"Aku tidak melihat apa-apa dalam dirinya," kataku, mengembalikan topi itu ke Sherlock Holmes.
“Tidak, Watson, kamu tahu, tapi kamu tidak mau bersusah payah untuk merenungkan apa yang kamu lihat.
Arthur Conan Doyle. Carbuncle biru
Dalam seri sebelumnya untuk pemula (posting pertama di sini ) dari remix dari buku Clojure for Data Science in Python karya Henry Garner, beberapa pendekatan numerik dan visual disajikan untuk memahami apa itu distribusi normal. Kami membahas beberapa statistik deskriptif seperti mean dan deviasi standar, dan bagaimana mereka dapat digunakan untuk meringkas sejumlah besar data secara singkat.
Kumpulan data biasanya merupakan sampel dari populasi yang lebih besar, atau populasi umum. Terkadang populasi ini terlalu besar untuk diukur sepenuhnya. Kadang-kadang sifatnya tidak dapat diukur karena ukurannya tidak terbatas atau karena tidak dapat diakses secara langsung. Bagaimanapun, kami dipaksa untuk menarik kesimpulan berdasarkan data yang kami miliki.
Dalam seri 4 posting ini, kita akan melihat implikasi statistik tentang bagaimana Anda dapat lebih dari sekadar mendeskripsikan sampel dan sebaliknya mendeskripsikan populasi dari mana sampel tersebut diambil. Kami akan melihat lebih dekat tingkat kepercayaan kami pada kesimpulan yang kami ambil dari data sampel. Kami akan mengungkapkan esensi dari pendekatan yang kuat untuk memecahkan masalah di bidang ilmu data, yaitu pengujian hipotesis statistik, yang hanya membawa keilmuan untuk mempelajari data.
Selain itu, selama presentasi, poin-poin penting yang terkait dengan penyimpangan terminologis dalam statistik domestik, terkadang mengaburkan makna dan konsep pengganti, akan disorot. Di akhir postingan terakhir, Anda dapat memilih atau menolak rangkaian postingan berikutnya. Sampai saat itu ...
, AcmeContent, .
AcmeContent
, , , AcmeContent . -, .
, AcmeContent - — . , -. , , - , - , AcmeContent , .
(dwell time)— , - , .
(bounce) — , — .
, , - - - - - - AcmeContent.
, : scipy, pandas matplotlib. pandas Excel, read_excel
. . pandas read_csv
, URL- .
- AcmeContent — - . :
ex_N_M, ex - example (), N - M - . . , .. - . , .
def load_data( fname ):
return pd.read_csv('data/ch02/' + fname, '\t')
def ex_2_1():
return load_data('dwell-times.tsv').head()
( Python Jupyter), , :
|
|
date |
dwell-time |
0 |
2015-01-01T00:03:43Z |
74 |
1 |
2015-01-01T00:32:12Z |
109 |
2 |
2015-01-01T01:52:18Z |
88 |
3 |
2015-01-01T01:54:30Z |
17 |
4 |
2015-01-01T02:09:24Z |
11 |
… |
… |
… |
, .
, dwell-time hist:
def ex_2_2():
load_data('dwell-times.tsv')['dwell-time'].hist(bins=50)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
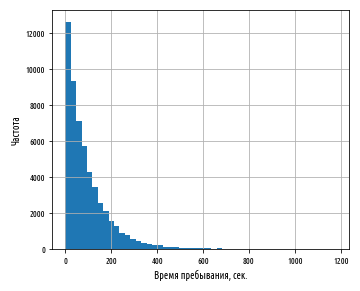
, ; . ( - 0 .). X , , .
, , , Y . , , . , « », . , , .
, , . , 10, , 5 10 4 . , — 30 10 20 . — .
Y logy=True
pandas plot.hist
:
def ex_2_3():
load_data('dwell-times.tsv')['dwell-time'].plot.hist(bins=20, logy=True)
plt.xlabel(' , .')
plt.ylabel(' ')
plt.show()
pandas , 10 . , , -. , - ( , loglog=True
).
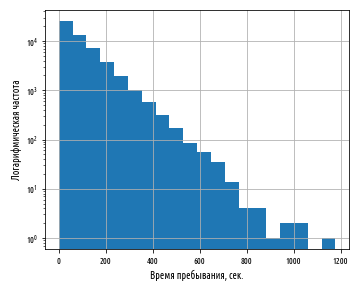
, — . , 10, , , .
— .
( ) , . , , , .
, — . , , . , — , -.
. :
def ex_2_4():
ts = load_data('dwell-times.tsv')['dwell-time']
print(': ', ts.mean())
print(': ', ts.median())
print(' :', ts.std())
: 93.2014074074074
: 64.0
: 93.96972402519819
. , . — .
.
( ). . , -, , , -, . 93 ., , 93 ., - .
, , - 93 . , , - 93 ., 5 . , .
x .
, . , ( ).
64 ., - . 93 . , . 6 . , . .
- . , , . Python, pandas — to_datetime.
, date-time, , , 1- Series
pandas , . , errors='ignore'
, . , mean_dwell_times_by_date
resample
. -, . 'D'
, mean
. , dt.resample('D').mean()
:
def with_parsed_date(df):
''' date date-time'''
df['date'] = pd.to_datetime(df['date'], errors='ignore')
return df
def filter_weekdays(df):
''' '''
return df[df['date'].index.dayofweek < 5] # ..
def mean_dwell_times_by_date(df):
''' '''
df.index = with_parsed_date(df)['date']
return df.resample('D').mean() #
def daily_mean_dwell_times(df):
''' - '''
df.index = with_parsed_date(df)['date']
df = filter_weekdays(df)
return df.resample('D').mean()
, :
def ex_2_5():
df = load_data('dwell-times.tsv')
mus = daily_mean_dwell_times(df)
print(': ', float(means.mean()))
print(': ', float(means.median()))
print(' : ', float(means.std()))
: 90.21042865056198
: 90.13661202185793
: 3.7223429053200348
90.2 . , , . , 3.7 . , , . :
def ex_2_6():
df = load_data('dwell-times.tsv')
daily_mean_dwell_times(df)['dwell-time'].hist(bins=20)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
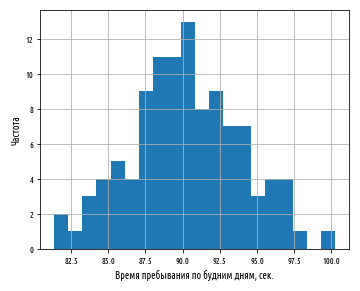
, 90 . 3.7 . , , .. , .
, . , , .
, , .
, - , — , , , . , , .
. , , . ( dropna, , ):
def ex_2_7():
''' '''
df = load_data('dwell-times.tsv')
means = daily_mean_dwell_times(df)['dwell-time'].dropna()
ax = means.hist(bins=20, normed=True)
xs = sorted(means) #
df = pd.DataFrame()
df[0] = xs
df[1] = stats.norm.pdf(xs, means.mean(), means.std())
df.plot(0, 1, linewidth=2, color='r', legend=None, ax=ax)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
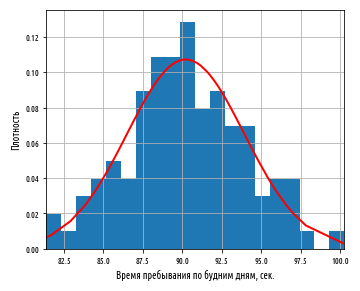
, , , 3.7 . , , 90 . , . 3.7 . — , , .
, (Standard Error, . SE) , , .
— .
, 6 . , , :

σx — , x, n — . , . . , — , :
def variance(xs):
''' () n <= 30'''
x_hat = xs.mean()
n = len(xs)
n = n-1 if n in range(1, 30) else n
square_deviation = lambda x : (x – x_hat) ** 2
return sum( map(square_deviation, xs) ) / n
def standard_deviation(xs):
return sp.sqrt(variance(xs))
def standard_error(xs):
return standard_deviation(xs) / sp.sqrt(len(xs))
:
. , , , .
, , , . , .
Topik posting berikutnya, posting # 2 , adalah perbedaan sampel dan populasi, serta selang kepercayaan. Ya, itu adalah interval kepercayaan , bukan interval kepercayaan.