
Halo, Habr!
Pada artikel ini, kita akan melihat beberapa pendekatan perkiraan deret waktu sederhana.
Materi yang disajikan dalam artikel, menurut saya, melengkapi kursus minggu pertama "Masalah Terapan Analisis Data" dari MIPT dan Yandex. Pada kursus yang ditunjukkan, Anda bisa mendapatkan pengetahuan teoritis yang cukup untuk memecahkan masalah memprediksi rangkaian dinamika, dan sebagai konsolidasi praktis materi, diusulkan menggunakan model ARIMA dari perpustakaan scipy untuk menghasilkan perkiraan gaji dalam bahasa Rusia. Federasi untuk tahun depan. Dalam artikel tersebut, kami juga akan menghasilkan perkiraan gaji, tetapi pada saat yang sama kami tidak akan menggunakan perpustakaan scipy , tetapi perpustakaan sklearn . Triknya, scipy sudah punya model ARIMA , tapi sklearn belum punya model siap pakai, jadi kita harus kerja keras dengan pulpen. Jadi, untuk memecahkan masalah tersebut, dalam arti tertentu, kita perlu mencari tahu cara kerja model dari dalam. Selain itu, sebagai materi tambahan, dalam artikel ini, masalah prediksi diselesaikan menggunakan jaringan saraf lapisan tunggal pustaka pytorch .
Semua kode ditulis dengan python 3 di notebook jupyter . Selain itu, notebook dirancang sedemikian rupa sehingga selain data upah, Anda dapat mengganti banyak rangkaian dinamika lainnya, misalnya, data harga gula, mengubah peramalan, validasi dan periode pelatihan, menambahkan faktor eksternal lain dan membentuk ramalan yang tepat. Dengan kata lain, simulator yang ditulis sendiri sederhana digunakan dalam pekerjaan, dengan bantuan yang memungkinkan untuk memprediksi berbagai rangkaian dinamika. Kode tersebut dapat dilihat di sini
Garis besar artikel
- Deskripsi singkat tentang simulator.
- Solusi langsungnya adalah memperkirakan deret waktu hanya dengan menggunakan data "mentah" dari nilai deret waktu lampau.
- Menambahkan variabel eksogen.
- Koreksi heteroskedastisitas melalui logaritma data awal.
- Membawa baris ke baris stasioner.
- Perkiraan dengan jaringan neural lapisan tunggal.
- Perbandingan pendekatan.
- link yang berguna
Deskripsi singkat tentang simulator
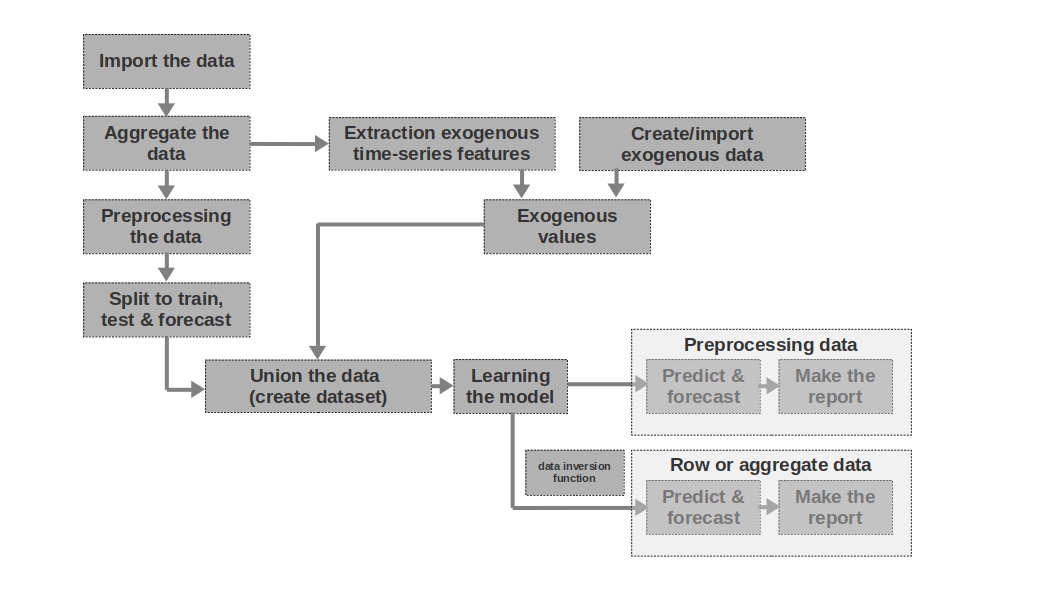
Impor data
Semuanya sederhana di sini - kami mengimpor data. Kadang-kadang terjadi bahwa data mentah cukup untuk membentuk ramalan yang lebih atau kurang dapat dipahami. Ini adalah prakiraan pertama dan kedua dalam artikel yang dimodelkan berdasarkan data mentah, yaitu, data mentah tentang upah pada periode sebelumnya digunakan untuk meramalkan upah.
Kumpulkan data
Artikel tidak menggunakan agregasi data karena tidak diperlukan. Namun, data seringkali dapat disajikan pada interval waktu yang tidak sama. Dalam hal ini, Anda hanya perlu menggabungkannya. Misalnya, data dari perdagangan sekuritas, mata uang, dan instrumen keuangan lainnya harus digabungkan. Biasanya, nilai rata-rata dalam interval diambil, tetapi maksimum, minimum, deviasi standar, dan statistik lainnya juga dimungkinkan.
Pemrosesan awal data
Dalam kasus kami, kami berbicara terutama tentang pemrosesan awal data, yang karenanya deret waktu memperoleh properti homoskedastisitas (melalui logaritma data) dan menjadi stasioner (melalui diferensiasi deret).
Pisahkan untuk melatih, menguji & memperkirakan
Dalam blok kode ini, deret waktu dibagi menjadi periode pelatihan, pengujian, dan perkiraan dengan menambahkan kolom baru dengan nilai yang sesuai "train", "test", "forecast". Artinya, kami tidak membuat tiga tabel terpisah untuk setiap periode, tetapi cukup menambahkan kolom, yang berdasarkan data tersebut kami akan membagi lebih lanjut.
Ekstraksi fitur deret waktu eksogen
Mengisolasi fitur eksternal (eksogen) tambahan dari deret waktu dapat berguna. Misalnya, tunjukkan apakah ini hari libur atau bukan, tunjukkan jumlah hari dalam sebulan (atau jumlah hari kerja dalam sebulan), dll. Biasanya, tanda-tanda ini "ditarik" dari deret waktu sendiri tanpa intervensi manual.
Membuat / mengimpor data eksogen
Tidak semua informasi dapat "ditarik" dari deret waktu. Terkadang data eksternal tambahan mungkin diperlukan. Misalnya, beberapa peristiwa episodik yang berdampak kuat pada nilai deret waktu. Peristiwa semacam itu mungkin tanggal dimulainya permusuhan, pengenaan sanksi, bencana alam, dll. Pekerjaan tidak mempertimbangkan faktor-faktor tersebut, tetapi kemungkinan penggunaannya harus diingat.
Nilai eksogen
Dalam blok kode ini, kami menggabungkan semua data eksogen ke dalam satu tabel.
Menyatukan data (membuat dataset)
Dalam blok kode ini, kami menggabungkan nilai-nilai deret waktu dan fitur-fitur eksogen ke dalam satu tabel. Dengan kata lain, kami sedang menyiapkan kumpulan data, yang menjadi dasarnya kami akan melatih model, menguji kualitas, dan membentuk perkiraan.
Mempelajari model
Semuanya jelas di sini - kami hanya melatih model.
Data praproses: prediksi & ramalan
Jika kita menggunakan data praproses untuk melatih model (logaritmik, diproses oleh fungsi box-coke, seri stasioner, dll.), Maka kualitas model dievaluasi terlebih dahulu pada data yang telah diproses sebelumnya dan hanya lalu pada data "mentah". Jika kami tidak melakukan praproses data, maka tahap ini dilewati.
Data baris: prediksi & ramalan
Tahap ini adalah tahap terakhir. Jika model dilatih pada data yang diproses sebelumnya, misalnya, kami memproklamasikannya, lalu untuk mendapatkan perkiraan upah dalam rubel, dan bukan logaritma rubel, kami harus menerjemahkan prakiraan itu kembali ke dalam rubel.
Saya juga ingin mencatat bahwa artikel tersebut menggunakan deret waktu satu dimensi untuk memprediksi upah. Namun, tidak ada yang menghalangi Anda untuk menggunakan seri multidimensi, misalnya, menambahkan data tentang nilai tukar rubel terhadap dolar atau seri lainnya.
Keputusan di dahi
Kami akan berasumsi bahwa data tentang gaji di masa lalu dapat mendekati gaji di masa yang akan datang. Dengan kata lain, besaran upah, misalnya, di bulan Januari bergantung pada berapa upah di bulan Desember, November, Oktober, ...
Mari kita ambil nilai-nilai upah dalam 12 bulan terakhir untuk memprediksi upah di bulan ke-13. Dengan kata lain, untuk setiap nilai target, kita akan memiliki 12 fitur.
Tanda-tanda tersebut akan diumpankan ke input Ridge Regression dari perpustakaan sklearn. Kami mengambil parameter default model, kecuali untuk parameter alfa, itu disetel ke 0, artinya, kami menggunakan regresi reguler.
Ini adalah solusi langsung - ini yang paling sederhana :) Ada situasi ketika Anda perlu memberikan setidaknya beberapa hasil dengan sangat mendesak, tetapi tidak ada waktu untuk praproses apa pun atau tidak ada cukup pengalaman untuk memproses atau menambahkan data dengan cepat. Dalam situasi seperti itu, Anda dapat menggunakan data mentah sebagai dasar untuk membuat perkiraan. Ke depan, saya perhatikan bahwa kualitas model ternyata sebanding dengan kualitas model yang menggunakan praproses data.
Mari kita lihat apa yang kita punya.
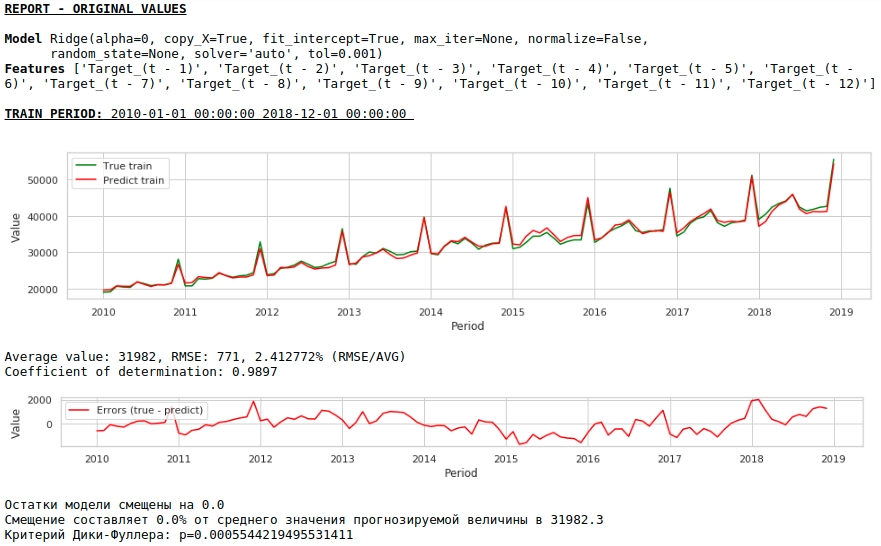
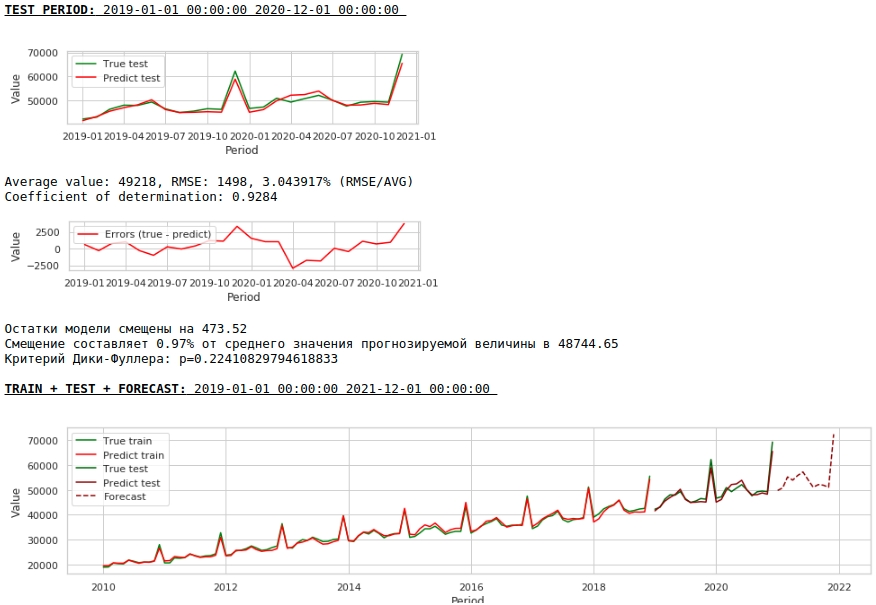
Sekilas, hasilnya terlihat, meski tidak sempurna, tapi mendekati kenyataan.
Sesuai dengan nilai koefisien regresi, nilai gaji memiliki pengaruh paling besar terhadap ramalan upah tepat setahun yang lalu.
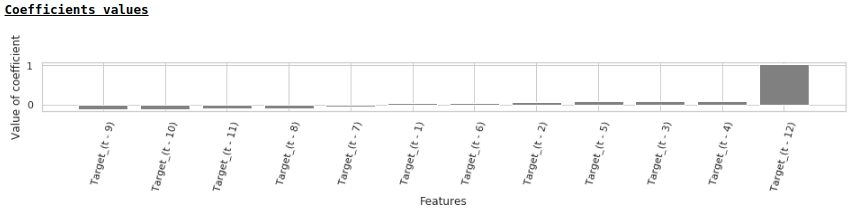
Mari kita coba menambahkan variabel eksogen ke model.
Menambahkan variabel eksogen
Kami akan menggunakan 2 tanda eksternal: jumlah hari dalam sebulan dan jumlah bulan (dari 1 hingga 12). Kita binarisasi atribut "Bulan nomor", sebagai hasilnya kita mendapatkan 12 kolom untuk setiap bulan dengan nilai 0 atau 1.
Mari kita bentuk dataset baru dan lihat kualitas modelnya.
Menonton grafik
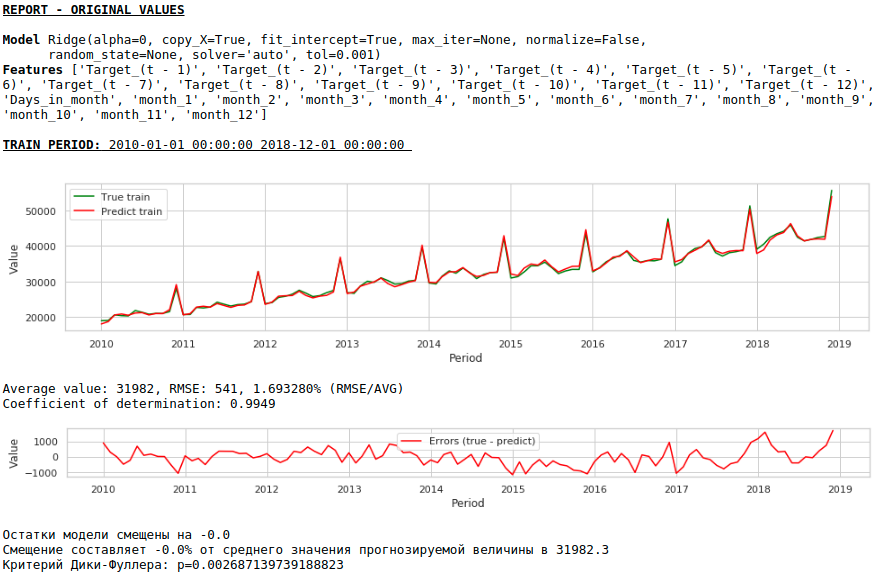
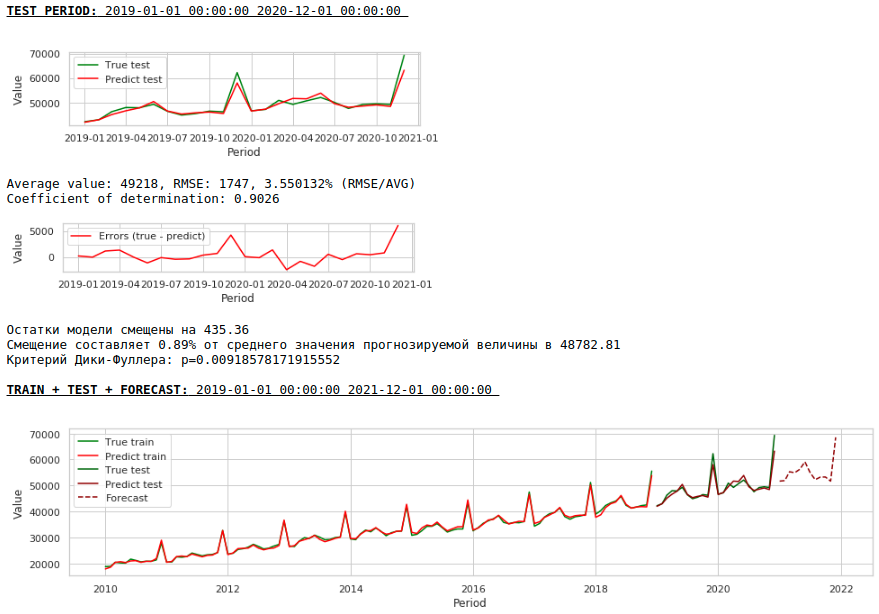
Kualitasnya lebih rendah. Secara visual, terlihat bahwa ramalan tersebut tidak terlihat sepenuhnya masuk akal dalam kaitannya dengan pertumbuhan upah di bulan Desember.
Sekarang mari kita lakukan preprocessing data pertama.
Koreksi heteroskedastisitas.
Jika kita melihat grafik pengupahan untuk periode 2010 hingga 2020, kita dapat melihat bahwa sebaran upah dalam satu tahun antar bulan meningkat setiap tahun.
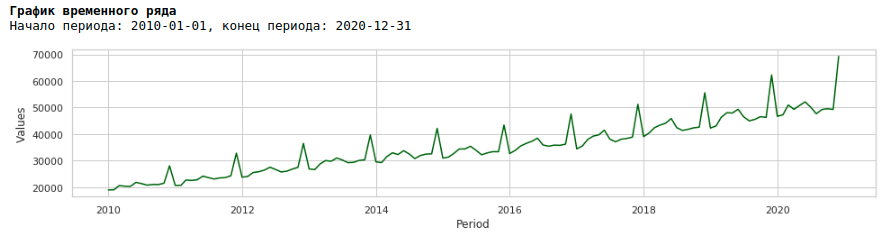
Peningkatan varians tahunan dari bulan ke bulan menyebabkan heteroskedastisitas. Untuk meningkatkan kualitas peramalan, kita harus menyingkirkan properti data ini dan membawanya ke homoskedastisitas.
Untuk melakukan ini, kita akan menggunakan logaritma biasa dan melihat bagaimana deret logaritma terlihat.
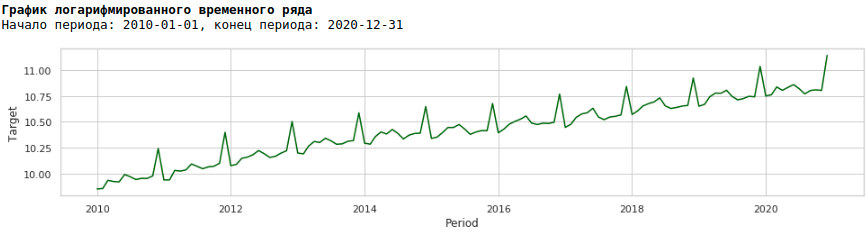
Mari latih model pada deret logaritmik
Menonton grafik
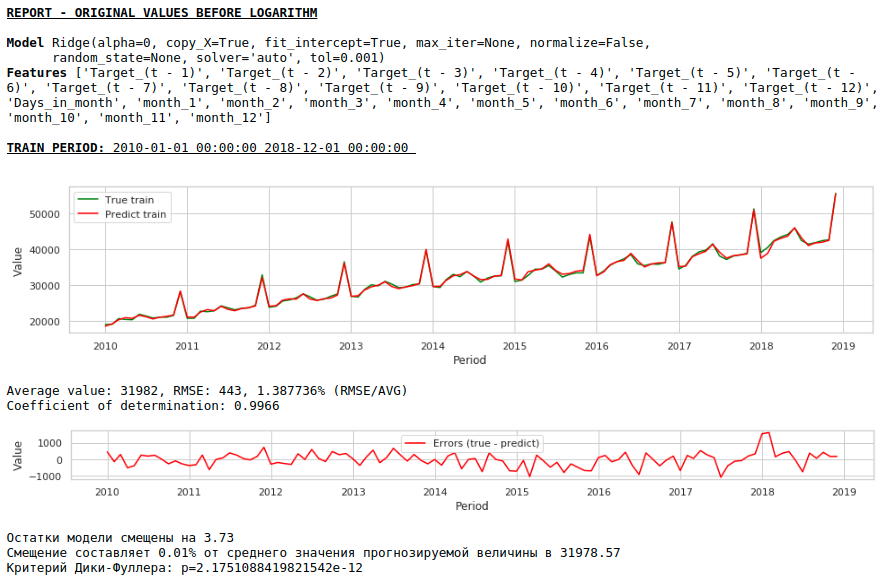
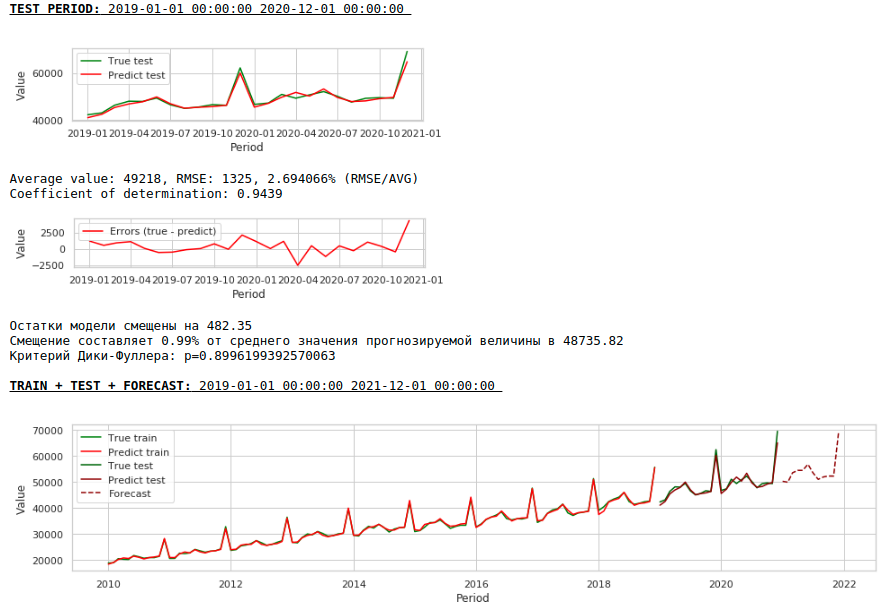
Hasilnya, kualitas prediksi pada sampel pelatihan dan pengujian memang meningkat, namun perkiraan untuk tahun 2021 secara visual terlihat kurang masuk akal dibandingkan dengan perkiraan model pertama. Kemungkinan besar, penggunaan faktor eksogen menurunkan model.
Membawa baris ke alat tulis
Kami akan mengurangi seri menjadi satu stasioner sebagai berikut:
- Tentukan selisih antara nilai gaji target dengan nilai setahun yang lalu: t - (t-12) = dif_1
- Tentukan selisih antara yang diterima dan digeser dengan nilai 1 bulan: dif_1 - (dif_1-1) = dif_2
Hasilnya, kita mendapatkan deret waktu berikut.
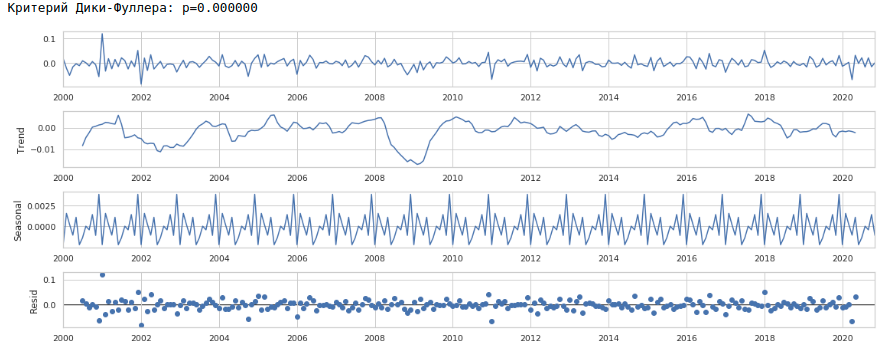
Rangkaiannya benar-benar terlihat tidak bergerak, hal ini juga ditunjukkan dengan nilai kriteria Dickey-Fuller.
Tidak perlu mengharapkan kualitas prediksi yang baik pada sampel pelatihan dan pengujian pada data yang diproses, yaitu pada seri stasioner, karena sebenarnya dalam hal ini model harus memprediksi nilai white noise. Tetapi bagi kami, untuk memprediksi upah, sama sekali tidak perlu menggunakan regresi, karena, dengan mereduksi rangkaian menjadi seri stasioner, kami, secara sederhana, telah menentukan rumus untuk mendekati variabel target. Tetapi kami tidak akan menyimpang dari kanon dan menggunakan model regresi, selain itu, kami memiliki faktor eksogen.
Mari kita lihat apa yang terjadi.
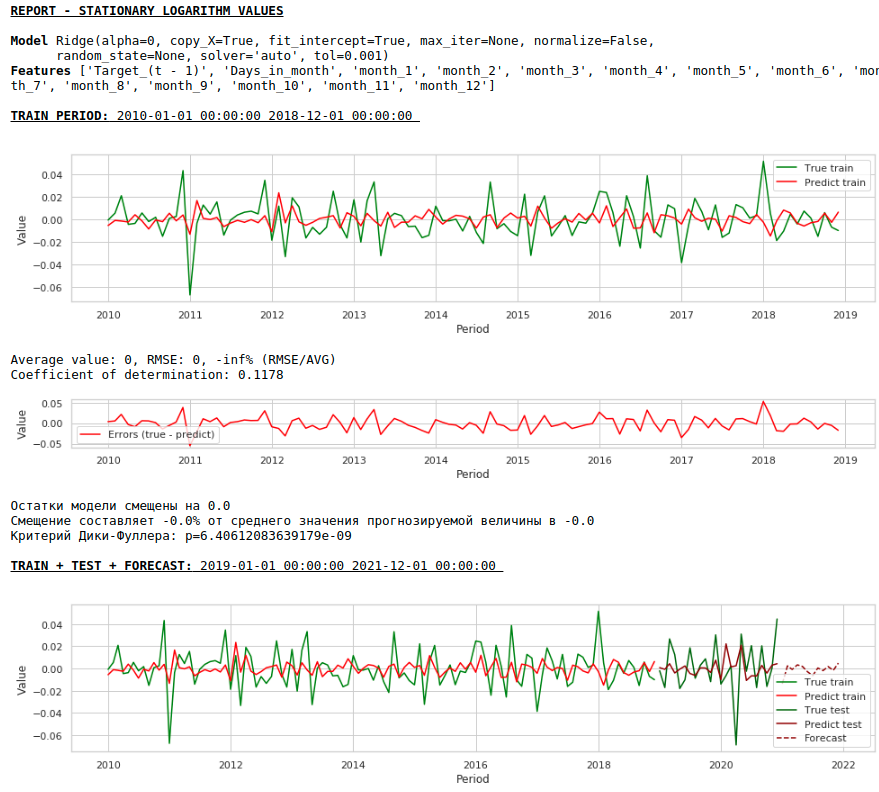
Seperti inilah tampilan prediksi deret stasioner. Seperti yang diharapkan - tidak terlalu bagus :)
Dan berikut adalah prediksi dan perkiraan upah.
Menonton grafik
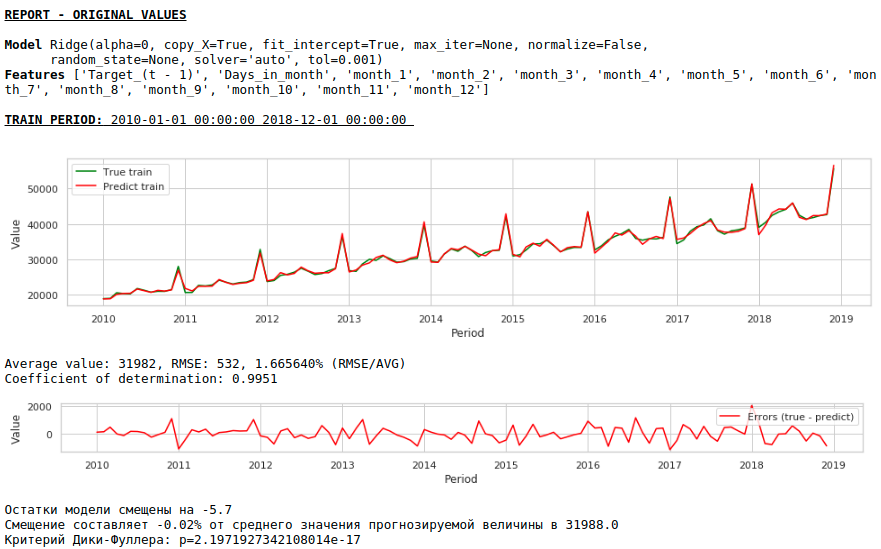
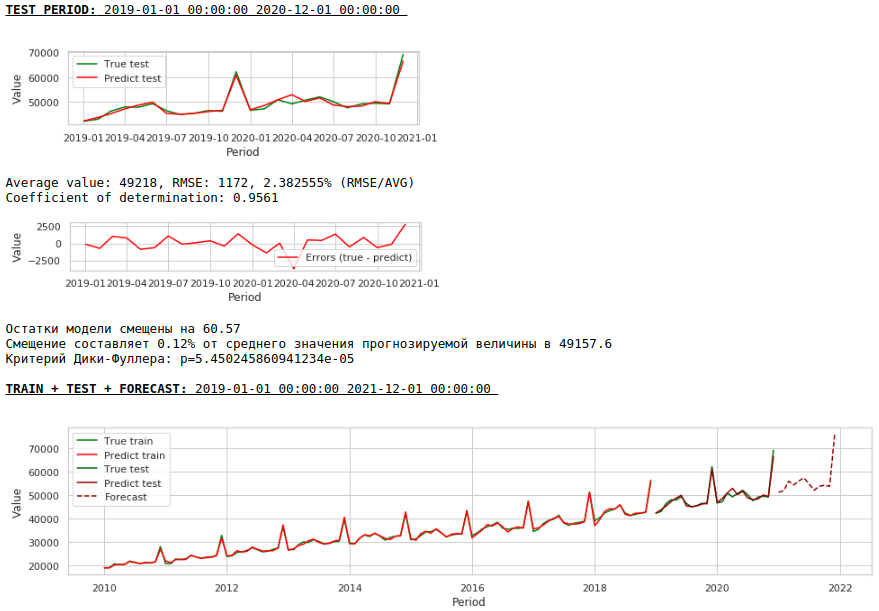
Kualitasnya telah meningkat secara nyata dan ramalannya dapat dipercaya secara visual.
Sekarang mari kita membuat ramalan tanpa menggunakan variabel eksogen.
Menonton grafik
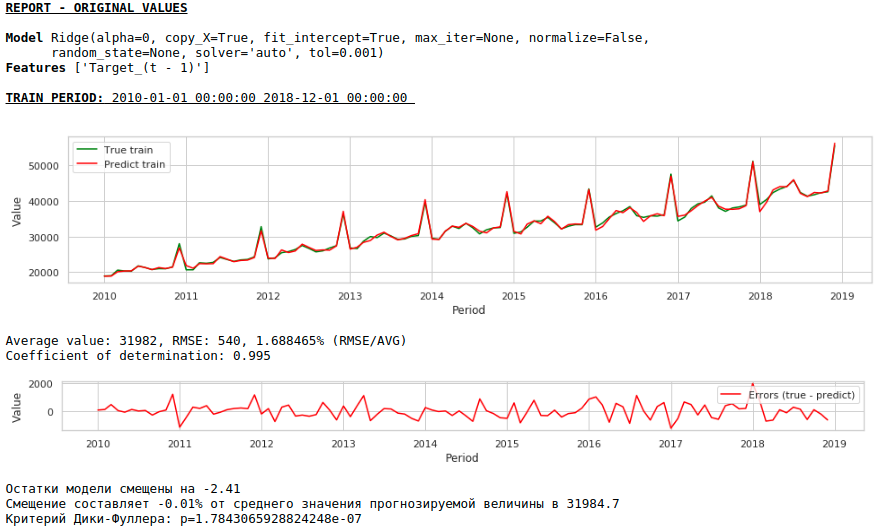
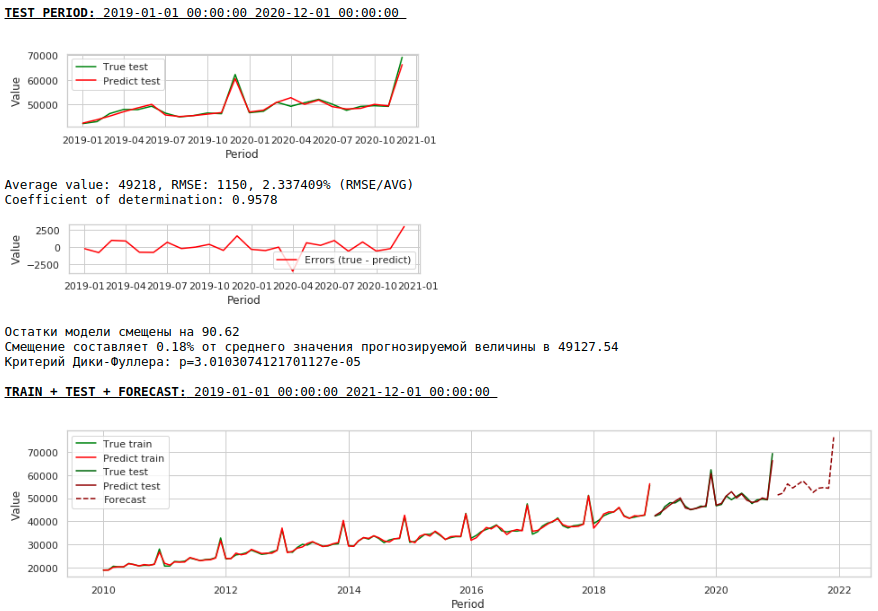
Kualitasnya semakin meningkat dan perkiraan yang masuk akal dipertahankan :)
Perkiraan dengan jaringan neural lapisan tunggal
Kami akan memberi makan kumpulan data yang ada ke input dari jaringan saraf. Karena jaringan kita adalah lapisan tunggal, sebenarnya ini adalah regresi linier yang sama dengan modifikasi sederhana dan Anda tidak perlu mengharapkan perbedaan yang sangat besar dalam kualitas prediksi.
Pertama, mari kita lihat jaringan itu sendiri.
Lihat kodenya
class Model_1(nn.Module):
def __init__(self, input_size, output_size):
super(Model_1, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.linear = nn.Linear(self.input_size, self.output_size)
def forward(self, x):
output = self.linear(x)
return output
Sekarang beberapa kata tentang bagaimana kami akan melatihnya.
- Kami memperbaiki benih acak untuk tujuan reproduktifitas hasil
- Menginisialisasi model
- Mengatur fungsi kerugian - MSELoss
- Memilih pengoptimal Adam sebagai pengoptimal
- Kami menunjukkan langkah awal pelatihan dan menentukan kondisi di mana langkah tersebut diturunkan. Perhatikan bahwa pilihan langkah yang benar dan perubahan selanjutnya (biasanya penurunan) memberikan hasil yang baik.
- Tentukan jumlah periode pembelajaran
- Kami memulai pelatihan
- Kami menyediakan seluruh dataset ke input jaringan, karena sangat kecil dan tidak masuk akal untuk memecahnya menjadi beberapa batch
- Selama pelatihan, setiap seribu masa kami membentuk grafik nilai fungsi kerugian pada sampel pelatihan dan pengujian. Hal ini memungkinkan kami untuk mengontrol overfitting atau tidak melatih ulang model.
Di bawah ini adalah kode untuk melatih jaringan pada dataset pertama. Untuk setiap set data, parameternya sedikit berubah: jumlah periode pelatihan dan langkah pelatihan.
Lihat kodenya
# fix the random seed
SEED = 42
random_init(SEED)
# initialization model, loss function, optimizator
model = Model_1(len(features),1)
loss_func = nn.MSELoss()
opt = torch.optim.Adam(model.parameters(), lr=5e-2)
# set the epoch numbers, initialization list for every loss after learning on epoch
epochs = 15000
losses_train = []
losses_test = []
# initialization counter for calculation epoch numbers
counter = 0
# start the learning model
for epoch in range(epochs):
model.train()
# make prediction targets on train data
y_pred_train = model(torch.tensor(X_train.to_numpy(), dtype=torch.float))
# calculate loss
loss = loss_func(y_pred_train,
torch.reshape(torch.tensor(y_train.to_numpy(), dtype=torch.float),(-1,1)))
# bacward loss to model and calculate new parameters (coefficients) with fixed learning rate
loss.backward()
opt.step()
opt.zero_grad()
# add loss to list losses
losses_train.append(loss)
model.eval()
y_pred_test = model(torch.tensor(X_test.to_numpy(), dtype=torch.float))
loss_test = loss_func(y_pred_test,
torch.reshape(torch.tensor(y_test.to_numpy(), dtype=torch.float),(-1,1)))
losses_test.append(loss_test)
# make the mini report for every 1000 epoch
if epoch % 1000 == 0 and epoch > 0:
print ('Epoch:', epoch // 1000)
print ('Learning rate:', opt.param_groups[0]['lr'])
print ('Last loss on TRAIN data:', losses_train[-1].cpu().detach().numpy(),
' Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
# print ('Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
fig, (ax1, ax2) = plt.subplots(1, 2)
# fig.suptitle('MSE on TRAIN & TEST DATA')
fig.set_figheight(3)
fig.set_figwidth(12)
ax1.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_train][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TRAIN data")
ax2.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_test][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TEST data")
plt.show()
counter += 1000
# reduce learning rate
if epoch == 1000:
opt = torch.optim.Adam(model.parameters(), lr=7e-3)
Kami tidak akan mempertimbangkan kualitas prediksi untuk setiap dataset secara terpisah (mereka yang ingin dapat melihat detailnya di gita). Mari bandingkan hasil akhirnya.
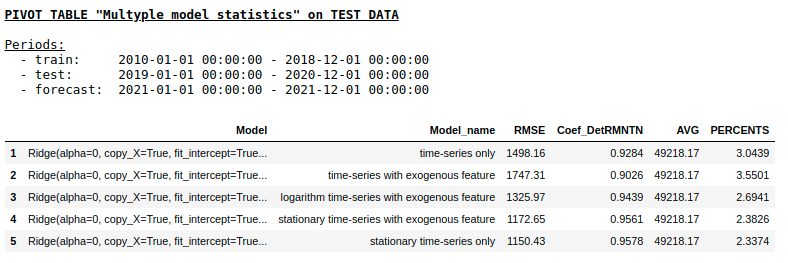
Kualitas pada sampel uji menggunakan Ridge Regression
Quality pada sampel uji menggunakan Single layer NN
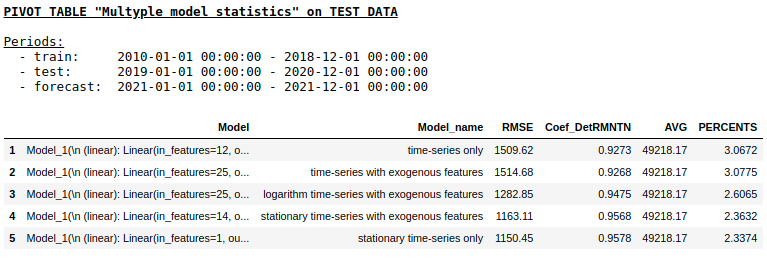
Seperti yang kami harapkan, tidak ada perbedaan mendasar antara regresi reguler dan jaringan saraf lapisan tunggal sederhana. Tentu saja, neuron memberikan lebih banyak manuver untuk pembelajaran: Anda dapat mengubah pengoptimal, menyesuaikan langkah-langkah pembelajaran, menggunakan lapisan tersembunyi dan fungsi aktivasi, Anda dapat melangkah lebih jauh dan menggunakan jaringan saraf berulang - RNN. Ngomong-ngomong, secara pribadi, saya tidak bisa mendapatkan kualitas yang waras dalam masalah ini menggunakan RNN, namun, di Internet, Anda dapat menemukan banyak contoh menarik dari peramalan deret waktu menggunakan LSTM.
Pada titik ini, artikel itu berakhir. Saya berharap materi ini dapat berguna sebagai semacam gambaran umum dari pendekatan dasar yang digunakan dalam meramalkan deret waktu dan akan menjadi tambahan praktis yang baik untuk kursus "Masalah Terapan Analisis Data" dari MIPT dan Yandex.