengeksekusi
jmp rax
. Ini adalah masalah pengkodean kecil yang saya harap Clang akan segera diperbaiki tanpa terlalu banyak kesulitan.
Batasan
Salah satu kelemahan utama dari pendekatan ini adalah bahwa semua urutan bahasa assembly yang indah ini secara serempak dinantikan dengan tidak adanya panggilan ekor. Setiap panggilan yang tidak disesuaikan akan membuat bingkai tumpukan dan mendorong banyak data ke tumpukan.
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Tiba-tiba kami mendapatkan ini
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
Untuk menghindari hal ini, kami mencoba memanggil fungsi lain hanya melalui panggilan sebaris atau ekor. Ini bisa membosankan jika operasi memiliki banyak tempat di mana situasi yang tidak biasa yang bukan merupakan kesalahan dapat terjadi. Misalnya, ketika kita mengurai protokol serialisasi, variabel integer seringkali satu byte, tetapi yang lebih panjang bukan merupakan kesalahan. Menyebariskan penanganan situasi seperti itu dapat menurunkan kualitas jalur cepat jika kode fallback terlalu rumit. Namun panggilan ekor dari fungsi fallback tidak membuatnya mudah untuk kembali ke operasi saat menangani kelainan, jadi fungsi fallback harus bisa menyelesaikan operasi. Hal ini menyebabkan duplikasi dan kerumitan kode.
Idealnya masalah ini dapat diselesaikan dengan menambahkan __attribute __ ((melestarikan_most))dalam fungsi fallback diikuti dengan panggilan normal, bukan panggilan ekor. Atribut tersebut
preserve_most
membuat callee bertanggung jawab untuk memelihara hampir semua register. Ini memungkinkan Anda mendelegasikan tugas mendahului register ke fungsi fallback, jika perlu. Kami bereksperimen dengan atribut ini, tetapi mengalami masalah misterius yang tidak dapat kami selesaikan. Mungkin kami membuat kesalahan di suatu tempat, kami akan kembali ke masalah ini di masa mendatang.
Batasan utama
musttail
adalah tidak portabel. Saya sangat berharap atribut ini akan berakar, itu akan diterapkan di GCC, Visual C ++ dan kompiler lain, dan suatu hari bahkan akan distandarisasi. Tetapi ini tidak akan segera terjadi, tetapi apa yang harus kita lakukan sekarang?
Saat ekspansi
musttail
tidak tersedia, Anda perlu mengeksekusi setidaknya satu yang benar
return
tanpa panggilan tail untuk setiap iterasi teoritis dari loop . Kami belum mengimplementasikan fallback seperti itu di pustaka upb, tetapi menurut saya ini akan berubah menjadi makro yang, bergantung pada ketersediaan,
musttail
akan membuat panggilan ekor atau hanya kembali.